
Логирование. NLog Platform. Зачем нужны логи в приложении
Ведение логов помогает разработчику в процессе создания и последующего сопровождения приложения, при поиске ошибок в коде и в разрешении непонятных ситуаций, когда наше приложение в момент работы ведет себя странным образом, и нам нужно найти причину такого поведения. Любой разработчик сталкивается с подобными ситуациями, когда какой-то компонент приложения отрабатывает странным образом, выдает не тот результат или вообще перестает работать. Использование логов поможет нам в подобных ситуациях. Время поиска проблемных мест в нашем коде сократится в разы, и мы быстрее сможем решить ту или иную проблему. Вообще, на сегодняшний момент ни одно более или менее серьезное приложение не обходится без написания логов.
Лог (log) — это специальный журнал, в котором хранится информация о состоянии работы приложения (программы).
Под таким журналом можно понимать и записи в обычный текстовый файл, и записи в базу данных, и записи на удаленный веб-сервис, и даже email-письма на определенный адрес о тех или иных состояниях нашего приложения. Какие записи делать в этот журнал, то есть, какую конкретно информацию записывать, определяет сам разработчик.
Что такое Логи и зачем они нужны
Это могут быть сведения о том, что все работает в штатном режиме, то есть просто ежедневный мониторинг нашего приложения, или что произошла какая-то ошибка, на которую нужно максимально срочно отреагировать и устранить, и так далее. Всего существует шесть уровней логирования, каждый из которых предназначен для сообщений того или иного типа, той или иной важности: Trace – максимально детальная информация о том, что происходит с целевым участком кода, по шагам.
Например: Попытка открыть подключение к БД, успешнонеуспешно. Сколько времени заняла эта операция. Сколько времени выполнялась выборка из БД, успешнонеуспешно. Сколько записей извлечено. Какая была нагрузка на систему, сколько использовано памяти. Сколько записей прошло нужную фильтрацию. Сколько записей оказалось в результирующей выборке, куда эти записи отправились дальше.
Проверка нужных значений в каждой записи. Debug – это информация для отладки. Логирование крупных операций, менее детально, чем в Trace. Здесь мы не так подробно описываем весь процесс операции, но, тем не менее, заносим в журнал основные операции. Например: Совершено обращение к БД. Из базы выбрано N записей. Записи успешно обработаны и отправлены клиенту.
Info – это более общие информационные сообщения о текущей работе приложения, что происходит с системой в процессе ее использования. Например: Была выгрузка студентов в Excel-файл. На сайте зарегистрирован новый студент. Студент добавил новый отчет. Студент перемещен в другую группу. Warn – сообщения о странной или подозрительной работе приложения.
Это еще не серьезная ошибка, но следует обратить внимание на такое поведение системы. Например: Добавлен студент с возрастом 2 года. Студент получил отрицательный балл. Преподаватель завершил курс, в котором училось 0 студентов. В группе находится больше студентов, чем максимально возможно.
Что такое лог (log) программы
Error – сообщения об ошибках в приложении. Подобные сообщения – это уже большая проблема, которую нужно решить для дальнейшей правильной работы системы. Например: Ошибка сохранения нового студента в БД. Невозможно загрузить студентов в данной группе. Ошибка при входе в личный кабинет студента. Fatal – сообщения об очень серьезных ошибках в системе.
Чаще всего это связано с работоспособностью всего приложения или его окружения на сервере. На такие сообщения следует реагировать МАКСИМАЛЬНО оперативно. Например: Приложение постоянно перезагружается из-за нехватки памяти или места на жестком диске. Приложение завершило работу по неизвестной причине. Нет доступа к базе данных. Нет доступа к сети.
Заблокирован какой-то порт. То есть, прежде чем отправить какое-то сообщение в лог, нам нужно отнести его к той или иной группе. Например, мы написали новый функционал и хотим его протестировать, как правильно и быстро он работает. Для этого мы будем использовать тип сообщений Trace, то есть все наши сообщения в логе будут помечены как Trace.
Подобным образом мы можем описать, как работает наше приложение в целом, сообщения будут с пометкой Info. Если же в опасных участках кода мы генерируем исключение, то теперь мы также добавим запись в лог с пометкой Error. К какой группе отнести то или иное сообщение решает сам разработчик. К данному вопросу следует подойти с максимальной серьезностью.
Очевидно, что ошибки не следует помечать как Info, не следует игнорировать ошибки и просто не записывать их в лог. От правильно настроенной системы логирования будет зависеть простота сопровождения всей системы, оперативность реагирования на ошибки и время, затраченное на устранение проблемы. Иногда разработчики ленятся писать логи, не хотят тратить на это время.
В дальнейшем оказывается, что время, затраченное на поиск и исправление ошибок, в разы больше времени, которое потребовалось бы на создание системы логов. Естественно, многое зависит от сложности проекта.
Если вы создаете простейший трехстраничный сайт-визитку или консольное приложение для собственных нужд у себя на локальном компьютере, то написание сложной системы логирования может быть дольше, чем создание самого проекта. В таком случае в логи можно записывать только сообщения об ошибках или почему упал сайт. Но если вы работаете над сложным проектом в команде с другими разработчиками, то грамотное ведение логов просто обязательно. Для того, чтобы начать логирование, мы подключим в наш проект платформу NLog. Это можно легко сделать посредством менеджера NuGet (прямо из Visual Studio).
