
Для быстрого перевода текста с бумажных носителей в электронный вид используют сканеры и программы распознавания символов .
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Наиболее широко известна и распространена такая программа отечественных производителей — ABBYY FineReader .
Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках (на 179 языках), а также для распознавания смешанных двуязычных текстов.
РЕДАКТИРОВАНИЕ PDF ✏️ КАК РАСПОЗНАТЬ И ПЕРЕВЕСТИ ДОКУМЕНТ В WORD
Возможности программы ABBYY FineReader:
- Работает с разными моделями сканеров.
- Позволяет из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст.
- Позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (многостраничными документами) и с бланками.
- Позволяет редактировать распознанный текст и проверять его орфографию.
- Сохраняет внешний вид документа, а также его структуру, то есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале.
- Экспортирует тексты в Word, Excel, PowerPoint или Outlook.
Преобразование бумажного документа в электронный вид происходит в пять этапов. Каждый из этих этапов программа FineReader может выполнять как автоматически, так и под контролем пользователя. Если все этапы проводятся автоматически, то преобразование документа происходит за один прием.
Пять этапов процесса обработки документа с помощью программы ABBYY FineReader:
- Сканирование документа (кнопка Сканировать).
- Сегментация документа (кнопка Сегментировать).
- Распознавание документа (кнопка Распознать).
- Редактирование и проверка результата (кнопка Проверить).
- Сохранение документа (кнопка Сохранить).
1) На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
2) Второй этап работы — сегментация , разбиение страницы на блоки текста. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции. Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке.
Scan documents into Excel with ABBYY Finereader by Chris Menard
Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
3) Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован.
4) Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad. Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
5) По щелчку на кнопке Сохранить запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки полученный текст можно сохранить в виде форматированного или неформатированного документа.
Источник: www.yaklass.ru
Какие программы для распознавания текста использовать в офисе
Меня часто спрашивают: «Отсканировали (сфотографировали) страничку, файл открывается, читается. Как теперь внести в этот документ исправления?» Ответ: просто так — никак! То, что вы отсканировали — изображение, картинка, набор разноцветных точек. Редактировать можно только документ, состоящий из знаков (символов).
Самое большее, что вы можете сделать с картинкой — в графическом редакторе (Paint, GIMP и т. п.) закрасить или вырезать на ней отдельные участки и нарисовать буквы и цифры. Редактируемым документом от этого изображение не станет!
Однако решение есть: оптическое распознавание символов (optical character recognition, OCR). Программа анализирует изображение, выделяет из него характерные очертания букв и цифр, а потом создает настоящий редактируемый документ. Примерно то же самое делаете вы, когда читаете написанное и набираете прочитанное на клавиатуре.
Правда, в распознавании символов компьютеру еще очень далеко до человека. Люди безошибочно разбирают любые каракули, а программы OCR пока хорошо справляются только с четкими изображениями печатных букв. С технологией OCR тесно связан рукописный ввод, который используется в планшетах и смартфонах. Пользователь пальцем или стилусом рисует на сенсорном экране буквы и цифры, а смартфон распознает их. Вы могли заметить, что устройство верно воспринимает только аккуратно начерченные символы, а криво или косо нарисованные приводят его в замешательство.
Весьма эффективное средство распознавания входит в состав пакета Microsoft Office. В предыдущих версиях пакета этим занималось отдельное приложение Microsoft Office Document Imaging (MODI). В Microsoft Office 2010 задача распознавания возложена на компонент OneNote. Примечательно, что теперь эта функция скромно именуется поиском и копированием текста в рисунках и вызывается «как бы между прочим». Как ею пользоваться?

Распознавание символов с помощью OneNote
- Изображение, текст с которого нужно распознать, любым образом вставьте в заметку OneNote. Например, перетащите мышью файл рисунка в окно OneNote или на ленте воспользуйтесь кнопками Вставка → Рисунок — как вам удобнее.
- В окне OneNote щелкните на рисунке правой кнопкой мыши и в контекстном меню выберите команду Копировать текст из рисунка (см. рис.). Весь текст, который программа сумеет распознать в изображении, будет скопирован в буфер обмена.
- Вставьте скопированный текст в любой документ. Пункт Поиск текста в рисунках в контекстном меню служит для выбора языка распознавания. Эта настройка позволяет точнее определить набор символов, ведь многие буквы разных алфавитов похожи по начертанию.
