
Так как средства и методы обработки данных могут иметь разное значение, то различают глобальную, базовую и специальную (конкретную) информационные технологии.
Глобальная ИТ включает модели, методы и средства формирования и использования информационных ресурсов в обществе.
Базовая ИТ ориентируется на определенную область применения (производство, научные исследования, проектирование, обучение и т. д.). Базовая информационная технология предназначена для определенной области применения — производства, научных исследований, обучения и др. Базовая технология должна задавать модели, методы и средства решения информационных задач в своей предметной области.
Специальные (конкретные) ИТ задают обработку данных в определенных типах задач пользователей.
Базовая ИТ может быть представлена совокупностью информационных процессов, процедур и операций (см. рис. 2.1-4) и направлена на получение качественного информационного продукта из исходного информационного ресурса в соответствии с поставленной задачей.
Рассмотрение заявок участников конкурентных процедур анализ информации об участнике закупки
Базовая информационная технология как совокупность процессов, процедур и операций может быть рассмотрена на трех уровнях: концептуальном (определяется содержательный аспект, использующий язык соответствующей предметной области), логическом (отображается формальное — модельное — описание на языке информационных или математических моделей) и физическом (описывается реализация на языке программно-аппаратных средств).
Применительно к информационной технологии это означает содержательное описание используемых в ней информационных процессов и процедур на концептуальном уровне, описание в виде набора моделей (информационных, математических и т. д.) процессов и их составляющих на логическом уровне и реализацию информационных процессов в виде совокупности аппаратных средств, системного и прикладного программного обеспечения на физическом уровне.
2.3.1. Концептуальный уровень описания (содержательный аспект)
Рис. 2.3-1. Концептуальная модель базовой информационной технологии
Если построить цепочку, состоящую из процессов и процедур, перечисленных на рис. 2.3-1 последовательно слева направо, то получим описание во времени процессов преобразования информационного ресурса в информационный продукт (рис. 2.3-2).
Формирование информационного ресурса осуществляется в процессе получение информации и начинается с процедуры «Сбор информации», отражающей предметную область (параметры, характеристики, состояние объекта управления). Собранная информация должна быть соответствующим образом подготовлена (осмыслена, структурирована, проверена на полноту, достоверность, непротиворечивость и т. д.). После подготовки и проверки информация может быть передана для преобразования традиционными способами (телефон, курьер, почта, телеграф), а может быть подвергнута процессу преобразования в данные, т. е. процессу ввода.
Рис. 2.3-2.
Процедуры сбора, подготовки, проверки и ввода информации в ИТ организационно-экономических систем процесса «Получение информации» по своей реализации являются в основном ручными (кроме процедур проверки и ввода, которые могут быть частично автоматизированными). В процессе ввода информация преобразуется в данные, имеющие форму цифровых кодов, реализуемых на физическом уровне с помощью различных физических явлений (электрических, магнитных, оптических, механических и т. д.).
Процедуры и функции в 1С 8.3: чем они отличаются и как их использовать
Следующие за процессом «Получение» информационные процессы уже производят преобразование данных. Эти процессы протекают в ЭВМ под управлением различных программ. Процесс обработки данных включает процедуры преобразования значений и структур данных, путем моделирования, логического вывода и др., а также процедур организации вычислений.
Процесс «Отображение» включает процедуры преобразования данных в форму, удобную для восприятия: звук, изображение — текстовое, цифровое, графическое, видео, твердая копия на бумаге.
Процесс формирования знаний включен в базовую информационную технологию, поскольку высшим продуктом ИТ является знание. Формирование знания как высшего информационного продукта до сих пор являлось прерогативой человека. Автоматизированный процесс предоставления знаний может оказать помощь при решении трудноформализуемых задач. В этом процессе объединяются такие процедуры, как формализация знаний, их накопление и генерация (вывод) новых знаний на основе накопленных в соответствии с поставленной задачей, объяснение полученных автоматизированным путем знаний.
Процесс «Обмен» предполагает передачу данных между всеми процессами ИТ и связан со всеми процедурами на уровне данных. При обмене данными можно выделить три основных типа процедур: коммутация, маршрутизация (передача данных по каналам связи и организации сети) и передача. Процедуры передачи данных реализуются с помощью операции кодирования-декодирования, модуляции-демодуляции, согласования и усиления сигналов. Операции по организации сети включаются в качестве основных в процедуры коммутации и маршрутизации потоков данных (трафика) в вычислительной сети. Процесс обмена позволяет передавать данные между источником и получателем и используется в процессах получения и отображения информации, а также он способствует процессу накопления информации, поступающей из многих источников.
