

Логи можно сравнить с уликами на месте преступления, а разработчиков — с криминалистами. Роль логов трудно переоценить, ведь когда необходимо найти баг или причину сбоя, сразу обращаются к ним. Подобно тому, как отсутствие улик приводит к нераскрытым делам, отсутствие содержательных логов осложняет диагностику и устранение ошибок, превращая их в затянувшийся или вовсе невыполнимый процесс. Мне приходилось наблюдать, как люди мучились с такими инструментами, как Strace и tcpdump, или развертывали новый код в продакшене во время сбоя лишь затем, чтобы получить больше лог-файлов для выявления проблемы.

Как говорится: “Хорошо подготовиться — половину дела сделать”, так что каждому профессиональному разработчику следует научиться эффективно вести логи и быть готовым к работе с ними. В данной статье мы не только рассмотрим список полезных практик логирования в приложении, но и разберем теоретические основы данного процесса: что записываем, когда и кто этим должен заниматься.
Логи Linux. Всё о логах и журналировании
Как осуществляется процесс отладки?
Прежде чем начать разговор о логах, необходимо ответить на два вопроса:
- Что такое программа?
- Как осуществляется отладка, в которой логи играют важную роль?
Программа как переходы состояний
Программа — это серия переходов между состояниями.
Состояния — это вся информация, которую программа хранит в своей памяти в определенный момент времени, а код программы определяет то, как она переходит от одного состояния к другому. Разработчики, использующие императивные языки программирования, такие как Java, зачастую акцентируют больше внимания на самом процессе (коде), чем состояниях. Однако понимание того, что программа является серией состояний, очень важно, поскольку они существенно ближе к тому, что должна делать программа, а не как.
Допустим, есть робот, задача которого — заполнить бензобак машины. Если мы рассмотрим выполняемые им действия как переходы состояний, то ему необходимо перейти от состояния (бак пустой, в наличии 50 $) к состоянию (бак полный, в наличии 15 $). Если же мы описываем его как процесс, то он должен найти заправку, доставить туда машину и заплатить. Конечно же, процесс имеет большое значение, но состояния дают более точную оценку правильности программы.
Отладка
Отладка — это мысленная реконструкция переходов состояний. Разработчики проигрывают в уме сценарий программы: как она принимает вводные данные, проходит через ряд изменений состояний и осуществляет вывод, а затем определяют, что пошло не так. Во время разработки этот мыслительный процесс подкрепляется использованием отладчика. Однако в продакшене делать это уже гораздо сложнее, поэтому на данном этапе чаще прибегают к помощи логов.
Как логи всё о Вас расскажут
Что записывать в лог ?
Понимая суть процесса отладки, мы с легкостью ответим на этот вопрос:
Логи должны содержать информацию, необходимую для реконструкции переходов состояний.
Невозможно, да и не нужно, фиксировать все состояния во все отрезки времени. Например, полиции достаточно лишь нескольких точных набросков, а не видеоклона, для поимки преступника. Тоже самое относится и к логам: разработчикам нужно только внести в них информацию о том, когда происходит переход в критическое состояние. Кроме того, логи должны содержать ключевые характеристики текущего состояния и причину перехода.
Переход в критическое состояние
Не все переходы состояний стоит записывать в лог. Важно рассмотреть программу как серию изменяемых состояний, разделить их на фазы и затем сосредоточиться на времени, когда выполнение переходит от одной фазы к другой.
Предположим, что существуют 3 фазы запуска приложения:
- загрузка настроек программы;
- подключение к зависимостям;
- запуск сервера.
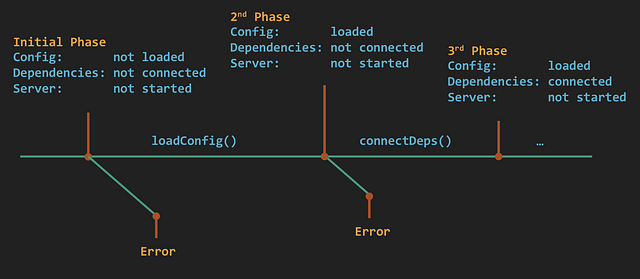
Было бы очень разумно вести логи в начале и конце каждой фазы. Если бы произошла ошибка на этапе подключения к зависимостям и приложение бы зависло, то логи отчетливо показали бы, что после загрузки настроек оно вошло во вторую фазу процесса, не завершив его. Располагая этой информацией, разработчики смогли бы быстро определить проблему.
