
Статические методы анализа основаны на исследовании исходного текста программ. Основная идея таких методов заключается в построении по индексным выражениям в операторах, обращающихся к массивам, систем уравнений и неравенств с неизвестными, соответствующими индексным переменным циклов. Например, для следующего фрагмента программы:
на основе использование одного и того же массива «а» может быть получено уравнение
Решение данного уравнения покажет наличие зависимости между соседними итерациями цикла: каждая следующая итерация использует значение, вычисленное на предыдущей итерации.
Существуют различные методы статического анализа зависимостей, различающиеся методами построения системы (возможно, неявно) по тексту программы и ее решения. В спорных ситуациях, когда метод не может доказать наличие или отсутствие зависимости, предполагается наличие зависимости. Это консервативное предположение гарантирует генерацию корректной параллельной программы, но связано с потерей эффективности из-за недостаточного использования параллелизма, в случае, если реальной зависимости в программе нет.
013. Статический анализ кода – Кошелев Артём
По своей природе статические методы анализа обладают рядом ограничений. Одно из основных связано с тем, что при анализе текста программы никогда не известны значения переменных, используемых в программе. В особенности это относится к входным данным, получаемым программой из внешних источников. В случае, если такие переменные используются в индексных выражениях при обращениях к массивам или в граничных значениях циклов, статические методы анализа не смогут сделать какие-либо выводы и будут вынуждены предположить наличие зависимости. В ряде случаев эта проблема может быть решена с помощью подсказок со стороны разработчика исходной программы, указывающих возможные значения некоторых переменных.
Помимо этого, большинство статических методов способны анализировать только линейные относительно переменных циклов индексные выражения. Это ограничение не является слишком сильным ограничением, поскольку зачастую используются именно линейные индексные выражения. Однако это препятствует проведению анализа в таких важных случаях, как косвенная индексация, а также вызовы функций в индексных выражениях.
В языках, подобных Си, у статических методов появляется еще одна проблема: интенсивное использование указателей. Как правило, статические методы анализа не могут работать с указателями, равно как и с весьма сложными выражениями, являющимися в языке нормой. Можно обязать программиста писать программы без использования соответствующих конструкций языка, но такие ограничения не применимы при распараллеливании библиотек, оптимизированных для выполнения на однопроцессорной машине.
Таким образом, статические методы анализа работают только с текстом программы и из-за этого имеют ряд ограничений, способных воспрепятствовать обнаружению параллелизма в программе. Тем не менее, этот тип методов анализа широко применяется в существующих системах автоматизации распараллеливания.
Защита программ и данных: лекция 5 «Статический метод анализа программ»
1.4 Динамический анализ
Динамический анализ программ основан на вставке в исходную программу дополнительных операторов, проводящих анализ. Полученная программа выполняется на некотором тестовом наборе входных данных (или нескольких наборах), и во время выполнения собирается информация о фактических зависимостях, присутствующих в программе на данном конкретном наборе данных.
Такой подход позволяет производить выявление зависимостей во многих ситуациях, когда статический анализ невозможен. Поскольку анализ происходит во время выполнения программы, анализатору доступны значения всех переменных, присутствующих в программе. Поэтому появляется возможность проанализировать любые ссылки на элементы массивов: через индексные выражения любой сложности, включая вызовы функций, через указатели. Динамический анализатор всегда может однозначно установить ячейку памяти, которая используется в любом операторе программы.
Недостатки динамического анализа также следуют из того, что он производится во время выполнения. Динамический анализ показывает только те зависимости, которые возникают на данном конкретном запуске программы. Поэтому, используя динамический анализ, никогда нельзя быть уверенным, что найдены все зависимости в программе.
Некоторые зависимости могут не проявиться на тестовых данных. Это может привести к генерации некорректной параллельной программы. Поэтому важной задачей становится составление хорошего набора тестов, достаточно полно покрывающего возможные поведения программы.
1.5 Распараллеливание во время выполнения
В некоторых случаях невозможно заранее сказать, будет ли некоторый цикл в программе параллельным (например, это зависит от входных данных). Как правило, в такой ситуации распараллеливание считается невозможным. Но иногда удается сформулировать достаточно простое условие, при котором вероятные зависимости по данным исчезают. Тогда применяется следующее решение: в параллельную программу включается два варианта данного фрагмента программы: один параллельный, другой последовательный. Во время выполнения программы проверяется выполнение условия, и в зависимости от результата выполняется либо один фрагмент, либо другой.
