
В современных вычислительных системах для облегчения сегментации программ и данных используется понятие математической памяти. Математическая память, иначе называемая виртуальной памятью, есть фиктивная память, диапазон адресов которой может превосходить объемфизической оперативной памяти. Математическая память делится на страницы, являющиеся, по существу, сегментами.
Виртуальным называется ресурс, который пользователь или пользовательской программе представляется средствами, которые в реальной действительности виртуальность не обладает. В случае с виртуальной памятью система, обладающая ограниченной физической оперативной памятью, представляется системой с огромной математической оперативной памятью. Виртуализация памяти может быть осуществлена на основе 2-х различных подходов:
В первом случае образ процесса выгружается на диск целиком, во втором – выгружается часть образа процесса.
Виртуальная память может быть представлена 3 способами:
1) страничная: перемещение данных организовывается страницами фиксированного (небольшого) размера (1Kb, 4 Kb);
Топ приложений подготовки к математике | Топскул
2) сегментная: данные перемещаются сегментами, т. е. участками виртуального адресного пространства произвольного размера. Участки выделяются с учетом смыслового значения данных (массивы, структуры, строки загружаются и выгружаются целиком)
3) сегментно-страничная: используется двухуровневое деление памяти: сначала все адреса пространства делятся на сегменты, а потом каждый сегмент делится на страницы. Единица перемещения – страница.
При сегментном распределении памяти для преобразования виртуального адреса процесса в физический строится таблица сегментов (для каждого процесса). В этой таблице указывается:
a. базовый физический адрес сегмента в оперативной памяти,
b. размер сегмента,
c. правила доступа к сегменту,
d. признаки модификации, обращения, присутствия.
Для этого метода программу необходимо разбивать на части и уже каждой такой части выделять физическую память. Естественным способом разбиения программы на части является разбиение ее на логические элементы — так называемые сегменты. В принципе, каждый программный модуль (или их совокупность, если мы того пожелаем) может быть воспринят как отдельный сегмент, и вся программа тогда будет представлять собой множество сегментов. Каждый сегмент размещается в памяти как до определенной степени самостоятельная единица. Логически обращение к элементам программы в этом случае будет состоять из имени сегмента и смещения
относительно начала этого сегмента. Физически имя (или порядковый номер) сегмента будет соответствовать некоторому адресу, с которого этот сегмент начинается при его размещении в памяти, и смещение должно прибавляться к этому базовому адресу. Преобразование имени сегмента в его порядковый номер осуществит система программирования.
Для каждого сегмента система программирования указывает его объем. Он должен быть известен операционной системе, чтобы она могла выделять ему необходимый объем памяти. Операционная система будет размещать сегменты в памяти и для каждого сегмента она должна вести учет о местонахождении этого сегмента. Вся информация о текущем размещении сегментов задачи в памяти обычно сводится в таблицу сегментов, чаще такую таблицу называют таблицей
Что Каждый Программист Должен Знать О Памяти. (с)
дескрипторов сегментов задачи. Каждая задача имеет свою таблицу сегментов. Достаточно часто эти таблицы называют таблицами дескрипторов сегментов, поскольку по своей сути элемент таблицы описывает расположение сегмента. Таким образом, виртуальный адрес для этого способа будет состоять из двух полей — номера сегмента и смещения относительно начала сегмента.
Итак, каждый сегмент, размещаемый в памяти, имеет соответствующую информационную структуру, часто называемую дескриптором сегмента. Именно операционная система строит для каждого исполняемого процесса соответствующую таблицу дескрипторов сегментов, и при размещении каждого из сегментов в оперативной или внешней памяти отмечает в дескрипторе текущее местоположение сегмента.
Если сегмент задачи в данный момент находится в оперативной памяти, то об этом Делается пометка в дескрипторе. Как правило, для этого используется бит присутствия Р (от слова ≪present≫). В этом случае в поле адреса диспетчер памяти записывает адрес физической памяти, с которого сегмент начинается, а в поле длины сегмента (limit) указывается количество адресуемых ячеек памяти. Это поле используется не только для того, чтобы размещать сегменты без наложения друг на друга, но и для того, чтобы контролировать, не обращается ли код исполняющейся задачи за пределы текущего сегмента. В случае превышения длины сегмента вследствие ошибок программирования мы можем говорить о нарушении адресации и с помощью введения специальных аппаратных средств генерировать сигналы прерывания, которые позволят фиксировать (обнаруживать) такого рода ошибки.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Современные системы компьютерной математики

В этой статье вниманию наших читателей предлагается обзор самых популярных математических систем, представленных на российском рынке программного обеспечения.
