
Говорим о словах: ключевых и не только. LSI — что это, зачем нужно и нужно ли вообще? Какими инструментами пользоваться? А также мы дадим несколько советов от наших SEO-специалистов.
- Что такое LSI-фразы?
- А теперь немного истории
- Принципы LSI копирайтинга
- Почему LSI важны для SEO?
- Ранжирование страниц с LSI-оптимизацией и без
- Где взять LSI-семантику?
- Инструменты и онлайн сервисы для поиска и подбора LSI фраз
- Чем пользуемся мы?
- Четыре (крутых!) совета от наших SEOшников: LSI-фразы и слова
Что такое LSI-фразы?
LSI-ключи — это не только синонимы, это фразы и слова, которые связаны с основным семантическим запросом.
А теперь немного истории
Когда Google запустил алгоритм “Панда”, тогда появилась фраза “LSI” да и само понятие тоже. Но особое внимание к LSI появилось с запуском алгоритма “Колибри”. Тогда Гугл совершил прорыв в области семантического поиска. С того момента система начала оценивать контент не только по количеству ключевых слов в тексте, но и по смысловому наполнению нужным контентом.
LSI копирайтинг, что это?
То есть поисковая система не просто следит за количеством ключевиков, но и анализирует контекст материала, чтобы он был релевантен теме.
А пример будет? Конечно!
Пишем запрос “заказать день рождения ребенку”, и нам выходят страницы, где есть информация о заказе праздника для ребенка. Система начинает собирать страницы и формировать выдачу с помощью LSI-фраз (и не только!).

Оптимальное время загрузки страницы — 3-4 секунды. Все, что больше — уже не очень хорошо. Но имейте в виду, что для очень нагруженных страниц скорость загрузки может отличаться в сторону увеличения. В этом случае, чтобы понять, на сколько вы “в тренде”, нужно посмотреть скорость загрузки сайтов конкурентов и высчитать средний показатель.
Принципы LSI копирайтинга
Мы уже разобрались, что LSI-контент — это не просто набор ключевых слов, это ответ на замаскированный пользовательский запрос. То, что вбивает пользователь в строку поиска есть его вопрос, просто формулируется он иначе.
Каким принципам нужно следовать для создания качественного текста с LSI-фразами?
- Уберите все пустые слова (вводные, конструкции “для красоты” и так далее). Текст должен нести информацию, это его главная задача. Конечно, стоит обращать внимание и на стратегию продвижения, и каким языком вы общаетесь с аудиторией.
- Добавляйте жизнь в LSI-фразы. “Заказать праздник самара” звучит не очень естественно, поэтому сделайте фразу более понятной для читателя. Например, “заказать детский праздник в самаре на выходные”.
- Разбавляйте текст не только синонимами, но и словами, подходящими под тематику запроса. Например, для детских праздников это: “веселый”, “год”, “организация”.
- Задавайте себе вопросы: Есть ли полезная информация в предложении? Говорим ли мы такими фразами в настоящей жизни? Если отвечаете на оба вопроса положительно, то LSI-текст готов.
Мы советуем собирать LSI-фразы с помощью специальных инструментов (о них расскажем чуть позже) и отдавать их копирайтерам “на распределение”. Да, хороший текст с точки зрения LSI будет содержать значительное количество ключей, так как развернутый ответ на запрос пользователя всегда содержит ключевики. Но все же какие-то фразы могут быть упущены из взора “писателя для SEO”.
Урок 13. Что такое SEO и LSI текста, и как их использовать | Курс «Копирайтинг с нуля за 30 дней»

Помните, что для поднятия сайта в выдаче с помощью LSI важно не количество, а качество вхождений. Достаточно одного употребления ключевого слова, но похожих по запросу слов должно быть много.
Что такое контент маркетинг
Почему LSI важны для SEO?
Яндекс и Google с каждым годом становятся всё “умнее” — стараются выдавать все более и более полезный контент пользователям. То есть юзер видит в топе выдачи не столько страницы с ключевиками, сколько полезный и качественный контент.
Поисковые системы анализируют полезность контента, чтобы определить, что страница сайта подходит под запрос пользователя. Иначе говоря, система смотрит релевантность страницы. Она оказывает огромное влияние на позиции сайта.
Ранжирование страниц с LSI-оптимизацией и без
- сайт поднимается в выдаче
- меньший риск попадания под фильтры
- расширяется семантическое ядро
- улучшаются поведенческие факторы
Нужно понимать, что страницы без ключевых запросов (что, конечно, не очень возможно) не будут так хорошо продвигаться системой. То есть вы можете потерять все преимущества, указанные выше.
Владельцы стартапов и локальных бизнесов, у которых еще нет сформированного бренда в интернете, должны понимать, что тексты, наполненные LSI-фразами и словами “нравятся” системе. Чем больше оптимизированных страниц, тем лучше. Если страницы созданы под разные запросы, это увеличивает количество потенциальных посетителей сайта.

Где взять LSI-семантику для seo текста?
- Соберите маркерные запросы
Это фундамент семантического ядра. Для любой коммерческой страницы, например для сайта по организации детских праздников, нужен костяк семантики. В нашем случае это “организовать детский праздник”, “детский день рождения в самаре” и так далее.
Маркерные вопросы сократить не получится, ведь если уберете хотя бы одно слово, то поисковая система уже не сможет понять, под какой запрос ей выдавать вашу страницу.
- Найдите конкурентов вашей страницы и соберите LSI-фразы
Для этого можно использовать специальные инструменты, которые покажут ТОП-10 конкурентов и пояснят, какие слова наиболее часто употребляются на этих ресурсах. Так можно составить семантическое ядро для вашего текста.
Инструменты и онлайн сервисы для поиска и подбора LSI фраз
- Подсказки в поисковиках
Берем поисковой запрос “заказать детский день рождения в самаре” и изучаем предлагаемые Google и Яндекс подсказки.

- Яндекс. Вордстат
Вводим актуальный запрос, а платформа показывает популярные запросы по этой теме. В качестве lsi фраз хорошо подойдут низкочастотные запросы.

- Сниппеты в ТОП-10
Посмотрите на маленькие текстовые фрагменты и определите общие слова и фразы.

- MegaIndex
Необходимо просто вбить актуальный запрос и регион поиска при необходимости, а система самостоятельно найдет синонимы и расширяющие тематику слова.

- Pixel Tools
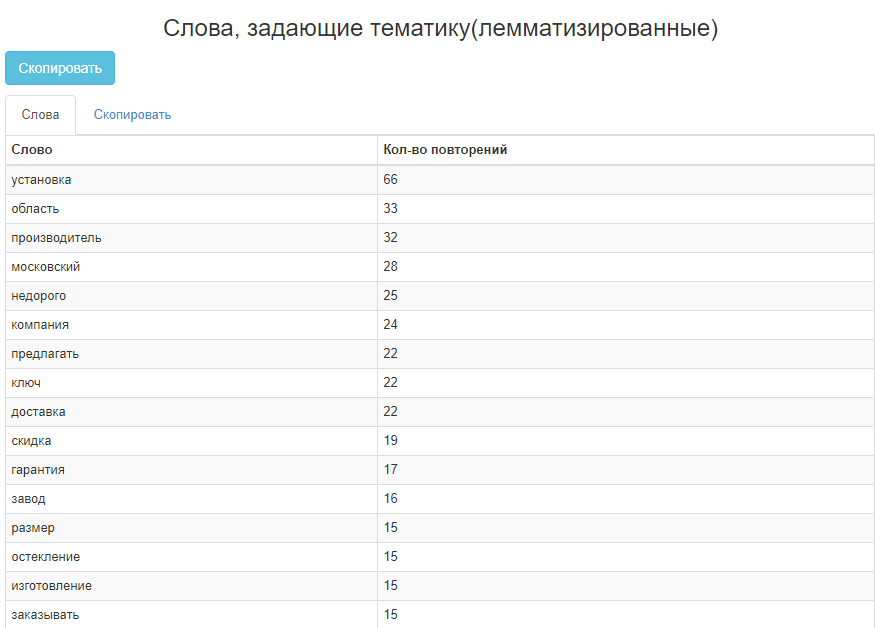
Инструмент показывает уникальные слова и стоп-слова. Слова, задающие тематику, то, что нам нужно. Это те самые LSI-фразы, которые помогают сделать текст более релевантным.

- ARSENKIN TOOLS
Этот инструмент парсит поисковые подсказки из выдачи по заданным ключам.

- Serpstat
Показывает LSI-фразы, опираясь на 20 популярных сайтов в выдаче по актуальному запросу.

- Ultimate Keyword Hunter
Похож на все остальные описанные выше инструменты. Отличается тем, что имеет встроенный текстовый редактор, который показывает количество необходимых ключевых слов и фраз в процентах в конкретном тексте.

- Google Search Console
В разделе “Эффективность” выбираем период, например 6 месяц, и добавляем страницу для анализа. Ниже появляются запросы, по которым пользователи находили сайт в выдаче. Эти запросы и являются LSI-фразами.

- Яндекс. Вебмастер
В разделе “Поисковые запросы” заходим в “Статистику запросов”, выбираем “Популярные запросы” и выставляем любой период. Затем появляются запросы, по которым сайт находили в выдаче. Можно выгрузить данные в таблицу Excel.

Чем пользуемся мы?
- Яндекс. Вордстат
- Пиксель Тулс
- Google Search Console
- Яндекс. Вебмастер
- Поисковые подсказки в Яндексе и Google
- Ultimate Keyword Hunter
Четыре (крутых!) совета от наших SEOшников: LSI-фразы и слова
- Чем больше разноплановых фраз и слов по теме, тем лучше.
- Советуем собирать LSI-фразы сразу в нескольких сервисах (если у вас есть на это время). Так вы получите наиболее полную картину околосемантического ядра. Идеальный вариант — сочетание Pixel Tools и Ultimate Keyword Hunter.
- Если не получается вставить какую-либо фразу по смыслу в текст, вы можете использовать теги alt у картинок и тег “Description”.
- Некоторые слова, предлагаемые инструментами, можно убрать, но делайте это аккуратно. Вы можете подумать, что это слово никак не касается темы, но оно косвенно будет подходить.
Нужно seo продвижение сайта?
Оставьте заявку и мы отправим вам КП
Источник: lz.media
Lsi что это за программа и нужна ли она
На вашу электронную почту было отправлено письмо со специальной ссылкой подтверждения учетной записи. Перейдите по этой ссылке, чтобы активировать доступ к сервису.
Восстановление пароля
На вашу электронную почту было отправлено письмо со специальной ссылкой. Перейдите по этой ссылке, чтобы изменить пароль доступа к сервису.
Задать вопрос
Ваш вопрос отправлен.
ООО «Интернет-лингвистика»
| 7727645011 |
| 773101001 |
| 1087746363682 |
| 85663819 |
| 40702810238000190336 |
| ПАО СБЕРБАНК |
| 044525225 |
| 30101810400000000225 |
| 121357, Москва г, Верейская, дом 29, строение 134, этаж 7, помещение В7 |
| +7 (495) 269 06 30 |
| Волович Михаил Маркович |
Лаборатория поисковой аналитики
Вход / Регистрация
LSI-Анализ
Для чего нужен LSI-анализ
Когда-то, в почти доисторические времена, на заре интернета, наивные поисковые машины считали самыми релевантными те страницы, на которых запрос в точной форме встретился больше всего раз. С тех пор всё изменилось, и нашпиговывать текст ключевиками стало не только опасно, но и бесполезно. Наши исследования показывают, что самые сильные из текстовых факторов — те, которые дальше всего от точного запроса. В частности, важны слова, которых в запросе вообще нет — например, синонимы и слова, выделенные в снипете. Последние могут, например, указывать на географическую локализацию (если запрос геозависимый) или определять интент (цели) пользователя: в Москве, недорого, своими руками.
Текст для поисковой машины — это набор взаимодействующих векторов. Каждое слово в нём может свидетельствовать о релевантности (тематической близости) запросу или, наоборот, «уводить» от него в сторону. Как понять, какие слова полезны, а какие, возможно, вредны, если у нас нет доступа к моделям и алгоритмам поисковика? Очень просто: нужно проанализировать то, что он уже находит по интересующим вас запросам.
Поисковые машины не поощряют оригинальность. Главный принцип оптимизации — стать похожим на тех, кто в топе. Даже если ты хочешь быть лучше их, приходится действовать с оглядкой. Слова, которые часто встречаются на страницах, попавших в топ, проверены поисковиком на релевантность запросу, а уход в сторону может быть расценен как попытка побега.
Собственно, в этом и состоит принцип LSI-анализа: сравниваем статистику употребления слов в вашем тексте или на странице вашего сайта со статистикой страниц в топ-10 или в топ-30 и видим, чего у вас не хватает, а что лишнее.
Результаты можно увидеть наглядно: слова в тексте будут раскрашены оттенками зеленого или красным в зависимости от того, встречаются ли они на страницах, попавших в топ, и если да, то насколько часто. А можно изучить таблицы со статистикой.
Только, пожалуйста, не надо бросаться сразу удалять все «красные» слова и без конца повторять «зеленые». Всё хорошо в меру: уникальные слова есть на каждой странице, в том числе и на тех, которые занимают самые верхние позиции. Помните, что текст должен быть в первую очередь естественным, интересным и полезным, и что вы пишете его не только для поисковых машин.
LSI-анализ: список заданий

