
FindMPI
Поиск реализации интерфейса передачи сообщений (MPI).
Интерфейс передачи сообщений (Message Passing Interface-MPI)представляет собой библиотеку,используемую для написания высокопроизводительных параллельных приложений с распределенной памятью,и обычно развертывается на кластере.MPI-это стандартный интерфейс (определяемый форумом MPI),для которого доступно множество реализаций.
Новое в версии 3.10:Значительная переработка модуля:множество новых переменных,компоненты для каждого языка,поддержка более широкого спектра систем исполнения.
Переменные для использования MPI
Модуль подвергает компоненты C , CXX , MPICXX и Fortran . Каждый из них управляет различными языками MPI для поиска. Разница между CXX и MPICXX является то , что CXX относится к API MPI — C будучи пригодными для использования C ++, тогда как MPICXX относится к MPI-2 C ++ API , который был удален снова в MPI-3.
В зависимости от включенных компонентов будут установлены следующие переменные:
Создание проекта VisualStudio с поддержкой MPI
Переменная, указывающая, что были найдены настройки MPI для всех запрошенных языков. Если компоненты не указаны, это верно, если были обнаружены настройки MPI для всех включенных языков. Обратите внимание, что компонент MPICXX не влияет на эту переменную.
Минимальная версия MPI обнаружена среди запрошенных языков,или все включенные языки,если ни один из компонентов не был указан.
Этот модуль устанавливает следующие переменные для каждого языка в вашем проекте, где — это одна из C, CXX или Fortran:
Была найдена переменная, указывающая настройки MPI для , и что простые тестовые программы MPI компилируются с предоставленными настройками.
MPI-компилятор для , если такая программа существует.
Опции компиляции для программ MPI в , заданные как ;-list .
Определения компиляции для программ MPI в , заданные как ;-list .
Включите путь(ы)для заголовка MPI.
Флаги компоновки для MPI-программ.
Все библиотеки для связи MPI программ с.
Новое в версии 3.9: Дополнительно определены следующие IMPORTED цели:
Цель для использования MPI из .
Будут определены следующие переменные,указывающие,какие из них присутствуют:
Переменная,указывающая на наличие креплений MPI-2 C++(введено в MPI-2,удалено с помощью MPI-3).
True, если доступен заголовок Fortran 77 mpif.h
Истинно, если для доступа к MPI можно использовать mpi модуля Fortran 90 (только MPI-2 и выше).
Истинно, если Fortran 2008 mpi_f08 доступен для программ MPI (только MPI-3 и выше).
По возможности,версия MPI будет определяться этим модулем.Средства определения версии MPI были введены в MPI-1.2,и поэтому не могут быть найдены для более старых версий MPI.
Основная версия MPI, реализованная для дистрибутивом MPI.
Незначительная версия MPI, реализованная для дистрибутивом MPI.
Версия MPI, реализованная для дистрибутивом MPI.
Обратите внимание, что нет переменной для привязок C, доступных через mpi.h , поскольку стандарты MPI всегда требовали, чтобы эта привязка работала как в коде C, так и в коде C ++.
Установка, настройка и запуск программ средствами MPI в Visual Studio 2019
Для запуска MPI-программ модуль устанавливает следующие переменные
Исполняется для запуска MPI-программ,если таковые существуют.
Флаг для передачи в mpiexec перед указанием количества процессоров для запуска.
Количество используемых MPI-процессоров.По умолчанию-количество процессоров,обнаруженных в хост-системе.
Флаги для передачи в mpiexec непосредственно перед запуском исполняемого файла.
Флаги для передачи в mpiexec после других флагов.
Переменные для определения местоположения MPI
Этот модуль выполняет четырехступенчатый поиск реализации MPI:
- Найдите MPIEXEC_EXECUTABLE и, если он найден, используйте его базовый каталог.
- Проверьте, имеет ли компилятор встроенную поддержку MPI. Это тот случай, если пользователь передал оболочку компилятора как CMAKE__COMPILER или если он использует оболочки системного компилятора Cray.
- Попробуйте найти обертку MPI-компилятора и определить по ней информацию о компиляторе.
- Попробуйте найти MPI реализацию,которая не поставляет такую обертку,угадав настройки.В настоящее время поддерживаются только Microsoft MPI и MPICH2 на Windows.
Для управления шагом MPIEXEC_EXECUTABLE могут быть установлены следующие переменные:
Вручную укажите расположение mpiexec .
Укажите базовый каталог установки MPI.
Переменная окружения для указания базового каталога установки MPI.
Переменная окружения для указания базового каталога установки MPI.
Для управления шагом обертки компилятора можно задать следующие переменные:
Найдите указанную обертку компилятора и используйте ее.
Флаги для передачи обертке MPI компилятора во время допроса.Некоторые обертки компилятора поддерживают линковку отладочных или трассировочных библиотек,если передан определенный флаг и эта переменная может быть использована для их получения.
