
Компиляция, компоновка и выполнение проекта
Компиляция (compilation) – это преобразование программы или ее отдельного модуля, текст которых составлен на языкепрограммирования высокого уровня (исходная программа, исходный модуль – это файл с расширением .срр) в программу или модуль намашинном языке или на языке, близком к машинному (получаютобъектный модуль – файл с расширением .obj). Компиляцию осуществляет специальная программа –компилятор (compiler), которая является неотъемлемой частью системы программирования. На вход компилятора поступаетисходный модуль (файл .срр), который после компиляции преобразуется в объектный модуль (файл .obj)
Объектный модуль не может быть исполнен, его местоположение в оперативной памяти еще не известно (не определено). Компилятор вырабатывает только относительные адресасвязи с другими модулями. В дальнейшем их предстоит заменить конкретными адресами (абсолютными адресами) той части оперативной памяти, в которой этот модуль будет выполняться.
Что такое компилятор и интерпретатор ? Их основные отличия.
Результат компиляции – это промежуточная форма программных модулей, к которым впоследствии необходимо присоединить библиотечные модули, содержащие стандартные подпрограммы и процедуры, а если нужно, то можно добавить любые другие модули, написанные самим пользователем, и скомпилированные в объектные модули, возможно даже с других языков высокого уровня.
Существуют различные виды компиляторов:
Источник: studfile.net
Что такое компилятор
Если вы программист, то наверняка слышали слово “компилятор”. Но знаете ли вы, что это такое на самом деле? Вы когда-нибудь задумывались, что происходит под капотом, когда вы запускаете команду javac (если у вас код на Java)? Вы когда-нибудь хотели создать свой собственный язык программирования? — и просто заводили бесполезный репозиторий GitHub, где все равно есть только один readme.md, потому что вы даже не знаете, с чего начать. Я думаю, что начинать стоит с этого: узнать больше о компиляторе.
Итак, в этой статье мы разберёмся, что представляет собой компилятор. Если вы опытный программист, который знает про компилятор каждую мелочь, то извините, эта статья не для вас. Но если вы — тот самый парень из абзаца выше, то вперёд за мной, в кроличью нору. На протяжении статьи я буду обсуждать следующие подтемы:
- введение в компилятор;
- типы компиляторов;
- архитектура компилятора.
Мне хочется, чтобы к концу статьи вы могли понимать, что происходит под капотом, когда вы запускаете команду javac , а также получили некоторое представление о том, как написать свой собственный язык программирования.
Вступление
Компилятор — это не что иное, как переводчик исходного кода.
Задача компилятора — перевести исходный код с одного языка на другой. Это означает, что если вы скормите компилятору исходный код Java, то сможете получить исходный код Python (не самый лучший пример, просто для понимания сути. На самом деле вы получите байт-код Java, который можно запустить на JVM). Для выполнения этого процесса у компилятора есть несколько взаимосвязанных компонентов.
Компиляция и интерпретация за 10 минут
Типы компиляторов
Мы можем классифицировать компиляторы по-разному. В этой статье я расскажу о двух способах классификации компиляторов, однако особенно углубляться в это не буду.
Классификация компиляторов в соответствии с этапами компиляции
Здесь мы рассмотрим количество этапов, которые проходит компилятор. Некоторые компиляторы непосредственно преобразуют высокоуровневый исходный код в машинный код, а некоторые — сначала преобразуют высокоуровневый исходный код в промежуточное представление перед преобразованием в машинный код.
Таким образом, в соответствии с этой классификацией можно выделить три типа компиляторов:
- Однопроходной компилятор.
- Двухпроходной компилятор.
- Многопроходной компилятор.
Если вы хотите узнать больше об этой классификации компиляторов, посмотрите сюда.
Классификация компиляторов в соответствии с исходным кодом и целевым кодом
Для преобразования исходного кода в целевой применяются разные подходы. Некоторые компиляторы преобразуют код на высокоуровневом языке в машинный. Некоторые компиляторы преобразуют с одного языка высокого уровня на другой язык высокого уровня. Таким образом, здесь выделяются следующие типы:
- Кросс-компиляторы — такие компиляторы работают на одной платформе и производят код для запуска на другой платформе. Например, компилятор работает на платформе X и создает код для запуска на платформе Y. Такими компиляторами пользуются разработчики встроенных систем.