Тут всё просто: вы видите таблицу со списком запущенных или уже выполненных заданий. По умолчанию они отсортированы по дате, но можно пересортировать по другим полям или, если заданий много, применить фильтры.
В одной из колонок выводятся результаты сравнения проверенных текстов (страниц) со страницами из топа по 100-балльной шкале.
Результаты по заданиям, запущенным по списку страниц, можно выгрузить в формат CSV и затем открыть в Excel.
Запуск LSI-анализа
Вы можете запустить анализ для текста или для списка страниц (задаются URL).
Не забудьте дать заданию «говорящее» название — иначе потом будет трудно его найти.
Выберите поисковую систему (Яндекс или Google), диапазон (топ-10 или топ-30) и регион, из которого должны задаваться запросы. При желании можно указать также тип сайтов (информационные или коммерческие) или страниц — (главные или внутренние; информационные или коммерческие). Информационность сайтов и страниц определяется автоматически.
Если вы оцениваете текст, введите список запросов и сайты-исключения — не забудьте указать в их числе свой собственный сайт, иначе может оказаться, что ваш текст сравнивается сам с собой.
Если вы оцениваете список страниц, укажите для каждой из них по одному или несколько запросов. По странице на строку; в качестве разделителей можно использовать точки с запятой или табуляции, например:
https://example.com/somepage; первый запрос; второй запрос
URL страницы должен быть в начале или в конце — порядок не важен. Данные можно загрузить из файла в формате CSV.
Сайты, с которых берутся страницы для оценки, исключаются из сравнения автоматически.
Во избежание ошибок желательно указать класс (CSS-селектор), в котором выводится SEO-текст. Если явного SEO-текста на странице нет — например, если страница информационная, — желательно задать класс, содержащий основной контент страницы без меню.
Результаты
Раскрашенный текст
Тут нет никаких чисел, зато всё наглядно. Ярко-зеленые слова — это те, которые у конкурентов встречаются часто, тематическое ядро с точки зрения поисковой машины. Другие оттенки зеленого и оранжевый — слова, которые встречаются у конкурентов реже. (Условные обозначения см. на странице Справка.)
Ярко-красное — это то, что встречается только у вас. Увидев «красные» слова не нужно пугаться и сразу их убирать — в них может быть, например, выражена специфика вашего «уникального торгового предложения». Но про те предложения и тем более абзацы, в которых явно преобладает красный цвет, точно стоит подумать — а нужны ли они вам вообще. Может быть, без них можно обойтись, и текст станет короче и яснее?
Серый цвет — «стоп-слова» (для них частота у конкурентов не оценивается). Полужирным выделены слова запросов и то, что поисковая машина выделяет в снипетах.
Статистика: чего в тексте не хватает
Здесь собрана подробная статистика по вашему тексту (и странице, если она проверялась) и страницам конкурентов.
Слова упорядочены по тому, на скольких страницах у конкурентов они встретились (Конкуренты/Страница/Страницы). Выводятся также данные о том, насколько часто они встречаются на тех страницах, где они есть — см. колонки Медиана.
Данные приводятся для страницы конкурента в целом, для SEO-текста (выделяется автоматически), для «текстовых фрагментов» (части страницы за вычетом SEO-текста) и для заголовка .
Полужирным выделены слова, которых у вас значительно меньше, чем у конкурентов. Красным — те, которых в вашем тексте (или на странице) нет совсем.
«Лишнее»: от чего можно избавиться
Здесь приведена статистика слов, которые встречаются у вас, но отсутствуют у конкурентов. Каждое из них может быть вам действительно нужно — и тогда ничего страшного, все тексты разные, и в каждом могут быть уникальные слова.
Но они могут быть и лишними — особенно если они далеки от тематики запросов и уводят читателя в сторону. Например, если только у вас рассказана легенда о том, как в стародавние времена люди пользовались изделиями продвигаемой вами марки, стоит подумать, не избавиться ли от нее: такая оригинальность может мешать продвижению сайта.
Список конкурентов
Здесь собраны все страницы, которые попали в выдачу по вашим запросам — в топ-10 или в топ-30 в зависимости от того, какой вариант вы использовали в задании. Это особенно полезно, если запросов много: конкурентов нужно знать в лицо, а просматривать результаты поиска вручную неудобно.
Страницы ранжированы по «видимости» — в выдачу по скольким запросам каждая из них попала. Для каждой из страниц показаны также ее средние позиции в выдаче.
Уникальность
По многочисленным просьбам мы включили в LSI-анализ проверку на уникальность (плагиат). Она осуществляется через сервис Content-watch.ru и является факультативной; за проверку каждой страницы с вашего счета будет списано по 5 лимитов.
На вкладке «Уникальность» можно увидеть страницы, текст которых «пересекается» с проверяемым, и увидеть фрагменты, которые им соответствуют.
Часто задаваемые вопросы
Как рассчитывается цена за LSI-анализ? 

Анализ каждой страницы или текста стоит 50 лимитов, при условии, что вы указали для них не более пяти запросов. Если запросов больше, за каждый дополнительный запрос дополнительно списывается по 5 лимитов.
Для чего и как указывать CSS-селектор для текста?
Если вы проверяете страницы с сайта и не указываете CSS-селектор, текст для анализа выделяется автоматически. Для этого используется алгоритм, который не всегда работает идеально, — это вообще довольно сложная задача, не имеющая идеального решения.
Алгоритм рассчитан на выделение SEO-текста на страницах коммерческих сайтов — например, интернет-магазинов. Он не всегда хорошо справляется с информационными страницами, сайтами услуг, ленгдингами и т. п.
Мы рекомендуем для интернет-магазинов и других коммерческих сайтов указывать классы, которыми оформляется SEO-текст; в остальных случаях — классы, содержащие весь основной контент страницы (за исключением меню и других блоков, присутствующих на многих страницах сайта).
Можно указывать классы с тегом (например, div.content ) или без него — в последнем случае они должны начинаться с точки (например, .description ). В случае необходимости можно «собрать» текст из разных классов — можно указать несколько CSS-селекторов через запятую.
Что означает оценка, которая выставляется тексту?
Оценка в диапазоне от ноля до единицы показывает, насколько лексический состав проверяемого текста соответствует лексике страниц, попавших в топ-10 (или топ-30) по указанным вами запросам. Чем выше, тем лучше.
По нашему опыту, «хорошими» можно считать оценки примерно от 0,6 и выше. Но это зависит от тематики — например, для новостных сайтов оценки могут быть заметно ниже, и это нормально.
В моем тексте совсем не оказалось «красных» слов. Это хорошо?
Это немного подозрительно. Возможно, вы забыли внести свой сайт в список исключаемых, и среди страниц, с которыми сравнивается ваш текст, есть та, с которой он взят. В таком случае лучше внести сайт в список исключений и повторить анализ.
Источник: searchlab.ru
Что такое LSI-ключи, как их найти и внедрить на сайт

105
В этой статье речь пойдёт о том, что такое LSI, как и где искать LSI-запросы, как внедрить на сайт, и каких результатов можно достичь с их помощью.
- Немного предыстории
- Развитие LSI
- Где найти LSI-ключи для своего сайта
- Поисковые подсказки
- Похожие запросы
- Поиск по картинкам
- Яндекс.Вордстат
- Megaindex
- Arsenkin
- GSC и Y.Webmaster
LSI (от англ. latent semantic indexing или скрытое семантическое индексирование) — это методика написания текста с использованием семантически связанных слов и фраз, которая повышает релевантность содержания и смысла текста.
Многие заблуждаются в том, что LSI-запросы — это только синонимы. На самом же деле, это любые ключевые слова, которые появляются в результатах поиска вместе с заданным ключевым словом, потому что имеют один и тот же смысл.
Таким образом, ключевые слова LSI делятся на два вида:
- синонимические (sLSI);
- релевантные (rLSI).
LSI-запросы играют важную роль для продвижения, так как алгоритм LSI лежит в основе современных поисковиков. С помощью них поисковые системы намного лучше понимают смысл вашего контента. Робот анализирует веб-страницы и определяет те слова, которые наиболее часто употребляются вместе. Это и есть LSI-ключи.
Немного предыстории
LSI является частью алгоритма LSA, который расшифровывается как «латентно-семантический анализ». LSA появился в 1988 году в США благодаря инженерам, применившим его для индексирования текстов и представления баз данных. Однако до СНГ это добралось только с выходом алгоритма «Палех» в 2016 году.
Развитие LSI
1. Февраль 2011 — запуск алгоритма Panda в Google

Его появление способствовало изменениям в поисковом ранжировании веб-сайтов. Главная цель нововведения — распознать и снизить количество низкокачественного контента в интернете, при этом увеличить рейтинг сайтов с добротными и полезными текстами.
После выхода этого алгоритма в 2012 появилась первая информация о LSI-копирайтинге, а Мэтт Катт (главный инженер поисковой оптимизации Google) призвал создавать естественный контент.
2. Ноябрь 2016 — запуск алгоритма Палех в Яндексе
Яндекс подхватил эстафету только в 2016 году и выкатил алгоритм Палех. Его задача — распознавать низкочастотные и сложные запросы из «длинного хвоста». То есть понимать запросы в разговорном ключе.
3. Декабрь 2019 — запуск алгоритма Вега в Яндексе

После запуска алгоритма «Палех» появился ещё один алгоритм «Королёв», который работает на базе нейронных сетей. Поэтому Яндекс умеет искать не только по словам, но и по смыслу.
С выходом алгоритма «Вега» нейросети используются уже на стадии составления поисковой базы, поэтому Яндекс заранее выявляет в базе близкие по смыслу веб-документы и объединяет их в смысловые кластеры.
Запуск этих алгоритмов в полной мере раскрывает значимость LSI-методики для поискового продвижения, но, к сожалению, не все это ещё понимают.
Где найти LSI-ключи для своего сайта
Доступны разные варианты поиска и подбора LSI-запросов. Мы рассмотрим их в порядке от самых простых до более сложных способов.
1. Поисковые подсказки

Поисковые подсказки являются самым простым способом добычи LSI-ключей. При введении ключевой фразы в поисковой строке Яндекса или Google нам покажут, что чаще всего люди ищут в рамках такого запроса.
2. Похожие запросы

Поисковые системы в конце первой страницы выдачи добавляют блок «Поиск по похожим запросам». Здесь вы сможете найти LSI-фразы, которые могут и не содержать ни одного слова из исходного запроса, однако между ними будет смысловая связь.
3. Поиск по картинкам

