
Необходимо ли логирование программ?
К написанию данной статьи меня сподвиг опыт работы с проектами в которых либо отсутсвоала система логирования как таковая, либо присутствовало ее жалкое подобие, по которому было невозможно ни определить проблему, ни даже примерное место ее появления. Под катом немного теории и непосредственно практическая реализация класса для записи логов на С++.
Вступление
Мне часто приходилось сталкиваться с полным отсутствием понимания назначения логирования в приложениях, хотя система логирования это далеко не второстепенная фаза в разработке проекта. Но, зачастую, люди это понимают уже на стадии сдачи поекта, когда введение полноценной системы логирования — процесс достаточно затратный и как результат, оставляют все как есть.
Что в результате имеем? А имеем мы систему, в которой любая проблема у заказчика превращается в головную боль разработчика, т.к невозможно восстановить причины возникновения проблемы у заказчика, т.е у разработчика есть только описание проблемы от человека, у которого эта проблема воспроизвелась. К сожалению, мы живем не в идеальном мире и как правило описания проблемы носит малоинформативный характер, т.к пользователи системы не являются грамотными тестерами и не могут описать проблему подробно(есть конечно приятные исключения, но их мало). Особенно остро проблема логирования стоит когда нет возможности воспроизведения проблемы на своей стороне.
Типичные ошибки
- Интерфейс к логам является набором #define’ов под которыми скрывается простой fprintf в файл. А что если появится новый поток? Или понадобится более умная обработка логов? Правильно все сломается и придется переписывать.
- Строчка выводимая в лог является конкантенацией имени подсистемы и непосредственно сообщения. Например в модуле ответсвенном за взаимодействие с БД, строчка типа: «sql: ». О чем говорит эта строчка? Да ни чем, просто о факте, что где-то был выполнен запрос к БД.
- Нет timestamp при выводе строки лога.
- Нет порогового разделения логов, т.е нет возможности отключить часть логов или выключить их совсем(сомнительная опция 🙂 )
- Слишком редкая запись информации в лог(например в начале и в конце ф-ии, без трассировки ее)
- Малоинформативные записи(не выводится значения переменных и т.д)
Зачем нужны логи?
- Возможность быстрого определения причин проблемы, без многочасового сидения в дебагере, пытаясь определить проблему.
- Возможность «удаленной отладки», т.е возможность отлаживать приложение по имеющимся логам от заказчика(очень полезно когда нет возможности тестировать свое приложение без участия заказчика)
- Перекладывания части работы на техническую поддержку. Т.е support обучается типовым проблемам, секциям в логах и т.д. После чего они сами в состоянии будут определить лежащие на поверхности проблемы, не отвлекая каждый раз разработчиков по пустякам.
- Выбор имени лог файла
- Выбор директории где будут храниться лог файлы
- Включениевыключение межпроцессорной синхронизации
- Ограничение размера лог файла
- Ограничение числа лог файлов, которые могут быть сохранены в директории
- Задание процедуры, котрая будет вызвана при ошибке в записи в лог файл, или при его открытии
- Задание процедуры, которая будет изменять каждую строчку при записи, так, как необходимо пользователю. Удобно, когда Вы не хотите, чтобы кто-то посторонний читал Ваш лог.
- Уровень логов, которые в данный момент могут быть выведены(всего в классе представлен 3 уровня: Обычный, Расширеный и Дебажный). Т.е отсекает все логи приоритет которых выше порога.
Реализация:
Logger.h
namespace smart_log
typedef void (*ErrorHandler)( const std:: string
typedef const std:: string (*Obfuscater)( const std:: string
//This type provides constant which set the writing log mode.
//If a current mode is bigger then methods mode the writing will be ignored.
//It needs for log flood control
enum LogLevel;
struct LogParameters
std:: string m_strLogFileName;
//Pointer to a function which does appropriate manipulations in case of a log corruption. Set to 0 if it doesn’t need.
ErrorHandler m_pErrorHandler;
//Pointer to a function which obfuscates each string writing to a log file. Set to 0 if it doesn’t need.
