
Хотя машинный перевод ассоциируется прежде всего с , первые наработки в этой области появились задолго до изобретения всемирной паутины. В 1933 году во Франции и Советском Союзе инженеры независимо друг от друга предложили 2 вида устройств для перевода.
Франция: «механический мозг»
Первое устройство называлось «механическим мозгом». Его разработал французский инженер армянского происхождения Жорж Арцруни. Как отмечает Джон Хатчинс, британский лингвист и специалист в области машинного перевода, «механический мозг», в отличие от других подобных изобретений того периода, был предназначен не для ускорения вычислений, а для хранения и последующего извлечения информации. Иными словами, он обладал своего рода памятью, данные из которой можно было напечатать.

Сам Арцруни предлагал использовать изобретение для:
8 бесплатных аналогов платных программ для переводчика
- составления телефонных справочников и расписания поездов;
- работы с банковскими документами;
- генерации телеграфных кодов;
- расшифровки и шифрования сообщений;
- переводов с одного языка на другой.
Последнюю функцию инженер выделял особо. В описании своего устройства он отмечал: «мозг» можно использовать для «перевода с одного иностранного языка на любой другой из трех, записанных в нем… Даже если существующая модель работает только на четырех языках, [потенциально] количество языков и количество слов для каждого из них может быть неограниченным».
В изобретении было 4 основных компонента. Первый — собственно «память», куда заносились слова на четырех языках. Второй — механизм ввода. Последние два элемента — механизм поиска (селектор) и механизм вывода. Как это работало?
Хатчинс рассказывает, что перевод проходил в четыре этапа:
- Вводилось слово для перевода, что активировало считывающую головку.
- Одновременно приводились в движение ленты механизма поиска и «памяти».
- Движение прекращалось, когда перфорация на ленте селектора совпадала с перфорацией на ленте «памяти».
- Оператор считывал результаты перевода.
Арцруни представил свое изобретение на Всемирной выставке в Париже в 1937 году. Некоторые государственные организации Франции — например, Министерство обороны и почтовая служба — заключили с инженером контракты на разработку устройств под их конкретные требования. Однако во время Второй мировой войны практически все наработки и прототипы «механического мозга» были утрачены.
СССР: «машина для подбора и печатания слов при переводе с одного языка на другой»
В том же 1933 году, когда Арцруни получил патент на «механический мозг», советский ученый Петр Троянский разработал свое устройство. Он назвал его «машиной для подбора и печатания слов при переводе с одного языка на другой или на несколько других одновременно». В отличие от механизма Арцруни, изобретение Троянского предназначалось только для перевода.
Самый лучший в мире переводчик?
Как отмечает Хатчинс, устройство было довольно простым: печатная машинка, пленочный фотоаппарат и «глоссарное поле» — пластина со словами на разных языках. Оператор находил на пластине нужное слово и фиксировал на нем ленту печатной машины. Затем он вводил код, обозначавший грамматическую категорию слова или его роль в предложении, после чего фотографировал комбинацию исходного слова и кода, которая переводилась на другой язык. Таким образом создавалась заготовка текста — последовательность слов с определенными характеристиками.

После этого в дело вступал редактор — он должен был знать язык перевода. Ориентируясь на коды, он менял форму слов и ставил их на нужные места в предложении. В результате получался связный текст.
Таким образом, Троянский создал не просто механический словарь — он показал, какой могла бы быть система полноценного машинного перевода. Но в Советском Союзе его наработки не посчитали полезными. К ним вернулись только в 1950-х годах — после Джорджтаунского эксперимента.

Конец 1940-х: Уоррен Уивер
Считается, что машинный перевод в известном нам виде зародился именно в 1940-е годы благодаря работам американского математика Уоррена Уивера. 4 марта 1947 года он отправил своему коллеге, математику и философу Норберту Винеру, письмо, где предложил применить к переводу методы криптографии. Он полагал, что перевод — это дешифровка текста оригинала:
«Полностью осознавая — хотя и смутно — семантические трудности, я задался вопросом, так ли уж немыслимо спроектировать компьютер, который будет переводить… Когда я смотрю на статью на русском языке, то говорю: „На самом деле это написано по-английски и закодировано какими-то странными символами. Теперь мне надо их расшифровать“».
У Винера это предложение энтузиазма не вызвало. Он считал, что для создания такой технологии «границы слов в разных языках слишком расплывчаты, а эмоциональные и межнациональные коннотации слишком разнообразны». Уивера, однако, мнение коллеги не остановило — он начал работать над своей идеей и в 1949 году опубликовал меморандум, который назвал «Translation» («Перевод»).
В этой публикации Уивер предложил четыре принципа, благодаря которым можно было бы выйти за рамки дословного машинного перевода:
- Уточнять значение слов с помощью контекста.
