
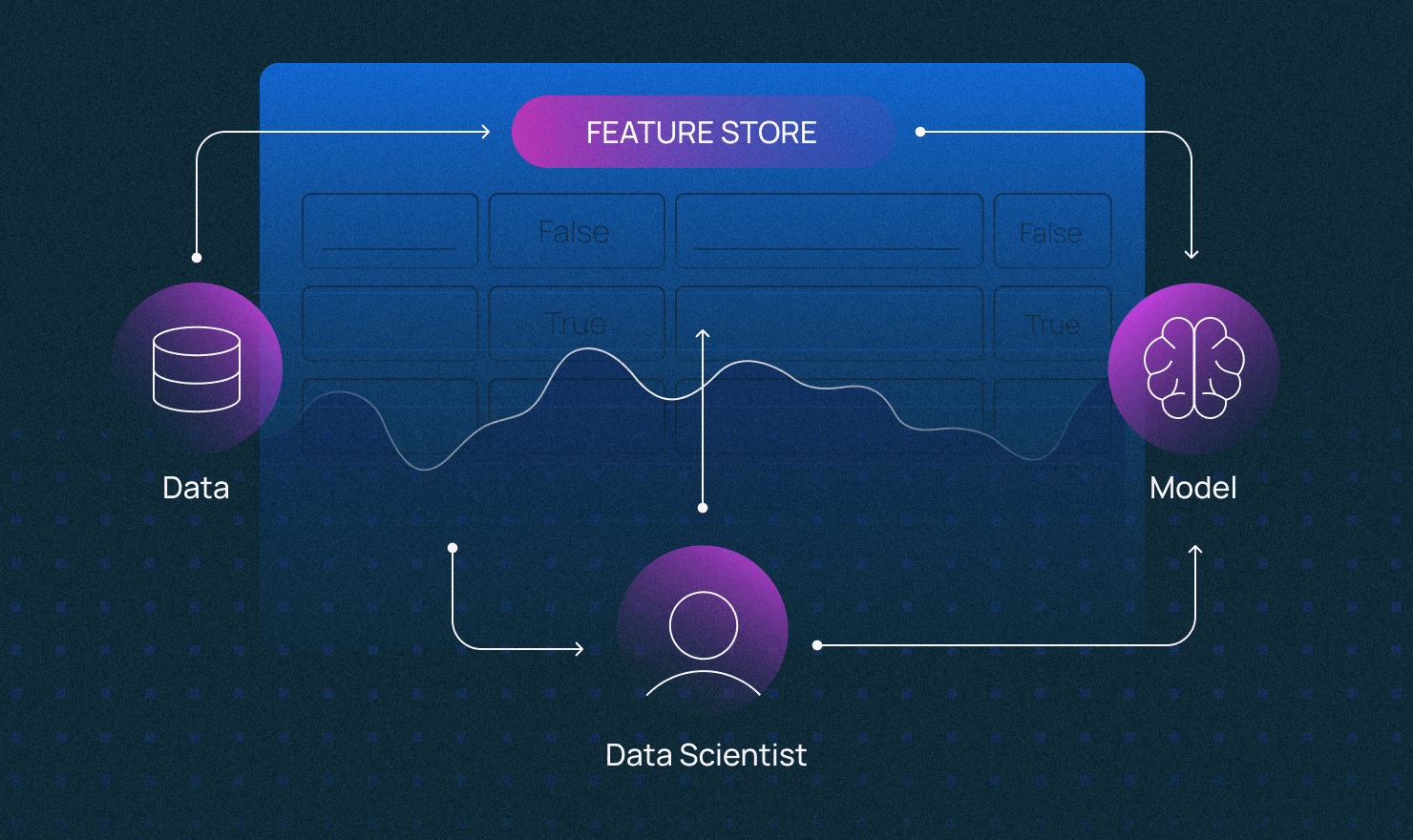
В работе с данными для обучения нейросетей много рутины: под каждую ML-модель нужно создать датасет, потом «вычеркнуть» лишние признаки (фичи) и протестировать точность предсказаний. Иногда при изменении датасета нужно собирать данные по новой. Это неудобно, если нужно переиспользовать уже собранные фичи для обучения новых моделей. Чтобы оптимизировать работу с данными, ML-инженеры объединили разные практики и сформировали парадигму Feature Store.
Если вам интересна тема статьи, присоединяйтесь к нашему сообществу «MLечный путь» в Telegram. Там мы вместе обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также делимся собственным опытом. А еще там раз в неделю выходят дайджесты по DataOps и MLOps.
Задачи Feature Store

Артём Глазков, ведущий эксперт MLOps Polymatica:
ML System Design: Feature Store
Feature Store — это «магазин» фичей, интерфейс между данными и моделями ML. Но технология вовсе не революционная. Она объединяет давно сложившиеся практики по управлению данными. В частности, каталогизацию фичей для обучения и продакшена ML. Просто раньше их применяли в работе с офлайн-данными (батчами), а сейчас «перебрались» в онлайн.
По сути, технология абстрагирует работу с данными от разработки ML-моделей, делает процессы независимыми друг от друга. Подробней о том, что такое Feature Store в принципе, можно узнать тут.
Вот несколько случаев, когда Feature Store может выручить.
- Нужно переобучить нейросеть на новом наборе параметров.
- Нужно перенести датасет из одной модели в другую с учетом ее особенностей параметризации.
Кому может понадобиться?
Feature Store нужен не всем. В первую очередь технология полезна компаниям, которые много работают с ML-сервисами. Рассмотрим пару примеров.
Классический случай: онлайн-банк выдает займы клиентам. Последних можно описать большим количеством внутренних и внешних данных — они подаются на входы моделей в виде фичей. По усредненному результату система определяет, можно ли заключить с клиентом договор.
С помощью Feature Store банк организовал централизованную работу с фичами, которые одинаково хорошо работают в моделях, собранных разными департаментами.