последнее время в широких кругах пользователей вычислительных машин различного класса стал достаточно популярным и широко используемым термин «компьютерная математика». Данное понятие включает совокупность как теоретических и методических средств, так и современных программных и аппаратных средств, позволяющих производить все математические вычисления с высокой степенью точности и производительности, а также строить сложные цепочки вычислительных алгоритмов с широкими возможностями визуализации процессов и данных при их обработке.
Спрос на универсальные и специализированные программные пакеты для решения различных прикладных задач вызвал появление на рынке программных продуктов систем компьютерной математики, которые быстро стали популярными. На рынке современных математических систем в настоящее время присутствует целый ряд крупных фирм: Macsyma, Inc., Waterloo Maple Software, Inc., Wolfram Research, Inc., MathWorks, Inc., MathSoft, Inc., SciFace GmbH и др. К разработке каждой такой математической системы привлекаются сотни профессионалов из известных университетов и крупных научных центров, а также высококвалифицированные программисты и эксперты в области проектирования сложных программных систем. В результате мы имеем весьма совершенные, гибкие и одновременно универсальные продукты, включающие существенные математические понятия и обладающие богатым набором методов для решения общих математических и научно-технических задач. Именно обзору и краткому анализу таких программных продуктов и посвящена данная статья.
MATLAB
MATLAB — продукт компании MathWorks, Inc.(http://www.mathwork.com/), представляющий собой язык высокого уровня для научно-технических вычислений. Среди основных областей применения MATLAB — математические расчеты, разработка алгоритмов, моделирование, анализ данных и визуализация, научная и инженерная графика, разработка приложений, включая графический интерфейс пользователя.
MATLAB решает множество компьютерных задач — от сбора и анализа данных до разработки готовых приложений. Среда MATLAB соединяет в себе математические вычисления, визуализацию и мощный технический язык.
Встроенные универсальные интерфейсы позволяют легко работать с внешними информационными источниками, а также осуществлять интеграцию с процедурами, написанными на языках высокого уровня (C, C++, Java и др.). Мультиплатформенность MATLAB сделала его одним из самых распространенных продуктов — он фактически стал принятым во всем мире стандартом технических вычислений. MATLAB имеет широкий спектр применений, в том числе цифровую обработку сигналов и изображений, проектирование систем управления, естественные науки, финансы, экономику, приборостроение и т.п. Цена — 2940 долл.
Mathсad
Это интегрированная среда для выполнения, документирования и обмена результатами технических вычислений от компании MathSoft, Inc. (http://www.mathsoft.com/). Данный продукт позволяет пользователям вводить, редактировать и решать уравнения, визуализировать результаты, документировать их, а также обмениваться результатами анализа, отслеживая при этом их размерность. Mathсad служит средством вычислений, анализа и написания отчетов для профессионалов во всех областях науки и техники. Продукт прост в использовании и не вызывает проблем при обучении. Цена — 818 долл.
Maple
Модель памяти в языках программирования
Память — одна из самых сложных тем в информатике, но понимание устройства памяти компьютера позволяет разрабатывать более эффективные программы, а для более низкоуровневого программирования, например, при разработке ОС, это понимание и вовсе является обязательным.
В этой статье будет рассмотрена модель памяти с высокоуровневой точки зрения — виды памяти, аллокаторы, сборщик мусора.
Виды памяти
Существует 3 типа памяти: статический, автоматический и динамический.
Статический — выделение памяти до начала исполнения программы. Такая память доступна на протяжении всего времени выполнения программы. Во многих языках для размещения объекта в статической памяти достаточно задекларировать его в глобальной области видимости.
int // определение статической глобальной переменной int main() < std::cout
Автоматический, также известный как «размещение на стеке», — самый основной, автоматически выделяет аргументы и локальные переменные функции, а также прочую метаинформацию при вызове функции и освобождает память при выходе из неё.
Стек, как структура данных, работает по принципу LIFO («последним пришёл — первым ушёл»). Другими словами, добавлять и удалять значения в стеке можно только с одной и той же стороны.
Автоматическая память работает именно на основе стека, чтобы вызванная из любой части программы функция не затёрла уже используемую автоматическую память, а добавила свои данные в конец стека, увеличивая его размер. При завершении этой функции её данные будут удалены с конца стека, уменьшая его размер. Длина стека останется той же, что и до вызова функции, а у вызывающей функции указатель на конец стека будет указывать на тот же адрес.