Ключевые характеристики
Логирование состояний напоминает создание эскизов программы только с учетом ключевых характеристик основ бизнес-логики. Если есть информация закрытого характера, например персональные данные, то ее также нужно записать в лог, но в завуалированном виде.
Например, когда HTTP-сервер переходит из состояния ожидания запроса в состояние получения запроса, он должен зафиксировать в логе HTTP-метод и URL, так как они описывают основы HTTP-запроса. Остальные его элементы (заголовки или часть тела сообщения) записываются в том случае, если их значения влияют на бизнес-логику. Например, если поведение сервера сильно отличается между состояниями Content-Type:application/json и Content-Type:multipart/form-data, заголовок следует записать.
Причина перехода состояния
Пример
Рассмотрим простой пример для обобщения всего сказанного. Предположим, что сервер получает некорректный номер социального страхования, и разработчик намерен внести в лог информацию об этом событии.
Вот несколько анти-шаблонов логов, в которых отсутствуют ключевые характеристики состояния и причины:
- [2020–04–20T03:36:57+00:00] server.go: Error processing request (Запрос на обработку ошибок)
- [2020–04–20T03:36:57+00:00] server.go: SSN rejected (Номер социального страхования отклонен)
- [2020–04–20T03:36:57+00:00] server.go: SSN rejected for user UUID “123e4567-e89b-12d3-a456–426655440000” (Номер социального страхования отклонен для пользователя UUID “123e4567-e89b-12d3-a456–426655440000”)
Все они содержат определенную информацию, но ее недостаточно для ответов на вопросы, которые могут возникнуть у разработчиков в процессе поиска ошибки. Какой запрос не смог обработать сервер? Почему номер социального страхования был отклонен? Какой пользователь столкнулся с этой ситуацией? Грамотный и полезный для отладки лог будет выглядеть так:
[2020–04–20T03:36:57+00:00] server.go: Received a SSN request(track id: “e4a49a27–1063–4ab3–9075-cf5faec22a16”) from user uuid “123e4567-e89b-12d3-a456–426655440000”(previous state), rejecting it(next state) because the server is expecting SSN format AAA-GG-SSSS but got **-***(why)
([2020–04–20T03:36:57+00:00] server.go: Получен запрос номера социального страхования (трек id: “e4a49a27–1063–4ab3–9075-cf5faec22a16”) от пользователя user uuid “123e4567-e89b-12d3-a456–426655440000” (предыдущее состояние), запрос отклонен (следующее состояние), так как сервер требует номер социального страхования в формате AAA-GG-SSSS, а получил **-*** (причина)
Кто должен записывать логи?
Типичная ошибка, которую многие допускают, связана с тем, “кто” должен фиксировать информацию. Ведение логов не теми функциями оборачивается дублированием или дефицитом информации.
Программа как уровни абстракции
Большинство грамотно созданных программ подобны пирамиде с уровнями абстракции. Классы/функции верхних уровней разбивают сложную задачу на подзадачи, тогда как классы/функции нижних уровней абстрагируют реализацию подзадач, таких как черные ящики, и предоставляют интерфейсы для вызова верхним уровнем. Эта парадигма облегчает программирование, поскольку каждый уровень сосредоточен на своей логике, не беспокоясь о всевозможных деталях.
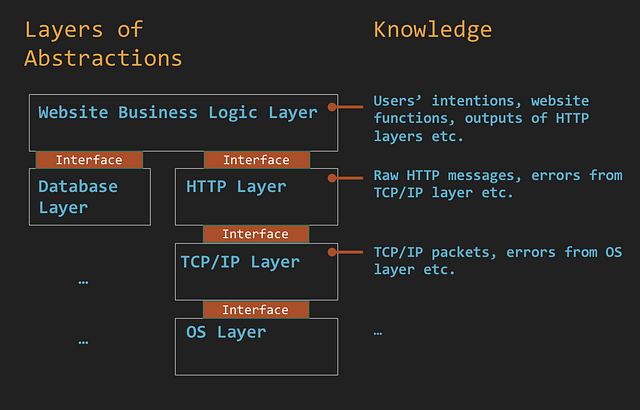
Например, веб-сайт может состоять из следующих уровней: бизнес-логика, HTTP и TCP/IP. Реагируя на URL-запрос, уровень бизнес-логики решает, какую веб-страницу показать, и отправляет ее контент на уровень HTTP, где он превращается в HTTP-ответ. Следующий уровень TCP/IP преобразует HTTP-ответ в пакеты TCP и рассылает их.