Студия ML-сервисов
Случился «бум!» — всем вдруг понадобилось машинное обучение. Tesla тестирует новые машины с компьютерным зрением, а очередной банк создал голосового помощника «Олежа». И все обращаются к студии ML.
Компании нужно ускорить time-to-market сервисов, чтобы быстрее сдавать заказы. Для этого разработчики студии интегрировали Feature Store. Теперь они способны централизованно проводить эксперименты с разными параметрами моделей и оперативно выпускать сервисы в продакшен.
Но Feature Store не всегда был таким «эффективным».
MLOps Feature Store Explanation

История развития
Задачи о подготовке данных появились давно. Однако термин Feature Store ввели лишь в 2017 году. Тогда в компании Uber начали развивать сервисы обработки данных и в рамках ML-платформы Michelangelo ввели «новую» технологию.
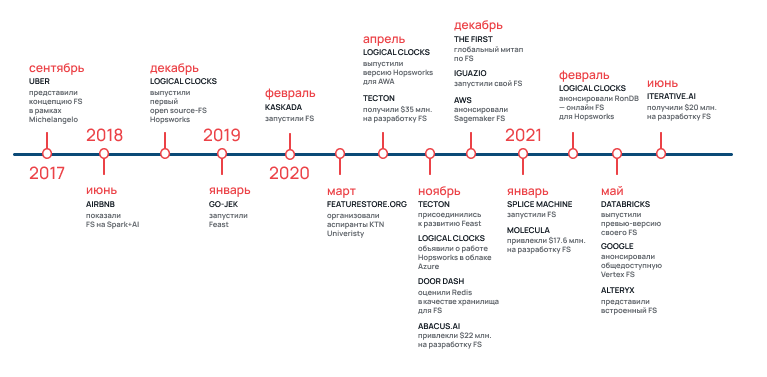
Хронология развития Future Store. Источник
В 2018-2019 был важный «поинт» — появление первых open source-платформ — Hopsworks и Feast. И уже в 2020-2021 годах компании начали запускать альтернативные платформы, а стартапы — внедрять Feature Store в свои проекты.
Рынок Feature Store-платформ сегодня
На рынке есть около 20 решений, которые можно использовать в своих ML-системах.
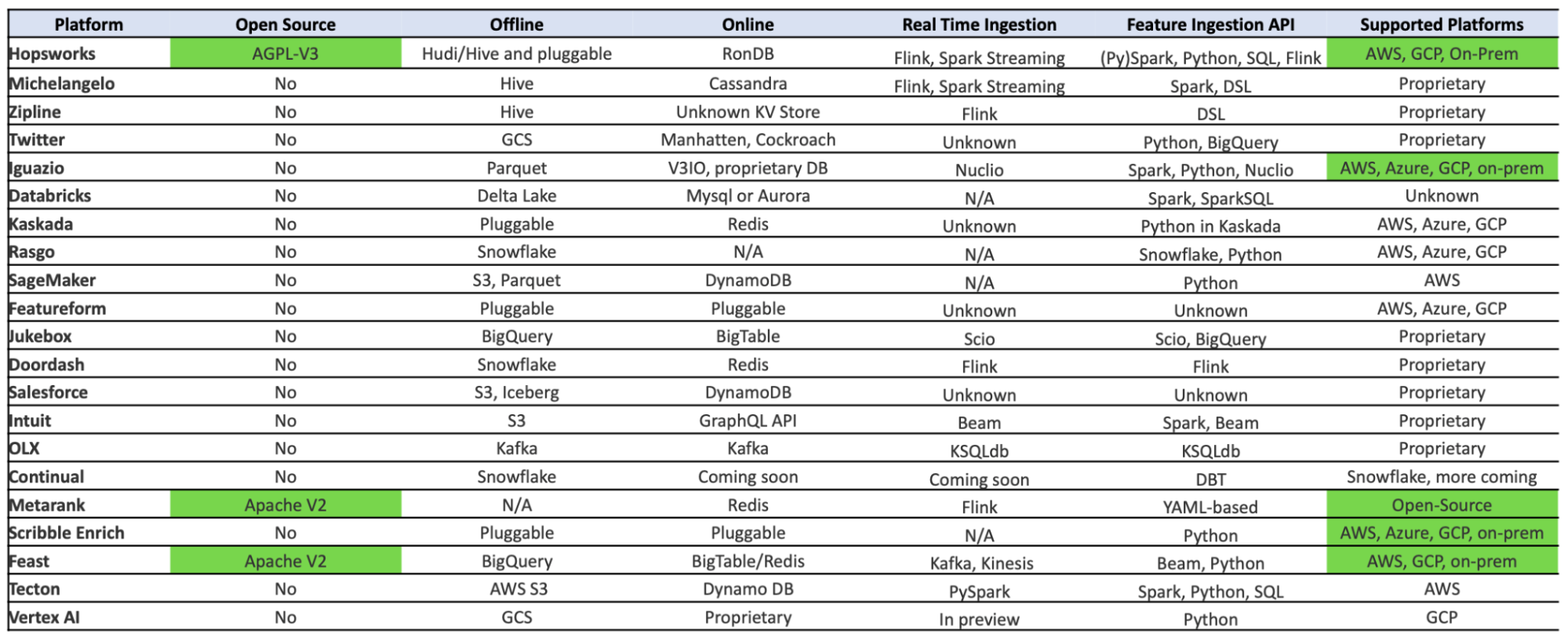
Список Feature Store-платформ. Источник
Большинство Feature Store-платформ проприетарны, open source-решений мало. Это нужно учитывать, например, при проектировании собственной ML-платформы.
Также смотрите, чтобы выбранное решение соответствовало вашим требованиям. Иногда вендоры называют свой продукт Feature Store, а внутри платформы реализуют только базовый функционал. Так каким запросам должен отвечать современный Feature Store?
Что нужно ML-инженерам от Feature Store?