Процесс накопления позволяет преобразовывать информацию, хранящуюся в форме данных так, что ее удается длительное время хранить, постоянно обновляя, и при необходимости оперативно извлекать в заданном объеме и по заданным признакам. Процедуры этого процесса — архивирование, обновление и поиск — состоят в организации хранения (быстро и неизбыточно накапливать данные по заданным признакам и не менее быстро осуществлять их поиск) и актуализации данных (поддержание хранимых данных на уровне, соответствующем информационным потребностям решаемых задач). Актуализация данных осуществляется с помощью операций добавления новых данных, корректировки (изменения значений или элементов структур) данных и их уничтожения.
В информатике часто используются слова «информация» и «данные», причем часто как взаимозаменяемые. Хотя в необходимых случаях специалисты отмечают и их смысловое различие. Например, «информация кодируется с помощью данных и извлекается путем их декодирования и интерпретации». Кодирование информации происходит в процессе ввода ее в память ЭВМ, и можно считать, что данные — это информация, представленная в специальной фиксированной форме, пригодной для последующей компьютерной обработки, хранения и передачи.
В этом смысле представленные на схеме информационные процессы накопления, обработки и обмена манипулируют именно с данными, а процесс получения обеспечивает поступление информации и ее превращение в данные, так же как процесс отображения выполняет обратную функцию превращения данных в информацию.
2.3.2. Логический уровень (формализованное/модельное описание)
Логический уровень информационной технологии представляется комплексом взаимосвязанных моделей, формализующих информационные процессы при трансформации информации в данные. Формализованное в виде моделей представление информационной технологии позволяет связать параметры информационных процессов и дает возможность реализации управления информационными процессами и процедурами. На рис. 2.3-3 приведена логическая модель базовой информационной технологии, которая отражает схему взаимосвязи моделей информационных процессов.
Рис. 2.3-3. Логическая модель базовой ИТ уровня процессов
На основе модели предметной области, характеризующей объект управления, создается общая модель управления, а на ее основе формируются модели решаемых задач. Так как для решения задач необходимы различные информационные процессы, то необходимо строить модель организации информационных процессов, которая на логическом уровне увязывает применяемые при решении задач процессы управления.
При обработке данных формируются все основные информационные процессы: обработка, обмен и накопление данных, представление знаний.
Модель обработки данных включает в себя формализованное описание процедур организации вычислительного процесса (операционные системы), преобразования (алгоритмы и программы сортировки, поиска, создания и преобразования статических и динамических структур) и логического вывода (моделирования).
Модель обмена данными включает в себя формальное описание процедур, выполняемых в вычислительной сети: передачи (кодирование, модуляция в каналах связи), коммутации и маршрутизации (протоколы сетевого обмена) и описывается с помощью международных стандартов: OSI (взаимодействие отрытых систем), локальных сетей (IEEE 802) и спецификации сети Internet (см. гл. 18).
Модель накопления данных описывает как систему управления базой данных (СУБД), так и саму информационную базу (ИБ), которая представляется базой данных и базой знаний. Процесс перехода от смыслового (информационного) описания к физическому описывается трехуровневой системой моделей представления информационной базы: концептуальной (какая и в каком объеме информация должна накапливаться при реализации информационной технологии), логической (описывает ее структуру и взаимосвязь элементов информации) и физической (описывает методы размещения данных и доступа к ним на машинных носителях). Функции управления базами данных регламентируют (см. гл. 19): язык баз данных SQL (Structured Query Language); информационно-справочную систему IRD (Information Resource Dictionary System); протокол удаленного доступа операций RDA (Remote Data Access); PAS (Publicly Available Specifications) Microsoft на открытый прикладной интерфейс доступа к базам данных ODBC (Open Data Base Connectivity) API (Application Program Interface).
Модель представления знаний выбирается в зависимости от представления и содержания предметной области и вида решаемых задач. В настоящее время используются такие модели представления знаний, как логические, алгоритмические, семантические, фреймовые и интегральные.
Модель получения информации строится с учетом следующих стандартов, регламентирующих структуры данных и документов, а также форматы данных (см. гл. 18):
- средства языка ASN.1 (Abstract Syntax Notation One), предназначенного для спецификации прикладных структур данных — абстрактного синтаксиса прикладных объектов;
- форматы метафайла для представления и передачи графической информации CGM (Computer Graphics Metafile);
- спецификация сообщений и электронных данных для электронного обмена в управлении, коммерции и транспорте EDIFACT (Electronic Data Interchange for Administration, Commence and Trade);
- спецификации документов: спецификации структур учрежденческих документов ODA (Open Document Architecture);
- спецификации структур документов для производства, например: SGML (Standard Generalized Markup Language);
- языки описания документов гипермедиа и мультимедиа, например: HyTime, SMDL (Standard Music Description Language), SMSL (Standard Multimedia/Hypermedia Scripting Language), SPDS (Standard Page Description Language), DSSSL (Document Style Semantics and Specification Language), HTML (HyperText Markup Language);
- спецификация форматов графических данных, например: форматов JPEG, JBIG и MPEG.