Аналогично работает схема inspector-executor. Спорный цикл выполняется 2 раза. Первый раз – для выяснения, является ли цикл параллельным. При этом никаких вычислений не производится. Второй раз – уже реальное выполнение вычислений с учетом результата первого прохода.
Дополнительный плюс такой схемы состоит в том, что, когда один и тот же цикл выполняется много раз, а его основные параметры остаются одними и теми же, инспекционный проход можно делать только один раз, используя полученный результат при каждом новом выполнении цикла.
Таким образом, вынесение некоторых проверок с этапа анализа на этап выполнения программы позволяет смягчить ограничения методов, рассмотренных выше.
Данная работа посвящена методам динамического анализа. Ставится цель создать рабочую реализацию динамического анализатора – библиотеки, собирающей информацию о зависимостях по данным в исходной программе. В будущем этот анализатор может стать частью системы автоматизации распараллеливания программ для систем с общей памятью.
Источник: kazedu.com
О статическом анализе начистоту
Последнее время все чаще говорят о статическом анализе как одном из важных средств обеспечения качества разрабатываемых программных продуктов, особенно с точки зрения безопасности. Статический анализ позволяет находить уязвимости и другие ошибки, его можно использовать в процессе разработки, интегрируя в настроенные процессы.
Однако в связи с его применением возникает много вопросов. Чем отличаются платные и бесплатные инструменты? Почему недостаточно использовать линтер? В конце концов, при чем тут статистика? Попробуем разобраться.

Сразу ответим на последний вопрос – статистика ни при чем, хотя статический анализ часто по ошибке называют статистическим. Анализ статический, так как при сканировании не происходит запуск приложения.
Для начала разберемся, что мы хотим искать в программном коде. Статический анализ чаще всего применяют для поиска уязвимостей – участков кода, наличие которых может привести к нарушению конфиденциальности, целостности или доступности информационной системы. Однако те же технологии можно применять для поиска и других ошибок или особенностей кода.
Оговоримся, что в общем виде задача статического анализа алгоритмически неразрешима (например, по теореме Райса). Поэтому приходится либо ограничивать условия задачи, либо допускать неточность в результатах (пропускать уязвимости, давать ложные срабатывания). Оказывается, что на реальных программах рабочим оказывается второй вариант.
Существует множество платных и бесплатных инструментов, которые заявляют поиск уязвимостей в приложениях, написанных на разных языках программирования. Рассмотрим, как обычно устроен статический анализатор. Дальше речь пойдет именно о ядре анализатора, об алгоритмах. Конечно, инструменты могут отличаться по дружелюбности интерфейса, по набору функциональности, по набору плагинов к разным системам и удобству использования API. Наверное, это тема для отдельной статьи.
Промежуточное представление
В схеме работы статического анализатора можно выделить три основных шага.
- Построение промежуточного представления (промежуточное представление также называют внутренним представлением или моделью кода).
- Применение алгоритмов статического анализа, в результате работы которых модель кода дополняется новой информацией.
- Применение правил поиска уязвимостей к дополненной модели кода.
В разных статических анализаторах могут использоваться разные модели кода, например, исходный текст программы, поток лексем, дерево разбора, трехадресный код, граф потока управления, байткод — стандартный или собственный — и так далее.

Аналогично компиляторам, лексический и синтаксический анализ применяются для построения внутреннего представления, чаще всего — дерева разбора (AST, Abstract Syntax Tree). Лексический анализ разбивает текст программы на минимальные смысловые элементы, на выходе получая поток лексем. Синтаксический анализ проверяет, что поток лексем соответствует грамматике языка программирования, то есть полученный поток лексем является верным с точки зрения языка. В результате синтаксического анализа происходит построение дерева разбора – структуры, которая моделирует исходный текст программы. Далее применяется семантический анализ, он проверяет выполнение более сложных условий, например, соответствие типов данных в инструкциях присваивания.
Дерево разбора можно использовать как внутреннее представление. Также из дерева разбора можно получить другие модели. Например, можно перевести его в трехадресный код, по которому, в свою очередь, строится граф потока управления (CFG). Обычно CFG является основной моделью для алгоритмов статического анализа.

При бинарном анализе (статическом анализе двоичного или исполняемого кода) также строится модель, но здесь уже используются практики обратной разработки: декомпиляции, деобфускации, обратной трансляции. В результате можно получить те же модели, что и из исходного кода, в том числе и исходный код (с помощью полной декомпиляции). Иногда сам бинарный код может служить промежуточным представлением.
Теоретически, чем ближе модель к исходному коду, тем хуже будет качество анализа. На самом исходном коде можно делать разве что поиск по регулярным выражениям, что не позволит найти хоть сколько-нибудь сложную уязвимость.
