
Аннотация: В лекции рассматриваются основные понятия и алгоритмы сжатия данных, приводятся примеры программной реализации алгоритма Хаффмана через префиксные коды и на основе кодовых деревьев.
Цель лекции: изучить основные виды и алгоритмы сжатия данных и научиться решать задачи сжатия данных по методу Хаффмана и с помощью кодовых деревьев.
Основоположником науки о сжатии информации принято считать Клода Шеннона. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и насколько та или иная информация при этом сожмется. Кроме того, им были проведены опыты по эмпирической оценке избыточности английского текста. Шенон предлагал людям угадывать следующую букву и оценивал вероятность правильного угадывания. На основе ряда опытов он пришел к выводу, что количество информации в английском тексте колеблется в пределах 0,6 – 1,3 бита на символ. Несмотря на то, что результаты исследований Шеннона были по-настоящему востребованы лишь десятилетия спустя, трудно переоценить их значение .
Код Хаффмана
Сжатие данных – это процесс, обеспечивающий уменьшение объема данных путем сокращения их избыточности. Сжатие данных связано с компактным расположением порций данных стандартного размера. Сжатие данных можно разделить на два основных типа:
- Сжатие без потерь (полностью обратимое) – это метод сжатия данных, при котором ранее закодированная порция данных восстанавливается после их распаковки полностью без внесения изменений. Для каждого типа данных, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
- Сжатие с потерями – это метод сжатия данных, при котором для обеспечения максимальной степени сжатия исходного массива данных часть содержащихся в нем данных отбрасывается. Для текстовых, числовых и табличных данных использование программ, реализующих подобные методы сжатия, является неприемлемыми. В основном такие алгоритмы применяются для сжатия аудио- и видеоданных, статических изображений.
Алгоритм сжатия данных (алгоритм архивации) – это алгоритм , который устраняет избыточность записи данных.
Введем ряд определений, которые будут использоваться далее в изложении материала.
Алфавит кода – множество всех символов входного потока. При сжатии англоязычных текстов обычно используют множество из 128 ASCII кодов. При сжатии изображений множество значений пиксела может содержать 2, 16, 256 или другое количество элементов.
Кодовый символ – наименьшая единица данных, подлежащая сжатию. Обычно символ – это 1 байт , но он может быть битом, тритом , или чем-либо еще.
Кодовое слово – это последовательность кодовых символов из алфавита кода. Если все слова имеют одинаковую длину (число символов), то такой код называется равномерным (фиксированной длины), а если же допускаются слова разной длины, то – неравномерным (переменной длины).
Код – полное множество слов.
Токен – единица данных, записываемая в сжатый поток некоторым алгоритмом сжатия. Токен состоит из нескольких полей фиксированной или переменной длины.
2 курс, лекция 22, Сжатие данных, LZW.
Фраза – фрагмент данных, помещаемый в словарь для дальнейшего использования в сжатии.
Кодирование – процесс сжатия данных.
Декодирование – обратный кодированию процесс, при котором осуществляется восстановление данных.
Отношение сжатия – одна из наиболее часто используемых величин для обозначения эффективности метода сжатия.
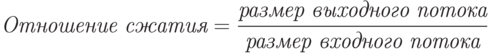
Значение 0,6 означает, что данные занимают 60% от первоначального объема. Значения больше 1 означают, что выходной поток больше входного (отрицательное сжатие, или расширение).
Коэффициент сжатия – величина, обратная отношению сжатия.
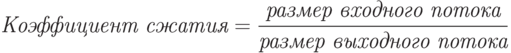
Значения больше 1 обозначают сжатие, а значения меньше 1 – расширение.
Средняя длина кодового слова – это величина, которая вычисляется как взвешенная вероятностями сумма длин всех кодовых слов.
Lcp=p1L1+p2L2+. +pnLn,
где – вероятности кодовых слов;
Существуют два основных способа проведения сжатия.