Obfuscater m_pObfuscater;
size_t m_uiLogMaxSize;
unsigned short m_siMaxSavedLogs;
//Is the thread synchronization needed?
bool m_bIsMultiThreaded;
//Indicates whether log will be saved or not. If this flag is set then log will be saved when its size exceed m_uiLogMaxSize.
//Use m_siMaxSavedLogs to control how many log files will be saved. If the current number of log files has reached the m_siMaxSavedLogs then
//new saved log would replace the oldest one.
bool m_bIsSaveLog;
LogLevel m_xLogLevel;
//Path to the log location. It will be created if no exists.
boost::filesystem::path m_xLogSavedPath;
>;
class Logger
//—————————————Data
size_t m_uiCurrentLogSize;
short int m_siCurrentSavedLogs;
LogParameters m_xParameters;
std::ofstream m_xOfstream;
boost::interprocess::named_mutex m_xMutex;
//File name with full path in which it will be create
boost::filesystem::path m_xFullFileName;
//—————————————Internal methods
private :
//Common method for message writing
void WriteLog(LogLevel xLevel, const std:: string
void HandleLogSizeExcess();
std:: string Timestamp();
void CreatePath(boost::filesystem::path xPath);
//—————————————Interface
public :
Logger( const LogParameters
//Set of methods which concretize the common WriteLog method to log levels.
void WriteNormalLog( const std::ostringstream
>
void WriteExtendedLog( const std::ostringstream
>
void WriteDebugLog( const std::ostringstream
>
//————————————Setters
void SetErrorHandler(ErrorHandler pErrorHandler)
m_xParameters.m_pErrorHandler = pErrorHandler;
>
void SetLogMode(LogLevel xLevel)
m_xParameters.m_xLogLevel = xLevel;
>
>;
>
#endif _LOGGER_
* This source code was highlighted with Source Code Highlighter .
#include «Logger.h»
#include
#include
#include
#include < set >
#include
#include
namespace fs = boost::filesystem;
namespace multiprocess = boost::interprocess;
using namespace smart_log;
void Logger::WriteLog(LogLevel xLevel, const std:: string
if (m_xParameters.m_bIsMultiThreaded)
xLock = multiprocess::scoped_lock(m_xMutex, multiprocess::defer_lock_type());
xLock. lock ();
>
CreatePath(m_xParameters.m_xLogSavedPath);
//Don’t do anything if the current log level less then the message demands
if (xLevel > m_xParameters.m_xLogLevel)
return ;
if (m_uiCurrentLogSize + strMessage.length() > m_xParameters.m_uiLogMaxSize)
HandleLogSizeExcess();
if ( !m_xOfstream.is_open() )
m_xOfstream.open( (m_xFullFileName.file_string() + «-» + Timestamp() + «.log» ).c_str() );
//Make an output string
std::ostringstream xStream;
xStream const std:: string
if (m_xParameters.m_pObfuscater)
m_xOfstream else
m_xOfstream m_uiCurrentLogSize += strMessage.length();
>
catch (std::ofstream::failure xFail)
if (m_xParameters.m_pErrorHandler)
m_xParameters.m_pErrorHandler( «Problem with a file creation or writing to the already existing file.» );
else
throw ;
>
void Logger::HandleLogSizeExcess()
if (m_xOfstream.is_open())
m_xOfstream.close();
//Goes through the log directory and finds files which looks like «m_strLogFileName-*Timestamp*»
fs::directory_iterator xEndIterator;
std:: set xFileList;
for ( fs::directory_iterator it(m_xParameters.m_xLogSavedPath); it != xEndIterator; ++it )
std:: string xCurrentFile = it->path().filename();
if ( fs::is_regular_file(it->status()) )
if (xCurrentFile.find(m_xParameters.m_strLogFileName) != std:: string ::npos)
xFileList.insert(xCurrentFile);
>
//If the log files number exceeds the m_siMaxSavedLogs then keep on removing
//files until current files number won’t be less then threshold