Анализ потока данных
Одним из основных алгоритмов статического анализа является анализ потока данных. Задача такого анализа — определить в каждой точке программы некоторую информацию о данных, которыми оперирует код. Информация может быть разная, например, тип данных или значение. В зависимости от того, какую информацию нужно определить, можно сформулировать задачу анализа потока данных.

Например, если необходимо определить, является ли выражение константой, а также значение этой константы, то решается задача распространения констант (constant propagation). Если необходимо определить тип переменной, то можно говорить о задаче распространения типов (type propagation). Если необходимо понять, какие переменные могут указывать на определенную область памяти (хранить одни и те же данные), то речь идет о задаче анализа синонимов (alias analysis). Существует множество других задач анализа потока данных, которые могут использоваться в статическом анализаторе. Как и этапы построения модели кода, данные задачи также используются в компиляторах.
В теории построения компиляторов описаны решения задачи внутрипроцедурного анализа потока данных (отследить данные необходимо в рамках одной процедуры/функции/метода). Решения опираются на теорию алгебраических решеток и другие элементы математических теорий. Решить задачу анализа потока данных можно за полиномиальное время, то есть за приемлемое для вычислительных машин время, если условия задачи удовлетворяют условиям теоремы о разрешимости, что на практике происходит далеко не всегда.
Расскажем подробнее про решение задачи внутрипроцедурного анализа потока данных. Для постановки конкретной задачи, помимо определения искомой информации, нужно определить правила изменения этой информации при прохождении данных по инструкциям в CFG. Напомним, что узлами в CFG являются базовые блоки – наборы инструкций, выполнение которых происходит всегда последовательно, а дугами обозначается возможная передача управления между базовыми блоками.
Для каждой инструкции определяются множества:
- (информация, порождаемая инструкцией ),
- (информация, уничтожаемая инструкцией ),
- (информация в точке перед инструкцией ),
- (информация в точке после инструкции ).
Целью анализа потока данных является определение множеств и для каждой инструкции программы. Основная система уравнений, с помощью которой решаются задачи анализа потока данных, определяется следующим соотношением (уравнения потока данных):
Второе соотношение формулирует правила, по которым информация «объединяется» в точках слияния дуг CFG ( – предшественники в CFG). Может использоваться операция объединения, пересечения и некоторые другие.
Искомая информация (множество значений введенных выше функций) формализуется как алгебраическая решетка. Функции и рассматриваются как монотонные отображения на решётках (функции потока). Для уравнений потока данных решением является неподвижная точка этих отображений.
Алгоритмы решения задач анализа потока данных ищут максимальные неподвижные точки. Существует несколько подходов к решению: итеративные алгоритмы, анализ сильно связных компонент, T1-T2 анализ, интервальный анализ, структурный анализ и так далее. Существуют теоремы о корректности указанных алгоритмов, они определяют область их применимости на реальных задачах. Повторюсь, условия теорем могут не выполняться, что приводит к усложнению алгоритмов и неточности результатов.
Межпроцедурный анализ
На практике необходимо решать задачи межпроцедурного анализа потока данных, так как редко уязвимость будет полностью локализовываться в одной функции. Существует несколько общих алгоритмов.
Встраивание (inline) функций. В точке вызова функции мы осуществляем встраивание вызываемой функции, тем самым сводим задачу межпроцедурного анализа к задаче внутрипроцедурного анализа. Такой метод легко реализуем, однако на практике при его применении быстро достигается комбинаторный взрыв.
Построение общего графа потока управления программы, в котором вызовы функций заменены на переходы по адресу начала вызываемой функции, а инструкции возврата заменены на переходы на все инструкции, следующие после всех инструкций вызова данной функции. Такой подход добавляет большое количество нереализуемых путей выполнения, что сильно уменьшает точность анализа.
Алгоритм, аналогичный предыдущему, но при переходе на функцию происходит сохранение контекста – например, стекового фрейма. Таким образом решается проблема создания нереализуемых путей. Однако алгоритм применим при ограниченной глубине вызовов.
Построение информации о функциях (function summary). Наиболее применимый алгоритм межпроцедурного анализа. Он основан на построении summary для каждой функции: правил, по которым преобразуется информация о данных при применении данной функции в зависимости от различных значений входных аргументов. Готовые summary используются при внутрипроцедурном анализе функций.
Отдельной сложностью здесь является определение порядка обхода функций, так как при внутрипроцедурном анализе для всех вызываемых функций уже должны быть построены summary. Обычно создаются специальные итеративные алгоритмы обхода графа вызовов (call graph).
