
Чем бы не занималась компания, в современных реалиях ИТ-инфраструктура — важная часть бизнеса. Ведь на ней завязано много критических для компании процессов. Благодаря мониторингу можно узнавать о приближающихся инцидентах до того, как они возникли, оперативно их устранять и не терять деньги на незапланированных простоях. Рассказываем, как организован мониторинг клиентской ИТ-инфраструктуры в ITGLOBAL.COM.
Что такое мониторинг
К мониторингу ITGLOBAL.COM подключены ИТ-инфрастурктура и сервисы более 100 компаний. Мониторинг организован так, чтобы можно было контролировать все до единого процессы в информационных системах. Мониторить можно бесконечное количество параметров, но ITGLOBAL.COM фокусируется на ключевых характеристиках, критичных для конкретного бизнеса. Все сделано не ради отчетов, а ради эффективности и соблюдения SLA.
Мониторинг ITGLOBAL.COM
Компания накопила большой опыт, и для всех ключевых сервисов существуют базовые наборы правил — «модели здоровья». Наши специалисты настраивают мониторинг так, что система посылает только нужные уведомления и только тогда, когда надо. То есть у нас полностью исключена ситуация, при которой генерируются тысячи бессмысленных уведомлений.
Сейчас объясню. Мониторинг ИТ-инфраструктуры: метрики, инструменты и полезные советы
На каком программном решении организован мониторинг
- Это одно из лучших решений для организации системы мониторинга на большом количестве точек.
- У Icinga высокая отказоустойчивость, при условии размещения в нескольких географических точках.
- Решение поддерживает формат баз данных InfluxDB — один из самых удобных вариантов для организации службы мониторинга.
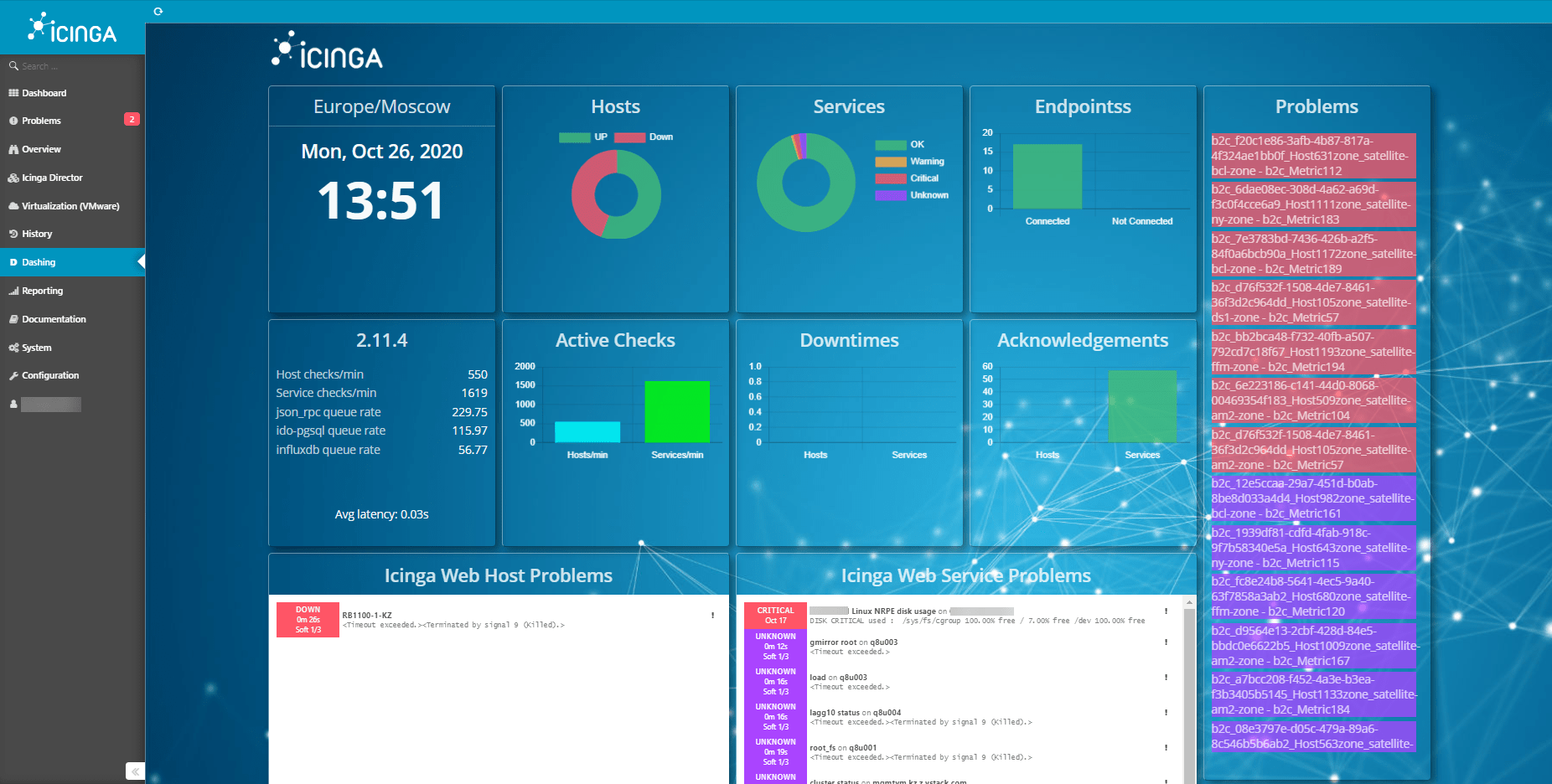
Как устроены «модели здоровья»
Устройство каждой конкретной модели зависит от типа сервиса, который контролируется. Существуют базовые метрики: состояние CPU, RAM, свободного места на дисках, аптайм и сетевая доступность (пинг с разных точек).
