
Смотрите места, где были сделаны фотографии, на карте (если информация о местоположении была записана).
Поддерживает множество тегов Exif, которые могут быть записаны на фотографии, например:
• Марка камеры,
• Модель камеры,
• Серийный номер камеры,
• Место нахождения,
• Дата и время,
• Программное обеспечение, обрабатывающее фотографии,
• Режим вспышки,
• Источник света,
• Марка линз,
• Модель объектива,
• Серийный номер объектива,
• Ширина, высота и разрешение,
• F-стоп,
• Время воздействия,
• Чувствительность ISO,
• Фокусное расстояние,
• Режим замера,
• Расстояние до объекта,
• Контрастность, яркость, насыщенность и резкость,
• Баланс белого,
• И многое другое!
Особенности
• Простой и легкий в использовании,
• Поддерживает множество тегов Exif,
• Просмотр местоположения фотографии на карте (если местоположение было записано),
• Нет раздутых / ненужных функций,
Значение слова метаданные. Что такое метаданные.
• Нет ненужных разрешений,
• Бесплатно!
Последнее обновление
13 апр. 2023 г.
Инструменты
Безопасность данных
arrow_forward
Чтобы контролировать безопасность, нужно знать, как разработчики собирают ваши данные и передают их третьим лицам. Методы обеспечения безопасности и конфиденциальности могут зависеть от того, как вы используете приложение, а также от вашего региона и возраста. Информация ниже предоставлена разработчиком и в будущем может измениться.
Источник: play.google.com
Что такое метаданные: включая их типы и изучите метод редактирования метаданных
Ты хочешь знать что это за метаданные? Если это так, вы должны прочитать этот информативный обзор. Чтобы дать вам краткое представление, метаданные необходимы для файла, веб-страницы, документа и многого другого. Речь идет о данных о данных. Чтобы глубже понять обсуждение, мы подробнее остановимся на них для вас.
Вы узнаете полное описание метаданных, включая их типы и примеры. Также мы предложим отличный метод для редактирования метаданных. Итак, если вам интересно, прочитайте этот обзор и узнайте все, что вам нужно знать.

- Часть 1. Что такое метаданные
- Часть 2. Для чего используются метаданные
- Часть 3. Различные типы метаданных
- Часть 4. Что такое пример метаданных
- Часть 5. Как редактировать метаданные
- Часть 6. Часто задаваемые вопросы о метаданных
Часть 1. Что такое метаданные
Набор информации, называемый метаданными, определяет другие данные. Метаданные контекстуализируют другие данные, предоставляя сведения о дате и методе сбора. Это упрощает идентификацию, доступ, управление и многое другое. Другими словами, каждый голос, фотография, фильм или файл также содержат загадочные данные. С его помощью вы можете управлять и упорядочивать наборы данных.
Метаданные: Невидимая информация о файлах
Метаданные могут создаваться вручную или автоматически посредством обработки информации. Ручное строительство обычно более точное. Это позволяет пользователям включать детали, которые они считают уместными или полезными при описании файла. Автоматическое создание метаданных может быть более простым, представляя такие сведения, как размер файла, расширение, дата создания и создатель файла.
Часть 2. Для чего используются метаданные
Метаданные создаются каждый раз при редактировании документа, файла или другого информационного актива, в том числе при его удалении. Помогая пользователям находить новые приложения для существующих данных, точные метаданные могут помочь продлить срок службы этих данных.
Более того, метаданные организуют объект данных, используя терминологию, относящуюся к этой конкретной вещи. Чтобы максимизировать использование активов данных, это также позволяет идентифицировать и сопоставлять вещи, которые не похожи на те, которые есть. Как уже упоминалось, поисковые системы и браузеры анализируют теги метаданных, прикрепленные к HTML-документу, чтобы решить, какой веб-контент отображать. Метаданные выражаются на языке, понятном компьютерным системам и людям, что позволяет улучшить совместимость и интеграцию различных приложений.
