
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Switch branches/tags
Branches Tags
Could not load branches
Nothing to show
Could not load tags
Nothing to show
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
- Local
- Codespaces
HTTPS GitHub CLI
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
САМОЕ БЫСТРОЕ РАСПОЗНАВАНИЕ РЕЧИ БЕЗ ИНТЕРНЕТА НА PYTHON
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
f922eb0 Feb 17, 2021
Git stats
Files
Failed to load latest commit information.
Latest commit message
Commit time
September 22, 2019 18:04
May 4, 2020 15:14
September 6, 2020 00:29
September 28, 2019 11:58
September 14, 2019 12:13
February 17, 2021 17:13
February 17, 2021 17:13
September 14, 2019 12:13
February 6, 2020 16:52
May 11, 2020 14:52
README.md
Проект для распознавания речи на русском языке на основе pykaldi.
- Установить kaldi:
- Установить необходимые Python-библиотеки:
$ pip install -r requirements.txt
- Установить pykaldi:
- С помощью conda (с поддержкой GPU):
$ conda install -c pykaldi pykaldi
- С помощью conda (без поддержки GPU):
$ conda install -c pykaldi pykaldi-cpu
- Собрать из исходников (раздел From Source):
- Добавить в PATH пути к компонентам kaldi:
- Склонировать репозиторий проекта:
$ git clone https://github.com/SergeyShk/Speech-to-Text-Russian.git
- Отредактировать файл model/conf/ivector_extractor.conf, указав в нем корректные директории
- Собрать docker-образ:
$ docker build -t speech_recognition:latest .
$ docker pull ghcr.io/sergeyshk/stt-ru:0.2.0
- Создать docker-том для работы с внешними данными:
$ docker volume create -d local -o type=none -o o=bind -o device=[DIR] asr_volume
- Запустить docker-контейнер:
$ docker run -it —rm -p 9000:9000 -p 5000:5000 -v asr_volume:/archive speech_recognition
Файлы проекта расположены в директории /speech_recognition:
- start_recognition.py — скрипт запуска процедуры распознавания;
- /tools — набор инструментов для распознавания:
- data_preparator.py — скрипт подготовки данных для распознавания;
- recognizer.py — скрипт распознавания речи;
- segmenter.py — скрипт сегментации речи;
- transcriptins_parser.py — скрипт парсинга результатов распознавания;
В качестве акустической и языковой модели используется русскоязычная модель от alphacep:
Голосовой ассистент на Python | Голосовое управление компьютером | Распознавание речи Python
При необходимости использования собственной модели, необходимо заменить соответствующие файлы в директории /model.
Внимание! Размер файла HCLG.fst составляет более 500МБ, поэтому для корректного клонирования репозитория необходимо установить на свой компьютер GitHub LFS. Также можно скачать данный файл вручную с соответствующей страницы проекта.
