
ЛАБОРАТОРНАЯ РАБОТА 1 ПРОЕКТИРОВАНИЕ И РЕАЛИЗАЦИЯ ТАБЛИЦ, ИСПОЛЬЗУЕМЫХ В ТРАНСЛЯТОРЕ Рейн Т. С. — презентация
Презентация на тему: » ЛАБОРАТОРНАЯ РАБОТА 1 ПРОЕКТИРОВАНИЕ И РЕАЛИЗАЦИЯ ТАБЛИЦ, ИСПОЛЬЗУЕМЫХ В ТРАНСЛЯТОРЕ Рейн Т. С.» — Транскрипт:
1 ЛАБОРАТОРНАЯ РАБОТА 1 ПРОЕКТИРОВАНИЕ И РЕАЛИЗАЦИЯ ТАБЛИЦ, ИСПОЛЬЗУЕМЫХ В ТРАНСЛЯТОРЕ Рейн Т. С.
2 Цель работы Получить представление о видах таблиц, используемых при трансляции программ. Изучить множество операций с таблицами и особенности реализации этих операций для таблиц, используемых на этапе лексического анализа. Реализовать классы таблиц, используемых сканером.
3 Схема транслятора Лексичекий анализ Синтаксический анализ Семантический анализ Генерация промежуточного кода Оптимизация кода Генерация кода Диспетчер таблиц символов Обработчик ошибок Исходная программа Целевая программа
4 Типы таблиц Таблицы можно классифицировать как постоянные и переменные. Постоянные таблицы создаются одновременно с проектированием транслятора и не изменяются в процессе работы с транслируемой программой. К переменным таблицам относятся таблицы, создаваемые в процессе трансляции исходной программы.
Lexema-ECM. Бизнес-процесс по формированию документа Поручение
5 Постоянные таблицы таблицы, содержащие алфавит входного языка ; таблица зарезервированных слов ; таблицы, реализующие какой — либо из методов синтаксического анализа (LL- разбор, LR- разбор и др.).
6 Переменные таблицы таблица символов ( идентификаторов, имен ); таблица констант.
7 Определения Лексема – неделимая единица языка и ее атрибуты. Единица языка – константа, идентификатор, ключевое слово, разделитель, знак операции. Множество атрибутов определяется типом единицы языка и может включать : имя, значение, тип, параметры ( для функций ). Лексемы сохраняются в соответствующих таблицах лексем.
8 Функции компилятора Одной из важнейших функций компилятора является запись используемых в исходной программе идентификаторов и сбор информации о различных атрибутах каждого идентификатора. Эти атрибуты предоставляют сведения об отведенной идентификатору памяти, его типе, области видимости ( в какой части программы он может применяться ).
9 Состав лексхемы При использовании имен процедур атрибуты говорят о количестве и типе их аргументов, методе передачи каждого аргумента ( например, по ссылке ) и типе возвращаемого значения, если таковое имеется. Вся эта информация составляет лексему.
10 Таблица символов Таблица символов представляет собой структуру данных, содержащую записи о каждом идентификаторе с полями для его атрибутов. Данная структура позволяет найти информацию о любом идентификаторе и внести необходимые изменения.
11 Таблица символов Когда идентификатор считан из исходной программы, требуется определить, не появлялся ли этот идентификатор ранее. Если лексическим анализатором в исходной программе обнаружен новый идентификатор, он записывается в таблицу символов.
12 Определение После того, как лексема сохранена или найдена в таблице символов, сохраняется токен ( тип лексемы и адрес в соответствующей таблице ), связанный с этой лексемой, в файле токенов. атрибуты идентификатора обычно не могут быть определены в процессе лексического анализа.
Как работает язык программирования(Компилятор)? Основы программирования.
13 Механизм таблицы сиволов Механизм таблицы символов должен обеспечивать эффективный поиск и добавление символов в таблицу. Такими механизмами могут быть линейные списки и хеш — таблицы. Линейный список более прост в реализации, но его производительность невысока. Хеширование обеспечивает более высокую производительность, но за счет большего количества памяти и несколько больших усилий по программированию.
