
На сегодняшний день наше общение с компьютером сводится к использованию клавиатуры, мыши, монитора и других устройств ввода-вывода. Это стало так естественно, что редко кто задумывается об их альтернативах. Но если вернуться во времена создания первых ЭВМ, то уже тогда разработчики думали о компьютерах, которые могли бы общаться с человеком на его языке.
Человеческий язык при кажущейся простоте и доступности плохо изучен. Еще не создано достаточно хорошей модели его построения, хотя работы в этой области напряженно ведутся. А без построения алгоритма синтеза речи невозможно создание речевых программ. Поэтому “читающие” программы до сих пор не реализованы в полной мере.
Для нормального синтеза недостаточно простого чтения слов в предложении, необходим глубокий анализ смысла читаемого текста и, как следствие, правильная расстановка ударений, нужные интонации и темп генерируемой речи. И это лишь видимая часть айсберга.
За долгую историю создания “говорящих” программ было пройдено несколько этапов решения этой задачи.
Russian T for English speakers
Первыми появились озвученные словари (самые старые и ограниченные в применении). Такой подход годится только для областей, где достаточно небольшого озвученного набора слов. Примером являются электронные справочные системы, зачитывающие по телефону железнодорожное расписание, а также всем известная служба точного московского времени “100”.
Позже стали появляться программы моделирования работы голосовых связок и ротовой полости человека, использующие хорошо изученные сведения из области физиологии.
И наконец, самая перспективная технология — TTS (Text to Speech), получившая в последнее время широкое распространение.
Реализация этой технологии стимулировала создание новых компактных голосовых продуктов с ранее немыслимыми возможностями.
Технология TTS, известная на компьютерном рынке уже более 15 лет, обычно используется в приложениях, где необходимо речевое воспроизведение большого числа различных текстов. Основной чертой, выделяющей TTS из голосовых программ, разработанных ранее, является способность произносить слова на основе фонетических правил и заранее озвученного или синтезированного машиной набора звуков. Приближенно процесс синтеза речи можно представить как склеивание по правилам фонетики заранее озвученных фрагментов языка (дифтонгов или более длинных фрагментов) в слова и затем — в предложения. Из этого вытекают достоинства технологии TTS:
— возможность озвучивания любых слов данного языка, как только появившихся в обиходе, так и никогда не существовавших;
— низкие требования к оперативной памяти компьютера, в которой находятся только озвученные фонемы, а не целые словари, как это реализовано в других технологиях синтеза речи;
— более быстрый процесс, поскольку синтез речи проходит скорее, чем поиск в громадной базе заранее озвученных слов (особенно это преимущество проявляется, когда необходимо воспроизвести большое число разнообразных слов);
Rostov Volmet (Russia), 11297 USB, 2023.05.21, 05.55 UTC
— простота выделения ударений и интонаций в синтезированных словах;
— возможность изменить темп чтения, не нарушая тембра голоса.
Конечно, это не означает, что технология TTS является окончательным этапом. Например, в автоматизированных системах синтеза речи с использованием ограниченного набора слов более дешевым и качественным (на сегодняшний день!) будет решение, основанное на небольшом озвученном словаре. Но это лишь тенденция ближайшего времени, а позже непременно получат распространение программы, построенные по технологии TTS с внедренными средствами искусственного интеллекта для “понимания” смысла произносимой речи.
Следует учесть, что синтез речи основан на знании многих научных дисциплин: лингвистики, психологии, физиологии человека, компьютерных технологий. Необходим анализ структуры предложения, в результате которого определяется произношение отдельных слов, интонация и оптимальный ритм синтезированной речи (с учетом синтаксиса и семантики). Должны правильно произноситься имена собственные, телефоны, почтовые адреса и другие специфические элементы генерируемого текста, без которых немыслим современный Интернет. Недавно появилась новая разработка — Visual TTS (см. www. research.att.com/projects/tts), заключающаяся в синхронизации генерируемой речи с моделируемой мимикой лица говорящего человека. Реалистичное движение губ позволяет улучшить не только восприятие синтезированной речи, но и разборчивость произносимого.
Голосовой интерфейс между человеком и компьютером можно представить в виде замкнутого круга. Процесс начинается с регистрации микрофоном аналоговой звуковой волны, возникающей при звучании человеческой речи. Далее звуковая плата конвертирует ее в цифровой сигнал, который программа распознавания речи преобразует сначала в набор фонем, а затем в слова.