- Рассматривать язык как логическую систему и выстраивать процесс перевода на основе законов формальной логики.
- Рассматривать процесс перевода как процесс дешифровки и использовать инструменты криптографии.
- Упрощать перевод с помощью лингвистических универсалий — базовых элементов, свойственных всем естественным языкам.
Реакция на меморандум была неоднозначной. Некоторые исследователи отрицали саму идею механизации такого сложного процесса, как перевод. Но были и те, кто воспринял предложения Уивера более оптимистично. Ученые из разных областей — лингвистики, математики, логики и других — начали собственные исследования. Результатом впоследствии стал Джорджтаунский эксперимент.
1950-е годы: Джорджтаунский эксперимент и советские исследования
В 1952 году в Массачусетском технологическом университете прошла первая конференция по машинному переводу. Обсудив лингвистические и технические вопросы в этой области, ученые и инженеры пришли к выводу: уже в ближайшие годы можно провести эксперименты на опытных машинах. Первый такой эксперимент состоялся в 1954 году.
7 января 1954 года специалисты компании IBM и Джорджтаунского университета продемонстрировали возможности машинного перевода на практике. В компании компьютер IBM 701 перевел более 60 предложений с русского языка на английский. Скорость перевода составила 2,5 строки в секунду. Оригинальный текст вводился в компьютер на перфокартах, а результат распечатывался на принтере.

Отметим, что принципы перевода были весьма далеки от идей дешифровки, которые предлагал Уивер. Программа учитывала шесть синтаксических правил и использовала словарь из 250 слов. Иными словами, она анализировала связи между членами предложения, а не подсчитывала сочетания элементов. Так появился RBMT (Rule-based Machine Translation) — машинный перевод на основе правил.
В середине 50-х эксперимент стал сенсацией во всем мире. Многие страны начали разрабатывать свои системы машинного перевода, и прежде всего Советский Союз.
В октябре 1954 года в реферативном журнале Института научной информации (с 2004 года — Всероссийский институт научной и технической информации РАН) появилось сообщение о Джорджтаунском эксперименте. Оно стало стимулом для начала советских исследований в области машинного перевода. Уже в 1955 году в Институте точной механики и вычислительной техники АН СССР разработали первый советский компьютерный переводчик, использовавший словарь из 2300 слов. А через год, в 1956-м, в Москве появилось Объединение по машинному переводу.
В мае 1958 года прошла первая в СССР конференция по машинному переводу. На ней обсуждались проблемы перевода не только с английского, но и с других языков — арабского, норвежского, вьетнамского, китайского и так далее.
1960-е и 1970-е: комиссия ALPAC и система ЭТАП
Хотя Джорджтаунский эксперимент был, несомненно, впечатляющим, найти деньги для дальнейших исследований он не слишком помог. Все они стоили довольно дорого, и в 1964 году Пентагон и Национальный научный фонд США создали Консультативный комитет по автоматической языковой обработке (Automatic Language Processing Advisory Committee, ALPAC). Комитет должен был оценить, целесообразно ли финансировать разработки в области машинного перевода.
В 1966 году был опубликован отчет, после которого интерес американских ученых к машинному переводу угас, как отмечает Джон Хатчинс, примерно на 20 лет. Эксперты ALPAC рассматривали это направление чисто с практической точки зрения и пришли к выводу, что работа живого переводчика будет дешевле и качественнее. К тому же спрос на переводы не так уж велик: по данным ALPAC, из 4000 переводчиков, которые числились тогда в штате госучреждений США, постоянно были загружены только около 300. В итоге специалисты посчитали, что финансирование машинного перевода бесперспективно, тем более что его качество оставляло желать лучшего.
Тем не менее именно в 1960-е стали появляться и первые коммерческие разработки в этой области. В 1968 году Питер Тома, бывший сотрудник Джорджтаунского университета, открыл в компанию Systran. Она специализировалась на создании программ для машинного перевода и технологий, позволяющих его ускорить. Хотя по качеству такой перевод заметно уступал человеческому, в 1969 году компания подписала контракт с Минобороны США и постепенно стала работать не только с русским и английским, но и с другими языковыми парами.

Отчет ALPAC повлиял и на советские исследования в области машинного перевода — интерес к ним заметно снизился. Тем не менее работа не остановилась совсем. Так, в 1974 году в институте «Информэлектро» начали создавать систему ЭТАП — электротехнического автоматического перевода — на основе модели «смысл — текст».
Модель «смысл — текст» была разработана советским лингвистом И.А. Мельчуком в 1960-х годах. Она предполагала, что любой язык — это способ преобразовывать смыслы в соответствующие им тексты и наоборот. Фактически такое утверждение описывает модель перевода с языка на язык.