Статистические методы – методы сжатия, присваивающие коды переменной длины символам входного потока, причем более короткие коды присваиваются символам или группам символам, имеющим большую вероятность появления во входном потоке. Лучшие статистические методы применяют кодирование Хаффмана.
Словарное сжатие – это методы сжатия, хранящие фрагменты данных в «словаре» (некоторая структура данных ). Если строка новых данных, поступающих на вход, идентична какому-либо фрагменту, уже находящемуся в словаре, в выходной поток помещается указатель на этот фрагмент. Лучшие словарные методы применяют метод Зива-Лемпела.
Рассмотрим несколько известных алгоритмов сжатия данных более подробно.
Метод Хаффмана
Этот алгоритм кодирования информации был предложен Д.А. Хаффманом в 1952 году. Хаффмановское кодирование (сжатие) – это широко используемый метод сжатия, присваивающий символам алфавита коды переменной длины, основываясь на вероятностях появления этих символов.
Идея алгоритма состоит в следующем: зная вероятности вхождения символов в исходный текст, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Таким образом, в этом методе при сжатии данных каждому символу присваивается оптимальный префиксный код , основанный на вероятности его появления в тексте.
Префиксный код – это код, в котором никакое кодовое слово не является префиксом любого другого кодового слова. Эти коды имеют переменную длину.
Оптимальный префиксный код – это префиксный код , имеющий минимальную среднюю длину.
Алгоритм Хаффмана можно разделить на два этапа.
- Определение вероятности появления символов в исходном тексте. Первоначально необходимо прочитать исходный текст полностью и подсчитать вероятности появления символов в нем (иногда подсчитывают, сколько раз встречается каждый символ). Если при этом учитываются все 256 символов, то не будет разницы в сжатии текстового или файла иного формата.
Коды Хаффмана имеют уникальный префикс , что и позволяет однозначно их декодировать, несмотря на их переменную длину.
Пример 1. Программная реализация метода Хаффмана.
#include «stdafx.h» #include using namespace std; void Expectancy(); long MinK(); void SumUp(); void BuildBits(); void OutputResult(char **Result); void Clear(); const int MaxK = 1000; long k[MaxK + 1], a[MaxK + 1], b[MaxK + 1]; char bits[MaxK + 1][40]; char sk[MaxK + 1]; bool Free[MaxK + 1]; char *res[256]; long i, j, n, m, kj, kk1, kk2; char str[256]; int _tmain(int argc, _TCHAR* argv[])< char *BinaryCode; Clear(); cout > str; Expectancy(); SumUp(); BuildBits(); OutputResult( cout //описание функции обнуления данных в массивах void Clear() < for (i = 0; i < MaxK + 1; i++)< k[i] = a[i] = b[i] = 0; sk[i] = 0; Free[i] = true; for (j = 0; j < 40; j++) bits[i][j] = 0; >> /*описание функции вычисления вероятности вхождения каждого символа в тексте*/ void Expectancy() < long *s = new long[256]; for ( i = 0; i < 256; i++) s[i] = 0; for ( n = 0; n < strlen(str); n++ ) s[str[n]]++; j = 0; for ( i = 0; i < 256; i++) if ( s[i] != 0 )< j++; k[j] = s[i]; sk[j] = i; >kj = j; > /*описание функции нахождения минимальной частоты символа в исходном тексте*/ long MinK() < long min; i = 1; while ( !Free[i] i < MaxK) i++; min = k[i]; m = i; for ( i = m + 1; i Free[m] = false; return min; > //описание функции подсчета суммарной частоты символов void SumUp() < long s1, s2, m1, m2; for ( i = 1; i kk1 = kk2 = kj; while (kk1 > 2) < s1 = MinK(); m1 = m; s2 = MinK(); m2 = m; kk2++; k[kk2] = s1 + s2; a[kk2] = m1; b[kk2] = m2; Free[kk2] = true; kk1—; >> //описание функции формирования префиксных кодов void BuildBits() < strcpy(bits[kk2],»1″); Free[kk2] = false; strcpy(bits[a[kk2]],bits[kk2]); strcat( bits[a[kk2]] , «0»); strcpy(bits[b[kk2]],bits[kk2]); strcat( bits[b[kk2]] , «1»); i = MinK(); strcpy(bits[m],»0″); Free[m] = true; strcpy(bits[a[m]],bits[m]); strcat( bits[a[m]] , «0»); strcpy(bits[b[m]],bits[m]); strcat( bits[b[m]] , «1»); for ( i = kk2 — 1; i >0; i— ) if ( !Free[i] ) < strcpy(bits[a[i]],bits[i]); strcat( bits[a[i]] , «0»); strcpy(bits[b[i]],bits[i]); strcat( bits[b[i]] , «1»); >> //описание функции вывода данных void OutputResult(char **Result)
Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов, но он малоэффективен для файлов маленьких размеров (за счет необходимости сохранения словаря). В настоящее время данный метод практически не применяется в чистом виде, обычно используется как один из этапов сжатия в более сложных схемах. Это единственный алгоритм , который не увеличивает размер исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).