Программное приложение анализирует этот текст и вырабатывает на него ответ в виде нового набора слов для синтеза. Теперь программа TTS переводит эти слова в фонемы, а затем, например, методом склеивания звуков и используя другие особенности технологии — в цифровой сигнал. И наконец на последнем этапе круг замыкается: звуковая плата через акустические колонки воспроизводит компьютерную речь, предназначенную для человека.
По технологии TTS построено уже довольно много приложений. Речевые технологии используются в широком спектре задач: чтение электронной почты, веб-страничек, баз данных, в интеллектуальных бортовых системах или, в идеальном случае, при обучении произношению слов иностранного языка. Но большинство этих приложений строится на основе готовых речевых “движков” таких фирм, как Microsoft, Lucent, Lernout больших вычислительных мощностей не требуется. А можно приобрести пакет разработчика за $595 и писать свои собственные речевые программы. На сайте Bell Labs есть множество синтезированных примеров, включая песни. При желании можно с заранее выбранным голосом (мужской, женский, детский, или писк комара, если хотите) воспроизвести любой английский текст или получить звуковой файл (реализована поддержка форматов aiff, au и wav) и прослушать его у себя на компьютере в автономном режиме.
Elan Informatique (www.elantts.com/speech/). В отличие от других эта компания предлагает широкий спектр продуктов, использующих технологию TTS: Speech cube, Speech platform, Speech unit, Speech engine, Speech engine for Windows CE, Elan talk embedded. В совокупности они могут читать электронную почту, факсы, веб-страницы, применяются в качестве электронного ассистента в автомобилях, конвертируют текстовые базы данных в голосовые. Поражает количество партнеров Elan Corporation, использующих ее технологию TTS: это такие громкие имена, как Dialogic, Novavox, France Telecom, Dragon System (уже подразделение L позволяет воспроизводить синтезированную речь и записывать ее в различных звуковых форматах; включает библиотеку препроцессора e-mail (MIME), примеры кода на Си и Visual C++; осуществляет поддержку всех популярных операционных систем: Windows 9x, 2000, NT, UNIX SCO, UNIX Solaris, Linux; работает с английским, француским, испанским, немецким, русским и португальским языками.
Lernout H, www.lhs.com или www.lhsl.com): RealSpeak. По мнению компании, этот продукт представляет собой “квантовый скачок” в улучшении технологии TTS: речь робота заменяется на речь вполне конкретного человека. Алгоритм конкатенации позволяет компьютеру запоминать человеческую речь и использовать ее для синтеза. Для генерации речи служат не только озвученные человеком слоги, но и его же длинные фонемные предложения. Набор этих голосовых сегментов и применение лингвистических знаний обеспечили интеллектуальность компьютерной речи.
RealSpeak поддерживает американскую версию английского, французский и корейский языки. В ближайшее время планируется добавить поддержку немецкого, испанского, итальянского, голландского, шведского и классического английского языков. А к началу 2001 года этот список пополнят японский и китайский.
Продукт широко используется в приложениях, предназначенных для автомобилей, телевидения, телефонных сетей, бытовой электроники и Интернета.
Алгоритм конкатенации обеспечивает интеллектуальное произношение, основанное на реальных образцах человеческой речи. Создана модель для обеспечения натуральной интонации в предложениях и фразах.
Компания L кроме того, она имеет встроенную реверберацию, позволяет редактировать голоса, поет, в том числе под MIDI-аккомпанемент с настройкой голоса на музыкальный инструмент, читает вслух текущую дату и время.
Уже выпущен тираж с новой версией 5.0, в которую добавлены поддержка полноценного чтения на английском языке и возможность сохранять синтезированный голос в виде WAV-файла. Программа занимает весь CD-ROM (около 650 Мб) и требует процессора Pentium 75 и выше, Windows 95 и звуковой платы.
На официальном сайте клуба можно самим вводить любой текст и оценивать качество синтезируемой речи. Причем это доступно как для мужского, так и для недавно разработанного женского голоса.
Конференции по речевым технологиям
Речевым технологиям посвящены многие выставки и конференции.