Если ввести запрос и открыть поиск по картинкам, как в Яндексе, так и в Google под строкой поиска Вы увидите теги с уточняющими запросами, которые можно отлично использовать в качестве LSI-ключей.
4. Яндекс.Вордстат
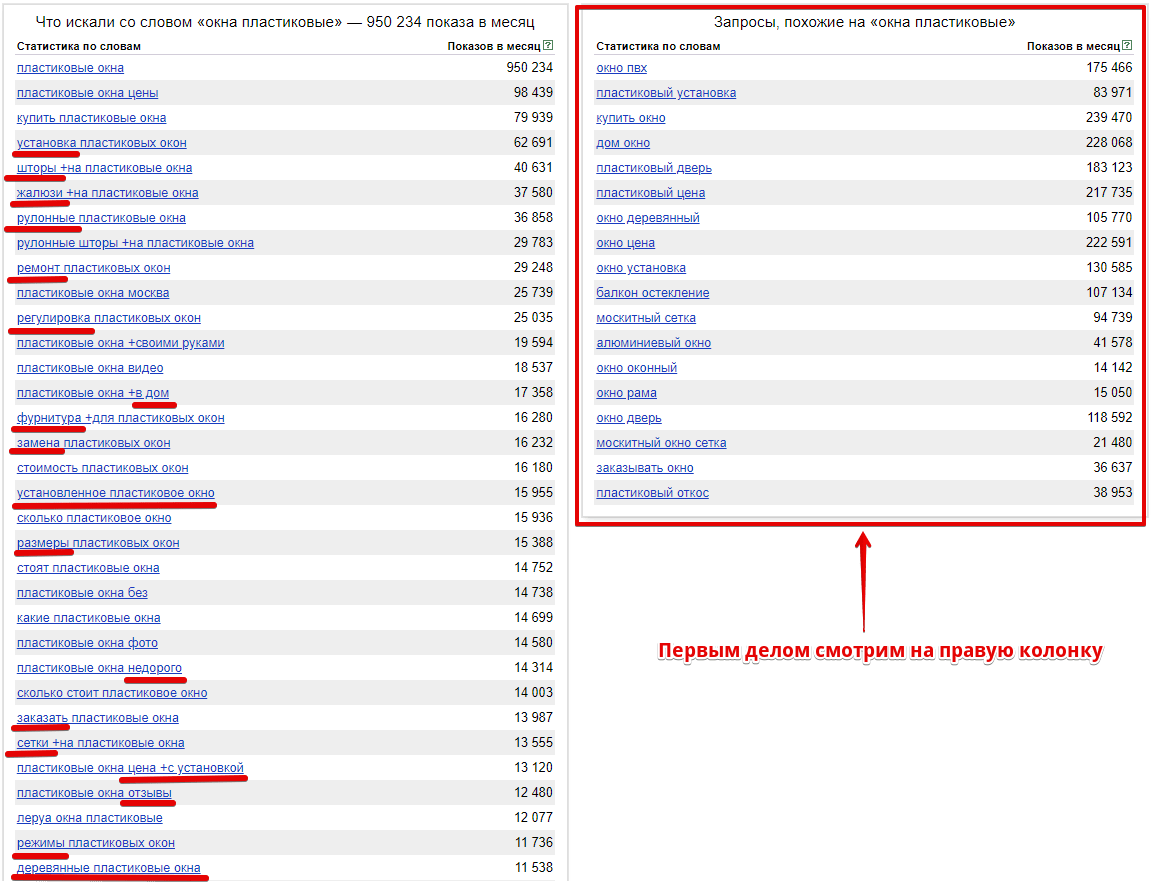
Для работы используйте и левую, и правую колонку Вордстата, так как там зачастую находятся значимые синонимические (sLSI) ключи. Поэтому первое, на что нужно обратить внимание, это правая колонка сервиса. А дальше уже точечно просматривать левую колонку, так как может быть такое, что из поисковых подсказок мы вытянули неполный список LSI-запросов.
5. Megaindex
У Megaindex есть очень удобный, на мой взгляд Инструмент для SEO-анализа текста, который позволяет собрать дополнительные LSI-запросы, которые используют ваши конкуренты из ТОП-10 по Google и Яндексу.
Введя основные запросы Вашего сайта:
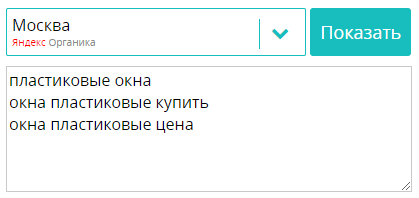
Вы получите список конкурентов из ТОПа и список запросов, которые они используют. Единственный минус в том, что все они — однословные.
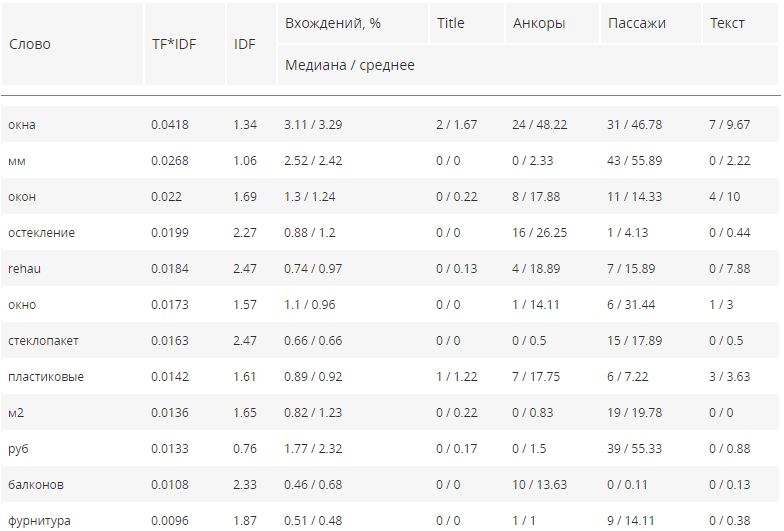
Дополнительно он покажет такие показатели, как: оценка важности слова в контексте — TF*IDF и инверсия частоты, с которой слово встречается в документах коллекции — IDF.
6. Arsenkin
Также хороший инструмент парсинга подсветок, позволяющий быстро собрать слова, задающие тематику по 50 введённым запросам.
7. GSC и Y.Webmaster
Дополнительный способ поиска LSI-запросов — поисковые запросы, по которым люди попадают на ваш сайт.
Алгоритм работы следующий:
1) Выгрузить запросы из Google Search Console:
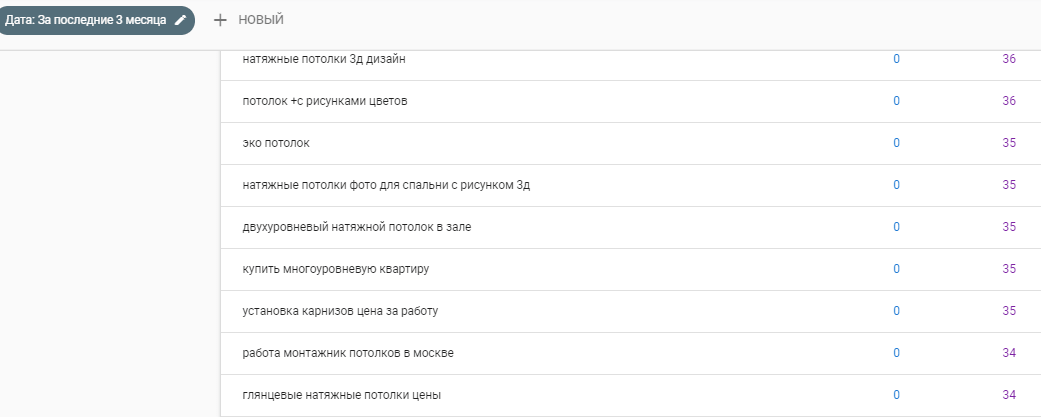
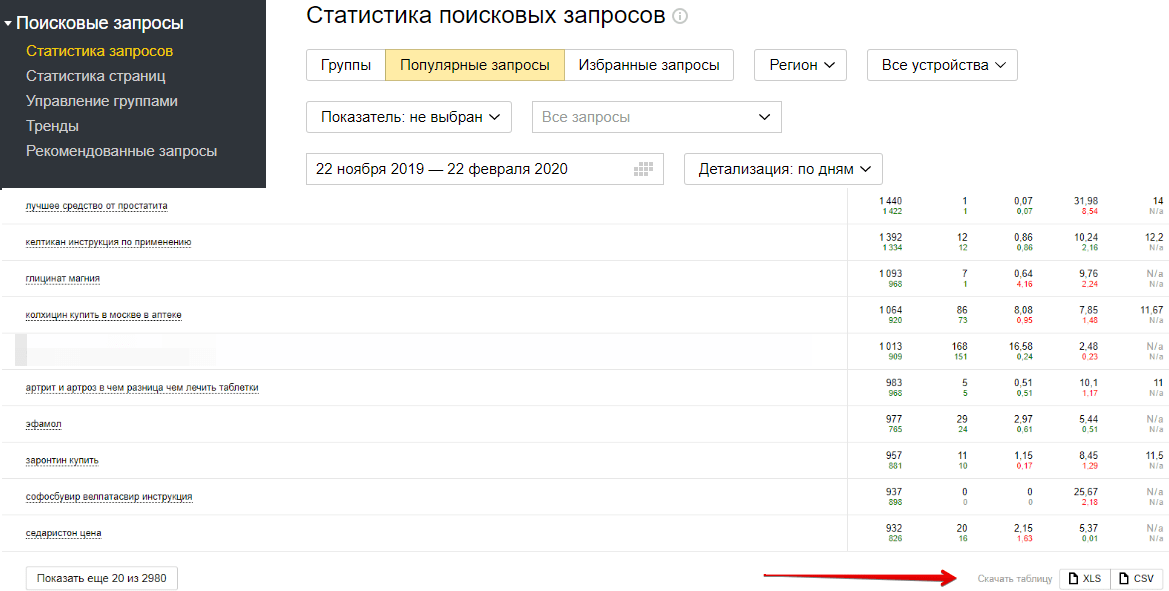
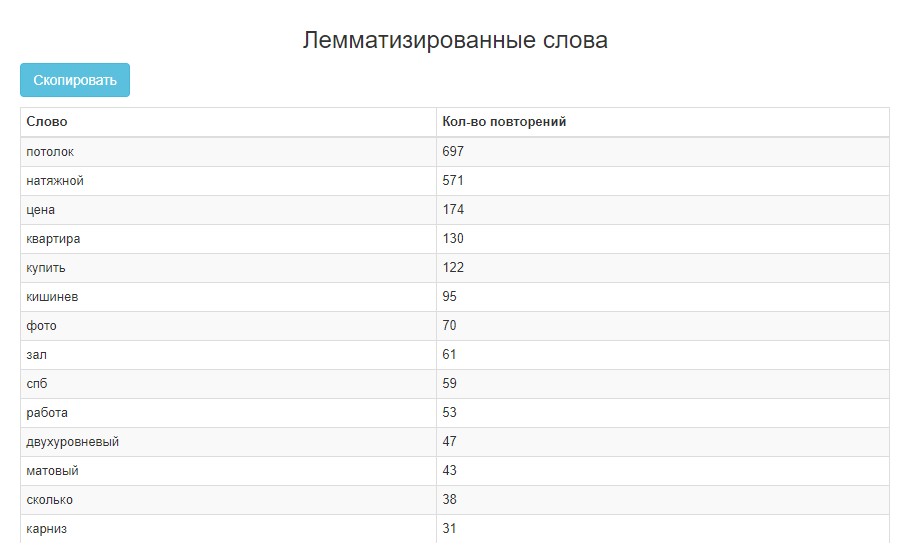
2) Воспользоваться лемматизатором текста, для того чтобы разбить фразы на односоставные слова и понять, что пользователи чаще всего употребляют с основными запросами.
3) Получить список лемматизированных слов, в которых можно найти много полезных вариантов, задающих тематику:
Как внедрять LSI-запросы на сайт
Во внедрении LSI-запросов нет абсолютно ничего сложного, а внедрять их можно на любом этапе работ.
1. Техническое задание на написание статьи
Начните с составления качественного ТЗ копирайтеру с использованием дополнительного списка LSI-запросов. Такое ТЗ позволит получить хорошие тексты на выходе, так как:
- копирайтер заряжается на более качественный текст;
- исполнителю сложнее написать бред, когда нужно упомянуть слова, повышающие ценность и информативность статьи;
- позволяет слегка выйти за рамки основных ключей и не зацикливаться только на них.
2. Дописывайте дополнительные блоки в уже готовую статью
Также LSI-ключи можно внедрять дополнительными блоками к уже готовому тексту, например, к статье о строительных или бытовых отходах не лишним будет добавить информацию о штрафах за несанкционированный выброс таких отходов.