Источник: intuit.ru
6.3. Алгоритмы сжатия данных
В общем смысле под сжатием данных понимают такое их преобразование, что его результат занимает меньший объем памяти. При этом (по сравнению с исходным представлением) экономится память для их хранения и сокращается время передачи сжатых данных по каналам связи. Синонимы термина “сжатие” – упаковка, компрессия, архивация.
Обратный процесс (получение исходных данных по сжатым) называется распаковкой, декомпрессией, восстановлением. Качество сжатия характеризуется коэффициентом сжатия, равным отношению объема сжатых данных к объему исходных данных. В зависимости от возможной точности восстановления исходных данных, различаю сжатие без потерь (данные восстанавливаются точно в исходном виде) и сжатие с потерями (восстановленные данные не идентичны исходным, но их различиями в том контексте, в котором эти данные используются, можно пренебречь). Сжатие с потерями применяется, например, для упаковки многоцветных фотографических изображений (алгоритм JPEG), звука (алгоритм MP3), видео (группа алгоритмов MPEG). При этом используются особенности человеческого восприятия: например, глаз человека не может — 39 —
различить два близких оттенка цвета, закодированных 24 битами, поэтому можно без видимых искажений уменьшить разрядность представления цвета. Для многих разновидностей данных – текстов, исполняемых файлов и т.д. – допустимо применение только алгоритмов сжатия без потерь. Сжатие без потерь, в основном, базируется на двух группах методов: словарных и статистических.
Словарные методы используют наличие повторяемых групп данных и, например, записывают первое вхождение повторяемого участка непосредственно, а все последующие вхождения заменяют на ссылку на первое вхождение. Другие словарные методы отдельно хранят словарь в явной форме и заменяют все вхождения словарных терминов на их номер в словаре. Статистические методы используют тот факт, что частота появления в данных различных байтов (или групп байтов) неодинакова, следовательно, часто встречающиеся байты можно закодировать более короткой битовой последовательностью, а редко встречающиеся – более длинной. Часто в одном алгоритме используют и словарные, и статистические методы.
6.3.1. Алгоритм RLE
Самый простой из словарных методов – RLE (Run Length Encoding, кодирование переменной длины) умеет сжимать данные, в которых есть последовательности повторяющихся байтов. Упакованные RLE данные состоят из управляющих байтов, за которыми следуют байты данных.
Если старший бит управляющего байта равен 0, то следующие байты (в количестве, записанном в семи младших битах управляющего байта) при упаковке не изменялись. Если старший бит равен 1, то следующий байт нужно повторить столько раз, какое число записано в остальных разрядах управляющего байта. Например, исходная последовательность 00000000 00000000 00000000 00000000 11001100 10111111 10111011 будет закодирована в следующем виде (выделены управляющие байты): 10000100 00000000 00000011 11001100 10111111 10111011. А, например, данные, состоящие из сорока нулевых байтов, будут закодированы всего двумя байтами: 1010 1000 00000000.