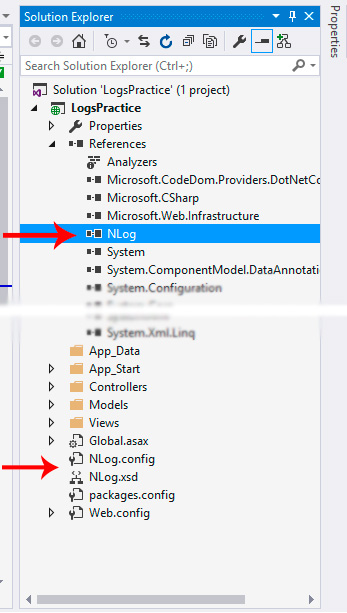
Добавление NLog Platform в проект
Обратите внимание на конфигурационный файл NLog.config. В этом файле находятся настройки логгера (куда будут выводиться логи, формат записи логов и т.д.). Давайте настроим файл следующим образом:
NLog.config
/logs/$.log» layout=»$ | $ | $> | $ $» /> /logs/errors/$.log» layout=»$ | $ | $> | $ $» />
- $ — корневой каталог нашего приложения
- $ — текущая дата в формате yyyy-MM-dd
- $ — текущая дата в формате yyyy-MM-dd HH:mm:ss.ffff
- $ — место вызова лога (название класса, название метода)
- $ — уровень логирования
- $ — непосредственно сообщение, которое будет записано в лог
- $ — символ новой строки
Далее уже в коде объявим новый логгер (здесь код проекта приводится в сокращенном виде, исходный код всего проекта можно скачать в конце статьи):
public class StudentsRepository < private static Logger logger = LogManager.GetCurrentClassLogger(); //. >
Чаще всего следует объявлять один статичный логгер в пределах всего класса. Здесь мы посредством класса-менеджера LogManager объявили новый логгер, с которым будем работать.
Начнем логирование с уровня Trace. В методе, где мы выбираем студента по его идентификатору, давайте максимально подробно опишем как это происходит:
public Student GetStudentById(int id) < //здесь моделируется ситуация реальной выборки студента из базы данных. logger.Trace(«Запрашиваемый id студента: » + id); logger.Trace(«Попытка подключения к источнику данных»); logger.Trace(«Подключение к источнику данных прошло успешно. Затраченное время(мс): » + new TimeSpan(0, 0, 0, 0, 20).Milliseconds); var student = _studentsList.FirstOrDefault(x =>x.Id == id); logger.Trace(«Выборка прошла успешно.
Выбран студент с + student.Id); return student; >
Обратите внимание, что мы на объекте logger вызываем метод Trace(). Он имеет соответствующее значение — запись в лог сообщения типа Trace. Если обратиться к определению класса Logger, то можно обнаружить, там также присутствуют и другие методы для всех уровней лога, которые мы будем использовать далее.
Теперь давайте добавим несколько сообщений уровня Debug. Как мы помним, это тоже отладочная информация, но менее детальная. Данный подход мы используем в другом методе, для наглядности:
public List GetStudents() < //здесь моделируется ситуация реальной выборки студентов из базы данных. logger.Debug(«Произведено подключение к базе данных»); logger.Debug(«Произведена выборка всех студентов»); return _studentsList; >
Идем далее. На уровне Info мы описываем регулярные операции в нашем приложении, то есть поднимаемся еще на уровень выше. Предположим, что мы работаем над ASP.NET MVC приложением, и у нас есть действие в контроллере, которое обращается к ранее описанному методу GetStudentById():
public ActionResult GetStudent(int id)
Теперь добавим в логи сообщения уровня Warn. Как мы помним, на этом уровне логирования мы описываем все потенциально опасные ситуации, странное и нелогичное поведение компонентов. Будем заносить в лог запись, если студенту меньше 15 лет:
//. Student student = repository.GetStudentById(id); logger.Trace(«Выборка прошла успешно. Выбран студент с + student.Id); if (student.Age < 15) logger.Warn(«Выбран студент моложе 15 лет»); //.
Далее обработаем ошибку в нашем коде и запишем в лог сообщение уровня Error:
var student = _studentsList.FirstOrDefault(x => x.Id == id); if (student == null) logger.Error(«Ошибка. Не найден студент с » + id); logger.Trace(«Выборка прошла успешно. Выбран студент с + student.Id); if (student.Age < 15) logger.Warn(«Выбран студент моложе 15 лет»);
Теперь определим, что же нам записать на уровне Fatal. В нашем простейшем примере просто смоделируем подобную ситуацию:
//. logger.Fatal(«Достигнут максимально допустимый в приложении предел использования оперативной памяти 90%»); //.
Мы рассмотрели все шесть уровней логирования и описали процесс работы нашего приложения максимально подробно. Теперь мы можем сразу проанализировать работу сайта, просто изучив логи, и не заглядывать в исходный код.