На рынке нет «серебряной пули» — существующие платформы можно оценить только через потребности ML-команд и компаний. Вот распределение по частоте запросов бизнеса к функциональным возможностям Feature Store:

Распределение запросов к Feature Store-платформам. Источник
Рассмотрим самые частые требования, отраженные в первой и четвертой группах:
- Версионирование фичей — наблюдение за версиями и логикой расчета фичей на исторической прямой. Если нужно ввести новую переменную, можно посмотреть, как она влияет на точность фичей. И «зашить» ее в логику расчетов таким образом, чтобы качество модели не пострадало.
- Офлайн-расчеты — возможность расчета витрины в офлайн-режиме. Можно организовать на базе простого хранилища данных (DWH). Здесь нет rocket science.
- Поддержка on-premise — реализация всего пайплайна внутри собственной IT-инфраструктуры. Особенно важно для тех, кто не доверяет публичным облакам свои фичи и «секретные статистики». Актуально для научных, банковских и других организаций.
- Наличие Linage — наличие взаимосвязей между моделями и данными. Во время работы с большим количеством экспериментов важно, чтобы в любой момент была доступна информация о том, в каких моделях используются фичи.
- Работа с моделями в потоковом режиме — возможность использовать Feature Store в онлайн- и офлайн-режимах одновременно. Например, в онлайн-режиме запускать модели с данными для продакшена, а в офлайн — для обучения.
- Расчеты внутри источников данных — возможность «опустить код к данным» и делать ресурсоемкие расчеты внутри источника данных.
- Управление ресурсами — функция резервирования памяти и мощности процессора под N расчетов, например, внутри источников данных.
- Процессы согласования — то, что редко встречается в платформах «из коробки». Полезно для компаний, в которых есть несколько отделов, — например, риск-менеджеры, маркетологи и антифроды — которые используют ML-модели. С помощью процессов согласования DS-специалист может «запросить» разрешение на изменение логики расчёта фичей и предупредить коллег, чтобы не «сломать» модели.
Рассмотрим пример хорошего открытого решения.
Feast: «эталон» open source-Feature Store
Feast — наиболее популярный открытый Feature Store. На него можно ориентироваться при выборе платформы.
В рамках реализации платформы есть пять функциональных блоков — Registry, Transform, Storage, Serving и Operational Monitoring. Рассмотрим их по отдельности.
Registry
Это «каталог фичей» — основной компонент Feast. Некий центральный интерфейс для каталогизации и классификации фичей. Помогает расставить все «по полочкам» — сформировать структуру репозитория признаков.
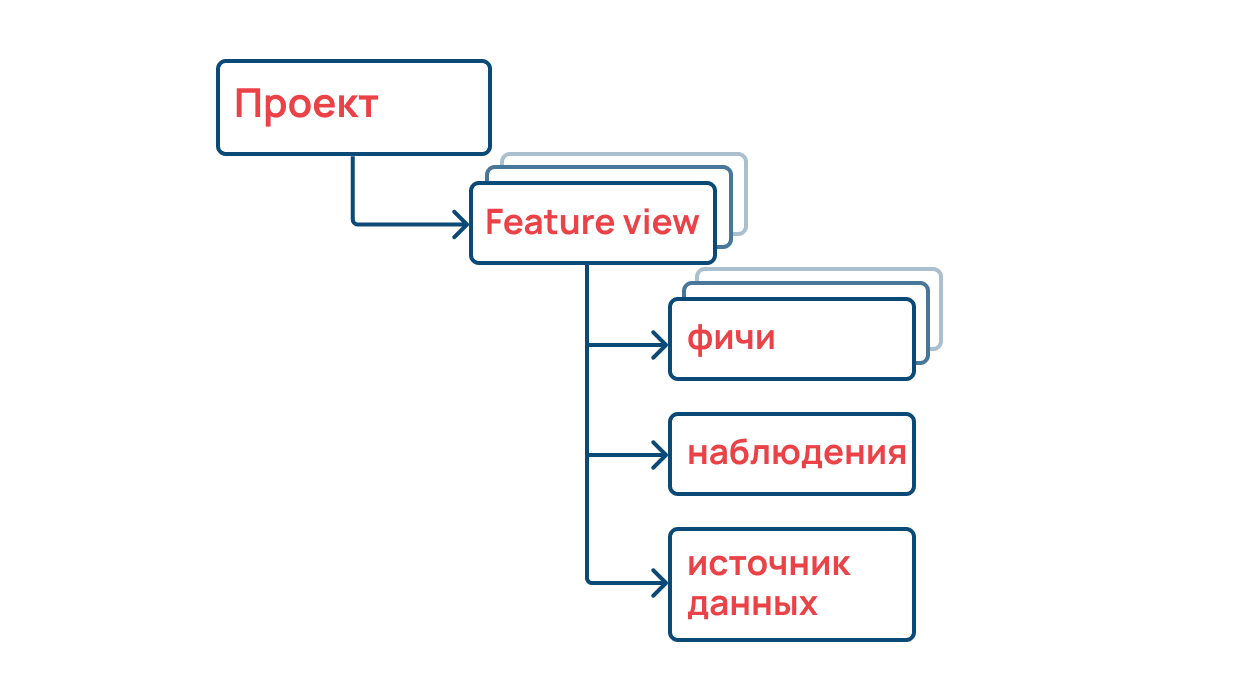
Структура репозитория признаков. Источник
В представлении этой структуры хранятся фичи по такому сценарию:
Есть проект, который решает определенную бизнес-задачу. Feature view описывает набор наблюдений (Entity). На этом уровне можно понять, из какого источника брать фичи, и получить их.
Transform
Компонент для преобразования фичей под определенные модели.

Типы преобразований в Transform. Источник
Вот основные типы преобразований:
- Преобразования на пакетных данных — когда на основании таблиц из базы данных нужно сделать определенные расчеты, чтобы подать фичи на вход модели.
- Потоковые преобразования — расчеты данных, которые поступают в режиме реального времени, и подготовка их для работы модели. Актуально для сервисов в продакшене — например, для онлайн-сервисов по покупке авиабилетов.