14 Работа с таблицей символов При работе с таблицей символов полезна возможность ее динамического роста в процессе компиляции. Для хранения лексем, образующих идентификаторы, не стоит отводить память фиксированного размера. Этой памяти может оказаться недостаточно для очень длинного идентификатора И слишком много для коротких идентификаторов ( например, i), что приводит к нерациональному использованию памяти.
15 Методы ТС Процедуры для работы с таблицей символов, ориентированы, в основном, на хранение и получение лексем. Класс, реализующий таблицу символов, должен содержать следующие основные функции : поиск / добавление идентификатора в таблице ; поиск / добавление атрибутов идентификатора в таблицу.
16 Константы Везде, где в выражении встречается отдельное число, на его месте естественно использовать произвольную константу, ее участие в трансляции обозначается созданием лексемы и соответствующего ей токена для такой константы.
17 Таблица констант Таблица констант представляет собой структуру данных, содержащую записи о каждой константе с полями для ее атрибутов ( тип константы и др.). Данная структура позволяет осуществлять корректную работу с константами на всех этапах трансляции. Организация таблицы констант и процедуры работы с ней аналогичны механизмам работы с таблицей символов.
Источник: www.myshared.ru
Основы структуры программ
Для больших программных текстов более подходит другая структура, отражающая синтаксис . Она основана на понятии «дерева», часто используемого для отображения организационной структуры компании. Это понятие ассоциируется с настоящими деревьями, их ветвями и листьями. Правда, у наших деревьев, в отличие от настоящих, корень дерева располагается вверху и дерево «растет» сверху вниз или слева направо. Дерево имеет корень, ветви которого идут к другим узлам, а те, в свою очередь , могут иметь ветви, или быть листом дерева . Деревья служат для представления иерархических структур, как показано ниже:
Рисунок представляет абстрактное синтаксическое дерево. Оно абстрактно, поскольку не включает элементы, играющие роль разделителей, такие как do и end. Мы можем построить конкретное синтаксическое дерево , включающее такие элементы.
Дерево включает узлы и ветви (вершины и дуги ). Каждая ветвь связывает один узел с другим. У данного узла может быть несколько выходящих ветвей, но в каждый узел ведет максимум одна ветвь . Узел, у которого нет входящей в него ветви, называется корнем. Узлы без выходящих ветвей называются листьями. Узел, не являющийся ни корнем, ни листом, называется внутренним узлом.
Непустое дерево имеет в точности один корень (структура, представленная нулем, одним или несколькими раздельными деревьями, имеющая произвольное число корней, называется лесом).
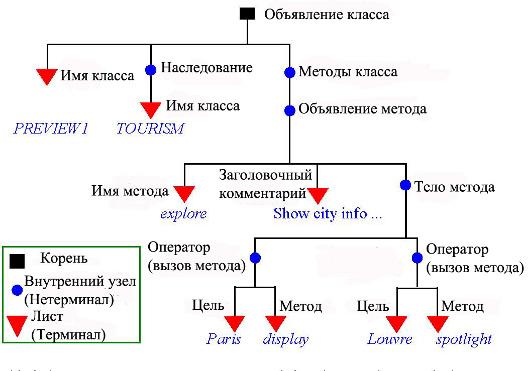
Рис. 3.2. Абстрактное синтаксическое дерево
Деревья являются важными структурами в информатике , нам часто придется с ними встречаться в разных контекстах. Здесь мы рассматриваем их как деревья, задающие структуру синтаксиса элемента программы – класса. Она представлена вложенными образцами с тремя видами узлов.
- Корень, представляющий общую структуру, – самый внешний прямоугольник на предыдущем рисунке.
- Внутренние узлы, которые представляют подструктуры, содержащие вложенные образцы – например, вызов метода содержит цель и имя метода.
- Листья, представляющие образцы, которые не содержат последующих вложений, такие как имена классов и методов.
Листья абстрактного синтаксического дерева называются также терминалами, а корень и внутренние узлы – нетерминалами.
