
[Распознавание рукописного текста] — Пример кода JavaAPI

Распознавание рукописного текста — пример кода JavaAPI
- Сам того не зная, Baidu начал предлагать тестирование распознавания рукописного текста. Друзья, которым это было нужно, пошли подавать заявки. Подайте заявку, чтобы присоединиться к группе распознавания текста, чтобы найти PM. Или подайте заявку на наряд на работу. Вы должны указать свой APPID.
- адрес интерфейса: https://aip.baidubce.com/rest/2.0/ocr/v1/handwriting
- Распознавание рукописного текста — образец кода
Потому что документа еще нет. Не уверен, каковы параметры. По умолчанию передается только параметр изображения. Горизонтальные линии на картинке также будут распознаны.
«log_id»: 8502255431261249697, «words_result_num»: 11, «words_result»: [«location»: «width»: 323, «top»: 20, «left»: 5, «height»: 18>, «words»: «………………….…………………………………………»>, «location»: «width»: 1041, «top»: 25, «left»: 347, «height»: 41>, «words»: «……………………………………………………………………………………………………………………………………………………………………………………………………»>, «location»: «width»: 944, «top»: 159, «left»: 2, «height»: 39>, «words»: «………………………»>, «location»: «width»: 438, «top»: 176, «left»: 981, «height»: 25>, «words»: «…………………………………:*»>, «location»: «width»: 243, «top»: 298, «left»: 2, «height»: 23>, «words»: «………………………………………………………….»>, «location»: «width»: 436, «top»: 309, «left»: 266, «height»: 20>, «words»: «……………………………………»>, «location»: «width»: 729, «top»: 314, «left»: 698, «height»: 23>, «words»: «………………………………………………»>, «location»: «width»: 233, «top»: 588, «left»: 5, «height»: 22>, «words»: «…………»>, «location»: «width»: 692, «top»: 454, «left»: 366, «height»: 198>, «words»: «Разработчик Xiaoshuai»>, «location»: «width»: 398, «top»: 732, «left»: 423, «height»: 15>, «words»: «………………,………………………………………………………………………………»>, «location»: «width»: 596, «top»: 862, «left»: 840, «height»: 19>, «words»: «……………………………………»>]>
- Строка JSON, возвращаемая распознаванием рукописного текста (текстовое содержимое изображения)
«log_id»: 8502255431261250000, «words_result_num»: 11, «words_result»: [ «location»: «width»: 692, «top»: 454, «left»: 366, «height»: 198 >, «words»: «Разработчик Xiaoshuai» > ] >
- Картинка для теста распознавания рукописного текста