- Подготовить директорию для размещения WAV-файлов;
- Для запуска процедуры распознавания речи выполнить команду:
$ ./start_recognition.py /archive/wav /archive/output -dw -l
- Для запуска режима мониторинга директории выполнить команду:
$ ./start_recognition.py /archive/wav /archive/output -l -t 60 -d 1
Описание параметров запуска доступно по команде:
usage: start_recognition.py [-h] [-rm REC_MODEL] [-rg REC_GRAPH] [-rw REC_WORDS] [-rc REC_CONF] [-ri REC_ICONF] [-sm SEGM_MODEL] [-sc SEGM_CONF] [-sp SEGM_POST] [-p PROCESSES] [-l] [-dw] [-t TIME] [-d DELTA] WAV OUT Запуск процедуры распознавания речи positional arguments: WAV Путь к .WAV файлам аудио OUT Путь к директории с результатами распознавания optional arguments: -h, —help show this help message and exit -rm REC_MODEL, —rec_model REC_MODEL Путь к .MDL файлу модели распознавания -rg REC_GRAPH, —rec_graph REC_GRAPH Путь к .FST файлу общего графа распознавания -rw REC_WORDS, —rec_words REC_WORDS Путь к .TXT файлу текстового корпуса -rc REC_CONF, —rec_conf REC_CONF Путь к .CONF конфигурационному файлу распознавания -ri REC_ICONF, —rec_iconf REC_ICONF Путь к .CONF конфигурационному файлу векторного экстрактора -sm SEGM_MODEL, —segm_model SEGM_MODEL Путь к .RAW файлу модели сегментации -sc SEGM_CONF, —segm_conf SEGM_CONF Путь к .CONF конфигурационному файлу сегментации -sp SEGM_POST, —segm_post SEGM_POST Путь к .VEC файлу апостериорных вероятностей сегментации -p PROCESSES, —processes PROCESSES Количество процессов для обработки файлов -l, —log Логировать результат распознавания -dw, —delete_wav Удалять .WAV файлы после распознавания -t TIME, —time TIME Пауза перед очередным сканированием директории в секундах -d DELTA, —delta DELTA Дельта, выдерживаемая до чтения файла в минутах
- Запустить веб-сервер:
- Перейти по адресу:
- Запустить сервис:
Источник: github.com
Распознавание и анализ речи с помощью библиотеки SPEECH RECOGNITION, PYAUDIO и LIBROSA
В основе систем распознавания речи стоит скрытая марковская модель, суть модели заключается в том, что при рассмотрении сигнала в промежутке небольшой длительности (от пяти до 10 миллисекунд), возможна его аппроксимация как при стационарном процессе.
Если простыми словами скрытую марковскую модель можно объяснить на примере.

Допустим, есть два человека, которые каждый вечер созваниваются и обсуждают свои действия в течение дня. Выбор одного из друзей: ходил за покупками; гулял в парке; занимался домашними делами. При выборе активности, он полагался лишь на погоду. Второй же знал о погоде, которая была на тот момент в месте первого и, основываясь на выборе первого, мог догадаться, какая погода была в какой-то момент.
То есть, допустим, мы делим сигнал на фрагменты скажем в 10 миллисекунд и выделяем кепстральные коэффициенты, которые, по сути, являются графиком зависимости мощности от частоты сигнала отображающегося на векторе действительных чисел. Результатом скрытой марковской модели является последовательность этих векторов.
В последствии мы сопоставляем фонемы и эти векторы, а так как звук фонемы изменяется от источника к источнику, то процесс сопоставления требует обучения.
Для python существует несколько пакетов которые используются в данной сфере речи, такие как apiai, assemblyai и другие, но Speech Recognition выделяется среди них довольно высокой простотой использования.
Библиотека Speech Recognition — это, инструмент для передачи речевых API от компаний (google, microsoft, sound hound, ibm, а также pocketsphinx), который в отличие от остальных имеет возможность работы офлайн.
Для демонстрации работы в данной статье я буду использовать дефолтный Google Speech API.
Также для работы с инструментами потребуется библиотека pyAudio.
Установим библиотеку для распознавания речи:
pip install SpeechRecognition
Для работы с инструментами звукозаписи
pip install pyAudio
Бываю некие сложности с установкой pyaudio через pip, поэтому альтернативный вариант — установка pipwin или conda
Для анализа звуковых данных
pip install librosa
Для работы с wave файлами
pip install wave
и импортируем в код
import speech_recognition as speech_r import pyaudio import wave
Для начала нужно выставить параметры записи звука:
CHUNK = 1024 # определяет форму ауди сигнала FRT = pyaudio.paInt16 # шестнадцатибитный формат задает значение амплитуды CHAN = 1 # канал записи звука RT = 44100 # частота REC_SEC = 5 #длина записи OUTPUT = «output.wav»
Далее нужно создать объект для обращения к устройству звукозаписи:
p = pyaudio.PyAudio()
и открыть поток для записи звука:
stream = p.open(format=FRT,channels=CHAN,rate=RT,input=True,frames_per_buffer=CHUNK) # открываем поток для записи print(«rec») frames = [] # формируем выборку данных фреймов for i in range(0, int(RT / CHUNK * REC_SEC)): data = stream.read(CHUNK) frames.append(data) print(«done») и закрываем поток stream.stop_stream() # останавливаем и закрываем поток stream.close() p.terminate()
Дальше нам нужно записать оцифрованную звуковую дорожку в файл.