Используется для инициализации MPI__COMPILER_FLAGS , если не указан флаг для конкретного языка. Пусто по умолчанию.
Суффикс, который добавляется ко всем именам, которые ищутся. Например, вы можете установить это значение в .mpich или .openmpi , чтобы предпочитать одно или другое в Debian и его производных.
Для управления шагом отгадывания можно установить следующую переменную:
Допустимые значения: MSMPI и MPICH2 . Если установлено, будет выполняться поиск только в указанной библиотеке. По умолчанию MSMPI будет предпочтительнее MPICH2 , если оба доступны. Это также устанавливает для MPI_SKIP_COMPILER_WRAPPER значение true , которое может быть переопределено.
Каждый из этапов поиска можно пропустить с помощью следующих управляющих переменных:
Если это так,модуль предполагает,что компилятор сам по себе не предоставляет реализацию MPI и пропускает этап 2.
Если верно,то обертка компилятора не будет искаться.
Если это правда,шаг догадки будет пропущен.
Кроме того,для изменения поведения поиска доступна следующая управляющая переменная:
Добавьте некоторые определения,которые отключат привязки MPI-2 C++.В настоящее время поддерживаются MPICH,Open MPI,Platform MPI и их производные,например MVAPICH или Intel MPI.
Если процедура поиска завершается с ошибкой для переменной MPI__WORKS , то параметры, обнаруженные или переданные модулю, не сработали, и даже простая программа тестирования MPI не скомпилировалась.
Если всех этих параметров было недостаточно для поиска правильной реализации MPI, пользователь может отключить весь процесс автоопределения, указав как список библиотек в MPI__LIBRARIES ,так и список включаемых каталогов в MPI__ADDITIONAL_INCLUDE_DIRS . Любая другая переменная может быть установлена в дополнение к этим двум. Затем модуль проверит настройки MPI и сохранит настройки в кеше.
Переменные кэша для MPI
Переменная MPI__INCLUDE_DIRS будет собрана из следующих переменных. Для C и CXX:
Расположение заголовка mpi.h на диске.
Расположение заголовка Fortran 77 mpif.h , если он существует.
Местонахождение mpi или mpi_f08 модулей, если таковые имеются.
Для всех языков дополнительно рассматриваются следующие переменные:
;-список путей , необходимых в дополнение к обычным включаемым каталогам.
Переменные пути для включаемых папок, на которые ссылается .
;-список < , которые будут добавлены к местам включения < .
Переменная MPI__LIBRARIES будет собрана из следующих переменных:
Расположение библиотеки с именем для использования с MPI.
; -список < lib_name , который будет добавлен во включаемые местоположения < .
Использование спиексека
При использовании MPIEXEC_EXECUTABLE для выполнения приложений MPI обычно следует использовать все флаги MPIEXEC_EXECUTABLE следующим образом:
$ $ $ $ EXECUTABLE $ ARGS
где EXECUTABLE — программа MPI, а ARGS — аргументы для передачи программе MPI.
Расширенные переменные для использования MPI
Модуль может выполнять некоторые расширенные детекции функций по конкретному запросу.
Важное примечание: Следующие проверки не могут быть выполнены без выполнения программы тестирования MPI. try_run() внимание на особенности поведения try_run () во время кросс-компиляции. Кроме того, запуск программы MPI может вызвать дополнительные проблемы, такие как уведомление брандмауэра в некоторых системах. Вы должны разрешить эти обнаружения, только если вам абсолютно необходима информация.
Если следующие переменные будут установлены в true,то будет выполнен соответствующий поиск:
Определите для всех доступных Фортрана привязок , что значения MPI_SUBARRAYS_SUPPORTED и MPI_ASYNC_PROTECTS_NONBLOCKING являются и сделать их значения доступны MPI_Fortran__SUBARRAYS и MPI_Fortran__ASYNCPROT , где является одним из F77_HEADER , F90_MODULE и F08_MODULE .
Для каждого языка найдите выход MPI_Get_library_version и сделайте его доступным как MPI__LIBRARY_VERSION_STRING . Эта информация обычно связана с компонентом времени выполнения реализации MPI и может отличаться в зависимости от . Обратите внимание, что возвращаемое значение полностью определяется реализацией. Эта информация может использоваться для идентификации поставщика MPI и, например, выбора правильного одного из множества сторонних двоичных файлов, который соответствует поставщику MPI.
Backward Compatibility
Утратил силу с версии 3.10.
Для обратной совместимости с более старыми версиями FindMPI эти переменные установлены:
MPI_COMPILER MPI_LIBRARY MPI_EXTRA_LIBRARY MPI_COMPILE_FLAGS MPI_INCLUDE_PATH MPI_LINK_FLAGS MPI_LIBRARIES
В новых проектах, пожалуйста, используйте MPI__XXX . Кроме того, следующие переменные устарели:
MPI__COMPILE_OPTIONS используйте MPI_ _COMPILE_OPTIONS и MPI__COMPILE_DEFINITIONS .
