
Hadoop — фреймворк, предназначенный для построения распределённых приложений для работы с данными очень большого объёма. Hadoop реализует вычислительную парадигму MapReduce, в которой приложение разбивается на множество независимых частей, каждая из которых может исполняться на отдельном узле.
Главным языком проекта является Java.
Примеры использования Hadoop (и парадигмы MapReduce вообще) [1] :
- распределённый grep;
- распределённая сортировка;
- кластеризация документов;
- обработка статистики журналов доступа;
- машинное обучение;
- построение обратного индекса;
- статистический перевод.
Hadoop применяет для обработки только очень большого количества данных, которые хранятся распределённо на множестве узлов. Грубым правилом оценки целесообразности использования Hadoop можно считать такое: если данные можно уместить на одном узле (несколько терабайтов), то смысла в Hadoop нет; если нужно обрабатывать десятки или сотни, то имеет смысл [2] . Так же нужно учитывать, какой объём данных обрабатывается в ходе одного типичного запроса и допустимое время на эту обработку: даже если данных всего один терабайт, но запрос должен выполняться за несколько минут, распределённая обработка неизбежна: при скорости доступа к диску 100 MB/s чтобы прочитать только один терабайт потребуется 3 часа, если чтение будет выполняться на одном узле.
Поднимаем Hadoop-кластер локально | Скринкасты | Ok #1
Важнейшие компоненты инфраструктуры Hadoop:
- HDFS (Hadoop Distributed Filesystem) — распределённая файловая система, работающая на больших кластерах из обычных машин;
- Avro — фреймворк/библиотека для сериализации данных, наподобие Google Protocol Buffers;
- Pig — высокоуровневая платформа для создания MapReduce-программ;
- Hive — высокоуровневой программное обеспечение, позволяющее управлять и опрашивать большие объёмы данных, находящиеся в инфраструктуре Hadoop; использует свой собственный SQL-подобный язык, HiveQL;
- HBase — распределённая, колонко-ориентированная СУБД, работающая поверх HDFS;
- ZooKeeper — служба, предназначенная для хранения конфигурационной информации, имён, выполнения распределённой синхронизации процессов;
- Sqoop — программа для переноса большого объёма данных из структурированных хранилищ (например, реляционных СУБД) на HDFS;
- MRUnit — Java-библиотека, предназначенная для юнит-тестирования MapReduce-работ;
- Oozie — планировщик, управляющий взаимосвязанными задачами MapReduce и Pig.
Слабые стороны Hadoop
Где Hadoop значительно проигрывает конкурентам в производительности [3] :
- Database joins (compare any SQL database);
- OLTP (compare VoltDB);
- Realtime analytics (compare Cloudscale);
- Supercomputing, e.g. modelling, simulation, fluid dynamics (compare MPI and BSP);
- Graph computing (compare Pregel);
- Interactive analysis of big data (compare Dremel);
- Incremental analysis of big data (compare Cloudscale or Percolator/Caffeine).
На этом минусы Hadoop не заканчиваются. Нужно помнить также, что:
Очень кратко про Hadoop и Spark
- Hadoop это фреймворк, а не готовое решение;
- Hive и Pig имеют множество архитектурных ограничений в сравнении с реляционной СУБД;
- Hadoop легко установить и настроить, но сложнее сопровождать;
- Сложно выполнять AdHoc-анализ;
- В некоторых случаях Hadoop очень медленный.
Основные понятия
MapReduce
HDFS
Datanode Узлы, на которых хранятся данные файлов. Namenode Узел, на котором находится информация о том, на каких узлах и в каких блоках находятся файлы. Secondary namenode Фактически не является namenode, несмотря на имя. Задача secondary namenode заключается в том чтобы периодически вносить в образ пространства имён изменения из лога операций, чтобы лог не разрастался.
HDFS
- ориентация на работу с большими файлами;
- ориентация на работу в режиме «однократная запись, многократное чтение»;
- отсутствие особенных требований к оборудованию.
Слабые места HDFS:
- работа с маленькими файлами;
- одновременная запись из нескольких источников;
- сложности с обеспечением маленького времени доступа.
Веб-интерфейс
- http://localhost:50070/
- http://localhost:50030/
Hadoop Streaming
Основным языком Hadoop является Java. Но, конечно, можно использовать и другие языки. Механизм, с помощью которого Hadoop может запускать программы, написанные на других языках называется Streaming. Программы получают данные через стандартный поток ввода и отдают на стандартный поток вывода.
Вот простейший пример использования стриминга:
Обработка данных выполняется маленьким скриптом, написанным на awk.
Hadoop и Python
Программы на Python могут быть запущенны двумя разными способами:
- Через интерфейс Streaming;
- Через Jython.
Запуск через streaming проще и очевиднее.
