
Вычислительный кластер
Вычислительный кластер – это набор соединенных между собой компьютеров (серверов), которые работают вместе и могут рассматриваться как единая система. В отличие от грид-вычислений, все узлы компьютерного кластера выполняют одну и ту же задачу и управляются одной системой управления.
Серверы кластера обычно соединяются между собой по быстродействующей локальной сети, причем на каждом из серверов работает собственный экземпляр операционной системы. В большинстве случаев все вычислительные узлы кластера используют одинаковое оборудование и одну и ту же операционную систему. Однако в некоторых инсталляциях, например, с использованием платформы приложений для организации кластеров OSCAR (Open Source Cluster Application Resources), могут использоваться различные операционные системы или разное серверное оборудование.
Кластеры обычно развертываются для большей производительности и доступности, чем то, что можно получить от одного компьютера, пусть даже очень мощного. Часто такое решение более экономично, чем отдельные компьютеры.
Кластерный Анализ Рынка. Два разных взгляда на одну ситуацию.
Компоненты кластера
Вычислительные кластеры обычно состоят из следующих компонентов:
- узел доступа;
- вычислительные узлы;
- файловый сервер;
- файловая или объектная СХД с общим доступом;
- локальная сеть LAN.

Виды кластеров
Различают следующие основные виды кластеров:
- кластеры высокой доступности (High-availability clusters, HA);
- кластеры с балансировкой нагрузки (Load balancing clusters);
- высокопроизводительные кластеры (High performance computing clusters, HPC).
Кластеры высокой доступности
Кластеры высокой доступности НА (high-availability cluster) известны также как отказоустойчивые (failover) кластеры, построенные по схеме сети с большой избыточностью (redundancy). Они применяются для критических серверных приложений, например сервера баз данных. Компьютерный кластер может называться НА-кластером, если он обеспечивает доступность приложений не менее, чем «пять девяток», т. е. приложение должно быть доступно (uptime) в течение 99,999 % времени за год.
Чрезвычайно высокая доступность в НА-кластерах достигается за счет использования специального программного обеспечения и аппаратных решений со схемами обнаружения отказов, а также благодаря работе по подготовке к отказам.
ПО для НА-кластеров обычно заблаговременно конфигурирует узел на резервном сервере и запускает на нем приложение в фоновом режиме так, чтобы основной экземпляр приложения мог немедленно переключиться на свою реплику на резервном компьютере при отказе основного.
НА-кластеры обычно используются для терминальных серверов, серверов баз данных, почтовых серверов, а также для серверов общего доступа к файлам. Они могут быть развернуты как на одном местоположении («серверной ферме»), так и в географически разнесенных местоположениях.
Кластерный анализ. Подробная инструкция с примерами
Но не следует думать, что технология кластера высокой доступности, или вообще кластеризация, могут служить заменой резервному копированию (backup), а также решениям катастрофоустойчивости (disaster recovery).
Кластеры с балансировкой нагрузки
Балансировка нагрузки – это эффективное распределение входящего сетевого трафика в группе (кластере) серверов.
Современные веб-сайты должны одновременно обслуживать сотни тысяч и даже миллионы запросов от пользователей или клиентов и не слишком задерживать их в получении контента: текста, видео или данных приложений. Чем больше серверов будут обслуживать эти запросы, тем лучше будет качество воспринимаемого сервиса для клиентов. Однако может возникнуть ситуация, когда одни серверы сайта будут работать с перегрузкой, а другие будут почти простаивать.
Балансировщик нагрузки направляет запросы клиентов равномерно на все серверы кластера, которые способны ответить на те или иные запросы. Таким образом, балансировщик максимизирует процент использования вычислительной емкости, а также обеспечивает то, что ни один сервер не оказывается перегруженным, вызывая общую деградацию производительности кластера.
Если какой-то сервер отказывает, то балансировщик перенаправляет трафик на оставшиеся серверы. Когда новый сервер добавляется к группе (кластеру), то балансировщик автоматически перераспределяет нагрузку на всех серверах с учетом вновь вступившего в работу.
Таким образом, балансировщик нагрузки выполняет следующие функции:
- Распределяет запросы клиентов и нагрузку сети эффективным образом в во всем кластере серверов.
- Обеспечивает высокую доступность и надежность посылкой запросов только на те серверы, которые находятся в режиме онлайн.
- Обеспечивает гибкость, добавляя или удаляя серверы по мере надобности.