Кроме того, метаданные используются предприятиями в области цифровой публикации, проектирования, финансовых услуг, здравоохранения и производства, чтобы получить представление об обновлении процессов или улучшении товаров. Чтобы защитить правообладателей и предоставить аутентифицированным пользователям доступ к музыке и фильмам, поставщики потокового контента, например, автоматизируют управление информацией об интеллектуальной собственности, чтобы ее можно было хранить в различных приложениях.
Часть 3. Различные типы метаданных
В этой части вы познакомитесь с различными типами метаданных. Прочитайте и изучите все типы метаданных ниже.
Административные метаданные
Информация из административных метаданных помогает управлять ресурсами. Он предлагает подробную информацию о безопасности, ограничениях доступа и управлении. Он содержит техническую информацию об авторских правах, управлении правами и лицензионных соглашениях. Она может состоять из связанной с творением технологической информации. Это влечет за собой управление правами, контроль доступа и обеспечение качества произведений.
Описательные метаданные
Информация из описательных метаданных помогает найти ресурс данных. Это объясняет, кто ресурс, что, когда и где. Он включает сведения о контексте и содержании данных. Он структурирован и следует одной или нескольким установленным стандартным схемам. Он напоминает MARC или Dublin Core. Он также может указывать физические характеристики ресурса. Он охватывает пропорции и тип носителя.
На системном уровне он помогает пользователям в поиске и получении информации. Это дает пользователям возможность находить ресурсы в Интернете. Например, он использует гиперссылки на документы.
Структурные метаданные
Структурированные метаданные предоставляют информацию о конкретном объекте или ресурсе. Имеются в виду электронные СМИ. Фильм на DVD, например, состоит из множества отдельных частей. Каждая часть фильма имеет установленное время работы. Каждый вписывается в структуру в определенном порядке.
Другими словами, структурные метаданные отслеживают данные о том, как сортировать конкретный ресурс. Пользователи будут проинформированы о правильном расположении этих компонентов на DVD через структурные метаданные, как было указано ранее.
Метаданные о происхождении
Вы можете узнать источник происхождения из метаданных происхождения. В нем содержится информация о том, кому он принадлежит. Более того, какие-либо модификации данных могли претерпевать. Использование и сохранение ресурса данных. Эти данные помогают отслеживать срок службы ресурса.
Каждый раз, когда создается новая версия набора данных, создаются метаданные происхождения. Он обозначает связь между различными версиями объекта данных. Пользователи могут запрашивать связь между версиями, при этом включается один или оба типа подробной информации о происхождении ресурсов данных.
Сохранение метаданных
Метаданные сохранения в цифровых репозиториях могут охватывать управление правами. Он содержит сведения о правообладателях, разрешающих такое поведение. Он опирается на другие структуры, такие как административные и структурные метаданные. Это относится к проверке и действиям, предпринятым с ресурсом при отправке в репозиторий.
Метаданные определений
Метаданные определений относятся к метаданным, которые обеспечивают общий словарь. Это способствует общему пониманию смысла данных. Значение данных включает информацию об определениях данных. Он включает правила, управляющие контекстом данных и вычислениями. Он также может включать логику, используемую при создании производных данных, чтобы понять их значение.
Часть 4. Что такое пример метаданных
Метаданные файла изображения
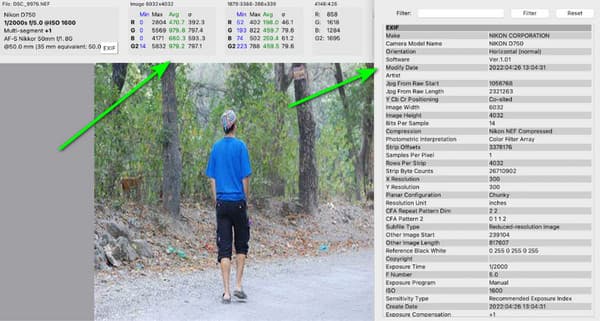
Вы можете увидеть метаданные ниже примеров изображений. Он включает в себя используемые объективы, фокусное расстояние, разрешение изображения, цветовые профили, марку камеры, время, когда изображение было снято, и GPS-координаты местоположения.