Ведите логи только на правильных уровнях
Как следствие абстракции, разные уровни имеют разные степени понимания выполняемой задачи. В предыдущем примере уровень HTTP не владел данными ни о количестве отправляемых пакетов TCP, ни о намерении пользователей в момент URL-запроса. Предпринимая попытку логирования, разработчикам следует выбрать правильный уровень, который содержит полную информацию о переходах состояний и причинах.
Вернемся к нашему примеру проверки корректности номера социального страхования. Допустим, что логика его проверки обернута в класс Validator следующим образом:
public class Validator < // другие функции проверки. public static void validateSSN(String ssn) throws ValidationException < // выполнение проверки String regex = «^(?!000|666)[0-8][0-9]-(?!00)[0-9]-?!0000)[0-9]$»; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(ssn); if (!matcher.matches()) < // —>Записываем в лог местоположение A > >
Есть еще другая функция, которая проверяет запрос, обновляющий информацию о пользователе, и вызывает проверку номера социального страхования.
public class Validator < // другие функции проверки. public static void validateUserUpdateRequest(UserUpdateRequestreq) < // проверка другого атрибута req . try < validateSSN(req.ssn); >catch (ValidationException e) < // —>Записываем в лог местоположение B // остальная логика. > >
Существует два местоположения (A и B) для записи логов об ошибке проверки номера социального страхования, но только B владеет достаточной для этого информацией . В A программа не знает, ни какой запрос она обрабатывает, ни от какого пользователя он поступает. Логирование просто добавляет деталей. Будет лучше, если validateUserUpdateRequest выбросит ошибку из вызывающего компонента (validateRequest), содержащего больше контекста для лога.
Однако это вовсе не означает, что логирование на нижних уровнях программы совершенно необязательно, особенно когда они не раскрывают ошибки верхним уровням. Например, сетевой уровень может иметь встроенную логику повторных попыток, из чего следует, что верхние уровни не замечают проблем с прерывающимися соединениями. В общем, нижние уровни могут вести логи больше на уровне DEBUG, чем на INFO, в целях сокращения многословности. При необходимости разработчики могут настроить уровень лога для получения большего количества деталей.
Сколько должно быть логов?
Существует очевидное соотношение между объемом логов и их полезностью. Чем более содержательные логи, тем легче реконструировать переходы состояний. Вы можете воспользоваться двумя способами контроля количества логов:
Установите соотношение между логами и рабочей нагрузкой
Для контроля объема логов сначала важно его правильно измерить. Большинство программ имеют 2 типа рабочей нагрузки:
- получение рабочих элементов (запросов) и последующая реакция на них;
- запрос рабочих элементов откуда-либо и последующее выполнение действий.
В большинстве случаев процесс логирования запускается рабочей нагрузкой: чем больше ее у программы, тем больше логов она записывает. Могут быть и другие логи, не связанные с рабочей нагрузкой, но они становятся малозначимыми, когда программа начинает работу. Разработчики должны сохранять соотношение # логов и # рабочих элементов линейным. Иначе говоря:
# логов = X * # рабочих элементов+ константы
где X можно определить, изучив код. Разработчики должны иметь хорошее представление об X-факторах для своих программ и приводить их в соответствие с возможностями логирования и бюджетом. Вот еще несколько типичных случаев X:
- 0 < X < 1. Это значит, что логи отбираются выборочно, и не у всех рабочих элементов они есть, например ведётся запись только ошибок или используются другие алгоритмы отбора логов. Это способствует снижению объемов лога, но при этом может ограничить возможности поиска проблемы.
- X ~ 1. Это значит, что в среднем каждый рабочий элемент производит примерно одну запись. И это целесообразно до тех пор, пока один лог содержит достаточно информации (подробно в разделе “Что записывать в лог?”).
- X >> 1. У разработчиков должна быть весомая причина для того, чтобы X был существенно больше, чем 1. Когда рабочая нагрузка возрастает, например в случае с сервером, на который обрушивается внезапный шквал HTTP-запросов, то X лишь усиливает ее и чрезмерно нагружает инфраструктуру логирования, что обычно вызывает проблемы.
