
Лексический анализ программы что это
Основная задача лексического анализа — разбить входной текст, состоящий из последовательности одиночных символов, на последовательность слов, или лексем, т.е. выделить эти слова из непрерывной последовательности символов. Все символы входной последовательности с этой точки зрения разделяются на символы, принадлежащие каким-либо лексемам, и символы, разделяющие лексемы (разделители). В некоторых случаях между лексемами может и не быть разделителей. С другой стороны, в некоторых языках лексемы могут содержать незначащие символы (например, символ пробела в Фортране). В Си разделительное значение символов-разделителей может блокироваться («» в конце строки внутри «. «).
Обычно все лексемы делятся на классы. Примерами таких классов являются числа (целые, восьмеричные, шестнадцатиричные, действительные и т.д.), идентификаторы, строки. Отдельно выделяются ключевые слова и символы пунктуации (иногда их называют символы-ограничители). Как правило, ключевые слова — это некоторое конечное подмножество идентификаторов. В некоторых языках (например, ПЛ/1) смысл лексемы может зависеть от ее контекста и невозможно провести лексический анализ в отрыве от синтаксического.
Как работает лексический анализатор
С точки зрения дальнейших фаз анализа лексический анализатор выдает информацию двух сортов: для синтаксического анализатора, работающего вслед за лексическим, существенна информация о последовательности классов лексем, ограничителей и ключевых слов, а для контекстного анализа, работающего вслед за синтаксическим, важна информация о конкретных значениях отдельных лексем (идентификаторов, чисел и т.д.).
Таким образом, общая схема работы лексического анализатора такова. Сначала выделяется отдельная лексема (возможно, используя символы-разделители). Ключевые слова распознаются либо явным выделением непосредственно из текста, либо сначала выделяется идентификатор, а затем делается проверка на принадлежность его множеству ключевых слов.
Если выделенная лексема является ограничителем, то он (точнее, некоторый его признак) выдается как результат лексического анализа. Если выделенная лексема является ключевым словом, то выдается признак соответствующего ключевого слова. Если выделенная лексема является идентификатором — выдается признак идентификатора, а сам идентификатор сохраняется отдельно. Наконец, если выделенная лексема принадлежит какому-либо из других классов лексем (например, лексема представляет собой число, строку и т.д.), то выдается признак соответствующего класса, а значение лексемы сохраняется отдельно.
Лексический анализатор может быть как самостоятельной фазой трансляции, так и подпрограммой, работающей по принципу «дай лексему». В первом случае (рис. 3.1, а) выходом анализатора является файл лексем, во втором (рис.
3.1, б) лексема выдается при каждом обращении к анализатору (при этом, как правило, признак класса лексемы возвращается как результат функции «лексический анализатор», а значение лексемы передается через глобальную переменную). С точки зрения обработки значений лексем, анализатор может либо просто выдавать значение каждой лексемы, и в этом случае построение таблиц объектов (идентификаторов, строк, чисел и т.д.) переносится на более поздние фазы, либо он может самостоятельно строить таблицы объектов. В этом случае в качестве значения лексемы выдается указатель на вход в соответствующую таблицу.
Лексический анализ. Восходящий анализ
Работа лексического анализатора задается некоторым конечным автоматом. Однако, непосредственное описание конечного автомата неудобно с практической точки зрения. Поэтому для задания лексического анализатора, как правило, используется либо регулярное выражение, либо праволинейная грамматика. Все три формализма (конечных автоматов, регулярных выражений и праволинейных грамматик) имеют одинаковую выразительную мощность. В частности, по регулярному выражению или праволинейной грамматике можно сконструировать конечный автомат, распознающий тот же язык.
3.1 Регулярные множества и выражения
Введем понятие регулярного множества, играющего важную роль в теории формальных языков.
- (пустое множество) — регулярное множество в алфавите T;
- — регулярное множество в алфавите T (e — пустая цепочка);
- — регулярное множество в алфавите T для каждого a T;
- если P и Q — регулярные множества в алфавите T, то регулярными являются и множества
- PQ (объединение),
- PQ (конкатенация, т.е. множество ),
- P * (итерация: P * = n=0 P n );
Приведенное выше определение регулярного множества позволяет ввести следующую удобную форму его записи, называемую регулярным выражением.