Метаданные книги

Каждая книга имеет внутри стандартные метаданные. Он включает имя автора, название, издательство, оглавление, номера страниц, предметный указатель и описание на обороте.
Метаданные файла Paper

Административная информация в файлах бумажных документов часто используется для управления документами. Он включает в себя букву файлов в алфавитном порядке, логотип, информацию о контроле доступа и многое другое.
Метаданные файла рабочего стола
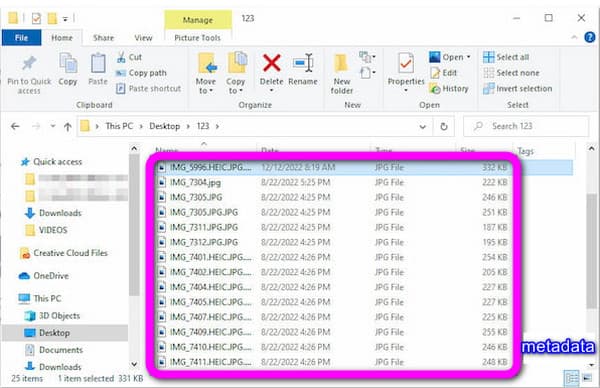
Вы можете видеть метаданные в каждом файле, который вы открываете в папке «Файл». Сами файлы содержат точные данные. Вы можете увидеть размер файла, имя файла, дату и время последнего изменения, а также дату и время создания.
Часть 5. Как редактировать метаданные
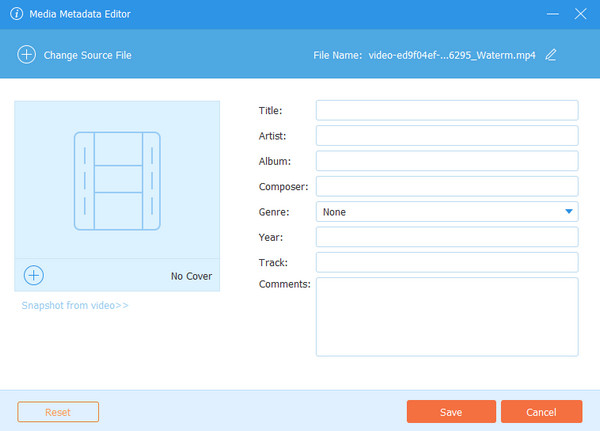
Если вам нужен отличный способ редактирования метаданных, используйте Tipard Video Converter Ultimate. С помощью этой автономной программы вы можете легко и быстро редактировать метаданные ваших файлов. Вы можете редактировать почти все параметры при редактировании метаданных файла.
Автономная программа позволяет редактировать название видео, исполнителя, композитора, комментарии и многое другое. Вы также можете поместить фотографию на обложку, чтобы сделать ее более сытной и приятной для просмотра. Tipard Video Converter Ultimate предлагает простую процедуру.
Он также имеет интуитивно понятный пользовательский интерфейс, который идеально подходит для всех пользователей. Кроме того, вы можете изменить имя файла. Таким образом, вы можете свободно изменять все детали, которые хотите для видео. Кроме того, Tipard Video Converter Ultimate доступен в операционных системах Mac и Windows.
Его также можно загрузить бесплатно, что делает его удобным для пользователей. Кроме того, помимо редактирования метаданных, есть и другие функции, с которыми вы можете столкнуться при использовании загружаемой программы. Попробуйте использовать Tipard Video Converter Ultimate и испытайте программное обеспечение самостоятельно. Используйте простые инструкции ниже, чтобы редактировать метаданные с помощью компьютера.
Шаг 1 Скачать Tipard Video Converter Ultimate на вашем компьютере Mac и Windows. Для быстрого доступа к автономной программе нажмите кнопку Скачать кнопку ниже.