Одно из лучших приложений для распознавания документов и таблиц — ABBYY FineReader. Программа легко обрабатывает изображения документов со сложной структурой и очень точно воспроизводит ее в распознанном документе. Хотя в FineReader предусмотрено множество гибких настроек, с большинством типичных задач программа прекрасно справляется «на полном автомате». За простым и интуитивно понятным интерфейсом скрывается мощный интеллектуальный «движок». По умолчанию при запуске предлагается выбрать один из готовых сценариев.
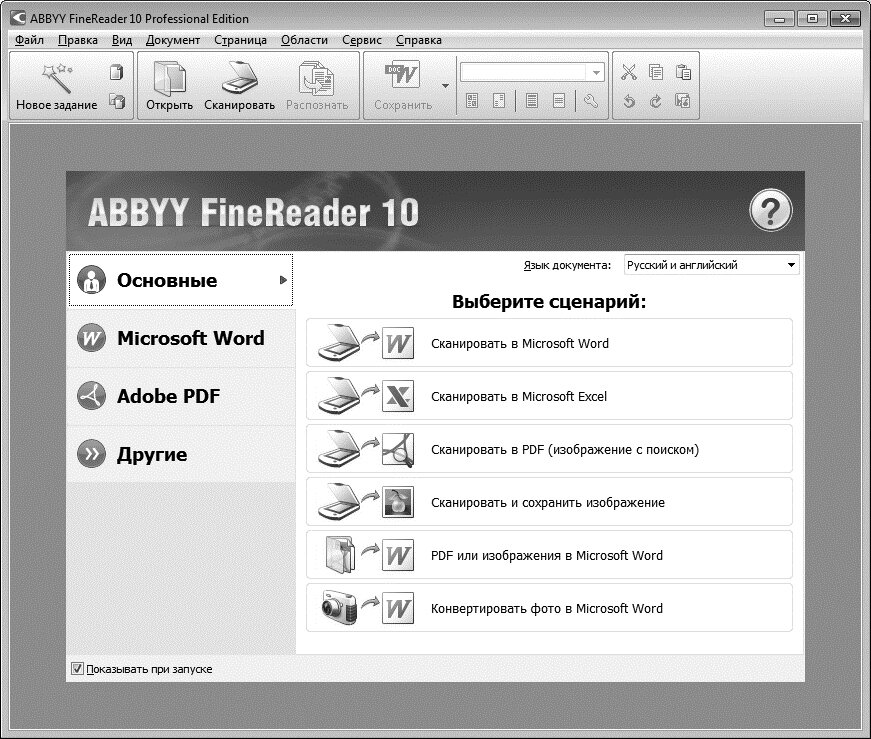
Запуск программы ABBYY FineReader
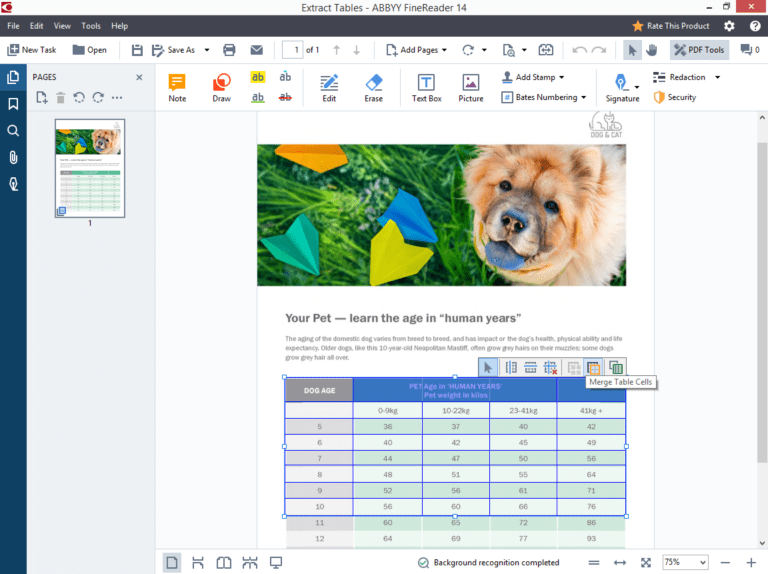
Например, если вы выберете сценарий Сканировать в Microsoft Word, сначала откроется диалоговое окно сканирования. После сканирования первой страницы программа запрашивает, нужно ли сканировать следующую, либо можно переходить к следующему шагу. Когда получены изображения всех страниц, начинается их обработка и распознавание. Ход и результаты распознавания отображаются в главном окне программы. В левой части окна показаны эскизы страниц, а в рабочей области вы видите исходное изображение и рядом с ним — уже распознанный документ.