6.3.2. Алгоритм Лемпела-Зива
Наиболее широко используются словарные алгоритмы из семейства LZ, чья идея была описана Лемпелом и Зивом в 1977 году. Существует множество модификаций этого алгоритма, отличающихся способами хранения словаря, добавления слова в словарь и поиска слова в словаре. Словом в этом алгоритме называется последовательность символов (не обязательно совпадающая со словом естественного языка). Слова хранятся в словаре, а их вхождения в исходные данные заменяются адресами (номерами) слов в словаре. Некоторые разновидности алгоритма хранят отдельно словарь и отдельно упакованные данные в виде последовательности номеров слов. — 40 —
Другие считают словарем весь уже накопленный результат сжатия. Например, сжатый файл может состоять из записей вида [a,l,t], где a – адрес (номер позиции), с которой начинается такая же строка длины l, что и текущая строка. Если a>0, то запись считается ссылкой на словарь и поле t (текст) в ней – пустое.
Если a = 0, то в поле t записаны l символов, которые до сих пор в такой последовательности не встречались. Алгоритм сжатия заключается в постоянном поиске в уже упакованной части данных максимальной последовательности символов, совпадающей с последовательностью, начинающейся с текущей позиции. Если такая последовательность (длины > 3) найдена, в результат записывается ее адрес и длина. Иначе в результат записывается 0, длина последовательности и сама (несжатая) последовательность.
6.3.3. Кодирование Шеннона-Фано
Методы эффективного кодирования сообщений для передачи по дискретному каналу без помех, предложенные Шенноном и Фано, заложили основу статистических методов сжатия данных. Код Шеннона-Фано строится следующим образом: символы алфавита выписывают в таблицу в порядке убывания вероятностей.
Затем их разделяют на две группы так, чтобы суммы вероятностей в каждой из групп были максимально близки (по возможности, равны). В кодах всех символов верхней группы первый бит устанавливается равным 0, в нижней группы – 1. Затем каждую из групп разбивают на две подгруппы с одинаковыми суммами вероятностей, и процесс назначения битов кода продолжается по аналогии с первым шагом.
Кодирование завершается, когда в каждой группе останется по одному символу. Качество кодирования по Шеннону-Фано сильно зависит от выбора разбиений на подгруппы: чем больше разность сумм вероятностей подгрупп, тем более избыточным оказывается код. Для дальнейшего уменьшения избыточности, используют кодирование крупными блоками – в качестве “символов” используются комбинации исходных символов сообщения, но и этот подход имеет те же ограничения. От указанного недостатка свободна методика кодирования Хаффмана.
6.3.4. Алгоритм Хаффмана
Алгоритм Хаффмана гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов кода на символ сообщения. На первом шаге подсчитываются частоты всех символов в исходных данных. На втором шаге строятся новые коды (битовые последовательности) для каждого символа, так, чтобы никакие две разные последовательности не имели общего начала, например, три последовательности 0, 10, 110. удовлетворяют этому требованию. Хаффман предложил строить двоичное дерево символов, в корне которого находится наиболее частый символ, на расстоянии 1 от корня – следующие по частоте — 41 —
Источник: studfile.net
Алгоритмы сжатия данных без потерь, часть 2
Для сжатия данных придумано множество техник. Большинство из них комбинируют несколько принципов сжатия для создания полноценного алгоритма. Даже хорошие принципы, будучи скомбинированы вместе, дают лучший результат. Большинство техник используют принцип энтропийного кодирования, но часто встречаются и другие – кодирование длин серий (Run-Length Encoding) и преобразование Барроуза-Уилера (Burrows-Wheeler Transform).