Просмотр log-файла
Подобным образом происходит логирование. В нашем простейшем примере, где мы моделируем работу со студентами, все предельно ясно и прозрачно даже без логов. Но в сложных проектах ведение логов является неотъемлемой частью разработки.
Конечно, это далеко не полные возможности настройки платформы NLog. В конфигурационном файле можно настроить запись логов в другие места, например, в базу данных, на консоль, в оперативную память, отправлять как емаил-сообщение, отправлять сообщения по сети и так далее. Также можно настроить фильтрацию сообщений, более сложный шаблон сообщений. Если вас не устраивает стандартный функционал логгера, то можно написать свое собственное расширение и подключить.
На этом здесь все, давайте подведем небольшой итог. Мы изучили тему логирования в приложении. Посмотрели как правильно логировать те или иные участки кода, а также познакомились с одной из самых популярных платформ логирования – это NLog Platform, также рассмотрели ее возможности и как можно настроить генерацию логов на этой платформе.
Источник: alekseev74.ru
Необходимо ли логирование программ?
К написанию данной статьи меня сподвиг опыт работы с проектами в которых либо отсутсвоала система логирования как таковая, либо присутствовало ее жалкое подобие, по которому было невозможно ни определить проблему, ни даже примерное место ее появления. Под катом немного теории и непосредственно практическая реализация класса для записи логов на С++.
Вступление
Мне часто приходилось сталкиваться с полным отсутствием понимания назначения логирования в приложениях, хотя система логирования это далеко не второстепенная фаза в разработке проекта. Но, зачастую, люди это понимают уже на стадии сдачи поекта, когда введение полноценной системы логирования — процесс достаточно затратный и как результат, оставляют все как есть.
Что в результате имеем? А имеем мы систему, в которой любая проблема у заказчика превращается в головную боль разработчика, т.к невозможно восстановить причины возникновения проблемы у заказчика, т.е у разработчика есть только описание проблемы от человека, у которого эта проблема воспроизвелась. К сожалению, мы живем не в идеальном мире и как правило описания проблемы носит малоинформативный характер, т.к пользователи системы не являются грамотными тестерами и не могут описать проблему подробно(есть конечно приятные исключения, но их мало). Особенно остро проблема логирования стоит когда нет возможности воспроизведения проблемы на своей стороне.
Типичные ошибки
- Интерфейс к логам является набором #define’ов под которыми скрывается простой fprintf в файл. А что если появится новый поток? Или понадобится более умная обработка логов? Правильно все сломается и придется переписывать.
- Строчка выводимая в лог является конкантенацией имени подсистемы и непосредственно сообщения. Например в модуле ответсвенном за взаимодействие с БД, строчка типа: «sql: ». О чем говорит эта строчка? Да ни чем, просто о факте, что где-то был выполнен запрос к БД.
- Нет timestamp при выводе строки лога.
- Нет порогового разделения логов, т.е нет возможности отключить часть логов или выключить их совсем(сомнительная опция 🙂 )
- Слишком редкая запись информации в лог(например в начале и в конце ф-ии, без трассировки ее)
- Малоинформативные записи(не выводится значения переменных и т.д)
Зачем нужны логи?
- Возможность быстрого определения причин проблемы, без многочасового сидения в дебагере, пытаясь определить проблему.
- Возможность «удаленной отладки», т.е возможность отлаживать приложение по имеющимся логам от заказчика(очень полезно когда нет возможности тестировать свое приложение без участия заказчика)
- Перекладывания части работы на техническую поддержку. Т.е support обучается типовым проблемам, секциям в логах и т.д. После чего они сами в состоянии будут определить лежащие на поверхности проблемы, не отвлекая каждый раз разработчиков по пустякам.
- Выбор имени лог файла
- Выбор директории где будут храниться лог файлы
- Включениевыключение межпроцессорной синхронизации
- Ограничение размера лог файла
- Ограничение числа лог файлов, которые могут быть сохранены в директории
- Задание процедуры, котрая будет вызвана при ошибке в записи в лог файл, или при его открытии
- Задание процедуры, которая будет изменять каждую строчку при записи, так, как необходимо пользователю. Удобно, когда Вы не хотите, чтобы кто-то посторонний читал Ваш лог.
- Уровень логов, которые в данный момент могут быть выведены(всего в классе представлен 3 уровня: Обычный, Расширеный и Дебажный). Т.е отсекает все логи приоритет которых выше порога.
Реализация:
Logger.h
namespace smart_log
typedef void (*ErrorHandler)( const std:: string
typedef const std:: string (*Obfuscater)( const std:: string
//This type provides constant which set the writing log mode.
//If a current mode is bigger then methods mode the writing will be ignored.
//It needs for log flood control
enum LogLevel;
struct LogParameters
std:: string m_strLogFileName;
//Pointer to a function which does appropriate manipulations in case of a log corruption. Set to 0 if it doesn’t need.
ErrorHandler m_pErrorHandler;
//Pointer to a function which obfuscates each string writing to a log file. Set to 0 if it doesn’t need.