1990-е и 2000-е: статистические системы
К 1990-м годам стало понятно, что описать естественный язык с помощью понятных машине правил достаточно сложно. Исследователи начали искать другие пути.
Например, компания IBM разработала систему машинного перевода Candide. В некотором роде это был возврат к идеям Уоррена Уивера — текст на языке оригинала рассматривался как зашифрованный текст на языке перевода. Алгоритм подсчитывал, сколько раз слово было переведено определенным образом в определенном сочетании, и предлагал соответствующий вариант. В расшифровке могли быть некоторые ошибки, но все же в целом она была понятной.
Так начали появляться статистические системы машинного перевода — Statistical Machine Translation (SMT). Они анализировали множество примеров параллельных текстов — на языке оригинала и языке перевода — и самостоятельно выделяли из них правила. SMT лучше работали с омонимами, идиомами и многозначными словами, чем RBMT-системы. А еще были более обучаемыми: чем больше текстов проходило через алгоритм, тем больше статистики он собирал и тем точнее предлагал варианты. Неудивительно, что с развитием интернета перевод, основанный на правилах, использовался все реже.
Впоследствии появилась более эффективная версия статистического перевода — перевод на основе фраз (Phrase-based Machine Translation, PBMT). Теперь алгоритм мог анализировать и сопоставлять не только отдельные слова, но и целые фразы. Это позволило более точно переводить, например, устойчивые выражения.
До 2016 года на рынке господствовали именно статистические онлайн-переводчики: всем известный Google Translate (2007), Яндекс Переводчик (2011) и другие. В 2016 году ситуация стала меняться — появился нейронный машинный перевод.
2016–2022: перевод и нейросети
В сентябре 2016 года команда Google Brain опубликовала статью о своей системе нейронного машинного перевода (Neural Machine Translation, NMT). Речь о таких системах шла еще в нулевых. В отличие от предыдущих систем, в NMT алгоритм рассматривает предложение не как совокупность слов и фраз, а как цельную единицу текста. В результате количество ошибок при резко сократилось, а точность повысилась.
В июле 2017 года Google представила новую архитектуру нейросетей — Transformer. Такие нейросети эффективнее считывали связи между словами, стоявшими в предложении далеко друг от друга. Например, в предложении «I arrived at the bank after crossing the…» перевод слова bank зависит от того, что находится в конце фразы:
I arrived at the bank after crossing the road («Я пересек дорогу и оказался в банке»).
I arrived at the bank after crossing the river («Я пересек реку и оказался на берегу»).
Такие предложения корректно переводились и раньше. Но нейросети архитектуры Transformer анализируют контекст эффективнее.
В сентябре 2017 года нейросети архитектуры Transformer стали использовать и в Яндекс Переводчике. Яндекс применяет сразу два метода: статистический и нейронный. Программа выполняет перевод по обеим моделям, а затем алгоритм, основанный на методе машинного обучения CatBoost, предлагает пользователю лучший из двух вариантов.
В последние годы машинный перевод начали использовать и в других целях — для работы с видео. Например, в 2021 году в Яндекс Браузере появилась функция закадрового перевода англоязычных видео на YouTube и других сервисах. Пользователю достаточно нажать одну кнопку в проигрывателе, подождать пару минут — и можно смотреть ролик с озвучкой на русском языке. Все это благодаря работе нейросетей. Позже добавились и другие языки — немецкий, французский, испанский, итальянский.
А в августе 2022 года Яндекс добавил возможность автоматического закадрового перевода прямых трансляций — сейчас технология находится в публичном тестировании. Как она устроена? Одна нейросеть распознает речь и превращает ее в текст, когда фразу даже еще не закончили произносить. Вторая определяет пол спикера.
Третья расставляет знаки препинания и таким образом выделяет в речи смысловые фрагменты. Именно они отправляются четвертой нейросети — благодаря этому переводить удается почти на лету. Последняя, пятая, нейросеть отвечает за синтез речи. Технология позволяет смотреть интервью или презентации самых ожидаемых технологических новинок — в прямом эфире и сразу на русском языке. Работу технологии перевода прямых трансляций можно протестировать на примере «вечного» стрима NASA.
Источник: theoryandpractice.ru
Как работает нейронный машинный перевод?

В этой публикации нашего цикла step-by-step статей мы объясним, как работает нейронный машинный перевод и сравним его с другими методами: технологией перевода на базе правил и технологией фреймового перевода (PBMT, наиболее популярным подмножеством которого является статистический машинный перевод — SMT).
Результаты исследования, полученные Neural Machine Translation, удивительны в части того, что касается расшифровки нейросети. Создается впечатление, что сеть на самом деле «понимает» предложение, когда переводит его. В этой статье мы разберем вопрос семантического подхода, который используют нейронные сети для перевода.