- Преобразование по запросу — работает только на этапе применения модели. Они нужны для определения оптимальных путей обработки входящих запросов. Актуально для тех, кто хочет «скармливать» данные и критерии без помощи экспертов, — например, менеджерам.
Storage
После описания и получения фичей в Registry нужно их «материализовать» — представить в виде конкретных таблиц и векторов, а после — загрузить в хранилище фичей Storage.

Схема компонента Storage. Источник
Feast позволяет загружать фичи в офлайн- и онлайн-хранилища. Первое подходит для хранения kv-store (оперативных данных), а последнее — для data lake (данных для обучения).
Возможно, эти тексты тоже вас заинтересуют:
Serving
Позволяет пользователю получить доступ к фичам, которые размещены в Storage.
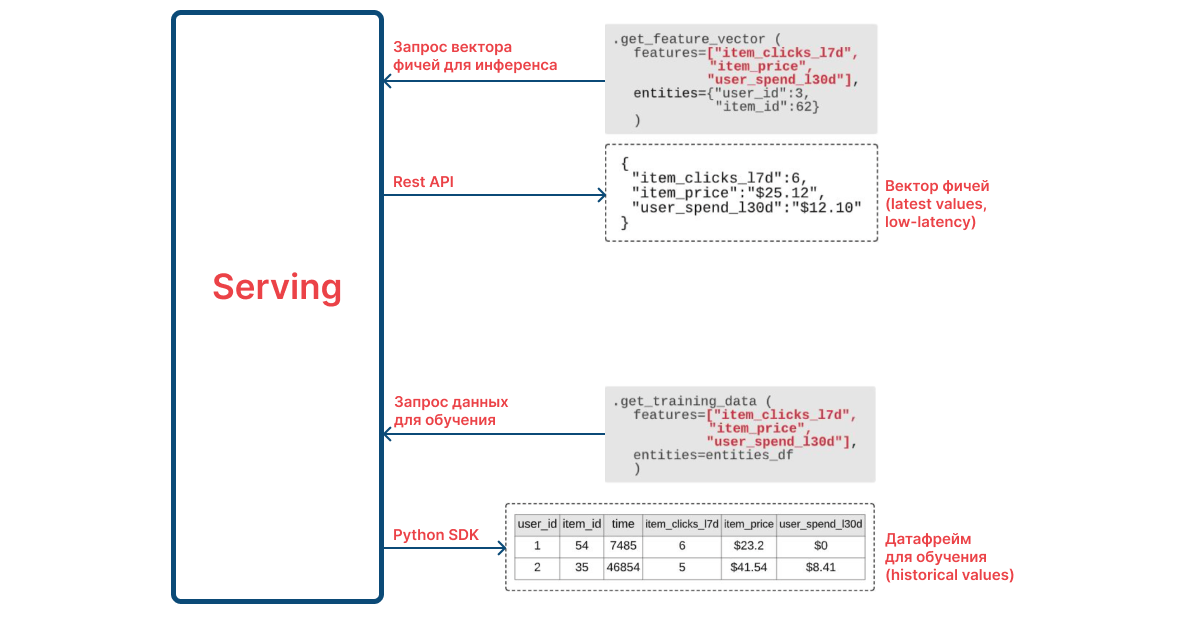
Схема компонента Serving. Источник
Serving реализован в простом Python SDK. То есть пользователь может прямо из Jupyter Notebook сделать запрос к Feast и описать, по каким переменным нужно построить модель данных. Платформа вернет результат в формате Pandas-dataframe.
Как компоненты работают в связке
Рассмотрим пример работы Feature Store.

Работа компонентов в связке. Источник
Чтобы платформа заработала, нужно описать схему расчета фичей — за это отвечает Registry. На основании этой схемы загружаются фичи для обучения и Feature Store наполняется материальными данными. Далее признаки можно использовать для построения моделей. А после проверки корректности расчета — выпустить Feature Store в продакшен.
На этапе инференса платформа может рассчитывать фичи — для этого Feature Store запускает логирование вектора данных на вход моделей. В режиме реального времени можно отслеживать качество сборки фичей, прогнозы моделей и в дальнейшем дрейф данных. Это полезно, когда нужно, например, беспрерывно прогнозировать продажи в собственном интернет-магазине.
Используют ли Feature Store в вашей компании? Какой подход вам нравится больше: разработка собственного FS с нуля или внедрение готового решения? Поделитесь своим опытом и мнением в комментариях.
- selectel
- feature store
- машинное обучение
- ML
- работа с данными
- обработка данных
- Блог компании Selectel
- Высокая производительность
- Машинное обучение
- Искусственный интеллект
Источник: habr.com
Зачем вам Feature Store или что не так с микросервисами в ML-системах
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем здесь потоковая обработка событий с Apache Kafka и Spark Streaming.
Проблемы микросервисной архитектуры в ML-системах на практическом примере
В настоящее время микросервисная архитектура стала стандартом де-факто, который чаще всего применяется для построения различных информационных систем, от небольших приложений до крупных Big Data Платформ. Благодаря автономности каждого микросервиса от других компонентов решения, общая скорость разработки, тестирования и развертывания продукта существенно возрастает, чего и требует основная идея Agile. Обратной стороной этого преимущества является увеличение нагрузки на архитектора при проектировании системы и разделении ее на отдельные сервисы. Кроме того, слишком частые вызовы сервиса, могут привести к перегрузке системы.
В частности, микросервисы очень сложно применять при построении моделей машинного обучения (Machine Learning, ML) на сложных источниках данных, таких как поведение пользователей. В этих случаях, чтобы сделать прогноз, нужно множество взаимозависимых микросервисов, чтобы получить всю необходимую им контекстную информацию. Например, нужно создать персонализированный канал Reddit – социальном новостном сайте, где зарегистрированные пользователи могут размещать ссылки на понравившуюся информацию. Для этого требуется знать обо всех сообществах, в которых участвует пользователь, о самых популярных сообщениях в этих группах, о любых сообщениях, которые он прочитал, и они ему понравились, а также прочая подробная информация. Добавление дополнительных входов даст больше данных для обучения ML-модели, позволяя ей уловить важные тенденции и сделать прогноз точнее.