Проще всего это понять из примера на С++:
int main() < int a = 3; int result = factorial(a); std::cout int factorial(int n)
Стек при вызове последней рекурсивной функции будет выглядеть следующим образом:
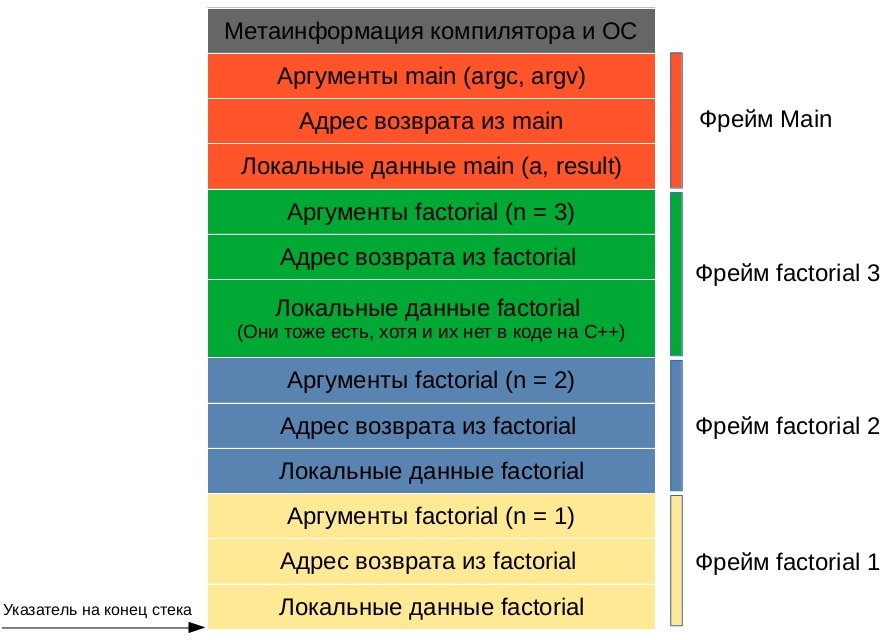
Детали реализации автоматической памяти могут быть разными в зависимости от конкретной платформы. Например, кому очищать из стека метаинформацию функции и её аргументы: вызывающей функции или вызываемой? Как передавать результат: через стек или, что намного быстрее, через регистры процессора (память, расположенную прямо на кристалле процессора. В этой статье не рассматривается, т. к. в языках программирования высокого уровня зачастую нет прямого доступа к регистрам процессора). На все эти вопросы отвечает конкретная реализация calling convention — описание технических особенностей вызова подпрограмм, определяющее способы передачи параметров/результата функции и способы вызова/возврата из функции.
Таким образом, когда одна функция вызывает другую, последняя всегда в курсе, где ей взять свои аргументы: на конце стека. Но откуда ей знать, где конец стека? В процессоре для этого есть специальный регистр, хранящий указатель на конец стека. В большинстве случаев стек расположен ближе к концу виртуальной памяти и растёт в сторону начала.
Размер автоматической памяти, а он тоже фиксированный, определяется линковщиком (обычно — 1 мегабайт), максимальный размер зависит от конкретной системы и настроек компилятора/линковщика.
Если приложение выйдет за максимум автоматической памяти, его там может ждать Page Fault (сигнал SIGSEGV в POSIX-совместимых системах: Mac OS X, Linux, BSD и т. д.) — ошибка сегментации, приводящая к аварийному завершению программы.
Динамическая — выделение памяти из ОС по требованию приложения.
Автоматическая и статическая память выделяются единоразово перед запуском программы. При их нехватке, либо если модель LIFO не совсем подходит, используется динамическая память.
Приложение при необходимости может запросить у ОС дополнительную память через аллокатор или напрямую через системный вызов. Пример использования динамической памяти с помощью аллокатора ниже на примере языка Си.
char *i = malloc(sizeof(char)); // просим у аллокатора память для char if (i != NULL) // аллокатор может вернуть NULL (0) < *i = 120; // делаем что-то с памятью, на которую указывает указатель i printf(«Чтение символа из выделенной памяти: %cn», *i); free(i); // возвращаем память обратно аллокатору >
После выделения памяти в распоряжение программы поступает указатель на начало выделенной памяти, который, в свою очередь, тоже должен где-то храниться: в статической, автоматической или также в динамической памяти. Для возвращения памяти обратно в аллокатор необходим только сам указатель. Попытка использования уже очищенной памяти может привести к завершению программы с сигналом SIGSEGV.
Языки сверхвысокого уровня используют динамическую память как основную: создают все или почти все объекты в динамической памяти, а на стеке или в статической памяти держат указатели на эти объекты.
Максимальный размер динамической памяти зависит от многих факторов: среди них ОС, процессор, аппаратная архитектура в целом, не говоря уже о самом очевидном — максимальном размере ОЗУ у конкретного устройства. Например x86_64 процессоры используют только 48 бит для адресации виртуальной памяти, что позволяет использовать до 256 ТБ памяти. В следующей статье про более низкоуровневую архитектуру памяти будет объяснено, почему не все 64 бита.