Давайте начнем с того, что рассмотрим методы работы всех трех технологий на различных этапах процесса перевода, а также методы, которые используются в каждом из случаев. Далее мы познакомимся с некоторыми примерами и сравним, что каждая из технологий делает для того, чтобы выдать максимально правильный перевод.
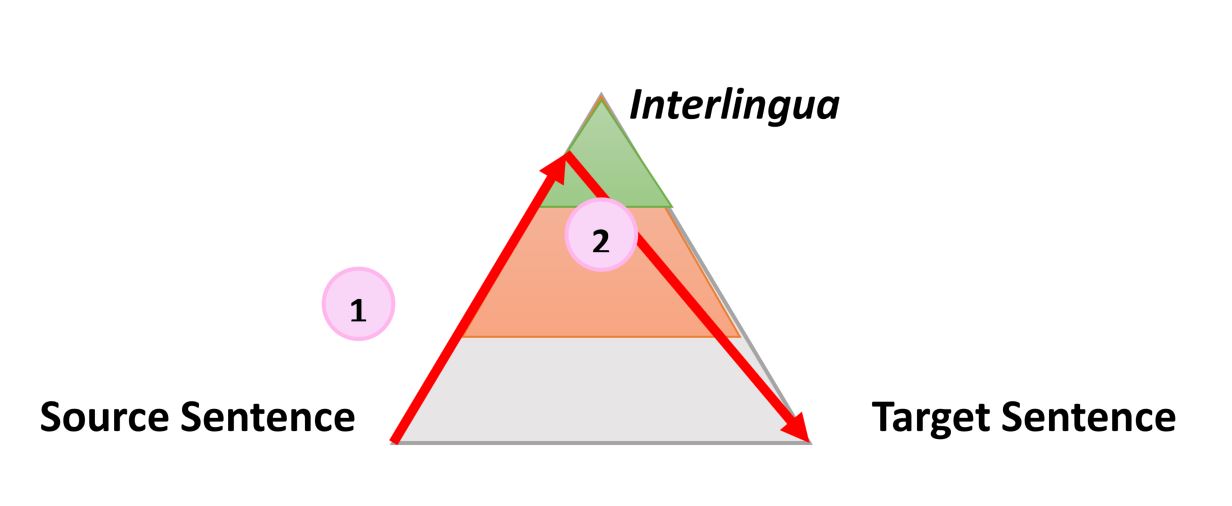
Очень простой, но все же полезной информацией о процессе любого типа автоматического перевода является следующий треугольник, который был сформулирован французским исследователем Бернардом Вокуа (Bernard Vauquois) в 1968 году:
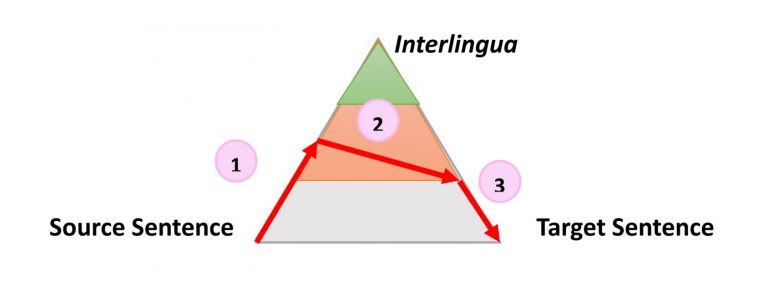
В этом треугольнике отображен процесс преобразования исходного предложения в целевое тремя разными путями.
Левая часть треугольника характеризует исходный язык, когда как правая — целевой. Разница в уровнях внутри треугольника представляет глубину процесса анализа исходного предложения, например синтаксического или семантического. Теперь мы знаем, что не можем отдельно проводить синтаксический или семантический анализ, но теория заключается в том, что мы можем углубиться на каждом из направлений. Первая красная стрелка обозначает анализ предложения на языке оригинала. Из данного нам предложения, которое является просто последовательностью слов, мы сможем получить представление о внутренней структуре и степени возможной глубины анализа.
Например, на одном уровне мы можем определить части речи каждого слова (существительное, глагол и т.д.), а на другом — взаимодействие между ними. Например, какое именно слово или фраза является подлежащим.
Когда анализ завершен, предложение «переносится» вторым процессом с равной или меньшей глубиной анализа на целевой язык. Затем третий процесс, называемый «генерацией», формирует фактическое целевое предложение из этой интерпретации, то есть создает последовательность слов на целевом языке. Идея использования треугольника заключается в том, что чем выше (глубже) вы анализируете исходное предложение, тем проще проходит фаза переноса. В конечном итоге, если бы мы могли преобразовать исходный язык в какой-то универсальный «интерлингвизм» во время этого анализа, нам вообще не нужно было бы выполнять процедуру переноса. Понадобился бы только анализатор и генератор для каждого переводимого языка на любой другой язык (прямой перевод прим. пер.)