Модель отображения информации строится с учетом стандартов (см. гл. 18): X Windows, MOTIF, OPEN LOOK, VT, CGI, PHIGS, машинной графики — GKS, графического пользовательского интерфейса — GUI.
Модели управления информацией, данными и знаниями увязывают базовые информационные процессы, синхронизируют их на логическом уровне.
Так как базовые информационные процессы оперируют с информацией, данными и знаниями, то управление информацией происходит через процессы получения (сбор, подготовка и ввод) и отображения (построение графики, текста и видео, синтез речи), а управление данными происходит через процессы: обработки (управление организацией вычислительного процесса преобразования), обмена (управление маршрутизацией и коммутацией в вычислительной сети, передачей сообщений по каналам связи) и накопления (системы управления базами данных), а управление знаниями — через процесс представления знаний (управление получением и генерацией знаний).
2.3.3. Физический уровень (программно-аппаратная реализация)
Физический уровень информационной технологии представляет ее программно-аппаратную реализацию. На физическом уровне информационная технология рассматривается как система, состоящая из крупных подсистем: обработки данных, обмена данными, накопления данных, получения и отображения информации, представления знаний и управления данными и знаниями (рис. 2.3-4). С системой, реализующей информационные технологии на физическом уровне, взаимодействуют пользователь и разработчик системы.
Рис. 2.3-4. Состав подсистем базовой информационной технологии
Подсистемы обработки данных строятся на базе электронных вычислительных машин различных классов и отличаются как по вычислительной мощности, так и по производительности. В зависимости от потребности решаемых задач используются как большие универсальные ЭВМ (мейнфреймы) для обработки громадных объемов информации, так и персональные компьютеры (ПК). В сети используются как серверы, так и клиенты (рабочие станции).
Подсистемы обмена данными включают комплексы программ и устройств (модемы, усилители, коммутаторы, кабели и др.), создающих вычислительную сеть и осуществляющих коммутацию, маршрутизацию и доступ к сетям.
Подсистема накопления данных реализуется с помощью банков и баз данных на внешних устройствах компьютеров и ими управляемых. Возможна организация как локальных баз и банков, реализуемых на отдельных компьютерах, так и организация распределенных банков данных, использующих сети ЭВМ и распределенную обработку данных.
Подсистемы получения, отображения информации и представления знаний используются для формирования модели предметной области из ее фрагментов и модели решаемой задачи. На стадии проектирования разработчик формирует в памяти компьютера комплекс моделей решаемых задач. На стадии эксплуатации пользователь обращается к подсистеме отображения информации и представления знаний и, исходя из поставленной задачи, выбирает соответствующую модель решения, после чего через подсистему управления данными включаются другие подсистемы.
Подсистема управления данными и знаниями, как правило, частично реализуется на тех же компьютерах, на которых реализуются соответствующие подсистемы, а частично с помощью систем управления организацией вычислительного процесса и систем управления базами данных. При больших потоках информации создаются специальные службы администраторов сети и баз данных.
Источник: intuit.ru
Обработка данных и информации
ИТ широко используются в самых различных сферах деятельности современного общества и, в первую очередь, — в информационной сфере Они позволяют оптимизировать разнообразные ИП, начиная от подготовки и издания печатной продукции и кончая информационным моделированием и прогнозированием глобальных процессов развития при роды и общества. При этом ИТ в любых предметных областях наиболее часто используются для обработки данных (информации).
Обработка – понятие широкое, часто включает в себя несколько взаимосвязанных более мелких операций. К обработке относят операции проведения расчётов, выборки, поиска, объединения, слияния, сортировки, фильтрации и др.
Важно помнить, что обработка – это систематическое выполнение операций над данными (информацией, знаниями); процесс преобразования, вычисления, анализа и синтеза любых форм данных, информации и знаний путём систематического выполнения операций над ними.
Обычно отдельно выделяют операции обработки данных, информации и знаний.
| Технология обработки информации –это упорядоченная взаимосвязь действий, выполняемых в строго определённой последовательности с момента возникновения информации до получения заданных результатов. |
Технология обработки информации зависит от характера решаемых задач, используемых средств вычислительной техники, числа пользователей, систем контроля за процессом обработки информации и т. д. При этом она используется при решении хорошо структурированных задач с имеющимися входными данными и алгоритмами, а также стандартными процедурами их обработки.
Технологический процесс обработки информации может включать следующие операции (действия): генерация, сбор, регистрация, анализ, собственно обработка, накопление, поиск данных, информации, знаний и др.
Обработка информации происходит в процессе реализации технологического процесса, определяемого предметной областью. Рассмотрим основные операции (действия) технологического процесса обработки информации.