Для использования используйте MPI__INCLUDE_DIRS , а для указания папок используйте MPI__ADDITIONAL_INCLUDE_DIRS .
MPIEXEC_EXECUTABLE этого используйте MPIEXEC_EXECUTABLE .
Источник: runebook.dev
Лабораторная работа №1 Принципы работы mpi в операционной системе Windows
Цель работы: Получить представление о MPI-программах.
Получить навыки конфигурирования программы MPICH2.
Краткая теория
MPI (Message Passing Interface) — интерфейс обмена сообщениями (информацией) между одновременно работающими вычислительными процессами. Он широко используется для создания параллельных программ для вычислительных систем с распределённой памятью (кластеров).
MPICH — самая известная реализация MPI, созданная в Арагонской национальной лаборатории (США). Существуют версии этой библиотеки для всех популярных операционных систем. К тому же, она бесплатна. Перечисленные факторы делают MPICH идеальным вариантом для того, чтобы начать практическое освоение MPI.
В данной лабораторной работе речь пойдёт об MPICH2. Двойка в названии — это не версия программного обеспечения, а номер того стандарта MPI, который реализован в библиотеке. MPICH2 соответствует стандарту MPI 2.0, отсюда и название.
MPICH2 — это быстродействующая и широко портируемая реализация стандрта MPI (реализованы оба стандарта MPI-1 и MPI-2). Цели создания MPICH2 следующие:
- Предоставить реализацию MPI, которая эффективно поддерживает различные вычислительные и коммуникационные платформы, включая общедоступные кластеры (настольные системы, системы с общей памятью, многоядерные архитектуры), высокоскоростные сети (Ethernet 10 ГБит/с, InfiniBand, Myrinet, Quadrics) и эксклюзивные вычислительные системы (Blue Gene, Cray, SiCortex).
- Сделать возможными передовые исследования технологии MPI с помощью легко расширяемой модульной структуры для создания производных реализаций.
В нашем случае мы имеем кластер из 9 машин (вычислительных узлов), работающих под управлением Microsoft Windows. Для учебных целей можно запускать все вычислительные процессы и на одном компьютере. Если компьютер одноядерный, то, естественно, прироста быстродействия вы не получите, — только замедление.
В качестве среды разработки можно использовать Visual Studio 2005 .. 2008 или Dev C++. Для удобства изложения созданную вами программу, использующую MPI, и предназначенную для запуска на нескольких вычислительных узлах, будем называть MPI-программой.
Принципы работы mpich
Начнем изложение материала о программе MPICH2, с принципов её работы.
MPICH для Microsoft Windows состоит из следующих компонентов:
- Менеджер процессов smpd.exe, который представляет собой системную службу (сервисное приложение). Менеджер процессов ведёт список вычислительных узлов системы, и запускает на этих узлах MPI-программы, предоставляя им необходимую информацию для работы и обмена сообщениями.
- Заголовочные файлы (.h) и библиотеки стадии компиляции (.lib), необходимые для разработки MPI-программ.
- Библиотеки времени выполнения (.dll), необходимые для работы MPI-программ.
- Дополнительные утилиты (.exe), необходимые для настройки MPICH и запуска MPI-программ.
Все компоненты, кроме библиотек времени выполнения, устанавливаются по умолчанию в папку C:Program FilesMPICH2; dll-библиотеки устанавливаются в C:WindowsSystem32.
Менеджер процессов является основным компонентом, который должен быть установлен и настроен на всех компьютерах сети (библиотеки времени выполнения можно, в крайнем случае, копировать вместе с MPI-программой). Остальные файлы требуются для разработки MPI-программ и настройки некоторого «головного» компьютера, с которого будет производиться их запуск.
Менеджер работает в фоновом режиме и ждёт запросов к нему из сети со стороны «головного» менеджера процессов (по умолчанию используется сетевой порт 8676). Чтобы как-то обезопасить себя от хакеров и вирусов, менеджер требует пароль при обращении к нему. Когда один менеджер процессов обращается к другому менеджеру процессов, он передаёт ему свой пароль.
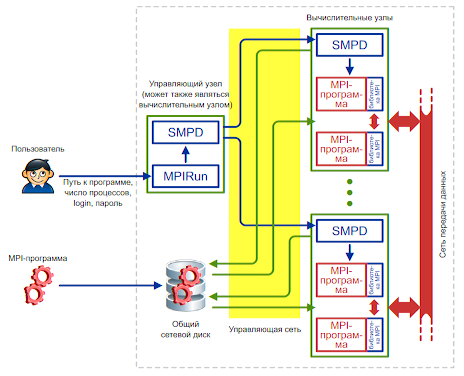
Рис. 1.1. Схема работы MPICH на кластере.