- Традиционные компиляторы — нам лучше всего знаком именно этот тип компиляторов. Такие компиляторы преобразуют исходный код языка высокого уровня в исходный код машинного языка. Набор компиляторов GCC преобразует эти языки в низкоуровневые, которые выполняются на этих платформах.
- Транспилеры — они преобразуют исходный код языка высокого уровня в исходный код другого языка высокого уровня. Например, Babel transpiler преобразует ECMAScript 2015+ в JavaScript.
- Декомпиляторы — они принимают низкоуровневый исходный код в качестве входных данных и пытаются создать высокоуровневый исходный код, который может быть успешно перекомпилирован.
Архитектура компилятора
Когда компилятор компилирует (переводит) исходный код, он проходит несколько этапов:
- Исходный код.
- Лексический анализ.
- Синтаксический анализ.
- Семантический анализ.
- Промежуточная генерация кода.
- Оптимизация кода.
- Генерация кода.
- Целевой код.
Мы можем разделить все эти этапы на две фазы, примерно как фронтенд и бэкенд. Эти фазы включают в себя следующие этапы:
Фронтенд
- Лексический анализ.
- Синтаксический анализ.
- Семантический анализ.
- Генерация промежуточного кода.
Бэкенд
- Оптимизация кода.
- Генерация кода.
В следующем разделе я кратко опишу, что происходит на каждой фазе. Если вы не программируете компиляторы, то нормально иметь о них лишь поверхностное представление, но если вы хотите разработать компилятор сами, то вам стоит подробно изучить их работу.
Лексический анализ
Теперь вы знаете, что компилятор — это программа, которая преобразует исходный код в другой исходный код. Компилятор получает исходный код в виде файла. Этот файл содержит код в текстовом формате, но компилятор не может работать с этим текстом. Необходимо преобразовать этот текст в некоторый другой формат, понятный компилятору. Для этого компилятор разбивает текст по маркерам.
Помните, что эти маркеры заранее определены в грамматике языка. Маркеры пригодятся на следующих этапах процесса компиляции:
KEYWORD, BRACKET, IDENTIFIER, OPERATOR, NUMBER на приведенной выше диаграмме — это и есть маркеры. Компилятор использует лексический анализ для идентификации маркеров, и если он получает маркер, который не определен заранее в грамматике языка, то это будет считаться ошибкой.
Синтаксический анализ (парсинг)
На этом этапе компилятор проверяет, расположены ли идентифицированные ранее маркеры в правильном порядке. Для этого в каждом языке есть набор правил, называемый грамматикой. Во-первых, компилятор пытается построить структуру данных — дерево синтаксического анализа. Если компилятор смог успешно построить дерево синтаксического анализа в соответствии с заранее определенными правилами грамматики, то в исходном коде нет синтаксических ошибок. В противном случае возникают ошибки и компилятор их покажет.
Здесь мы сначала определили грамматику. Затем компилятор пытается построить дерево синтаксического анализа для исходного кода 2 + 3 * 3. В этом случае компилятору удается построить дерево синтаксического анализа (с правой стороны) в соответствии с грамматикой, следовательно в этой программе нет синтаксических ошибок.
Семантический анализ
Просто потому, что программа не содержит синтаксических ошибок, код еще не может считаться правильным. Рассмотрим предложение ниже.
Теперь предположим, что все слова в этом предложении — правильные лексемы, идентифицированные на этапе лексического анализа. Как люди, мы знаем, что в предложении на английском языке есть порядок подлежащее -> сказуемое -> дополнение.
Компилятор при анализе синтаксиса может решить, что в этом предложении нет синтаксических ошибок, потому что маркеры (слова) расположены в правильном порядке.
Теперь рассмотрим предложение ниже.
Предположим, что eat — правильный маркер в соответствии с грамматикой. Таким образом, предложение признается правильным на этапе лексического и синтаксического анализа, поскольку слова расположены в правильном порядке. Но в этом предложении нет никакого смысла — никто не может есть компиляторы.
