
Оптимизация – это метод преобразования программы, который пытается улучшить код, заставляя его потреблять меньше ресурсов (т. Е. ЦП, память) и обеспечивать высокую скорость.
При оптимизации общие программные конструкции высокого уровня заменяются очень эффективными низкоуровневыми программными кодами. Процесс оптимизации кода должен следовать трем правилам, приведенным ниже:
- Выходной код никоим образом не должен изменять значение программы.
- Оптимизация должна увеличить скорость программы и, если возможно, программа должна потреблять меньше ресурсов.
- Оптимизация должна быть быстрой и не должна задерживать весь процесс компиляции.
Выходной код никоим образом не должен изменять значение программы.
Оптимизация должна увеличить скорость программы и, если возможно, программа должна потреблять меньше ресурсов.
Оптимизация должна быть быстрой и не должна задерживать весь процесс компиляции.
Усилия по оптимизации кода могут быть предприняты на разных уровнях компиляции процесса.
Сборка проекта С++
- В начале пользователи могут изменять / переставлять код или использовать лучшие алгоритмы для написания кода.
- После генерации промежуточного кода компилятор может модифицировать промежуточный код путем вычисления адресов и улучшения циклов.
- При создании целевого машинного кода компилятор может использовать иерархию памяти и регистры процессора.
В начале пользователи могут изменять / переставлять код или использовать лучшие алгоритмы для написания кода.
После генерации промежуточного кода компилятор может модифицировать промежуточный код путем вычисления адресов и улучшения циклов.
При создании целевого машинного кода компилятор может использовать иерархию памяти и регистры процессора.
Оптимизацию можно разделить на два типа: машинно-независимый и машинно-зависимый.
Машинно-независимая оптимизация
При этой оптимизации компилятор принимает промежуточный код и преобразует часть кода, которая не включает какие-либо регистры ЦП и / или абсолютные ячейки памяти. Например:
do item = 10; value = value + item; > while(value100);
Этот код включает в себя повторное присвоение идентификатора элемента, который, если мы скажем так:
Item = 10; do value = value + item; > while(value100);
Следует не только сохранять циклы процессора, но и использовать его на любом процессоре.
Машинно-зависимая оптимизация
Машинно-зависимая оптимизация выполняется после того, как целевой код был сгенерирован, и когда код преобразуется в соответствии с архитектурой целевой машины. Он включает регистры ЦП и может иметь абсолютные ссылки на память, а не относительные ссылки. Машинно-зависимые оптимизаторы прилагают усилия, чтобы максимально использовать иерархию памяти.
Основные блоки
Исходные коды обычно имеют ряд инструкций, которые всегда выполняются последовательно и рассматриваются как основные блоки кода. В этих базовых блоках нет операторов перехода, т. Е. Когда выполняется первая инструкция, все инструкции в одном и том же базовом блоке будут выполняться в их последовательности появления без потери управления потоком программы.
Вадим Винник — Декларативное метапрограммирование: обработка списков на этапе компиляции
Программа может иметь различные конструкции в качестве базовых блоков, таких как условные операторы IF-THEN-ELSE, SWITCH-CASE и циклы, такие как DO-WHILE, FOR и REPEAT-UNTIL и т. Д.
Идентификация основного блока
Презентация на тему Лексер. Парсер. (Часть 2)

символ не из алфавита
Цепочка — последовательность символов
Терминальная цепочка – цепочка, состоящая из терминальных символов
Язык – множество терминальных цепочек
Пример грамматики:
S->aQbZ
Q->ab | cc | Qd
Z -> aQa | c | ε
Строгие определения. Грамматики.

Слайд 8Тип 0: неограниченные
Тип 1: контекстно-зависимые / неукорачивающие
Тип
2: контекстно-свободные
Тип 3: регулярные: праволинейные/леволинейные
Классификация грамматик по

Слайд 9Регулярные грамматики:
праволинейные (A → w, A →
wB, A,B ∈ N, w ∈ T*)
леволинейные
(A → w, A → Bw, A,B ∈ N, w ∈ T*)
Контекстно-свободные грамматики:
(A → w, A ∈ N, w ∈ (T U N)*)
Строгие определения. Типы грамматик.

Слайд 10Тип 0 (неограниченные): естественные языки:
Русский
Английский
Тип 2 (контекстно-свободные):
большинство языков программирования:
Java
С++
Тип 3: (регулярные): описание отдельных
лексем в языках программирования:
Идентификатор
Числовая константа
Соответствие языков и грамматик

Слайд 11Тип 2 контекстно – свободная грамматика:
может быть
описана с помощью конечного автомата с магазинной
памятью
Используется для анализа последовательности токенов синтаксическим анализатором
Тип 3 регулярная грамматика:
Может быть описана с помощью конечного автомата
Используется для формирования лексемы лексическим анализатором
Способы разбора грамматик

Слайд 12 Недетерминированный
Детерминированный
Строгие определения. Конечные автоматы с магазинной
памятью.