В современных кластерах «сеть передачи данных» обычно отделяется от «управляющей сети»
Запуск MPI-программы производится следующим образом
(смотрите рис. 1.1.):
- Пользователь с помощью программы Mpirun (или Mpiexec, при использовании MPICH2 под Microsoft Windows) указывает имя исполняемого файла MPI-программы и требуемое число процессов. Кроме того, можно указать имя пользователя и пароль: процессы MPI-программы будут запускаться от имени этого пользователя.
- Mpirun передаёт сведения о запуске локальному менеджеру процессов, у которого имеется список доступных вычислительных узлов.
- Менеджер процессов обращается к вычислительным узлам по списку, передавая запущенным на них менеджерам процессов указания по запуску MPI-программы.
- Менеджеры процессов запускают на вычислительных узлах несколько копий MPI-программы (возможно, по несколько копий на каждом узле), передавая программам необходимую информацию для связи друг с другом.
Очень важным моментом здесь является то, что перед запуском MPI-программа не копируется автоматически на вычислительные узлы кластера. Вместо этого менеджер процессов передаёт узлам путь к исполняемому файлу программы точно в том виде, в котором пользователь указал этот путь программе Mpirun. Это означает, что если, например, запустить программу C:proga.exe, то все менеджеры процессов на вычислительных узлах будут пытаться запустить файл C:proga.exe. Если хотя бы на одном из узлов такого файла не окажется, произойдёт ошибка запуска MPI-программы.
Чтобы каждый раз не копировать вручную программу и все необходимые для её работы файлы на вычислительные узлы кластера, обычно используют общий сетевой ресурс. В этом случае пользователь копирует программу и дополнительные файлы на сетевой ресурс, видимый всеми узлами кластера, и указывает путь к файлу программы на этом ресурсе. Дополнительным удобством такого подхода является то, что при наличии возможности записи на общий сетевой ресурс запущенные копии программы могут записывать туда результаты своей работы.
Работа MPI-программы происходит следующим образом:
- Программа запускается и инициализирует библиотеку времени выполнения MPICH путём вызова функции MPI_Init.
- Библиотека получает от менеджера процессов информацию о количестве и местоположении других процессов программы, и устанавливает с ними связь.
- После этого запущенные копии программы могут обмениваться друг с другом информацией посредством библиотеки MPICH. С точки зрения операционной системы библиотека является частью программы (работает в том же процессе), поэтому можно считать, что запущенные копии MPI-программы обмениваются данными напрямую друг с другом, как любые другие приложения, передающие данные по сети.
- Консольный ввод-вывод всех процессов MPI-программы перенаправляется на консоль, на которой запущена Mpirun. Перенаправлением ввода-вывода занимаются менеджеры процессов, так как именно они запустили копии MPI-программы, и поэтому могут получить доступ к потокам ввода-вывода программ.
- Перед завершением все процессы вызывают функцию MPI_Finalize, которая корректно завершает передачу и приём всех сообщений, и отключает MPICH.
Все описанные выше принципы действуют, даже если запустить
MPI-программу на одном компьютере.
Источник: studfile.net
Обмен данными с использованием MPI. Работа с библиотекой MPI на примере Intel® MPI Library

В этом посте мы расскажем об организации обмена данными с помощью MPI на примере библиотеки Intel MPI Library. Думаем, что эта информация будет интересна любому, кто хочет познакомиться с областью параллельных высокопроизводительных вычислений на практике.
Мы приведем краткое описание того, как организован обмен данными в параллельных приложениях на основе MPI, а также ссылки на внешние источники с более подробным описанием. В практической части вы найдете описание всех этапов разработки демонстрационного MPI-приложения «Hello World», начиная с настройки необходимого окружения и заканчивая запуском самой программы.
MPI (Message Passing Interface)
MPI — интерфейс передачи сообщений между процессами, выполняющими одну задачу. Он предназначен, в первую очередь, для систем с распределенной памятью (MPP) в отличие от, например, OpenMP. Распределенная (кластерная) система, как правило, представляет собой набор вычислительных узлов, соединенных высокопроизводительными каналами связи (например, InfiniBand).
MPI является наиболее распространенным стандартом интерфейса передачи данных в параллельном программировании. Стандартизацией MPI занимается MPI Forum. Существуют реализации MPI под большинство современных платформ, операционных систем и языков. MPI широко применяется при решении различных задач вычислительной физики, фармацевтики, материаловедения, генетики и других областей знаний.
Параллельная программа с точки зрения MPI — это набор процессов, запущенных на разных вычислительных узлах. Каждый процесс порождается на основе одного и того же программного кода.
Основная операция в MPI — это передача сообщений. В MPI реализованы практически все основные коммуникационные шаблоны: двухточечные (point-to-point), коллективные (collective) и односторонние (one-sided).