Итак, согласно этапу семантического анализа, эта программа содержит ошибку. Мы называем эту разновидность ошибок семантическими ошибками. Взгляните на этот простой Java-код:
class SemanticAnalysis public static void main(String[] args) int a = 5;
int b = 10;
int total = c + d;
>
>
Здесь нет синтаксических ошибок. Все маркеры упорядочены правильно. Но на пятой строке int total = c + d — не имеет никакого значения, так как идентификаторы c и d не определены. Это и есть семантическая ошибка.
Генерация промежуточного кода
Любой компилятор может непосредственно генерировать машинный код из исходного. Так зачем же тогда нужна фаза генерации промежуточного кода?
Существуют различные типы машин. Таким образом, машинный код зависит от системы, а высокоуровневый исходный код — нет. Если компилятор непосредственно генерирует машинный код из исходного кода, то каждая машина нуждается в полной компиляции от фронта к бэку. Но когда компилятор генерирует промежуточный код (промежуточное представление), он уже может генерировать машинный код для каждой машины с его помощью, без повторения лексического анализа и парсинга для каждой машины.
Существует два основных типа промежуточных представлений:
- Высокоуровневый — более близкий к высокоуровневому языку.
- Низкоуровневый — более близкий к машинному коду.
Существует также несколько способов представления промежуточного представления.
- AST — абстрактное синтаксическое дерево (графическое).
- Постфиксная нотация.
- Трехадресный код.
- Двухадресный код.
Оптимизация кода
Этап оптимизации кода выполняет две основные задачи: минимизация времени или минимизация ресурсов. Что все это значит? Когда пользователь пишет код, нет ничего, кроме инструкций. Когда процессор выполняет эти инструкции, требуют время и ресурсы памяти. Таким образом, целью этапа оптимизации кода становится сокращение времени выполнения и ресурсов, потребляемых программой. Оптимизатор кода всегда следует трем правилам:
- Выходной код никоим образом не должен изменять значение исходного кода.
- Минимизируйте либо время, либо ресурсы, либо и то и другое вместе.
- Фаза оптимизации кода сама по себе не должна занимать много времени и замедлять весь процесс компиляции.
Существует два способа оптимизации кода:
- Машинно-независимая оптимизация.
- Машинно-зависимая оптимизация.
Машинно-независимая оптимизация принимает промежуточное представление относительно входных данных и не заботится ни о каких регистрах процессора и ячейках памяти. Она происходит после генерации промежуточного кода.
При машинно-зависимой оптимизации кода компилятор заботится о регистрах процессора, расположениях памяти и архитектуре машины. Она происходит после генерации машинного кода.
Генерация кода
Генерация кода — это последний этап процесса компиляции. Да, после может следовать машинно-зависимая оптимизация кода. Но мы можем рассматривать и то, и другое вместе как генерацию кода. На этом этапе компилятор генерирует машинно-зависимый код. Генератор кода должен иметь представление о среде выполнения целевой машины и ее наборе команд.
На этом этапе компилятор выполняет несколько основных задач:
- Выбор инструкций — какую инструкцию использовать.
- Создание расписания инструкций — в каком порядке должны быть упорядочены инструкции.
- Распределение регистров — выделение переменных в регистры процессора.
- Отладка данных — отладка кода с помощью отладочных данных.
Итоговый машинный код, сгенерированный генератором кода, может быть выполнен на целевой машине. Именно так высокоуровневый исходный код, который мы пишем в нашем любимом редакторе кода, преобразуется в формат, который можно запустить на любой целевой машине.
В этой статье я предоставляю только краткое описание. Если вам хочется углубиться в эти концепции, к вашим услугам миллионы ресурсов в интернете.
- Пять отличных Python-библиотек для data science
- Значение Data Science в современном мире
- Шесть рекомендаций для начинающих специалистов по Data Science
Источник: medium.com
Введение
Таким образом, то, что вы можете назвать языком программирования, на самом деле представляет собой просто программное обеспечение, называемое компилятором, которое читает текстовый файл, много обрабатывает его и генерирует двоичный файл.Поскольку компьютер может читать только 1 и 0, а люди пишут лучше, чем Rust, чем двоичные файлы, были созданы компиляторы, чтобы превратить этот читаемый человеком текст в читаемый компьютером.Машинный код,
Компилятором может быть любая программа, которая переводит один текст в другой. Например, вот компилятор, написанный на Rust, который превращает 0 в 1, а 1 в 0:

Что такое переводчик
интерпретаторы очень похожи на компиляторы в том, что они читают язык и обрабатывают его. Хотя,интерпретаторы пропускают генерацию кода и выполняют AST вовремя ,Самое большое преимущество для интерпретаторов — это время, необходимое для запуска вашей программы во время отладки. Компилятору может потребоваться от секунды до нескольких минут, чтобы скомпилировать программу перед выполнением, в то время как интерпретатор начинает выполнение немедленно, без компиляции. Самым большим недостатком переводчика является то, что он должен быть установлен на компьютере пользователя, прежде чем программа может быть выполнена.