Слайд 13Нисходящий анализ
Метод рекурсивного спуска (парсер с возвратом)
Предиктивный
анализатор (предсказывающий анализатор) (LL анализатор)
Восходящий анализ (LR
анализатор)
Варианты синтаксического анализа

Слайд 14id + id * id
Дерево разбора
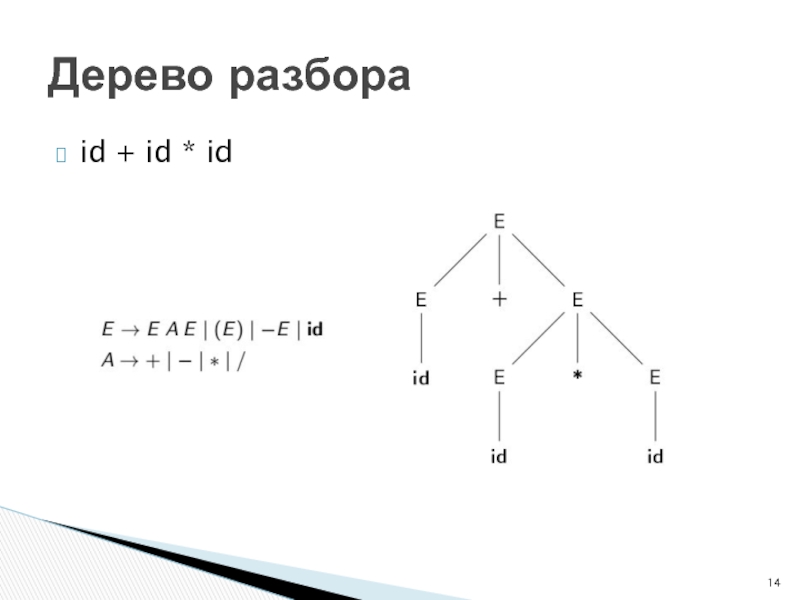
Слайд 15Дерево разбора строится сверху вниз, слева направо
Токены
от лексера рассматриваются в порядке поступления
Метод рекурсивного

Слайд 16Каждому нетерминалу соответствует процедура, в которую жёстко
зашиты продукции данного нетерминала
Процедура последовательно сравнивает пришедшие
токены с терминалами продукций
Если ни одна продукция не подходит – ошибка
Если встречается нетерминал управление переходит в процедуру нетерминала
Метод рекурсивного спуска

Слайд 17
Пример применения метода рекурсивного спуска
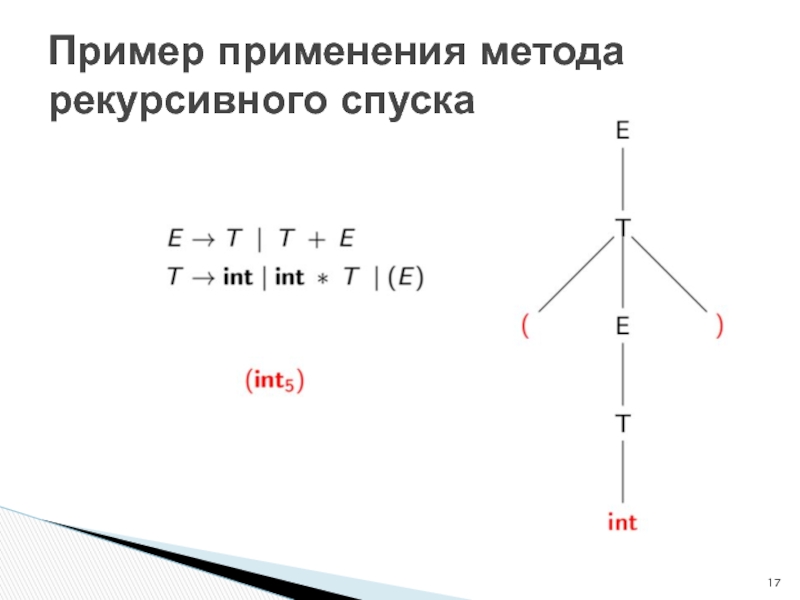
Слайд 18Грамматика жёстко зашита в алгоритм. В последующих
алгоритмах на основании грамматики строятся таблицы
Алгоритм выполняется
за экспоненциальное время
Алгоритм может зацикливаться
Использование неявного стека
Рекурсивный спуск, минусы