Пример использования Streaming на Python:
#!/usr/bin/env python import sys for line in sys.stdin: line = line.strip() keys = line.split() for key in keys: value = 1 print( «%st%d» % (key, value) )
#!/usr/bin/env python import sys last_key = None running_total = 0 for input_line in sys.stdin: input_line = input_line.strip() this_key, value = input_line.split(«t», 1) value = int(value) if last_key == this_key: running_total += value else: if last_key: print( «%st%d» % (last_key, running_total) ) running_total = value last_key = this_key if last_key == this_key: print( «%st%d» % (last_key, running_total) )
from itertools import groupby from operator import itemgetter import sys def read_mapper_output(file, separator=’t’): for line in file: yield line.rstrip().split(separator, 1) def main(separator=’t’): data = read_mapper_output(sys.stdin, separator=separator) for current_word, group in groupby(data, itemgetter(0)): try: total_count = sum(int(count) for current_word, count in group) print «%s%s%d» % (current_word, separator, total_count) except ValueError: # count was not a number, so silently discard this item pass if __name__ == «__main__»: main()
$ head -n1000 mobydick.txt | ./mapper.py | sort | ./reducer.py
hadoop jar /opt/hadoop/contrib/streaming/hadoop-streaming-1.0.3.jar -mapper «python $PWD/mapper.py» -reducer «python $PWD/reducer.py» -input «wordcount/mobydick.txt» -output «wordcount/output»
Дополнительная информация
- Writing MapReduce Program in Python (англ.) — очень простое пошаговое руководство, рассказывающее как запускать Python-программу в Hadoop через streaming-интерфейс
- Java vs Python on Hadoop — сравнение Python и Java в контексте использования с Hadoop
- A starting point for learning how to implement MapReduce/Hadoop in Python?
- MapReduce Patterns, Algorithms, and Use Cases (англ.)
- Finding Similar Items with Amazon Elastic MapReduce, Python, and Hadoop Streaming (англ.) — простейший пример использования Hadoop и Python в Amazon
- Hadoop in Action (Paperback) (англ.) — введение в Hadoop и Python, книга
- mrjob (англ.) — python-модуль для запуска задач через streaming
Hadoop и Scala
Засчёт хорошей интеграции Scala и JVM, программы на Scala можно использовать непосредственно с Hadoop, без Streaming. Есть несколько библиотек/API для совместного использования Scala и Hadoop:
- scalding
- Scoobi
- Scrunc
Пример Map/Reduce-кода для Hadoop на Scala (scalding):
package com.twitter.scalding.examples import com.twitter.scalding._ class WordCountJob(args : Args) extends Job(args) < TextLine( args(«input») ) .flatMap(‘line ->’word) < line : String =>tokenize(line) > .groupBy(‘word) < _.size >.write( Tsv( args(«output») ) ) // Split a piece of text into individual words. def tokenize(text : String) : Array[String] = < // Lowercase each word and remove punctuation. text.toLowerCase.replaceAll(«[^a-zA-Z0-9\s]», «»).split(«\s+») >>
Другие примеры использования Scalding:
- Scalding Rosetta Code
И с использованием Scoobi:
import Scoobi._, Reduction._ val lines = fromTextFile(«hdfs://in/. «) val counts = lines.mapFlatten(_.split(» «)) .map(word => (word, 1)) .groupByKey .combine(Sum.int) counts.toTextFile(«hdfs://out/. «, overwrite=true).persist(ScoobiConfiguration())
Небольшая презентация на тему сравнения scalding и scoobi:
- Why Hadoop MapReduce needs Scala (англ.)
Дополнительная информация
- MapReduce: Simplified Data Processing on Large Clusters (англ.) — первоначальная статья от Google на тему MapReduce
- Powerde By Hadoop (англ.) — примеры использования Hadoop в реальных инсталляциях
- Writing An Hadoop MapReduce Program In Python (англ.) — небольшое введение в Hadoop на примере простейших Python-скриптов
Инсталляция и базовая настройка
- Running Hadoop on Ubuntu Linux (Single-Node Cluster) (англ.) — небольшое хауту о том, как запускать hadoop на ubuntu
- Running Hadoop on Ubuntu Linux (Multi-Node Cluster) (англ.) — небольшое хауту о том, как запускать hadoop на ubuntu, несколько узлов
- Installing Apache Hadoop — Hadoop: The Definitive Guide (англ.) — небольшое введение в Hadoop (инсталляция и базовая настройка)
- Cloudera Hadoop RHEL/CentOS 6 Install Guide (англ.)
- Setting up a Hadoop cluster — Part 1: Manual Installation (англ.)
- Set Up and Run a Fully Distributed Hadoop/HBase Cluster In (About) an Hour. (Quickstart) (англ.)
Книги по Hadoop
- 15+ Great Books for Hadoop (англ.) — краткое описание 15 разных книг по Hadoop
Примечания
- ↑http://research.google.com/archive/mapreduce-osdi04-slides/index-auto-0005.html
- ↑http://www.chrisstucchio.com/blog/2013/hadoop_hatred.html
- ↑https://www.quora.com/What-is-Hadoop-not-good-for
Источник: xgu.ru
Что такое Apache Hadoop в Azure HDInsight?