- — регулярное выражение, обозначающее множество ;
- e — регулярное выражение, обозначающее множество ;
- a — регулярное выражение, обозначающее множество ;
- если p и q — регулярные выражения, обозначающие регулярные множества P и Q соответственно, то
- (p|q) — регулярное выражение, обозначающее регулярное множество P Q,
- (pq) — регулярное выражение, обозначающее регулярное множество PQ,
- (p * ) — регулярное выражение, обозначающее регулярное множество P * ;
Мы будем опускать лишние скобки в регулярных выражениях, договорившись о том, что операция итерации имеет наивысший приоритет, затем идет операции конкатенации, наконец, операция объединения имеет наименьший приоритет.
Кроме того, мы будем пользоваться записью p + для обозначения pp * . Таким образом, запись (a|((ba)(a * ))) эквивалентна a|ba + .
Наконец, мы будем использовать запись L(r) для регулярного множества, обозначаемого регулярным выражением r.
- a(e|a)|b — обозначает множество ;
- a(a|b) * — обозначает множество всевозможных цепочек, состоящих из a и b, начинающихся с a;
- (a|b) * (a|b)(a|b) * — обозначает множество всех непустых цепочек, состоящих из a и b, т.е. множество + ;
- ((0|1)(0|1)(0|1)) * — обозначает множество всех цепочек, состоящих из нулей и единиц, длины которых делятся на 3.
Ясно, что для каждого регулярного множества можно найти регулярное выражение, обозначающее это множество, и наоборот. Более того, для каждого регулярного множества существует бесконечно много обозначающих его регулярных выражений.
Будем говорить, что регулярные выражения равны или эквивалентны (=), если они обозначают одно и то же регулярное множество.
Существует ряд алгебраических законов, позволяющих осуществлять эквивалентное преобразование регулярных выражений.
Лемма. Пусть p, q и r — регулярные выражения. Тогда справедливы следующие соотношения:
Источник: citforum.ru
Немного о лексическом анализе
Давным-давно, когда небо было голубым, трава зеленее и по Земле бродили динозавры… Нет, забудьте про динозавров. Ну, в общем, когда-то тогда пришла в голову мысль отвлечься от стандартного web-программирования и заняться чем-то более безумным. Можно было, конечно, чем угодно, но выбор пал на написание своего интерпретатора.
Что я могу сказать… Никогда не пишите свои языки программирования. Но некоторый опыт из всего этого я извлёк, так что вот и решил поделиться. Начнём с самой основы — лексера.
Предисловие
Перед тем, как начать понимать что за животное такое «лексер» — стоит разобраться из чего вообще состоят ЯП.
В современном мире каждый компилятор/интерпретатор/транспайлер/что-то-там-ещё-подобное (давайте, я просто буду называть далее это «компилятором», без разграничений на типы) делится на два куска. В терминологии умных дядек подобные куски называются «фронтендом» и «бекендом». Нет, это совсем не то, работая с web, что мы привыкли называть и фронт не написан на JS с HTML. Хотя… Ладно.
Задача первого, фронтенда — взять текст и превратить его в AST (абстрактное синтаксическое дерево), по дороге проверив правильность синтаксиса (и иногда семантики). Задача второго, бекенда — заставить всё это работать. Если код собирается внутри интерпретатора, то из AST создаётся набор команд для виртуального процессора (виртуальной машины), если компилятор, то набор команд для реального процессора. В жизни всё довольно сложнее и реализовываться может не совсем так. Например, в случае с GCC компилятором — там всё вперемешку, а вот Clang уже более каноничен, LLVM — это типичный представитель «бекенда» для компиляторов.
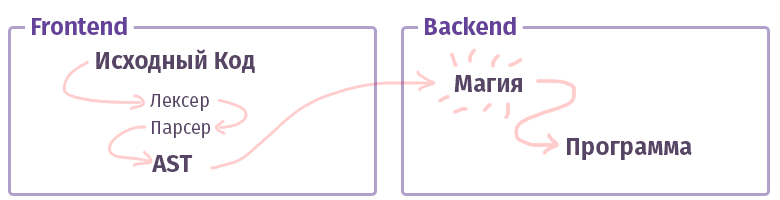
А теперь давайте познакомимся с куском, называемым «фронтендом».