Каждый логический вход в ML-модель называется признаком/предиктором или фичей (от англ. feature). Feature-engineering считается одной из самых трудоемких задач Machine Learning: много времени уходит на поиск нужных данных, изучение их особенностей и крайних случаев. Также сюда входит построение конвейеров данных (data pipeline) для их очистки и преобразования в пригодную для использования форму.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
14 августа, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
В микросервисной архитектуре сбор данных выполняется через API. Одна ML-модель может иметь много разных фичей, требующих соответствующих вызовов API.
Например, модели нужно запросить пользовательский сервис для сообществ, в которые входит пользователь, затем получить самые популярные сообщения в каждом из них, а после определить его отношение к этим записям через отметки «нравится» (лайк от англ. like). Такая сложная последовательность действий приведет к эффекту домино сетевых вызовов. В отличие от веб-интерфейса, ML-модель не обладает гибкостью в отношении недостающих фичей: ей придется дождаться завершения всех запросов или использовать некорректные входные данные [1]. Последнее может привести к некачественным результатам, т.к. один из принципов Data Science вообще и Machine Learning в частности гласит: «мусор на входе дает мусор на выходе» (garbage in – garbage out).

3 альтернативы микросервисной архитектуре
Для обучения ML-модели нужен набор данных наблюдаемых результатов и входные данные в момент времени наблюдения. Создание датасета в микросервисной архитектуре не просто. В рассматриваемом примере с Reddit требуется набор пользовательских оценок вместе с набором фичей на этот момент.
Технически можно получать оценки пользователей и все данные о публикациях с помощью микросервисов. Однако в этом случае теряется точность на определенный момент времени. В частности, для обучения нужно знать, какой ранг занимает пост в одном тематическом подразделе (subreddit), однако здесь необходима обратные вызовы, что вряд ли будет поддерживать микросервис.
При полном отказе от микросервисов нарушится инкапсуляцию и чтение из дампов СУБД. Однако, теперь возможны обратные вызовы API и подключение датасетов непосредственно к Apache Spark или другому Big Data приложению пакетной или потоковой обработки. Можно объединять таблицы и удобнее работать с данными, создавая обучающие датасеты со такой скоростью, с какой Spark Streaming и MLLib могут обрабатывать их.
При этом стоит помнить, что ML-сервисы зависят от схемы необработанных данных, которые обучно хранятся в корпоративном озере (Data Lake) на базе Apache Hadoop. Но, как мы разбирали вчера, схемы данных меняются со временем, микросервисы выводятся из эксплуатации и заменяются новыми решениями, накапливаются несоответствия, ошибки и прочие проблемы. Кроме того, каждая команда ML-разработки должна поддерживать собственные data pipeline’ы, чтобы они не превратились в архаичный спагетти-код. На это уходит много времени и ресурсов.
Альтернативой является использование платформы потоковой обработки событий, такой как Apache Kafka, чтобы ML-команды подписывались на нужные потоки событий. В отличие от дампов Data Lake, потоки событий обычно содержат данные более высокого качества.
Но здесь появляется проблема холодного запуска, т.к. платформы потоковой передачи событий обычно редко предназначены для длительного хранения событий. Проблема холодного запуска проявляется при создании новой фичи с отслеживанием состояния, которая требует агрегации событий за определенный промежуток времени. Например, количество сообщений, опубликованных пользователем за последние 7 дней. В таких ситуациях создание обучающего датасета может занять несколько недель. А при том, что Feature-engineering – итеративный процесс, общее время разработки продукта растягивается еще больше.
Чтобы решить проблему микросервисной архитектуры в Machine Learning, многие data-driven компании независимо друг от друга пришли к одному и тому же выводу: AirBnB построил Zipline, Uber создал Michelangelo, а Lyft разработал Dryft. Сюда же можно отнести StreamSQL [2]. Все эти системы называются хранилищами фичей (Feature Store), которые предоставляют стандартизированный способ их определения. Feature Store обрабатывает создание обучающих данных и предоставляет фичи онлайн для различных сервисов, абстрагируя инжиниринг данных от рабочего ML-процесса. Под капотом Feature Store координирует несколько Big Data систем для беспрепятственной обработки событий, как недавно случившихся, так и исторических [1].
Источник: bigdataschool.ru
Как установить российский магазин приложений NashStore на Андроид
Отключение платежей в Google Play, удаление из каталога банковских клиентов и блокировка обновлений некоторых приложений заставили российский IT-сектор задуматься о разработке собственного магазина приложений — и лучше не одного. За его создание взялись сразу 4 компании: Сбер, VK, Яндекс и Цифровые платформы, принадлежащие Минцифры. Первым, как это ни удивительно, справилась государственная контора, которая 9 мая запустила NashStore для разработчиков, а сегодня — 16 мая — российский магазин приложений для Android стал доступен всем желающим. Разберёмся, насколько хорошим получился новый каталог и стоит ли вообще им пользоваться в текущих реалиях.

В России официально заработал NashStore — отечественный магазин приложений для Android
Начнём с того, что запуск НашСтор в обещанные сроки — это уже большое событие. На фоне других госорганов в Минцицры и правда сработали очень чётко. Допускаю, что им не оставили выбора, но нам-то с вами какая разница? Для нас главное — результате, и он уже есть, его можно потрогать и сделать собственные выводы.
Как установить NashStore
Пока НашСторе находится в стадии бета-тестирования, пусть и открытого. Скачать его может кто угодно, но на идеальную стабильность магазина приложений, к сожалению, рассчитывать не стоит. Забегая вперёд, скажу, что кое-какие проблемы в его работоспособности проявляются уже в самом начале. Например, каталог может тормозить, медленно загружать новые страницы и не реагировать на ваши действия. Впрочем, обо всём по порядку.