1) Сбор данных, информации, знаний. Эта операция представляет собой процесс регистрации, фиксации, записи детальной информации (данных, знаний) о событиях, объектах (реальных и абстрактных), связях, признаках и соответствующих действиях. При этом иногда выделяютв отдельные операции «сбор данных и информации» и «сбор знаний».
| Сбор данных и информации –это процесс идентификации и получения данных от различных источников, группирования полученных данных и представления их в форме, необходимой для ввода в ЭВМ. |
Сбор знаний – это получение информации о предметной области от специалистов (экспертов) и представления ее в форме, необходимой для записи в базу знаний.
Различают механизированный, автоматизированный и автоматический способы сбора и регистрации информации и данных. Вариантом технологии автоматического сбора информации является RFID (от англ. radio frequency identification — радиочастотная идентификация) – специальный микрочип размером в несколько сантиметров, встраиваемый в какой-либо объект. С помощью имеющейся в нём антенны RFID обеспечивает обмен информацией с внешними устройствами (компьютером и др.). Он позволяет проводить диагностику оборудования, выявлять нуждающиеся в замене комплектующие и т. д. Внедрение этой технологии обеспечит высокоэффективные методы учёта и сервисного обслуживания различных изделий и объектов.
2) Обработка данных, информации, знаний. Обработка часто включает в себя несколько взаимосвязанных более мелких операций. К обработке можно отнести такие операции, как: проведение расчётов, выборка, поиск, объединение, слияние, сортировка, фильтрация и т. д. Обработка представляет собой систематическое выполнение операций над данными, процесс преобразования, вычисления, анализа и синтеза любых форм данных, информации и знаний посредством систематического выполнения операций над ними.
При определении такой операции, как обработка, выделяют понятия «обработка данных», «обработка информации» и «обработка знаний». При этом отмечают обработку текстовой, графической, мультимедийной и иной информации.
Обработка текстов является одним из средств электронного офиса.
Обычно наиболее трудоёмким процессом работы с электронным текстом является его ввод в ЭВМ. За ним следуют этапы подготовки (в том числе редактирование) текста, его оформление, сохранение и вывод. Этот вид обработки предоставляет пользователям различный инструментарий, повышающий эффективность и производительность их деятельности. При этом существуют программы, распознающие отсканированный текст, что существенно облегчает работу с подобными данными.
Обработка изображений получила широкое распространение с развитием электронной техники и технологий. При обработке изображений требуются высокие скорости, большие объёмы памяти, специализированное техническое и программное обеспечение. При этом существуют средства сканирования изображений, существенно облегчающие их ввод и обработку в ЭВМ. В компьютерных технологиях используют векторную, растровую и фрактальную графику. Изображения имеют различный вид, могут быть двух- и трёхмерными, с выделенными контурами и т. д.
Обработка таблиц осуществляется специальными прикладными программами, дополненными макросами, диаграммами, аналитическими и иными возможностями. Работа с электронной таблицей позволяет вводить и обновлять данные, команды, формулы, определять взаимосвязь и взаимозависимость между клетками (ячейками), таблицами, страницами, файлами с таблицами и БД, данными в виде функций, аргументами которых являются записи в ячейках.
| Обработка данных(от англ. data processing) — это процесс последовательного управления данными (числа и символы) и преобразования их в информацию. |
Обработка данных может осуществляться в интерактивном и фоновом режимах. Основное развитие эта технология получила в СУБД.
Общеизвестны следующие способы обработки данных: централизованная, децентрализованная, распределённая и интегрированная.
Централизованная обработка данных в ЭВМ в основном представляла собой пакетную обработку информации. При этом пользователь доставлял в вычислительный центр (далее –ВЦ) свою исходную информацию, а затем получал результаты обработки в виде документов и (или) носителей. Особенностью такого способа являются сложность и трудоёмкость налаживания быстрой, бесперебойной работы, большая загруженность ВЦ информацией (большой объём), регламентация времени выполнения операций, организация безопасности системы от возможного несанкционированного доступа. Поскольку сложность решаемых задач обычно обратно пропорционально их количеству, то централизованная обработка данных зачастую приводила к неэффективному использованию вычислительных ресурсов центральной ЭВМ, ограничивала доступ пользователей к её ресурсам, но требовала значительных материальных затрат на создание и эксплуатацию систем обработки данных.
Принцип централизованной обработки данных ранее не овечал высоким требованиям к надёжности процесса обработки, затруднял развитие систем, не мог обеспечить необходимые временные параметры при диалоговой обработке данных в многопользовательском режиме. А даже кратковременный выход из строя центральной ЭВМ мог привести к серьёзным негативным последствиям. Ныне эта технология получила новое развитие в создаваемых высоконадёжных и эффективных центров обработки данных (далее -ЦОД).