Первоначально технология Apache Hadoop была платформой с открытым кодом для распределенной обработки и анализа наборов больших данных в кластерах. Экосистема Hadoop состоит из взаимосвязанного программного обеспечения и служебных программ, таких как Apache Hive, Apache HBase, Spark, Kafka и т. д.
Azure HDInsight — это полностью управляемая комплексная облачная служба аналитики с открытым кодом, предназначенная для предприятий. Тип кластера Apache Hadoop в Azure HDInsight позволяет использовать распределенную файловую систему Apache Hadoop (HDFS) и управление ресурсами Apache Hadoop YARN, а также простую модель программирования MapReduce для параллельной обработки и анализа пакетных данных. Кластеры Hadoop в HDInsight совместимы с Хранилищем BLOB-объектов Azure, Azure Data Lake Storage 1-го поколения или Azure Data Lake Storage 2-го поколения.
Просмотреть доступные компоненты стека технологии Hadoop в HDInsight можно в статье Что представляют собой компоненты и версии Hadoop, доступные в HDInsight? Дополнительные сведения о Hadoop в HDInsight см. на странице возможностей HDInsight в Azure.
Что такое MapReduce
Apache Hadoop MapReduce — это программная платформа для создания заданий, обрабатывающих большие объемы данных. Входные данные разбиваются на независимые блоки, которые затем обрабатываются параллельно на узлах кластера. Задание MapReduce состоит из двух функций.
- Mapper(Модуль сопоставления) — принимает входные данные, анализирует их (обычно с помощью фильтрации и сортировки) и передает кортежи (пары «ключ-значение»).
- Reducer(Редуктор) — принимает кортежи, сформированные в модуле сопоставления, и выполняет операцию сводки, которая создает результат меньшего размера, объединяющий данные модуля сопоставления
На следующей диаграмме показан пример задания MapReduce, которое выполняет простую операцию подсчета слов:
Выходные данные этого задания представляют собой частоту использования каждого слова в тексте.
- Процедура map берет каждую строку из входного текста в качестве входных данных и разбивает ее на слова. Она генерирует пару «ключ-значение» каждый раз, когда встречается слово, за которым следует 1. Перед отправкой на обработку редуктором выходные данные сортируются.
- Затем редуктор суммирует эти отдельные счетчики для каждого слова и выдает одну пару «ключ-значение», содержащую слово, за которым следует частота его использования.
Задание MapReduce может быть реализовано на различных языках. Java — это наиболее распространенная реализация, которая используется в данном документе для примера.
Языки разработки
Языки или платформы на основе Java или виртуальной машины Java можно запускать непосредственно как задание MapReduce. В качестве примера в этом документе приведено приложение MapReduce на языке Java. Прочие языки и платформы, например C# или Python, или изолированные исполняемые файлы должны использовать потоковую передачу Hadoop.
Потоковая передача Hadoop взаимодействует с модулями сопоставления и редукции через потоки STDIN и STDOUT. Модули сопоставления и редукции построчно считывают данные из потока STDIN и записывают выходные данные в поток STDOUT. Каждая строка, которая читается или генерируется модулем сопоставления или редукции, должна быть в формате пар «ключ-значение», разделенных знаком табуляции.
Дополнительные сведения см. в документации по потоковой передаче Hadoop.
Примеры использования потоковой передачи Hadoop с HDInsight см. в следующих документах:
С чего начать
- Краткое руководство. Создание кластера Apache Hadoop в Azure HDInsight с помощью портала Azure
- Учебник. Отправка заданий Apache Hadoop в HDInsight
- Разработка программ MapReduce на Java для Apache Hadoop в HDInsight
- Использование Apache Hive как средства для извлечения, преобразования и загрузки
- Extract, transform, and load (ETL) at scale (Извлечение, преобразование и загрузка (ETL) в масштабе)
- Ввод в эксплуатацию конвейера аналитики данных
Дальнейшие действия
- Создание кластера Apache Hadoop в HDInsight с помощью портала
- Создание кластера Apache Hadoop в HDInsight с помощью шаблона ARM
Источник: learn.microsoft.com
Big Data от А до Я. Часть 2: Hadoop
Привет, Хабр! В предыдущей статье мы рассмотрели парадигму параллельных вычислений MapReduce. В этой статье мы перейдём от теории к практике и рассмотрим Hadoop – мощный инструментарий для работы с большими данными от Apache foundation.
В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.