Работа балансировщика нагрузки
Алгоритмы балансировки нагрузки
Различные алгоритмы балансировки предназначены для разных целей и достижения разных выгод. Можно назвать следующие алгоритмы балансировки:
- Round Robin – запросы распределяются по кластеру серверов последовательно.
- Least Connections – новый запрос посылается на сервер с наименьшим числом подключений клиентов, однако при этом учитывается и вычислительная мощность каждого сервера.
- Least Time – запросы посылаются на сервер, выбираемый по формуле, которая комбинирует быстроту ответа и наименьшее число активных запросов.
- Hash – распределяет запросы на основании определяемого пользователем ключа, например, IP-адреса клиента или URL запрашиваемого сайта.
- Random with Two Choices – выбираются два сервера по методу произвольного выбора и затем запрос посылается на один из них, который выбирается по критерию наименьшего числа подключений.
Программная и аппаратная балансировка нагрузки
Балансировщики нагрузки бывают двух типов: программные и аппаратные. Программные балансировщики можно установить на любой сервер достаточной для задачи емкости. Поставщики аппаратных балансировщиков просто загружают соответствующее программное обеспечение балансировки нагрузки на серверы со специализированными процессорами. Программные балансировщики менее дорогие и более гибкие. Можно также использовать облачные решения сервисов балансировки нагрузки, такие как AWS EC2.
Высокопроизводительные кластеры (HPC)
Высокопроизводительные вычисления HPC (High-performance computing) – это способность обрабатывать данные и выполнять сложные расчеты с высокой скоростью. Это понятие весьма относительное. Например, обычный лэптоп с тактовой частотой процессора в 3 ГГц может производить 3 миллиарда вычислений в секунду. Для обычного человека это очень большая скорость вычислений, однако она меркнет перед решениями HPC, которые могут выполнять квадриллионы вычислений в секунду.
Одно из наиболее известных решений HPC – это суперкомпьютер. Он содержит тысячи вычислительных узлов, которые работают вместе над одной или несколькими задачами, что называется параллельными вычислениями.
HPC очень важны для прогресса в научных, промышленных и общественных областях.
Такие технологии, как интернет вещей IoT (Internet of Things), искусственный интеллект AI (artificial intelligence), и аддитивное производство (3D imaging), требуют значительных объемов обработки данных, которые экспоненциально растут со временем. Для таких приложений, как живой стриминг спортивных событий в высоком разрешении, отслеживание зарождающихся тайфунов, тестирование новых продуктов, анализ финансовых рынков, – способность быстро обрабатывать большие объемы данных является критической.
Чтобы создать HPC-кластер, необходимо объединить много мощных компьютеров при помощи высокоскоростной сети с широкой полосой пропускания. В этом кластере на многих узлах одновременно работают приложения и алгоритмы, быстро выполняющие различные задачи.
Чтобы поддерживать высокую скорость вычислений, каждый компонент сети должен работать синхронно с другими. Например, компонент системы хранения должен быть способен записывать и извлекать данные так, чтобы не задерживать вычислительный узел. Точно так же и сеть должна быстро передавать данные между компонентами НРС-кластера. Если один компонент будет подтормаживать, он снизит производительность работы всего кластера.
Существует много технических решений построения НРС-кластера для тех или иных приложений. Однако типовая архитектура НРС-кластера выглядит примерно так, как показано на рисунке ниже.

Примеры реализации вычислительного кластера
В лаборатории вычислительного интеллекта создан вычислительный кластер для решения сложных задач анализа данных, моделирования и оптимизации процессов и систем.
Кластер представляет собой сеть из 11 машин с распределенной файловой системой NFS. Общее число ядер CPU в кластере – 61, из них высокопроизводительных – 48. Максимальное число параллельных высокоуровневых задач (потоков) – 109. Общее число ядер графического процессора CUDA GPU – 1920 (NVidia GTX 1070 DDR5 8Gb).
На оборудовании кластера успешно решены задачи анализа больших данных (Big Data): задача распознавания сигнала от процессов рождения суперсимметричных частиц, задача классификации кристаллических структур по данным порошковой дифракции, задача распределения нагрузки электросетей путем определения выработки электроэнергии тепловыми и гидроэлектростанциями с целью минимизации расходов, задача поиска оптимального расположения массива кольцевых антенн и другие задачи.

Архитектура вычислительного кластера
Другой вычислительный НРС-кластер дает возможность выполнять расчеты в любой области физики и проводить многодисциплинарные исследования.

Графические результаты расчета реактивного двигателя, полученные на НРС-клатере (источник: БГТУ «ВОЕНМЕХ»)
На рисунке показана визуализация результатов расчета реактивного двигателя, зависимость скорости расчетов и эффективности вычислений от количества ядер процессора.
Вам может быть интересно:
Источник: itelon.ru
Кластерный анализ в трейдинге — основы, паттерны и программы

Как говорил великий трейдер — объем это единственный индикатор в вашем терминале, который действительно помогает торговать в профит. Это действительно так, умение работать с объемами поможет вам уверенно действовать и в скапельперских сделках и в среднесрочных и в долгосрочных. Но в последнее время стал популярен кластерный анализ, который основан именно на объемах. В этой статье мы рассмотрим, как использовать кластерный анализ в трейдинге и какие плюсы от этого вы сможете получить.
Что такое кластерный анализ
Кластерный анализ — это, по сути, профиль объема для каждой свечи графика на выбранном таймфрейме. Т.е. с помощью кластерного анализа вы можете заглянуть внутрь свечи и увидеть на каком уровне цены, какой объем контрактов был проторгован.
Кластер представляет собой уровень в свече, который отображает объем проторгованных контрактов, либо дельту, смотря, что вы выбираете в настройках программы.
Какую информацию открывает кластерный анализ
С помощью кластеров вы можете узнать следующее:
- Объем проторгованных контрактов по каждому уровню цены внутри свечи графика.
- Объем сделок по Ask — цене продавцов.
- Объем сделок по Bid — цене покупателей.
- Дельту — разницу объемов покупателей и продавцов.
- Общий объем все проторгованных контрактов.
- Рыночный профиль.
Логика кластерного анализа
Поскольку вы видите точные размеры проторгованных объемов на каждом ценовом уровне, то вы можете применять эту информацию следующим образом:
- Строить объемные уровни поддержки и сопротивления. Т.е. находить на графике скопления больших объемов и строить на их основе уровни, поскольку в будущем цена обязательно будет на них реагировать.
- Понимать, кто в данный момент преобладает на рынке — покупатель или продавец. Вы можете использовать дельту, чтобы понять, в какую сторону в данный момент может двинуться рынок с большей долей вероятности.
Плюс к этому вы должны понимать, что рынок толкает рыночный ордер, а останавливает движение лимитный ордер. Все крупные игроки всегда входят в рынок с помощью лимитных заявок, при этом движение или тренд останавливается, а то и во все разворачивается. Поскольку рыночный ордер не в силах выкупить все лимитные заявки.
Основные типы баров
Это довольно важная информация, поскольку на ней строятся торговые системы для кластерного анализа, поэтому рассмотрим здесь основные типы баров.
В зависимости от того, где в свече (баре) расположен максимальный объем, бары делятся на:
Толкающие бары — своего рода создатели движения, т.к. они толкают цену, а тормозящие, как уже понятно наоборот тормозят и разворачивают цену.
Что было более понятно, я подобрал изображения этих баров.