Вот как установить NashStore себе на смартфон:
- Перейдите на сайт проекта nashstore.ru и нажмите на АПК-файл каталога;
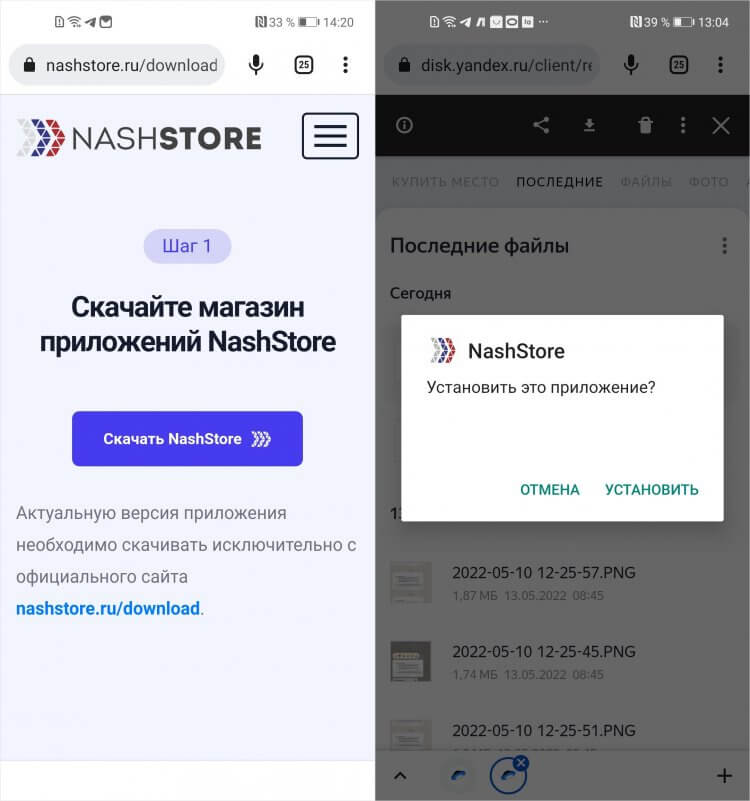
Если сайт NashStore не работает, скачивайте каталог с Яндекс.Диска напрямую
- Подтвердите его загрузку, запустите и зарегистрируйтесь;
- Выйдите из каталога и откройте «Настройки» Android;
- Отсюда перейдите в «Безопасность» — NashStore и разрешите установку приложений из неизвестных источников;
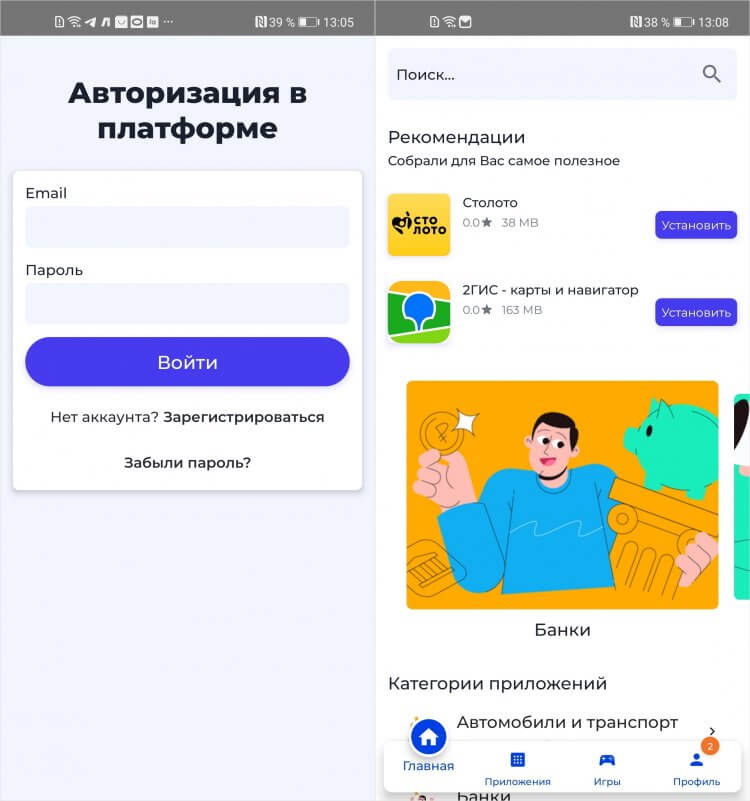
NashStore собирает слишком много данных уже на старте
- Вернитесь в Nash Store, выберите нужное приложение и нажмите «Установить».
❗️ЧАТИК ДЛЯ ИЗБРАННЫХ. ЗАЛЕТАЙ, ПОТОМ СПАСИБО СКАЖЕШЬ
Из-за большого наплыва посетителей на этапе установки Наш Стора могут наблюдаться кое-какие проблемы. Например, приложение может не скачиваться на смартфон напрямую. Мне помогла загрузка на компьютер с последующим перебрасыванием на мобилку. Заняло это пару лишних минут, но зато магазин встал на смартфон как родной. Попробуйте, если что-то пойдёт не так.
NashStore — регистрация, дизайн и установка приложений
Не понравилось, что на стадии регистрации NashStore требует, как по мне, слишком уж много данных. Тут и ФИО, и номер телефона, который нужно писать строго через +7, и адрес электронной почты — сразу виден казённый подход. Хорошо, хоть снилс не попросили, хотя, честно сказать, я бы не удивился. Но, шутки шутками, а с этим надо что-то делать. Так что, ребята, прекращайте.
Вам тут не МФЦ. С пользователями так нельзя.