if (m_xParameters.m_siMaxSavedLogs)
if (xFileList.size() >= m_xParameters.m_siMaxSavedLogs)
for (std:: set ::iterator it = xFileList.begin(); it != xFileList.end()
xFileList.size() >= m_xParameters.m_siMaxSavedLogs;)
fs::remove(fs::path(m_xParameters.m_xLogSavedPath) /= *it);
xFileList.erase(it++);
>
>
>
else //Save files property is turned off hence remove all existing log files
for (std:: set ::iterator it = xFileList.begin(); it != xFileList.end();)
fs::remove(fs::path(m_xParameters.m_xLogSavedPath) /= *it);
xFileList.erase(it++);
>
>
m_uiCurrentLogSize = 0;
//Create a new file
m_xOfstream.open( (m_xFullFileName.file_string() + «-» + Timestamp() + «.log» ).c_str() );
>
void Logger::CreatePath(fs::path xPath)
try
//If a directory doesn’t exist then try to create full path up to the required directory
if ( !fs::exists(m_xParameters.m_xLogSavedPath) )
fs::path xTmpPath;
for (fs::path::iterator xIt = m_xParameters.m_xLogSavedPath.begin();
xIt != m_xParameters.m_xLogSavedPath.end();
++xIt)
xTmpPath /= *xIt;
if ( !fs::exists(xTmpPath) )
fs::create_directory(xTmpPath);
>
>
>
catch (fs::basic_filesystem_error)
<
if (m_xParameters.m_pErrorHandler)
m_xParameters.m_pErrorHandler( «Problem with a directory creation» );
else
throw ;
>
* This source code was highlighted with Source Code Highlighter .
Пример создания удобного интерфейса к классу:
#include «Logger.h»
#include
#include
#include
class LogInstance
static boost::scoped_ptr m_spLogger;
public :
static const boost::scoped_ptr
xParams.m_bIsMultiThreaded = true ;
xParams.m_pErrorHandler = 0;
xParams.m_pObfuscater = 0;
xParams.m_siMaxSavedLogs = 0;
xParams.m_strLogFileName = «log_file» ;
xParams.m_uiLogMaxSize = 8192;
xParams.m_xLogLevel = smart_log::eNormal;
xParams.m_xLogSavedPath = «./log/log/log» ;
m_spLogger.reset( new smart_log::Logger(xParams));
>
return m_spLogger;
>
* This source code was highlighted with Source Code Highlighter .
Надеюсь этим постом я сподвигну людей не использующих логи, на их использование и надеюсь моя реализацию будет им полезна. Удачной всем отладки 🙂
Источник: habr.com
Логирование как инструмент повышения стабильности веб-приложения
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.

Профессия тестировщик: разбираемся в QA, QC и testing
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
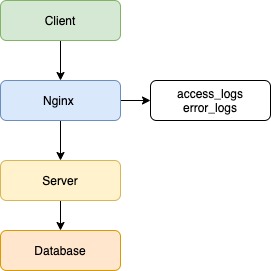
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: «GET /api/v1/users/levels HTTP/2.0», upstream: «http://127.0.0.1:5000/api/v1/users/levels», host: «app.dunice-testing.com»
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.
Источник: tproger.ru
Логирование: что это и в чем его польза
Если в работе сервера, компьютера или программного обеспечения возникла неизвестная ошибка, в первую очередь смотрят логи. Лог — текстовый файл с информацией о действиях программного обеспечения или пользователей, который хранится на компьютере или сервере. Это хронология событий и их источников, ошибок и причин, по которым они произошли. Читать и анализировать логи можно с помощью специального ПО.
Логирование: что это и где применяется
- Администратор ищет причины возникновения технических проблем, сбоев в устройства или операционной системы и недоступности сайта.
- Разработчик проводит дебаг, то есть ищет, локализует и устраняет ошибки.
- Seo-специалисты собирают статистику посещаемости, оценивают качество целевого трафика.
- Администратор интернет-магазина отслеживает историю взаимодействия с платежными системами и данные об изменениях в заказах.
