
❗Важные файлы журналов для мониторинга
Здесь мы рассмотрим ключевые файлы логов, какую информацию они хранят, как настраивается rsyslog для записи и как посмотреть информацию с помощью journalctl .
Журнал /var/log/syslog или /var/log/messages
Это «всеохватывающий» системный лог:
# logger «this is a test» # tail -1 /var/log/syslog May 7 15:33:11 ubuntu-bionic test-user: this is a test
Вы найдёте здесь все сообщения: ошибки, информационные сообщения и все другие серьёзности . Исключением является stop action .
Если в /var/log/syslog или /var/log/messages пусто, скорее всего, journald не перенаправляет данные в syslog. Все те же данные можно просмотреть, вызвав journalctl без параметров.
# journalctl —no-pager | grep «this is a test» May 07 15:33:11 ubuntu-bionic test-user[7526]: this is a test
Журналы /var/log/kern.log или /var/log/dmesg
Сюда по умолчанию отправляются сообщения ядра:
Apr 17 16:47:28 ubuntu-bionic kernel: [ 0.004000] console [tty1] enabled
И снова, если у вас нет syslog (или файл пустой/отсутствует) – используйте journalctl:
Анализатор лог-файлов Январь 5.1/7.2 Log Viewer
kern.* /var/log/kern.log
Журналы /var/log/auth.log или /var/log/secure
Здесь вы найдете сообщения об аутентификации, генерируемые такими службами, как sshd :
May 7 15:03:09 ubuntu-bionic sshd[1202]: pam_unix(sshd:session): session closed for user vagrant
Вот ещё один фильтр по значениям auth и authpriv :
auth,authpriv.* /var/log/auth.log
Вы можете использовать такие фильтры в journalctl, используя числовые уровни объектов :
# journalctl SYSLOG_FACILITY=4 SYSLOG_FACILITY=10 . May 7 15:03:09 ubuntu-bionic sshd[1202]: pam_unix(sshd:session): session closed for user vagrant .
Журнал /var/log/cron.log
Сюда отправляются ваши cron-сообщения (jobs-ы, выполняемые регулярно):
May 06 08:19:01 localhost.localdomain anacron[1142]: Job `cron.daily’ started
cron.* /var/log/cron
С journalctl можно сделать так:
# journalctl SYSLOG_FACILITY=9
Журнал /var/log/mail.log или /var/log/maillog
Практически все демоны (такие как Postfix, cron и т. д.) обычно пишут свои логи в syslog. Затем rsyslog раскладывает эти логи по файлам:
mail.* /var/log/mail.log
С помощью journald просматривать журналы можно так:
# journalctl SYSLOG_FACILITY=2
Подведём итоги
- Расположение и формат системных журналов Linux зависят от того, как настроен дистрибутив.
- Большинство дистрибутивов имеют systemd, и все логи «живут» там. Чтобы что-то просмотреть и найти, используйте journalctl.
- Некоторые дистрибутивы передают системные журналы в syslog, либо напрямую, либо через journal. В этом случае у вас, скорее всего, есть логи, записанные в отдельные файлы в /var/log .
- Если вы управляете несколькими серверами, вам потребуется централизовать журналирование с помощью специального ПО или использовать собственный ELK-стек.
Логгирование событий невероятно важная и серьёзная штука в любой сфере администрирования и ОС. Рекомендуем отнестись ответственно к данной теме – она будет полезна при дебагинге, разработке и просто в управлении инфраструктурой.
Большие файлы логов? | LogFileNavigator | Удобная работа с логами
Источники
Источник: proglib.io
Все о Process Mining от ProcessMi
Все о технологии Process Mining — кейсы, термины, решения и аналитика. Российский и зарубежный опыт от группы экспертов ProcessMi
Лог процесса

Лог – это файл с системными записями о работе компьютера, куда занесены все действия пользователя/программы.
Лог иногда называют лог-файлом или журналом, который содержит в себе пул записей об инцидентах (любом действии), отмеченных информационной системой в хронологическом порядке. Все действия происходят с огромной скоростью, и пользователь физически не успевает их отследить. Выглядит лог-файл как текстовый документ, разделенный на строки. Одна строка – одно действие.
Основная задача логов – протоколировать все операции, выполняемые на компьютере, чтобы в дальнейшем администратор мог в любое время “поднять” их и проанализировать. Благодаря регулярному подробному анализу возможно не только найти ошибки в работе системы/программы/сайта/сервиса, собрать статистику и найти подозрительные аномалии, но и визуализировать бизнес-процессы.