3. Дополнительные методы
Для внедрения LSI можно использовать:
- Description страницы.
- Alt изображений на странице.
Выводы и результаты
Сегодня LSI — отличный способ продвижения. Убедился в этом на собственном опыте. Точечно проработав страницы своего сайта по LSI-ключам, получил следующие результаты в поисковой системе Яндекс:
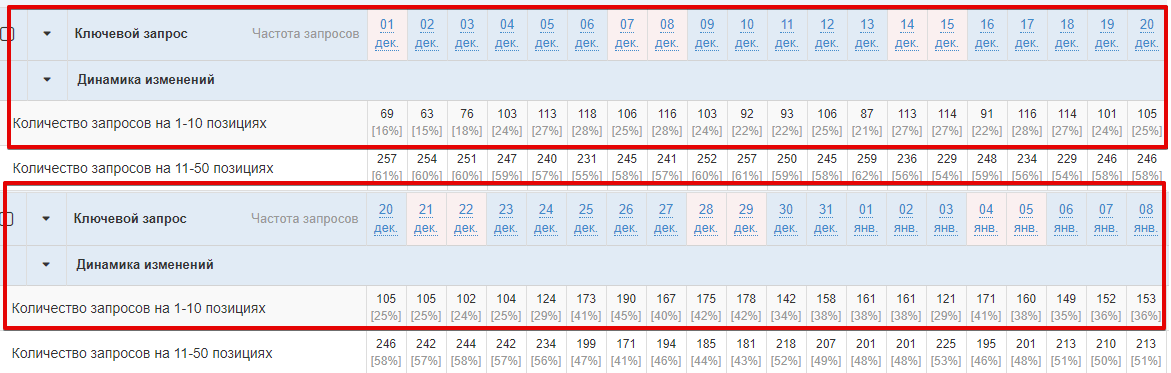
LSI были внедрены до выхода алгоритма Вега в Яндексе, и после результаты значительно усилились. Отсюда вывод, что дополнительная ценность на страницах для Яндекса сейчас важна.
В заключение хотелось бы сказать, что благодаря LSI:
- такой текст выглядит целостным, отвечает на запрос пользователя;
- видимость и позиции вашего сайта улучшаются по ряду НЧ и ВЧ запросов;
- текст очищается от воды и переспама;
- можно получать дополнительный трафик по LSI-запросам;
- повышается релевантность, что послужит отличным толчком для улучшения поведенческих факторов.
Возникли проблемы с оптимизацией сайта? Обращайтесь к нам!
Подписаться на рассылку
- Внутренняя перелинковка сайта: ответы на часто задаваемые вопросы Если вы не уверены, правильно ли настраиваете внутреннюю перелинковку — эта статья поможет развеять сомнения и подскажет, как поступить в той или иной ситуации. Сегодня мы отвечаем на часто задаваемые вопросы наших.
- Как сделать контент релевантнее и заставить сайт ранжироваться выше Как сделать контент более релеватным и ранжироваться выше – читайте, какие 10 шагов нужно сделать, чтобы соответствовать ожиданиями пользователей и поисковых систем. Своим опытом делится.
- Lazy loading или «ленивая загрузка» для изображений Что такое «ленивая загрузка» Для кого нужна «ленивая загрузка» Почему следует внедрить lazy loading Виды отображения при «отложенной загрузке» Как реализовать: Рекомендации Google по.
- Как обновить контент на сайте При SEO-оптимизации сайта важно понимать, что сохранять высокие позиции в выдаче можно лишь за счёт регулярной актуализации и обновления контента. Необходимо не только создавать новый.
- Как оптимизировать зомби-страницы Почему zombie-страницы вредят вашему сайту Виды Zombie Pages Определяем список зомби-страниц Как убрать влияние зомби Зомби-страницы (от англ. Zombie Pages) – это страницы веб-ресурса без.

Начинал с изучения вёрстки, затем плавно переключился на SEO, и вот уже на протяжении 2 лет занимаюсь продвижением коммерческих сайтов в компании Siteclinic.
Веду несколько проектов под руководством опытного SEO Team Lead. Одним из основных направлений моей работы является анализ Usability веб-сайтов и изучение поведения пользователей на них. Считаю, что простота и удобство использования — главный фактор, напрямую влияющий на конверсии и продажи коммерческих веб-проектов.
Девиз: Судьба помогает смелым
Источник: siteclinic.ru
LSI-запросы: что они значат и так ли важны (перевод)

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Многие говорят, что использование LSI-ключей в тексте помогает выводить запросы в топ и получать больше трафика из поисковых систем. Сегодня будем разбираться, правда ли это или очередной миф.
Откройте любую статью про LSI и увидите в ней:
- что Google использует технологию для индексации страниц;
- соответственно, использование LSI-запросов в тексте повышает рейтинг страницы.
Оба утверждения не верны.
Содержание скрыть
- Что такое LSI-запросы
- Что такое латентно-семантическое индексирование?
- Подробнее про синонимы
- Подробнее про многозначные слова
- 1. LSI — устаревшая технология
- 2. LSI создана для работы с известными документами
- 3. Технология LSI запатентована
- 1. Используйте здравый смысл
- 2. Посмотрите на результаты автозаполнения
- 3. Посмотрите на поисковые подсказки
- 4. Используйте LSI keyword tool
- 5. Посмотрите на семантику страниц из топа
- 6. Проведите TF-IDF-анализ
- 7. Посмотрите в базу знаний
- 8. Проведите обратный инжиниринг графа знаний
- 9. Воспользоваться Google’s Natural Language API
Что такое LSI-запросы
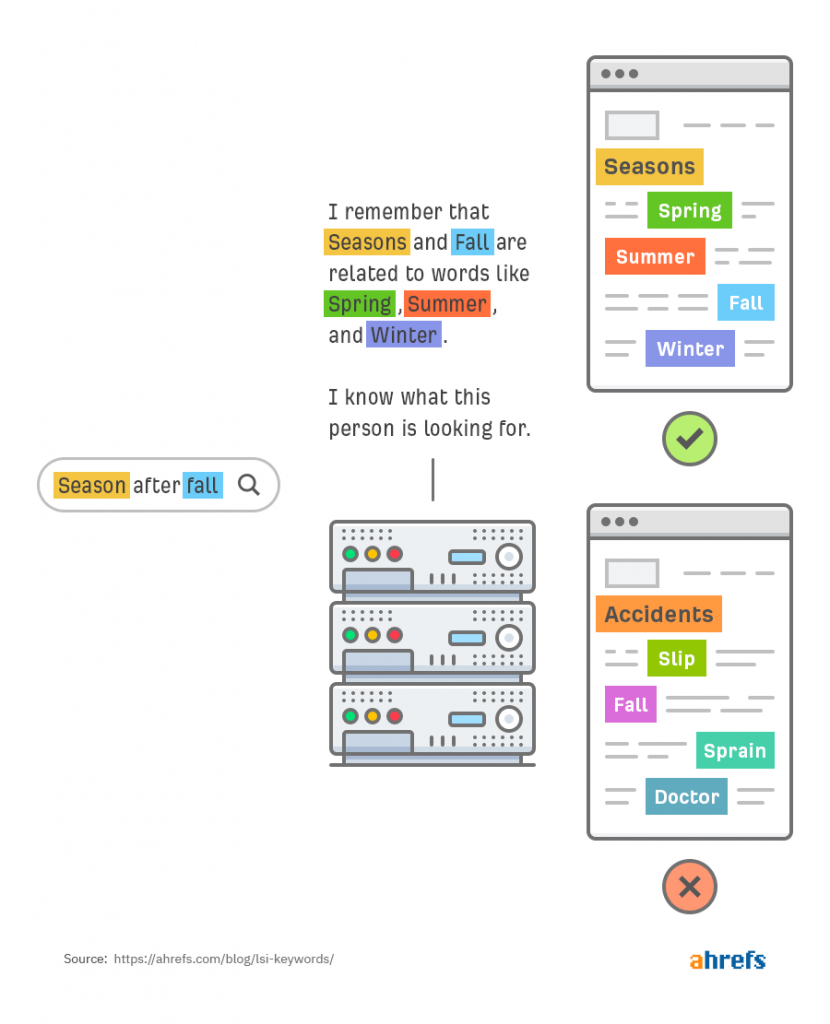
Речь про латентно-семантическое индексирование. Google использует семантически близкие слова к поисковой фразе, чтобы лучше понимать степень релевантности страницы запросу. По крайней мере, так говорят в SEO-сообществе. Если говорим про автомобили, то LSI-словами будут: двигатель, мотор, дорога, техника, моторное масло и т. д.
Согласно заявлению Джона Мюллера, LSI-слов не существует:
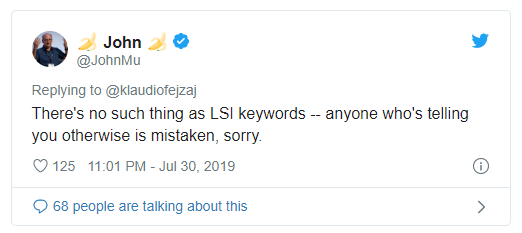
И что теперь делать? Для ответа давайте разбираться, как все работает.
Что такое латентно-семантическое индексирование?
Латентно-семантический анализ — техника обработки естественного языка. Ее разработали ученые в 1980 году.
Если вы не знакомы с математическими понятиями и не знаете, что такое собственные значения, векторы и разложения по отдельным значениям, разобраться будет непросто.
Создатели технологии так описывали проблематику: запросы, которые использует человек, часто не совпадают со словами, которыми можно дать ответ, в т. ч. на странице сайта.
Представьте, что у вас отключили интернет, и вы идете в библиотеку за большим словарем. Чтобы не листать тысячи страниц, вы находите в путеводителе нужное слово и открываете нужную страницу. Нужно слово «fall»? Вот, что вы увидите:

Не то, что нужно. В английском языке слова fall и autumn (осень) — синонимы. Нужно открыть другую страницу:

Проблема в том, что слово, которое мы ищем — многозначное. В русском языке, например, есть «замок» — в значении крепости или в значении запирающего механизма.
Подробнее про синонимы
Синонимы — это слова или фразы, которые означают близкие по смыслу объекты (или одинаковые), но при этом друг на друга не похожи совершенно. Крепость — это замок, твердыня, форт.
Вот, почему работа с синонимами проблематична: люди могут описывать один и тот же объект разными словами — в силу словарного запаса, в зависимости от контекста или места проживания.
Но как это относится к поисковым системам? Предположим, у нас есть две страницы про автомобили. Они одинаковы, но на одной везде вместо слова «автомобиль» — «машина».
Если использовать примитивную поисковую систему, которая индексирует только конкретные слова и фразы на странице, по запросу «машина» мы увидим только одну страницу.
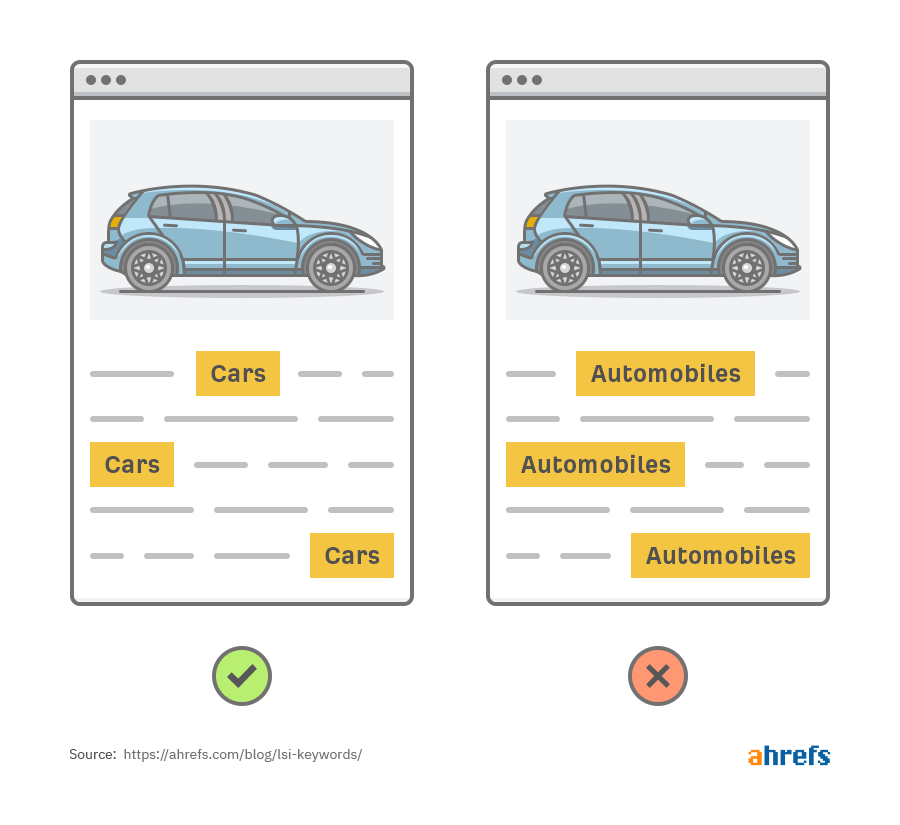
Это плохо, потому что оба результата релевантны запросу. Он описывает то же самое, но просто другими словами.
Итог: поисковикам нужно понимать синонимы, чтобы лучше отвечать на поисковые запросы.
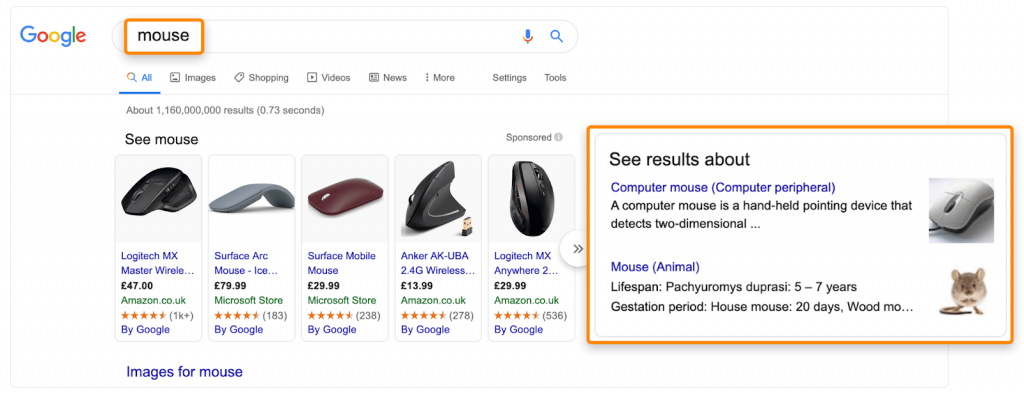
Подробнее про многозначные слова
Многозначные слова и фразы: мышь (для компьютера и животное). Одинаковое слово может использоваться в совершенно разных значениях.
Отсюда и проблемы. В разных контекстах одно и тоже слово приобретает разное референтное значение. Так, использование такого слова в поисковом запросе может не всегда означать, что пользователю интересно именно то, что он видит в выдаче.
Так, по запросу «apple computer» можно увидеть совершенно разные страницы:
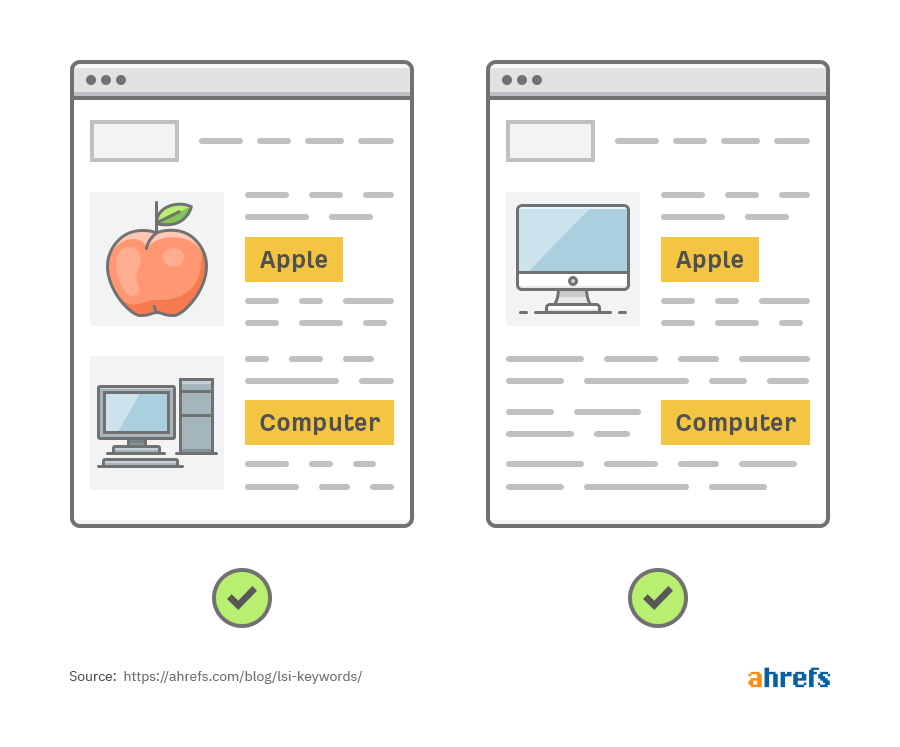
Итог: поисковые системы, которые не понимают различия между многозначными словами, скорее всего, выдадут нерелевантные ответы.
Принцип работы LSI
Они не понимают словесные отношения, которое понятно людям. Например, очень большой и огромный — два разных слова, которые значат одно и то же. И все помнят, что Джон Леннон играл в Битлз.
Но у машины таких знаний нет. Проблема в том, что компьютеру невозможно рассказать все — на это уйдет слишком много времени и сил. LSi решает как раз эту проблему: технология использует математические формулы для получения связей между словами и фразами из набора документов.
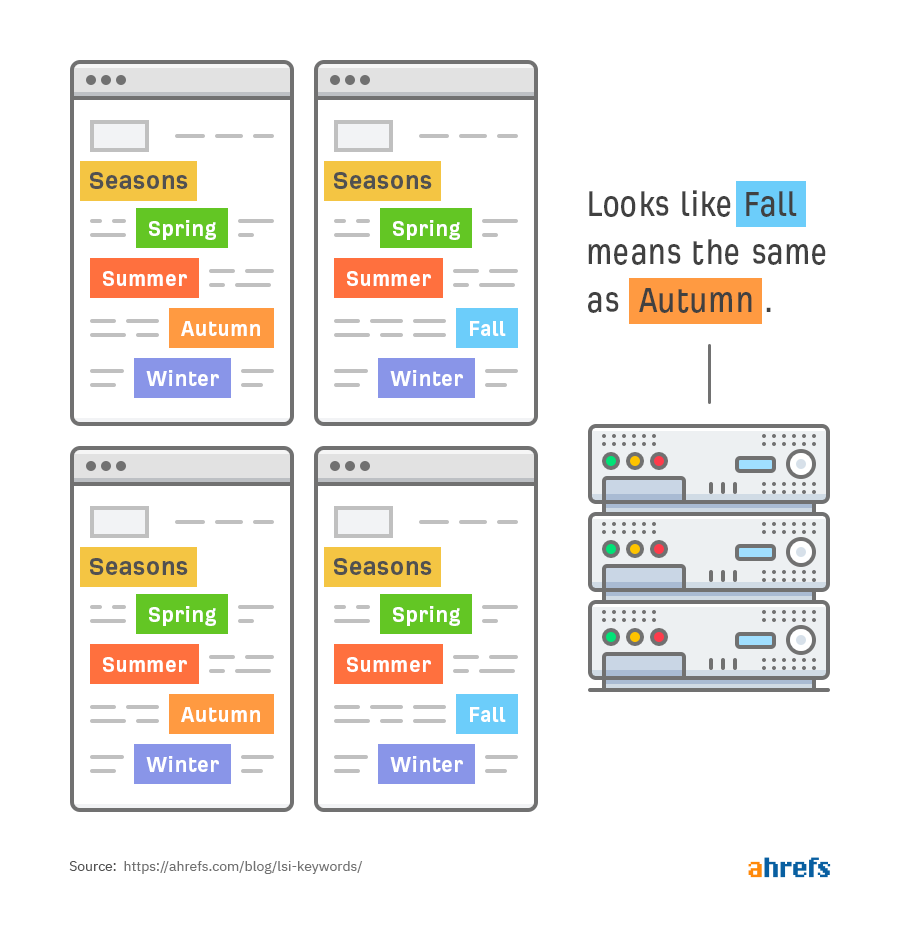
Проще говоря, если применить метод к документам про смену времен года, компьютер сможет выяснить несколько моментов.
Например, что слова fall и autumn — синонимы:
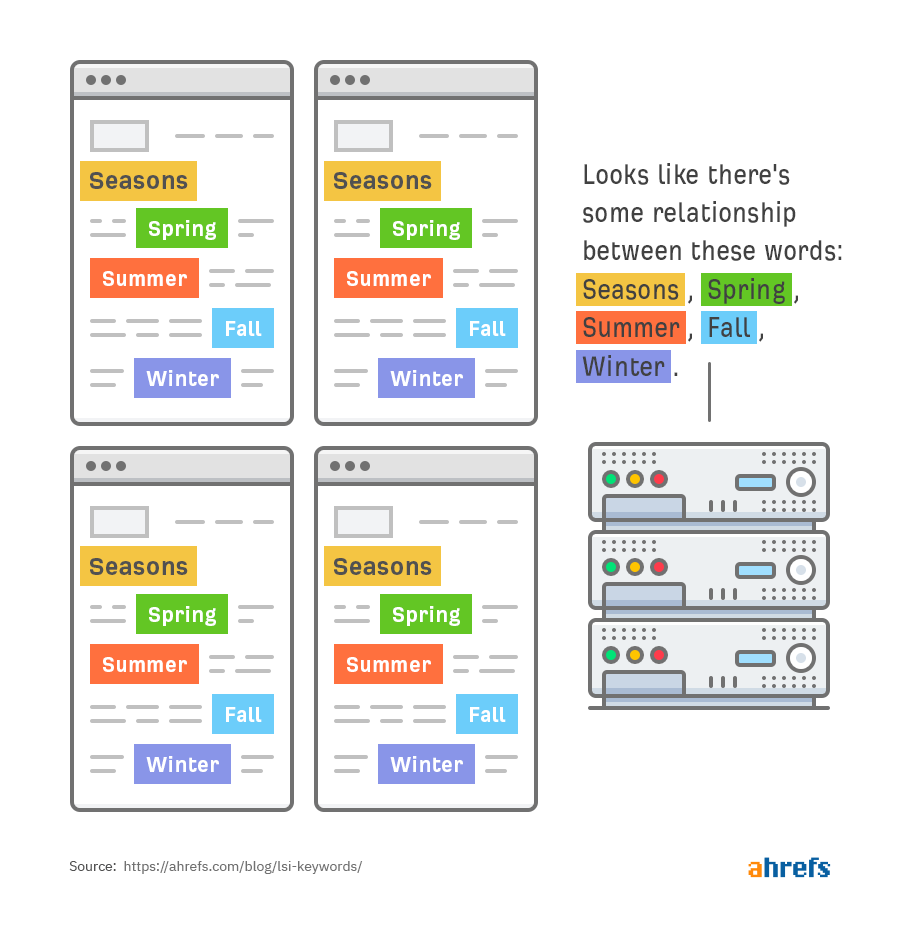
Второе: слова «сезон», «лето», «зима», «весна» — синонимически схожи, потому что используются для описания одного процесса — смены времен года.
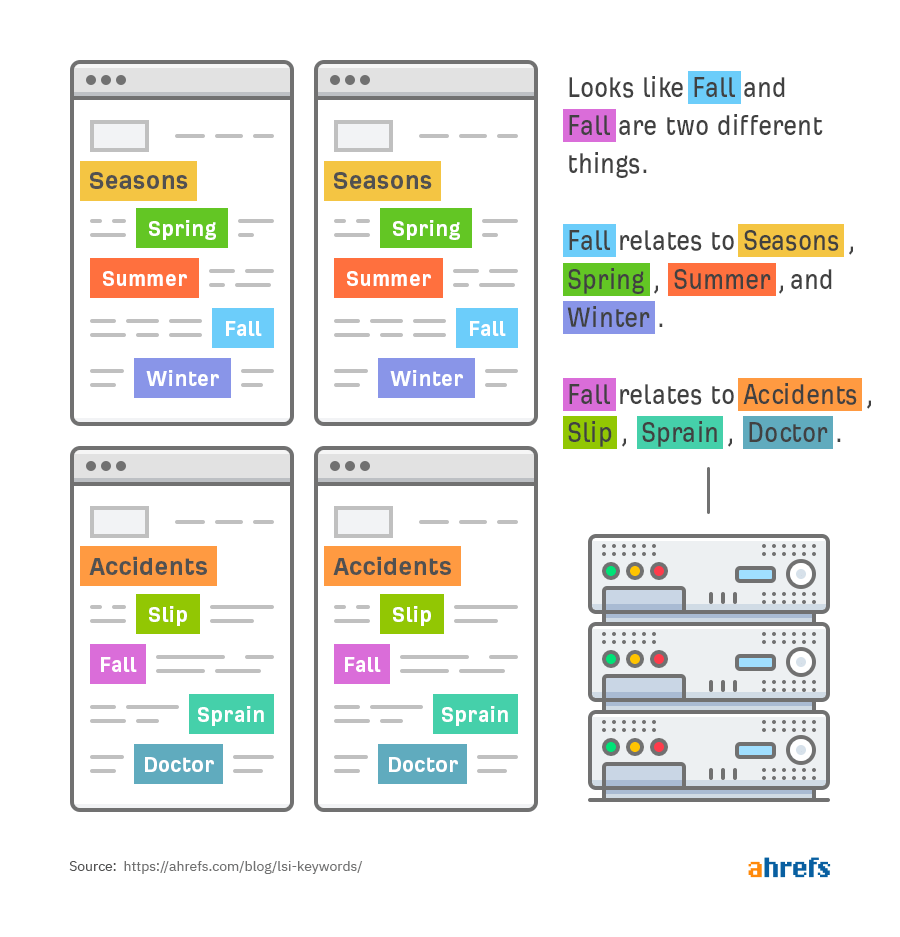
В-третьих, слово fall синонимически связано с двумя разными наборами слов:
Затем поисковые системы могут использовать информацию, чтобы выйти за рамки точного соответствия и предоставить более релевантные результаты поиска.
Использует ли Google LSI: 3 аргумента, почему нет
Учитывая проблемы, которые решает LSI, легко понять, почему многие считают, что Google использует эту технологию. В конце концов, очевидно, что сопоставление точных запросов — ненадежный способ предоставлять лучший ответ на вопрос.
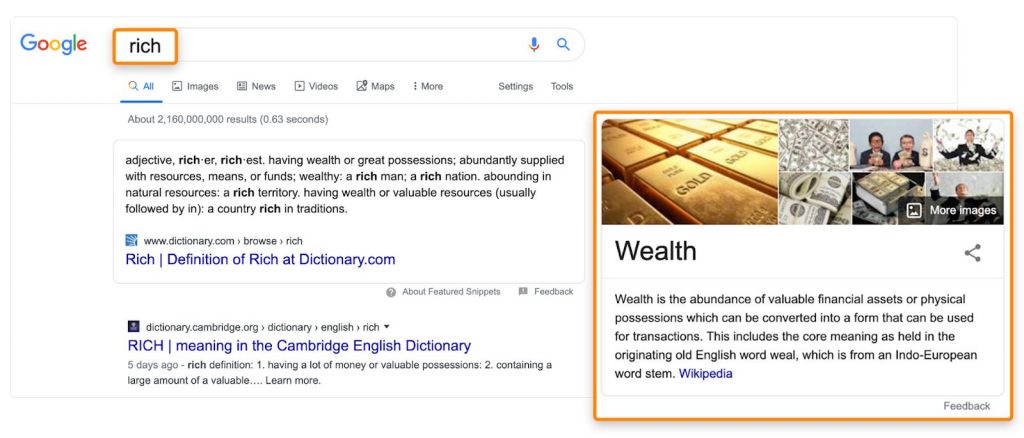
Кроме того, мы ежедневно получаем доказательства, что Google понимает синонимы:
Но, скорее всего, дело не в LSI. Вот три доказательства, что система это не использует.
1. LSI — устаревшая технология
Технологию изобрели в 1980, когда не было интернета. Как таковая, она никогда не предназначалась для применения к такому большому набору документов.
Google разработал лучшую технологию, которую можно масштабировать. Она решает те же проблемы. Билл Славски говорит: LSI-технология не подходит для использования на такой большой выборке документов. У Google есть собственная модель, основанная на векторах — Rankbrain в том числе — она более современна.
2. LSI создана для работы с известными документами
Интернет не только большой, но и динамичный. Миллиарды страниц в индексе поисковика постоянно меняются.
Это проблема, потому что в патенте LSI есть упоминание: запускать анализ каждый раз, когда происходит существенное обновление файлов, которые хранятся в системе. Это занимает много вычислительной мощности.
3. Технология LSI запатентована
Патент на технологию получила компания Bell Communications Research Inc. в 1989 году. Сьюзан Дюма, которая работала над проектом, позже присоединилась к Майкрософт, где она работала над проектами, связанными с поиском информации.
Патент дается на 20 лет по законам США, а это значит, что его действие прекратилось в 2008 году.
Учитывая, что Google достаточно хорошо понимал язык запросов и давал релевантные результаты намного раньше 2008, можно сказать, что Google не использует LSI.
Как влияют синонимы и близкие по смыслу слова на ранжирование