Типы логов
Существуют разные уровни и разные подробности логирования. Когда ошибку сложно воспроизвести, используют максимально подробные логи; если это не требуется, собирают только ключевую информацию. Для работы с логами и поиском информации в огромных текстовых данных используют специализированные инструменты.
Для удобной работы с логами их делят на типы. Это помогает быстрее находить нужные и выбирать правильные инструменты для работы с ними. Например, выделяют:
- системные логи, то есть те, которые связаны с системными событиями;
- серверные логи, регистрирующие обращения к серверу и возникшие при этом ошибки;
- логи баз данных, фиксирующие запросы к базам данных;
- почтовые логи, относящиеся к входящим/исходящим письмам и отслеживающие ошибки, из-за которых письма не были доставлены;
- логи авторизации;
- логи аутентификации;
- логи приложений, установленных на этих операционных системах.
Также логи можно типизировать по степени их важности:
- Fatal/critical error — то, что нужно срочно исправить.
- Not critical error — ошибки, которые не влияют на пользователя.
- Warning — предупреждения, то, на что нужно обратить внимание.
- Initial information — информация о вызовах API сервиса, запросах в БД, вызовах других сервисов.
Где ITGLOBAL.COM использует логирование
Специалисты ITGLOBAL.COM настраивают автоматический сбор, хранение и обработку логов в облачном хранилище. Облако позволяет воспроизвести события на целевой системе даже при ее полном отказе.
Поясним на примере. Допустим, файловая система одной из виртуальных машин повредилась и все данные на сервере были уничтожены. Инженеры получают уведомление об этом инциденте от системы мониторинга и восстанавливают работоспособность сервера через бэкапы. После этого они анализируют логи, которые сохранились благодаря удаленной системе хранения. Они похожи на черный ящик самолета, так как с их помощью специалисты восстанавливают последовательность событий при инциденте, делают выводы и вырабатывают решения, которые предотвратят появление таких инцидентов в будущем.
Также инженеры ITGLOBAL.COM используют логи для анализа действий пользователей. Они в любой момент могут восстановить, кто и когда совершал определенные действия внутри системы. Для этого специалисты используют инструменты, которые автоматически контролируют базовые события, касающиеся безопасности. Например, если в субботу ночью появится учетная запись с правами суперпользователя, система сразу зарегистрирует это событие и пришлет уведомление. Инженеры уточнят легитимность новой записи, чтобы предотвратить попытку несанкционированного доступа.
Инструменты
Сбор, хранение и анализ логов выполняется с помощью специальных инструментов. Расскажем, какие из них используют специалисты ITGLOBAL.COM.
Elasticsearch, Logstash и Kibana
Логи всех информационных систем, подключенных к услуге Managed IT, хранятся в распределенном хранилище на базе решения ELK (Elasticsearch, Logstash и Kibana). Механизм сбора логов выглядит так: Logstash собирает логи и переносит их в хранилище, Elasticsearch помогает найти нужные строки в этих логах, а Kibana визуализирует их. Все три компонента разработаны на основе открытого кода, благодаря чему их можно модифицировать под потребности компании.