Дополнительные метрики зависят от роли сервера. Например, для статичного сайта добавляется уведомление об экспирации доменного имени и сертификатов безопасности. Для веб-сервера — количество порождаемых дочерних процессов. Кроме того, клиент, как правило, сообщает метрики, которые важны именно ему. Таким образом, с каждым новым клиентом, модели здоровья компании постоянно улучшаются.
Какие проблемы способен выявить мониторинг
Он дает около 80% необходимой информации для понимания источника проблемы. При покрытии всех процессов и настроенных моделей здоровья, мониторинг дает полный контроль и возможность увидеть всю «картинку» целиком и далее уже планировать изменения. Вот несколько примеров, что именно учитывает мониторинг ITGLOBAL.COM.
- Работу HTTP, SMTP, NNTP, POP3, NNTP, Ping и других сетевых служб.
- Использование жестких дисков, загрузку процессоров, использование RAM и другую работу ресурсов хоста.
- Работоспособность хостов.
- Работу маршрутизаторов, коммутаторов, датчиков (температуры, влажности и других), серверов и другого оборудования ЦОД.их компонентов в серверных.
Какие параметры мониторинга важны
Базовые метрики сразу выявляют 80% всех проблем. Таким образом можно заранее предотвратить возможные убытки. Кроме того, ITGLOBAL.COM делает фокус на метрики, которые важны для конкретного бизнеса. К примеру, это может быть RPS, количество обрабатываемых запросов в секунду.
Настраиваем MSI Afterburner — Мониторинг, фпс, frametime, железо в оверлее
Метрика, критичная для ритейла и многих других отраслей — количество транзакций в единицу времени и стабильность потока данных. Ведь каждая транзакция — это прибыль для клиента.
Что происходит после того, как система обнаруживает проблему
Если модель здоровья сгенерировала предупреждение, в системе поддержки автоматически заводится инцидент-тикет. Служба поддержки ITGLOBAL.COM работает круглосуточно и в течение 15 минут реагирует на инцидент.