Используйте уровни логов
Что, если X все еще слишком большой даже после оптимизации? На помощь приходят уровни логов. Если X намного больше, чем 1, то можно поместить логи на уровень DEBUG, тем самым снизив X уровня INFO. В процессе устранения неполадок программа может временно выполняться на этом уровне для предоставления дополнительной информации.
Краткие выводы
Чтобы профессионально писать логи, следует рассматривать программу как серию переходов состояний с уровнями абстракции. Владея теоретическими знаниями, можно ответить на ключевые вопросы о логировании в приложении:
1.Когда писать логи? В момент перехода в критическое состояние.
2.Что записывать в лог? Ключевыехарактеристики текущего состояния и причину перехода состояния.
3.Кто должен записывать логи? Логирование должно происходить на правильном уровне, содержащем достаточно информации.
4.Каким должно быть количество логов? Определите X-фактор (по формуле # логов = X * # рабочих элементов+ константы) и настройте его экономно, но выгодно.
- Логирование в Python с помощью Logzero
- Используйте перечисления, а не логические аргументы
- Логи в Python. Настройка и централизация
Источник: nuancesprog.ru
Зачем нужно логирование
Привет! При написании лекций я особо отмечаю, если какая-то конкретная тема обязательно будет использоваться в реальной работе.  Так вот, ВНИМАНИЕ! Тема, которой мы коснемся сегодня, точно пригодится тебе на всех твоих проектах с первого дня работы. Мы поговорим о логировании.
Так вот, ВНИМАНИЕ! Тема, которой мы коснемся сегодня, точно пригодится тебе на всех твоих проектах с первого дня работы. Мы поговорим о логировании.
Тема эта совсем не сложная (я бы даже сказал легкая). Но на первой работе и без того будет достаточно стресса, чтобы еще разбираться с очевидными вещами, поэтому лучше досконально разобрать ее сейчас 🙂 Итак, начнем. Что такое логирование? Логирование — это запись куда-то данных о работе программы. Место, куда эти данные записываются называется «лог».
Возникает сразу два вопроса — куда и какие данные записываются? Начнем с «куда». Записывать данные о работе программы можно во множество разных мест. Например, ты во время учебы часто выводил данные в консоль с помощью System.out.println() . Это настоящее логирование, хоть и самое простое.
Конечно, для клиента или команды поддержки продукта это не очень удобно: они явно не захотят устанавливать IDE и мониторить консоль 🙂 Есть и более привычный человеку формат записи информации — в текстовый файл. Людям гораздо удобнее читать их в таком виде, и уж точно гораздо удобнее хранить! Теперь второй вопрос: какие данные о работе программы должны записываться в лог?
А вот здесь все зависит от тебя! Система логирования в Java очень гибкая. Ты можешь настроить ее таким образом, что в лог попадет весь ход работы твоей программы. Это, с одной стороны, хорошо. Но с другой — представь себе, каких размеров могут достичь логи Facebook или Twitter, если туда писать вообще все.
У таких крупных компаний наверняка есть возможность хранить даже такое количество информации. Но вообрази, как сложно будет искать информацию об одной критической ошибке в логах на 500 гигабайт текста? Это даже хуже, чем иголка в стоге сена. Поэтому логирование в Java можно настроить так, чтобы в журнал (лог) записывались только данные об ошибках.
Или даже только о критических ошибках! Хотя, говорить «логирование в Java» не совсем верно. Дело в том, что потребность ведения логов возникла у программистов раньше, чем этот функционал был добавлен в язык. И к тому времени, как в Java появился собственная библиотека для логирования, все уже пользовались библиотекой log4j.
История появления логирования в Java на самом деле очень долгая и познавательная, на досуге можешь почитать этот пост на Хабре. Короче говоря, своя библиотека логирования в Java есть, но ей почти никто не пользуется 🙂 Позже, когда появились несколько разных библиотек логирования, и все программисты начали пользоваться разными, возникла проблема совместимости.
Чтобы люди не делали одно и то же с помощью десятка разных библиотек с разными интерфейсами, был создан абстрагирующий фреймворк slf4j («Service Logging Facade For Java»). Абстрагирующим он называется потому, что хотя ты и пользуешься классами slf4j и вызываешь их методы, под капотом у них работают все предыдущие фреймворки логирования: log4j, стандартный java.util.logging и другие.