Лексический анализ
Задача лексера и стадии лексического анализа — это получить на вход много-много букв и сгруппировать их по каким-то категориям — «токенам». По этому лексический анализ ещё называют «токенизацией». Это самая первая стадия обработки текста, которую производит каждый существующий компилятор.
Примерно вот так:
$tokens = [‘class’, ‘w+’, ‘>’, », $tokens)); // array(4) < // [0] =>string(5) «class» // [1] => string(7) «Example» // [2] => string(1) » string(1) «>» // >
К слову, тут у нас уже понаписана куча инструментов для облегчения жизни. Те же самые функции preg, которые мы привыкли использовать для парсинга текста — вполне себе справляется с данной задачей. Однако существуют и более удобные инструменты для этого дела:
- Phlexy, написанный Никитой Поповым.
- Hoa — инструментарий, состоящий из Лексера + Парсера + Грамматики.
- Порт Yacc, написанный Энтони Феррара, который так же представляет из себя комплексный инструментарий, и на котором написан небезызвестный PHP парсер Попова, применимый в инструментах, использующих анализ кода.
- Railt Lexer моя реализация под PHP 7.1+
- Parle — расширение для PHP, допускающее ограниченный набор PCRE выражений (нет lookahead и некоторых других синтаксических конструкций).
- Ну и наконец стандартная функция php token_get_all, которая предназначена непосредственно для лексического анализа PHP.
Типы лексеров
И как всегда всё не так просто, как казалось. Существует как минимум две разных категории лексеров. Есть обычный вариант, довольно тривиальный, которому подсовываешь правила, а он уже делит всё на токены. Конфигурация оного мало чем отличается от примера, показанного мною выше. Однако есть и другой вариант, который называется multistate.
Такие лексеры чуть сложнее для понимания, поэтому, хочется поговорить о них чуть подробнее.
Задача multistate лексера выводить различные токены в зависимости от предыдущего состояния. Ну например в PHP такие «переходные» состояния образовываются с помощью тегов , внутри строк, комментариев и HEREDOC/NOWDOC конструкций.
Помните предыдущий пример с 4мя токенами выше? Давайте его чуть-чуть модифицируем, чтобы понимать что это за состояния такие:
class Example < // class Example <>>
В данном случае, если мы имеем простейший лексер без широких возможностей PCRE, то получим следующий набор токенов:
var_dump(lex(. )); // array(9) < // [0] =>string(5) «class» // [1] => string(7) «Example» // [2] => string(1) » string(2) «//» // [4] => string(5) «class» // [5] => string(7) «Example» // [6] => string(1) » string(1) «>» // [8] => string(1) «>» //>
Как видно, мы получили совершенно банальный косяк на элементах 3-5: Комментарий воспринялся совершенно неожиданно и сам поделился на токены, хотя должен был считаться как цельный кусок.
Конечно, при наличии функционала PCRE такой токен можно было бы выдрать с помощью простенькой регулярки «//[^n]*n», но если его нет? Ну или мы руками хотим запилить? Короче, в случае с multistate лексером — можно сказать, что все токены должны быть в группе No1, как только будет найден токен «//», то должен произойти переход в группу No2. А внутри второй группы обратный переход, если найден токен «n» — переход обратно в первую группу.
Примерно как-то так:
$tokens = [ ‘group-1’ => [ ‘class’, ‘w+’, », ‘//’ => ‘group-2’ // Переход после слешей в группу 2 ], ‘group-2’ => [ «n» => ‘group-1’, // Переход в группу 1 после переноса строки ‘.*’ ] ];
Думаю теперь становится понятнее как парсится какой-нибудь HEREDOC, ведь даже при наличии всей мощи PCRE написать регулярку для этого дела крайне проблематично, учитывая то, что этот синтаксис HEREDOC поддерживает интерполяцию переменных. Просто попробуйте распарсить что-нибудь такое с помощью встроенной функции token_get_all (обратите внимание на >12 токен):
Ладно, кажется мы уже готовы приступать к практике.