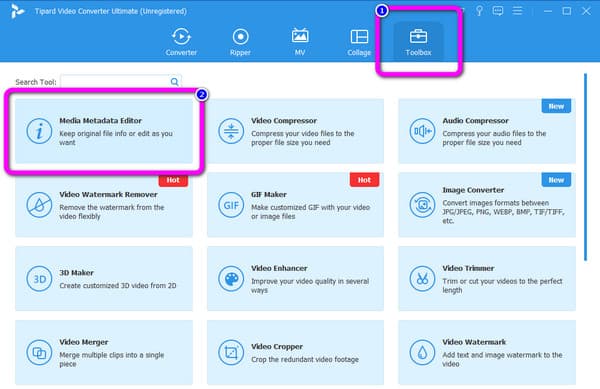
Шаг 2 После процесса установки запустите программу. Когда интерфейс программы уже появится, нажмите кнопку Ящик для инструментов панель на верхнем интерфейсе. Затем выберите Редактор медиа-метаданных инструмент.
Шаг 3 На экране появится другой интерфейс. Нажмите на Дополнительная символ, чтобы добавить файл, который вы хотите отредактировать. Выберите файл из папки вашего компьютера.
Шаг 4 В этой части вы уже можете редактировать детали из вашего файла. Вы можете изменить название файла, исполнителя, альбом, композитора, год и многое другое. Вы также можете добавить фотографию для обложки вашего файла. Затем, после завершения процесса, нажмите кнопку Save. кнопку.
Часть 6. Часто задаваемые вопросы о метаданных
Что такое тег ID3?
Тег ID3 является компонентом аудиофайлов, особенно MP3. Тег ID3 — это метаданные для аудиофайла, обеспечивающие их правильное отображение в программном обеспечении для настольных ПК. Он включает в себя DAW, приложение для потоковой передачи музыки или программное обеспечение для потоковой передачи DJ. Некоторые теги ID1 включают название альбома, номер дорожки, жанр, исполнителя, битрейт и ключ.
Каково значение метаданных?
Значение метаданных уже было рассмотрено, и совершенно очевидно, что метаданные файла могут разглашать важную информацию и причинять значительный вред. Вы должны соблюдать крайнюю осторожность, если вы работаете с информационной безопасностью.
Чем отличаются метаданные и данные?
С помощью метаданных можно определить характер и характеристики исходных данных. Напротив, данные могут быть фактом, набором измерений или наблюдений или описанием конкретного объекта.
Вот оно! Этот подлинный обзор дал вам всю необходимую информацию о что это за метаданные. Вы также найдете его пример и различные типы. Итак, если вы хотите изменить или отредактировать метаданные ваших файлов, используйте Tipard Video Converter Ultimate. Он предлагает простой метод с простым интерфейсом для редактирования метаданных.
Размещено от Лилия Старк в Редактировать видео, Аудио
Март 16, 2023 10: 50
Вам могут понравиться эти статьи
![]()
Нажмите здесь, чтобы присоединиться к обсуждению и поделиться своими комментариями

Источник: ru.tipard.com
DIY-метаданные: как мы собрали велосипед, который везет на себе технологические данные компании

Привет, Хабр! Меня зовут Ткачев Константин, и я работаю архитектором в Леруа Мерлен.
В этой статье я хочу рассказать, как мы смогли, используя только open-source, построить систему работы с метаданными, которая позволила:
- централизовать и унифицировать описания данных, используемых в компании;
- автоматизировать процессы загрузки данных в корпоративное хранилище — платформу данных;
- и сделать еще многое-многое другое…
А если добавить к этому, что мы сделали это быстро — и в итоге за пару месяцев получили работающую систему, то станет ясно, почему мы решили поделиться этим опытом с пользователями Хабра.
Что такое метаданные
Если совсем коротко, то метаданные — это информация (данные) о другой информации. Метаданные могут описывать объекты базы данных, как, например, это выполняет системный каталог PostgreSQL, или процессы обработки данных ETL/ELT в виде направленного графа (DAG’а) Airflow.
Важность метаданных в IT-системах чрезвычайно высока, поскольку без них поиск и использование нужной информации были бы весьма и весьма затруднительны.