Каждый образец относится к специальному виду: верхний узел задает класс , другие представляют имя класса , предложение » наследования «, множество объявлений методов. Каждый такой вид образца является грамматической категорией. На рисунке дерева для каждого узла приведено имя категории. Категория может быть как терминальной, так и нетерминальной, что зависит от образцов, представляющих категорию. Рисунок показывает, что «Объявление метода» является нетерминальной категорией, а имя метода – терминальной.
Категория определяет общее синтаксическое понятие. Синтаксис языка программирования определяется множеством категорий и их структурой.
3.7. Лексемы и лексическая структура
Базисными составляющими синтаксической структуры являются терминалы, ключевые слова, специальные символы , такие как точка в вызове метода. Эти базисные элементы называются лексемами (tokens).
Лексемы подобны словам и символам обычного языка. Предложение «Ах, ох – это восклицания!» содержит четыре слова и три символа.
Виды лексем
Лексемы бывают двух видов.
- Терминалы соответствуют, как мы видели, листьям абстрактного синтаксического дерева, каждое из которых несет некоторую семантическую информацию. Они включают имена, такие как Paris или display, называемые идентификаторами и выбираемые каждым программистом для именования семантических элементов, например, объектов (Paris) и методов (display). Другими примерами являются знаки операций, такие как + и
- Ограничители играют чисто синтаксическую роль и не несут никакой семантики. Они включают 65 ключевых слов, таких как class, inherit, feature, и специальные символы , например, точку и двоеточие. Они не появляются в абстрактном синтаксическом дереве, но появятся как листья при построении конкретного синтаксического дерева.
Уровни описания языка
Форма лексем определяет лексическую структуру языка. Синтаксический уровень является надстройкой – более высоким уровнем по отношению к лексическому, а семантический уровень выше синтаксического.
- Лексические правила определяют, как создаются лексемы из символов.
- Синтаксические правила определяют, как создаются образцы из лексем, удовлетворяющих лексическим правилам.
- Семантические правила определяют эффект программ, удовлетворяющих синтаксическим правилам.
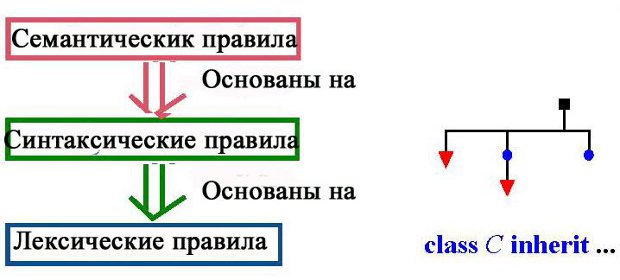
Рис. 3.3. Уровни описания языка
Важной особенностью этой иерархии является то, что свойства любого уровня определены только при условии выполнения ограничений на предыдущих уровнях. Синтаксис определен только для лексически корректных текстов, а семантика существует только для синтаксически корректных программ.
Мы встретимся с еще одним специальным уровнем, лежащим между синтаксисом и семантикой : обоснованием (validity), на котором рассматриваются правила, не относящиеся к синтаксису, например, ограничения типа.
Идентификаторы
На данный момент нам необходимо только одно лексическое правило для идентификаторов.
Синтаксис: идентификаторы
Идентификатор начинается с буквы, за которой следует ноль или более символов, каждый из которых может быть:
- буквой;
- цифрой (0-9);
- символом подчеркивания «_».
Примером идентификатора, содержащего цифры, является Route1
Действует одно исключение: нельзя использовать в роли идентификаторов ключевые слова, зарезервированные для специальных целей (на данный момент нам известно лишь несколько ключевых слов, но, если ошибочно мы попытаемся использовать в роли идентификатора ключевое слово, появится сообщение об ошибке).
Почувствуй стиль
Выбирая идентификаторы
Для повышения читабельности программ выбирайте идентификаторы, четко идентифицирующие предполагаемую роль, за исключением специальных случаев, которые вскоре рассмотрим. Используйте полные имена, а не аббревиатуры: Route1, а не R1 или Rte1.
Нет налога на нажатие клавиш. Те несколько секунд, которые вы, возможно, сэкономите, опустив несколько символов, ничего не стоят в сравнении с тем временем, когда вам или кому-либо другому понадобится понять, что же делается в вашей программе.