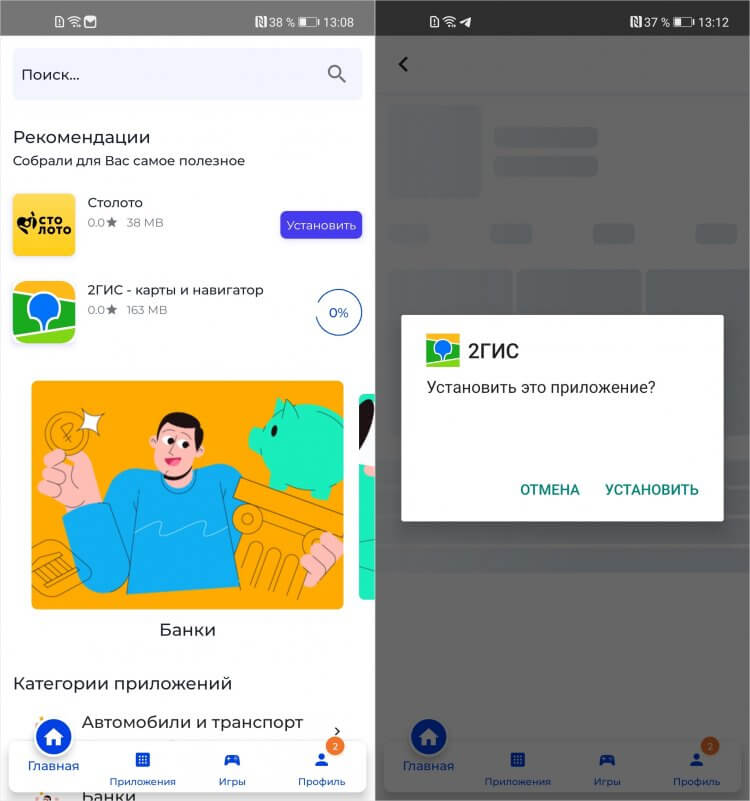
В установке приложений из NashStore есть ещё один этап — подтверждение установки уже после загрузки
Но в целом дизайн NashStore оформлен на удивление ненавязчиво. Я бы даже сказал, дружелюбно. Он не перегружен визуальными элементами, а его интерфейс оформлен с использованием только двух цветов — белого и синего. Белым окрашен фон, а синим подсвечены элементы управления, которые разбавляют цветные баннеры.
Нарисованы они, кстати, довольно интересно, но аккуратно — в NashStore нет той визуальной тяжести, как в Google Play. Это мне понравилось.
❗️ХОЧЕШЬ ПОКУПАТЬ ТОЛЬКО ЛУЧШИЕ ТОВАРЫ С Алиэкспресс? ТОГДА ТЕБЕ СЮДА. БЕЗ ВАРИАНТОВ
Интерфейс каталога поделён на 4 части:
- Главная (отсюда можно перейти в нужный раздел или посмотреть рекомендации);
- Приложения (здесь размещаются списки всех приложений, доступных для загрузки);
- Игры (их пока не так много, но кое-что уже можно скачать);
- Профиль (здесь можно изменить кое-какие настройки, а также обновить установленные приложения или связаться с разработчиками).
Не устанавливаются приложения на Андроид
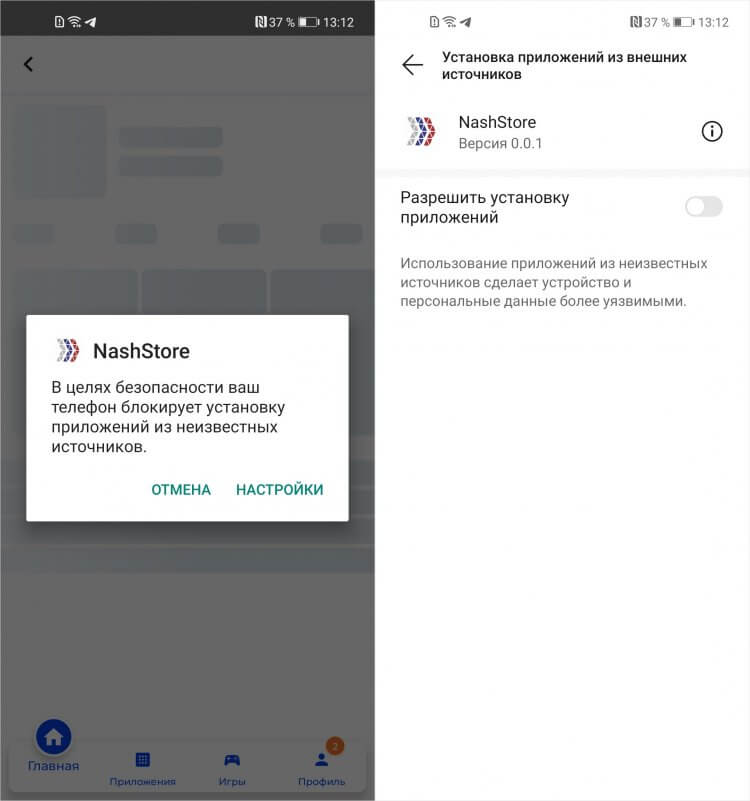
Приложение из NashStore не установится, если не разрешить установку софта из неизвестных источников
Установка приложений из NashStore выполняется не совсем так, как в Google Play. По завершении загрузки отечественный каталог спрашивает, действительно ли вы хотите установить скачанное приложение. Если нажать отмену, то установка не выполнится, а в памяти вашего устройства останется APK-файл, который был загружен из каталога. Это не раздражает, но явно не способствует тому, чтобы назвать использование NashStore совсем уж удобным.
Не забудьте разрешить NashStore установку приложений из неизвестных источников. Это ключевое условие, которое позволит вам скачивать софт из отечественного каталога. Если этого не сделать, загрузка застопорится, и вы ничего не скачаете. Возможно, в прошивке вашего смартфона соответствующий пункт будет располагаться где-то в другом месте, но вы всегда сможете найти его поиском по запросу «установка приложений».