Эта статья в основном относится к компиляторам, но должно быть ясно, как они различаются и как соотносятся компиляторы.
1. Лексический анализ
Первый шаг — разделить входные данные символ за символом. Этот шаг называется лексический анализ или токенизация. Основная идея заключается в том, чтомы группируем символы вместе, чтобы сформировать наши слова, идентификаторы, символы и многое другое.Лексический анализ в основном не имеет ничего общего с решением 2+2 — было бы просто сказать, что есть три жетоны: число: 2 , знак плюс, а затем еще один номер: 2 ,
Допустим, вы лексировали строку как 12+3 : это будет читать символы 1 , 2 , + , а также 3 , У нас есть отдельные персонажи, но мы должны сгруппировать их; одна из главных задач токенизатора. Например, мы получили 1 а также 2 как отдельные буквы, но нам нужно сложить их и проанализировать как одно целое число. + также должен быть признан как знак плюс, а не его буквальное значение символа — код символа 43.

Если вы можете видеть код и таким образом придавать ему большее значение, то следующий токенайзер Rust может сгруппировать цифры в 32-разрядные целые числа и знаки плюс в качестве Token ценность Plus
Rust Playground
play.rust-lang.org
Вы можете нажать кнопку «Выполнить» в верхнем левом углу Rust Playground, чтобы скомпилировать и выполнить код в вашем браузере.
В компиляторе для языка программирования лексеру может потребоваться несколько различных типов токенов. Например: символы, числа, идентификаторы, строки, операторы и т. Д. От самого языка зависит, какие именно токены вам нужно извлечь из исходного кода.

Дерево, которое генерирует парсер при разборе, называется абстрактное синтаксическое дерево или АСТ.AST содержит все операции. Парсер не вычисляет операции, он просто собирает их в правильном порядке.
Я добавил к нашему коду лексера ранее, чтобы он соответствовал нашей грамматике и мог генерировать AST, как на диаграмме. Я отметил начало и конец нового кода парсера с комментариями // BEGIN PARSER // а также // END PARSER // ,
Rust Playground
play.rust-lang.org
Мы можем пойти гораздо дальше. Скажем, мы хотим поддерживать входные данные, которые являются просто числами без операций, или добавлением умножения и деления, или даже добавлением приоритета. Это все возможно благодаря быстрой смене файла грамматики и настройке, чтобы отразить его внутри нашего кода синтаксического анализатора.

3. Генерация кода
генератор кода берет AST и испускает эквивалент в коде или сборке.Генератор кода должен перебирать каждый отдельный элемент в AST в порядке рекурсивного спуска — очень похоже на работу синтаксического анализатора — и затем выдавать эквивалент, но в коде.
Compiler Explorer — Rust (rustc 1.29.0)
pub fn main ()
godbolt.org
Если вы откроете ссылку выше, вы можете увидеть сборку, созданную в примере кода слева. Строки 3 и 4 кода сборки показывают, как компилятор генерировал код для констант, когда он встретил их в AST.
Godbolt Compiler Explorer — отличный инструмент, позволяющий писать код на языке программирования высокого уровня и видеть его сгенерированный код сборки. Вы можете поэкспериментировать с этим и посмотреть, какой код должен быть сделан, но не забудьте добавить флаг оптимизации в компилятор вашего языка, чтобы увидеть, насколько он умный ( -O для ржавчины)
Если вас интересует, как компилятор сохраняет локальную переменную в памяти в ASM, Эта статья (раздел «Генерация кода») объясняет стек в деталях. В большинстве случаев продвинутые компиляторы выделяют память для переменных в куче и сохраняют их там, а не в стеке, когда переменные не являются локальными. Вы можете прочитать больше о хранении переменных в этот ответ StackOverflow,
Поскольку сборка — это совершенно другой, сложный предмет, я не буду особо говорить об этом. Я просто хочу подчеркнуть важность и работу генератора кода. Кроме того, генератор кода может производить больше, чем просто сборка. Haxe компилятор имеет бэкенд который может генерировать более шести различных языков программирования; в том числе C ++, Java и Python.
