
Виртуальные машины для обработки и анализа данных Azure (DSVM) включают комплексный набор примеров кода. Эти примеры содержат записные книжки и сценарии Jupyter на таких языках, как Python и R.
Дополнительные сведения о том, как запустить записные книжки Jupyter на виртуальных машинах для обработки и анализа данных, см. в разделе Доступ к Jupyter.
Предварительные требования
Доступные примеры
| Язык Python | В примерах рассматриваются такие сценарии, как подключение к облачным хранилищам данных на основе Azure и работа с Машинным обучением Azure. Язык Python |
~notebooks |
Доступ к Jupyter
Доступ к Jupyter можно получить, щелкнув значок Jupyter на рабочем столе или в меню приложения. Также можно получить доступ к Jupyter с помощью Linux Edition виртуальной машины для обработки и анализа данных. Для удаленного доступа из веб-браузера перейдите к https://:8000 в Ubuntu.
Введение в Машинное Обучение (Машинное Обучение: Zero to Hero, часть 1)
Чтобы добавить исключения и получить доступ к Jupyter через браузер, ознакомьтесь со следующим руководством:

Войдите в систему, используя тот же пароль, который вы используете для входа на виртуальную машину для обработки и анализа данных.

Домашняя страница Jupyter
Источник: learn.microsoft.com
Принцип машинного обучения

Однако что будет, если зубная паста придет к роботу в испорченном виде или просто будет положена перед ним под непривычным углом. Если такая ситуация не прописана в программе, робот не справится с поставленной задачей. Он либо упакует некачественный товар, либо вообще запечатает пустую коробку.
На этом этапе обычный компьютер упирается в предел своих возможностей.
В какой-то момент люди подумали, что можно «на ходу» адаптировать компьютерную программу под реалии окружающего мира. В таком случае, программа сможет более гибко реагировать на разнообразие происходящих в мире событий. Но как это сделать?
Как обучить машину: пример кредитного скоринга
Рассмотрим пример кредитного скоринга.
Когда человек хочет взять кредит в банке, кредитный менеджер должен решить, надежный это заемщик или нет. У хорошего кредитного менеджера довольно высокая зарплата и конечно руководству банка хочется эту задачу автоматизировать и заменить человека машиной.
Распознавание объектов на Python / Глубокое машинное обучение