Слайд 19Идея – убрать откатывание. По каждому символу
должно быть изначально ясно куда переходим.
левой рекурсии
Левая факторизация
Вычисление множеств
FIRST
FOLLOW
Составление таблицы

Слайд 20Удаление левой рекурсии
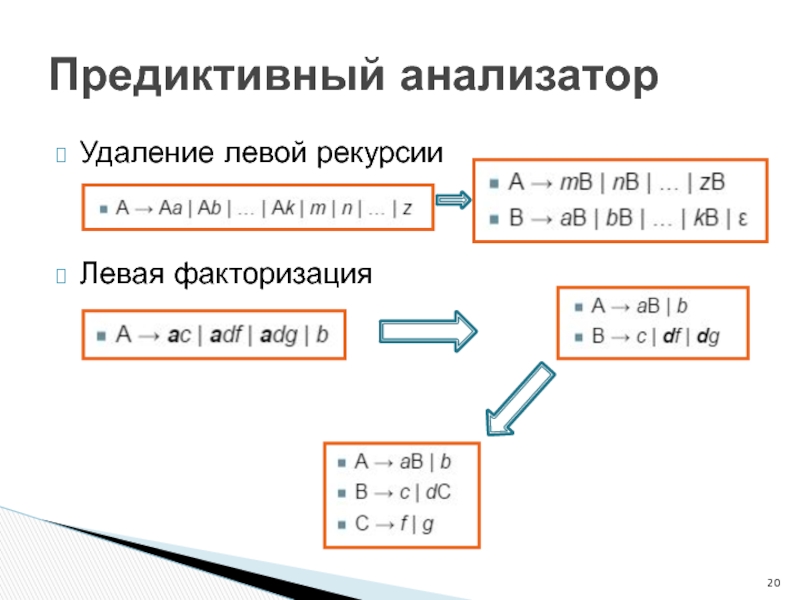
Слайд 21Пример преобразования
грамматики:
Предиктивный анализатор

Слайд 22Определение множества FIRST
FIRST(a), a∈(N⋃T)* — множество терминалов
или ℇ, с которых может начинаться а.
Построение
множества FIRST

Слайд 23Определение множества FOLLOW
FOLLOW(A), A∈N – множества терминалов,
которые могут появиться сразу за А, включая
концевой маркер $
Построение множества FOLLOW

Слайд 24Пример построения FIRST, FOLLOW
Предиктивный анализ

Слайд 25Построение таблицы
Предиктивный анализ

Слайд 26Пример построения таблицы
Предиктивный анализ

Слайд 27
Предиктивный анализ, разбор

Слайд 28
Предиктивный анализ, пример
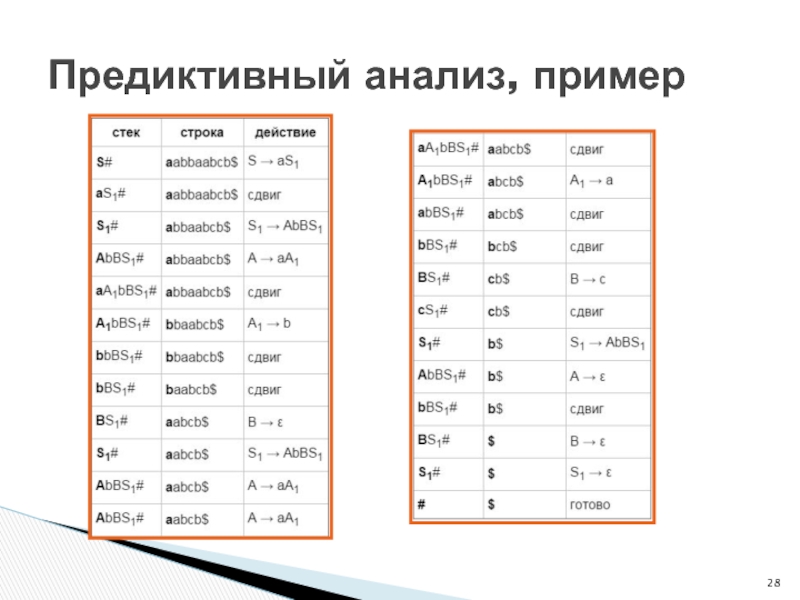
Слайд 29Строим дерево разбора начиная с листьев
Для большинства
языков программирования можно построить LR грамматику
Наиболее общий
метод анализа без отката
Существуют генераторы LR анализаторов

Слайд 30Построение LR(1) анализатора
1. Пополнение грамматики
2. Построение канонической
системы множеств допустимых LR(1)-ситуаций
3. Построение таблицы анализатора
3.1 Построение таблицы Goto
3.2 Построение таблицы Actions
4. Разбор цепочки

Слайд 31Пополнение грамматики
Добавим новое правило S’ → S,
и сделаем S’ аксиомой грамматики.
Допуск имеет место
⬄ когда возможно осуществить свёртку по правилу S → S’.