Backend относится к генератору или оценщику кода компилятора; поэтому передний конец — это лексер и парсер. Существует также средний конец, который в основном связан с оптимизацией и IR, описанными далее в этом разделе. Задний конец в основном не связан с внешним интерфейсом и заботится только о AST, который он получает. Это означает, что можно использовать один и тот же бэкэнд для нескольких разных интерфейсов или языков. Это случай с пресловутым Коллекция компиляторов GNU ,
У меня не может быть лучшего примера генератора кода, чем у моего компилятора C; ты можешь найти это Вот ,
После того, как сборка произведена, она будет записана в новый файл сборки ( .s или .asm ). Затем этот файл будет передан через ассемблер, который является компилятором для сборки, и сгенерирует эквивалент в двоичном виде. Затем двоичный код будет записан в новый файл, называемый объектным файлом ( .o ).
Объектные файлы являются машинным кодом, но они не являются исполняемыми.Чтобы они стали исполняемыми, объектные файлы должны быть связаны друг с другом. Компоновщик берет этот общий машинный код и делает его исполняемым, общая библиотека или статическая библиотека,Подробнее о компоновщиках Вот ,
Линкеры — это служебные программы, которые различаются в зависимости от операционной системы. Один сторонний компоновщик должен иметь возможность компилировать объектный код, который генерирует ваш бэкэнд. При создании компилятора не должно быть необходимости создавать собственный компоновщик.
Компилятор может иметь промежуточное представление или IR.IR — это представление оригинальных инструкций без потерь для оптимизации или перевода на другой язык.IR не является исходным кодом; IR — это упрощение без потерь для поиска потенциальных оптимизаций в коде. Разматывание петли а также векторизации сделано с помощью ИК. Больше примеров оптимизации, связанной с ИК, можно найти в этот PDF,
Вывод
Когда вы понимаете компиляторы, вы можете более эффективно работать с языками программирования. Может быть, когда-нибудь вы захотите создать свой собственный язык программирования? Я надеюсь, что это помогло вам.
Ресурсы и дальнейшее чтение
- http://craftinginterpreters.com/ — поможет вам сделать переводчик в C и Java.
- https://norasandler.com/2017/11/29/Write-a-Compiler.html — вероятно, самый полезный для меня учебник по «написанию компилятора».
- Мой компилятор C и парсер научного калькулятора можно найти Вот а также Вот,
- Можно найти пример другого типа парсера, называемого парсером с повышением приоритета. Вот, Предоставлено: Уэсли Норрис.
Источник: machinelearningmastery.ru
0.5 – Введение в компилятор, компоновщик (линкер) и библиотеки
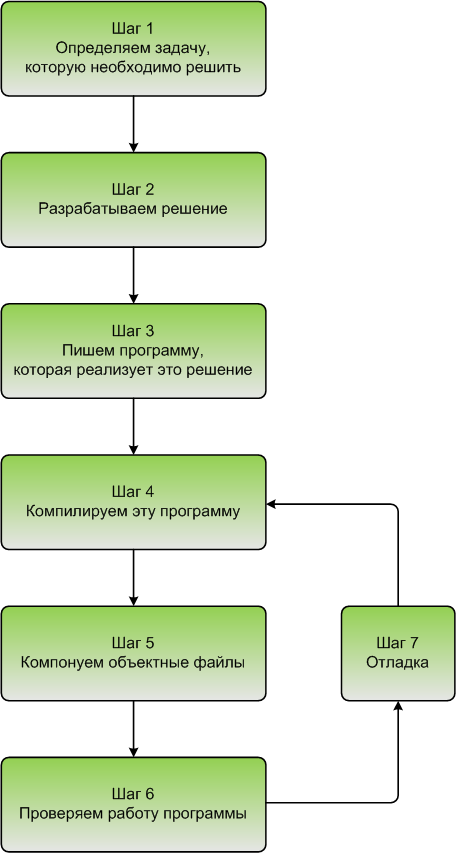
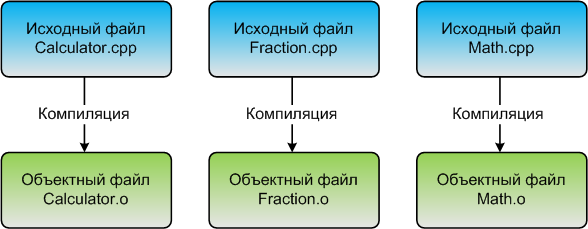
Чтобы скомпилировать программу на C++, мы используем компилятор C++, который последовательно просматривает каждый файл исходного кода ( .cpp ) в вашей программе и выполняет две важные задачи:
Сначала он проверяет ваш код, чтобы убедиться, что он соответствует правилам языка C++. В противном случае компилятор выдаст вам ошибку (и номер соответствующей строки), чтобы помочь точно определить, что нужно исправить. Процесс компиляции будет прерван, пока ошибка не будет исправлена.