Общая информация о Hadoop
Как известно парадигму MapReduce предложила компания Google в 2004 году в своей статье MapReduce: Simplified Data Processing on Large Clusters. Поскольку предложенная статья содержала описание парадигмы, но реализация отсутствовала – несколько программистов из Yahoo предложили свою реализацию в рамках работ над web-краулером nutch. Более подробно историю Hadoop можно почитать в статье The history of Hadoop: From 4 nodes to the future of data
Изначально Hadoop был, в первую очередь, инструментом для хранения данных и запуска MapReduce-задач, сейчас же Hadoop представляет собой большой стек технологий, так или иначе связанных с обработкой больших данных (не только при помощи MapReduce).
Основными (core) компонентами Hadoop являются:
-
Hadoop Distributed File System (HDFS) – распределённая файловая система, позволяющая хранить информацию практически неограниченного объёма.
-
Hive – инструмент для SQL-like запросов над большими данными (превращает SQL-запросы в серию MapReduce–задач);
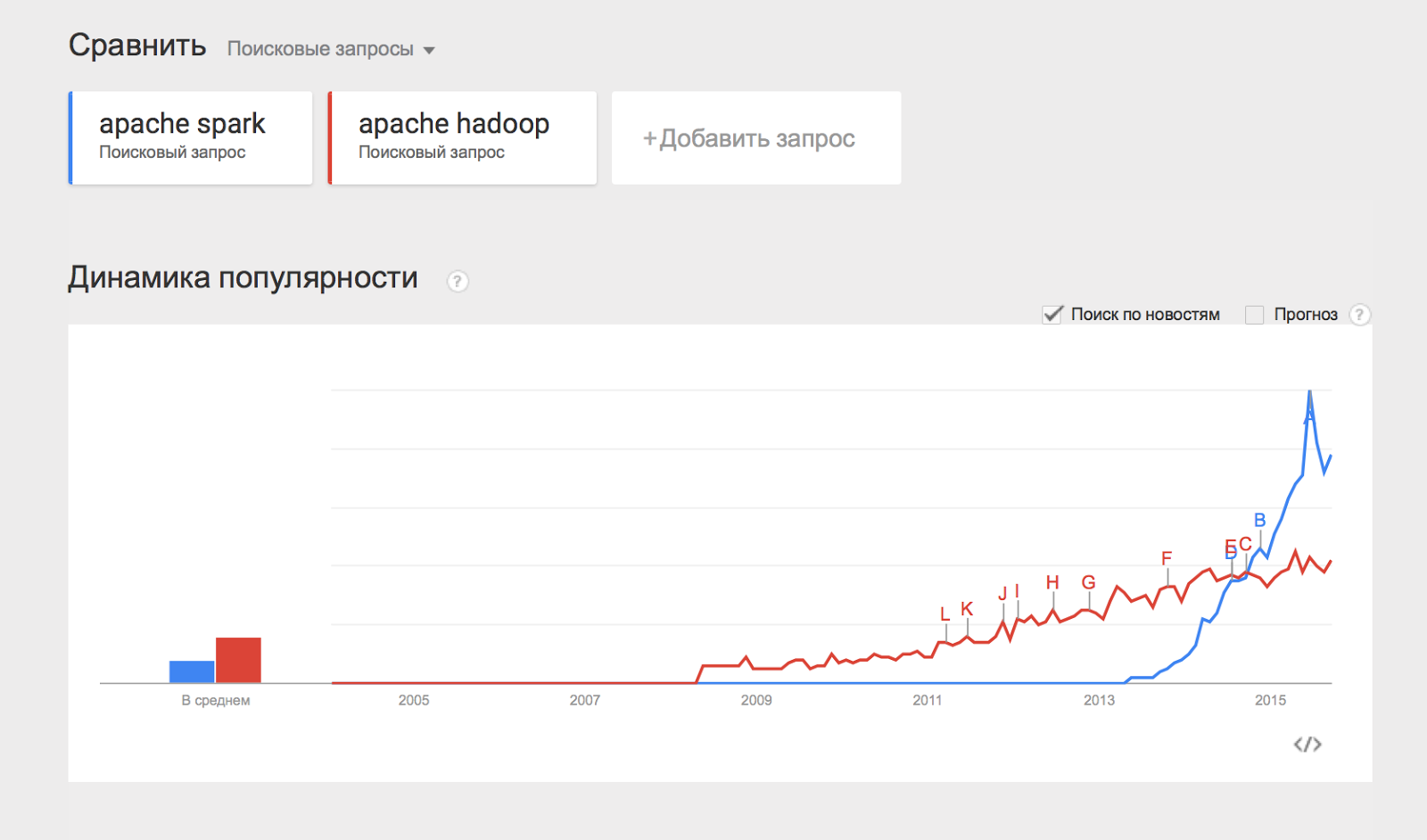
Некоторым из перечисленных компонент будут посвящены отдельные статьи этого цикла материалов, а пока разберём, каким образом можно начать работать с Hadoop и применять его на практике.
