
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Switch branches/tags
Branches Tags
Could not load branches
Nothing to show
Could not load tags
Nothing to show
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
- Local
- Codespaces
HTTPS GitHub CLI
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Лучшие программы для распознавания текста. Рейтинг OCR.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
Latest commit message
Commit time
README.md
Распознавание рукописного текста в школьных тетрадях
Соревнование, проводимое в рамках олимпиады НТО

6 место на паблике и 7 на привате
Вам нужно разработать алгоритм, который способен распознать рукописный текст в школьных тетрадях. В качестве входных данных вам будут предоставлены фотографии целых листов. Предсказание модели — список распознанных строк с координатами полигонов и получившимся текстом.
Общий пайплайн решения
- Найти области каждого слова на изображении
- Определить на каком языке писали на этой фотографии (англиский/русский)
- Каждую найденную область прогнать через OCR модель и распознать что там написано
- Instance Segmentation = crop + maskrcnn_resnet50_fpn
- Language classification = resnet_34
- Ocr = microsoft/trocr-small-handwritten + hkr + generating dataset + HandWrittenBlot
В качестве модели распознавания мы попробовали две модели: detectoRS — одна из моделей зоопарка mmdetection и предобученный на COCO maskrcnn_resnet50_fpn (реализовали на торче).
Использовали дефолтную версию из mmdetection. При обучении ресайзили картинку в (1333, 800) и предсказывали сразу все слова на изображение
Чтобы размеры картинок не были помехой (были и вертикальные и горизонтальные сэмплы), модель обучили на кропах размерами (256, 256), а предсказание полигонов происходило в несколько этапов:
- Сжать размер картинки в 4 раза
- Пройтись окном (256, 256) и сделать предсказания
- Склеить слова на границах окон
Для того, чтобы склеивание происходило быстрее алгоритм сопоставления цветов был переписна на numba.jit
Программы распознавания текста

Так как на одной фотографии мог быть либо только русский, либо только англиский, то мы брали несколько слов из тех, что нашли при помощи сегментации и распознавали на каком языке они были написаны. Потом смотрели каких слов больше (русских или англиских) и в зависимости от этого определяли язык.
Было два способа распознавать язык
- Обучить trOcr на русском и англиском языке и просто получать с них предикт. Хоть CER у такой мультиязычной модели был и больше чем у тех, что обучены по отдельности, язык она практически не путала, однако довольно долго работала
- Дообучить resnet_34, чтобы он определял какой это язык. Данная модель косячила заметно чаще, но зато была шустренькой
В итоге остановились на втором варианте, так как первый чуть-чуть не залезал в тайм лимит
При обучение модели распознавания текста мы во многом вдохновились статьей ребят, которы заняли первое место на Digital Petr
В качестве модели распознавания текста была использована state-of-the-art модель trOcr: Transformer-based Optical Character Recognition. Мы дообучали microsoft/trocr-small-handwritten на нашем датасете и смогли выбить CER=0.04 для русского языка и CER=0.06 для англиского.
Для обучения русскоязычной модели мы собрали соединили несколько датасетов:

- Тот, что дали огранизаторы соревнования
- HKR dataset — датасет русских и казахских рукописных слов
- Сгенерированные нами данные. Так как из модели, которая используют CTC Loss можно достать границы букв в словах, то мы смогли разбить данные нам слова на буквы и потом склеивать собственные слова (подробнее про генерацию датасета туть).
Для англиского языка было взято всего два датасета
- Тот, что дали организаторы соревнования
- IAM dataset — стандартный датасет для OCR на англиском
Чтобы добится лучшего качества распознавния мы добавили аугов
transforms = A.Compose([ A.Resize(384, 384), AlbuHandWrittenBlot(blots, p=0.3), A.Rotate(limit=[-7, 7]), A.OneOf([ A.ToGray(always_apply=True), A.CLAHE(always_apply=True, clip_limit=15), ], 0.3) ])
Из нестандартных аугментаций были использованы HandWrittenBlot — имитация рукописных почеркушек.

About
Распознавание рукописного текста в школьных тетрадях
Источник: github.com
Алгоритм распознавания текстовой информации на изображении с помощью ЭВМ
Ломанов, Д. К. Алгоритм распознавания текстовой информации на изображении с помощью ЭВМ / Д. К. Ломанов. — Текст : непосредственный // Молодой ученый. — 2019. — № 28 (266). — С. 14-16. — URL: https://moluch.ru/archive/266/61607/ (дата обращения: 24.06.2023).
Одним из самых быстрых и удобных способов перевода информации из физического формата в электронный вид является сканирование документов. Результатом данного процесса будет электронный файл, представленный в виде графического изображения. Графическое изображение не позволяет производить необходимый набор действий, как при работе с текстом, что делает его менее функциональным. Основные отличия хранения текстовой информации, в отличии от графической: экономия затрат на хранении, более обширный список сценариев использование документа.
OCR — это система оптического распознавания символов. В настоящее время данная система имеет большую популярность, она применяется в большом количестве программ, связанных с распознаванием текста.
Алгоритм работы распознания текста всегда строится одинаково.В систему загружается отсканированный файл, представленный в виде растрового изображения страницы документа. Качества изображения играет важную роль в распознании текста: чем выше качество, тем выше точность. Поэтому первым этапом будет являться обработка поступившего изображения: снижение шума, повышения контраста, повышение резкости, бинаризация изображения, выравнивание угла наклона [1].
Обработанный файл передается в модуль сегментации, задачей которого является выявление структурных единиц текста — страниц, строк, слов и символов. После сегментации полученные данные собираются в обратном порядке в готовый файл.