В общем контексте рынка это выглядит так:

Как использовать кластерный анализ в торговле
Сейчас я вам покажу простейшую стратегию.
Для этого находим на графике флетовую проторговку, натягиваем на нее профиль объема. Это поможет нам определить, где именно в этой проторговке сосредоточен максимальный объем.

На скриншоте это отчётливо видно, это красная полоса, в которой проторговали 1758 контрактов. Это так называем уровень POC.
Далее ожидаем, когда мы выйдем из этого флета. И после того, как выйдем, мы обязательно подойдем к уровню, где сосредоточен максимальный объем.
В 80% случаев мы получаем от этого уровню реакцию в виде отскока. Так вот, при касании этого уровня мы можем входить в сделку. Ставим стоп-лосс за вершиной проторговки.
Точно таким же образом можно работать не только на форексе, но и на бинарных опционах. Мы заключаем ставку, на отскок от уровня.
Как видите довольно простая стратегия и очень эффективная, попробуйте сами.
Дельта в кластерном анализе
Помимо объема, кластера могу показывать нам и дельту. Это разница между проторгованными объемами продавцов и покупателей.
Дельта = ASK — BID

Если дельта положительная, это значит что покупателей больше, чем продавцов, если дельта отрицательная, то на оборот — продавцов больше, чем покупателей на данном ценовом уровне.
Трейдеры разделяют несколько видов дельты:
- Умеренная (возникает, как правило, во флете, примерно одинаковое количество покупателей и продавцов, так называем баланс).
- Нормальная (это обычно трендовая фаза, где видно сильно преобладание какой либо стороны).
- Критическая (разворот и зарождение нового тренда).
Программы для кластерного графика
Представляю вам самые популярные программы для кластерного анализа на данный момент:
1) SBPro

Кластеры
Кластерные графики для отображения объемов, дельты и Bid-Ask.
Симулятор
Тестирование стратегий на истории.
Лента сделок
Лента сделок прямо на графике! Гибкая аккумуляция принтов.
Профили
Множество типов Profile графиков с фильтрацией по объему и дельте.
2) ATAS

Smart Tape
“Умная Лента Принтов” агрегирует и фильтрует рыночные сделки, что позволит Вам увидеть реальных крупных игроков рынка.
Графики
6 видов построения графиков, в том числе профильные и кластерные графики (25 вариантов футпринта).
Smart DOM
“Умный Стакан” позволит проводить анализ биржевой ликвидности и отслеживать заявки крупных игроков.
Торговля
Удобная торговля и управление позициями, как через торговый стакан, так и прямо с графика (Chart Trader).
3) Volfix

Многоуровневая система алертов.
Широкий набор инструментов для объемного и профильного анализа.
Интегрированный DOM Analyzer можно адаптировать под любые Ваши торговые идеи.
Более семи лет исторических данных — цена, Tick , Trade и Bid https://skillblog.ru/trejding-i-investirovanie/klasternyj-analiz-v-trejdinge-osnovy-patterny-i-programmy.html» target=»_blank»]skillblog.ru[/mask_link]
Кластерная программа что это

Теперь предположим, что мы знаем, что эти данные разбиваются на 3, относительно очевидные, категории и выглядеть это будет так:

Наша задача – использовать алгоритм кластеризации K-means, чтобы произвести эту категоризацию.
Шаг 1: Выбираем число кластеров, k
Число кластеров, которые мы хотим распознать, это и есть k в K-means. В нашем случае, так как мы предположили, что всего 3 кластера, k = 3.
Шаг 2: Выбираем k случайных значений
Процесс обнаружения кластеров мы начинаем с выбора 3 случайно выбранных значений (не обязательно, чтобы они были нашими данными). Эти точки будут сейчас работать как центроиды или центры кластеров, которые мы собираемся сгруппировать:
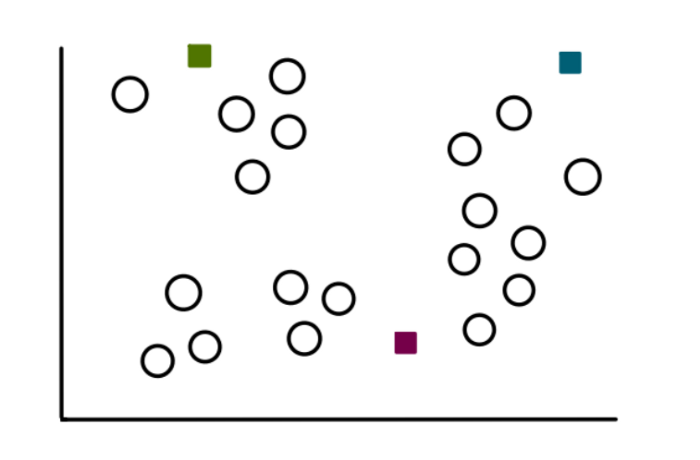
Шаг 3: Создать k кластеров
Чтобы создать кластеры, мы начнем измерять расстояние между каждым значением наших данных до каждого из трех центроидов, а затем добавляем его к наиболее близкому кластеру. Для значения, взятого в качестве примера, расстояния будут выглядеть примерно так:
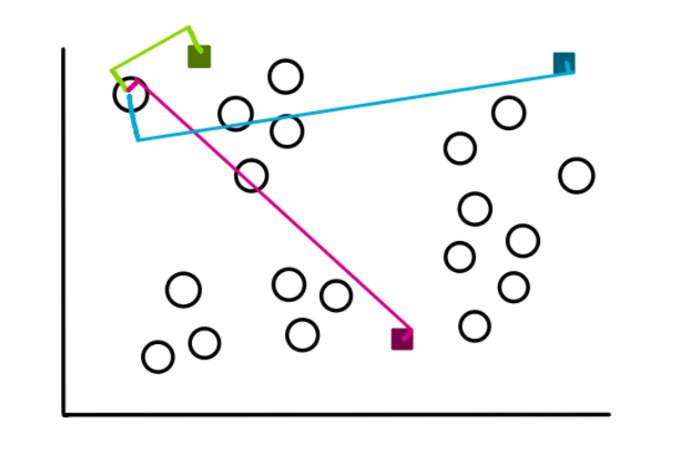
Смотря на рисунок, мы понимаем, что расстояние от значения до зеленого центроида наименьшее, поэтому мы и добавляем значение в зеленый кластер.
В 2-мерном пространстве для нахождения расстояния между двумя точками используется формула:
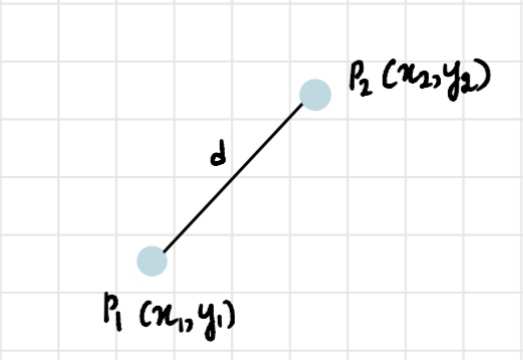
d = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2
Используя эту формулу, мы повторяем процесс с оставшимися значениями, после этого кластеры будут выглядеть следующим образом:

Больше полезных материалов вы найдете на нашем телеграм-канале «Библиотека программиста»
Шаг 4: Вычисляем новый центроид каждого кластера
Теперь, когда у нас есть все три кластера, мы находим новые центроиды для каждого из них. Например, ниже изображена формула для нахождения координат синего кластера:
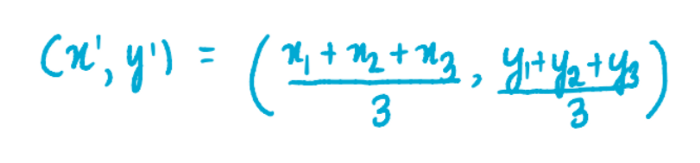
где x1, x2 и x3 – это координаты по оси x каждого из трех значений синего кластера, а y1, y2 и y3 – координаты соответствующих точек по оси y. Мы разделили сумму координат на 3, потому что 3 значения содержится в кластере. Аналогично, координаты центроид розового и зеленого кластеров будут равны:
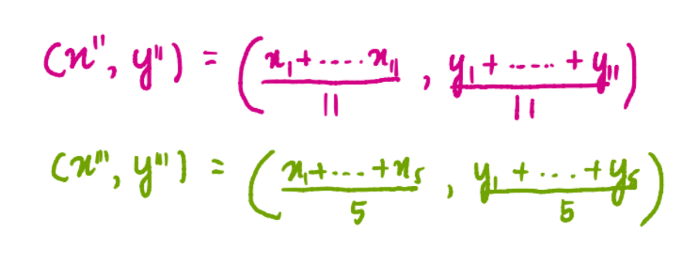
Так, новые центроиды будут иметь вид:

Шаг 5: Оценить качество каждого кластера
Так как k-means не может видеть кластеры так, как это делаем мы, он измеряет качество, находя среднее отклонение внутри всех кластеров. Основная идея, лежащая в основе k-means, заключается в определении таких кластеров, что отклонения внутри каждого кластера минимальны. Чтобы оценить отклонение, мы вычислим такую величину, как WCSS ( within-cluster sum of squares ) – cумму квадратов внутрикластерных расстояний до центра кластера.
WCSS = ∑ C k C n ( ∑ d i i n C i d m distance ( d i , C k ) 2 )
Где С – это кластерные центроиды, а d – значения данных в каждом кластере
Но в целях упрощения, давайте представим, что отклонение визуально выглядит так:

Шаг 6: повторяем шаги 3-5
Итак, мы получили кластеры и отклонение, и … Мы начинаем все сначала.
Но теперь мы используем центроиды, которые были вычислены ранее, чтобы создать 3 новых кластера, пересчитать центры новых кластеров и вычислить сумму расстояний внутри каждого кластера.
Давайте предположим, что следующие 4 итерации будут выглядеть так:
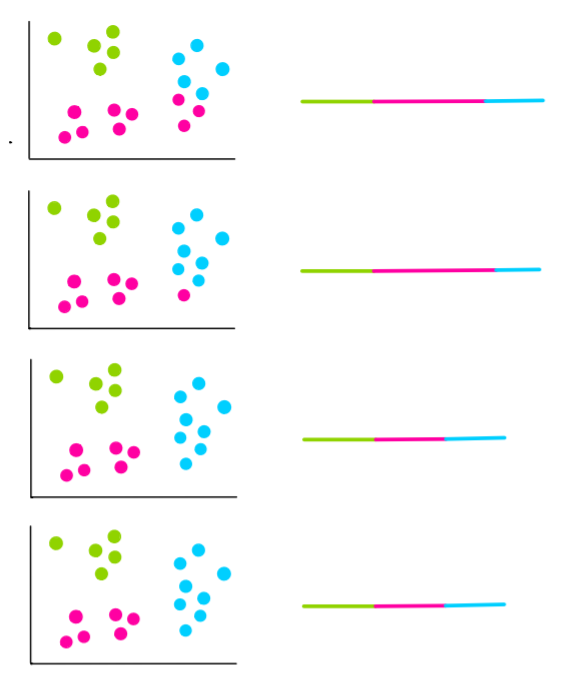
На двух последних итерациях мы видим, что кластеры не меняются. Это значит, что алгоритм сошелся и мы останавливаем процесс. Затем мы выбираем кластеры с наименьшим WCSS. Это будут кластеры на последних 2 итерациях, поэтому они и становятся нашими финальными кластерами.
Как выбирать k?
В нашем примере мы знали, что нам нужно 3 кластера. Но что, если мы не знаем, какое количество кластеров мы имеем, тогда как нам выбрать k?
В этом случае мы пытаемся использовать различные значения k и считать WCSS.