Установка Hadoop на кластер при помощи Cloudera Manager
Раньше установка Hadoop представляла собой достаточно тяжёлое занятие – нужно было по отдельности конфигурировать каждую машину в кластере, следить за тем, что ничего не забыто, аккуратно настраивать мониторинги. С ростом популярности Hadoop появились компании (такие как Cloudera, Hortonworks, MapR), которые предоставляют собственные сборки Hadoop и мощные средства для управления Hadoop-кластером. В нашем цикле материалов мы будем пользоваться сборкой Hadoop от компании Cloudera.
Для того чтобы установить Hadoop на свой кластер, нужно проделать несколько простых шагов:
- Скачать Cloudera Manager Express на одну из машин своего кластера отсюда;
- Присвоить права на выполнение и запустить;
- Следовать инструкциям установки.
После установки вы получите консоль управления кластером, где можно смотреть установленные сервисы, добавлять/удалять сервисы, следить за состоянием кластера, редактировать конфигурацию кластера:
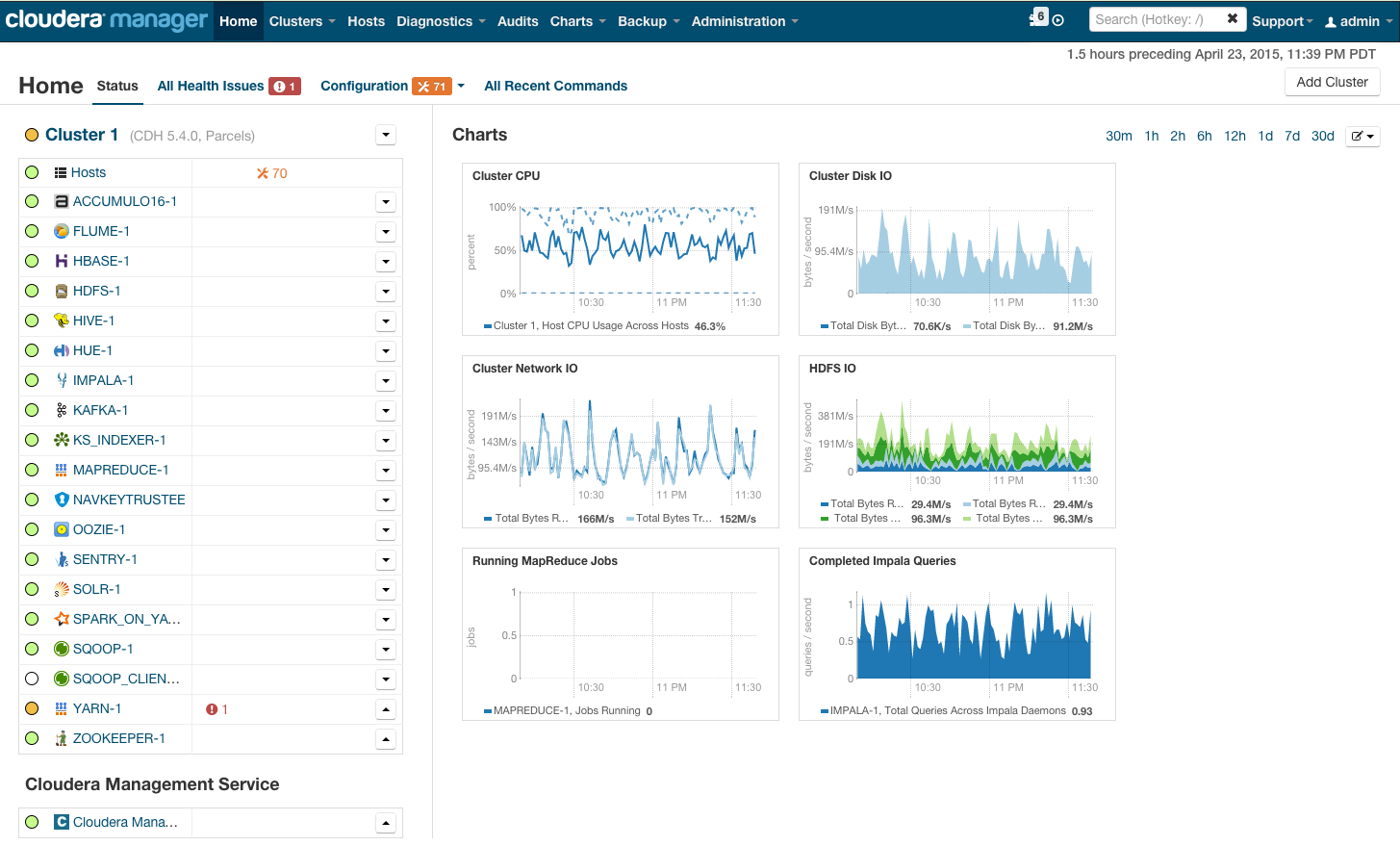
Более подробно с процессом установки Hadoop на кластер при помощи cloudera manager можно ознакомиться по ссылке в разделе Quick Start.