Пробуем традиционный алгоритм
Решая «в лоб» задачу автоматизации, можно взять все критерии надежности (возраст, стаж, доход, кредитную историю и т.д.) и явно прописать условия, в каких случаях выдавать займ, а в каких нет.
Но тут возникает проблема. Если, допустим, мы зададим порог дохода в 90 000 ₽, то окажется, что вполне надежному заемщику с зарплатой в 89 000 ₽ мы кредит не выдадим. С другой стороны, человек с зарплатой в 91 000 ₽ может не вернуть кредит. Получается то же самое, что с роботом и положенной криво зубной пастой.
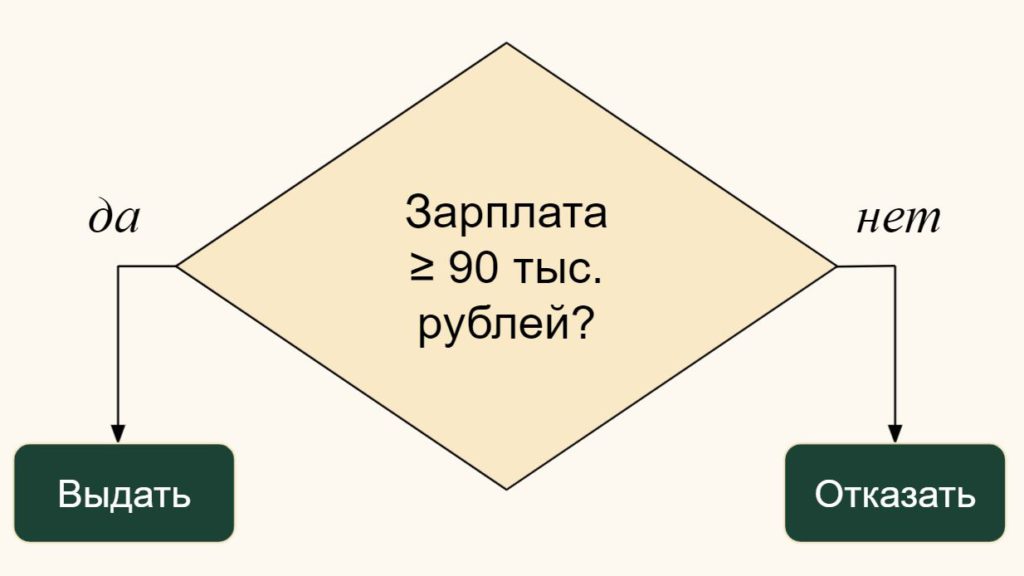
Так не пойдет, нужно попробовать что-то другое.
Озарение
Занимавшиеся этой проблемой математики подумали, что, наверное, каждый следующий приходящий в банк заемщик имеет что-то общее с предыдущими посетителями. Если так, то должен быть способ использовать знания о предыдущих заемщиках таким образом, чтобы предсказать вероятность возврата денег новым клиентом.
Другими словами, нужно взять исторические данные и с их помощью каким-то образом построить модель, которая не наугад, а математически предскажет возврат кредита новым клиентом.
Посмотрим, как это можно сделать.
Создаем алгоритм машинного обучения
С новым подходом мы можем задать для каждого критерия определенный коэффициент значимости или, как часто говорят, вес. Например, уровню дохода задать вес 0,2, а стажу — 0,35. Таким образом, чем выше доход, тем выше рейтинг заемщика, то же самое со стажем.
На практике это выглядит следующим образом. Если человек имеет 7 лет стажа, то модель прибавит к рейтингу 7 х 0,35 или 2,45 балла, если стаж только 4 года, то рейтинг вырастет на 4 х 0,35 или 1,4 балла.
Веса также могут быть отрицательными. Тогда рейтинг будет снижаться.
Строим уравнение
Если мы возьмем все интересующие нас критерии, то получим уравнение, где на входе мы вводим параметры нового заемщика (x1, x2,…, xn) с определенными весами (w0, w1, w2,…, wn), а на выходе получаем его рейтинг (y).
$$ y = w_1 times x_1 + w_2 times x_2 + … + w_n times x_n + w_0 $$
С таким уравнением вы уже познакомились на прошлом занятии.
Что нам даст это уравнение? Если мы подберем «правильные» веса (ведь вы помните, что веса это просто числа), то подставляя вместо (x1, x2,…, xn) критерии заемщика (возраст, стаж), мы получим некоторую оценку его надежности.
Приведу пример уравнения с уже подставленными весами:
y = (3,4 x возраст) + (0,35 х стаж) + (0,2 х доход) + (0,11 х кредитная история) − 13
Итак, мы получили модель надежности заемщика. Казалось бы, бери и пользуйся. Теперь все кредитные менеджеры должны остаться без работы. Но тут есть одна проблема. Мы взяли случайные веса.
Очевидно, что в реальности так делать нельзя. Но тогда как их найти?
Используем имеющиеся данные
Процесс подбора весов начнем с того, что, как мы и планировали, посмотрим на уже имеющиеся данные о заемщиках. Такие данные проще всего представить в виде таблицы:

Каждая колонка, кроме первой и последней — это те самые критерии (наши x из уравнения). В последнем столбце зафиксирован результат — вернул человек кредит или нет.
Что нам с этими данными делать?
Ищем веса
Оказывается, мы можем запустить на компьютере специальный алгоритм, его еще называют алгоритмом оптимизации, который подберет нам такие веса, которые максимально «уложатся» или будут соответствовать имеющимся данным о каждом предыдущем заемщике.
О том как работает эта магия оптимизации, мы поговорим во втором разделе курса.
Другими словами, алгоритм оптимизации поможет обучить нашу модель (уравнение, которое мы построили выше) на данных Ивана Ивановича и Ивана Петровича. Отсюда собственно и название дисциплины — «машинное обучение». Машина учится на исторических данных, чтобы предсказывать что-то новое.
Предположим, что после оптимизации наши веса выглядят вот так:
y = (1,7 x возраст) + (0,35 х стаж) + (0,2 х доход) + (0,45 х кредитная история) − 20
Как мы видим, веса изменились.
Проверяем модель на имеющихся данных
Чтобы убедиться в правильности подобранных весов, мы можем подставить в уравнение известные нам данные. Иван Иванович:
(1,7 x 0) + (0,35 х 4 года) + (0,2 х 75 тыс. рублей) + (0,45 х 4 пункта) − 20 = −1,8
(1,7 x 1) + (0,35 х 7 лет) + (0,2 х 95 тыс. рублей) + (0,45 х 8 пунктов) − 20 = 6,75
То есть с подобранными нами весами и нулевым пороговым значением Иван Иванович не получит кредит (−1,8 < 0), а Иван Петрович пойдет в автосалон покупать новую машину (6,75 >0).