Кодирование длин серий (RLE)
Это очень простой алгоритм. Он заменяет серии из двух или более одинаковых символов числом, обозначающим длину серии, за которым идёт сам символ. Полезен для сильно избыточных данных, типа картинок с большим количеством одинаковых пикселей, или в комбинации с алгоритмами типа BWT.
На входе: AAABBCCCCDEEEEEEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
На выходе: 3A2B4C1D6E38A
Преобразование Барроуза-Уилера (BWT)
Алгоритм, придуманный в 1994 году, обратимо трансформирует блок данных так, чтобы максимизировать повторения одинаковых символов. Сам он не сжимает данные, но подготавливает их для более эффективного сжатия через RLE или другой алгоритм сжатия.
— создаём массив строк
— создаём все возможные преобразования входящей строки данных, каждое из которых сохраняем в массиве
— сортируем массив
— возвращаем последний столбец
Алгоритм лучше всего работает с большими данными со множеством повторяющихся символов. Пример работы на подходящем массиве данных (3A». Но на реальных данных, к сожалению, настолько оптимальных результатов обычно не получается.
Энтропийное кодирование
Энтропия в данном случае означает минимальное количество бит, в среднем необходимое для представления символа. Простой ЭК комбинирует статистическую модель и сам кодировщик. Входной файл парсится для построения стат.модели, состоящей из вероятностей появления определённых символов. Затем кодировщик, используя модель, определяет, какие битовые или байтовые кодировки назначать каждому символу, чтобы самые часто встречающиеся были представлены самыми короткими кодировками, и наоборот.
Алгоритм Шеннона — Фано
Одна из самых ранних техник (1949 год). Создаёт двоичное дерево для представления вероятностей появления каждого из символов. Затем они сортируются так, чтобы самые часто встречающиеся находились наверху дерева, и наоборот.
Код для символа получается поиском по дереву, и добавлением 0 или 1, в зависимости от того, идём мы налево или направо. К примеру, путь к “А” – две ветки налево и одна направо, его код будет «110». Алгоритм не всегда даёт оптимальные коды из-за методики построения дерева снизу вверх. Поэтому сейчас используется алгоритм Хаффмана, подходящий для любых входных данных.
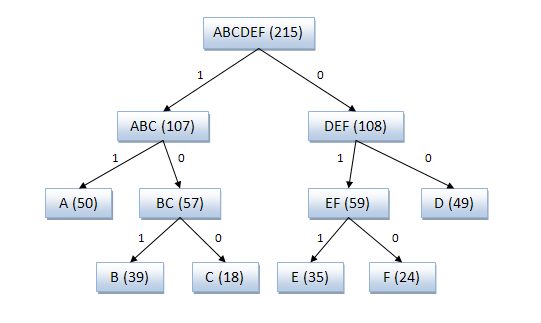
1. парсим ввод, считаем количество вхождений всех символов
2. определяем вероятность появления каждого из них
3. сортируем символы по вероятности появления
4. делим список пополам так, чтобы сумма вероятностей в левой ветке примерно равнялось сумме в правой
5. добавляем 0 или 1 для левых и правых узлов соответственно
6. повторяем шаги 4 и 5 для правых и левых поддеревьев до тех пор, пока каждый узел не будет «листом»
Кодирование Хаффмана
Это вариант энтропийного кодирования, работающий схожим с предыдущим алгоритмом методом, но двоичное дерево строится сверху вниз, для достижения оптимального результата.
1. Парсим ввод, считаем количество повторений символов
2. Определяем вероятность появления каждого символа
3. Сортируем список по вероятностям (самые частые вначале)
4. Создаём листы для каждого символа, и добавляем их в очередь
5. пока очередь состоит более, чем из одного символа:
— берём из очереди два листа с наименьшими вероятностями
— к коду первой прибавляем 0, к коду второй – 1
— создаём узел с вероятностью, равной сумме вероятностей двух нод
— первую ноду вешаем на левую сторону, вторую – на правую
— добавляем полученный узел в очередь
6. Последняя нода в очереди будет корнем двоичного дерева.