Если тебе в данный момент нужна какая-то специфическая фича log4j, которой нет у других библиотек, но ты не хотел бы при этом жестко привязывать проект именно к этой библиотеке, просто используй slf4j. А о она уже «дернет» методы log4j. Если ты передумаешь и решишь, что фичи log4j тебе больше не нужны, тебе надо только перенастроить «обертку» (то есть slf4j) на использование другой библиотеки.
Твой код не перестанет работать, ведь в нем ты вызываешь методы slf4j, а не конкретной библиотеки. Небольшое отступление. Чтобы следующие примеры заработали, тебе нужно скачать библиотеку slf4j отсюда, и библиотеку log4j отсюда. Далее архив нужно распаковать,и добавить нужные нам jar-файлы в classpath через Intellij IDEA. Пункты меню: File -> Project Structure -> Libraries Выбираешь нужные jar-ники и добавляешь в проект (в архивах, которые мы скачали, лежит много jar’ников, посмотри нужные на картинках) 
 Примечание — эта инструкция для тех студентов, которые не умеют использовать Maven. Если ты умеешь им пользоваться, лучше попробуй начать с него: это обычно намного проще Если используешь Maven, добавь такую зависимость:
Примечание — эта инструкция для тех студентов, которые не умеют использовать Maven. Если ты умеешь им пользоваться, лучше попробуй начать с него: это обычно намного проще Если используешь Maven, добавь такую зависимость:
org.apache.logging.log4j log4j-slf4j-impl 2.14.0
Отлично, с настройками разобрались 🙂 Давай рассмотрим, как работает slf4j. Как же нам сделать так, чтобы ход работы программы куда-то записывался? Для этого нам нужны две вещи — логгер и аппендер. Начнем с первого.
Логгер — это объект, который полностью управляет ведением записей. Создать логгер очень легко: это делается с помощью статического метода — LoggerFactory.getLogger() . В качестве параметра в метод нужно передать класс, работа которого будет логироваться. Запустим наш код:
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MyTestClass < public static final Logger LOGGER = LoggerFactory.getLogger(MyTestClass.class); public static void main(String[] args) < LOGGER.info(«Test log record. «); LOGGER.error(«В программе возникла ошибка!»); >>
Вывод в консоль: ERROR StatusLogger No Log4j 2 configuration file found. Using default configuration (logging only errors to the console), or user programmatically provided configurations. Set system property ‘log4j2.debug’ to show Log4j 2 internal initialization logging.
See https://logging.apache.org/log4j/2.x/manual/configuration.html for instructions on how to configure Log4j 2 15:49:08.907 [main] ERROR MyTestClass — В программе возникла ошибка! Что же мы тут видим? Сначала мы видим сообщение об ошибке. Она появилась, потому что сейчас у нас не хватает необходимых настроек. Поэтому наш логгер сейчас умеет выводить только сообщения об ошибках (ERROR) и только в консоль. Метод logger.info() выполнен не был.
А вот logger.error() сработал! В консоли появилась текущая дата, метод, где возникла ошибка ( main ), слово ERROR и наше сообщение! ERROR — это уровень логгрования. В общем, если запись в логе помечена словом ERROR, значит, в этом месте программы произошла ошибка. Если запись помечена словом INFO — значит это просто текущая информация о нормальной работе программы.
В библиотеке SLF4J довольно много разных уровней логгирования, которые позволяют гибко настроить ведение журнала. Управлять ими очень легко: вся необходимая логика уже заложена в класс Logger . Тебе достаточно просто вызывать нужные методы.
Если ты хочешь залогировать обычное сообщение, вызывай метод logger.info() . Сообщение об ошибке — logger.error() . Вывести предупреждение — logger.warn() Теперь поговорим об аппендере. Аппендер — это место, куда приходят твои данные. Можно сказать, противоположность источнику данных — «точка B». По умолчанию данные выводятся в консоль.
Обрати внимание, в предыдущем примере нам не пришлось ничего настраивать: текст появился в консоли сам, но при этом логгер из библиотеки log4j умеет выводить в консоль только сообщения уровня ERROR. Людям же, очевидно, удобнее читать логи из текстового файла и хранить логи в таких же файлах. Чтобы изменить поведение логгера по умолчанию, нам нужно сконфигурировать свой файловый аппендер. Для начала, прямо в папке src нужно создать файл log4j.xml, или в папке resources, если используешь Maven, or in the resources folder, in case you use Maven. С форматом xml ты уже знаком, у нас недавно была лекция про него 🙂 Вот таким будет его содержимое:
[%t] %-5level %logger — %msg%n»/>
Выглядит не особо-то и сложно 🙂 Но давай все-таки пройдемся по содержимому.