Если же Hadoop планируется использовать для «попробовать» – можно не заморачиваться с приобретением дорогого железа и настройкой Hadoop на нём, а просто скачать преднастроенную виртуальную машину по ссылке и пользоваться настроенным hadoop’ом.
Запуск MapReduce программ на Hadoop
Теперь покажем как запустить MapReduce-задачу на Hadoop. В качестве задачи воспользуемся классическим примером WordCount, который был разобран в предыдущей статье цикла. Для того, чтобы экспериментировать на реальных данных, я подготовил архив из случайных новостей с сайта lenta.ru. Скачать архив можно по ссылке.
Напомню формулировку задачи: имеется набор документов. Необходимо для каждого слова, встречающегося в наборе документов, посчитать, сколько раз встречается слово в наборе.
def map(doc): for word in doc.split(): yield word, 1
def reduce(word, values): yield word, sum(values)
Способ №1. Hadoop Streaming
Самый простой способ запустить MapReduce-программу на Hadoop – воспользоваться streaming-интерфейсом Hadoop.
Streaming-интерфейс предполагает, что map и reduce реализованы в виде программ, которые принимают данные с stdin и выдают результат на stdout.
Программа, которая исполняет функцию map называется mapper. Программа, которая выполняет reduce, называется, соответственно, reducer.
Streaming интерфейс предполагает по умолчанию, что одна входящая строка в mapper или reducer соответствует одной входящей записи для map.
Вывод mapper’a попадает на вход reducer’у в виде пар (ключ, значение), при этом все пары соответствующие одному ключу:
- Гарантированно будут обработаны одним запуском reducer’a;
- Будут поданы на вход подряд (то есть если один reducer обрабатывает несколько разных ключей – вход будет сгруппирован по ключу).
#mapper.py import sys def do_map(doc): for word in doc.split(): yield word.lower(), 1 for line in sys.stdin: for key, value in do_map(line): print(key + «t» + str(value))
#reducer.py import sys def do_reduce(word, values): return word, sum(values) prev_key = None values = [] for line in sys.stdin: key, value = line.split(«t») if key != prev_key and prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + «t» + str(result_value)) values = [] prev_key = key values.append(int(value)) if prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + «t» + str(result_value))
Данные, которые будет обрабатывать Hadoop должны храниться на HDFS. Загрузим наши статьи и положим на HDFS. Для этого нужно воспользоваться командой hadoop fs:
wget https://www.dropbox.com/s/opp5psid1x3jt41/lenta_articles.tar.gz tar xzvf lenta_articles.tar.gz hadoop fs -put lenta_articles
Утилита hadoop fs поддерживает большое количество методов для манипуляций с файловой системой, многие из которых один в один повторяют стандартные утилиты linux. Подробнее с её возможностями можно ознакомиться по ссылке.
Теперь запустим streaming-задачу:
yarn jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar -input lenta_articles -output lenta_wordcount -file mapper.py -file reducer.py -mapper «python mapper.py» -reducer «python reducer.py»
Утилита yarn служит для запуска и управления различными приложениями (в том числе map-reduce based) на кластере. Hadoop-streaming.jar – это как раз один из примеров такого yarn-приложения.
Дальше идут параметры запуска:
- input – папка с исходными данными на hdfs;
- output – папка на hdfs, куда нужно положить результат;
- file – файлы, которые нужны в процессе работы map-reduce задачи;
- mapper – консольная команда, которая будет использоваться для map-стадии;
- reduce – консольная команда которая будет использоваться для reduce-стадии.