Децентрализованная обработка данных связана с появлением ПЭВМ (малых ЭВМ, микроЭВМ), позволивших автоматизировать конкретные рабочие места и повлекших за собой возникновение распределённой обработки данных.
Распределённая обработка данных — это обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределённую систему, т. е. в компьютерных информационных сетях. Она реализуется двумя путями. Первый предполагает установку ЭВМ в каждом узле сети (или на каждом уровне системы), при этом обработка данных осуществляется одной или несколькими ЭВМ в зависимости от реальных возможностей системы и её потребностей на текущий момент времени.
Второй путь предполагает размещение большого числа различных процессоров внутри одной системы. Распределённый способ основывается на комплексе специализированных процессоров – каждая ЭВМ используется для решения определённых задач, или задач своего уровня. Он применяется там, где необходима сеть обработки данных (филиалы, отделения и т. д.), например, в системах обработки банковской и финансовой информации.
Преимущества такого способа заключаются в возможности: обрабатывать в заданные сроки любой объём данных с высокой степенью надёжности (при отказе одного технического средства можно моментально заменить его на другой); сократить время и затраты на передачу данных; повысить гибкость систем; упростить разработку и эксплуатацию ПО и т. д.
Интегрированный способ обработки информации предусматривает создание информационной модели управляемого объекта – РБД. Он обеспечивает максимальное удобство для пользователя. С одной стороны, БД предусматривают коллективное пользование и централизованное управление. С другой стороны, объём информации, разнообразие решаемых задач требуют распределения БД. Технология интегрированной обработки информации позволяет улучшить качество, достоверность и скорость обработки, так как обработка производится на основе единого информационного массива, однократно введенного в ЭВМ.
Особенность этого способа заключается в отделении технологически и по времени процедуры обработки от процедур сбора, подготовки и ввода данных.
В информационных сетях обработка информации осуществляется различным образом: в пакетном и регламентном режимах; режимах реального масштаба времени, разделения времени и телеобработки, а также в запросном, диалоговом, интерактивном; однопрограммном и многопрограммном (мультиобработка) режимах.
Обработка данных в пакетном режиме означает, что каждая порция не срочно передаваемой информации (как правило, в больших объёмах) обрабатывается без вмешательства извне – формирование отчётных данных (сводок и т. п.). При его использовании пользователь не имеет непосредственного общения с ЭВМ.
Как правило, это задачи неоперативного характера, с долговременным сроком действия результатов решения. При этом сбор, регистрация, ввод и обработка информации не совпадают по времени. Сначала пользователь собирает информацию и формирует её в пакеты в соответствии с видом задач или другим признаком. По окончании приёма информации производится её ввод и обработка. В результате происходит задержка обработки.
Этот режим порой называют фоновым. Он реализуется, когда свободны ресурсы вычислительных систем и обработка может прерваться более срочными и приоритетными процессами и сообщениями, по окончании которых она возобновляется автоматически. Режим используется, как правило, при централизованном способе обработки информации.
В режиме разделения времени в одном компьютере осуществляется чередование во времени процессов решения разных задач. В этом режиме ресурсы компьютера (системы) для оптимального их использования предоставляются сразу группе пользователей циклично, на короткие интервалы времени. При этом система выделяет свои ресурсы группе пользователей поочерёдно. Поскольку ЭВМ быстро обслуживает каждого из группы пользователей, создаётся впечатление одновременной их работы. Такая возможность достигается путём использования специального ПО.
Режим реального времени – это технология. обеспечивающая реакцию управления объектом, соответствующую динамике его производственных процессов. Он означает способность вычислительной системы взаимодействовать с контролируемыми или управляемыми процессами в темпе протекания этих процессов. Время реакции может измеряться секундами, минутами, часами и должно удовлетворять темпу контролируемого процесса или требованиям пользователей и иметь минимальную задержку.
В системах реального времени обработка данных по одному сообщению (запросу) завершается до появления другого. Как правило, такой режим используется при децентрализованной и распределённой обработке данных и применяется для объектов с динамическими процессами. Например, обслуживание клиентов в банке по любому набору услуг должно учитывать допустимое время ожидания клиента, одновременное обслуживание нескольких клиентов и укладываться в заданный интервал времени (время реакции системы).
Интерактивный режим предполагает возможность двустороннего взаимодействия пользователя с системой, т. е. пользователь может воздействовать на процесс обработки данных. Интерактивная работа осуществляется в режиме реального времени и обычно используется для организации диалога (диалоговый режим).
Диалоговый (запросный) режим характеризуется возможностью пользователя в процессе работы с ЭВМ непосредственно взаимодействовать с ней. Программы обработки данных могут находиться в памяти компьютера постоянно (ЭВМ доступна в любое время) или в течение определённого промежутка времени (только когда ЭВМ доступна пользователю).