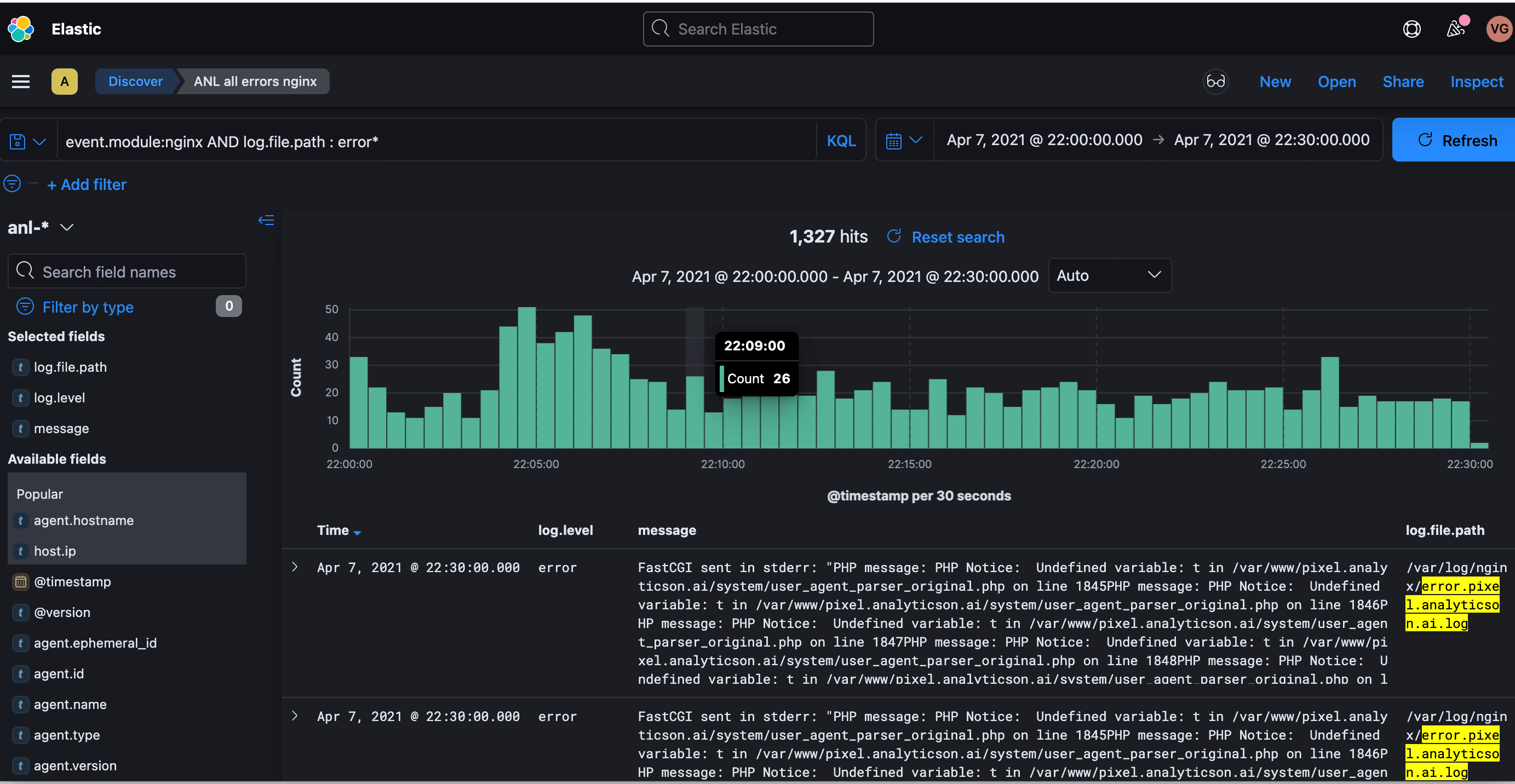
- Logstash — приложение для работы с большими объемами данных, собирает информацию из разных источников и переводит ее в удобный формат.
- Elasticsearch — система для поиска информации. Помогает быстро найти нужные строки в файлах хранения.
- Kibana — плагин визуализации данных и аналитики в Elasticsearch. Помогает обрабатывать информацию, находить в ней закономерности и слабые места.
Wazuh
Решение с открытым кодом для поиска логов, коррелирующих с моделями угроз информационной безопасности. С его помощью специалисты ITGLOBAL.COM мониторят целостность ИТ-систем и оперативно реагируют на инциденты.
- обнаружить скрытые процессы программ, которые используют уязвимости в ПО для обхода антивирусных систем;
- автоматически блокировать сетевую атаку, останавливать вредоносные процессы и файлы, зараженные вирусами.
Почему логирование нужно каждой компании
Логирование — еще один способ эффективно контролировать состояние инфраструктуры. В ITGLOBAL.COM оно входит в пакет услуг Managed IT. Вместе с сервисами мониторинга логирование существенно экономит время инженеров при расследовании тех или иных инцидентов. А главное, с помощью анализа логов можно предотвратить инциденты в будущем.