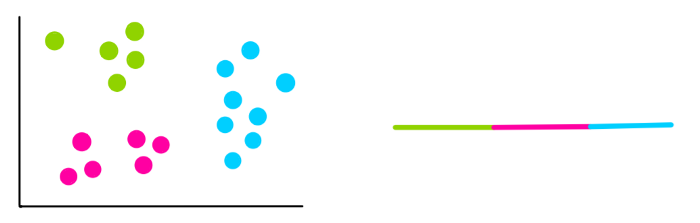
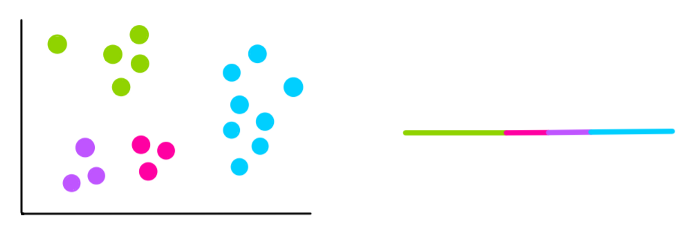
Вы можете заметить, что каждый раз, когда мы добавляем новый кластер, общее отклонение внутри каждого кластера становится все меньше и меньше. В конце настанет случай, когда на каждое значение данных будет приходиться отдельный кластер, и тогда отклонение будет равно 0.
Нам нужно использовать подход, называемый «метод локтя», чтобы найти наилучшее значение k. Для этого мы строим график зависимости WCSS от количества кластеров, или k.
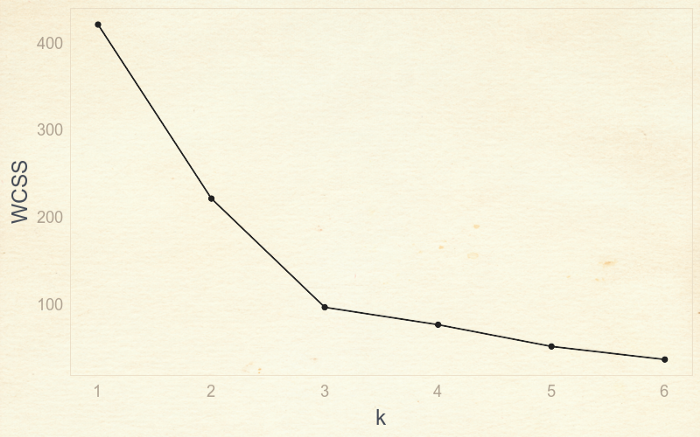
Подход называется «метод локтя», потому что мы можем найти оптимальное значение k, когда найдем «согнутый локоть» графика, что находится в точке с k=3. Вы можете заметить, что до 3 наблюдается быстрое уменьшение отклонения, но потом отклонение перестает падать также быстро.
Что ж, а на этом все. Вот такой он, k-means – простой, но эффективный алгоритм кластеризации! Подведем краткий итог. Сегодня из этой статьи мы узнали, что же такое k-means, как он работает при решении задач кластеризации, а также как находить количество кластеров, когда это неизвестно. Надеюсь, что статья вам понравилось.
До новых встреч.
Мне нужно оперативно освоить алгоритмы и структуры данных. Что делать?
Если хотите подтянуть или освежить знания по алгоритмам и структурам данных, загляните на наш курс «Алгоритмы и структуры данных», на котором вы:
- углубитесь в решение практических задач;
- научитесь применять алгоритмы и структуры данных при разработке программ;
- изучите сленг, на котором говорят все разработчики независимо от языка программирования: язык алгоритмов и структур данных;
- узнаете все про сложные алгоритмы, сортировки, сжатие данных и многое другое.
Вы также будете на связи с преподавателем и другими студентами. В итоге будете браться за сложные проекты и повысите чек за свою работу. Курс подходит как junior, так и middle-разработчикам.
Источники
Источник: proglib.io
PARALLEL.RU — Информационно-аналитический центр по параллельным вычислениям
Для начинающих пользователей вычислительных кластеров
Данная страница написана с таким расчетом, чтобы она могла быть полезной не только пользователям вычислительных кластеров НИВЦ, но и всем, желающим получить представление о работе вычислительного кластера. Решение типичных проблем пользователей кластера НИВЦ изложено на отдельной странице.
Что такое вычислительный кластер?
В общем случае, вычислительный кластер — это набор компьютеров (вычислительных узлов), объединенных некоторой коммуникационной сетью. Каждый вычислительный узел имеет свою оперативную память и работает под управлением своей операционной системы. Наиболее распространенным является использование однородных кластеров, то есть таких, где все узлы абсолютно одинаковы по своей архитектуре и производительности.
Подробнее о том, как устроен и работает вычислительный кластер можно почитать в книге А.Лациса «Как построить и использовать суперкомпьютер».
Как запускаются программы на кластере?
Для каждого кластера имеется выделенный компьютер — головная машина (front-end). На этой машине установлено программное обеспечение, которое управляет запуском программ на кластере. Собственно вычислительные процессы пользователей запускаются на вычислительных узлах, причем они распределяются так, что на каждый процессор приходится не более одного вычислительного процесса. Запускать вычислительные процессы на головной машине кластера нельзя.
Пользователи имеют терминальный доступ на головную машину кластера, а входить на узлы кластера для них нет необходимости. Запуск программ на кластере осуществляется в т.н. «пакетном» режиме — это значит, что пользователь не имеет непосредственного, «интерактивного» взаимодействия с программой, программа не может ожидать ввода данных с клавиатуры и выводить непосредственно на экран. Более того, программа пользователя может работать тогда, когда пользователь не подключен к кластеру.
Какая установлена операционная система?
Вычислительный кластер, как правило, работает под управлением одной из разновидностей ОС Unix — многопользовательской многозадачной сетевой операционной системы. В частности, в НИВЦ МГУ кластеры работают под управлением ОС Linux — свободно распространяемого варианта Unix. Unix имеет ряд отличий от Windows, которая обычно работает на персональных компьютерах, в частности эти отличие касаются интерфейса с пользователем, работы с процессами и файловой системы.
Более подробно об особенностях и командах ОС UNIX можно почитать здесь:
- Инсталляция Linux и первые шаги (книга Matt Welsh, перевод на русский язык А.Соловьева).
- Учебник по Unix для начинающих.
- Энциклопедия Linux.
- Операционная система UNIX (информационно-аналитические материалы на сервере CIT-Forum).
Как хранятся данные пользователей?
Все узлы кластера имеют доступ к общей файловой системе, находящейся на файл-сервере. То есть файл может быть создан, напрмер, на головной машине или на каком-то узле, а затем прочитан под тем же именем на другом узле. Запись в один файл одновременно с разных узлов невозможна, но запись в разные файлы возможна.
Кроме общей файловой системы, могут быть локальные диски на узлах кластера. Они могут использоваться программами для хранения временных файлов. После окончания (точнее, непосредственно перед завершением) работы программы эти файлы должны удаляться.