Работа с MPI
Рассмотрим на живом примере, как устроена типичная MPI-программа. В качестве демонстрационного приложения возьмем исходный код примера, поставляемого с библиотекой Intel MPI Library. Прежде чем запустить нашу первую MPI-программу, необходимо подготовить и настроить рабочую среду для экспериментов.
Настройка кластерного окружения
Для экспериментов нам понадобится пара вычислительный узлов (желательно со схожими характеристиками). Если под руками нет двух серверов, всегда можно воспользоваться cloud-сервисами.
Для демонстрации я выбрал сервис Amazon Elastic Compute Cloud (Amazon EC2). Новым пользователям Amazon предоставляет пробный год бесплатного использования серверами начального уровня.
Работа с Amazon EC2 интуитивно понятна. В случае возникновения вопросов, можно обратиться к подробной документации (на англ.). При желании можно использовать любой другой аналогичный сервис.
Создаем два рабочих виртуальных сервера. В консоли управления выбираем EC2 Virtual Servers in the Cloud, затем Launch Instance (под «Instance» подразумевается экземпляр виртуального сервера).
Следующим шагом выбираем операционную систему. Intel MPI Library поддерживает как Linux, так и Windows. Для первого знакомства с MPI выберем OC Linux. Выбираем Red Hat Enterprise Linux 6.6 64-bit или SLES11.3/12.0.
Выбираем Instance Type (тип сервера). Для экспериментов нам подойдет t2.micro (1 vCPUs, 2.5 GHz, Intel Xeon processor family, 1 GiB оперативной памяти). Как недавно зарегистрировавшемуся пользователю, мне такой тип можно было использовать бесплатно — пометка «Free tier eligible». Задаем Number of instances: 2 (количество виртуальных серверов).
После того, как сервис предложит нам запустить Launch Instances (настроенные виртуальные сервера), сохраняем SSH-ключи, которые понадобятся для связи с виртуальными серверами извне. Состояние виртуальных серверов и IP адреса для связи с серверами локального компьютера можно отслеживать в консоли управления.
Важный момент: в настройках Network
Настройка MPI библиотеки
Итак, рабочее окружение настроено. Время установить MPI.
В качестве демонстрационного варианта возьмем 30-дневную trial-версию Intel MPI Library (~300МБ). При желании можно использовать другие реализации MPI, например, MPICH. Последняя доступная версия Intel MPI Library на момент написания статьи 5.0.3.048, ее и возьмем для экспериментов.
Установим Intel MPI Library, следуя инструкциям встроенного инсталлятора (могут потребоваться привилегии суперпользователя).
$ tar xvfz l_mpi_p_5.0.3.048.tgz
$ cd l_mpi_p_5.0.3.048
$ ./install.sh
Выполним установку на каждом из хостов с идентичным установочным путем на обоих узлах. Более стандартным способом развертывания MPI является установка в сетевое хранилище, доступное на каждом из рабочих узлов, но описание настройки подобного хранилища выходит за рамки статьи, поэтому ограничимся более простым вариантом.
Для компиляции демонстрационной MPI-программы воспользуемся GNU C компилятором (gcc).
В стандартном наборе программ RHEL образа от Amazon его нет, поэтому необходимо его установить:
$ sudo yum install gcc
В качестве демонстрационной MPI-программы возьмем test.c из стандартного набора примеров Intel MPI Library (находится в папке intel/impi/5.0.3.048/test).
Для его компиляции первым шагом выставляем Intel MPI Library окружение:
$. /home/ec2-user/intel/impi/5.0.3.048/intel64/bin/mpivars.sh
Далее компилируем нашу тестовую программу с помощью скрипта из состава Intel MPI Library (все необходимые MPI зависимости при компиляции будут выставлены автоматически):
$ cd /home/ec2-user/intel/impi/5.0.3.048/test
$ mpicc -o test.exe ./test.c
Полученный test.exe копируем на второй узел:
$ scp test.exe ip-172-31-47-24:/home/ec2-user/intel/impi/5.0.3.048/test/
Прежде чем выполнять запуск MPI-программы, полезно будет сделать пробный запуск какой-нибудь стандартной Linux утилиты, например, ‘hostname’:
$ mpirun -ppn 1 -n 2 -hosts ip-172-31-47-25,ip-172-31-47-24 hostname
ip-172-31-47-25
ip-172-31-47-24
Утилита ‘mpirun’ — это программа из состава Intel MPI Library, предназначенная для запуска MPI-приложений. Это своего рода «запускальщик». Именно эта программа отвечает за запуск экземляра MPI-программы на каждом из узлов, перечисленных в ее аргументах.
Касательно опций, ‘-ppn’ — количество запускаемых процессов на каждый узел, ‘-n’ — общее число запускаемых процессов, ‘-hosts’ — список узлов, где будет запущено указанное приложение, последний аргумент — путь к исполняемому файлу (это может быть и приложение без MPI).