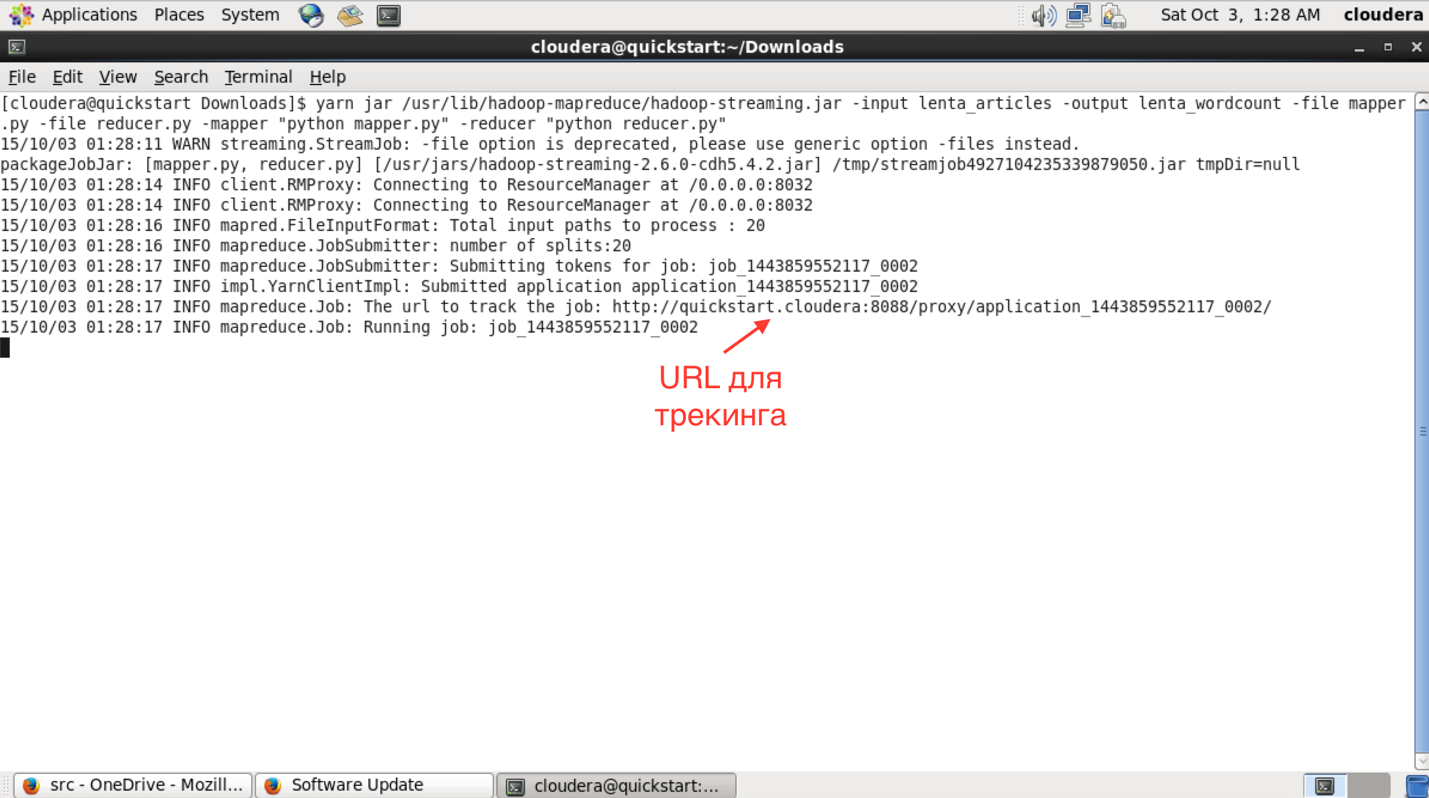
В интерфейсе доступном по этому URL можно узнать более детальный статус выполнения задачи, посмотреть логи каждого маппера и редьюсера (что очень полезно в случае упавших задач).
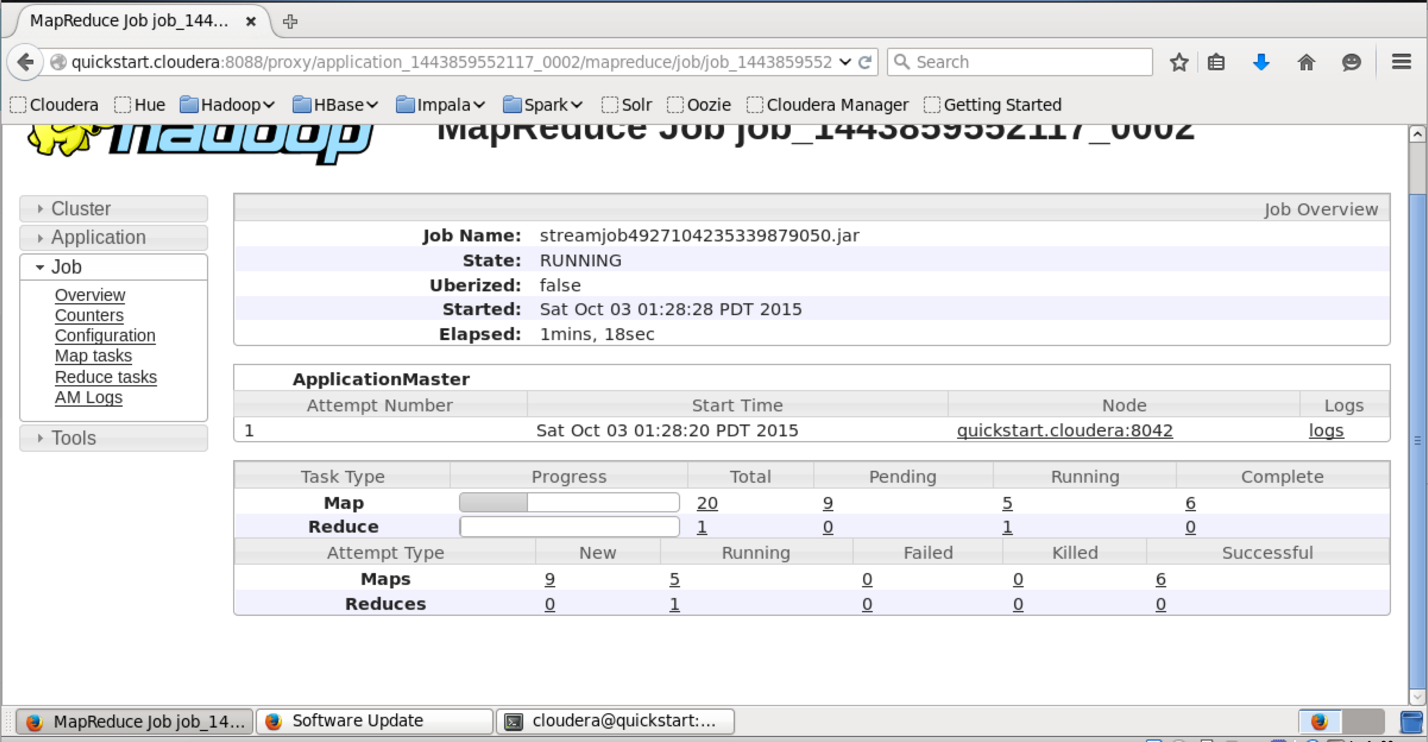
Сам результат можно получить следующим образом:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 с 41 что 43 на 82 и 111 в 194
Команда «hadoop fs -text» выдаёт содержимое папки в текстовом виде. Я отсортировал результат по количеству вхождений слов. Как и ожидалось, самые частые слова в языке – предлоги.
Способ №2
Сам по себе hadoop написан на java, и нативный интерфейс у hadoop-a тоже java-based. Покажем, как выглядит нативное java-приложение для wordcount:
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount < public static class TokenizerMapper extends Mapper < private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException < StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) < word.set(itr.nextToken()); context.write(word, one); >> > public static class IntSumReducer extends Reducer < private IntWritable result = new IntWritable(); public void reduce(Text key, Iterablevalues, Context context ) throws IOException, InterruptedException < int sum = 0; for (IntWritable val : values) < sum += val.get(); >result.set(sum); context.write(key, result); > > public static void main(String[] args) throws Exception < Configuration conf = new Configuration(); Job job = Job.getInstance(conf, «word count»); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(«hdfs://localhost/user/cloudera/lenta_articles»)); FileOutputFormat.setOutputPath(job, new Path(«hdfs://localhost/user/cloudera/lenta_wordcount»)); System.exit(job.waitForCompletion(true) ? 0 : 1); >>
Этот класс делает абсолютно то же самое, что наш пример на Python.
Мы создаём классы TokenizerMapper и IntSumReducer, наследуя их от классов Mapper и Reducer соответсвенно. Классы, передаваемые в качестве параметров шаблона, указывают типы входных и выходных значений. Нативный API подразумевает, что функции map на вход подаётся пара ключ-значение. Поскольку в нашем случае ключ пустой – в качестве типа ключа мы определяем просто Object.