Obfuscater m_pObfuscater;
size_t m_uiLogMaxSize;
unsigned short m_siMaxSavedLogs;
//Is the thread synchronization needed?
bool m_bIsMultiThreaded;
//Indicates whether log will be saved or not. If this flag is set then log will be saved when its size exceed m_uiLogMaxSize.
//Use m_siMaxSavedLogs to control how many log files will be saved. If the current number of log files has reached the m_siMaxSavedLogs then
//new saved log would replace the oldest one.
bool m_bIsSaveLog;
LogLevel m_xLogLevel;
//Path to the log location. It will be created if no exists.
boost::filesystem::path m_xLogSavedPath;
>;
class Logger
//—————————————Data
size_t m_uiCurrentLogSize;
short int m_siCurrentSavedLogs;
LogParameters m_xParameters;
std::ofstream m_xOfstream;
boost::interprocess::named_mutex m_xMutex;
//File name with full path in which it will be create
boost::filesystem::path m_xFullFileName;
//—————————————Internal methods
private :
//Common method for message writing
void WriteLog(LogLevel xLevel, const std:: string
void HandleLogSizeExcess();
std:: string Timestamp();
void CreatePath(boost::filesystem::path xPath);
//—————————————Interface
public :
Logger( const LogParameters
//Set of methods which concretize the common WriteLog method to log levels.
void WriteNormalLog( const std::ostringstream
>
void WriteExtendedLog( const std::ostringstream
>
void WriteDebugLog( const std::ostringstream
>
//————————————Setters
void SetErrorHandler(ErrorHandler pErrorHandler)
m_xParameters.m_pErrorHandler = pErrorHandler;
>
void SetLogMode(LogLevel xLevel)
m_xParameters.m_xLogLevel = xLevel;
>
>;
>
#endif _LOGGER_
* This source code was highlighted with Source Code Highlighter .
#include «Logger.h»
#include
#include
#include
#include < set >
#include
#include
namespace fs = boost::filesystem;
namespace multiprocess = boost::interprocess;
using namespace smart_log;
void Logger::WriteLog(LogLevel xLevel, const std:: string
if (m_xParameters.m_bIsMultiThreaded)
xLock = multiprocess::scoped_lock(m_xMutex, multiprocess::defer_lock_type());
xLock. lock ();
>
CreatePath(m_xParameters.m_xLogSavedPath);
//Don’t do anything if the current log level less then the message demands
if (xLevel > m_xParameters.m_xLogLevel)
return ;
if (m_uiCurrentLogSize + strMessage.length() > m_xParameters.m_uiLogMaxSize)
HandleLogSizeExcess();
if ( !m_xOfstream.is_open() )
m_xOfstream.open( (m_xFullFileName.file_string() + «-» + Timestamp() + «.log» ).c_str() );
//Make an output string
std::ostringstream xStream;
xStream const std:: string
if (m_xParameters.m_pObfuscater)
m_xOfstream else
m_xOfstream m_uiCurrentLogSize += strMessage.length();
>
catch (std::ofstream::failure xFail)
if (m_xParameters.m_pErrorHandler)
m_xParameters.m_pErrorHandler( «Problem with a file creation or writing to the already existing file.» );
else
throw ;
>
void Logger::HandleLogSizeExcess()
if (m_xOfstream.is_open())
m_xOfstream.close();
//Goes through the log directory and finds files which looks like «m_strLogFileName-*Timestamp*»
fs::directory_iterator xEndIterator;
std:: set xFileList;
for ( fs::directory_iterator it(m_xParameters.m_xLogSavedPath); it != xEndIterator; ++it )
std:: string xCurrentFile = it->path().filename();
if ( fs::is_regular_file(it->status()) )
if (xCurrentFile.find(m_xParameters.m_strLogFileName) != std:: string ::npos)
xFileList.insert(xCurrentFile);
>
//If the log files number exceeds the m_siMaxSavedLogs then keep on removing
//files until current files number won’t be less then threshold
if (m_xParameters.m_siMaxSavedLogs)
if (xFileList.size() >= m_xParameters.m_siMaxSavedLogs)
for (std:: set ::iterator it = xFileList.begin(); it != xFileList.end()
xFileList.size() >= m_xParameters.m_siMaxSavedLogs;)
fs::remove(fs::path(m_xParameters.m_xLogSavedPath) /= *it);
xFileList.erase(it++);
>
>
>
else //Save files property is turned off hence remove all existing log files
for (std:: set ::iterator it = xFileList.begin(); it != xFileList.end();)
fs::remove(fs::path(m_xParameters.m_xLogSavedPath) /= *it);
xFileList.erase(it++);
>
>
m_uiCurrentLogSize = 0;
//Create a new file
m_xOfstream.open( (m_xFullFileName.file_string() + «-» + Timestamp() + «.log» ).c_str() );
>
void Logger::CreatePath(fs::path xPath)
try
//If a directory doesn’t exist then try to create full path up to the required directory
if ( !fs::exists(m_xParameters.m_xLogSavedPath) )
fs::path xTmpPath;
for (fs::path::iterator xIt = m_xParameters.m_xLogSavedPath.begin();
xIt != m_xParameters.m_xLogSavedPath.end();
++xIt)
xTmpPath /= *xIt;
if ( !fs::exists(xTmpPath) )
fs::create_directory(xTmpPath);
>
>
>
catch (fs::basic_filesystem_error)
<
if (m_xParameters.m_pErrorHandler)
m_xParameters.m_pErrorHandler( «Problem with a directory creation» );
else
throw ;
>
* This source code was highlighted with Source Code Highlighter .