Во-вторых, он переводит исходный код C++ в файл машинного кода, называемый объектным файлом. Объектные файлы обычно имеют имена name.o или name.obj , где name совпадает с именем файла .cpp , из которого он был создан.
Если бы в вашей программе было бы 3 файла .cpp , компилятор сгенерировал бы 3 объектных файла:
Компиляторы C++ доступны для многих операционных систем. Мы скоро обсудим установку компилятора, поэтому сейчас нет необходимости останавливаться на этом.
Шаг 5. Компоновка (линковка) объектных файлов и библиотек
После того, как компилятор создал один или несколько объектных файлов, включается другая программа, называемая компоновщиком (линкером). Работа компоновщика состоит из трех частей:
Во-первых, взять все объектные файлы, сгенерированные компилятором, и объединить их в единую исполняемую программу.
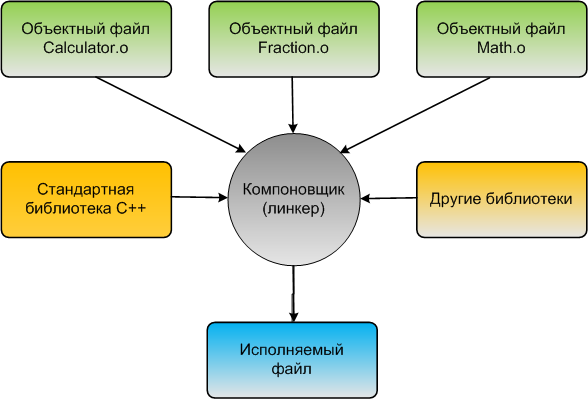
Во-вторых, помимо возможности связывать объектные файлы, компоновщик (линкер) также может связывать файлы библиотек. Файл библиотеки – это набор предварительно скомпилированного кода, который был «упакован» для повторного использования в других программах.
Ядро языка C++ на самом деле довольно небольшое и лаконичное (и вы узнаете многое о нем в последующих статьях). Однако C++ также поставляется с обширной библиотекой, называемой стандартной библиотекой C++ (обычно сокращенно «стандартная библиотека», или STL), которая предоставляет дополнительные функции, которые вы можете использовать в своих программах. Одна из наиболее часто используемых частей стандартной библиотеки C++ – это библиотека iostream , которая содержит функции для печати текста на мониторе и получения от пользователя ввода с клавиатуры. Почти каждая написанная программа на C++ в той или иной форме использует стандартную библиотеку, поэтому она часто подключается к вашим программам. Большинство компоновщиков автоматически подключают стандартную библиотеку, как только вы используете какую-либо ее часть, так что, как правило, вам не о чем беспокоиться.
Вы также можете при желании выполнить линковку с другими библиотеками. Например, если вы собрались написать программу, которая воспроизводит звук, вы, вероятно, не захотите писать свой собственный код для чтения звуковых файлов с диска, проверки их правильности или выяснения, как маршрутизировать звуковые данные к операционной системе или оборудованию для воспроизведения через динамик – это потребует много работы! Вместо этого вы, вероятно, загрузили бы библиотеку, которая уже знала, как это сделать, и использовали бы ее. О том, как связывать библиотеки (и создавать свои собственные!), мы поговорим в приложении.