Диалоговое взаимодействие пользователя с компьютером может быть многоаспектным и определяться такими факторами, как: язык общения; активная или пассивная роль пользователя; кто является инициатором диалога (пользователь или ЭВМ); время ответа; структура диалога и т. д. Если инициатором диалога является пользователь, то он должен обладать знаниями и навыками работы с процедурами, форматами данных и т. д.. Если инициатор – ЭВМ, то она сама на каждом шаге сообщает, что нужно делать пользователю – метод «выбора меню». Данный метод обеспечивает поддержку действий пользователя и предписывает их последовательность. При этом от пользователя требуется меньшая подготовленность.
Диалоговый режим требует определённого уровня технической оснащённости пользователя: наличие терминала или ПЭВМ, связанных телекоммуникациями с центральной ЭВМ. Возможность работы в диалоговом режиме может быть ограничена во времени началом и концом работы, а может быть неограниченной. Режим используется для доступа к информации, вычислительным или программным ресурсам.
Иногда различают диалоговый и запросный режимы. Под запросным режимом понимается одноразовое обращение к системе, после которого она выдаёт ответ и отключается (например, справочная система), а под диалоговым – режим, при котором система после запроса выдаёт и ждёт дальнейших действий пользователя.
Режим телеобработки позволяет удалённому пользователю взаимодействовать с ЭВМ (его порой называют терминальным).
Однопрограммный или многопрограммный режимы характеризуют возможность системы работать одновременно по одной или нескольким программам.
Регламентный режим ориентирован на определённую во времени последовательность выполнения отдельных задач пользователя. Например, регулярное (ежемесячное, квартальное и т.п.)т получение результатных сводок и отчётов, расчёт ведомостей начисления зарплаты к определённым датам и т. д. При этом выделяют регулярные, специальные, сравнительные, чрезвычайные и иные виды отчётов.
Регулярные отчёты обычно создаются по запросам администрации или в случае незапланированных ситуаций. Названные отчёты могут иметь форму суммирующих, сравнительных и чрезвычайных отчётов. В суммирующих отчётах данные объединяют в отдельные группы, сортируют, представляют в виде промежуточных и окончательных итогов по отдельным полям. Сравнительные отчёты включают данные, полученные из разных источников или квалифицированные по различным признакам и используемые для целей сравнения. Чрезвычайные отчёты содержат данные исключительного (чрезвычайного) характера.
Обработка информации подразумевает переработку информации определённого типа (текстовой, звуковой, графической и др.) и преобразования её в информацию другого определённого типа. Так, например, принято различать обработку текстовой информации, изображения (графики, фото, видео и мультипликация) и звуковой информации (речь, музыка, другие звуковые сигналы). Использование новейших технологий обеспечивает их комплексное представление. При этом человеческое мышление может рассматриваться как процесс обработки информации.
ИТ обработки информации предназначена для решения хорошо структурированных задач, по которым имеются необходимые входные данные, известны алгоритмы и другие стандартные процедуры их обработки. Эта технология применяется в целях автоматизации рутинных постоянно повторяющихся операций, что позволяет повышать производиетельность труда, освобождая исполнителей от рутинных операций, а порой и сокращая численность работников. При этом решаются задачи: обработки данных; создания периодических отчётов о состоянии дел; связанные с получением ответов на различные текущие запросы и оформлением их в виде документов и отчётов. При этом применяя. такие ИТ, как: сбор и регистрация данных непосредственно в процессе производства в форме документа с использованием центральной ЭВМ или персональных компьютеров; обработка данных в режиме диалога; агрегирование (объединение) данных; использование электронных носителей информации (например, дисков).
Технологический процесс обработки информации с использованием ЭВМ включает следующие операции:
1) Приём и комплектование первичных документов (проверка полноты и качества их заполнения, комплектности и т. д.);
2) Подготовка электронного носителя и контроль его состояния;
3) Ввод данных в ЭВМ;
4) Контроль, результаты которого выдаются на внешние устройства (принтер, монитор и т. д.).
Существуют и другие подобные технологии, однако обратим внимание на ИТ (операции) контроля данных, редко рассматриваемые в специальной учебной литературе. В различных ситуациях приходится контролировать получаемые или распространяемые данные и информацию. С этой целью широко применяют ИТ. Различают визуальный и программный контроль, позволяющий отслеживать информацию на полноту ввода, нарушение структуры исходных данных, ошибки кодирования. Контроль не является самоцелью. При обнаружении ошибки производят:
· исправление вводимых данных, корректировку и их повторный ввод;
· запись входной информации в исходные массивы;
· сортировку (если в этом есть необходимость);
· повторный контроль и выдачу окончательной информации.