В нашем примере с запуском утилиты hostname мы должны получить ее вывод (название вычислительного узла) с обоих виртуальных серверов, тогда можно утверждать, что менеджер MPI-процессов работает корректно.
«Hello World» с использованием MPI
В качестве демонстрационного MPI-приложения мы взяли test.c из стандартного набора примеров Intel MPI Library.
Демонстрационное MPI-приложение cобирает с каждого из параллельно запущенных MPI-процессов некоторую информацию о процессе и вычислительном узле, на котором он запущен, и распечатывает эту информацию на головном узле.
Рассмотрим подробнее основные составляющие типичной MPI-программы.
#include «mpi.h»
Подключение заголовочного файла mpi.h, который содержит объявления основных MPI-функций и констант.
Если для компиляции нашего приложения мы используем специальные скрипты из состава Intel MPI Library (mpicc, mpiicc и т.д.), то путь до mpi.h прописывается автоматически. В противном случае, путь до папки include придется задать при компиляции.
MPI_Init (argv); . MPI_Finalize ();
Вызов MPI_Init() необходим для инициализации среды исполнения MPI-программы. После этого вызова можно использовать остальные MPI-функции.
Последним вызовом в MPI программе является MPI_Finalize(). В случае успешного завершения MPI-программы каждый из запущенных MPI-процессов делает вызов MPI_Finalize(), в котором осуществляется чистка внутренних MPI-ресурсов. Вызов любой MPI-функции после MPI_Finalize() недопустим.
Чтобы описать остальные части нашей MPI-программы необходимо рассмотреть основные термины используемые в MPI-программировании.
MPI-программа — это набор процессов, которые могут посылать друг другу сообщения посредством различных MPI-функций. Каждый процесс имеет специальный идентификатор — ранг (rank). Ранг процесса может использоваться в различных операциях посылки MPI-сообщений, например, ранг можно указать в качестве идентификатора получателя сообщения.
Кроме того в MPI существуют специальные объекты, называемые коммуникаторами (communicator), описывающие группы процессов. Каждый процесс в рамках одного коммуникатора имеет уникальный ранг. Один и тот же процесс может относиться к разным коммуникаторам и, соответственно, может иметь разные ранги в рамках разных коммуникаторов. Каждая операция пересылки данных в MPI должна выполняться в рамках какого-то коммуникатора. По умолчанию всегда создается коммуникатор MPI_COMM_WORLD, в который входят все имеющиеся процессы.
Вернемся к test.c:
MPI_Comm_size (MPI_COMM_WORLD, MPI_Comm_rank (MPI_COMM_WORLD,
MPI_Comm_size() вызов запишет в переменную size (размер) текущего MPI_COMM_WORLD коммуникатора (общее количество процессов, которое мы указали с mpirun опцией ‘-n’).
MPI_Comm_rank() запишет в переменную rank (ранг) текущего MPI-процесса в рамках коммуникатора MPI_COMM_WORLD.
MPI_Get_processor_name (name,
Вызов MPI_Get_processor_name() запишет в переменную name строковой идентификатор (название) вычислительного узла, на котором был запущен соответствующий процесс.
Собранная информация (ранг процесса, размерность MPI_COMM_WORLD, название процессора) далее посылается со всех ненулевых рангов на нулевой с помощью функции MPI_Send():
MPI_Send ( MPI_Send ( MPI_Send ( MPI_Send (name, namelen + 1, MPI_CHAR, 0, 1, MPI_COMM_WORLD);
MPI_Send() функция имеет следующий формат:
MPI_Send(buf, count, type, dest, tag, comm)
buf — адрес буфера памяти, в котором располагаются пересылаемые данные;
count — количество элементов данных в сообщении;
type — тип элементов данных пересылаемого сообщения;
dest — ранг процесса-получателя сообщения;
tag — специальный тег для идентификации сообщений;
comm — коммуникатор, в рамках которого выполняется посылка сообщения.
Более подробное описание функции MPI_Send() и ее аргументов, а также других MPI-функций можно найти в MPI-стандарте (язык документации — английский).
На нулевом ранге принимаются сообщения, посланные остальными рангами, и печатаются на экран:
printf («Hello world: rank %d of %d running on %sn», rank, size, name); for (i = 1; i
Для наглядности нулевой ранг дополнительно печатает свои данные наподобие тех, что он принял с удаленных рангов.
MPI_Recv() функция имеет следующий формат:
MPI_Recv(buf, count, type, source, tag, comm, status)
buf, count, type — буфер памяти для приема сообщения;
source — ранг процесса, от которого должен быть выполнен прием сообщения;
tag — тег принимаемого сообщения;
comm — коммуникатор, в рамках которого выполняется прием данных;
status — указатель на специальную MPI-структуру данных, которая содержит информацию о результате выполнения операции приема данных.