Разработанная нами система управления метаданными оперирует, если так можно выразиться, технологическими метаданными, которые описывают:
- структуру источников центрального хранилища данных компании — платформу данных (платформа);
- различные STTM (Source To Target Mapping);
- настройки наших инструментов, например Airflow, который используется для загрузки данных в платформу (о работе нашего коммунального Airflow мы писали тут);
- права доступов к объектам платформы;
- описания DAG’ов Airflow, использующихся в одном из наших решений — Marts Loader;
- правила работы наших сервисов, например, условия партиционирования таблиц платформы данных для соответствующего сервиса.
Наши метаданные не только описывают данные, но и определяют потоки их обработки, а также настройки инструментов работы с данными в нашей компании.
С чего все началось
В далеком 2019-м одним из направлений наших работ было построение платформы данных, к которой ваш покорный слуга имел самое непосредственное отношение. Мы определились с подходом и инструментарием, за исключением того, что у нас не была выбрана система управления метаданными и справочниками. В данной статье речь пойдет только о метаданных, так как о справочниках и всем, что с ними связано, напрашивается целый цикл статей)).
Поскольку нам необходимо было оперативно двигаться в отношении построения платформы и мы начинали интегрировать первые источники, отсутствие инструментария по работе с различными метаданными «несколько» сдерживало нас. Можно сказать, что, создавая платформу данных, мы не знали, что она будет в себе хранить и как в ней можно будет найти требуемую информацию. Необходимо было в краткие сроки найти подходящий инструмент. В число базовых требований были включены гибкость применения и расширение функциональных возможностей инструмента. Да, и мы, в рамках принятого подхода, рассматривали только open-source-инструменты.
Требования к системе управления метаданными
Требования к системе управления метаданными включают:
- описание объектов и процессов информационных систем, причем не только платформы данных;
- описание различных настроек работы информационных систем;
- возможность предоставления метаданных через REST API;
- наличие инструмента по редактированию и просмотру метаданных с учетом прав доступа;
- возможность гибкой классификации и редактирования структуры метаданных;
- необходимость дополнительно обеспечить data lineage (забегая немного вперед, скажу, что мы это обеспечили хранением STTM, которые используются в наших процессах обработки данных);
- скорость разработки и применения инструмента управления метаданными;
- скорость освоения сотрудниками компании;
- простую интеграцию в CI/CD pipeline;
- обеспечение качества метаданных, на основе выработанных критериев;
- использование только собственных разработок или open-source-инструментов.
Рассматривали собственную разработку с хранением метаинформации в БД (планировали использовать PostgreSQL), но времени на разработку относительно гибкой структуры и пользовательского интерфейса не было, так как, повторю, начиналась интеграция источников.
Также мы рассмотрели применение следующих инструментов:
Hive metastore заточен для описания таблиц в БД, включая наименования и типы столбцов, а также специфическую для HDFS информацию — партиции и бакеты. Мы же планировали не только описывать таблицы в БД, тем более что системный каталог платформы данных уже решал эту задачу.
Atlas предполагал слишком уж большой уровень абстракции, мы решили, что его применение, описание метаданных и поддержка будут сложны и нам, как внедренцам, и пользователям.
Amundsen неплох: имеет приятный интерфейс и развитые средства Data Discovery, использует Airflow для Data ingestion, ElasticSearch для поиска данных и Neo4J или Atlas для хранения метаданных, API layer реализован с использованием Flask. В общем, он нам понравился, но все-таки его функционал ограничен (фактически ограничен предоставляемым UI) и он не отвечал многим из наших требований. Стоит отметить, что к исследованию Amundsen мы приступили, уже начав разработку собственного инструмента, и это окончательно повлияло на наше решение. Если перед вами стоит вопрос выбора инструмента управления метаданными, то можем порекомендовать обратить внимание на эту систему.