Главное окно ABBYY FineReader
Результат распознавания FineReader в соответствии со сценарием передает в другую программу или сохраняет. Например, в данном случае автоматически откроется окно Microsoft Word с новым документом. Как правило, в созданном документе заголовки, абзацы и другие составляющие оформления выглядят почти так же, как на исходном изображении. Подбирается даже наиболее похожий шрифт! Другие сценарии позволяют отправить результат распознавания в Microsoft Excel — это удобно, если на оригинале изображена таблица, сохранить его в виде документа Adobe Reader (PDF), вместо сканирования открыть сделанное раньше фото оригинала и т. д.
Кроме того, программу можно запустить в пошаговом режиме. Для этого на панели инструментов нажмите кнопку Новое задание. Окно выбора сценариев закроется. Нажимая кнопки на панели инструментов, вы сможете последовательно и под полным контролем отсканировать документ или открыть готовое изображение, при необходимости исправить его дефекты и искажения, проанализировать и выделить то, что нужно распознавать, проверить и сохранить результат.
К сожалению, программа FineReader передает документы лишь в приложения Microsoft Office (если они установлены), а с пакетом OpenOffice.org она не знакома. В таком случае очевидный выход — сохранять результаты распознавания в универсальном формате RTF, который прекрасно «понимают» любые редакторы документов. Очень качественное, но коммерческое ПО ABBYY FineReader подходит тем, кто распознает текст с бумажных оригиналов часто и регулярно.
Существуют ли бесплатные альтернативы?
Давний конкурент ABBYY — компания Cognitive Technologies в 2007 г. выпустила бесплатную версию программы CuneiForm и открыла ее исходные тексты. С тех пор поддержкой проекта (www.cuneiform.ru) занялось сообщество программистов, а сама программа сегодня работает на платформах Windows, Linux, FreeBSD и Mac OS X. Другой полностью свободный проект — Tesseract.
Бесплатная программа COCR2 примечательна тем, что распознает китайские иероглифы. В связке с электронным переводом, например Переводчиком Google, это приложение дает удивительную возможность прочитать и понять документацию на китайском прямо «с листа»! Коммерческими программами Readiris и CrystalOCR комплектуются многие МФУ. Для конечного пользователя OEM-лицензия является бесплатной — фактически она была оплачена при покупке аппарата.
Сервисы распознавания символов появились и в Интернете: FineReaderOnline.ru, Onlineocr.ru, Liveocr.com и некоторые другие. С помощью формы на веб-странице указывается путь к файлу изображения на вашем компьютере, а результат распознавания выдается опять же через Интернет. В принципе, сервисы работают на коммерческой основе: нужно зарегистрироваться на сайте и оплатить услугу. Однако ограниченное число страниц в течение суток они обрабатывают бесплатно.
Источник: pivot-table.ru
Программы для распознавания текста из изображений
Программы
Несмотря на то, что в цифровую эпоху все идет в цифровую форму, вы возможно заметили, что бумага не исчезла. У нас все еще есть стопки распечаток, книг, счетов, листовок, журналов, выписок и других газет, с которыми нам приходится иметь дело ежедневно.
Как текстовые документы могут идти в ногу с текущими технологическими изменениями
Вот тут-то и появляется оптическое распознавание символов (OCR). Программное обеспечение OCR позволяет оцифровывать печатные или рукописные документы, делая их редактируемыми с помощью программ обработки текста.
Оптическое распознавание символов (OCR) — это программа, которая может конвертировать отсканированные, распечатанные или рукописные файлы изображений в машиночитаемый текстовый формат. Или если говорить более просто это программы для распознавания текста из изображений.
Возможно, у вас есть книга или квитанция, которую вы напечатали или напечатали несколько лет назад, и вы хотите, чтобы она была в цифровом формате, но вы не хотите ее перепечатывать. OCR может быть очень полезным в таком случае.
В этой статье, мы поговорим про лучшие программы для распознавания текста из изображений. Это основной вопрос, который у вас может возникнуть перед загрузкой OCR. Мы поможем вам выбрать, ответив на более конкретные вопросы:
- Поддерживает ли программа несколько форматов файлов?
- Есть ли в программе OCR распознавание разных языков?