AVIOS — старейшее общество, занимающееся сбором и распространением информации о речевых технологиях. Ежегодно оно проводит конференции, и со времени своего образования в 1981 году их проведено уже 18. В течение последних трех лет по результатам конференции происходит отбор лучших речевых решений и их публикация на сайте (www.avios.com). В этом году конференция открылась 22 мая и продлилась всего три дня.
Более популярна выставка и конференция SpeechTek (www.speechtek.com), посвященная голосовым технологиям. В последней выставке, проходившей в октябре прошлого года, приняли участие около 60 экспонентов, среди которых были почти все фирмы, рассмотренные нами. Они продемонстрировали достижения в области синтеза (TTS) и автоматического распознавания речи (ASR), связанные с ними проблемы сжатия речи, идентификации говорящего, машинного перевода, а также применение этих технологий в образовании, здравоохранении, банковской деятельности, производстве и т. п. (см. также PC Week/RE, № 43/99, с. 1).
Из-за ограниченного объема в обзор не вошли многие интересные решения, в частности, таких известных фирм, как IBM, Philips, Panasonic, Motorola и многих других. Но и по рассмотренным реализациям технологии TTS можно сделать некоторые выводы. Во-первых, технологии фонетического синтеза речи TTS явно доминируют над теми, что использовались раньше, — озвученными словарями и моделями голосовых связок и ротовой полости человека. Во-вторых, бурно развивающийся рынок компьютерной телефонии и сотовой связи подталкивает исследователей к разработке конкурентоспособных речевых продуктов. В-третьих, четко видна тенденция к созданию многоязычных систем синтеза речи.
Конечно, в этой области еще остается множество нерешенных проблем. Очень часто в произносимом программой слове проглатываются буквы. Пока невозможно добиться произношения всех слов, имеющих одинаковое написание, но различающихся ударением: синтезаторы упорно читают только одно из них. Неестественно звучит интонация вопросительных предложений. Но несмотря на все эти недостатки, новые речевые синтезаторы уже можно с большим успехом использовать в различных областях.
В заключение приведу очень интересный ресурс в Интернете — сайт morph.ldc.upenn.edu/ltts/, посвященный сравнению различных систем синтеза речи как в оффлайновом, так и в онлайновом режиме. Он не только предоставляет доступ к десяткам TTS-систем, работающих с различными языками мира, но и позволяет самому пользователю сравнить их в действии.
Источник: www.itweek.ru
Как установить языки преобразования текста в речь в Windows
Распознавание речи и механизмы преобразования текста в речь прошли долгий путь со времен Microsoft печально известный Презентация системы распознавания речи Vista.
Microsoft поставляет механизмы преобразования текста в речь со своими операционными системами Windows и использует их в некоторых своих инструментах, таких как Экранный диктор. Другие программы также могут использовать голоса, например, чтобы предоставить пользователям возможности преобразования текста в речь.
Механизмы преобразования текста в речь по умолчанию были улучшены Microsoft в новых выпусках Windows. Хотя это так, их результаты по-прежнему явно идентифицируются как компьютерные.
Речевые возможности добавлены для языка операционной системы по умолчанию, но вы можете добавить поддержку других языков в более новых версиях Windows, чтобы получить поддержку речи и для этих языков.
Кроме того, вы можете установить сторонние языки, языковые пакеты или приложения, которые добавляют еще больше голосов в операционную систему.
Установка новых языков преобразования текста в речь в Windows 10
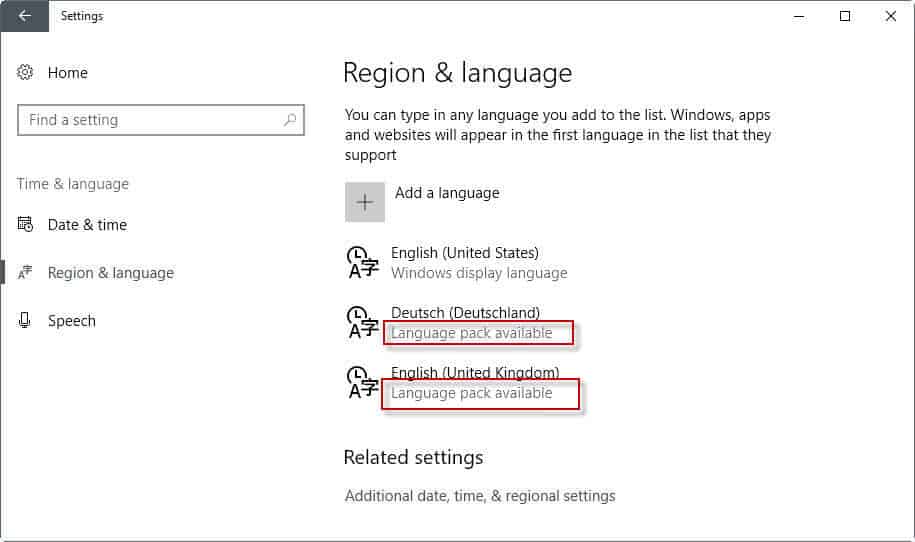
Установить новый язык в Windows 10 просто:
- Используйте сочетание клавиш Windows-I, чтобы открыть приложение «Настройки». Или выберите Пуск> Настройки.