Пример создания удобного интерфейса к классу:
#include «Logger.h»
#include
#include
#include
class LogInstance
static boost::scoped_ptr m_spLogger;
public :
static const boost::scoped_ptr
xParams.m_bIsMultiThreaded = true ;
xParams.m_pErrorHandler = 0;
xParams.m_pObfuscater = 0;
xParams.m_siMaxSavedLogs = 0;
xParams.m_strLogFileName = «log_file» ;
xParams.m_uiLogMaxSize = 8192;
xParams.m_xLogLevel = smart_log::eNormal;
xParams.m_xLogSavedPath = «./log/log/log» ;
m_spLogger.reset( new smart_log::Logger(xParams));
>
return m_spLogger;
>
* This source code was highlighted with Source Code Highlighter .
Надеюсь этим постом я сподвигну людей не использующих логи, на их использование и надеюсь моя реализацию будет им полезна. Удачной всем отладки 🙂
Источник: habr.com
Где посмотреть и как читать логи с ошибками сервера

Блоги, форумы, посадочные страницы и другие интернет-ресурсы представляют собой совокупность графического, текстового, аудио- и видео-контента, размещенного на веб-страницах в виде кода. Чтобы обеспечить к ним доступ пользователей через интернет, файлы размещают на серверах.
Это аппаратное обеспечение (персональный компьютер или рабочая станция), на жестком диске которого и хранится код. Ключевые функции выполняются без участия человека, что актуально для всех типов оборудования, включая виртуальный выделенный сервер. Но это не означает, что контроль не осуществляется. Большинство событий, которые происходят при участии оборудования, пользователей и софта, включая ошибки, логи сервера фиксируют и сохраняют. Из этой статьи вы узнаете, что они собой представляют, зачем нужны, и как их читать.

Что такое логи
Это текстовые файлы, которые хранятся на жестком диске сервера. Создаются и заполняются в автоматическом режиме, в хронологическом порядке. В них записываются:
- системная информация о переданных пользователю данных;
- сообщения о сбоях и ошибках;
- протоколирующие данные о посетителях платформы.
Посмотреть логи сервера может каждый, у кого есть к ним доступ, но непосвященному обывателю этот набор символов может показаться бессмысленным. Интерпретировать записи и получить пользу после прочтения проще профессионалу.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Классификация логов
Для каждой разновидности софта предусмотрены соответствующие файлы. Все логи сервера могут храниться на одном диске или даже на отдельном сервере. Существует довольно много разновидностей логов, вот наиболее распространенные:
- доступа (access_log) — записывают IP-адрес, время запроса, другую информацию о пользователях;
- ошибок (error_log) — показывают файлы, в которых выявлены ошибки и классифицируют сбои;
- FTP-авторизаций — отображают данные о попытках входа по FTP-соединению;
- загрузки системы — с его помощью выполняется отладка при появлении проблем, в файл записываются основные системные события, включая сбои;
- основной — содержит информацию о действиях с файерволом, DNS-сервером, ядром системы, FTP-сервисом;
- планировщика задач — в нем выполняется протоколирование задач, отображаются ошибки при запуске cron;
- баз данных — хранит подробности о запросах, сбоях, ошибки в логах сервера отображаются наравне с другой важной информацией;
- хостинговой панели — включает статистику использования ресурсов сервера, время и количество входов в панель, обновление лицензии;
- веб-сервера — содержит информацию о возникавших ошибках, обращениях;
- почтового сервера — в нем ведутся записи о входящих и исходящих сообщениях, отклонениях писем.
Записи в системные журналы выполняет установленный софт.
Зачем нужны логи
Анализ логов сервера — неотъемлемая часть работы системного администратора или веб-разработчика. Обрабатывая их, специалисты получают массу полезных сведений. Используются в следующих целях:
- поиск ошибок и сбоев в работе системы;
- выявление вредоносной активности;
- сбор статистики посещения веб-ресурса.
После изучения информации можно получить точную статистику в виде сводных цифр, информацию о юзерах, выявить поведенческие закономерности пользовательских групп.

Где посмотреть логи
Расположение определяется хостинг-провайдером или настройками установленного софта. На виртуальном хостинге доступ к лог-файлам предоставляется из панели управления хостингом. Если администратор не открыл его для владельца сайта, получить информацию не получится. Но большинство провайдеров разрешают свободно пользоваться журналами и проводить анализ логов сервера.
Независимо от разновидности сервера лог-файлы хранятся в текстовом документе. По умолчанию он называется access.log, но настройки позволяют переименовать файл. Это актуально для Nginx, Apache, прокси-разновидностей squid, других типов. Для просмотра их надо скачать и открыть в текстовом редакторе. В качестве альтернативы можно использовать Grep и схожие утилиты.