Для этого нам и пригодится библиотека wave:
w = wave.open(OUTPUT, ‘wb’) w.setnchannels(CHAN) w.setsampwidth(p.get_sample_size(FRT)) w.setframerate(RT) w.writeframes(b».join(frames)) w.close()
В итоге мы получаем готовую звуковую дорожку записанную с микрофона устройства и готовую к распознаванию для этого нам потребуется библиотека Speech Recognition:
sample = speech_r.WavFile(‘C:\Users\User\Desktop\1\pythonProject\output.wav’)
Непосредственно для распознавания текста нам потребуется класс Recognizer он имеет множество функций, а также определяет каким API мы будем пользоваться:
r = speech_r.Recognizer()
Открываем записанный файл.
Для расшифровки сигнала мы будем использовать метод recognize_google().
Для использования данного метода необходим объект AudioData и для дальнейшей работы требуется преобразовать сигнал в объект модуля Speech_recognition для этого существует метод record():
with sample as audio: content = r.record(audio)
но, перед тем как передать сигнал на расшифровку, нужно очистить его от шумов. У библиотеки speech_recognition есть для этого метод adjust_for_ambient_noise()
with sample as audio: content = r.record(audio) r.adjust_for_ambient_noise(audio)
Так как выбранный нами Api поддерживает русский язык мы можем им воспользоваться:
print(r.recognize_google(audio, language=»ru-RU»))
Распознаватель возвращает: «Привет»
Таким образом у нас получается небольшой распознаватель речи буквально в пару строк кода. В момент, когда речь прекращается он автоматически переводит ее в текст.
Далее можно приступить к получению аналитических данных с помощью библиотеки librosa. Для начала загружаем наш файл:
A_Data = ‘C:\Users\User\Desktop\1\pythonProject\output.wav’ y , sf = librosa.load(A_Data)
в данном случае мы получаем значения временного ряда звука в качестве массива с частотой дискретизации.
Далее мы можем вернуть график массива нашей звуковой дорожки. Для работы с графиком импортируем pyplot из библиотеки matplotlib и используем librosa.display.waveplot() для построения графика массива:
import matplotlib.pyplot as plt import librosa.display plt.figure(figsize=(14, 5)) librosa.display.waveplot(y, sr=sf)

В самом начале я упоминал про кепстральные коэффициенты, они обычно используются для определения тембральных аспектов музыкального инструмента или голоса и мы можем построить их тепловую карту и хроматограмму.
fcc = librosa.feature.mfcc(y=y, sr=sf, hop_length=8192, n_mfcc=12) import seaborn as sns from matplotlib import pyplot as plt fcc_delta = librosa.feature.delta(fcc) sns.heatmap(fcc_delta) plt.show()
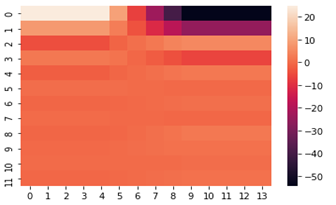
chromo = librosa.feature.chroma_cqt(y=y, sr=sf) sns.heatmap(chromo) plt.show()
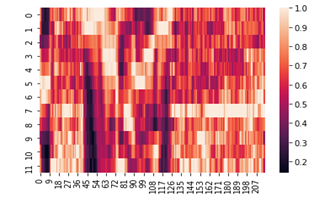
Надеюсь, что данный материал будет полезен при решении задач по распознаванию речи.
Источник: habr.com