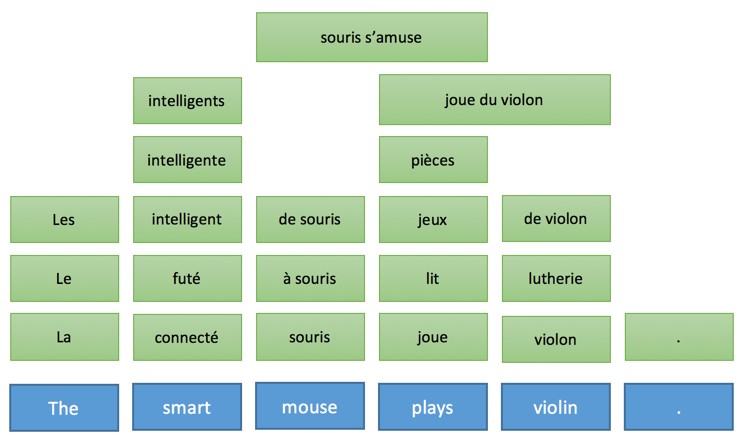
Эта общая идея и объясняет промежуточные этапы, когда машина переводит предложения пошагово. Что еще более важно, эта модель описывает характер действий во время перевода. Давайте проиллюстрируем, как эта идея работает для трех разных технологий, используя в качестве примера предложение «The smart mouse plays violin» (Выбранное авторами публикации предложение содержит небольшой подвох, так как слово «Smart» в английском языке, кроме самого распространенного смысла «умный», имеет по словарю в качестве прилагательного еще 17 значений, например «проворный» или «ловкий» прим. пер.)
Машинный перевод на базе правил
Машинный перевод на базе правил является самым старым подходом и охватывает самые разные технологии. Однако, в основе всех их обычно лежат следующие постулаты:
- Процесс строго следует треугольнику Вокуа, анализ очень часто завышен, а процесс генерации сводится к минимальному;
- Все три этапа перевода используют базу данных правил и лексических элементов, на которые распространяются эти правила;
- Правила и лексические элементы заданы однозначно, но могут быть изменены лингвистом.
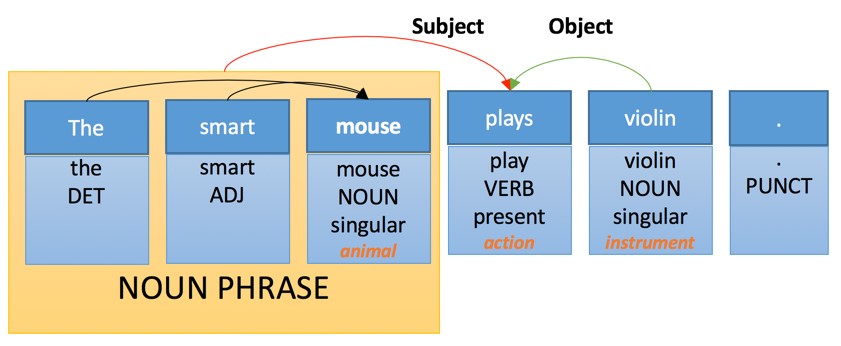
Тут мы видим несколько простых уровней анализа:
- Таргеритование частей речи. Каждому слову присваивается своя «часть речи», которая является грамматической категорией.
- Морфологический анализ: слово «plays» распознается как искажение от третьего лица и представляет форму глагола «Play».
- Семантический анализ: некоторым словам присваивается семантическая категория. Например, «Violin» — инструмент.
- Составной анализ: некоторые слова сгруппированы. «Smart mouse» — это существительное.
- Анализ зависимостей: слова и фразы связаны с «ссылками», при помощи которых происходит идентификация объекта и субъекта действия основного глагола «Plays».

Применение этих правил приведет к следующей интерпретации на целевом языке перевода:
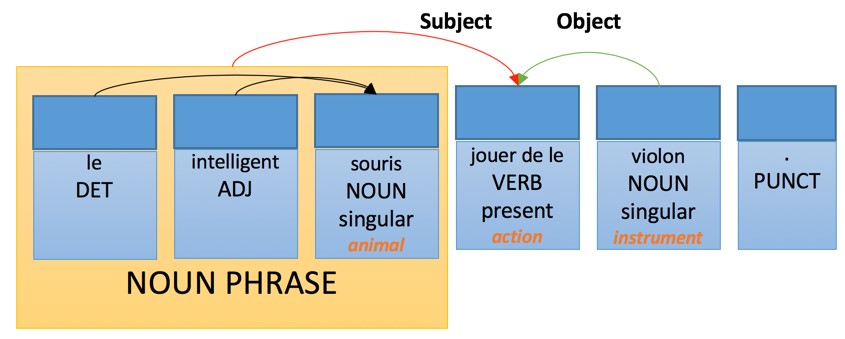
Тогда как правила генерации на французском будут иметь следующий вид:
- Прилагательное, выраженное словосочетанием, следует за существительным — с несколькими перечисленными исключениями.