Они позволяют открыть и отфильтровать логи прямо на сервере.

Как читать логи. Пример
Существует довольно много форматов записи, combined — один из наиболее распространенных. В нем строчка кода может выглядеть так:
%h %l %u %t «%r» %>s %b «%i» «%i»
Директивы имеют следующее значение:
- %h — IP-адрес, с которого был сделан запрос;
- %l — длинное имя удаленного хоста;
- %u — удаленный пользователь, если запрос был сделан аутентифицированным юзером;
- %t — время запроса к серверу и его часовой пояс;
- %r — тип и содержимое запроса;
- %s — код состояния HTTP;
- %b — количество байт информации, отданных сервером;
- % — URL-источник запроса;
- % — HTTP-заголовок.
Еще один пример чтения логов можно посмотреть в статье «Как читать логи сервера».
Опытные веб-мастера для сбора и чтения лог-файлов используют программы-анализаторы. Они позволяют читать логи сервера без значительных временных затрат. Вот некоторые из наиболее востребованных:
- Analog. Один из самых популярных анализаторов, что во многом объясняется высокой скоростью обработки данных и экономным расходованием системных ресурсов. Хорошо справляется с объемными записями, совместим с любыми ОС.
- Weblog Expert. Программа доступна в трех вариациях: Lite (бесплатная версия), Professional и Standard (платные релизы). Версии отличаются функциональными возможностями, но каждая позволяет анализировать лог-файлы и создает отчеты в PDF и HTML.
- SpyLOG Flexolyzer. Простой аналитический инструмент, позволяющий получать отчеты с высокой степенью детализации. Интегрируется c системой статистики SpyLOG, позволяет решать задачи любой сложности.
Логи сервера с ошибками error.log
Это журнал с информацией об ошибках на сайте. В нем можно посмотреть, какие страницы отсутствуют, откуда пришел пользователь с конкретным запросом, имеются ли «битые» ссылки, другие недочеты, включая те, которые не удалось классифицировать. Используется для выявления багов и погрешностей в коде.
Каждая ошибка в логе сервера error.log отображается с новой строки. Идентифицировав и устранив ее, программист сможет наладить работу сайта. Используя журнал, можно выявить и слабые места веб-платформы. Это простой и удобный инструмент анализа, которым должен уметь пользоваться каждый веб-мастер, системный администратор и программист.
Источник: timeweb.com
Логирование: что это и в чем его польза
Если в работе сервера, компьютера или программного обеспечения возникла неизвестная ошибка, в первую очередь смотрят логи. Лог — текстовый файл с информацией о действиях программного обеспечения или пользователей, который хранится на компьютере или сервере. Это хронология событий и их источников, ошибок и причин, по которым они произошли. Читать и анализировать логи можно с помощью специального ПО.
Логирование: что это и где применяется
- Администратор ищет причины возникновения технических проблем, сбоев в устройства или операционной системы и недоступности сайта.
- Разработчик проводит дебаг, то есть ищет, локализует и устраняет ошибки.
- Seo-специалисты собирают статистику посещаемости, оценивают качество целевого трафика.
- Администратор интернет-магазина отслеживает историю взаимодействия с платежными системами и данные об изменениях в заказах.
Типы логов
Существуют разные уровни и разные подробности логирования. Когда ошибку сложно воспроизвести, используют максимально подробные логи; если это не требуется, собирают только ключевую информацию. Для работы с логами и поиском информации в огромных текстовых данных используют специализированные инструменты.
Для удобной работы с логами их делят на типы. Это помогает быстрее находить нужные и выбирать правильные инструменты для работы с ними. Например, выделяют:
- системные логи, то есть те, которые связаны с системными событиями;
- серверные логи, регистрирующие обращения к серверу и возникшие при этом ошибки;
- логи баз данных, фиксирующие запросы к базам данных;
- почтовые логи, относящиеся к входящим/исходящим письмам и отслеживающие ошибки, из-за которых письма не были доставлены;
- логи авторизации;
- логи аутентификации;
- логи приложений, установленных на этих операционных системах.
Также логи можно типизировать по степени их важности:
- Fatal/critical error — то, что нужно срочно исправить.
- Not critical error — ошибки, которые не влияют на пользователя.
- Warning — предупреждения, то, на что нужно обратить внимание.
- Initial information — информация о вызовах API сервиса, запросах в БД, вызовах других сервисов.
Где ITGLOBAL.COM использует логирование
Специалисты ITGLOBAL.COM настраивают автоматический сбор, хранение и обработку логов в облачном хранилище. Облако позволяет воспроизвести события на целевой системе даже при ее полном отказе.
Поясним на примере. Допустим, файловая система одной из виртуальных машин повредилась и все данные на сервере были уничтожены. Инженеры получают уведомление об этом инциденте от системы мониторинга и восстанавливают работоспособность сервера через бэкапы. После этого они анализируют логи, которые сохранились благодаря удаленной системе хранения. Они похожи на черный ящик самолета, так как с их помощью специалисты восстанавливают последовательность событий при инциденте, делают выводы и вырабатывают решения, которые предотвратят появление таких инцидентов в будущем.