В данной статье мы не будем углубляться в тонкости работы функций MPI_Send()/MPI_Recv(). Описание различных типов MPI-операций и тонкостей их работы — тема отдельной статьи. Отметим только, что нулевой ранг в нашей программе будет принимать сообщения от других процессов строго в определенной последовательности, начиная с первого ранга и по нарастающей (это определяется полем source в функции MPI_Recv(), которое изменяется от 1 до size).
Описанные функции MPI_Send()/MPI_Recv() — это пример так называемых двухточечных (point-to-point) MPI-операций. В таких операциях один ранг обменивается сообщениями с другим в рамках определенного коммуникатора. Существуют также коллективные (collective) MPI-операции, в которых в обмене данными могут участвовать более двух рангов. Коллективные MPI-операции — это тема для отдельной (и, возможно, не одной) статьи.
В результате работы нашей демонстрационной MPI-программы мы получим:
$ mpirun -ppn 1 -n 2 -hosts ip-172-31-47-25,ip-172-31-47-24 /home/ec2-user/intel/impi/5.0.3.048/test/test.exe
Hello world: rank 0 of 2 running on ip-172-31-47-25
Hello world: rank 1 of 2 running on ip-172-31-47-24
Вас заинтересовало рассказанное в этом посте и вы хотели бы принять участие в развитии технологии MPI? Команда разработчиков Intel MPI Library (г.Нижний Новгород) в данный момент активно ищет инженеров-соратников. Дополнительную информацию можно посмотреть на официальном сайте компании Intel и на сайте BrainStorage.
И, напоследок, небольшой опрос по поводу возможных тем для будущих публикаций, посвященных высокопроизводительным вычислениям.
Источник: habr.com
Основные функции MPI и пример простейшей программы
Приветствую всех в третьей статье посвященной параллельному программированию с помощью библиотеки MPICH. В прошлых сериях мы научились устанавливать MPI в Linux Ubuntu и заставили Eclipse понимать код библиотеки. Наконец пришло время взяться за программирование. А какую программу должен написать каждый уважающий себя программист?
Правильно, сегодня мы напишем «Hello World» на MPI, и заодно глянем на самые базовые функции библиотеки. Поехали!
Основные функции MPI
Я сейчас говорю о тех, которые помогут нам грамотно идентифицировать каждый процесс, чтобы управлять общей логикой приложения. Реализовано это следующим образом: все процессы делятся на группы, называемые коммуникаторами, при этом один процесс может находиться сразу в нескольких коммуникаторах. По умолчанию все процессы попадают в коммуникатор MPI_COMM_WORLD . Каждый процесс имеет порядковый номер в коммуникаторе, называемый рангом. Как правило, процесс с рангом 0 назначается главным, он рулит бизнес логикой приложения и раздает команды другим процессам, еще он может отвечать за вывод в консоль, если вывод предусмотрен.
Но прежде чем начать рулить процессами, нужно их инициализировать с помощью функции MPI_Init(int *argc, char ***argv) , которая принимает аргументы командной строки и раздает их процессам. А после завершения грамотно оборвать все связи и убить процессы функцией MPI_Finalize() .
Перечень основных функций MPI
MPI_Initi(int *argc, char ***argv) — как уже было сказано, инициализирует все процессы и раздает им аргументы командной строки. По умолчанию, все вновь созданные процессы принадлежат стандартному коммуникатору MPI_COMM_WORLD ;
MPI_Finalize() — обрывает связи и убивает процессы;
MPI_Comm_size(MPI_Comm comm, int* size) — Функция запишет в переменную size количество процессов в коммуникаторе comm. Для того, чтобы узнать общее число процессов следует первым аргументом передать стандартный коммуникатор MPI_COMM_WORLD;
MPI_Comm_rank(MPI_Comm comm, int* rank) — Функция запишет в переменную rank ранг процесса в коммуникаторе comm. Это и есть способ идентифицировать процесс для того, чтобы отдать ему какую либо логику. Разделение полномочий между процессами осуществляется с помощью условных конструкций, например, if (rank == 0) < … >или switch(rank) < … >.
Простейшая программа с использованием библиотеки MPI
Этих функций нам уже вполне достаточно для того, чтобы написать «Hello World» на MPI. Пусть каждый процесс поздоровается с миром от своего имени, а главный, нулевой процесс в свою очередь расскажет миру о том, сколько процессов у него в подчинении(считая себя, конечно же, контроль над собой терять нельзя).
#include «mpi.h» int main(int argc, char **argv) < int rank, size; MPI_Init(argv); //Количество процессов в этом коммуникаторе MPI_Comm_size(MPI_COMM_WORLD, //Ранг процесса MPI_Comm_rank(MPI_COMM_WORLD, if(rank == 0) < printf(«Hello world, Im main process! There are %d processes in my comm.n», size); > else < printf(«Hello world! Im %d process in comm.n», rank); > MPI_Finalize(); return 0; >
Заключение
Нехитрое дело сделано, в следующей серии будет обмен сообщениями между процессами и какое нибудь задание поинтереснее, но начинать всегда нужно с «Hello world»! А на сегодня у меня все, спасибо за внимание!