- Определяющее слово согласованно по числу и роду с существительным, которое оно модифицирует.
- Прилагательное согласовано по числу и полу с существительным, которое оно модифицирует.
- Глагол согласован с подлежащим.
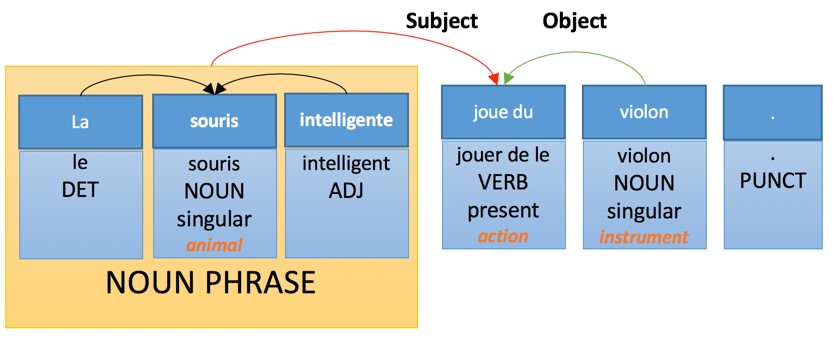
Машинный перевод на базе фраз
Машинный перевод на базе фраз — это самая простая и популярная версия статистического машинного перевода. Сегодня он по-прежнему является основной «рабочей лошадкой» и используется в крупных онлайн-сервисах по переводу.
Выражаясь технически, машинный перевод на базе фраз не следует процессу, сформулированному Вокуа. Мало того, в процессе этого типа машинного перевода не проводится никакого анализа или генерации, но, что более важно, придаточная часть не является детерминированной. Это означает, что технология может генерировать несколько разных переводов одного и того же предложения из одного и того же источника, а суть подхода заключается в выборе наилучшего варианта.
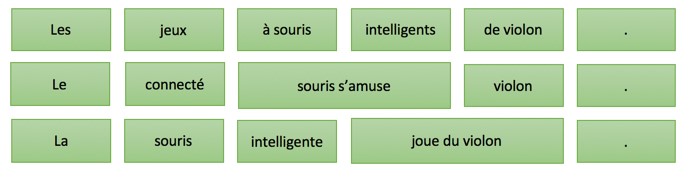
Эта модель перевода основана на трех базовых методах:
- Использование фразы-таблицы, которая дает варианты перевода и вероятность их употребления в этой последовательности на исходном языке.
- Таблица изменения порядка, которая указывает, как могут быть переставлены слова при переносе с исходного на целевой язык.
- Языковая модель, которая показывает вероятность для каждой возможной последовательности слов на целевом языке.
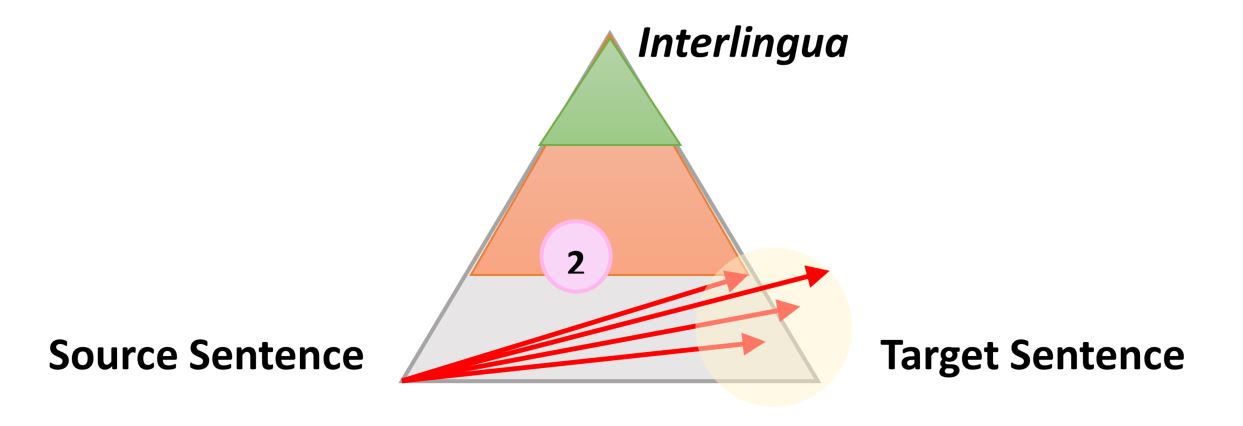
Далее из этой таблицы генерируются тысячи возможных вариантов перевода предложения, например:
Однако благодаря интеллектуальным вычислениям вероятности и использованию более совершенных алгоритмов поиска, будет рассмотрен только наиболее вероятные варианты перевода, а лучший сохранится в качестве итогового.