Все, модель обучилась и готова заменить человека.
Выдавать ли кредит новому заемщику?

Теперь, когда к нам придет новый заемщик, пусть это будет Алексей, и его рейтинг на основе модели составит 3,05 балла, модель самостоятельно без помощи кредитного менеджера выдаст Алексею кредит (ведь 3,05 > 0).
(1,7 x 1) + (0,35 х 6 лет) + (0,2 х 85 тыс. рублей) + (0,45 х 5 пунктов) − 20 = 3,05
Подведем итог
Повторим, какие шаги нужно выполнить для обучения модели:
- Выделяем важные для нас критерии (возраст, стаж и т.д.)
- Составляем уравнение с этими критериями и пока еще неизвестными весами
- Берем имеющися исторические данные
- Запускаем алгоритм оптимизации и ищем веса, которые максимально «укладываются» в наши данные
- Подставляем веса в модель
- На все тех же имеющихся данных проверяем качество модели
- Используем модель в работе с новыми данными
Что еще важно. В отличие от обычной компьютерной программы и, кстати, в отличие от человека, наша модель при настройке («обучении») может учитывать десятки тысяч заемщиков (не только Ивана Ивановича и Ивана Петровича), а также десятки признаков этих заемщиков (а не только возраст, стаж, доход и кредитную историю).
На основе этих данных модель способна делать очень точные предсказания. Часто гораздо более точные, чем даже самый опытный кредитный менеджер.
В этом и заключается принцип машинного обучения.
Вопросы для закрепления
Какие данные используются для обучения модели, новые или уже имеющиеся?
Посмотреть правильный ответ
Ответ: уже имеющиеся (Иван Иванович и Иван Петрович)
Как называется процесс подбора весов уравнения (модели)?
Посмотреть правильный ответ
Какие данные используются для предсказания, новые или уже имющиеся?
Посмотреть правильный ответ
Ответ: новые (Алексей)
Приведенный выше пример построения модели — учебный. Однако теперь, я надеюсь, у вас есть понимание того, какую цель преследуют все последующие занятия.
Для создания настоящих моделей, нам в первую очередь нужно разобраться с необходимым ПО.
Ответы на вопросы
Вопрос. Модель классификации, которую вы используете в качестве примера, она действительно существует?
Ответ. Да, это настоящая модель, называется «логистическая регрессия», правда упрощённая и слегка укороченная. Ее мы будем подробно изучать на более продвинутых курсах.
Для того чтобы стать полноценной моделью этому уравнению, по большому счету, не хватает (1) сигмоиды, то есть функции, которая превратила бы рейтинг заёмщика (на графике ниже он отложен по оси x) в вероятность от 0 до 1 (ось y).
Если кредитный рейтинг отрицательный, то вероятность меньше 0,5, и мы относим этот случай к нулевому классу. Если балл положительный, наоборот.

Также необходимо добавить (2) функцию потерь, которая в тексте занятия для простоты скрыта за словами «магия оптимизации».
Опять же в дальнейшем я планирую обо всем этом подробно рассказать. Пока эти детали только запутают.
Вопрос. Откуда в примере 1 появилась постоянная е = −13, а во втором примере с оптимизацией эта величина равна е = −20?
Ответ. Конкретно в этих примерах я просто подогнал константы под нужные мне итоговые значения, чтобы показать работу модели.
На практике веса до оптимизации (включая, в данном случае, константу −13) берутся случайно, после оптимизации (в том числе значение −20) — находятся в процессе обучения модели.
Подбор оптимальных весов будет подробно разобран на курсе по оптимизации.
UPD: константа переименована в w0.
Источник: www.dmitrymakarov.ru
Машинное обучение пример программы

Комментарии
Популярные По порядку
Не удалось загрузить комментарии.
ЛУЧШИЕ СТАТЬИ ПО ТЕМЕ
ТОП-15 книг по Python: от новичка до профессионала
Книги по Python (и связанным с ним специальным темам) на русском языке. Расставлены в порядке возрастания сложности, обобщены указанные читателями преимущества и недостатки.
DeepFake-туториал: создаем собственный дипфейк в DeepFaceLab
Рассказываем о технологии DeepFake и шаг за шагом учимся делать дипфейки в DeepFaceLab – нейросетевой программе, меняющей лица в видеороликах.
Пишем свою нейросеть: пошаговое руководство
Отличный гайд про нейросеть от теории к практике. Вы узнаете из каких элементов состоит ИНС, как она работает и как ее создать самому.
Источник: proglib.io