Какие используются компиляторы?
Никаких специализированных параллельных компиляторов для кластеров не существует. Используются обычные оптимизирующие компиляторы с языков Си и Фортран — GNU, Intel или другие, умеющие создавать исполняемые программы ОС Linux. Как правило, для компиляции параллельных MPI-программ используются специальные скрипты (mpicc, mpif77, mpif90 и др.), которые являются надстройками над имеющимися компиляторами и позволяют подключать необходимые библиотеки.
Как использовать возможности кластера?
Существует несколько способов задействовать вычислительные мощности кластера.
1. Запускать множество однопроцессорных задач. Это может быть разумным вариантом, если нужно провести множество независимых вычислительных экспериментов с разными входными данными, причем срок проведения каждого отдельного расчета не имеет значения, а все данные размещаются в объеме памяти, доступном одному процессу.
2. Запускать готовые параллельные программы. Для некоторых задач доступны бесплатные или коммерческие параллельные программы, которые при необходимости Вы можете использовать на кластере. Как правило, для этого достаточно, чтобы программа была доступна в исходных текстах, реализована с использованием интерфейса MPI на языках С/C++ или Фортран. Примеры свободно распространяемых параллельных программ, реализованных с помощью MPI: GAMESS-US (квантовая химия), POVRay-MPI (трассировка лучей).
3. Вызывать в своих программах параллельные библиотеки. Также для некоторых областей, таких как линейная алгебра, доступны библиотеки, которые позволяют решать широкий круг стандартных подзадач с использованием возможностей параллельной обработки.
Если обращение к таким подзадачам составляет большую часть вычислительных операций программы, то использование такой параллельной библиотеки позволит получить параллельную программу практически без написания собственного параллельного кода. Примером такой библиотеки является SCALAPACK. Русскоязычное руководство по использованию этой библиотеки и примеры можно найти на сервере по численному анализу НИВЦ МГУ. Также доступна параллельная библиотека FFTW для вычисления быстрых преобразований Фурье (БПФ). Информацию о других параллельных библиотеках и программах, реализованных с помощью MPI, можно найти по адресу http://www-unix.mcs.anl.gov/mpi/libraries.html.
4. Создавать собственные параллельные программы. Это наиболее трудоемкий, но и наиболее универсальный способ. Существует два основных варианта. 1) Вставлять параллельные конструкции в имеющиеся параллельные программы. 2) Создавать «с нуля» параллельную программу.
Как работают параллельные программы на кластере?
Параллельные программы на вычислительном кластере работают в модели передачи сообщений (message passing). Это значит, что программа состоит из множества процессов, каждый из которых работает на своем процессоре и имеет свое адресное пространство.
Причем непосредственный доступ к памяти другого процесса невозможен, а обмен данными между процессами происходит с помощью операций приема и посылки сообщений. То есть процесс, который должен получить данные, вызывает операцию Receive (принять сообщение), и указывает, от какого именно процесса он должен получить данные, а процесс, который должен передать данные другому, вызывает операцию Send (послать сообщение) и указывает, какому именно процессу нужно передать эти данные. Эта модель реализована с помощью стандартного интерфейса MPI. Существует несколько реализаций MPI, в том числе бесплатные и коммерческие, переносимые и ориентированные на конкретную коммуникационную сеть.
Как правило, MPI-программы построены по модели SPMD (одна программа — много данных), то есть для всех процессов имеется только один код программы, а различные процессы хранят различные данные и выполняют свои действия в зависимости от порядкового номера процесса.
Более подробно об MPI можно почитать здесь:
- Курс Вл.В.Воеводина «Параллельная обработка данных». Лекция 5. Технологии параллельного программирования. Message Passing Interface.
- Вычислительный практикум по технологии MPI (А.С.Антонов).
- А.С.Антонов «Параллельное программирование с использованием технологии MPI».
- MPI: The Complete Reference (на англ.яз.).
- Глава 8: Message Passing Interface в книге Яна Фостера «Designing and Building Parallel Programs» (на англ.яз.).
Где можно посмотреть примеры параллельных программ?
Схематичные примеры MPI-программ можно посмотреть здесь:
- Курс Вл.В.Воеводина «Параллельная обработка данных». Приложение к лекции 5.
- Примеры из пособия А.С.Антонова «Параллельное программирование с использованием технологии MPI».
Примеры простейших работающих MPI-программ доступны в составе пакета MPICH, свободно распространяемой реализации MPI. Для пользователей НИВЦ МГУ простейшие примеры MPI-программ на Си и Фортране доступны в директории /home/examples/mpi. Примеры использования конструкций MPI в программах на языке Си можно посмотреть в тестах производительности для параллельных компьютеров. Примеры программ на Фортране с комментариями можно посмотреть в англоязычном документе «MPI User’s Guide in Fortran» (формат Word).
Можно ли отлаживать параллельные программы на персональном компьютере?