Рассмотрим более подробно обработку различных названных выше типов (видов) информации.
Источник: studopedia.su
Запись вспомогательных алгоритмов на языке Паскаль. Процедуры

В данном видеоуроке рассматривается запись вспомогательных алгоритмов на языке Паскаль с помощью процедур, а также применение процедур при решении задач.

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет.
Получите невероятные возможности

1. Откройте доступ ко всем видеоурокам комплекта.

2. Раздавайте видеоуроки в личные кабинеты ученикам.

3. Смотрите статистику просмотра видеоуроков учениками.
Получить доступ
Конспект урока «Запись вспомогательных алгоритмов на языке Паскаль. Процедуры»
· Какие существуют инструменты для записи вспомогательных алгоритмов в языке паскаль?
· Что такое процедуры, и как они записываются?
· Применение процедур при решении задач.
Ранее мы изучили метод последовательного конструирования алгоритмов, при котором алгоритм последовательно разбивается на отдельные подзадачи, пока они не станут понятны исполнителю. А также мы узнали, что решение отдельных подзадач бывает удобно оформить в виде вспомогательных алгоритмов. Вспомним, что вспомогательным называется алгоритм, который целиком использован в составе другого алгоритма. Сегодня мы начнём применять эти знания при написании программ на языке Pascal.
Какие же инструменты есть в языке Pascal для записи вспомогательных алгоритмов. Вспомогательные алгоритмы в языке Pascal записываются с помощью подпрограмм. Подпрограмма – это именованная последовательность команд. Подпрограммы записываются между разделом описания переменных и телом основной программы в любом удобном порядке. Подпрограммы имеют схожую с основной программой структуру.
В языке Pascal есть два вида подпрограмм: процедуры и функции. Сегодня мы узнаем, что такое процедура и как она записывается на языке Паскаль.
Процедурой называется подпрограмма, которая имеет произвольное количество входных и выходных параметров. То есть такая подпрограмма может принять на ввод одну или несколько переменных, и по выполнении команд вернуть одну или несколько переменных.
Схема работы процедуры
Процедуры записываются следующим образом… В начале идёт служебное слово Procedure, и через пробел указывается имя процедуры. Имя процедуры не должно совпадать с именем программы или переменных, остальные требования те же, что и к имени программы, то есть оно может содержать от 1 до 255 цифр, букв латинского алфавита и знаков подчёркивания, и должно начинаться с буквы латинского алфавита или знака подчёркивания.
После имени процедуры в круглых скобках, как в разделе описания переменных, перечисляются сначала входные параметры с указанием типа, затем после служебного слова var перечисляются выходные параметры с указанием типа. В конце строки ставится точка с запятой. Если необходимы промежуточные переменные, то строкой ниже записывается раздел описания переменных процедуры, который, как и в основной программе, начинается со слова var. Далее, между служебными словами begin и end, следует тело процедуры. В данном случае после служебного слова end ставится точка с запятой.
Схематичная запись процедуры
Для вызова процедуры в основной программе достаточно записать имя процедуры, после которого в круглых скобках перечислить входные и выходные параметры. В качестве входных параметров могут быть заданы как названия переменных, так и константы.
Схематичная запись вызова процедуры
Важно при этом: точно соблюдать порядок записи параметров, он должен быть таким же, как и в заголовке процедуры. А также важно точно соблюдать соответствие типов. То есть если в процедуре вторым параметром указана переменная типа integer, то при вызове вторым параметром также должна быть переменная типа integer, или целочисленная константа в пределах, соответствующих данному типу.
Задача: Три прямых на координатной плоскости заданы коэффициентами своих уравнений вида y = kx + b, при этом они образуют треугольник. Найти координаты вершин данного треугольника.
Построим математическую модель. Очевидно, что три прямые на координатной плоскости образуют треугольник, если никакие две из них не совпадают и не параллельны друг другу. А вершинами данного треугольника будут точки пересечения данных прямых. При этом, если прямые параллельны или совпадают, то коэффициенты k их уравнений будут равны. То есть, чтобы три прямые образовали треугольник, коэффициенты k их уравнений не должны совпадать.
Посмотрим, как же найти точку пересечения двух прямых. Для этого достаточно решить следующую систему уравнений. Где k1 и b1 – соответствующие коэффициенты первого уравнения, а k2 и b2 – второго.
Вычтем из первого уравнения второе и получим уравнение, из которого нам остаётся лишь выразить x, теперь остаётся лишь известную координату x подставить в любое из уравнений, допустим в первое, и получить координату y.
Составим блок-схему алгоритма решения задачи, при этом обозначим через k1, k2, k3 и b1, b2, b3 коэффициенты уравнений соответствующих прямых, а через xa, xb, xc, ya, yb, yc – соответствующие координаты вершин A, B и C. В качестве вспомогательного алгоритма оформим нахождение координат точки пересечения двух прямых.