Большинство оптимизаторов видят ключевые LSI-фразы как не более, чем связанные по смыслу сущности.
Если мы используем это определение — хотя оно технически неточное — тогда да, некоторые связные слова на странице могут улучшить SEO. Просто подумайте: когда вы вводите запрос со словом «собака», наверняка вам не понравится текст, где это слово упоминается сотню раз. Поисковик оценивает, содержит ли страница другое ключевое слово, которое относится к этой же тематике.
На странице о собаках Google видит названия отдельных пород как семантически связанные. Но почему разные слова помогают лучше ранжироваться этой странице? Все просто: потому что они помогают Google понять общую суть контента.
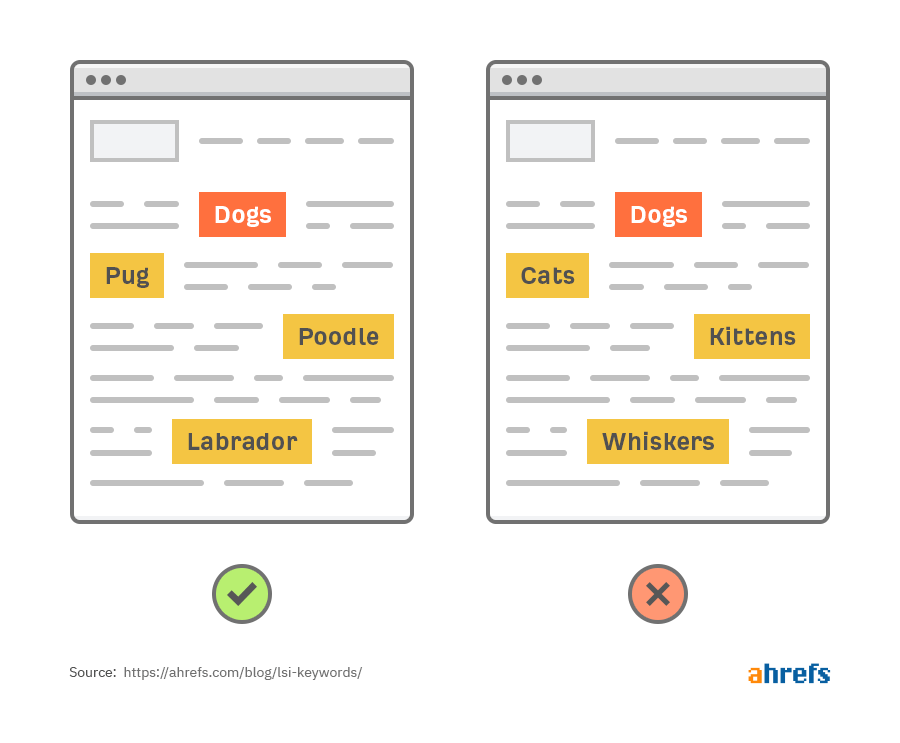
Глядя на другие важные слова и фразы на странице, мы узнаем, что только первая рассказывает именно о собаках.
Как найти связанные ключевые слова
Если вы хорошо разбираетесь в теме, вы естественным образом включите такие синонимы в свое СЯ.
Например, было бы сложно написать о лучших видеоиграх без упоминания фраз вроде «PS4 games», «Call of Duty», «Fallout». Но легко пропустить важные ключи с более сложными темами.
Например, в нашем гайде про nofollow нет ни слова про UGS или sponsored.
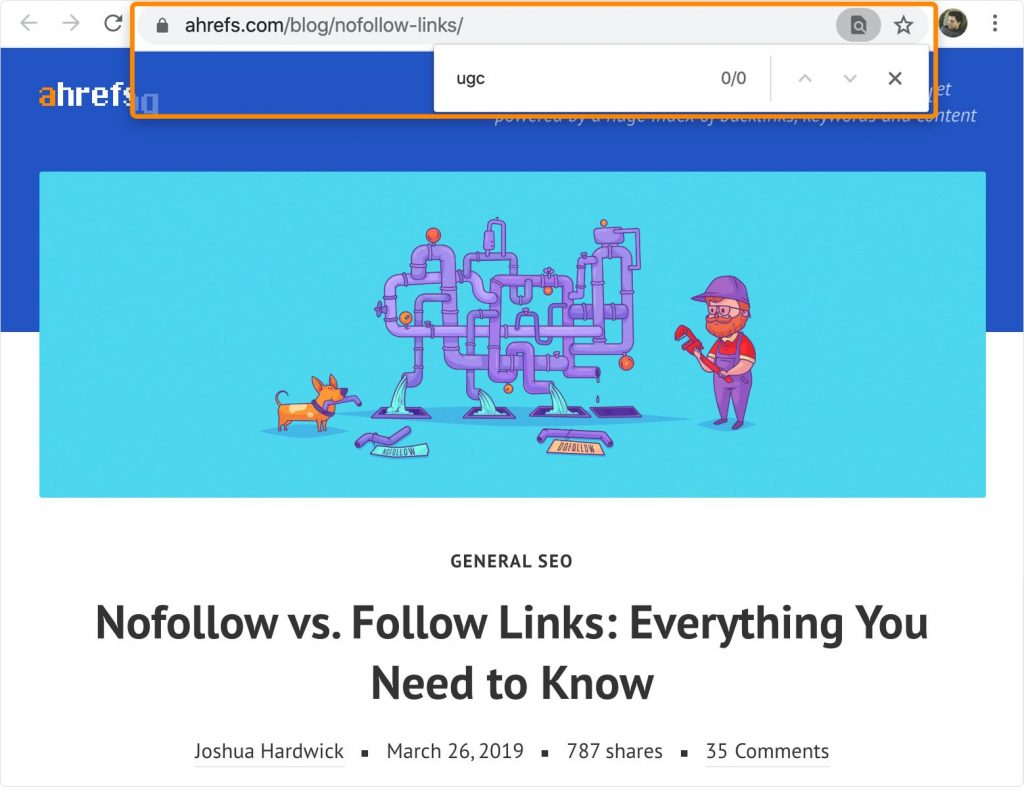
Google, вероятно, считает это важными семантически связанными терминами, которые следует упомянуть в любой хорошей статье по этой теме. Это может быть одна из причин, почему другие статьи про ссылки ранжируются лучше, чем наша.
1. Используйте здравый смысл
Проверьте свои страницы, чтобы увидеть, не пропустили ли вы ничего. Например, если пишете про биографию Дональда Трампа и не упоминаете его импичмент, вероятно, нужно добавить раздел про это.
2. Посмотрите на результаты автозаполнения
Результаты автозаполнения не всегда показывают важные фразы, но они могут дать подсказки, о чем обязательно нужно упомянуть в статье.
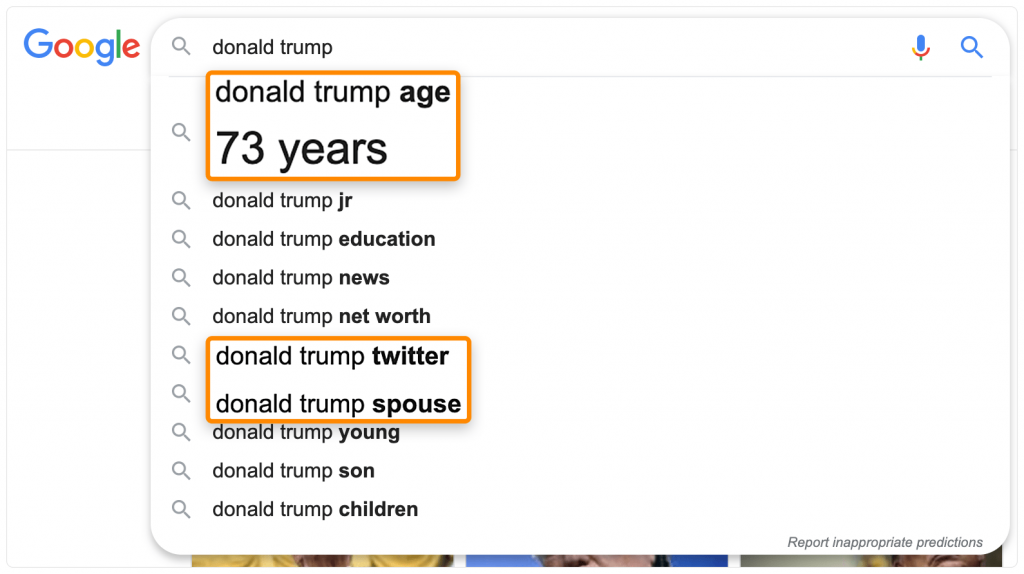
Сами по себе, выделенные слова не связаны между собой, но они относятся к основному запросу. Например, тут обязательно надо добавить раздел про его супругу Мелани.
3. Посмотрите на поисковые подсказки
Подсказки появляются под выдачей. Как и результаты автозаполнения, они могут помочь понять о связанных понятиях и объектах, про которые нужно рассказать.
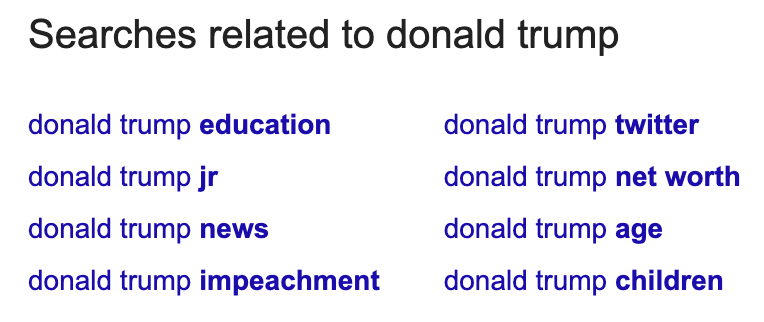
Здесь «donald trump education» относится к The Wharton School of the University of Pennsylvania, в которой он учился.
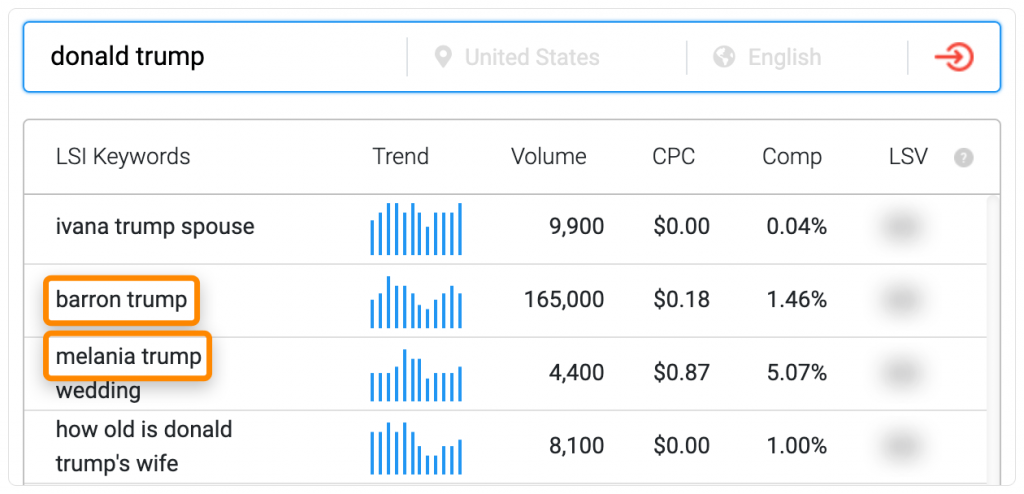
4. Используйте LSI keyword tool
Популярные генераторы :LSI не имеют ничего общего с настоящим LSI. Тем не менее, они иногда выдают некоторые полезные мысли.
Например, если мы введем «donald trump», сервис выдаст несколько полезных имен:
5. Посмотрите на семантику страниц из топа
Используйте отчет Also Rank For в Ahrefs, чтобы найти потенциально связанные друг с другом слова.
![]()
Есть еще инструмент Content Gap, который показывает, где в контенте на сайте есть пробелы, исходя из поисковой семантики.
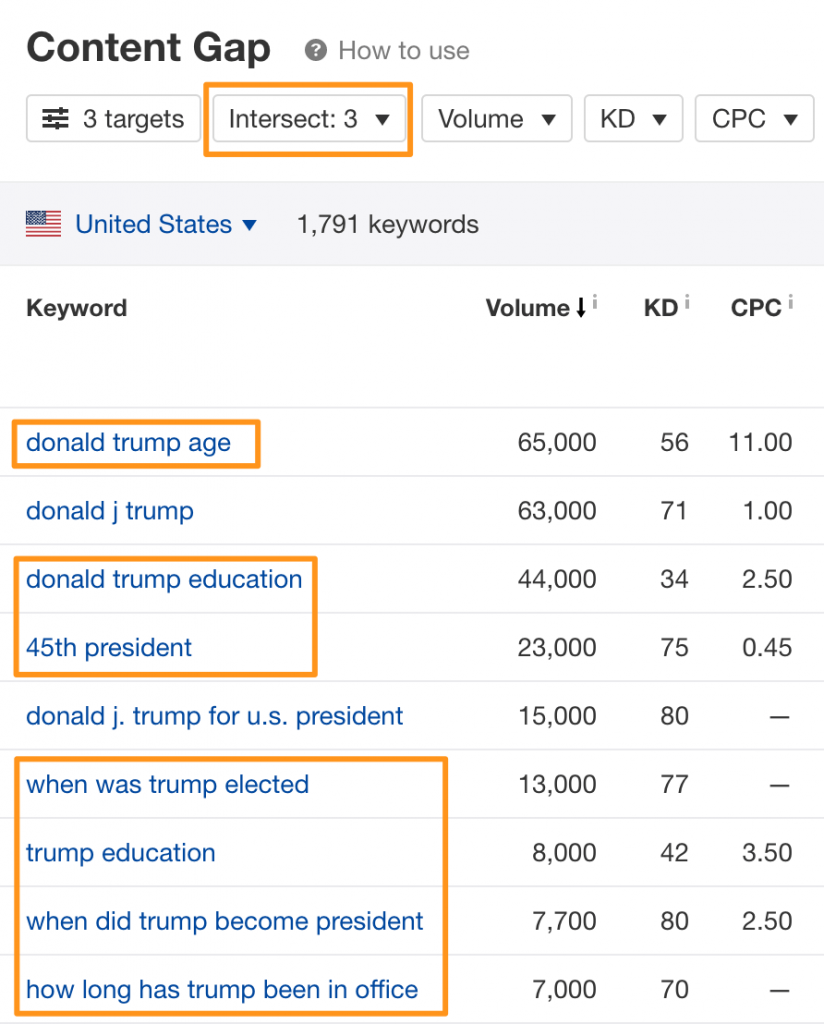
Здесь показаны те ключевые слова, по которым ранжируются все страницы из топа. Часто они дают более полный список всех запросов для статьи.
6. Проведите TF-IDF-анализ
TF-IDF не имеет ничего общего с LSI или LSA, но иногда помогает обнаружить пропущенные слова или сущности.
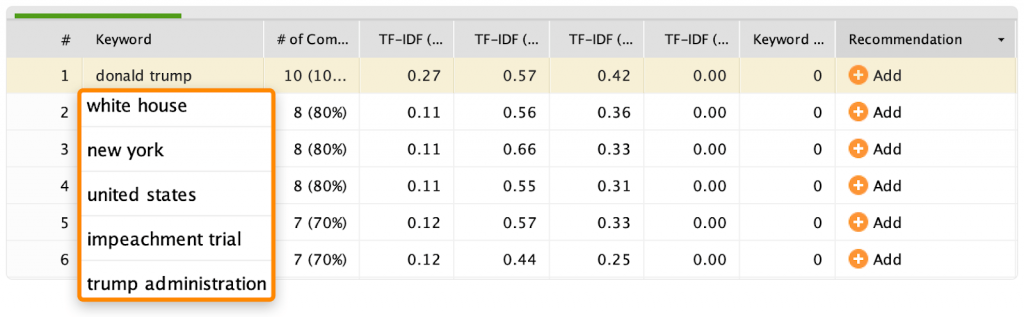
7. Посмотрите в базу знаний
Такие базы знаний, как Википедия или Викидата — просто фантастические источники терминов.Google извлекает отсюда информацию для своего графа знаний.
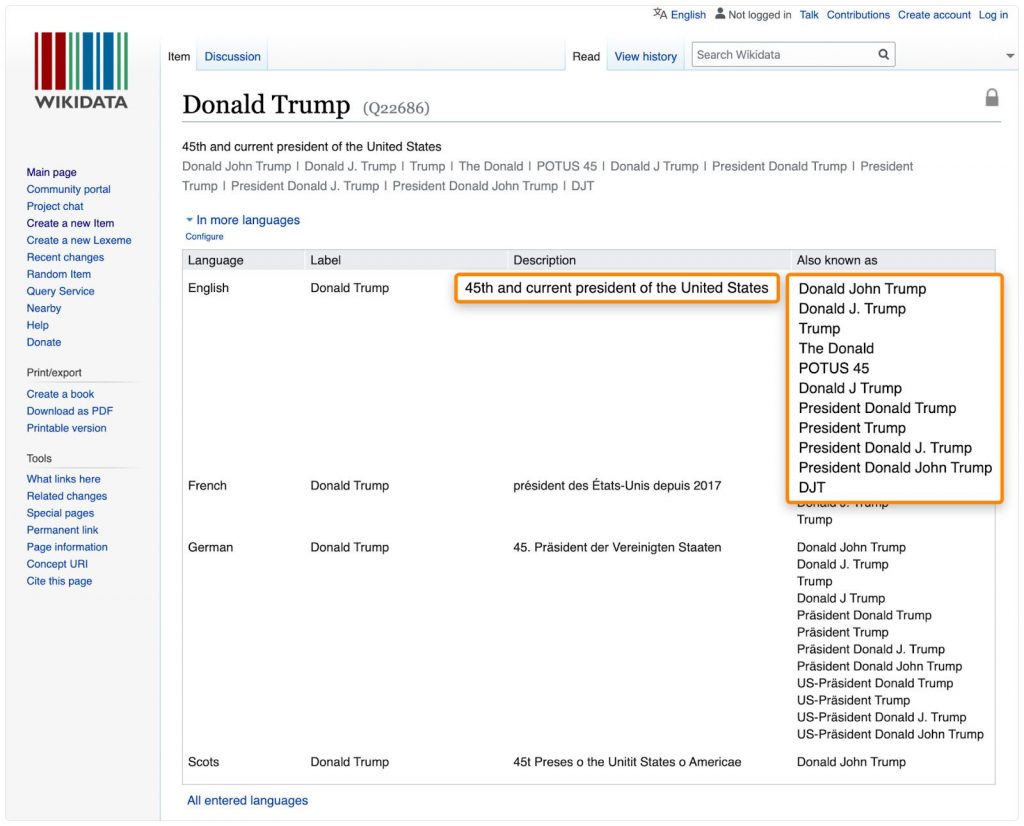
8. Проведите обратный инжиниринг графа знаний
Google хранит отношения между множеством людей, вещей и концепций в графе знаний. Результаты часто попадают в расширенные сниппеты.
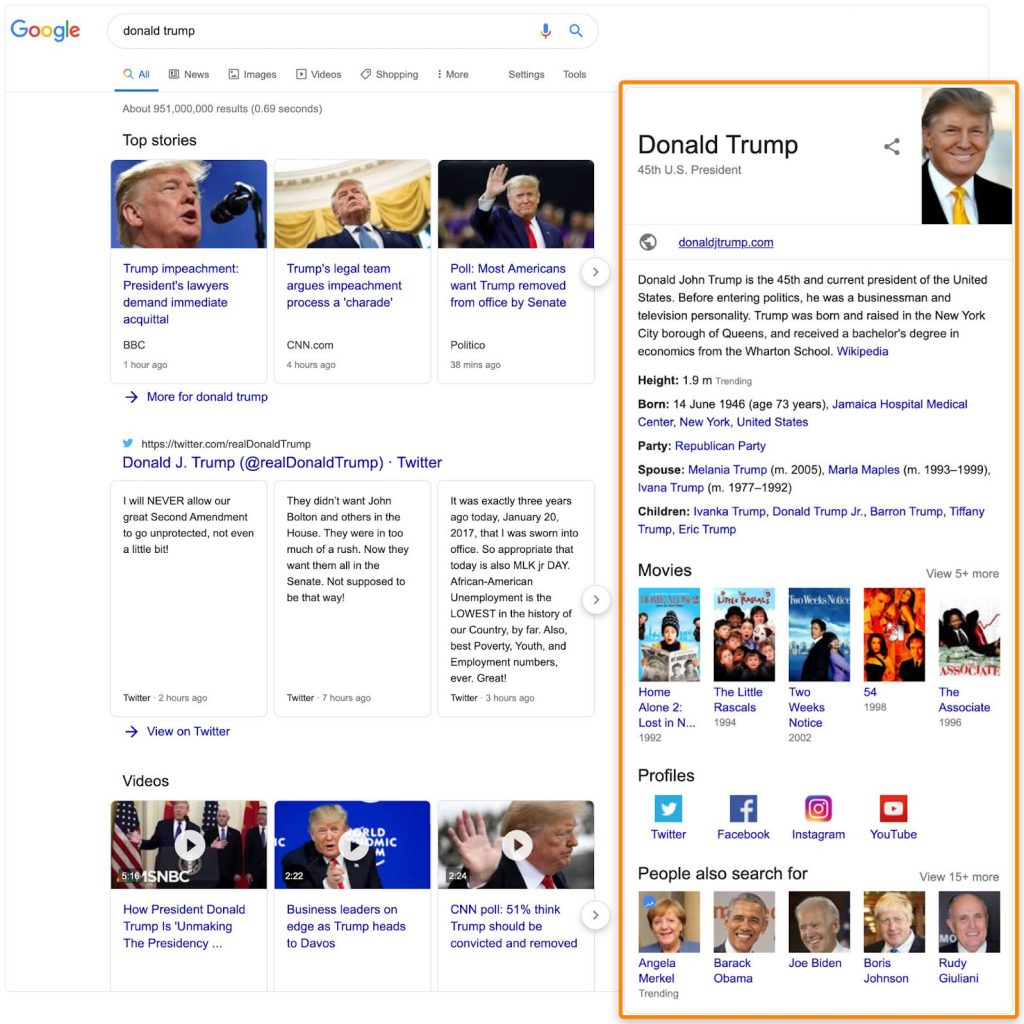
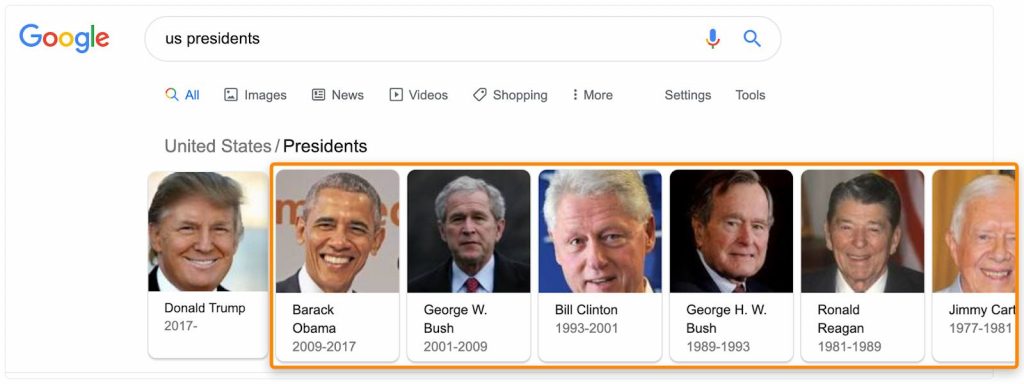
Попробуйте выполнить поиск по ключевому слову и посмотрите, есть ли какие-то данные из этого графа. Так как это термины, которые Гугл связывает друг с другом, определенно стоит поговорить о существующих словах, с которыми они могут быть связаны.
9. Воспользоваться Google’s Natural Language API
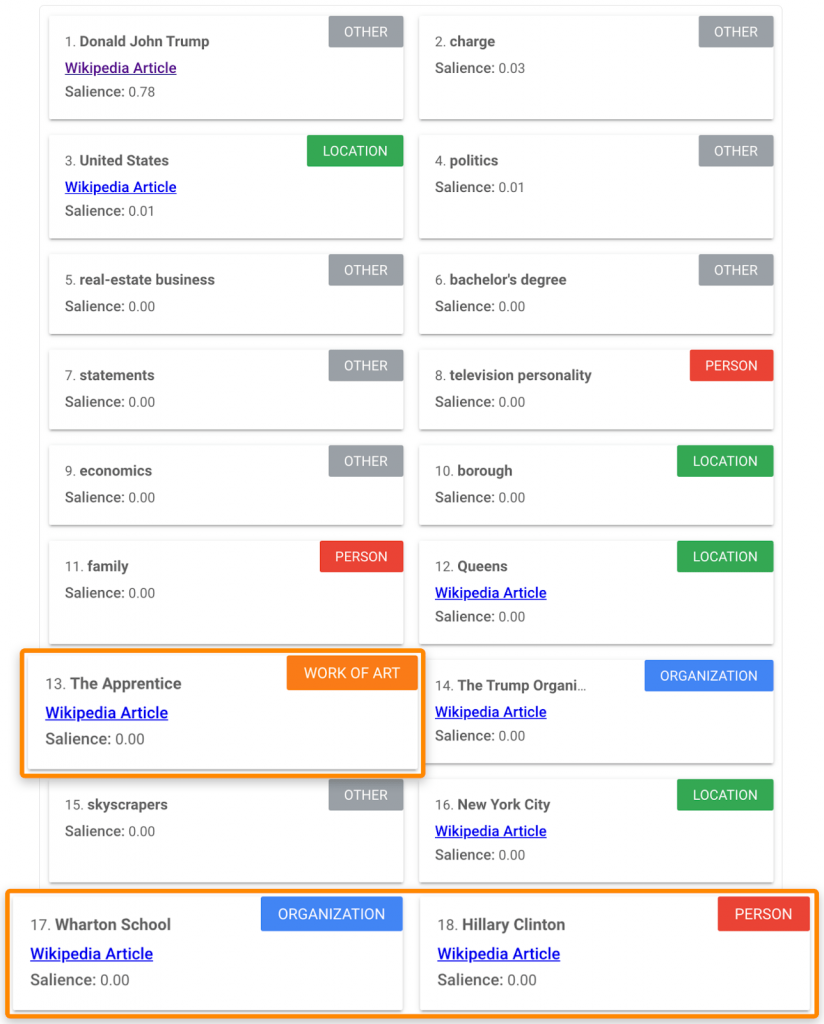
Вставьте текст со страницы с самым высоким рейтингом в демонстрационную версию Language API. Ищите релевантные и потенциально важные сущности, которые вы могли пропустить:
Заключение
Ключевых слов LSI не существует. Но есть слова, фразы и сущности, которые связаны с семантикой. Они способны повысить рейтинг страницы в поисковой системе.
Убедитесь, что вы используйте их там, где они действительно нужны. В некоторых случаях это может означать добавление нового раздела в ваши статьи.
Например, если вы хотите добавить слова и сущности вроде «импичмент» и «комитет внутренней разведки» к статье про Дональда Трампа, для этого потребуется несколько разделов с отдельными подзаголовками.
Источник: semantica.in
Как работать с LSI-фразами? Все о них слышали, но мало кто использует