Как распознать текст с картинки / уроки Python
Распознавание текста с изображения на Python | EasyOCR vs Tesseract | Компьютерное зрение
Вы обнаружили, что распознавание довольно хорошее? Совершенно точно. Конечно, предполагается, что
В связи с дельной критикой хабрахабровцев, я кардинально переделал пост. Надеюсь, такой вариант будет оценен более положительно.
Я почти два года работаю в компании, которая занимается оцифровкой архивных и библиотечных фондов. Сканирование информации у нас поставлено на поток и в сутки мы получаем десятки тысяч графических образов, которые необходимо распознать и выгрузить заказчику. Моя задача состоит в создании конвейерной технологии для распознавания информации с графических образов.
В этом посте я хочу поделиться полученным опытом и рассказать о технологии распознавания рукописного текста.
Тестирование автоматического распознавания
Печатный текст
ABBYY FineReader является безоговорочным лидером в данном сегменте. Программы распознавания разрабатываются с уклоном на стандартную документацию компаний, которые является основными потребителями софта. Они не рассчитаны на нестандартные форматы, поэтому программы не могут дать уровень достоверности выше 80%.
При обработке библиотечных карточек десяти-двадцатилетней давности, ABBYY FineReader не может дать результат выше 60% достоверности. Смотрите скриншот ниже.
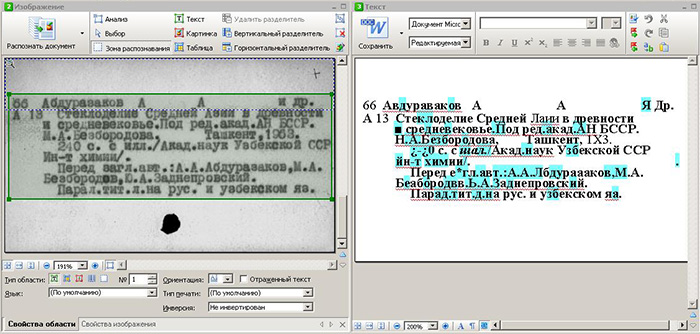
Рукописный текст
У ABBYY FineReader есть версии программы, где, после обучения, она должна распознавать текст. Суть проста – продукт представляет собой пустую нейронную сеть. Пользователю необходимо ее наполнить вручную. Если пользователь пытается распознать несколько почерков, программа не сможет выдать результат. Потратив неделю времени на обучение такого программного решения, в итоге, мы не получили положительный результат.
Применение автоматизированных программ для распознавания рукописного текста на сегодняшний день почти невозможно. Ввод оператором информации с графического образа является единственным способом получения оцифрованной информации. Смотрите скриншот ниже.
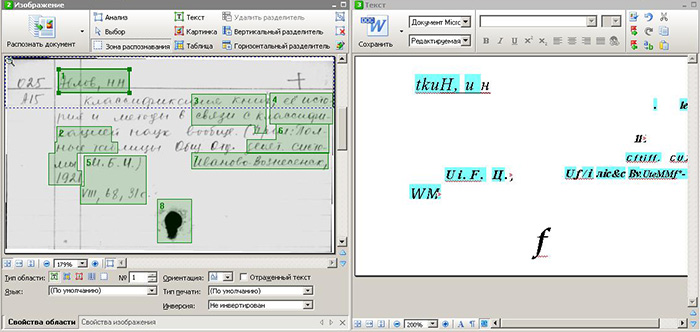
Создание технологии ручного распознавания
Далее пойдет речь о технологии, которую необходимо было создать. Был алгоритм, на реализацию которого ушло полгода. Ниже приведен порядок действий для получения распознанного текста:
- Сканирование – потоковый сканер выполняет сам.
- Разделение массива графических образов по признаку на подкатегории — это и все дальнейшие этапы выполняет человек. Этот этап позволяет повысить КПД ввода.
- Проверка работы сделанной на предыдущем этапе.
- Ввод данных. Вся информация логически разделяется на поля и заполняется частями. Каждый массив данных имеет свою специфику и свои правила ввода:
- если информация конфиденциальная — изображение автоматически режется на части, и каждый оператор получает для ввода только часть информации;
- при большом количестве полей — поля одной карточки делятся между несколькими операторами.
С ростом нагрузки — на сервере стали возникать новые проблемы по оптимальности алгоритмов и скорости их обработки. Пока они решаются локально, но, вполне возможно, скоро придется проводить оптимизацию всей системы.
Весь проект был реализован при поддержке Министерства культуры и туризма Украины, подробнее можно почитать по ссылке.
Кратко о системе
Язык программирования: PHP.
База данных: MySQL.
CMS, Framework: отсутствуют, разработка велась с нуля.
Напоследок
Если этот пост будет принят положительно, я опубликую продолжение и расскажу о том, как построена технология автоматизации библиотек в странах СНГ. Особое внимание я уделю модулю с интересными особенностями, который отвечает за отображение информации в интернете.
- Разработка веб-сайтов
- Алгоритмы
Источник: habr.com
Распознавание рукописного текста. Нейронные сети.Python
В этой статье мы напишем простую нейронную сеть(персептрон) для распознавания рукописного текса. Это скорей практикум по реализации конкретной сети, мы совсем поверхностно коснемся теории. План работы:
Теория.
Совсем без теории конечно не обойтись и начнем мы с нейрона.

Все нейронные сети состоят из нейронов. А если конкретней из математической модели работы настоящего нейрона. Суть этой модели в том что есть много входов ( X ) по которым поступают какие то данные ( например 1 или 0 ). У каждого сигналавхода есть вес (сила сигнала W) . Все эти данные обрабатываются внутри нейрона, так называемая функция активации нейрона f(x) .

Из этих кубиков собираются слои : входной, скрытый , выходной. Собственно на входной слой подаються сигналы, далее они передаться на скрытый слой ( их может быть и несколько) . В скрытом слое происходит сама работа всей сети. Ну и по аналоги со скрытого слоя данные поступают на выходной. На этих выходных данных и строиться результат работы.
Классификация объектов , распознавание или вероятность чего то. Важно помнить, не одна нейронная сеть не дает 100% точности так же как и мозг человека.