Арифметическое кодирование
Был разработан в 1979 году в IBM для использования в их мейнфреймах. Достигает очень хорошей степени сжатия, обычно большей, чем у Хаффмана, однако он сравнительно сложен по сравнению с предыдущими.
Вместо разбиения вероятностей по дереву, алгоритм преобразует входные данные в одно рациональное число от 0 до 1.
В общем алгоритм таков:
1. считаем количество уникальных символов на входе. Это количество будет представлять основание для счисления b (b=2 – двоичное, и т.п.).
2. подсчитываем общую длину входа
3. назначаем «коды» от 0 до b каждому из уникальных символов в порядке их появления
4. заменяем символы кодами, получая число в системе счисления с основанием b
5. преобразуем полученное число в двоичную систему
Пример. На входе строка «ABCDAABD»
1. 4 уникальных символа, основание = 4, длина данных = 8
2. назначаем коды: A=0, B=1, C=2, D=3
3. получаем число “0.01230013”
4. преобразуем «0.01231123» из четверичной в двоичную систему: 0.01101100000111
Если мы положим, что имеем дело с восьмибитными символами, то на входе у нас 8х8=64 бита, а на выходе – 15, то есть степень сжатия 24%.
Классификация алгоритмов
Алгоритмы, применяющие метод «скользящего окна»
Всё началось с алгоритма LZ77 (1977 год), который представил новую концепцию «скользящего окна», позволившую значительно улучшить сжатие данных. LZ77 использует словарь, содержащий тройки данных – смещение, длина серии и символ расхождения. Смещение – как далеко от начала файла находится фраза. Длина серии – сколько символов, считая от смещения, принадлежат фразе.
Символ расхождения показывает, что найдена новая фраза, похожая на ту, что обозначена смещением и длиной, за исключением этого символа. Словарь меняется по мере парсинга файла при помощи скользящего окна. К примеру, размер окна может быть 64Мб, тогда словарь будет содержать данные из последних 64 мегабайт входных данных.
К примеру, для входных данных «abbadabba» результат будет «abb(0,1,’d’)(0,3,’a’)»
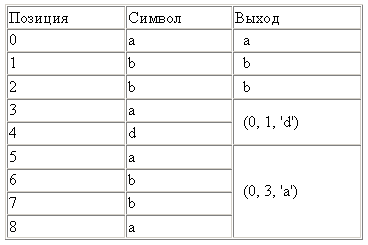
В данном случае результат получился длиннее входа, но обычно он конечно получается короче.
LZR
Модификация алгоритма LZ77, предложенная Майклом Роуде в 1981 году. В отличие от LZ77 работает за линейное время, однако требует большего объёма памяти. Обычно проигрывает LZ78 в сжатии.
DEFLATE
Придуман Филом Кацем в 1993 году, и используется в большинстве современных архиваторов. Является комбинацией LZ77 или LZSS с кодированием Хаффмана.
DEFLATE64
Патентованная вариация DEFLATE с увеличением словаря до 64 Кб. Сжимает лучше и быстрее, но не используется повсеместно, т.к. не является открытым.
LZSS
Алгоритм Лемпеля-Зива-Сторера-Цимански был представлен в 1982 году. Улучшенная версия LZ77, которая просчитывает, не увеличит ли размер результата замена исходных данных кодированными.
До сих пор используется в популярных архиваторах, например RAR. Иногда – для сжатия данных при передаче по сети.
LZH
Был разработан в 1987 году, расшифровывается как «Лемпель-Зив-Хаффман». Вариация LZSS, использует кодирование Хаффмана для сжатия указателей. Сжимает чуть лучше, но ощутимо медленнее.
LZB
Разработан в 1987 году Тимоти Беллом, как вариант LZSS. Как и LZH, LZB уменьшает результирующий размер файлов, эффективно кодируя указатели. Достигается это путём постепенного увеличения размера указателей при увеличении размера скользящего окна. Сжатие получается выше, чем у LZSS и LZH, но скорость значительно меньше.