Виды логов
В лог может быть записана следующая информация:
- редактирование/попытка редактирования страниц;
- вход на сайт/попытка входа;
- история работы с платежными системами на ресурсе;
- экспорт товаров;
- удаление или добавление.
Однако стоит отметить, что некоторые действия, например, редактирования шаблона веб-страницы, работа с пользователями на панели управления или мини-чаты, логами не фиксируются.
В большинстве случаев запись осуществляется в так называемые журналы событий (системные журналы, event log). Программные продукты, установленные на сервере, “заводят” собственные журналы. Среди самых распространенных логов:
содержат данные о работе с ядром системы, работе FTP, DNS;
помогают отлаживать систему, сохраняют основные события системы;
делятся на два вида: одни работают с данными веб-серверов, другие ориентированы на базы данных;
благодаря таким логам идет управление сайтами на хостинговых платформах: фиксируются попытки входа, обновления, попытки доступа;
в лог записывается информация о входящих и исходящих письмах, ошибках.
Запись в лог
Рассмотрим на примере сайта. Когда пользователь набирает в своем браузере адрес сайта и успешно переходит на него, то браузер передает на сервер, где расположен этот ресурс, запрос на выдачу нужной пользователю информации. Например, открывая сайт ProcessMi, вы делаете своеобразный запрос и одновременно с этим передаете массив следующей информации:
- IP-адрес;
- время запроса;
- браузер, с которого передан запрос;
- используемая операционная система;
- нужная страница;
- адрес страницы, откуда произошел переход на сайт.
После обмена данными, пользователь получает ответ на интересующий его запрос, а все данные о транзакции фиксируются в журнале событий.
Основные функции
- OpenEventLog
- ReadEventLog
- GetOldestEventLogRecord
- GetNumberOfEventLogRecords
- NotifyChangeEventLog
- BackupEventLog
- ClearEventLog
- OpenBackupEventLog
- CloseEventLog
- RegisterEventSource
- ReportEvent
Журнал событий
Все данные берутся из реестра, изначально всего три ответвления:
- Приложение (Application);
- Система (System);
- Безопасность (Security)
Кроме того, каждый журнал имеет свои ключи.
Когда журнал достигает своего пикового размера, он либо просто останавливает запись событий, либо начинает перезаписывать устаревшие события, что делает его уязвимым к DDOS-атакам. Одним из способов борьбы с этой проблемой является увеличение размера журнала. Как вариант – журналу можно задать функцию не перезаписывать устаревшие события, но это может стать источником сбоев.
Логи в process mining
Технология Process Mining (процессная аналитика) в своей основе использует именно логи для визуализации бизнес-процессов в состоянии “as is”. Благодаря этому все полученные результаты будут исключительно достоверными и прозрачными.
Источник: processmi.com
Логирование как инструмент повышения стабильности веб-приложения
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.

Профессия тестировщик: разбираемся в QA, QC и testing
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
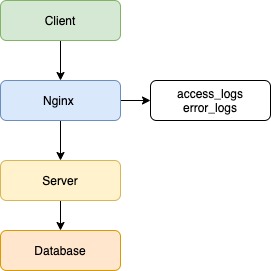
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: «GET /api/v1/users/levels HTTP/2.0», upstream: «http://127.0.0.1:5000/api/v1/users/levels», host: «app.dunice-testing.com»
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.
Источник: tproger.ru
Тестирование ПО

Идёт 2022-й год и такой вопрос задают реже, но ответ на него знать нужно.
Если вы тестируете свой личный софт — вам виднее.
Если вы работаете тестировщиком в каком то проекте, то ваша цель — предоставить максимально объективную информацию о софте вашему менеджеру, который будет решать можно такой софт отправлять в продакшн или нет для того чтобы компания заработала больше денег.
Тестировщик вообще нужен бизнесу для того, чтобы снять с разработчиков самую простую работу. Просто потому, что время тестировщика дешевле.
Изучение логов

Если у Вас возникли проблемы с работой софта первым делом стоит изучить логи.
Что такое лог
Если Вы начали заниматься IT совем недавно и не знаете, что такое логи — попробую объяснить в двух словах.
Логи — это обычно текстовые файлы в которые программы записывают результаты своей работы.
Какие бывают логи
Лог может быть подробным, тогда он занимает больше места на диске и отвлекает больше ресурсов.
Чтобы сократить занимаемое место можно записывать только самые важные события.
Один и тот же софт может иметь несколько режимов логирования. Режим задаётся в настройках и отличается уровнем детализации.
Степень детализации может отличаться очень сильно. От никаких или минимальных записей вроде
2022-03-22-10-06-01T Включился
2022-12-23-00-00-01T Выключился
До записи каждого действия.