В этом подходе целевая языковая модель крайне важна и мы можем получить представление о качестве результата, просто поискав в Интернете:

Поисковые алгоритмы интуитивно предпочитают использовать последовательности слов, которые являются наиболее вероятными переводами исходных с учетом таблицы изменения порядка. Это позволяет с высокой точностью генерировать правильную последовательность слов на целевом языке.
В этом подходе нет явного или неявного лингвистического или семантического анализа. Нам было предложено множество вариантов. Некоторые из них лучше, другие — хуже, но, на сколько нам известно, основные онлайн-сервисы перевода используют именно эту технологию.
Нейронный машинный перевод
Подход к организации нейронного машинного перевода кардинально отличается от предыдущего и, опираясь на треугольник Вокуа, его можно описать следующим образом:
Нейронный машинный перевод имеет следующие особенности:
- «Анализ» называется кодированием, а его результатом является загадочная последовательность векторов.
- «Перенос» называется декодированием и непосредственно генерирует целевую форму без какой-либо фазы генерации. Это не строгое ограничение и, возможно, имеются вариации, но базовая технология работает именно так.
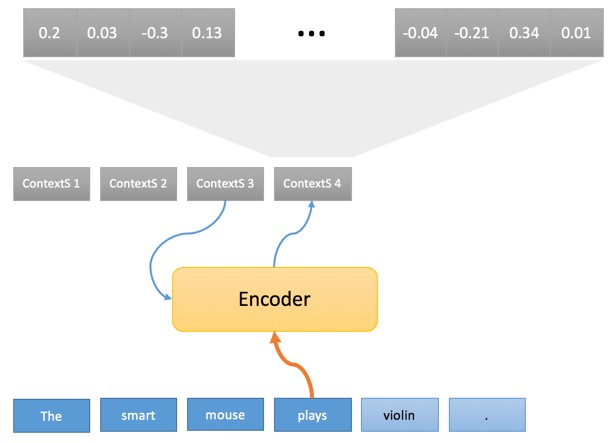
Последовательность исходных контекстов (ContextS 1,… ContextS 5) являет внутренней интерпретацией исходного предложения по треугольнику Вокуа и, как упоминалось выше, представляет из себя последовательность чисел с плавающей запятой (обычно 1000 чисел с плавающей запятой, связанных с каждым исходным словом). Пока мы не будем обсуждать, как кодировщик выполняет это преобразование, но хотелось бы отметить, что особенно любопытным является первоначальное преобразование слов в векторе «float».
На самом деле это технический блок, как и в случае с основанной на правилах системой перевода, где каждое слово сначала сравнивается со словарем, первым шагом кодера является поиск каждого исходного слова внутри таблицы.
Предположим, что вам нужно вообразить разные объекты с вариациями по форме и цвету в двумерном пространстве. При этом объекты, находящиеся ближе всего друг к другу должны быть похожи. Ниже приведен пример:
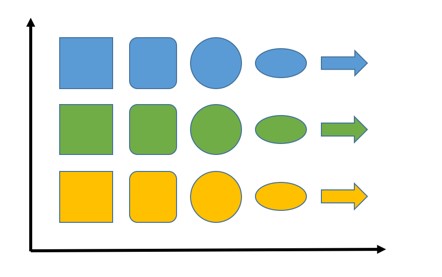
На оси абсцисс представлены фигуры и там мы стараемся поместить наиболее близкие по этому параметру объекты другой формы (нам нужно будет указать, что делает фигуры похожими, но в случае этого примера это кажется интуитивным). По оси ординат располагается цвет — зеленый между желтым и синим (расположено так, потому что зеленый является результатом смешения желтого и синего цветов, прим. пер.) Если бы у наших фигур были разные размеры, мы бы могли добавить этот третий параметр следующим образом:
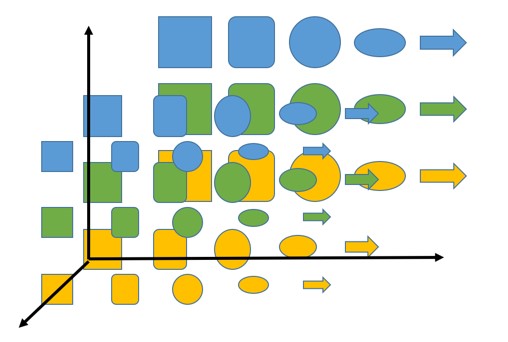
Если мы добавим больше цветов или фигур, мы также сможем увеличить и число измерений, чтобы любая точка могла представлять разные объекты и расстояние между ними, которое отражает степень их сходства.