Для продвижения сайта очень важен контент, который на этом сайте размещается. Одной из составляющих оптимизации текстов является работа с LSI-фразами. Что это такое и как с ними работать, будем разбираться в этой статье.
Что такое LSI-фразы?
Если совсем просто, то LSI-фразы – это синонимы нашей основной ключевой фразы. Это аббревиатура от Latent Semantic Indexing, что с английского дословно переводится как «скрытое семантическое индексирование». Эти фразы означают скрытый смысл или то, что читают между строк.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Почему важно использовать LSI-фразы?
Использование LSI-фраз позволяет избежать переоптимизации ключевых слов на странице. Также синонимы помогают повысить релевантность.
Пользователи могут не знать конкретное название чего-либо. Если они хотят купить диплом университета, они могут задать такие вопросы:
- «купить диплом»,
- «продажа документа о высшем образовании»,
- «покупка сертификата вуза».
Могут быть и любые другие вариации. Это кажется невероятным, но поисковые системы знают все эти синонимы. Поисковые роботы долгое время обучались на наших с вами запросах и запомнили все известные существующие фразы и их синонимы. Поисковые системы научились отвечать на странные вопросы, например: «фильм, где главный герой похож на мейн-куна». Если на вашем сайте будет эта LSI-фраза, то по ней вы будете ранжироваться высоко.
Где разместить LSI-фразы?
Контент на странице – это не только портянка текста. На странице много мест, где можно вставить ключевое слово. LSI-фразы можно разместить в:
- текстовой зоне,
- тайтле,
- заголовках,
- анкорах,
- пунктах меню,
- альтах картинок,
- на кнопках,
- в формах захвата.
Оптимизация посадочной страницы – это оптимизация каждой текстовой зоны. То есть не нужно ограничиваться только текстом. Попытайтесь выйти за рамки привычного мышления. Но важно помнить, что самый популярный ключ нужно размещать выше, в начале страницы. То есть в первом абзаце.
Как найти LSI-фразы?
Существуют разные способы для поиска LSI-фраз. Например, есть расширение для браузера Google Chrome. Оно называется Extractor de entidades.
Это расширение вытягивает сущности со страницы.
Другие места, где можно искать синонимы:
- Поисковые подсказки.
- Рекомендации поисковых систем.