- Можете ли вы использовать инструмент OCR онлайн?
- Распознает ли текст из файлов изображений?
Программы для распознавания текста из изображений
Сразу стоит отметить, что в этом списке, присутствуют программы не только для Ubuntu но и с поддержкой Windows/macOS.
Программы для распознавания текста из изображений для Ubuntu
Чтобы запустить Tesseract Goto откройте Terminal и введите следующее
tesseract imagefile.tif outputfile.txt
Readiris 17
Readiris 17 — последняя версия этого высокопроизводительного программного обеспечения для распознавания текста. Он поставляется с новым интерфейсом, новым механизмом распознавания и более быстрым управлением документами. Вы можете легко конвертировать во многие различные форматы, в том числе в аудиофайлы благодаря его устному распознаванию.
Readiris — это одно из самых мощных программ для распознавания текста, которое требует меньше усилий для начала работы. Хотя это платная программа, вы получаете то, за что платите. Readiris поддерживает большинство форматов файлов и поставляется с другими привлекательными функциями, которые упрощают процесс преобразования.
Например, изображения могут быть получены из подключенных устройств, таких как сканеры, и приложение также позволяет настраивать параметры обработки, такие как настройки DPI.
После завершения обработки Readiris определяет текстовые разделы или зоны и позволяет извлекать тексты либо из определенной зоны, либо из всего файла.
Readiris имеет редкую функцию сохранения в облаке, которая позволяет пользователям сохранять извлеченный текст в различные сервисы облачного хранения, такие как Google Drive, OneDrive, Dropbox и другие.
Он также имеет множество функций редактирования и обработки текста, что позволяет пользователям даже сканировать штрих-коды. Подписка начинается от 99 долларов, и предоставляется 10-дневная бесплатная пробная версия. Использование программы на Ubuntu возможно через Wine.
ABBYY FineReader 14
ABBYY FineReader 14 — это самое мощное программное обеспечение для распознавания текста на рынке и лучший инструмент для тех, кому нужно быстрое и точное распознавание текста.
Этот оптический распознаватель прекрасно справляется с работой с большими объемами и оснащен передовыми инструментами коррекции для сложных задач.
Превосходный инструмент проверки легко исправляет сомнительные показания, делая аккуратное сравнение между текстами OCR и оригиналом.
ABBYY Finereader 14 делает больше, чем вы ожидаете от распознавания текста. Вы хотите конвертировать старую книгу на 500 страниц в PDF с возможностью поиска? ABBYY справится с этим с максимальной точностью.
ABBYY извлечет самые точные тексты из изображений, найденных в Интернете.
Кроме того, он может конвертировать отсканированный документ в HTML или в формат ePub, используемый электронными читателями. Использование программы на Ubuntu возможно через Wine.
Microsoft OneNote (бесплатно)
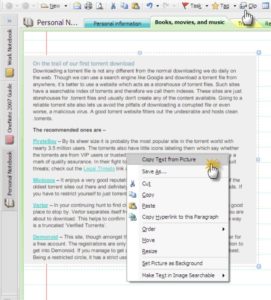
Microsoft OneNote также можно использовать в качестве OCR, несмотря на его функциональность в качестве хранителя заметок. Существует опция «Копировать текст из изображения», которая позволяет извлекать текст из изображений.
Его простота — вот что делает его уникальным; просто вставьте картинку в OneNote, затем щелкните правой кнопкой мыши на картинке и выберите «Копировать текст из картинки», а OneNote сделает все остальное. Он сохраняет текст в буфер обмена, а затем вы можете вставить текст в Microsoft Word или любую другую программу по вашему выбору.
Тем не менее, он не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Simple OCR (Free)
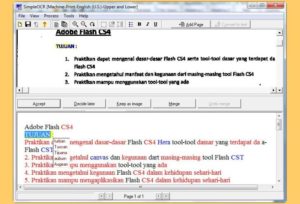
Если говорить про программы для распознавания текста из изображений, то это приложение является очень удобным. Simple OCR — это удобный инструмент, который вы можете использовать для преобразования распечаток в печатном виде в редактируемые текстовые файлы.
Если у вас много рукописных документов и вы хотите преобразовать их в редактируемые текстовые файлы, тогда Simple OCR будет вашим лучшим вариантом.
Тем не менее, рукописное извлечение имеет ограничения и предлагается только как 14-дневная бесплатная пробная версия. Машинная печать бесплатна и не имеет ограничений.