Также инженеры ITGLOBAL.COM используют логи для анализа действий пользователей. Они в любой момент могут восстановить, кто и когда совершал определенные действия внутри системы. Для этого специалисты используют инструменты, которые автоматически контролируют базовые события, касающиеся безопасности. Например, если в субботу ночью появится учетная запись с правами суперпользователя, система сразу зарегистрирует это событие и пришлет уведомление. Инженеры уточнят легитимность новой записи, чтобы предотвратить попытку несанкционированного доступа.
Инструменты
Сбор, хранение и анализ логов выполняется с помощью специальных инструментов. Расскажем, какие из них используют специалисты ITGLOBAL.COM.
Elasticsearch, Logstash и Kibana
Логи всех информационных систем, подключенных к услуге Managed IT, хранятся в распределенном хранилище на базе решения ELK (Elasticsearch, Logstash и Kibana). Механизм сбора логов выглядит так: Logstash собирает логи и переносит их в хранилище, Elasticsearch помогает найти нужные строки в этих логах, а Kibana визуализирует их. Все три компонента разработаны на основе открытого кода, благодаря чему их можно модифицировать под потребности компании.
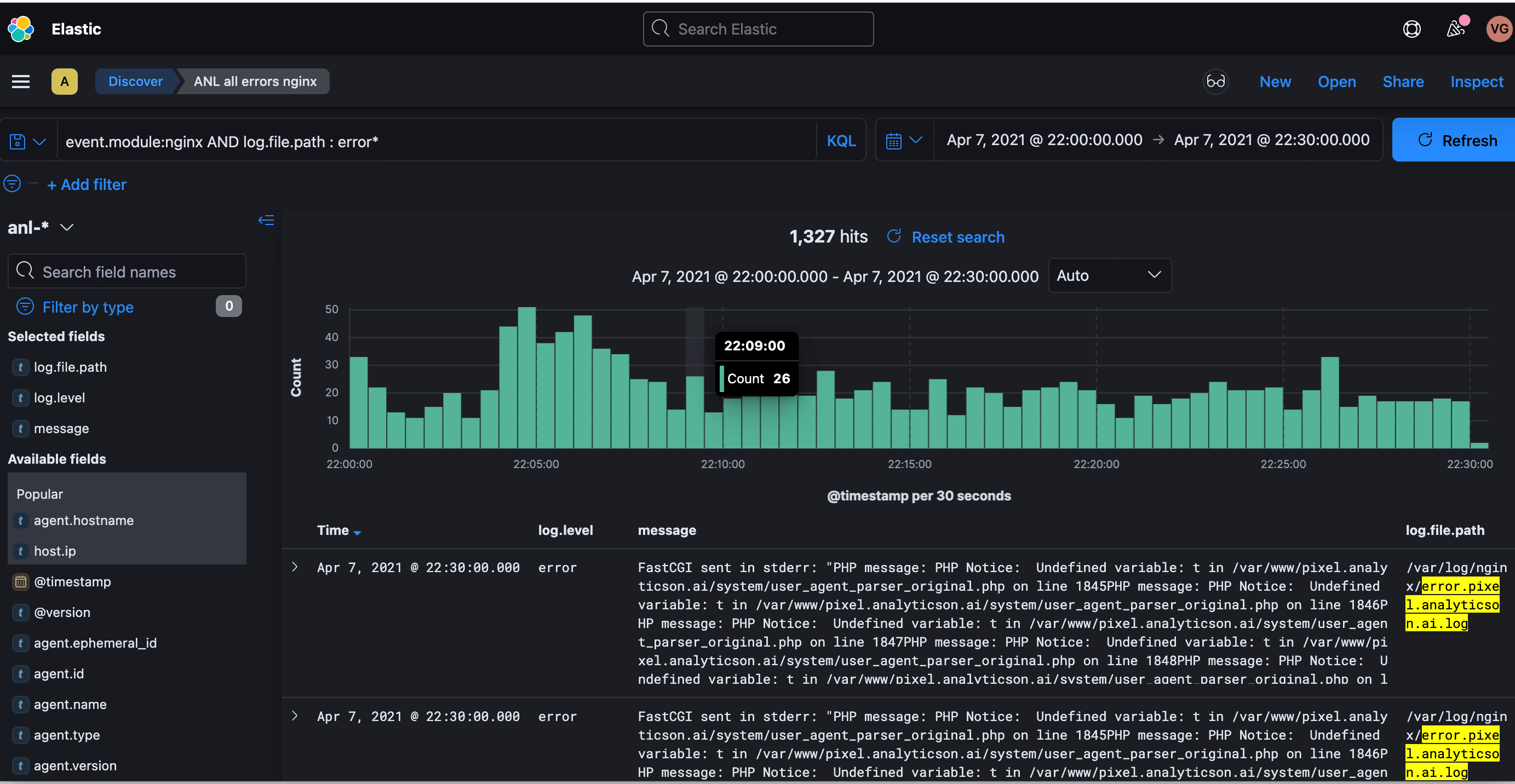
- Logstash — приложение для работы с большими объемами данных, собирает информацию из разных источников и переводит ее в удобный формат.