Жизнь не стоит на месте, появляются новые интересные инструменты для работы с метаданными. Мы пробуем использовать появившиеся возможности и сейчас мы тестируем такое средство как Open Metadata. Пока у нас нет полного представления о всех его функциях, но вполне вероятно, что оно приживется в нашем стеке технологий))
DIY-путь
Поскольку мы компания, работающая в сегменте DIY (Do It Yourself), то и на подходы в области IT-технологий философия компании влияет — разумеется, в хорошем смысле этого слова. Мы не сторонники изобретать велосипед, но у нас руки горят доработать этот самый велосипед, чтобы он максимально соответствовал целям, ради которых мы его используем. Ну и, конечно, добавить немного индивидуальности и привнести что-то свое и полезное — дополнительная мотивация для нас.
А если серьезно, то мы хотели в достаточно короткое время разработать систему, которая позволит удовлетворить наши потребности в области описания данных и, что немаловажно, их использования широкой аудиторией.
Так мы начали создавать свою систему по управлению метаданными, или DIY-мету.
Как все это работает (архитектура DIY-меты)
Общая идея такова.
Метаданные мы решили хранить в виде файлов yaml. Почему? Этот формат читабелен и пользователям легко с ним работать.
Для хранения и изменения DIY-меты мы используем github. Пользователи выполняют изменения метаданных и формируют pull request (PR). Выбрав github, как систему хранения для DIY-меты, мы дополнительно получили ряд полезных и вкусных «плюшек»:
- использование в CI/CD pipeline (об этом подробнее позже);
- решение вопроса с авторизацией и аутентификацией, в том числе использование CODEOWNERS для ограничения изменений данных в GIT.
После изменений в виде PR стартует CI/CD pipeline, который выполняет тестирование, сборку и деплой контейнера Docker с сервисом метаданных на определенное окружение (в зависимости от того, в какую ветку был PR). В результате сборки контейнер содержит yaml-файлы с метаданным.
Доступ к DIY-мете для наших информационных систем и пользователей предоставляется посредством сервиса метаданных.
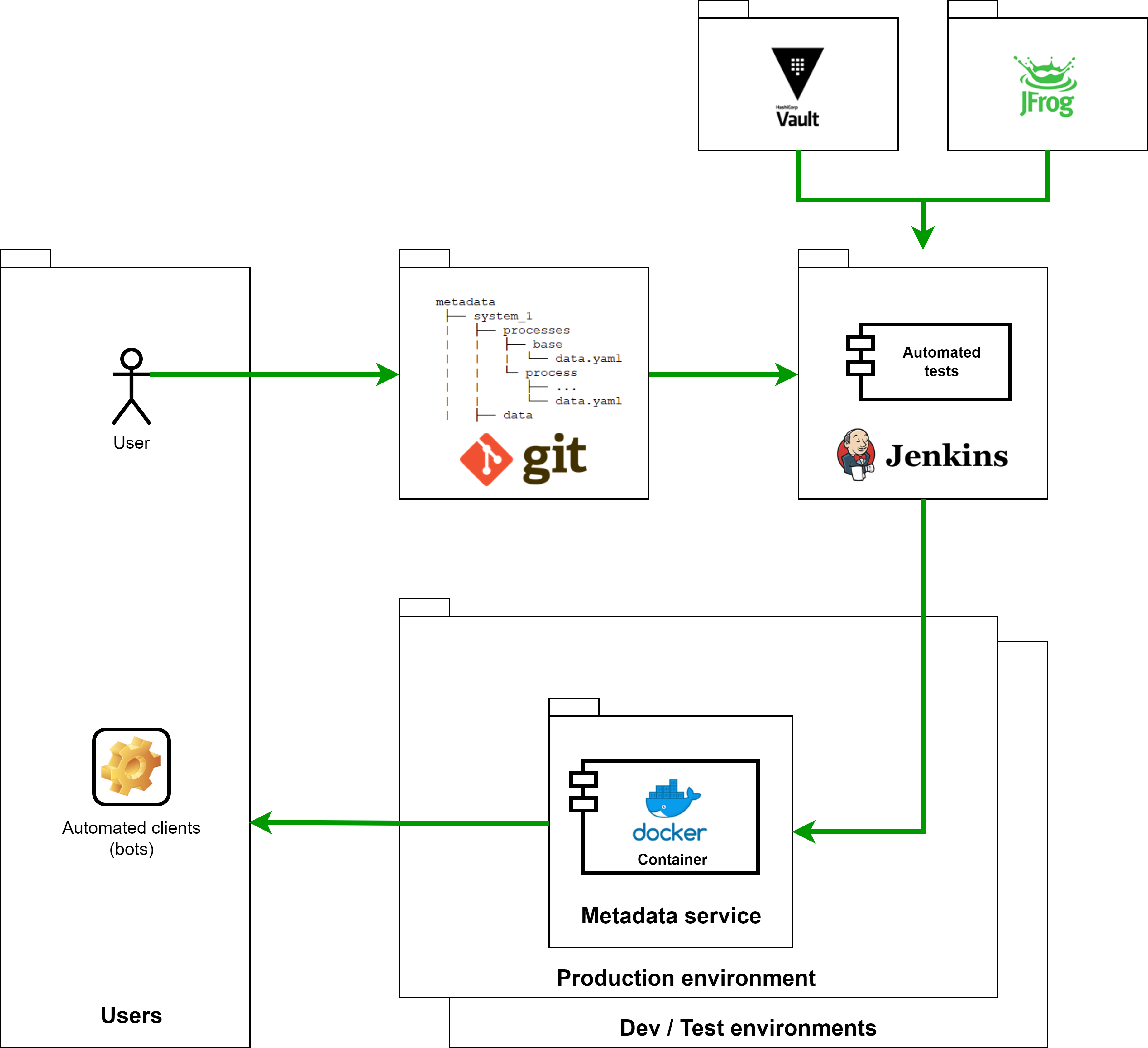
Структура хранения метаданных и соглашение по наименованию объектов
Получилось, что в нашем случае метаданные — набор yaml-файлов и python-файлов, которые объединены в определенную структуру хранения.