Слайд 32Каноническая система множеств
Вначале имеется множество I0 с конфигурацией
анализатора S’ → .S, $
К этой конфигурации
применяется операция закрытия до тех пор, пока в результате её применения не перестанут добавляться новые конфигурации.
Строятся переходы в новые множества путём сдвига точки на один символ вправо

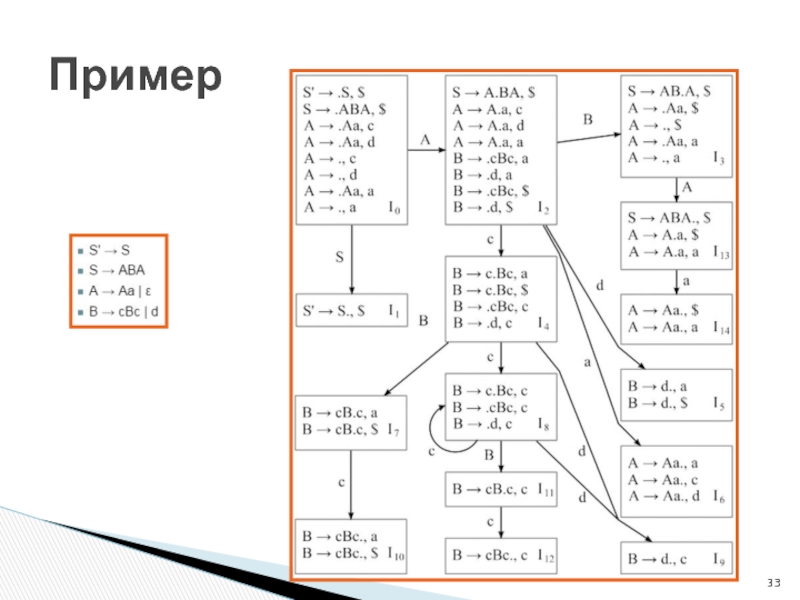
Слайд 33
Пример
Слайд 34Построение Goto
Eсли в канонической системе множеств есть
переход из Ii в Ij по символу A, то в Goto(Ii,
A) мы ставим состояние Ij. После заполнения таблицы полагаем, что во всех пустых ячейках Goto(Ii, A) = Error
После заполнения таблицы полагаем, что во всех пустых ячейках Goto(Ii, A) = Error

Слайд 35Построение action
Если есть переход по терминалу a
из состояния Ii в состояние Ij, то Action(Ii,
a) = Shift(Ij)
Если A ≠ S’ и есть конфигруация A → α., a, то Action(Ii, a) = Reduce(A → α)
Для состояния Ii, в котором есть конфигурация S’ → S., $, Action(Ii, $) = Accept
Для всех пустых ячеек Action(Ii, a) = Error
Источник: thepresentation.ru
Компиляторы
Аннотация: В этой лекции даются основные факты о назначении компиляторов, их работе и возможностям автоматической оптимизации.
Ключевые слова: транслятор, компилятор, корректность
Презентацию к данной лекции Вы можете скачать здесь.
Компиляция — первый шаг в создании процесса
От исходного текста программы к процессу (Linux)
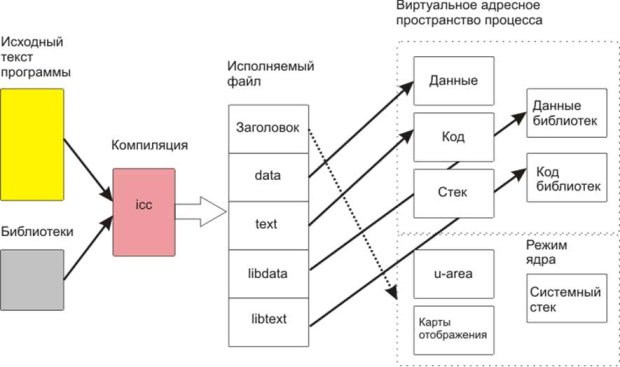
Транслятор выполняет преобразование программы, написанной на одном языке программирования в программу на другом языке программирования.
Компилятор выполняет преобразование программы, написанной на языке программирования (как правило, высокого уровня) в программу на языке машинного уровня.
Результат трансляции и компиляции должны быть эквивалентны исходным программам – прежде всего, должна сохраняться корректность алгоритма.
Основные фазы компиляции