Основная идея в том, что это работает и в случае размещения слов. Вместо фигур есть слова, пространство намного больше — например, мы используем 800 измерений, но идея заключается в том, что слова могут быть представлены в этих пространствах с теми же свойствами, что и фигуры.
Следовательно, слова, обладающие общими свойствами и признаками будут расположены близко друг к другу. Например, можно представить, что слова определенной части речи — это одно измерение, слова по признаку пола (если таковой имеется) — другое, может быть признак положительности или отрицательности значения и так далее.
Как работают программы машинного перевода?

Машинный перевод, хоть и не любим большинством переводчиков, является инструментом, который часто используется для решения таких задач в интернете, как переписка с иностранными партнерами, быстрый перевод сайтов, не имеющих официальной локализованной версии на родном языке, перевод комментариев и моментальных сообщений.
На базе информации, добытой таким образом, можно понять, о чем идет речь в целом, и нужен ли более точный и подробный перевод.
Программы машинного перевода можно разделить на переводящие пословно, по предложениям, и потекстово; на онлайн-сервисы и программы для персональных компьютеров. При этом с машинным переводом чаще всего ассоциируются с онлайн-сервисами, переводящими пофразово.
Чтобы понять, насколько программе сложно перевести не то что статью на сайте, но даже короткую фразу, которая будет отправлена как комментарий или личное сообщение, рассмотрим как такие программы работают.
Программе, чтобы переводить, требуется «знать» не только базовые правила грамматики двух языков и исключения к ним, но и уметь определить класс каждого слова, и прочие его атрибуты, такие как одушевленность или неодушевленность существительных, переходность глаголов.
Когда дело доходит до перевода, то программы действуют по следующей схеме:
- Подготовительный этап: сначала предложение разбивается на слова, производится их морфологический анализ и поиск в словаре значений их лексем. Потом производится синтаксический анализ предложения, в ходе которого выделяются придаточные предложения и определяется функция каждого отдельного слова.
- Лексический трансфер — каждому слову присваивается перевод на основе выявленного контекста, грамматической формы оригинала, а также пометок, сделанных в словарных статьях.
- Затем производится структурный трансфер — на этом этапе каждому слову присваивается место в предложении, устанавливаются структурные связи и производятся необходимые перестановки.
- Наконец, выбранным переводам слов придаются нужные (по мнению программы) грамматические формы.
Также различия есть и в механизме выбора вариантов перевода. Здесь подразделение идет на машинный перевод на базе лингвистических правил и на статистический метод машинного перевода. Первый базируется на доскональном анализе всех существующих правил, которые имеют жесткую привязку к конкретной языковой паре. Второй метод — статистический — выбирает на основе вероятности того, что конкретный вариант будет верным. Эта вероятность высчитывается по итогам анализа параллельных текстов на заданную тематику.
Программы, работающие на основе первого механизма, имеют большую точность и стабильность результата, особенно, когда производится перевод между языками с сильно разнящейся структурой и порядком слов. Однако для их создания требуются большие усилия по оснащению программы арсеналом баз и словарей, что сказывается и на скорости перевода. Кроме того необходима тщательная настройка параметров под заданную тематику, и полученные тексты звучат неестественно. Статистический метод работает быстрее, но проигрывает по фактору «надежности»: перевод может получиться или неожиданно хорошим, или очень плохим.
В качестве примера программы, работающей на основе лингвистических правил можно привести GramTrans. По статистическому методу работают Asia Online и всем известный Google Translate.
В силу того, что у обоих методов есть свои недостатки, разработаны и гибридные системы, к которым относится, например, система Promt. Суть работы подобных программ такова: в соответствии с лингвистическими правилами формируется не один, а несколько вариантов перевода. Затем статистические механизмы выбирают из них наиболее вероятный. Хоть времени и оперативной памяти это и не экономит, но делает результат настолько гладким, насколько это возможно без вмешательства человека.
Если бы задача компьютера в машинном переводе ограничивалась только быстрым перебором большого количества вариантов, записанных в различных статьях специальных словарей, то результат был бы куда лучше, чем мы имеем сейчас. Сложность скорее заключается в выборе значения, которое говорящий придает своим словам. А в этом плане человеческий язык нестабилен и переменчив, что делает машинный перевод таким сложным процессом.
Источник: perevodchik.me