Практика
Давайте вспомним что у нас есть в PHP для подобных дел? Ну конечно, preg_match! Ладно, сойдёт. Алгоритм на основе preg_match реализован в Hoa и вот в этой реализации Phelxy. Задача его довольно проста:
- Имеем на руках исходный текст и массив из регулярок.
- Матчим до тех пор, пока что-то не найдётся подходящее.
- Как только нашли кусок, вырезаем его из текста и матчим дальше.
Кодопростыня
Использование кодопростыни
$lexer = new SimpleLexer([ ‘T_CLASS’ => ‘class’, ‘T_CONST’ => ‘w+’, ‘T_BRACE_OPEN’ => ‘ ‘>’, ‘T_WHITESPACE’ => ‘s+’, ]); echo sprintf(‘| %-10s | %-20s |’, ‘VALUE’, ‘NAME’) . «n»; foreach ($lexer->lex(‘class Example <>’) as $name => $token)
Такой подход довольно тривиален и позволяет парой тычков по клавиатуре модифицировать лексер в районе метода next(), добавив переход между состояниями и превратив это поделие рукоблудства в примитивный multistate лексер. В районе $this->tokens достаточно добавить что-то вроде $this->tokens[$this->state].
Однако, помимо самого примитивизма есть ещё один недостаток, не фатальный как могло оказаться, но всё же… Подобная реализация невероятно медленно работает. На i7 7600k, обладателем которого я по чистой случайности оказался — подобный алгоритм обрабатывает примерно 400 токенов в секунду, а при увеличении их вариаций (т.е. определений, которые мы передали в конструктор) — может замедлиться до скорости смены президентов в РФ… кхм, простите. Я хотел сказать, конечно, что будет работать очень медленно.
Ладно, что мы можем сделать? Для начала можно понять что же идёт не так. Дело в том, что каждый раз, когда мы вызываем preg_match внутри дебрей языка поднимается компилятор со своим JIT, называемый PCRE (А с PHP 7.3 уже PCRE2). Он каждый раз парсит сами регулярки и собирает для них парсер, с помощью которого мы парсим текст для создания токенов. Звучит чуть-чуть странно и тавтологично.
Но если кратко, то каждый токен требует компиляции от 1 до N регулярок, где N — это количество определений этих токенов. При этом, стоит заметить, что даже применённый флаг «S» и оптимизация с помощью «G» в конструкторе, где формируются регулярные выражения для токенов, не помогают.
Выход из этой ситуации напрашивается один — надо парсить весь этот текст в один проход, т.е. с помощью выполнения лишь одной функции preg_match. Осталось решить две проблемы:
- Как обозначить что результат регулярного выражения N1 соответствует токену N2? Т.е. как обозначить, что «w+», например — это именно T_CONST.
- Как определить последовательность токенов в результате. Как известно, результат preg_match или preg_match_all будет содержать всё вперемешку. И даже с помощью флагов, передаваемых в качестве четвёртого аргумента ситуация не изменится.
Решение первой проблемы — это именованные группы PCRE, которые так же именуются «подмасками». С помощью правил: «(?s+|w+|. )» можно за один проход выгрести все токены сопоставив с их именами. В результате матчинга будет образовываться ассоциативный массив, состоящий из пар «[TOKEN_NAME => TOKEN_VALUE]».
Со второй чуть сложнее. Но тут можно применить тактическую хитрость и воспользоваться функцией preg_replace_callback. Особенность её в том, что анонимка, переданная в качестве второго аргумента будет вызываться строго последовательно, для каждого токена, от первого до последнего.
Дабы не томить — реализация следующая:
Ещё одна портянка кода
А её использование ничем не отличается от предыдущего варианта. При этом скорость работы возрастает с 400 до 57000 токенов в секунду. Именно этот алгоритм я применил в своей реализации, взявшись за переписывание исходников Hoa. К слову, если воспользоваться Parle, то можно выжать до 600000 токенов в секунду. А общая картина выглядит примерно следующим образом (с включённым XDebug на PHP 7.1, так что цифры тут ниже, но соотношение можно приблизительно представить).