Межпроцедурный анализ потока данных является экспоненциальной по сложности задачей, из-за чего анализатору необходимо проводить ряд оптимизаций и допущений (невозможно найти точное решение за адекватное для вычислительных мощностей время). Обычно при разработке анализатора необходимо искать компромисс между объемом потребляемых ресурсов, временем анализа, количеством ложных срабатываний и найденных уязвимостей. Поэтому статический анализатор может долго работать, потреблять много ресурсов и давать ложные срабатывания. Однако без этого невозможно находить важнейшие уязвимости.
Именно в этом моменте серьезные статические анализаторы отличаются от множества открытых инструментов, которые, в том числе, могут себя позиционировать в поиске уязвимостей. Быстрые проверки за линейное время хороши, когда результат нужно получить оперативно, например, в процессе компиляции. Однако таким подходом нельзя найти наиболее критичные уязвимости – например, связанные с внедрением данных.
Taint-анализ
Отдельно стоит остановиться на одной из задач анализа потока данных — taint-анализе. Taint-анализ позволяет распространить по программе флаги. Данная задача является ключевой для информационной безопасности, так как именно с помощью нее обнаруживаются уязвимости, связанные с внедрением данных (внедрения в SQL, межсайтовый скриптинг, открытые перенаправления, подделка файлового пути и так далее), а также с утечкой конфиденциальных данных (запись пароля в журналы событий, небезопасная передача данных).
Попробуем смоделировать задачу. Пусть мы хотим отследить n флагов – . Множеством информации здесь будет множество подмножеств , так как для каждой переменной в каждой точке программы мы хотим определить ее флаги.
- Задано множество правил, в которых определены конструкции, приводящие к появлению или изменению набора флагов.
- Операция присваивания перебрасывает флаги из правой части в левую.
- Любая неизвестная для множеств правил операция объединяет флаги со всех операндов и итоговое множество флагов добавляется к результатам операции.
Наконец, нужно определить правила слияния информации в точках соединения дуг CFG. Слияние определяется по правилу объединения, то есть если из разных базовых блоков пришли разные наборы флагов для одной переменной, то при слиянии они объединяются. В том числе отсюда появляются ложные срабатывания: алгоритм не гарантирует, что путь в CFG, на котором появился флаг, может быть исполнен.
Например, необходимо обнаруживать уязвимости типа «Внедрение в SQL» (SQL Injection). Такая уязвимость возникает, когда непроверенные данные от пользователя попадают в методы работы с базой данных. Необходимо определить, что данные поступили от пользователя, и добавить таким данным флаг taint. Обычно в базе правил анализатора задаются правила постановки флага taint. Например, поставить флаг возвращаемому значению метода getParameter() класса Request.