Часто одной и той же программе можно указать разный уровень подробности логов.
Типичные уровни логов — слева на право детализация растёт
OFF — FATAL — CRITICAL — ERROR — WARN — INFO — DEBUG — TRACE — ALL
Далеко не всегда используются все уровни. Например, во встроенном в Python модуле logging уровней всего пять, два из которых (INFO и DEBUG) отключены по умолчанию
CRITICAL — ERROR — WARN — INFO — DEBUG
Распространённый приём в работе тестировщика — на время тестирования включать подробное логирование — от DEBUG и выше.
Затем возвращать настройки в INFO или WARN для экономии места.
Для работы с логами может пригодится знание скриптовых языков программирования, или текстовых препроцессоров (sed, grep, awk)
Пример: показать только сегодняшние ERROR и WARNING строки из лога а также те, где присутствует слово panic
grep ‘2022-12-23’ topbicycle.log | grep -E ‘ERROR|WARNING|*panic*’
Пример ведения лога о вызовах функций с помощью декораторов — можете изучить в статье «Декораторы в Python»
Где лежат логи в Windows
Лог файл обычно называется по дате, например 2022-12-23-heiheiru-log.txt или 2022-12-23-heiheiru.log
Расположение лог файла обычно зависит от конкретного проекта, например:
У одного клиента логи могут лежать в
Glassfish на Windows server может писать в
Где лежат логи в Linux
В Linux системные логи находятся в
Например, лог утилиты cron за сегодня находится в
Иногда проще спросить расположение логов у разработчика
Зачастую полезно посмотреть, что именно клиент пытается отправить на сервер.
Откройте логи с помощью Notepad++ и сделайте поиск по слову POST
Советую не пренебрегать опцией Find All in Current Document.

Зачастую смотреть полный лог нет смысла. В нём может быть очень много мусора, который легко убрать с помощью текстовых препроцессоров.
О том как это сделать Вы можете прочитать в статьях sed grep awk и как бонус — «Комады Bash для тестировщика»
Кто должен читать логи: тестировщик или разработчик
Однажды мне задали такой вопрос, и я здесь вполне категоричен — конечно, тестировщик.
Логи для того и созданы, чтобы когда софт работает неправильно тестировщик мог, например по таймкоду, найти проблемное место и приложить нужный кусок лога к баг-репорту.
Конечно, разработчик и сам может всё это сделать. Но его время стоит дороже и для бизнеса выгодно, чтобы всё что может делать тестировщик делал тестировщик.
Тестирование пользовательского ввода
Если есть хотя бы небольшой шанс того, что Вы будете тестировать что-то связаннное с user input, почитайте статью Big List of Naughty Strings
Изучение спецификаций
Перед началом работы над новым проектом Вам нужно будет изучить одну или несколько спецификаций.
Несколько — потому что проект может иметь спецификацию, которая описывает бизнес логику, спецификацию интерфейсов и, например, документацию для поддержки проекта.
То какая информация попадает в одну спецификацию, а какая в другую зачастую завист от менеджера ведущего проект, либо может быть чётко прописана в корпоративных правилах.
Interfaces — спецификация интерфесов
В любом случае, в спецификации интерфейсов мы ожидаем увидеть описание API и задача тестировщика здесь сводится к тому, чтобы
- Связать бизнес логику с запросами, описанным в спецификации интерфейсов.
- Проверить качество спецификации а именно уточнить не забыли ли разработчики описать какое-либо действие. Насколько понятно названы запросы и т.д.
Так как логика разработчиков отличается от логики тестировщиков бывает полезным уточнить какие из перечисленных запросов создаются непосредственно клиентами а какие являются вторичными, то есть нуждаются в запросе триггере, который приходит от клиента или бэкенда.
Результатом проверки спецификации интерфейсов будет карта составленная в виде документа, либо просто в воображении тестировщика, которая накладывает на бизнес процессы соответсвующием им запросы либо цепочки запросов.
Контроль версий
В прошлом для контроля версий использовались различные решения, например SVN , но уже довольно продолжительное время стандартом считается GIT поэтому советую изучать именно его.
Руководств и тренировочных материалов довольно много, моё можете найти в статье «GIT для начинающих»
Чем занимается тестировщик
Нужно помнить, что тестирование сильно зависит от того, в какой компании работает тестировщик.
Это очевидно, но тем не менее акцентирую внимание на том, что очень сложно стать универсальным тестировщиком, разве что сменив несколько работодателей из разных IT сфер.
Я прочитал некоторые вакансии в рунете и в LinkedIn и сделал подборку популярных требований и описаний задач.