Удалённые приложения из Play Market — где скачать
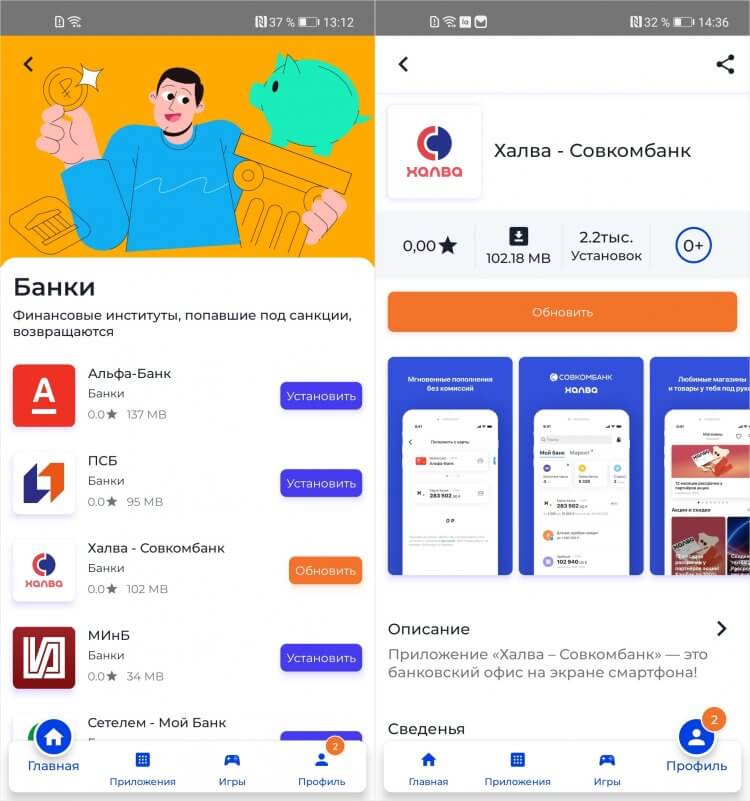
В NashStore есть отдельная вкладка для банковских приложений, попавших под санкции
Несмотря на то что неделю назад нам обещали, что на публикацию приложений в NashStore подали заявки более 3000 разработчиков, пока ассортимент каталога довольно скуден. Я не считал точное количество позиций, доступных для загрузки, но по ощущениям их точно не больше сотни. Однако многие популярные и востребованные среди российских пользователей приложения тут есть. Вот лишь некоторые из них:
- 2ГИС
- Столото
- Альфа-банк
- Совкомбанк (Халва)
- ПСБ
- Госуслуги
- Сбермаркет
Ещё есть приложение ВТБ Онлайн, но судя по приставке KZ в названии, оно относится к казахстанскому отделению банка, а к нашему не имеет никакого отношения. Это довольно странное решение — добавить клиент дочерней организации, но проигнорировать основной. Впрочем, высока вероятность, что вскоре это недоразумение будет исправлено.
Обновление приложений на Андроид
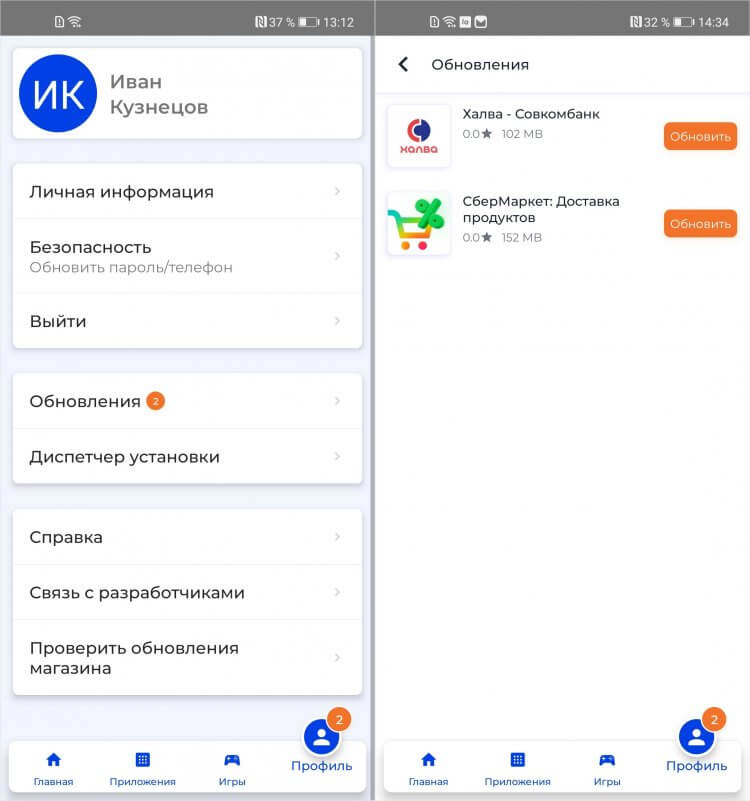
NashStore определяет уже установленные приложения, которые доступны в его ассортименте, и предлагает обновить их
Для банковских приложений сделали отдельный раздел, что удобно, и добавили подпись — финансовые институты, попавшие под санкции, возвращаются. Это очень уместное уточнение, потому что сейчас в NashStore по большей части доступны клиенты именно тех банков, которые больше недоступны для загрузки в Google Play и AppGallery.
Удобно, что NashStore сам определяет, какие приложения из доступных в каталоге, уже установлены на ваше устройство и предлагает обновить их при условии доступности новых версий. Это очень актуально для банковских клиентов, попавших под санкции, которые не обновлялись уже больше месяца. С NashStore вы сможете наконец установить новые версии без необходимости скачивать их с сайтов самих банков.
В целом, если забыть про то, что NashStore сильно лагает и зачастую не с первого раза реагирует на ваши действия, каталог мне понравился. Концептуально, не практически. Он ладно скроен, интуитивно понятен и нативно интегрирован в систему. Здесь пока нет платных приложений, как и самой возможности что-либо оплачивать.
Но я уверен, что в скором времени разработчики допилят свой магазин, и им можно будет реально пользоваться. Заменит ли он Google Play? Ну, в принципе такой задел у него есть. Особенно, если поисковый гигант отключит обновления. Но главное — исправить проблемы с быстродействием, потому что пока это тихий ужас.

Теги
- Google Play
- NashStore
- Новичкам в Android
Источник: androidinsider.ru