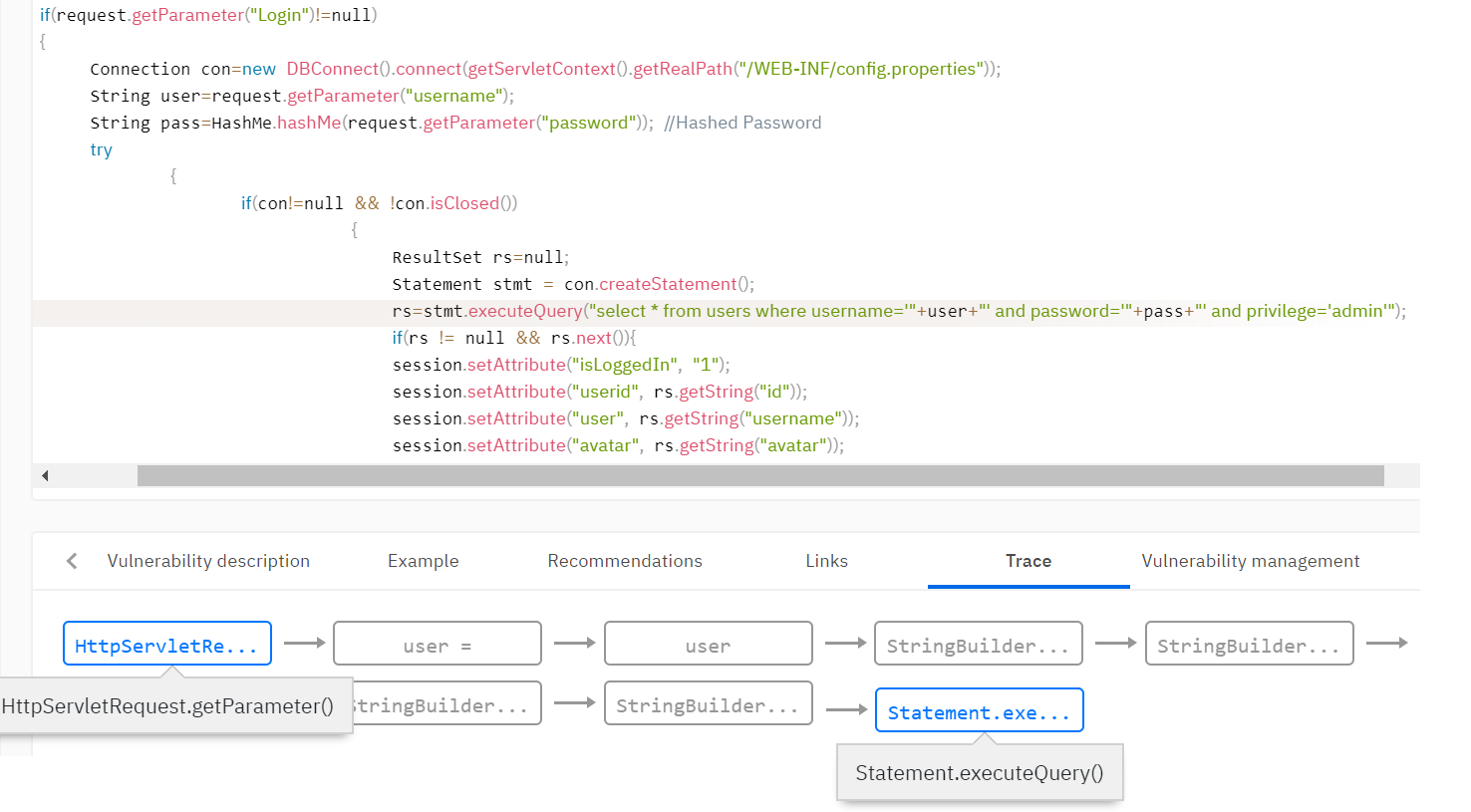
Далее необходимо распространить флаг по всей анализируемой программе с помощью taint-анализа, учитывая, что данные могут быть валидированы и флаг может исчезнуть на одном из путей исполнения. В анализаторе задается множество функций, которые снимают флаги. Например, функция валидации данных от html-тегов может снимать флаг для уязвимости типа «Межсайтовый скриптинг» (XSS). Или функция привязки переменной к SQL-выражению снимает флаг о внедрении в SQL.
Правила поиска уязвимостей
В результате применения указанных выше алгоритмов промежуточное представление дополняется информацией, необходимой для поиска уязвимостей. Например, в модели кода появляется информация о том, каким переменным принадлежат определенные флаги, какие данные являются константными. Правила поиска уязвимостей формулируются в терминах модели кода. Правила описывают, какие признаки в итоговом промежуточном представлении могут говорить о наличии уязвимости.
Например, можно применить правило поиска уязвимости, которое будет определять вызов метода с параметром, у которого есть флаг taint. Возвращаясь к примеру SQL-инъекции, мы проверим, что переменные с флагом taint не попадают в функции запроса к базе данных.
Получается, важной частью статического анализатора, помимо качества алгоритмов, является конфигурация и база правил: описание, какие конструкции в коде порождают флаги или другую информацию, какие конструкции валидируют такие данные, и для каких конструкций критично использование таких данных.
Другие подходы
Помимо анализа потока данных существуют и другие подходы. Одним из известных является символьное выполнение или абстрактная интерпретация. В этих подходах происходит выполнение программы на абстрактных доменах, вычисление и распространение ограничений по данным в программе. С помощью такого подхода можно не просто находить уязвимость, но и вычислить условия на входные данные, при которых уязвимость является эксплуатируемой. Однако у такого подхода есть и серьезные минусы – при стандартных решениях на реальных программах алгоритмы экспоненциально взрываются, а оптимизации приводят к серьезным потерям в качестве анализа.
Выводы
Под конец, думаю, стоит подвести итог, сказав о плюсах и минусах статического анализа. Логично, что сравнивать будем с динамическим анализом, в котором поиск уязвимостей происходит при выполнении программы.

Безусловным преимуществом статического анализа является полное покрытие анализируемого кода. Также к плюсам статического анализа можно отнести то, что для его запуска нет необходимости выполнять приложение в боевой среде. Статический анализ можно внедрять на самых ранних стадиях разработки, минимизируя стоимость найденных уязвимостей.