Это так называемый status-logger. Он не имеет отношения к нашему логгеру и используется во внутренних процессах log4j.
Можешь установить status=”TRACE” вместо status=”INFO”, и в консоль будет выводиться вся информация о внутренней работе log4j (status-logger выводит данные именно в консоль, даже если наш аппендер для программы будет файловым). Нам это сейчас не нужно, поэтому оставим все как есть.
[%t] %-5level %logger — %msg%n»/>
Тут мы создаем наш аппендер. Тег указывает что он будет файловым. name=»MyFileAppender» — имя нашего аппендера. fileName=»C:UsersUsernameDesktoptestlog.txt» — путь к лог-файлу, куда будут записываться все данные. append=»true» — нужно ли дозаписывать ли данные в конец файла. В нашем случае так и будет.
Если установить значение false, при каждом новом запуске программы старое содержимое лога будет удаляться. [%t] %-5level %logger — %msg%n»/> — это настройки форматирования. Здесь мы с помощью регулярных выражений можем настраивать формат текста в нашем логе.
Здесь мы указываем уровень логгирования (root level). У нас установлен уровень INFO: то есть, все сообщения уровней выше INFO (по таблице, которую мы рассматривали выше) в лог не попадут. У нас в программе будет 3 сообщения: одно INFO, одно WARN и одно ERROR. С текущей конфигурацией все 3 сообщения будут записаны в лог.
Если ты поменяешь значение root level на ERROR, в лог попадет только последнее сообщение из LOGGER.error(). Кроме того, сюда же помещается ссылка на аппендер. Чтобы создать такую ссылку, нужно внутри тега создать тег и добавить ему параметр ref=”имя твоего аппендера” . Имя аппендера мы создали вот тут, если ты забыл:
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MyTestClass < public static final Logger LOGGER = LoggerFactory.getLogger(MyTestClass.class); public static void main(String[] args) < LOGGER.info(«Начало работы программы. «); try < LOGGER.warn(«Внимание! Программа пытается разделить одно число на другое»); System.out.println(12/0); >catch (ArithmeticException x) < LOGGER.error(«Ошибка! Произошло деление на ноль!»); >> >
Он, конечно, немного кривоватый (перехват RuntimeException — идея так себе), но для нашей целей отлично подойдет 🙂 Давай запустим наш метод main() 4 раза подряд и посмотрим на наш файл testlog.txt. Создавать его заранее не нужно: библиотека сделает это автоматически. Все заработало! 🙂 Теперь у тебя есть настроенный логгер.
Ты можешь поиграться с какими-то написанными тобой ранее программами, добавив вызовы логгера во все методы, и посмотреть на получившийся журнал:) В качестве дополнительного чтения очень рекомендую тебе вот эту статью. Там тема логирования рассмотрена углубленно, и за один раз прочитать ее будет непросто. Но в ней содержится очень много полезной дополнительной информации. Например, ты научишься конфигурировать логгер так, чтобы он создавал новый текстовый файл, если наш файл testlog.txt достиг определенного размера:) А наше занятие на этом завершено! Ты сегодня познакомился с очень важной темой, и эти знания точно пригодятся тебе в дальнейшей работе. До новых встреч! 🙂
Источник: javarush.com
Логирование в Python это просто

При росте проекта использовать функции print для сообщения о запуске Python-скрипта или его падение уже становится неудобно. В этом случае используйте логирование (logging). В этой статье мы расскажем, как лучше всего создавать логи в Python, когда их стоит применять, а также покажем основы библиотеки logging.
Что такое логирование и какими должны быть логи
Логирование — это способ записи информации о состоянии программы. Логами называют сами записи. Логи должны быть описательными, контекстными, реактивными [1]. Следовательно, они описывают, что произошло; они предоставляют информацию о текущем состоянии в момент открытия лога; они позволяют узнать, какие действия нужно предпринять, если это требуется. Поэтому в логах рекомендуется писать только подобную информацию, иначе рискуете создать только шум, запутав тем самым себя и коллег.
Например, лог вроде: “operation connect failed” — это шум. В нем есть описание, но нет контекста (ведь не ясно какое именно соединение и в какой момент произошла авария), а также нет информации о действии, которые нужно предпринять. Можно пойти ещё дальше и сделать лог таким: “An error happened”.