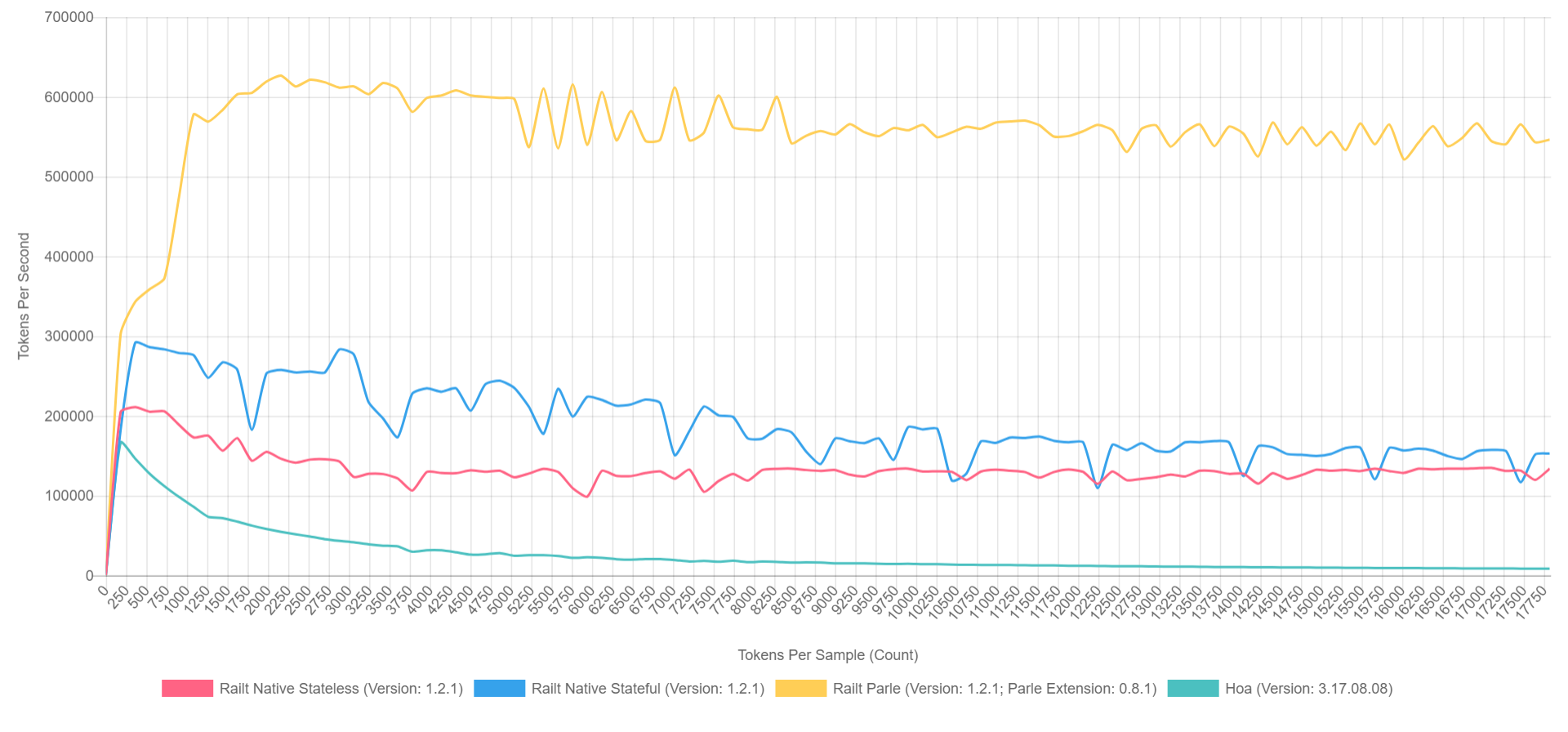
- Жёлтый — нативное расширение Parle.
- Голубой — реализация через preg_replace_callback с предварительно собранной регуляркой.
- Красный — всё тоже самое, но с генерируемой регуляркой во время вызова preg_replace_callback.
- Зелёный — реализация через preg_match.
Зачем?
Ладно, всё это, конечно, замечательно, но нетерпеливые жаждут задать вопрос: «Кому это вообще нужно?». В абстрактном мире PHP, где главенствует принцип «фигак-фигак-и-сайт-готов» — подобные библиотеки не нужны, будем честными. Но если говорить об экосистеме в целом, то можно вспомнить небезызвестные библиотеки, вроде symfony/yaml или Doctrine.