В первую очередь выясняется степень критичности инцидента и его влияние на работу ИТ-сервиса. В службе поддержки разработаны инструкции, как действовать при самых распространенных проблемах. Если проблема существенная, то к процессу подключаются специалисты второй линии.
Можно ли обойтись без мониторинга
Да, но это будет означать полное отсутствие контроля. Вы будете не предотвращать проблемы, а узнавать о них от клиентов. На вашей репутации и доходах это скажется самым негативным образом. Плюс важно учитывать, что на решение проблем вы будете тратить в 5-10 раз больше времени, чем команда профессиональных специалистов, «вооруженная» мониторингом.
Кому и когда следует обратиться за услугой мониторинга
Мониторинг как услуга освобождает вас от множества трудоемких задач:
- Вам не нужно устанавливать на свою инфраструктуру программное обеспечение и следить за его обновлением.
- Не нужно беспокоиться о полном покрытии мониторингом своих информационных систем.
- Не нужно придумывать и настраивать модели здоровья. Модели здоровья ITGLOBAL.COM успешно протестированы на сотнях клиентов.
- Не надо заниматься оперативной работой — добавлением, удалением, перенастройкой новых узлов инфраструктуры.
При подключении сервиса с клиентом согласовываются модели здоровья и условия получения уведомлений. Например, ИТ-службы могут получать их в круглосуточном режиме, а бизнес-подразделения можно информировать только о критичных случаях. Это сэкономит время и человеческие ресурсы.
Источник: itglobal.com
Что такое мониторинг приложений? — определение из техопедии
Мониторинг приложений — это процесс, который гарантирует, что программное приложение обрабатывает и работает ожидаемым образом и в объеме. Этот метод регулярно идентифицирует, измеряет и оценивает производительность приложения и предоставляет средства для выявления и исправления любых отклонений или недостатков.
Мониторинг приложений также известен как мониторинг производительности приложений (APM) и управление производительностью приложений (APM).
Techopedia объясняет мониторинг приложений
Процесс мониторинга приложений, как правило, включается через специализированное программное обеспечение APM, которое интегрировано в основное отслеживаемое приложение. Как правило, мониторинг приложений обеспечивает показатели времени выполнения системы, которые предоставляются администратору приложения.
Эти метрики включают время транзакции, системный ответ, объем транзакции и общее состояние внутренней инфраструктуры. Как правило, метрики доставляются через программную панель APM в виде графических фигур и статистики. Эти цифры позволяют оценить производительность приложения или всей инфраструктуры приложения. Мониторинг приложений также оценивает работу конечного пользователя и производительность приложения на уровне компонентов.
Источник: ru.theastrologypage.com
[Basics] Мониторинг: что/куда/зачем?
Привет, %username% ! Поговорим о такой безумно важной вещи как мониторинг! Постараемся ответить на некоторые вопросы связанные с мониторингом инфраструктуры и приложений.
Определения#
Для начала определимся что есть что:
- Мониторинг инфраструктуры – это сбор метрик описывающих состояние вашей IT-инфраструктуры;
- Метрика – это конкретная характеристика, показывающая текущее состояние по определенному параметру (пример: количество одновременных подключений);
- Сервер мониторинга – ПО, которое выполняет агрегацию, хранение, пересчет данных по метрикам;
- Агент мониторинга – ПО, которое выполняет сбор метрик с хоста, который подлежит мониторингу, а так же отправку данных на сервер мониторинга;
Вроде бы всё довольно просто выглядит: мониторинг – это сбор показателей системы (инфраструктуры) в реальном времени (ровно на столько, на сколько это возможно — об этом чуть ниже).
Инструменты#
На рынке уже давно устоялись такие замечательные инструементы как Zabbix, Prometheus, Nagios, OpenNMS, Cacti, Netdata. Обзор данных продуктов я делать не буду, т.к. этой информации предостаточно на просторах паутины. Главное что необходимо знать о системах мониторинга, это то как они работают (в общих чертах).