Подписывайтесь на рассылку чтобы не пропустить продолжение.
Источник: mindhalls.ru
Основные функции MPI
Наиболее распространенной технологией программирования для параллельных систем с распределенной памятью в настоящее время является MPI (Message Passing Interface). Основным способом взаимодействия параллельных процессов друг с другом в таких системах является передача сообщений (Message Passing). По сути MPI – это библиотека и среда исполнения для параллельных программ на языках C или Fortran. В данном пособии будут описаны примеры программ на языке С.
Изначально MPI позволяет использовать модель программирования MIMD (Multiple Instruction Multiple Data) – много потоков инструкций и данных, т.е. объединение различных программ с различными данными. Но программирование для такой модели на практике оказывается слишком сложным, поэтому обычно используется модель SIMD (Single Program Multiple Data) –одна программа и много потоков данных. Здесь параллельная программа пишется так, чтобы разные ее части могли одновременно выполнять свою часть задачи, таким образом, достигается параллелизм. Поскольку все функции MPI содержаться в библиотеке, то при компиляции параллельной программы необходимо будет прилинковать соответствующие модули.
Под параллельной программой в рамках MPI понимается множество одновременно выполняемых процессов. Процессы могут выполняться на разных процессорах, но на одном процессоре могут располагаться и несколько процессов (в этом случае их исполнение осуществляется в режиме разделения времени). При запуске MPI – программы на кластере на каждом из его узлов будет выполняться своя копия программы, выполняющая свою часть задачи, из этого следует, что параллельная программа – это множество взаимодействующих процессов, каждый из которых работает в своем адресном пространстве. В предельном случае для выполнения параллельной программы может использоваться один процессор — как правило, такой способ применяется для начальной проверки правильности параллельной программы.
Количество процессов и число используемых процессоров определяется в момент запуска параллельной программы средствами среды исполнения MPI — программ и в ходе вычислений меняться не может. Все процессы программы последовательно перенумерованы от 0 до np-1, где np есть общее количество процессов. Номер процесса называется рангом процесса.
Взаимодействуют параллельные процессы между собой при помощи посылки сообщений. Методы посылки (их называют коммуникации) бывают двух видов – коллективные(collective) и “точка-точка” (point-to-point).
При коллективных коммуникациях процесс посылает нужную информацию одновременно целой группе процессов, еще есть более общий случай, когда внутри группы процессов передача информации идет от каждого процесса к каждому. Более простыми коммуникациями являются коммуникации типа ”точка-точка”, когда один процесс посылает информацию второму или они оба обмениваются информацией.
Функции коммуникаций – основные функции библиотеки MPI. Кроме этого, обязательными функциями являются функции инициализации и завершения MPI – MPI_Init и MPI_Finalize. MPI_Init должна вызываться в самом начале программ, а MPI_Finalize – в самом конце. Все остальные функции MPI должны вызываться между этими двумя функциями.
Как процесс узнает о том, какую часть вычислений он должен выполнять? Каждый процесс, исполняющийся на кластере, имеет свой уникальный номер – ранг. Когда процесс узнает свой ранг и общее количество процессов, он может определить свою часть работы. Для этого в MPI существуют специальные функции – MPI_Comm_rank и MPI_Comm_size. MPI_Comm_rank возвращает целое число — ранг процесса, вызвавшего ее, а MPI_Comm_size возвращает общее число работающих процессов.
Процессы отлаживаемой параллельной программы пользователя объединяются в группы. Под коммуникатором в MPI понимается специально создаваемый служебный объект, объединяющий в своем составе группу процессов и ряд дополнительных параметров (контекст), используемых при выполнении операций передачи данных.
Коммуникатор, автоматически создаваемый при запуске программы и включающий в себя все процессы на кластере, называется MPI_COMM_WORLD. В ходе вычислений могут создаваться новые и удаляться существующие группы процессов и коммуникаторы. Один и тот же процесс может принадлежать разным группам и коммуникаторам. Коллективные операции применяются одновременно для всех процессов коммуникатора, поэтому для них одним из параметров всегда будет выступать коммуникатор.
При выполнении операций передачи сообщений в функциях MPI необходимо указывать тип пересылаемых данных. MPI содержит большой набор базовых типов данных, основанных на стандартных типах данных языка С. Кроме того, программист может конструировать свои типы данных при помощи специальных функций MPI. Ниже приведена таблица соответствия для базовых типов данных.
| Константы MPI | ТИП данных языка С |
| MPI_INT | signed int |
| MPI_UNSIGNED | unsigned int |
| MPI_SHORT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_SHORT | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_CHAR | signed char |
Пример запуска библиотеки MPI: логин student, пароль s304.
int main (int argc, char *argv[])
/* получение ранга процесса */
Источник: poznayka.org