Python-файлы содержат тесты пользователей, которые проверяются в рамках автотестов, о чем я расскажу ниже более подробно.
Однако простота и гибкость ведения DIY-меты могла обернуться полной неразберихой, поэтому мы задали определенные правила наименования, а также верхнеуровневую классификацию метаданных в виде структуры каталогов (папок). Таким образом, у нас появилось соглашение, которое определяет структуру хранения файлов и их наименования. При этом, поскольку мы храним DIY-мету как файлы в каталогах (как в файловой системе), мы сохраняем определенную гибкость по переопределению описания данных.
И еще, для некоторых типов файлов, структура которых должна быть четко определена, мы задали канонические схемы в виде json-схем. Эти схемы используются автотестами для проверки корректного описания данных. Например, такие схемы описывают таблицы, которые являются источниками для платформы данных, также схемы используются для задания мэппингов атрибутов объектов.
Ниже приведена структура метаданных, которую мы используем.
metadata(root) | ├── metadata_repository_tests (for metadata tests: structure, naming, etc) | ├── system_1 (e.g. dataplatform) | | | ├── processes | | ├── base (base process) | | | ├── . | | | └── data.yaml (types mapping, etc) | | | | | ├── technology process_1 | | | ├── . | | | └── data.yaml (types mapping, etc) | | └── technology process_N | | ├── . | | └── data.yaml (types mapping, etc) | | | ├── data (sources, destinations, etc) | │ ├── data_name_1 | │ | ├── namespace_1 (. If only necessary . ) | | | | ├── object_name_1 | │ | | | └── data.yaml | │ | | ├── object_name_N | │ | | | └── data.yaml | | | | └── data.yaml | | | └── data.yaml | │ │ | │ ├── data_name_N | │ | └── . | | | | | └── data.yaml | | | ├── access | │ ├── system_1(Greenplum) | | | | | │ | ├── data_name_1/namespace | │ │ | └── data.yaml | │ │ ├── . | | │ │ | | | └── data_name__N/namespace | │ | └── data.yaml | │ | | │ ├── system_2 (NiFi) | | ├── system_3 (S3) | | └── system_N (Airflow) | | | ├── infrastructure | | | | | ├── airflow_ | | └── . | | | └── data.yaml (common information about system) | └── system_N
А ниже приведен пример шаблона описания таблицы базы данных, который является источником платформы данных. Для этого шаблона у нас определена каноническая схема в json.
object: name: key_list: — — confidentiality: — confidential — sensitive attibutes: — name: type: — name: type: .