Существует встроенная проверка орфографии, которую вы можете использовать для проверки расхождений в преобразованном тексте. Вы также можете настроить программное обеспечение для чтения непосредственно со сканера.
Как и Microsoft OneNote, Simple OCR не поддерживает таблицы и столбцы. Использование программы на Ubuntu возможно через Wine.
Free OCR
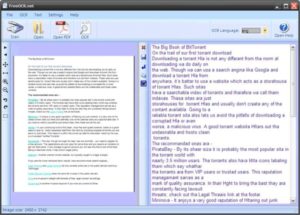
Free OCR использует Tesseract Engine, который был создан HP и теперь поддерживается Google.
Tesseract — очень мощный движок, и сегодня он считается одним из самых точных механизмов распознавания текста в мире. Free OCR отлично справляется с форматами PDF и поддерживает устройства TWAIN, такие как цифровые камеры и сканеры изображений.
Кроме того, он поддерживает практически все известные файлы изображений и многостраничные файлы TIFF. Вы можете использовать программное обеспечение для извлечения текста из картинок, и оно делает это с высокой степенью точности.
И, как и другое программное обеспечение Free OCR, Free OCR не поддерживает вывод таблиц и столбцов.
Boxoft Free OCR (Бесплатно)
Boxoft Free OCR — еще один удобный инструмент, который вы можете использовать для извлечения текста из всех видов изображений.
Эта бесплатная программа проста в использовании и способна анализировать многостолбцовый текст с высокой степенью точности.
Он поддерживает несколько языков, включая английский, испанский, итальянский, голландский, немецкий, французский, португальский, баскский и многие другие.
Это программное обеспечение OCR позволяет вам сканировать ваши бумажные документы и конвертировать их в редактируемые тексты в течение очень короткого времени.
Хотя существуют опасения, что это средство распознавания текста не справляется с извлечением текста из рукописных заметок, оно исключительно хорошо работает с печатными копиями.
Top OCR (Платный)
TopOCR отличается от типичного программного обеспечения OCR во многих аспектах, но выполняет работу точно. Лучше всего работает с цифровыми камерами и сканерами. Если говорить про лучшие программы для распознавания текста из изображений, то обязательно стоит и рассказать про эту программу более детально.
Его интерфейс также отличается, поскольку у него есть два окна — окно изображения (источника) и текстовое окно.
Как только изображение получено с камеры или сканера с левой стороны, извлеченный текст появляется с правой стороны, где находится текстовый редактор.
Программное обеспечение поддерживает форматы GIF, JPEG, BMP и TIFF. Вывод также может быть преобразован в несколько форматов, включая PDF, HTML, TXT и RTF.
Программное обеспечение также поставляется с настройками фильтра камеры, которые можно применять для улучшения изображения.
ABBYY FineReader Online (бесплатно)
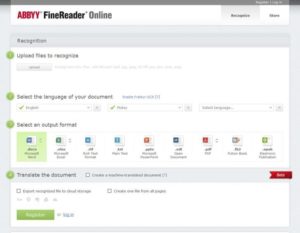
Если вы хотите насладиться мощными функциями, которые ABBYY предлагает, но не хотите идти дорогим путем, то вы можете попробовать бесплатную онлайн-версию.
FineReader Online поддерживает множество входных файлов, таких как PDF, JPEG, JPG, PNG, DCX, PCX, TIFF, TIF и BMP. Поддерживаемые выходные файлы включают PDF, Word, Excel, e-Pub и Powerpoint.
Бесплатная версия позволяет вам конвертировать до 10 страниц в месяц, и она требует сначала сделать регистрацию, которая также бесплатна.
Однако, если вы интенсивный пользователь и хотите конвертировать больше страниц в месяц, вам необходимо подписаться на платную версию.
Распознавание текста онлайн
Еще один отличный способ, это распознавать текст онлайн. Сайт img2txt предлагает очень удобный, легкий и быстрый для распознавания текста.
Готово! В этой статье, мы поговорили про лучшие программы для распознавания текста из изображений. Рынок наводнен программами OCR, которые могут извлекать текст из изображений и сэкономить вам много времени, которое вы могли бы потратить на перепечатывание документа.
Однако хорошие программы для распознавания текста из изображений должно делать больше, чем извлекать текст из печатных документов. Оно должно поддерживать макет, текстовые шрифты и текстовый формат в качестве исходного документа.