Модели работы#
Собственно две основные (ибо кмк являются уже стандартом де-факто для всей отрасли) системы мониторинга – Zabbix и Prometheus – могут работать в двух режимах (по двум моделям): Push и Pull.
- Push-модель – когда сервер мониторинга ожидает подключений от агентов для получения метрик;
- Pull-модель – когда сервер мониторинга сам подключается к агентам мониторинга и забирает данные;
Все довольно просто: выбор модели работы необходимо делать исходя из того, чего вы хотите и что вы можете. Например (пусть будет Zabbix):
У вас есть 10 серверов в приватной сети и без белых IP, а так же отсутствует возможность настроить хоть какой-то NAT (пробросить порты до агентов). А сервер мониторинга у вас отдельный (пусть стоит где-то у хостера) и он не имеет прямой связи с данными 10-ю серверами, которые вы хотите мониторить.
В данном кейсе ваш выбор очевидет – вам подходит только Push-модель. Вам необходимо будет добавить все хосты в мониторинг, указать им в качестве IP тот адрес который они имеют в приватной сети, порт оставить по дефолту, а в качестве шаблонов выбирать те, которые используют активного агента. В этом случае у вас будет агент подключаться к серверу и отдавать метрики.
Данную схему можно немного доработать – у Zabbix есть такая вещь как Zabbix-Proxy, а у Prometheus – Pushgateway. Данные сервисы в некоторых ситуациях помогут исправить картину мира. Например:
Возьмем ту же картину мира, что и в прошлом примере, и добавим туда еще один сервер, на котором развернем Zabbix-Proxy, а хосты в самом Zabbix (в веб-интерфейсе), привязываем к Zabbix-Proxy. После чего можем привязывать шаблоны с обычными агентами.
Что мониторить?#
Теперь попробуем определиться что именно мы хотим мониторить? Какие метрики нам нужны? Тут все так же просто – начнем по порядку снизу вверх:
- Аппаратные метрики – все то, на чем крутится ваша ОСь (даже если у вас виртуализация – собрайте метрики виртуализации);
- Метрики ОС – чем занимается ваша ОСь (CPU/RAM/Disks/Network);
- Метрики сервисов – метрики всего того, что обеспечивает доступность приложения (Nginx/Apache/Redis/MySQL/PostgreSQL);
- Метрики приложения – все метрики вашего приложения (тот же PHP/NodeJS). Сразу оговорюсь — тут без ваших разработчиков никак. Пусть дают конкретные ручки, которые будет дергать мониторинг. А сразу имеет смысл мониторить количество запущенных процессов (Кэп), количество потребляемой процессом памяти (мы так узнали, что у нас текла NodeJS по памяти, а пока разрабы не придумали как решить проблему — мы рестартовали демон каждые 20-30 минут);
- Метрики смежных сервисов – метрики всего того, с чем взаимодействует ваше приложение (внешние/внутренние интеграции — сторонние API, 1C);
Собственно говоря список не такой уж и большой, но при желании его так же можно расширять под себя и пихать туда всё, что захочется видеть.
Как часто собирать метрики?#
Я выше упомянул о том, что такое мониториг, а так же сказал, что он должен быть real time ровно на столько, на сколько это возможно реализовать. В чем собственно проблема, может спросить абсолютно любой. А проблема довольно простая и очевидная. Я как админ хочу знать, что моя инфратруктура жива и с ней все в порядке.
Любой неочень разраб, да и недалекий начальник — а-ля бигбосс — скажет: а давай собирать метрики раз в секунду! С одной стороны это выглядит вполне логично! И в идеальном мире я бы так и делал, но как всегда есть одно “НО”.
Начну с примера: у нас есть средний сайтик средней компании со средней посещаемостью 10 человек в месяц. Этот сайтик показывает картинку с котиком, каждый раз разную как только любой пользователь открывает главную страничку сайта. Пусть у нас будет средний PHP+MySQL+Nginx. Все это добро крутится на простеньком сервере (не будем называть характеристики для упрощения картины мира).