В идентификаторах, обозначающих сложные понятия, используйте подчеркивание для разделения последовательности слов, как в My_route или bus_station. Это относится и к именам классов, записываемых в верхнем регистре: PUBLIC_TRANSPORT. Не переусердствуйте: для большинства идентификаторов достаточно одного слова или двух слов, соединенных подчеркиванием. Ясность не означает многословие.
В некоторых программах, хотя для программ на Eiffel это не так, можно встретиться с многословными идентификаторами, в которых каждое следующее слово начинается с заглавной буквы: myRoute, PublicTransport. Это соглашение называется верблюжьим стилем (camel style) из-за возникающего горба. Лучше не следовать этому стилю, поскольку «онНамногоХужеЧитается», чем стиль с подчеркиванием, «остающийся_совершенно_ясным_даже_для _длинных_идентификаторов».
Уровни описания языка
Лексическая структура состоит из последовательности лексем. Для разделения соседствующих лексем можно использовать «белый пробел» (break), который может быть:
- пробелом;
- символом табуляции (задающим последовательность пробелов, которая позволяет перейти к фиксированной позиции в строке);
- символом перехода на новую строку.
Белые пробелы служат только для разделения лексем. Для синтаксиса и семантики нет разницы, как вы разделяете лексемы . Разрешается использовать один или несколько пробелов, переходы на новую строку или табуляцию. Такая гибкая структура, известная как «свободный формат», позволяет вам создать раскладку текста программы, отражающую структуру программы, что улучшает читабельность программы, как это сделано в примерах курса.
Ваша программа хранится в файле, который содержит последовательность символов, таких как буквы, цифры, знаки табуляции и другие специальные символы . Для большинства используемых сегодня файловых форматов для перехода на новую строку применяется один специальный символ «новая строка». Возможно, вы встречались и с символом «перевода каретки» (Carriage Return). Это название пришло из прошлого, когда тексты печатались на пишущей машинке, каретка смещалась в процессе печати строки и для перехода на новую строку необходимо было предварительно вернуть каретку в начальную позицию. В операционной системе Windows переход на новую строку кодируется последовательностью двух символов – возврата каретки и новой строки.
Белый пробел обычно не требуется между идентификатором и символом: можно писать a+b без всяких пробелов, поскольку не возникает двусмысленности. Однако правила стиля требуют использования белых пробелов для улучшения ясности текста: a + b .
3.8. Ключевые концепции, изученные в этой лекции
- Для записи программ используются языки программирования.
- Программы имеют лексическую структуру, определяющую форму базисных элементов. Лексемы разделяются «белыми» пробелами – табуляцией, возвратом строки, пробелом.
- Программы имеют синтаксическую структуру, которая определяет иерархическую декомпозицию на элементы (образцы), построенные из лексем.
- Программы имеют семантику , определяющую эффект времени выполнения каждого образца и всей программы в целом.
- Синтаксическая структура обычно включает вложенность и может быть задана в виде дерева, известного как абстрактное синтаксическое дерево.
Новый словарь
| Abstract syntax tree (AST) | Абстрактное синтаксическое дерево (АСД) | Break | Белый пробел | Carriage return? | Возврат каретки |
| Code | Код | Construct | Категория | Delimiter | Ограничитель |
| Expression | Выражение | Free format language | Свободный формат языка | Grammar | Грамматика |
| Identifier | Идентификатор | Instruction | Оператор | Internal node | Внутренний узел |
| Leaf | Лист | Lexical | Лексический | Natural language | Естественный язык |
| Nesting | Вложенность | New line | Новая строка | Node | Узел |
| Nonterminal | Нетерминал | Operator | Знак операции | Root | Корень |
| Semantics | Семантика | Special symbol | Специальный символ | Specimen | Образец |
| Syntax | Синтаксис | Terminal | Терминал | Token | Лексема |
| Tree | Дерево | Value | Значение |
3-У. Упражнения
3-У.1. Словарь
Дайте точные определения терминам словаря.
3-У.2. Карта концепций
Добавьте новые термины в карту концепций, спроектированную в предыдущей лекции.