Аннотации в Symfony — это такой же подязык внутри PHP, требующий отдельного лексического и синтаксического разбора. Помимо этого есть ещё чуть менее известные транспайлеры CoffeeScript, Less и Scss/Sass, написанные на PHP. Ну или Yay и preprocess, основанный на нём. Я даже не буду упоминать инструменты анализа кода, вроде phpmd или phpcs. Да и генераторы документации, вроде phpDocumentnor или Sami — довольно тривиальны.
Каждый и этих проектов в той или иной степени использует лексический анализ на первой стадии разбора текста/кода.
Это далеко не полный список проектов и возможно, надеюсь, мой рассказ поможет вам открыть что-то новое и пополнить его.
Послесловие
Забегая вперёд, если есть кто-либо заинтересованный в тематике парсеров и компиляторов, то есть несколько интересных докладов по этой теме, в частности от ребят из JetBrains:
Ещё, конечно, большинство выступлений Андрея Бреслава (abreslav), которые можно найти на просторах YouTube — советую к просмотру.
Ну а для любителей чтива есть вот такой ресурс, который был лично для меня крайне полезным.
Пост пост скриптум. Если где-то опечатался на просторах сего эпоса, то можете смело сообщать автору в любой удобной для вас форме.
В качестве бонуса, хотел бы привести пример простого лексера PHP, кажется это не так уж теперь и страшно, и теперь даже понятно что он делает, верно? Хотя кого я обманываю, от регулярок глаза кровоточат. =)
Источник: habr.com
6. Лексические анализаторы. Лексические анализаторы (сканеры). Принципы построения сканеров. Регулярные языки и грамматики. Построение лексических анализаторов. Оптимизации
Прежде чем перейти к рассмотрению лексических анализаторов, необходимо дать четкое определение того, что же такое лексема.
Лексема (лексическая единица языка) — это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка.
Лексемами языков естественного общения являются слова 1 . Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т. п. Состав возможных лексем каждого конкретного языка программирования определяется синтаксисом этого языка. Лексический анализатор (или сканер) — это часть компилятора, которая читает исходную программу и выделяет в ее тексте лексемы входного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
С теоретической точки зрения лексический анализатор не является обязательной частью компилятора. Все его функции могут выполняться на этапе синтаксического разбора, поскольку полностью регламентированы синтаксисом
В языках естественного общения лексикой называется словарный запас языка. Лексический состав языка изучается лексикологией и фразеологией, а значение лексем (слов языка) — семасиологией. В языках программирования словарный запас, конечно, не столь интересен и специальной наукой не изучается. входного языка. Однако существует несколько причин, по которым в состав практически всех компиляторов включают лексический анализ:
Источник: studfile.net
Теория компиляции: лексический анализатор
Лексический анализатор — это начальный этап выполнения компиляции, на котором символы, образующие исходный текст программы, перегруппировываются в набор отдельных минимальных единиц текста, имеющих смысловую нагрузку и именуемых лексемами.
Теория компиляции
История теории компиляции ведёт свой отчёт от 1957-го года, то есть с момента появления первого компилятора языка Фортран, реализованного Бэкусом и способного сформировать вполне эффективный объектный код. До этого момента формирование компиляторов было достаточно «творческой» процедурой. И только возникновение теории формальных языков и достоверных математических моделей предоставило возможность использовать вместо чисто творческих методик вполне научные. Именно это явилось причиной возникновения сотен разнообразных языков программирования. Кроме того, формализованная теория компиляторов явилась новым стимулом развития математической лингвистики и методов искусственного интеллекта, которые связаны с искусственным и естественным языком.
Решим твою учебную задачу всего за 30 минут
Попробовать прямо сейчас
Основанием теории компиляторов является теория формальных языков, представляющая собой достаточно сложный математический раздел. Естественно, что и реализация объектного кода, и машинно-ориентированная оптимизация, и реализация компоновки очень важны. Тем не менее они являются частностями, которые зависят в первую очередь от фактической структурной организации компьютера, от структуры используемой операционной системы, а основные принципы реализации компиляторов остаются неизменными. Архитектурные построения изменяются практически каждый год, а базовые методики неизменны уже много десятков лет.