В методе Main мы заводим mapreduce-задачу и определяем её параметры – имя, mapper и reducer, путь в HDFS, где находятся входные данные и куда положить результат.
Для компиляции нам потребуются hadoop-овские библиотеки. Я использую для сборки Maven, для которого у cloudera есть репозиторий. Инструкции по его настройке можно найти по ссылке. В итоге файл pom.xmp (который используется maven’ом для описания сборки проекта) у меня получился следующий):
4.0.0 cloudera https://repository.cloudera.com/artifactory/cloudera-repos/ org.apache.hadoop hadoop-common 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-auth 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-hdfs 2.6.0-cdh5.4.2 org.apache.hadoop hadoop-mapreduce-client-app 2.6.0-cdh5.4.2 org.dca.examples wordcount 1.0-SNAPSHOT
Соберём проект в jar-пакет:
mvn clean package
После сборки проекта в jar-файл запуск происходит похожим образом, как и в случае streaming-интерфейса:
yarn jar wordcount-1.0-SNAPSHOT.jar WordCount
Дожидаемся выполнения и проверяем результат:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 с 41 что 43 на 82 и 111 в 194
Как нетрудно догадаться, результат выполнения нашего нативного приложения совпадает с результатом streaming-приложения, которое мы запустили предыдущим способом.
Резюме
В статье мы рассмотрели Hadoop – программный стек для работы с большими данными, описали процесс установки Hadoop на примере дистрибутива cloudera, показали, как писать mapreduce-программы, используя streaming-интерфейс и нативный API Hadoop’a.
В следующих статьях цикла мы рассмотрим более детально архитектуру отдельных компонент Hadoop и Hadoop-related ПО, покажем более сложные варианты MapReduce-программ, разберём способы упрощения работы с MapReduce, а также ограничения MapReduce и как эти ограничения обходить.
Спасибо за внимание, готовы ответить на ваши вопросы.
Ссылки на другие статьи цикла:
Источник: habr.com