ROLZ
Расшифровывается как «Лемпель-Зив с уменьшенным смещением», улучшает алгоритм LZ77, уменьшая смещение, чтобы уменьшить количество данных, необходимого для кодирования пары смещение-длина. Впервые был представлен в 1991 году в алгоритме LZRW4 от Росса Вильямса. Другие вариации — BALZ, QUAD, и RZM. Хорошо оптимизированный ROLZ достигает почти таких же степеней сжатия, как и LZMA – но популярности он не снискал.
LZP
«Лемпель-Зив с предсказанием». Вариация ROLZ со смещением = 1. Есть несколько вариантов, одни направлены на скорость сжатия, другие – на степень. В алгоритме LZW4 используется арифметическое кодирование для наилучшего сжатия.
LZRW1
Алгоритм от Рона Вильямса 1991 года, где он впервые ввёл концепцию уменьшения смещения. Достигает высоких степеней сжатия при приличной скорости. Потом Вильямс сделал вариации LZRW1-A, 2, 3, 3-A, и 4
LZJB
Вариант от Джеффа Бонвика (отсюда “JB”) от 1998 года, для использования в файловой системе Solaris Z File System (ZFS). Вариант алгоритма LZRW1, переработанный для высоких скоростей, как этого требует использование в файловой системе и скорость дисковых операций.
LZS
Lempel-Ziv-Stac, разработан в Stac Electronics в 1994 для использования в программах сжатия дисков. Модификация LZ77, различающая символы и пары длина-смещение, в дополнение к удалению следующего встреченного символа. Очень похож на LZSS.
LZX
Был разработан в 1995 году Дж. Форбсом и Т.Потаненом для Амиги. Форбс продал алгоритм компании Microsoft в 1996, и устроился туда работать над ним, в результате чего улучшенная его версия стала использоваться в файлах CAB, CHM, WIM и Xbox Live Avatars.
LZO
Разработан в 1996 Маркусом Оберхьюмером с прицелом на скорость сжатия и распаковки. Позволяет настраивать уровни компрессии, потребляет очень мало памяти. Похож на LZSS.
LZMA
“Lempel-Ziv Markov chain Algorithm”, появился в 1998 году в архиваторе 7-zip, который демонстрировал сжатие лучше практически всех архиваторов. Алгоритм использует цепочку методов сжатия для достижения наилучшего результата. Вначале слегка изменённый LZ77, работающий на уровне битов (в отличие от обычного метода работы с байтами), парсит данные. Его вывод подвергается арифметическому кодированию.
Затем могут быть применены другие алгоритмы. В результате получается наилучшая компрессия среди всех архиваторов.
LZMA2
Следующая версия LZMA, от 2009 года, использует многопоточность и чуть эффективнее хранит несжимаемые данные.
Статистический алгоритм Лемпеля-Зива
Концепция, созданная в 2001 году, предлагает проводить статистический анализ данных в комбинации с LZ77 для оптимизирования кодов, хранимых в словаре.
Алгоритмы с использованием словаря
LZ78
Алгоритм 1978 года, авторы – Лемпель и Зив. Вместо использования скользящего окна для создания словаря, словарь составляется при парсинге данных из файла. Объём словаря обычно измеряется в нескольких мегабайтах. Отличия в вариантах этого алгоритма строятся на том, что делать, когда словарь заполнен.
При парсинге файла алгоритм добавляет каждый новый символ или их сочетание в словарь. Для каждого символа на входе создаётся словарная форма (индекс + неизвестный символ) на выходе. Если первый символ строки уже есть в словаре, ищем в словаре подстроки данной строки, и самая длинная используется для построения индекса.
Данные, на которые указывает индекс, добавляются к последнему символу неизвестной подстроки. Если текущий символ не найден, индекс устанавливается в 0, показывая, что это вхождение одиночного символа в словарь. Записи формируют связанный список.