Минусами статического анализа является неизбежное наличие ложных срабатываний, потребление ресурсов и длительное время сканирований на больших объемах кода. Однако, эти минусы неизбежны, исходя из специфики алгоритмов. Как мы увидели, быстрый анализатор никогда не найдет реальную уязвимость типа SQL-инъекции и подобных.
Об остальных сложностях использования инструментов статического анализа, которые, как оказывается, вполне можно преодолевать, мы писали в другой статье .
Вы подозреваете, что за вами кто-то СЛЕДИТ? Присоединяйтесь к нашему ТГ каналу и научитесь контролировать свои цифровые следы.
Источник: www.securitylab.ru
Применение статического анализа при разработке программ
Статический анализ — это способ проверки исходного кода программы на корректность. Процесс статического анализа состоит из трех этапов. Сначала анализируемый код разбивается на лексемы — константы, идентификаторы, и т. д. Эта операция выполняется лексером. Затем лексемы передаются синтаксическому анализатору, который выстраивает по этим лексемам дерево кода.
Наконец, проводится статический анализ построенного дерева. В данной обзорной статье приведено описание трех методов статического анализа: анализ с обходом дерева кода, анализ потока данных и анализ потока данных с выбором путей.
Введение
Тестирование является важной частью процесса разработки приложений. Существует множество различных видов тестирования, в том числе и два вида, касающиеся программного кода: статический анализ и динамический анализ.
Динамический анализ проводится над исполняемым кодом скомпилированной программы. При этом проверяется только поведение, зависящее от пользователя, т.е. только тот код, который выполняется во время теста. Динамический анализатор может находить утечки памяти, измерять производительность программы, получать стек вызовов и т. п.
Статический анализ позволяет проверять исходный код программы до ее выполнения. В частности, любой компилятор проводит статический анализ при компиляции. Однако, в больших реальных проектах зачастую возникает необходимость проверить весь код на предмет соответствия некоторым дополнительным требованиям. Эти требования могут быть весьма разнообразны, начиная от правил именования переменных и заканчивая мобильностью (например, код должен благополучно выполняться на платформах х86 и х64). Наиболее распространенными требованиями являются:
- Надежность — меньшее количество ошибок в тестируемой программе.
- Удобство сопровождения — более понятный код, который легко изменять и усовершенствовать.
- Мобильность — гибкость тестируемой программы при запуске на различных платформах.
- Удобочитаемость — сокращение времени, необходимого для понимания кода[1].
Требования можно разбить на правила и рекомендации. Правила, в отличие от рекомендаций, обязательны для выполнения. Аналогом правил и рекомендаций являются ошибки и предупреждения, выдаваемые анализаторами кода, встроенными в стандартные компиляторы.
Правила и рекомендации, в свою очередь, формируют стандарт кодирования. Этот стандарт определяет то, как программист должен писать программный код. Стандарты кодирования применяются в организациях, занимающихся разработкой программного обеспечения.
Статический анализатор находит строки исходного кода, которые, предположительно, не соответствуют принятому стандарту кодирования и отображает диагностические сообщения, чтобы разработчик мог понять причину проблемы. Процесс статического анализа аналогичен компиляции, только при этом не генерируется ни объектный, ни исполняемый код. В данном обзоре приводится пошаговое описание процесса статического анализа.
Процесс анализа
Процесс статического анализа состоит из двух основных шагов: создания дерева кода (также называемого абстрактным деревом синтаксиса) и анализа этого дерева.
Для того чтобы проанализировать исходный код, анализатор должен сначала «понять» этот код, т.е. разобрать его по составу и создать структуру, описывающую анализируемый код в удобной форме. Эта форма и называется деревом кода. Чтобы проверить, соответствует ли код стандарту кодирования, необходимо построить такое дерево.
В общем случае дерево строится только для анализируемого фрагмента кода (например, для какой-то конкретной функции). Для того чтобы создать дерево код обрабатывается сначала лексером, а затем синтаксическим анализатором.
Лексер отвечает за разбиение входных данных на отдельные лексемы, а также за определение типа этих лексем и их последовательную передачу синтаксическому анализатору. Лексер считывает текст исходного кода строку за строкой, а затем разбивает полученные строки на зарезервированные слова, идентификаторы и константы, называемые лексемами. После получения лексемы лексер определяет ее тип.
Рассмотрим примерный алгоритм определения типа лексемы.