3-У.3. Синтаксис и семантика
Для каждого из следующих предложений укажите, характеризуют ли они синтаксис, семантику , то и другое, ни то, ни другое (объясните решение).
- При вызове метода целевой объект должен отделяться точкой от имени метода.
- При вызове метода x.f нет необходимости помещать пробелы перед или после точки, хотя они являются допустимыми.
- Каждый вызов метода применяет метод к определенному объекту – цели вызова.
- Если у метода есть аргументы, то они должны заключаться в круглые скобки.
- Два или более аргумента заданного типа разделяются запятыми.
- Операторы, разделенные символом «точка с запятой», будут выполняться один после другого.
- Eiffel и Smalltalk являются объектно-ориентированными языками.
Источник: intuit.ru
Лексема программа
Приглашаем бухгалтеров средних и крупных компаний познакомиться с новой революционной технологией.
Программные роботы выступают ассистентами бухгалтеров и выполняют вместо них рутинные, часто повторяющиеся операции на компьютере и помогают сэкономить 70% времени бухгалтера

Программные роботы-ассистенты не меняют используемые системы, а поверх используемых систем выполняют необходимые бухгалтеру действия:
- переносят данные из одной системы в другую с помощью имитации действий человека по нажатию кнопок на клавиатуре и мыши
- распознают первичку
- заполняют экранные формы в 1С и других системах
- консолидируют данные и формируют отчеты
- проводят сверку информации из разных источников
- и многое другое
Программные роботы-ассистенты просты в разработке и стоят недорого.
За 1 час вебинара вы узнаете:
- как с помощью программ-ассистентов выжать максимум из существующих информационных систем
- как сэкономить кучу времени, настроив автоматическую обработку сложных первичных документов на примере форм KC-2, КС-3, Торг-12, Счет-фактура
- как консолидировать данные с разных подразделений
- как настраивать сверки, контролировать расхождения и многое другое
Все это мы разберем на реальных кейсах, работающих на ведущих российских компаниях: Газпром-бурение, ОДК-УМПО, Таттелеком.
Научим рассчитывать экономическую эффективность программных роботизированных ассистентов.
А для того, чтобы понять, как просто создавать ассистента, мы вместе с вами на вебинаре настроим робота
Подарим лицензию на одного робота за самый интересный вопрос на вебинаре
ВСЕМ УЧАСТНИКАМ ВЕБИНАРА — 10% СКИДКА НА ЛИЦЕНЗИЮ ПРОГРАММНОГО РОБОТА-АССИСТЕНТА
Источник: obd2bluetooth.ru
Лексема что это такое программа
Результатом работы лексического анализатора является перечень всех найденных в тексте исходной программы лексем с учетом характеристик каждой лексемы. Этот перечень лексем можно представить в виде таблицы, называемой таблицей лексем. Каждой лексеме в таблице лексем соответствует некий уникальный условный код, зависящий от типа лексемы, и дополнительная служебная информация. Таблица лексем в каждой строке должна содержать информацию о виде лексемы, ее типе и, возможно, значении. Обычно структуры данных, служащие для организации такой таблицы, имеют два поля: первое — тип лексемы, второе — указатель на информацию о лексеме.
Кроме того, информация о некоторых типах лексем, найденных в исходной программе, должна помешаться в таблицу идентификаторов (или в одну из таблиц идентификаторов, если компилятор предусматривает различные таблицы идентификаторов для различных типов лексем).
Не следует путать таблицу лексем и таблицу идентификаторов — это две принципиально разные таблицы, обрабатываемые лексическим анализатором.
Таблица лексем фактически содержит весь текст исходной программы, обработанный лексическим анализатором. В нее входят все возможные типы лексем, кроме того, любая лексема может встречаться в ней любое количество раз. Таблица идентификаторов содержит только определенные типы лексем — идентификаторы и константы.
В нее не попадают такие лексемы, как ключевые (служебные) слова входного языка, знаки операций и разделители. Кроме того, каждая лексема (идентификатор или константа) может встречаться в таблице идентификаторов только один раз. Также можно отметить, что лексемы в таблице лексем обязательно располагаются в том же порядке, что и в исходной программе (порядок лексем в ней не меняется), а в таблице идентификаторов лексемы располагаются в любом порядке так, чтобы обеспечить удобство поиска.