Вначале нам нужно считать значения коэффициентов уравнений прямых, затем необходимо проверить, образуют ли они треугольник, то есть не равны ли между собой какие-нибудь два коэффициента k. Если равных коэффициентов не нашлось, нужно при помощи вспомогательного алгоритма, назовём его point, что в переводе с английского языка означает «точка», поочерёдно найти координаты точек пересечения прямых, которые будут являться вершинами треугольника, а затем вывести их на экран, если же какие-то коэффициенты k равны между собой, мы должны вывести на экран поясняющее сообщение о том, что заданные прямые не образуют треугольник.
Блок-схема алгоритма решения задачи
Напишем программу по данной блок-схеме. Назовём её triangle, что в переводе с английского языка означает «треугольник». В разделе описания переменных укажем, что нам понадобятся переменные коэффициентов уравнений и также координат вершин, по смыслу задачи понятно, что данные необязательно будут целыми числами, поэтому укажем их тип: real. Запишем тело программы.
Вначале выведем на экран поясняющее сообщение о том, что это программа нахождения координат вершин треугольника по уравнениям прямых его сторон. Далее для всех коэффициентов уравнений выведем на экран запросы на ввод и запишем команды их считывания… Теперь проверим корректность ввода данных, то есть образуют ли данные прямые треугольник. Для этого запишем условный оператор с составным условием: (k1<> k2) and (k2<>k3) and (k1<>k3).
Запишем блок команд для выполнения условия. Если данные прямые образуют треугольник, вызовем процедуру point. Саму процедуру оформим позже. Процедура должна принимать в качестве входных параметров коэффициенты уравнений двух прямых, в данном случае для первых двух k1, b1 и k2, b2.
Выходными параметрами будут координаты точки пересечения прямых, в данном случае xa и ya. Так мы нашли координаты вершины А. Таким же образом, найдём координаты остальных двух вершин… Далее выведем координаты на экран, оформив вывод соответствующим образом… Теперь для случая, если начальное условие не выполняется, выведем на экран сообщение о том, что заданные прямые не образуют треугольник.

Исходный код основной программы
Теперь между разделом описания переменных и телом программы оформим процедуру для нахождения точки пересечения двух прямых. Запишем служебное слово procedure, и название процедуры point, после которого в круглых скобках запишем входные параметры. Обратим внимание, что имена параметров процедуры могут совпадать с именами переменных в основной программе.
Потому имена входных и выходных параметров, а также промежуточных переменных выбираются для решения заданной подзадачи. Входными параметрами будут коэффициенты двух уравнений прямых k1, b1 и k2, b2, все типа real. Теперь запишем служебное слово var и перечислим выходные параметры – ими будут координаты точки x и y, которые так же будут принадлежать к типу real. Промежуточных переменных для решения подзадачи нам не потребуется.
Между служебными словами begin и end запишем тело процедуры. Оно будет содержать всего две команды – расчёты координат точек по формулам, которые мы вывели в математической модели.
Исходный код процедуры нахождения координат точки пересечения прямых
Придумаем несколько тестов для программы. Для примера возьмём уравнения прямых и сразу же построим их графики. y = 4x, y= –3x + 7, и y=x/2. Построив данные прямые на координатной плоскости, мы можем определить, что вершинами треугольника, который образуют прямые, являются точки с координатами 0;0, 1;4 и 2;1.
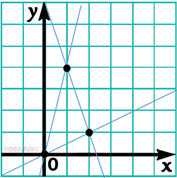
Придумаем ещё один тест при котором прямые не образуют треугольник. Для этого зададим две параллельные прямые с уравнениями: y = 4x и y = 4x – 10, и ещё одну прямую с уравнением y = x.
Введём данные из первого теста в программу… Координаты точек, которые вывела программа, совпадают с координатами, полученными на графике.
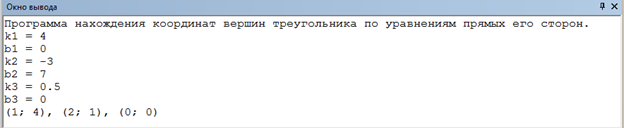
Результат работы программы по первому тесту
Введём данные из второго теста… Программа вывела поясняющее сообщение о том, что заданные прямые не образуют треугольник. Результаты тестов соответствуют ожидаемым – задача решена верно.
Результат работы программы по второму тесту
Важно запомнить:
· Вспомогательные алгоритмы на языке Pascal записываются в виде подпрограмм.
· Подпрограмма – это именованная последовательность команд.
· Подпрограммы в языке Pascal делятся на процедуры и функции.
· Процедура – это подпрограмма, которая имеет произвольное количество входных и выходных параметров.