- Яндекс.Вордстат.
- Анализ сниппетов (смотрим, какое описание у конкурентов, и ищем в нем нужные фразы).
- Анализ релевантных текстов (этот пункт приоритетный).
Работа с LSI-фразами
LSI-фраз на странице должно быть много. Когда есть семантическое ядро и LSI, пересечения фраз будут в любом случае. Семантическое ядро в данном случае важнее LSI-фраз.
Основной ключ нужно использовать во всех текстовых зонах. LSI-фраза должна встречаться на странице как минимум один раз. Это основной принцип работы – один раз точно, но можно и больше.
Пример
Открываем рандомный сайт по запросу «продвижение сайтов» и смотрим, что у него там с LSI:

В слайдере, то есть в самом верху страницы:
- «Продвижение сайта».
- «Раскрутка сайта».
- «Топ по запросу».
- «SEO».
- «Цены, которые позволят вашему сайту выйти в топ».
- «СЕО (SEO) – способ недорого продвинуть сайт и заставить его приносить доход».
- «Как заказать SEO».
- «Комплекс работ по оптимизации сайта для поисковых систем».
- «Происходит повышение сайта в выдаче».
- «Услуги SEO-продвижения».
Вы можете также анализировать своих конкурентов и проявлять креатив в разнообразии синонимов.
Вывод
Теперь вы знаете, что такое LSI-фразы и как с ними работать. О них знают все SEO-специалисты, но работают с ними далеко не все. Если вы будете работать с LSI-фразами, то получите преимущество над конкурентами. И если конкретная страница сайта действительно важна, поработать с ней однозначно стоит.
Источник: timeweb.com