Аллокатор
У динамической памяти есть две явные проблемы. Во-первых, любое выделение/освобождение памяти в ОС — системный вызов, замедляющий работу программы. Решением этой проблемы является аллокатор.
Аллокатор — это часть программы, которая запрашивает память большими кусками напрямую у ОС через системные вызовы (в POSIX-совместимых ОС это mmap для выделения памяти и unmap — для освобождения), затем по частям отдаёт эту память приложению (в Си это могут быть функции malloc() / free() ). Такой подход увеличивает производительность, но может вызвать фрагментацию памяти при длительной работе программы.
malloc() / free() и mmap / unmap — это не одно и то же. Первый является простейшим аллокатором в libc , второй является системным вызовом. В большинстве языков можно использовать только аллокатор по умолчанию, но в языках с более низкоуровневой моделью памяти можно использовать и другие аллокаторы.
Например, boost::pool аллокаторы, созданные для оптимальной работы с контейнерами ( boost::pool_allocator для линейных ( std::vector ), boost::fast_pool_allocator для нелинейных ( std::map, std::list )). Или аллокатор jemalloc, оптимизированный для решения проблем фрагментации и утилизации ресурсов CPU в многопоточных программах. Более подробно о jemalloc можно узнать из доклада с конференции C++ Russia 2018.
Способы контроля динамической памяти
Из-за сложности программ очень трудно определить, когда необходимо освобождать память в ОС, и это вторая явная проблема динамической памяти. Если забыть вызвать munmap() или free() , то произойдет следующая ситуация: приложению память уже не нужна, но ОС всё ещё будет считать, что эта память используется программой. Эту проблему называют «утечкой памяти». Существуют несколько способов автоматического или полуавтоматического решения этой проблемы:
RAII (Получение ресурса есть инициализация) — в ООП — организация получения доступа к ресурсу в конструкторе, а освобождения — в деструкторе соответствующего класса. Достаточно реализовать управление памятью в конструкторах и деструкторах, а компилятор вызовет их автоматически. Например, немного урезанный класс String из статьи про Move-семантику. Выделяем память в конструкторе, очищаем в деструкторе:
class String < public: explicit String(const char *const c_string) < size = strlen(c_string) + 1; this->c_string = new char[size]; // выделяем память strcpy(this->c_string, c_string); > ~String() noexcept < delete[] c_string; // очищаем память >private: char *c_string; size_t size; >;
Умные указатели на основе RAII — указатели, автоматически владеющие динамической памятью, то есть автоматически освобождающие её, когда она больше не нужна. Умные указатели инкапсулируют только управление памятью объекта, но не сам объект, как, например, происходит в String, который инкапсулирует объект целиком. Примеры умных указателей ниже.
std::unique_ptr — класс уникального указателя, является единственным владельцем памяти и очищает её в своём деструкторе. Поэтому объекты класса std::unique_ptr не могут иметь копий, но могут быть перемещены. Подробнее о семантике перемещения в этой статье.
std::shared_ptr — класс общего указателя, использующий атомарный счётчик ссылок для подсчёта количества владельцев памяти. В конструкторе счётчик инкрементируется, в деструкторе — декрементируется. Как только счётчик становится равным нулю, память освобождается.
Но у std::shared_ptr есть проблема, например, когда объект A ссылается на объект B, а объект B ссылается на объект A. В таком случае у обоих объектов счётчик ссылок никогда не будет меньше 1 и произойдёт утечка памяти. Решений у этой проблемы два. Использование std::weak_ptr , который ссылается на объект, но без счётчика ссылок, и не может быть разыменован без предварительной конвертации в std::shared_ptr . Вторым решением этой проблемы является сборщик мусора.
Сборка мусора — одна из форм автоматического управления динамической памятью, которая помечает все доступные из стека или статической памяти динамически выделенные объекты. Объекты, до которых нельзя добраться через цепочку указателей, начиная с автоматической или статической памяти, т. е. не помеченные сборщиком мусора, очищаются.
Умные указатели и RAII используются в основном в относительно низкоуровневых языках, например, С++ или Swift. В более высокоуровневых языках обычно используется сборщик мусора (Java), хотя может применяться комбинация умного указателя и сборщика мусора (Python).
У каждого способа управления динамической памятью есть свои плюсы и минусы. В основном приходится жертвовать производительностью программы ради скорости и простоты разработки, либо наоборот: высокая производительность, но и высокая требовательность к программистам, из-за чего вероятность ошибиться при разработке программы выше и медленней сам процесс.
Источник: tproger.ru