Лексический анализ — включает распознавание лексем языка программирования, замену их соответствующими кодами.
Лексемы — элементарные единицы, наделенные определенным «смыслом» и входящие в структуру предложения языка (ключевые или зарезервированные слова, константы, имена и т.д.).
Синтаксический анализ — проверка правильности использования предложений языка в соответствии с его грамматикой. Остальные фазы компиляции выполняются только при отсутствии синтаксических ошибок.
Трансляция кода в промежуточную форму — преобразование программы в матрицу промежуточного кода. Каждая строка матрицы содержит тройку: код операции и два операнда. Промежуточные коды не имеют прямых аналогов в системе машинных команд, поэтому данную форму представления программы называют машинно-независимой.
Оптимизация — уменьшение избыточности программы по затратам процессорного времени и памяти. Пользователь может управлять процессом оптимизации, используя подходящие сочетания ключей (опций) оптимизации.
Распределение памяти — определение объемов памяти каждого вида, используемого в программе. На этом этапе в матрицу промежуточного кода вносятся коды резервирования памяти . Каждая программа использует по крайней мере два вида памяти: статическую — для размещения данных и кодов программы, и стековую — для обращения к подпрограммам.
Генерация кода — подстановка кодовых образцов на выходном языке, соответствующих промежуточным кодам программы. Выполняется машинно-зависимая оптимизация программы – с учетом особенностей архитектуры целевой платформы.
Лексический анализ
Функции лексического анализатора:
- ввод строк исходной программы;
- распознавание лексем;
- заполнение таблиц идентификаторов и литералов;
- печать листинга исходной программы.
Лексический анализатор (сканер, лексер) учитывает особенности языка программирования. Это включает форматирование исходного текста, интерпретацию пробелов и т.д.
Лексический анализатор использует:
- исходный текст программы;
- таблицу терминальных символов;
- таблицу литералов;
- таблицу идентификаторов.
Таблица терминальных символов — таблица, содержащая терминальные символы языка, коды лексем и другую информацию.
Таблица символических имен — таблица, содержащая имена переменных, их тип, значение и другую информацию.
Таблица литералов — таблица, содержащая литералы (константы), их тип и другую информацию. Литералу выделяется ячейка памяти, в которую записывается константа. Далее все появления этого литерала заменяются обращениями по адресу этой ячейки.
Результат работы сканера — последовательность кодов лексем. Код лексемы представляется кодом таблицы и спецификатором. Спецификатор задает номер строки в таблице, куда занесена лексема.
Синтаксический анализ
Синтаксис и семантика.
Синтаксис — множество правил, описывающих структуру предложений языка (порядок следования лексем). Речь идет о формальной структуре предложений, а не о смысле.
Семантика — множество правил интерпретации смысла предложения.
Синтаксический анализ — построение дерева грамматического разбора обрабатываемого текста. Текст состоит из предложений.
Результат анализа исходного предложения в терминах грамматических конструкций представляется в виде дерева. Такие деревья обычно называются деревьями грамматического разбора или синтаксическими деревьями.
Таблица терминальных символов — таблица, содержащая терминальные символы языка, коды лексем и другую информацию.
Таблица символических имен — таблица, содержащая имена переменных, их тип, значение и другую информацию.
Таблица литералов — таблица, содержащая литералы (константы), их тип и другую информацию. Литералу выделяется ячейка памяти, в которую записывается константа. Далее все появления этого литерала заменяются обращениями по адресу этой ячейки.
Результат работы сканера — последовательность кодов лексем. Код лексемы представляется кодом таблицы и спецификатором. Спецификатор задает номер строки в таблице, куда занесена лексема.
Оптимизирующие преобразования
Использование возможностей автоматической оптимизации компилятора может дать значительный выигрыш в производительности
Удаление общих подвыражений
Если одно и то же подвыражение встречается несколько раз, компилятор может вычислить его один раз, а все последующие включения заменяются вычисленным значением:
a = (b+35) * (b+35); c = 12.0 * (b+35);
в результате удаления общего подвыражения превращается в следующий:
tmp = b + 35; a = tmp * tmp; c = 12.0 * tmp;
Развертка цикла
Развертка заключается в преобразовании цикла в линейную последовательность операций. Выигрыш в производительности достигается благодаря снижению накладных расходов на организацию цикла. Эффективным этот прием может быть в случае, когда тело цикла очень маленькое:
ifor (i = 0; i < 2; i++) a[i] = 2.0 * d[i];
Источник: intuit.ru