Постараюсь перевести их на понятный новичку язык.
Тестирование отдельных задач в тестовом и рабочем окружениях
Имеется в виду, что Вам придётся иногда тестировать в продакшене — то есть не dev а prod версию.
Если Вы тестируете сервер, который хостится Вашей конторой, то разница только в ответственности.
Если сервер на стороне клиента — готовьтесь подключаться по VPN, настраивать SSH туннель, а в худшем случае — разбираться в SSL сертификатах.
Покрытие тест-кейсами функционала системы
Означает, что нужно изучить спецификацию и понять, что можно протестировать. Затем описать эти тесты.
Проверка входящих баг-репортов из Tech Support
Клиенты обычно жалуются на баги и не только на баги.
Поддержка не всегда может быстро понять, что к чему, поэтому проще переслать баг-репорт тому тестировщику, который знаком с проектом.
Вы проверяете воспроизводится ли баг в тестовом окружении, если нет, то ковыряетесь в production логах где-нибудь на Kibana.
Функциональное тестирование и отслеживание качества выпускаемого сервиса
Здесь всё понятно — проверять нужно выполняет ли продукт свою функцию. После этого проверить насколько качественно и удобно для пользователя он это делает
Анализ функциональности сервиса
Может означать всё что угодно. Похоже скорее на задание для исследовательского тестирования.
Общение с командой разработки и менеджерами, принятие совместных решений об улучшении сервиса.
Это неотъемлемая часть работы практически любого инженера по тестированию, причём не только софта.
Локализация и документирование дефектов.
Под локализацией обычно понимают выяснение источника проблемы. Это выливается в поиск логов, относящихся непосредственно к ошибке и отслеживанию stack trace.
Документация это: описать что вызывает баг, какое действие клиента или какой конкертно запрос. Максимальное количество полезной информации приветствуется.
Обязательно указывать версию ПО в которой был получен баг и приложить логи.
Оптимизация процесса тестирования внутри команды и постановка задач разработчикам автотестов
Подразумевается, что тестировщик-мануальщик, должен общаться с тестировщиком-автоматизатором и просить у него разработать инструменты для автоматизации. Потом эти инструменты нужно изучить, применить и описать — смотрите следующий пункт.
Запуск и анализ результатов автотестов
Это очевидное продолжение предыдущего пункта.
Проведение ручного функционального тестирования
Функциональное тестирование мы уже обсудили, в этом пункте ключевое слово — ручное. Нужно будет кликать мышкой, делать запросы к API, нажимать на кнопки, всё зависит от продукта. Если Ваша компания производит мухобойки — возможно придётся бить мух.
Участие в регрессионном тестировании
Регрессионное тестирование обычно означает следующее. У Вас уже есть работающий продукт, но к нему пришёл Change Request (CR) и разработчики сделали новую фичу.
Фича работает, но теперь нужно понять не сломала ли новая фича что-то из старого функционала.
Для этого Вам придётся проделать все известные манипуляции с продуктом. Обычно под Regression Test есть отдельный документ, если Вы придумали что-то новое — просто добавляете это туда. Довольно скучный процесс.
Ведение тестовой документации, подготовка тест кейсов
Рутина, без которой никуда особенно в большиъ компаниях.
Регистрация найденных дефектов в баг-трекере, контроль их исправления.
Назначение баг-трекеров это упрощение контроля за ошибками.
Трекеров очень много, один из самых популярных это Jira .
Если Вы не знакомы с принципами их работы рекомендую изучть Jira причём заранее — чтобы во время не иметь ненужного пробела в резюме. Отпишитесь в комментариях чем пользуются в Вашей компании.
Взаимодействие с командой разработки.
Взаимодействие с разработчиками — это весело. Пример из жизни: в логах найдена неизвестная ошибка
2019-01-10 10:01:15 [ERROR]: Something is not ok
О ней написан репорт. Разработчик выпустил фикс. Тестировщик проверил и не увидев больше этого предупреждения в логах зааксептил.
Прошла неделя, тестировщик тестирует совершенно другую историю и вдруг
2019-01-17 10:01:15 [DEBUG]: Something is not ok
Тестировщик звонит разработчику и говорит, что ошибка снова появилась.
Первый вопрос разработчика — « А на каком уровне логов ты смотришь?»
Оказалось, что разработчик просто глубже закопал эту ошибку — теперь она не видна на ERROR уровне лога а видна только на DEBUG.
Присылайте свои истории в комментарии. Лучшие я включу в статью.
Куда складывают задачи и/или баги
Список планировщиков проектов и багтрекеров:
Попарное и общее сравнение:
Источник: www.andreyolegovich.ru