CI/CD pipeline
Применить изменения и выкатить их на окружения нам помогает старина Jenkins.
Понятно, что CI-часть у нас организована в github. При PR происходят достаточно стандартные действия: на Jenkins’е клонируется репозиторий с DIY-метой (в том числе с Jenkinsfile), а затем запускается процесс, определенный в Jenkinsfile, который тестирует изменения, собирает Docker-контейнер с DIY-метой и деплоит его на нужное окружение в зависимости от ветки GIT, в которую были внесены изменения.
Для старта CD pipleline в github настроены webhooks на наш сервер Jenkins, а он знает URL репозитория DIY-меты в github, по которому расположен в том числе Jenkinsfile, содержащий инструкции для исполнения. Базовый образ Docker’а, использующийся для создания контейнера, получаем из нашего Artifactory, пароли получаем из Vault и сохраняем их в переменных окружения.
В процесс деплоя мы внесли ограничения по изменению на ПРОД-окружении. Для изменений в master-ветке (и, соответственно, на ПРОД-окружении сервиса метаданных) пользователям нужен approve их PR от CODEOWNERS, для изменения в dev- или test-ветке (ДЕВ- или ТЕСТ-окружение сервиса) approve не нужен.
Сервис метаданных
Итак, как я уже сказал выше, сервис метаданных — Docker-контейнер, который содержит сами метаданные и предоставляет API для доступа к DIY-мете. Доступ есть только на чтение. Сервис развернут на окружениях, которые соответствуют веткам в GIT: ДЕВ-окружение сервиса использует dev-ветку, ПРОД-окружение использует ветку master.
Первая версия сервиса была реализована на Flask, так как нам был нужен быстрый результат. Позднее, по мере развития работы сервиса, мы портировали его на Go, что повысило производительность и надежность, а также стабилизировали процесс деплоя сервиса.
Автотесты
Поскольку сама DIY-мета хранится в GIT’е, то проверке подвергаются только измененные/добавленные метаданные (git diff нам в помощь). Проверок несколько, приведу основные:
- соответствие соглашению о наименовании файлов и папок DIY-меты;
- соответствие определенных файлов заранее заданной канонической схеме;
- yaml-линтер проверяет на соответствие формату;
- поскольку мы предоставили разработчикам возможность писать собственные тесты, которые запускаются при тестировании изменений, то дополнительно проверяем тесты разработчиков на наличие команд, которые могут потенциально удалить или изменить как метаданные, так и данные.
Надо сказать, автотесты можно использовать также и локально (на машинах разработчиков), и, что примечательно, автотесты работают на разных платформах (Windows, Linux).
Schema evolution
Дополнительно мы определили требования к процессу изменения структуры данных и конкретные инструкции, которым необходимо следовать при такого рода изменениях. В числе прочего коснулись, например, следующих вопросов:
- использование значений по умолчанию для атрибутов/полей объектов данных, что обеспечивает обратную совместимость;
- изменение существующих атрибутов/полей (наименование, тип); такие изменения выполняются путем добавления новых полей; поскольку в конечном итоге данные попадают в таблицы Платформы, такой подход позволяет сохранять историю;
- требования и рекомендации по использованию данных после изменения структуры.
Вместо заключения
В настоящее время результаты наших усилий по созданию DIY-меты пользуются популярностью, что не может нас не радовать.
Так получилось, что все системы и сервисы, которые выполняют обработку данных в интересах платформы и автоматизируют процессы интеграции и предоставления доступа, пользуются DIY-метой: это и Airflow, и Marts Loader, и все процессинги обработки данных. Да, мы разрабатываем системы, которые позволяют автоматизировать процессы интеграции в платформу и ускорить их до нескольких дней, но это уже совсем другая история…
- Блог компании Леруа Мерлен
- Git
- Хранилища данных
- DevOps
- Data Engineering
Источник: habr.com