Входные данные «abbadabbaabaad» на выходе дадут «(0,a)(0,b)(2,a)(0,d)(1,b)(3,a)(6,d)»
An input such as «abbadabbaabaad» would generate the output «(0,a)(0,b)(2,a)(0,d)(1,b)(3,a)(6,d)». You can see how this was derived in the following example:

LZW
Лемпель-Зив-Велч, 1984 год. Самый популярный вариант LZ78, несмотря на запатентованность. Алгоритм избавляется от лишних символов на выходе и данные состоят только из указателей.
Также он сохраняет все символы словаря перед сжатием и использует другие трюки, позволяющие улучшать сжатие – к примеру, кодирование последнего символа предыдущей фразы в качестве первого символа следующей. Используется в GIF, ранних версиях ZIP и других специальных приложениях. Очень быстр, но проигрывает в сжатии более новым алгоритмам.
LZC
Компрессия Лемпеля-Зива. Модификация LZW, использующаяся в утилитах UNIX. Следит за степенью сжатия, и как только она превышает заданный предел – словарь переделывается заново.
LZT
Лемпель-Зив-Тищер. Когда словарь заполняется, удаляет фразы, использовавшиеся реже всех, и заменяет их новыми. Не получил популярности.
LZMW
Виктор Миллер и Марк Вегман, 1984 год. Действует, как LZT, но соединяет в словаре не похожие данные, а две последние фразы. В результате словарь растёт быстрее, и приходится чаще избавляться от редко используемых фраз. Также непопулярен.
LZAP
Джеймс Сторер, 1988 год. Модификация LZMW. “AP” означает «все префиксы» — вместо того, чтобы сохранять при каждой итерации одну фразу, в словаре сохраняется каждое изменение. К примеру, если последняя фраза была “last”, а текущая – «next”, тогда в словаре сохраняются „lastn“, „lastne“, „lastnex“, „lastnext“.
LZWL
Вариант LZW от 2006 года, работающий с сочетаниями символов, а не с отдельными символами. Успешно работает с наборами данных, в которых есть часто повторяющиеся сочетания символов, например XML. Обычно используется с препроцессором, разбивающим данные на сочетания.
LZJ
1985 год, Матти Якобсон. Один из немногих вариантов LZ78, отличающихся от LZW. Сохраняет каждую уникальную строку в уже обработанных входных данных, и всем им назначает уникальные коды. При заполнении словаря из него удаляются единичные вхождения.
Алгоритмы, не использующие словарь
PPM
Предсказание по частичному совпадению – использует уже обработанные данные, чтобы предсказать, какой символ будет в последовательности следующим, таким образом уменьшая энтропию выходных данных. Обычно комбинируется с арифметическим кодировщиком или адаптивным кодированием Хаффмана. Вариация PPMd используется в RAR и 7-zip
bzip2
Реализация BWT с открытым исходным кодом. При простоте реализации достигает хорошего компромисса между скоростью и степенью сжатия, в связи с чем популярен в UNIX. Сначала данные обрабатываются при помощи RLE, затем BWT, потом данные особым образом сортируются, чтобы получить длинные последовательности одинаковых символов, после чего к ним снова применяется RLE. И, наконец, кодировщик Хаффмана завершает процесс.
PAQ
Мэтт Махоуни, 2002 год. Улучшение PPM(d). Улучшает их при помощи интересной техники под названием „перемешивание контекста“ (context mixing). В этой технике несколько предсказательных алгоритмов комбинируются, чтобы улучшить предсказание следующего символа. Сейчас это один из самых многообещающих алгоритмов.
С его первой реализации было создано уже два десятка вариантов, некоторые из которых ставят рекорды сжатия. Минус – маленькая скорость из-за необходимости использования нескольких моделей. Вариант под названием PAQ80 поддерживает 64 бита и показывает серьёзное улучшение в скорости работы (используется, в частности, в программе PeaZip для Windows).
Источник: habr.com