Транслятором называется программа, переводящая исходный программный текст в соответствующую объектную программу. В случае, когда объектный язык является автокодом или некоторым машинным языком, транслятор принято называть компилятором. Большинство команд автокода является точным символическим отображением машинных команд, то есть автокод является почти аналогом машинного языка.
Ассемблер представляет собой программу, переводящую исходную программу, сформированную на автокоде или ассемблерном языке (что, практически, то же самое), в исполняемый (то есть объектный) код.
«Теория компиляции: лексический анализатор»
Готовые курсовые работы и рефераты
Консультации эксперта по предмету
Помощь в написании учебной работы
Процесс компиляции
На рисунке ниже показана обобщённая стандартная структура компилятора. В реальности компилятор является целым программным комплексом.

Рисунок 1. Обобщённая стандартная структура компилятора. Автор24 — интернет-биржа студенческих работ
Здесь под исходной программой понимается текстовое отображение программы на языке высокого уровня, который необходимо преобразовать в машинные коды.
Информационные таблицы являются самостоятельными структурами, которые заполняются при выполнении лексического анализа и могут дополняться при осуществлении работы.
Лексический анализатор, то есть сканер, который имеет на выходе лексемный поток, требуется для того, чтобы отсеять всё второстепенное (например, комментарии), отделить лексемы, то есть лексические модули, необходимые для построения машинного языка, и выполнить их преобразование во внутренние или промежуточные формы представления. Этот этап предполагает активную работу с таблицами, в которые записываются информационные данные о идентифицированных лексемах, их значениях, типах и других параметрах. В итоге получается поток лексем, который является эквивалентом исходного теста.
Синтаксический анализатор требуется для выяснения соответствия предложений исходной программы грамматическим правилам выбранного языка. Параллельно с анализом синтаксиса выполняется генерация внутренней формы отображения программы.
Процесс компиляции, как правило, состоит из следующих этапов:
- Этап лексического анализа. На этом этапе выполняется подмена лексем их внутренним отображением (к примеру, подмена операторов, разделителей и идентификационных параметров числовыми значениями).
- Этап синтаксического анализа. Часто на данном этапе могут вводиться добавочные разделители и заменяться уже имеющиеся, чтобы облегчить обработку.
- Этап генерации промежуточных кодов (этап трансляции). Здесь выполняется анализ типа и вида всех идентификационных параметров и иных операндов. Как правило, процесс преобразования исходной программы в промежуточную форму записи выполняется вместе с синтаксическим анализом.
- Этап оптимизации кодов.
- Этап распределения памяти для переменных в формируемой программе.
- Этап генерации объектных кодов и выполнение компоновки сегментов программы.
На каждом из этапов осуществляется взаимодействие с таблицами разного типа.
В общем виде, весь набор этапов может быть представлен так:

Рисунок 2. Работа с таблицами. Автор24 — интернет-биржа студенческих работ
Замечание 1
Естественно, структура компилятора зависит от структуры компьютера, вернее, от величины его производительности.
Лексический анализатор
На вход лексического анализатора, то есть сканера, поступает символьная последовательность, являющаяся исходной программой. При его работе отдельные символьные наборы воспринимаются сканером в форме единого объекта. К примеру:
- Набор пробелов подменяется одним пробелом.
- Набор ключевых слов (типа BEGIN, END, INTEGER и другие).
- Последовательность символов, обозначающая константу.
- Последовательность символов, обозначающая имя (идентификатор).
То есть, лексический анализатор выполняет группировку определённых терминальных символов (входных символов) в объединенные синтаксические объекты, именуемые лексемами. Самой простой лексемой является набор типа .
Проблема формирования лексем из входного потока иногда превращается в сложную и зависящую от структурной организации используемого языка задачу.
Известно два главных вида лексических анализаторов:
- Прямые анализаторы.
- Непрямые анализаторы.
Прямой лексический анализатор находит лексему, которая расположена правее текущего указателя, и выполняет сдвиг указателя вправо от текстового участка, определяющего лексему. Непрямой анализатор анализирует, формируют ли знаки, находящиеся правее указателя, лексему данного типа.
Источник: spravochnick.ru