- В открывшемся окне выберите Время и язык> Регион и язык.
- Щелкните по кнопке «добавить язык». Обратите внимание, что возможности преобразования текста в речь ограничены следующими языками: китайский, английский, США, Великобритания, Индия, французский, немецкий, итальянский, японский, корейский, польский, португальский, русский, испанский (Мексика и Испания).
- Подождите, пока установится выбранный язык.
- Вернитесь на страницу назад и снова откройте страницу «Регион и язык». Вы должны увидеть уведомление о том, что Windows ищет языковые пакеты в Центре обновления Windows. Если языковой пакет найден, он будет выделен через короткое время.
- Щелкните язык и выберите Параметры.
- Вы можете установить полный языковой пакет или только один компонент, например Speech.
Установка языка преобразования текста в речь в Windows 8.1
Если вы используете Windows 8.1, процесс добавления нового языка в операционную систему отличается:
- Откройте панель управления.
- Выберите «Язык» и на открывшейся странице «добавьте язык».
- Выберите язык, который вы хотите добавить в систему, а затем нажмите кнопку добавления внизу.
- Выберите загрузить и установить языковой пакет для добавленного вами языка.
Указатель доступных языков преобразования текста в речь в Windows 10 и 8
| Язык (регион) | Windows 10 и Windows 8.1 | Windows 8 | название | Пол |
| Китайский (Гонконг) | Y | N | Трейси | женский |
| Китайский (Тайвань) | Y | Y | Ханхан | женский |
| Китайский (Китайская Народная Республика) | Y | Y | Хуэйхуэй | женский |
| Английский Соединенные Штаты) | Y | Y | Зира | женский |
| Английский Соединенные Штаты) | Y | Y | Дэвид | мужчина |
| Английский (Великобритания) | Y | Y | Хейзел | женский |
| Английский (Индия) | Y | N | Heera | женский |
| Французский (Франция) | Y | Y | Гортензия | женский |
| Немецкий (Германия) | Y | Y | Hedda | женский |
| Итальянский (Италия) | Y | N | Эльза | женский |
| Японский (Япония) | Y | Y | Харука | женский |
| Корейский (Корея) | Y | Y | Хами | женский |
| Польский (Польша) | Y | N | Паулина | женский |
| Португальский (Бразилия) | Y | N | Мария | женский |
| Русский (Россия) | Y | N | Ирина | женский |
| Испанский (Мексика) | Y | N | Сабина | женский |
| Испанский (Испания) | Y | Y | Елена | женский |
Бесплатные языки преобразования текста в речь с открытым исходным кодом
Ранее я упоминал, что вы также можете добавлять в Windows сторонние языки. Следующий список представляет собой небольшую подборку бесплатных решений с открытым исходным кодом:
- ESpeak — синтезатор речи для Windows и Linux. Он включает разные голоса и добавляет поддержку языков, для которых Windows не поддерживает преобразование текста в речь. Программа совместима с Windows 7 и более новыми версиями Windows.
- Африкаанс, албанский, арагонский, армянский, болгарский, кантонский, каталонский, хорватский, чешский, датский, голландский, английский, эсперанто, эстонский, фарси, финский, французский, грузинский, немецкий, греческий, хинди, венгерский, исландский, индонезийский, ирландский, Итальянский, каннада, курдский, латышский, литовский, ложбан, македонский, малайзийский, малаялам, мандаринский, непальский, норвежский, польский, португальский, пенджаби, румынский, русский, сербский, словацкий, испанский, суахили, шведский, тамильский, турецкий, вьетнамский, Валлийский.