Если первый символ лексемы является цифрой, лексема считается числом, если этот символ является знаком «минус», то это — отрицательное число. Если лексема является числом, она может быть числом целым или дробным. Если в числе содержится буква E, определяющая экспоненциальное представление, или десятичная точка, число считается дробным, в противном случае — целым. Заметим, что при этом может возникнуть лексическая ошибка — если в анализируемом исходном коде содержится лексема «4xyz», лексер сочтет ее целым числом 4. Это породит синтаксическую ошибку, которую сможет выявить синтаксический анализатор. Однако подобные ошибки могут обнаруживаться и лексером.
Если лексема не является числом, она может быть строкой. Строковые константы могут распознаваться по одинарным кавычкам, двойным кавычкам, или каким-либо другим символам, в зависимости от синтаксиса анализируемого языка.
Наконец, если лексема не является строкой, она должна быть идентификатором, зарезервированным словом, или зарезервированным символом. Если лексема не подходит и под эти категории, возникает лексическая ошибка. Лексер не будет обрабатывать эту ошибку самостоятельно — он только сообщит синтаксическому анализатору, что обнаружена лексема неизвестного типа. Обработкой этой ошибки займется синтаксический анализатор[2].
Синтаксический анализатор понимает грамматику языка. Он отвечает за обнаружение синтаксических ошибок и за преобразование программы, в которой такие ошибки отсутствуют, в структуры данных, называемые деревьями кода. Эти структуры в свою очередь поступают на вход статического анализатора и обрабатываются им.
В то время как лексер понимает лишь синтаксис языка, синтаксический анализатор также распознает и контекст. Например, объявим функцию на языке Си:
int Func()
Лексер обработает эту строку и разобьет ее на лексемы как показано в таблице 1:
Таблица 1 — Лексемы строки «int Func();».
Строка будет распознана как 8 корректных лексем, и эти лексемы будут переданы синтаксическому анализатору.
Этот анализатор просмотрит контекст и выяснит, что данный набор лексем является объявлением функции, которая не принимает никаких параметров, возвращает целое число, и это число всегда равно 0.
Синтаксический анализатор выяснит это, когда создаст дерево кода из лексем, предоставленных лексером, и проанализирует это дерево. Если лексемы и построенное из них дерево будут сочтены правильными — это дерево будет использовано при статическом анализе. В противном случае синтаксический анализатор выдаст сообщение об ошибке.
Однако процесс построения дерева кода не сводится к простому представлению лексем в виде дерева. Рассмотрим этот процесс подробнее.
Дерево кода
Дерево кода представляет самую суть поданных на вход данных в форме дерева, опуская несущественные детали синтаксиса. Такие деревья отличаются от конкретных деревьев синтаксиса тем, что в них нет вершин, представляющих знаки препинания вроде точки с запятой, завершающей строку, или запятой, которая ставится между аргументами функции.
Синтаксические анализаторы, используемые для создания деревьев кода, могут быть написаны вручную, а могут и создаваться генераторами синтаксических анализаторов. Деревья кода обычно создаются снизу вверх.
При разработке вершин дерева в первую очередь обычно определяется уровень модульности. Иными словами, определяется, будут ли все конструкции языка представлены вершинами одного типа, различаемыми по значениям. В качестве примера рассмотрим представление бинарных арифметических операций.
Один вариант — использовать для всех бинарных операций одинаковые вершины, одним из атрибутов которых будет тип операции, например, «+». Другой вариант — использовать для разных операций вершины различного типа. В объектно-ориентированном языке это могут быть классы вроде AddBinary, SubstractBinary, MultipleBinary, и т. п., наследуемые от абстрактного базового класса Binary[3].
В качестве примера разберем два выражения: 1 + 2 * 3 + 4 * 5 и 1+ 2 * (3 + 4) * 5 (см. рисунок 1).
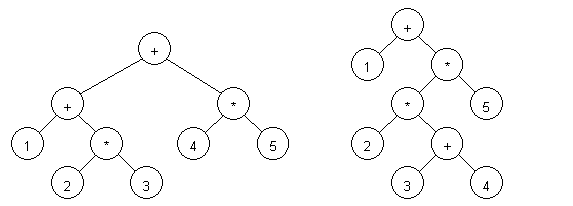
Рисунок 1 — Разобранные выражения: 1 + 2 * 3 + 4 * 5 (слева) и 1 + 2 * (3 + 4) * 5 (справа).
Как видно из рисунка, оригинальный вид выражения может быть восстановлен при обходе дерева слева направо.
После того, как дерево кода создано и проверено, статический анализатор может определить, соответствует ли исходный код правилам и рекомендациям, указанным в стандарте кодирования.