В-третьих, компоновщик обеспечивает правильное разрешение всех межфайловых зависимостей. Например, если вы определяете что-то в одном файле .cpp , а затем используете это в другом файле .cpp , компоновщик соединит их вместе. Если компоновщик не может связать ссылку с чем-то с ее определением, вы получите ошибку компоновщика, и процесс линковки будет прерван.
Как только компоновщик завершит линковку всех объектных файлов и библиотек (при условии, что всё идет хорошо), вы получите исполняемый файл, который затем можно будет запустить!
Для продвинутых читателей
Для сложных проектов в некоторых средах разработки используется make-файл (makefile), который представляет собой файл, описывающий, как собрать программу (например, какие файлы компилировать и связывать, или обрабатывать какими-либо другими способами). О том, как писать и поддерживать make-файлы, написаны целые книги, и они могут быть невероятно мощным инструментом. Однако, поскольку make-файлы не являются частью ядра языка C++, и вам не нужно их использовать для продолжения изучения, мы не будем обсуждать их в рамках данной серии статей.
Шаги 6 и 7. Тестирование и отладка
Это самое интересное (надеюсь)! Вы можете запустить исполняемый файл и посмотреть, выдаст ли он ожидаемый результат!
Если ваша программа работает, но работает некорректно, то пора немного ее отладить, чтобы выяснить, что не так. Мы обсудим, как тестировать ваши программы и как их отлаживать, более подробно в ближайшее время.
Интегрированные среды разработки (IDE)
Обратите внимание, что шаги 3, 4, 5 и 7 включают в себя использование программного обеспечения (редактор, компилятор, компоновщик, отладчик). Хотя для каждого из этих действий вы можете использовать отдельные программы, программный пакет, известный как интегрированная среда разработки (IDE), объединяет все эти функции вместе. Мы обсудим IDE и установим одну из них в следующем разделе.
Источник: radioprog.ru
Компилятивная программа что это
Дети , подготовьте материал к понедельнику по информатике , выберете любую тему. Сказала Анна Петровна своим ученикам 7го «Б» класса:) Ну как то так Паша!
Avgustin Уровень 25
24 августа 2022
Круто! СПАСИБО.
14 апреля 2022
Кайф, словно подышал свежим воздухом.
Musa Muradzade Уровень 20
2 февраля 2022
javac -d bin/ru/javarush src/ru/javarush/Calculator.java согласно приведённой Вами структуре, при -d bin Calculator.class будет генериться непосредственно в папке bin. Спасибо за статью, интересно))
15 августа 2021
Наиболее доходчиво из всех, что читал. Спасибо!
6 октября 2020
ой как просто удалось разобраться. спасибоо!
3 декабря 2019
Добрый день! У меня не получается выполнить программу. Я в блокноте набираю кода и сохраняю файл с расширением java (Calculator.java).
 В командной строке я перехожу в каталог где лежит файл и запускаю команду javac Calculator.java после чего в каталоге с java файлом создается Calculator.class
В командной строке я перехожу в каталог где лежит файл и запускаю команду javac Calculator.java после чего в каталоге с java файлом создается Calculator.class  после я набираю тут же в командной строке команду java Calculator (пробовал набирать и Calculator.class) но появляется ошибка «could not find or load main class Calculator». Почему ему не найти файл? Он лежит в той же самой папке что и Calculator.java, но ему почему то не найти его, что я делаю не так?
после я набираю тут же в командной строке команду java Calculator (пробовал набирать и Calculator.class) но появляется ошибка «could not find or load main class Calculator». Почему ему не найти файл? Он лежит в той же самой папке что и Calculator.java, но ему почему то не найти его, что я делаю не так? 
Дмитрий Щетинин Уровень 30
8 ноября 2019
«наш любимый языка» — одна буковка лишняя напечаталась. 🙂 Спасибо за статью!
dell Уровень 16
3 ноября 2019
А перевод байт-код а в машинный, это относиться к функции интерпретатора «анализ» или «обработка»?
Игорь Уровень 23
17 июня 2019
«Ускорение работы программы достигается за счет увеличения потребления памяти (где-то же нам нужно хранить скомпилированный машинный код!) и за счет увеличения временных затрат на компиляцию во время исполнения программы. » Может быть за счет уменьшения?
Источник: javarush.com