- разные голоса Microsoft English, голоса LH TTS3000 для британского английского, французского, испанского, немецкого, итальянского, голландского, португальского, японского, корейского и русского языков
Коммерческие провайдеры
Есть также коммерческие провайдеры. Эти пакеты предлагают пакеты для личного использования и бизнес-пакеты, которые вы можете использовать в коммерческих целях.
- Церепрок — Голоса Windows предлагаются по цене около 30 долларов за каждый для личного использования. Вы можете протестировать доступные голоса прямо на сайте. Также доступны коммерческие пакеты.
- Кепстрал — Предлагает голоса для личного использования для Windows, Mac и Linux, а также для коммерческого использования. Цена от 10 долларов до 45 долларов за личные голоса. Доступны демо.
Теперь ваша очередь : Вы пользуетесь приложениями или службами преобразования текста в речь?
Смотрите так же:
- Focus Keyboard улучшает ваш рабочий процесс Firefox
- Автоматическая закладка Firefox
- Pale Moon Commander добавляет расширенные настройки в Firefox (и Pale Moon)
- Какие ваши любимые функции в Windows 10 Fall Creators Update?
Источник: bauinvest.su
L h tts3000 russian что это за программа
Updated (06.06.2012): небольшое изменение в описании к архиву.
Updated (19.06.2012): из архива удален файл Spchapi.exe.
Также понадобится программа для чтения текста (говорилка), я рекомендую DeskBot (версию mini) — полное использование всех наворотов технологий MS Agent и Text-to-Speech: анимированные персонажи, чтение текстовых файлов, документов MS Office и буфера обмена через SAPI 4.0 — 5.x, напоминание времени, звуковые эффекты — реверберация, шепот и др., всего 1 Мб.
Там же можно найти дополнительные анимированные персонажи от сторонних разработчиков. Ну и движки тоже другие можно попробовать, если дефолтный TTS3000 не устроит. В топике как раз обсуждение идет в основном вокруг движков.
Updated (15.03.2013): как выяснилось DeskBot поддерживает только SAPI 4.0 (у меня были установлены движки Sam, Mike и Mary с этой страницы, и я их видимо по ошибке принял за движки для SAPI 5 и сделал вывод, что программа поддерживает и SAPI 5 тоже). А не поддерживает она SAPI 5 по той причине, что MS Agent и его персонажи, ради которых собственно и создавалась программа, в принципе несовместимы с этой версией SAPI. Однако, начиная с Windows Vista, MS Agent таки стал поддерживать SAPI 5, так что еще вполне может быть, что выпустят версию DeskBot с его поддержкой. А пока для SAPI 5 ищите что-нибудь более подходящее.
Всем остальным, кто интересуется этой темой, также рекомендую скачать дистрибутив Microsoft Speech API 5.1 — полный комплект со всеми голосовыми движками (английскими) для Windows 95-2003. Собран собственноручно из msm-модулей с этой странички по инструкции — 40 Мб. Или только SAPI без движков (включен в архив MSAgent.rar) — 500 Кб. Эксклюзив!
Updated (15.03.2013): ранее по ссылке был выложен standalone дистрибутив (4 в 1), добавил к нему отдельные дистрибутивы для каждого компонента — кому что удобнее, размер архива увеличился соответственно вдвое — 80 Мб.
На той же страничке зачем-то выложен файл msttss22L.exe без описания — это стандартный английский движок Microsoft TTS Engine 4.0 (Sam Voice) для SAPI 4.0 (в XP/2003 для сравнения стоит движок Microsoft TTS Engine 5.1 для SAPI 5.1 соответственно), который также можно скачать отсюда (вместе с голосами Mike и Mary) или отсюда (msttsl.exe — все три голоса в одном дистрибутиве).
SAPI 5.1 также можно найти здесь — абсолютно идентичный моему дистрибутив, сделанный из тех же вышеупомянутых msm-модулей. Предназначен для Windows 95-2003. В XP/2003 устанавливается только Mike + Mary Voices Addon, т.к. SAPI и TTS Engine (Sam Voice) в них уже предустановлены. Если не нужны английские голосовые движки, то лучше качать мою 500 килобайтную версию.
| На первую страницу #149 к последнему сообщению |
Источник: forum.ru-board.com