Разработка MPI-программ и проверка функциональности возможна на обычном ПК. Можно запускать несколько MPI-процессов на однопроцессорном компьютере и таким образом проверять работоспособность программы. Желательно, чтобы это был ПК с ОС Linux, где можно установить пакет MPICH. Это возможно и на компьютере с Windows, но более затруднительно.
Насколько трудоемко программировать вычислительные алгоритмы c помощью MPI и есть ли альтернативы?
Набор функций интерфейса MPI иногда называют «параллельным ассемблером», т.к. это система программирования относительно низкого уровня. Для начинающего пользователя-вычислителя может быть достаточно трудоемкой работой запрограммировать сложный параллельный алгоритм с помощью MPI и отладить MPI-программу. Существуют и более высокоуровневые системы программирования, в частности российские разработки — DVM и НОРМА, которые позволяют пользователю записать задачу в понятных для него терминах, а на выходе создают код с использованием MPI, и поэтому могут быть использованы практически на любом вычислительном кластере.
Как ускорить проведение вычислений на кластере?
Во-первых, нужно максимально ускорить вычисления на одном процессоре, для чего можно принять следующие меры.
1. Подбор опций оптимизации компилятора. Подробнее об опциях компиляторов можно почитать здесь:
- Компиляторы Intel C++ и Fortran (русскоязычная страница на нашем сайте).
- GCC online documentation.
2. Использование оптимизированных библиотек. Если некоторые стандартные действия, такие как умножение матриц, занимают значительную долю времени работы программы, то имеет смысл использовать готовые оптимизированные процедуры, выполняющие эти действия, а не программировать их самостоятельно.
Для выполнения операций линейной алгебры над матричными и векторными величинами была разработана библиотека BLAS («базовые процедуры линейной алгебры»). Интерфейс вызова этих процедур стал уже фактически стандартом и сейчас существуют несколько хорошо оптимизированных и адаптированных к процессорным архитектурам реализаций этой библиотеки. Одной из таких реализаций является свободно распространяемая библиотека ATLAS, которая при установке настраивается с учетом особенностей процессора. Компания Интел предлагает библиотеку MKL — оптимизированную реализацию BLAS для процессоров Intel и SMP-компьютеров на их основе. Тут статья про подбор опций MKL.
Подробнее о библиотеках линейной алгебры (BLAS) можно почитать здесь:
3. Исключение своппинга (автоматического сброса данных из памяти на диск). Каждый процесс должен хранить не больше данных, чем для него доступно оперативной памяти (в случае двухпроцессорного узла это примерно половина от физической памяти узла). В случае необходимости работать с большим объемом данных может быть целесообразным организовать работу со временными файлами или использовать несколько вычислительных узлов, которые в совокупности предоставляют необходимый объем оперативной памяти.
4. Более оптимальное использование кэш-памяти. В случае возможности изменять последовательность действий программы, нужно модифицировать программу так, чтобы действия над одними и те же или подряд расположенными данными данными выполнялись также подряд, а не «в разнобой». В некоторых случаях может быть целесообразно изменить порядок циклов во вложенных циклических конструкциях. В некоторых случаях возможно на «базовом» уровне организовать вычисления над такими блоками, которые полностью попадают в кэш-память.
5. Более оптимальная работа с временными файлами. Например, если программа создает временные файлы в текущем каталоге, то более разумно будет перейти на использование локальных дисков на узлах. Если на узле работают два процесса и каждый из них создает временные файлы, и при этом на узле доступны два локальных диска, то нужно, чтобы эти два процесса создавали файлы на разных дисках.
6. Использование наиболее подходящих типов данных. Например, в некоторых случаях вместо 64-разрядных чисел с плавающей точкой двойной точности (double) может быть целесообразным использовать 32-разрядные числа одинарной точности (float) или даже целые числа (int).
Более подробно о тонкой оптимизации программ можно почитать в руководстве по оптимизации для процессоров Intel и в других материалах по этой теме на веб-сайте Intel.
Как оценить и улучшить качество распараллеливания?
Для ускорения работы параллельных программ стоит принять меры для снижения накладных расходов на синхронизацию и обмены данными. Возможно, приемлемым подходом окажется совмещение асинхронных пересылок и вычислений. Для исключения простоя отдельных процессоров нужно наиболее равномерно распределить вычисления между процессами, причем в некоторых случаях может понадобиться динамическая балансировка.
Важным показателем, который говорит о том, эффективно ли в программе реализован параллелизм, является загрузка вычислительных узлов, на которых работает программа. Если загрузка на всех или на части узлов далека от 100% — значит, программа неэффективно использует вычислительные ресурсы, т.е. создает большие накладные расходы на обмены данными или неравномерно распределяет вычисления между процессами. Пользователи НИВЦ МГУ могут посмотреть загрузку через веб-интерфейс для просмотра состояния узлов.
В некоторых случаях для того, чтобы понять, в чем причина низкой производительности программы и какие именно места в программе необходимо модифицировать, чтобы добиться увеличения производительности, имеет смысл использовать специальные средства анализа производительности — профилировщики и трассировщики. На кластере Ant установлена система для отладки MPI-программ deb-MPI. Краткую информацию по системе можно найти по адресу http://parallel.ru/cluster/deb-MPI-UG.html .—>