- Elasticsearch — система для поиска информации. Помогает быстро найти нужные строки в файлах хранения.
- Kibana — плагин визуализации данных и аналитики в Elasticsearch. Помогает обрабатывать информацию, находить в ней закономерности и слабые места.
Wazuh
Решение с открытым кодом для поиска логов, коррелирующих с моделями угроз информационной безопасности. С его помощью специалисты ITGLOBAL.COM мониторят целостность ИТ-систем и оперативно реагируют на инциденты.
- обнаружить скрытые процессы программ, которые используют уязвимости в ПО для обхода антивирусных систем;
- автоматически блокировать сетевую атаку, останавливать вредоносные процессы и файлы, зараженные вирусами.
Почему логирование нужно каждой компании
Логирование — еще один способ эффективно контролировать состояние инфраструктуры. В ITGLOBAL.COM оно входит в пакет услуг Managed IT. Вместе с сервисами мониторинга логирование существенно экономит время инженеров при расследовании тех или иных инцидентов. А главное, с помощью анализа логов можно предотвратить инциденты в будущем.
Компании, которые используют логирование в рамках услуги Managed IT, уменьшают общее количество инцидентов и получают принципиально другой уровень контроля над инфраструктурой.
Также сервис удобен для разработчиков, которые с помощью простых интерфейсов могут в режиме реального времени отслеживать работу своих приложений.
Источник: itglobal.com
Как разобраться с логированием: гайд для начинающих
Этот материал мы ориентировали на тех, кто в первый раз сталкивается с логированием серверных служб и web-серверов. Познакомим с уровнями логирования, расскажем об основных типах логов и перечислим инструменты для работы с ними.
Зачем оно вообще нужно, это логирование?

На анализе логов базируется работа большинства ИТ-специалистов. Администраторы ищут в файлах логирования причины сбоя сервиса. Разработчики опираются на логи, чтобы локализовать и устранить ошибки приложения или веб-сайта. Служба безопасности по логам, как по физическим уликам, определяет вид взлома, оценивает нанесенный ущерб и даже может идентифицировать взломщика. Вот почему логирование мы рекомендуем отладить в первую очередь: в любой непонятной ситуации ответ на вопрос вы будете искать в логах!
Файлы логирования
Уровни логирования
- Debug — запись масштабных переходов состояний, например, обращение к базе данных, старт/пауза сервиса, успешная обработка записи и пр.
- Warning — нештатная ситуация, потенциальная проблема, может быть странный формат запроса или некорректный параметр вызова.
- Error — типичная ошибка.
- Fatal — тотальный сбой работоспособности, когда нет доступа к базе данных или сети, сервису не хватает места на жестком диске.
Дополнительно файл логирования может расширяться записями еще двух уровней:
- Trace — пошаговые записи процесса. Полезен, когда сложно локализовать ошибку.
- Info — общая информация о работе службы или сервиса.
Работа с уровнями логирования регламентируется методическими документами и внутренними правилами организации. В них может определяться соответствие источника сообщения уровню логирования, значимость, порядок обработки каждого уровня и другие параметры.
Типы логов
Для удобства обработки логов их делят на типы:
- системные, связанные с системными событиями,
- серверные, отвечающие за процесс обращения к серверу,
- почтовые, работающие с отправлениями,
- логи баз данных, которые отражают процессы обращения к базам данных,
- авторизационные и аутентификационные, которые отвечают за процесс входа, выхода из системы, восстановление доступа и пр.
У каждого типа логов свой журнал записи. Для проверки логов авторизации нужно идти в журнал доступов, чтобы проверить загрузку системы — в журнал dmesg, за данными о запросах пользователей — в access_log. Когда одни логи пишутся отдельно от других, проще диагностировать ситуацию и найти источник проблемы.

Логи в access_log
Инструменты для работы с логами
Сбор, хранение и анализ логов вручную хороши, когда у вас один сервер. Когда серверный парк разрастается, а приложений и сервисов становится больше десяти, работу с логами целесообразно автоматизировать и использовать специальные системы логирования, например, Graylog, ELK, Loggy или Splunk. Некоторые из них позволяют организовать полномасштабный мониторинг, настроить алерт раннего обнаружения конкретной проблемы или установить пороговые значения показателей, коррелирующих с угрозами информационной безопасности.
Логи сетевого, инженерного оборудования, баз данных и приложений мы храним в облачном хранилище. И вам советуем. Даже когда у вас полно места на жестких дисках и стоит мощная защита на все случаи жизни. Оборудование рано или поздно, а чаще неожиданно, выходит из строя, а злоумышленники давно умеют чистить файлы логирования, так что логи в облаке — это возможность восстановить события и расследовать инцидент даже при полном отказе системы.
Хранение логов в облаке
Логирование кажется второстепенным процессом, который занимает время, но не дает видимых результатов. Однако это только кажется и только до тех пор, пока не появится реальная проблема, с которой можно разобраться только по логам. И только если они записаны, распределены по уровням, собираются и доступны для анализа.
Источник: greendc.ru