Построение лексических анализаторов (сканеров)
Лексический анализатор имеет дело с такими объектами, как различного рода константы и идентификаторы (к последним относятся и ключевые слова). Язык описания констант и идентификаторов в большинстве случаев является регулярным, то есть может быть описан с помощью регулярных грамматик. Распознавателями для регулярных языков являются конечные автоматы (КА). Существуют правила, с помощью которых для любой регулярной грамматики может быть построен КА, распознающий цепочки языка, заданного этой грамматикой.
Любой КА может быть задан с помощью пяти параметров: M(Q. д,qo,F),
Q — конечное множество состояний автомата;
? — конечное множество допустимых входных символов (входной алфавит КА);
д — заданное отображение множества Q*? во множество подмножеств P(Q)д: Q*?> P(Q) (иногда д называют функцией переходов автомата);
q0 Q — начальное состояние автомата;
F Q. — множество заключительных состояний автомата.
Другим способом описания КА является граф переходов — графическое представление множества состояний и функции переходов КА. Граф переходов КА — это нагруженный однонаправленный граф, в котором вершины представляют состояния КА, дуги отображают переходы из одного состояния в другое, а символы нагрузки (пометки) дуг соответствуют функции перехода КА. Если функция перехода КА предусматривает переход из состояния q в q’ по нескольким символам, то между ними строится одна дуга, которая помечается всеми символами, по которым происходит переход из q в q’.
Недетерминированный КА неудобен для анализа цепочек, так как в нем могут встречаться состояния, допускающие неоднозначность, то есть такие, из которых выходит две или более дуги, помеченные одним и тем же символом. Очевидно, что программирование работы такого КА — нетривиальная задача. Для простого программирования функционирования КА M(Q,ўІ,д,qo,F) он должен быть детерминированным — в каждом из возможных состояний этого КА для любого входного символа функция перехода должна содержать не более одного состояния.
Доказано, что любой недетерминированный КА может быть преобразован в детерминированный КА так, чтобы их языки совпадали (говорят, что эти КА эквивалентны).
Кроме преобразования в детерминированный КА любой КА может быть минимизирован — для него может быть построен эквивалентный ему детерминированный КА с минимально возможным количеством состояний.
Можно написать функцию, отражающую функционирование любого детерминированного КА. Чтобы запрограммировать такую функцию, достаточно иметь переменную, которая бы отображала текущее состояние КА, а переходы из одного состояния в другое на основе символов входной цепочки могут быть построены с помощью операторов выбора. Работа функции должна продолжаться до тех пор, пока не будет достигнут конец входной цепочки. Для вычисления результата функции необходимо по ее завершении проанализировать состояние КА. Если это одно из конечных состояний, то функция выполнена успешно и входная цепочка принимается, если нет, то входная цепочка не принадлежит заданному языку.
Однако в общем случае задача лексического анализатора шире, чем просто проверка цепочки символов лексемы на соответствие ее входному языку. Он должен правильно определить конец лексемы (об этом было сказано выше) и выполнить те или иные действия по запоминанию распознанной лексемы (занесение ее в таблицу лексем). Набор выполняемых действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же при обнаружении конца распознаваемой лексемы.
Во входном тексте лексемы не ограничены специальными символами. Определение границ лексем — это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание. Если границы лексем всегда определяются (а выше было принято им¬Ц¬Я¬Я¬а такое соглашение), то их можно определить по заданным терминальным символам и по символам начала следующей лексемы.
Терминальные символы — это пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки е запятой и др.). Набор таких терминальных символов может варьироваться в зависимости от входного языка. Важно отметить, что знаки операций сами также являются лексемами и необходимо не пропустить их при распознавании текста.
Таким образом, алгоритм работы простейшего сканера можно описать так:
? просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему;
? для выбранной части входного потока выполняется функция распознавания лексемы;
? при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этапу;
? при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера: либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма).
Работа программы-сканера продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока.
Источник: studbooks.net