Рис. 1. Порядок сегментации
Для начала документ делится на страницы, далее определяются текстовые блоки. Для выявления слов из текстового блока производится определение угла наклона текста, для уменьшения будущих погрешностей, поиск вертикальных просветов в тексте, показывающих границы слова [2].
Для разбивки слова на символы проводится аналогичный процесс, только с меньшими просветами. Данные операции будут более точными, если текст будет черного цвета на белом фоне, если оригинальный текст иного цвета, то применяется бинаризация изображения.

Рис. 2. Пример входного текстового блока
На выходе из модуля сегментации будут получены данные, в состав которых входят структуры и местоположение текстовых блоков на странице, строки в этих блоках и их сегментация на слова и символы. Данные могут содержать не только информацию об обычном текстом блоке, а также о колонках, таблицах и т. д.

Рис. 3. Пример обработанного текстового блока
Определенные фрагменты слов и символов отправляются в модуль классификатора, результатом работы которого будет являться информация о принадлежности символа к определенной букве или символу. Нейронная сеть для каждого входящего символа, используя его пиксельное изображение, определяет признаки принадлежности буквы к нечеткому множеству.
После определения признаков у символа начинается процесс составление из символов слов. Для этого нейронная сеть сравнивает возможность написания отдельных букв, частоту сочетаний букв в языке, производится проверка по модели слова и словарю [3].
Модель слова — модель, разделяющая слова на определенные типы, такие как сокращения, аббревиатуры, обычные слова, имена собственные, числа и т. д.
С этого момента проверяется насколько хорошо подходит к данной модели полученное слово.
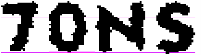
.
Рис. 4. Пример модели слова
Пример списка моделей слов
Вариант распознания слова
Модель
Источник: moluch.ru
Как происходит распознавание текстов

Сегодня нет необходимости заново набирать имеющийся текст, тратя на это драгоценное время. С этой работой помогают справиться многофункциональные устройства, которые выполняют ее в несколько этапов, освобождая человека от этой нудной процедуры.
Во-первых, нужно ввести отсканированный документ в компьютер. Страница в этом случае выглядит как изображение, еще не готовое для дальнейшей работы с ним.
Во-вторых, нужно произвести анализ макета, чтобы определить, где на странице находится текст, а где – таблицы и рисунки. Этот процесс выполняется при помощи OCR-приложения, которое позволяет разить текст на небольшие фрагменты, последовательно дробя их на предложения, слова и, наконец, самые мелкие – символы. Таким образом, конечным результатом данного этапа работы будет совокупность отдельных символов, каждый из которых находится в определенном месте страницы.
Далее программа начинает распознавать символы, т.е. идентифицировать их. От того, насколько правильно пройдет этот процесс, зависит весь результат распознавания. Главная проблема состоит в том, что существуют похожие по своему начертанию символы, которые несут различную смысловую нагрузку. Для идентификации символов используются такие методы, как сопоставление признаков и сопоставление с имеющимся образцом. Один из них (сопоставления признаков) основан на таком принципе, что программа ориентируется на то, что каждый символ имеет свои отличительные признаки, которые остаются неизменными независимо от начертания шрифтов.
В соответствии со вторым методом программа сравнивает распознаваемый символ с тем шаблоном, который хранится в базе данных ее памяти. Этот метод называется методом сопоставления, но не очень удобен, поскольку на распознавание текста уходит много времени. Причиной низкой эффективности является также и то, что при использовании этого метода должно быть стопроцентное соответствие между символом и шаблоном, чтобы программа смогла распознать текст.
После распознавания текста начинается реконструкция документа. Программа имеет встроенный словарь, с помощью которого происходит процесс объединения символов в значимые слова, далее – в предложения и абзацы. Одна из функций программы позволяет реконструировать текст с учетом грамматических особенностей отсканированного текста, чтобы предложения получились грамотно построенными с точки зрения стилистики, грамматики и пунктуации.
И, наконец, реконструированный текст нужно сохранить. Пользователь сам определяет, в каком формате нужен полученный документ. Это может быть текст в формате TXT или макет страницы в формате PDF либо Microsoft Word.
Одним из лидеров в области разработки программного обеспечения для распознавания текстов является компания ABBYY со своим программным продуктом ABBYY Fine Reader.
Источник: www.administrator-pro.ru