Когда создавать лог
Логи должны быть ясными и легкими для чтения. Пользователь может пропускать некоторые строчки, так как они понятны, и сосредотачивать внимание на необходимых ему аспектах. Например, логи оркестратора Apache Airflow информативны и объёмны, но вам быть может нужен только вывод, значения настроек конфигурации, время выполнения или появившаяся ошибка.
Логи должны быть подобны рассказу, у которого есть начало, кульминация и конец. Поэтому создавать их рекомендуется в следующие моменты:
- в начале выполнения операции (например, при соединении с внешней сетью и т.д.);
- после выполнения важных и релевантных операций (например, аутентификация выполнилась, код выполнения и т.д.);
- в конце выполнения операции: либо выполнилась, либо нет.
Создание логов в Python
Нам повезло, ведь в Python есть стандартная библиотека logging [2]. В нем есть специальные функции, которые названы в соответствии с уровнем или серьезностью событий. Эти уровни следующие:
- DEBUG — подробная информация, обычно интересующая только при диагностике проблем.
- INFO — подтверждение того, что все работает должным образом.
- WARNING — предупреждение, что произошло действие, которое не ждали, при этом программа все равно работает.
- ERROR — ошибка, из-за которой программа не работает.
- CRITICAL — серьезная ошибка, при которой программа не может продолжить работать.
Все эти уровни можно вызывать, используя соответствующие функции, например, logging.error . Но лучше пользоваться объектом logger (логер):
import logging logger = logging.getLogger(__name__) def myfunc(): . logger.info(«Something relevant happened») .
Объект logger предоставляет интерфейс для логирования. Также есть объекты handler (обработчик), filter (фильтр), formatter (объект формата вывода). Обработчики отправляют записи логов в соответствующее место назначения, например, в стандартный поток ошибок (stderr) или в файл.
Фильтры предоставляют более детальное средство для определения, какие записи логов нужно выводить, а объекты формата вывода каким образом (по какому шаблону) должны отображаться сами логи. Рассмотрим эти объекты подробнее.
Объекты logging
Обработчики отправляют сообщения журнала в места назначения, такие как стандартный выходной поток или айл, или через HTTP, или на вашу электронную почту через SMTP. Логер может иметь несколько обработчиков, поэтому логи могут быть и сохранены в файл, и отправлены на электронную почту.
Обработчики создаются в Python следующим образом:
s_handler = logging.StreamHandler() f_handler = logging.FileHandler(‘log’) s_handler.setLevel(logging.WARNING) f_handler.setLevel(logging.ERROR)
Итак, у нас есть два обработчика: первый со статусом WARNING записывает в стандартный поток, второй со статусом ERROR в файл.
Для форматированного вида используется шаблоны сходные с теми, которые используются в языке Си: %s — это строка, %d — это целое число. Только между процентом и символом в скобках ставится имя параметра.
s_format = logging.Formatter(‘%(name)s — %(levelname)s — %(message)s’) f_format = logging.Formatter(‘%(name)s — %(asctime)s — %(message)s’) s_handler.setFormatter(s_format) f_handler.setFormatter(f_format)
Вывод второго обработчика покажет ещё и время генерации записи лога через asctime .
Осталось только добавить обработчики к нашему объекту logger :
logger.addHandler(c_handler) logger.addHandler(f_handler)
Теперь, когда вы вызовите функцию warning , то в стандартном выводе увидите лог заданного формата:
>>> logger.warning(‘This is a warning’) __main__ — WARNING — This is a warning
А вот при вызове error вы получите ещё и файл, в котором будет содержаться форматированный вывод:
>>> logger.error(‘This is an error’) __main__ — ERROR — This is an error $ cat log 2021-09-17 16:36:59,684 — __main__ — ERROR — This is an error
Каждый раз, когда будет вызываться функция error в файл будет добавляться соответствующая строчка. Используйте подобный прием при запуске своих Python-скриптов. Логи можно применять и в тестах, о них тут.
О грамотном создании логов и о том, как работать с Python для решения задач Data Science вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- FUNP: Основы языка Python для анализа данных и решения задач машинного обучения
- DPREP: Подготовка данных для Data Mining на Python
- PYML: Машинное обучение на Python
- https://blog.guilatrova.dev/how-to-log-in-python-like-a-pro/
- https://docs.python.org/3/howto/logging
Источник: python-school.ru