Методы статического анализа
Существует множество различных методов статического анализа, в частности, анализ с обходом дерева кода, анализ потока данных, анализ потока данных с выбором пути и т. д. Конкретные реализации этих методов различны в разных анализаторах. Тем не менее, статические анализаторы для различных языков программирования могут использовать один и тот же базовый код (инфраструктуру). Эти инфраструктуры содержат набор основных алгоритмов, которые могут использоваться в разных анализаторах кода вне зависимости от конкретных задач и анализируемого языка. Набор поддерживаемых методов и конкретная реализация этих методов, опять же, будет зависеть от конкретной инфраструктуры. Например, инфраструктура может позволять легко создавать анализатор, использующий обход дерева кода, но не поддерживать анализ потока данных [4].
Хотя все три перечисленные выше метода статического анализа используют дерево кода, построенное синтаксическим анализатором, эти методы различаются по своим задачам и алгоритмам.
Анализ с обходом дерева, как видно из названия, выполняется путем обхода дерева кода и проведения проверок на предмет соответствия кода принятому стандарту кодирования, указанному в виде набора правил и рекомендаций. Именно этот тип анализа проводят компиляторы.
Анализ потока данных можно описать как процесс сбора информации об использовании, определении и зависимостях данных в анализируемой программе. При анализе потока данных используется граф потока команд, генерируемый на основе дерева кода.
Этот граф представляет все возможные пути выполнения данной программы: вершины обозначают «прямолинейные», без каких бы то ни было переходов, фрагменты кода, а ребра — возможную передачу управления между этими фрагментами. Поскольку анализ выполняется без запуска проверяемой программы, точно определить результат ее выполнения невозможно.
Иными словами, невозможно выяснить, по какому именно пути будет передаваться управление. Поэтому алгоритмы анализа потока данных аппроксимируют возможное поведение, например, рассматривая обе ветви оператора if-then-else, или выполняя с определенной точностью тело цикла while.
Ограничение точности существует всегда, поскольку уравнения потока данных записываются для некоторого набора переменных, и количество этих переменных должно быть ограничено, поскольку мы рассматриваем лишь программы с конечным набором операторов. Следовательно, для количества неизвестных всегда существует некий верхний предел, дающий ограничение точности. С точки зрения графа потока команд при статическом анализе все возможные пути выполнения программы считаются действительными. Из-за этого допущения при анализе потока данных можно получать лишь приблизительные решения для ограниченного набора задач [5].
Описанный выше алгоритм анализа потока данных не различает путей, поскольку все возможные пути, вне зависимости от того реальны они, или нет, будут ли они выполняться часто, или редко, все равно приводят к решению. На практике, однако, выполняется лишь малая часть потенциально возможных путей.
Более того, самый часто выполняемый код, как правило, составляет еще меньшее подмножество всех возможных путей. Логично сократить анализируемый граф потока команд и уменьшить таким образом объем вычислений, анализируя лишь некоторое подмножество возможных путей. Анализ с выбором путей проводится по сокращенному графу потока команд, в котором нет невозможных путей и путей, не содержащих «опасного» кода. Критерии выбора путей различны в различных анализаторах. Например, анализатор может рассматривать лишь пути, содержащие объявления динамических массивов, считая такие объявления «опасными» согласно настройкам анализатора.
Заключение
Число методов статического анализа и самих анализаторов возрастает из года в год, и это означает, что интерес к статическим анализаторам кода растет. Причина заинтересованности заключается в том, что разрабатываемое программное обеспечение становится все более и более сложным и, следовательно, проверять код вручную становится невозможно.
В этой статье было приведено краткое описание процесса статического анализа и различных методов проведения такого анализа.
Библиографический список
- Dirk Giesen Philosophy and practical implementation of static analyzer tools [Electronic resource]. -Electronic data. -Dirk Giesen, cop. 1998.
- James Alan Farrell Compiler Basics [Electronic resource]. -Electronic data. -James Alan Farrell, cop 1995. -Access mode: http://www.cs.man.ac.uk/~pjj/farrell/compmain.html
- Joel Jones Abstract syntax tree implementation idioms [Electronic resource]. -Proceedings of the 10th Conference on Pattern Languages of Programs 2003, cop 2003.
- Ciera Nicole Christopher Evaluating Static Analysis Frameworks [Electronic resource].- Ciera Nicole, cop. 2006.
- Leon Moonen A Generic Architecture for Data Flow Analysis to Support Reverse Engineering [Electronic resource]. — Proceedings of the 2nd International Workshop on the Theory and Practice of Algebraic Specifications, cop. 1997.
Источник: pvs-studio.ru