Подробнее об улучшении производительности параллельных программ можно почитать в книге В.В.Воеводина и Вл.В.Воеводина «Параллельные вычисления».
Источник: parallel.ru
Что такое кластеризация или кластерный анализ
Если у вас есть большой массив данных, то наиболее эффективный способ понять, что с ними делать — рассортировать их в группы для первичного анализа. Группировать можно при помощи — сегментации (вы сами задаете критерии, например, возрастные и ценовые группы) или кластеризации (математический алгоритм сам выявляет “связующий” критерий или признак, который объединяет данные). Ценность data-driven подхода и основное отличие кластеризации заключается в том, что алгоритмы выявляют и объединяют параметры с похожими чертами из первичного массива данных.
Маркетинг и продажи — одно из направлений применения кластерного анализа. В частности для прогнозирования будущего поведения покупателя — персонализации и таргетирования. Кластерный анализ использует математические модели для обнаружения групп схожих клиентов, основываясь на наименьших различиях среди покупателей в каждой группе.
Кластерный анализ (англ. cluster analysis) — многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы.
Боль: кампании, как маркетинговая инвестиция, должны быть направлены на конкретную целевую группу.
Стандартный пул данных в датасете:
- Основная информация о клиенте — профиль / идентификатор клиента, местоположение и цена покупок
- Информация о продукте — сегмент, бренд, иерархия продуктов, размер, и тд.
- Информация о транзакции — проданный объем, детали счета, дата, время и идентификатор продукта
Пример 3D визуализации результатов кластерного анализа
Более глубокое понимание клиентских сегментов достигается путем разработки 3D-модели кластеров на основе ключевых бизнес-показателей, таких как размещенные заказы (покупки), частота заказов, заказанные товары или изменение цен. Актуальность результатов кластеризации для бизнеса позволяет лицам, принимающим решения, выявлять проблемные кластеры, которые вынуждают продавца использовать больше ресурсов для достижения целевого результата. Затем можно сосредоточить свои маркетинговые и операционные усилия на правильных кластерах, чтобы обеспечить оптимальное использование ресурсов, включая:
- Анализ цен: кластеризация является отправной точкой для более глубокого анализа цен, чтобы получить инсайты и улучшить объемы продаж на основе прогнозируемых изменений в структуре (паттерне) закупок по отношению к изменениям цен внутри каждого идентифицированного кластера.
- Анализ аномалий: можно выявить неочевидные закономерности и аномалии в поведении покупателей.
- Анализ частоты покупок: позволяет сформировать кластеры покупателей, которые стали покупать реже или наоборот чаще в конкретном промежутке времени.
- Анализ времени покупок: кластеризация времени покупок в течении дня на протяжении недели и в разные сезоны может выявить периоды максимальной и минимальной загрузки для оптимизации логистики и перераспределения трафика.
- Аналитика дистрибуции: дистрибьюторы также могут извлечь выгоду из кластеризации продуктов, поскольку это помогает им идентифицировать товары, которые можно связать вместе, чтобы избежать многократных поездок и оптимизировать транспортные ресурсы.
- Прогнозируемые инсайты: кластеризация продуктов может предоставить ритейлерам возможности прогнозирования, позволяя им сопоставить нового клиента с уже существующими кластерами продуктов на основе определенных атрибутов клиента, таких как бизнес-категория, местоположение и предлагаемые услуги.
- Анализ продвижения: группировка похожих продуктов на основе кластеризации товаров может помочь розничным продавцам идентифицировать наборы продуктов, чтобы повысить продажи и увеличить количество товаров, заказанных конкретным покупателем, на основе выявленных сходств в выборе.
Хотя возможности прогнозирования, предлагаемые кластеризацией, могут трансформировать результаты целевого маркетинга, кластеризация наиболее эффективна при использовании вместе с другими решениями для розничной аналитики. Ценность кластеризации продуктов особенно видна в очень разреженном датасете (наборе данных). В дополнение к повышению рентабельности маркетинговых инвестиций (ROMI) с точки зрения прибыльности клиентов, кластеризация продуктов может помочь ритейлерам таргетировать и активизировать клиентов из категории с невысокой платежеспособностью.
Модуль кластеризации Polymatica позволяет распределять данные на кластеры или группы по одному или нескольким параметрам. Аналитическая платформа использует параллельно несколько алгоритмов, в том числе собственные разработки, чтобы:
- обеспечить интерактивное взаимодействие между пользователем и системой — разбиение массива на группы происходит в течение нескольких секунд;
- добиться воспроизводимых результатов. Известно, что недостатком алгоритма k-среднего является нестабильность распределения — при нескольких запусках один и тот же элемент может оказаться в разных кластерах. В Polymatica этот недостаток устранен.
Подробнее о функционале модуля “Кластеризация” смотрите в обучающем видео.
Источник: vc.ru