Компании, которые используют логирование в рамках услуги Managed IT, уменьшают общее количество инцидентов и получают принципиально другой уровень контроля над инфраструктурой.
Также сервис удобен для разработчиков, которые с помощью простых интерфейсов могут в режиме реального времени отслеживать работу своих приложений.
Источник: itglobal.com
Как разобраться с логированием: гайд для начинающих
Этот материал мы ориентировали на тех, кто в первый раз сталкивается с логированием серверных служб и web-серверов. Познакомим с уровнями логирования, расскажем об основных типах логов и перечислим инструменты для работы с ними.
Зачем оно вообще нужно, это логирование?

На анализе логов базируется работа большинства ИТ-специалистов. Администраторы ищут в файлах логирования причины сбоя сервиса. Разработчики опираются на логи, чтобы локализовать и устранить ошибки приложения или веб-сайта. Служба безопасности по логам, как по физическим уликам, определяет вид взлома, оценивает нанесенный ущерб и даже может идентифицировать взломщика. Вот почему логирование мы рекомендуем отладить в первую очередь: в любой непонятной ситуации ответ на вопрос вы будете искать в логах!
Файлы логирования
Уровни логирования
- Debug — запись масштабных переходов состояний, например, обращение к базе данных, старт/пауза сервиса, успешная обработка записи и пр.
- Warning — нештатная ситуация, потенциальная проблема, может быть странный формат запроса или некорректный параметр вызова.
- Error — типичная ошибка.
- Fatal — тотальный сбой работоспособности, когда нет доступа к базе данных или сети, сервису не хватает места на жестком диске.
Дополнительно файл логирования может расширяться записями еще двух уровней:
- Trace — пошаговые записи процесса. Полезен, когда сложно локализовать ошибку.
- Info — общая информация о работе службы или сервиса.
Работа с уровнями логирования регламентируется методическими документами и внутренними правилами организации. В них может определяться соответствие источника сообщения уровню логирования, значимость, порядок обработки каждого уровня и другие параметры.
Типы логов
Для удобства обработки логов их делят на типы:
- системные, связанные с системными событиями,
- серверные, отвечающие за процесс обращения к серверу,
- почтовые, работающие с отправлениями,
- логи баз данных, которые отражают процессы обращения к базам данных,
- авторизационные и аутентификационные, которые отвечают за процесс входа, выхода из системы, восстановление доступа и пр.
У каждого типа логов свой журнал записи. Для проверки логов авторизации нужно идти в журнал доступов, чтобы проверить загрузку системы — в журнал dmesg, за данными о запросах пользователей — в access_log. Когда одни логи пишутся отдельно от других, проще диагностировать ситуацию и найти источник проблемы.

Логи в access_log
Инструменты для работы с логами
Сбор, хранение и анализ логов вручную хороши, когда у вас один сервер. Когда серверный парк разрастается, а приложений и сервисов становится больше десяти, работу с логами целесообразно автоматизировать и использовать специальные системы логирования, например, Graylog, ELK, Loggy или Splunk. Некоторые из них позволяют организовать полномасштабный мониторинг, настроить алерт раннего обнаружения конкретной проблемы или установить пороговые значения показателей, коррелирующих с угрозами информационной безопасности.
Логи сетевого, инженерного оборудования, баз данных и приложений мы храним в облачном хранилище. И вам советуем. Даже когда у вас полно места на жестких дисках и стоит мощная защита на все случаи жизни. Оборудование рано или поздно, а чаще неожиданно, выходит из строя, а злоумышленники давно умеют чистить файлы логирования, так что логи в облаке — это возможность восстановить события и расследовать инцидент даже при полном отказе системы.
Хранение логов в облаке
Логирование кажется второстепенным процессом, который занимает время, но не дает видимых результатов. Однако это только кажется и только до тех пор, пока не появится реальная проблема, с которой можно разобраться только по логам. И только если они записаны, распределены по уровням, собираются и доступны для анализа.
Источник: greendc.ru