
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
Читать далее
Сравнение Системы распознавания текста
Выбрать по критериям:
Подходит для
Специалист
Малый бизнес
Средний бизнес
Корпорация
Администрирование
Импорт/экспорт данных
Многопользовательский доступ
Наличие API
Отчётность и аналитика
Тарификация
Ежемесячная оплата
Ежегодная оплата
Единовременная оплата
Оплата потребления
По запросу
Развёртывание
Сервер предприятия
Мобильное устройство
Персональный компьютер
Облако (SaaS)
Графический интерфейс
Веб-браузер
Поддержка языков
Азербайджанский
Белорусский
Бенгальский
Болгарский
Венгерский
Вьетнамский
Грузинский
Индонезийский
Итальянский
Распознавание текста с изображения на Python | EasyOCR vs Tesseract | Компьютерное зрение
Каталонский
Латвийский
Монгольский
Нидерландский
Норвежский
Персидский
Португальский
Украинский
Французский
Хорватский
Английский
Нет продуктов
Руководство по покупке Системы распознавания текста
1. Что такое Системы распознавания текста
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
2. Обзор основных функций и возможностей Системы распознавания текста
Администрирование Возможность администрирования позволяет осуществлять настройку и управление функциональностью системы, а также управление учётными записями и правами доступа к системе. Импорт/экспорт данных Возможность импорта и/или экспорта данных в продукте позволяет загрузить данные из наиболее популярных файловых форматов или выгрузить рабочие данные в файл для дальнейшего использования в другом ПО.
Многопользовательский доступ Возможность многопользовательской доступа в программную систему обеспечивает одновременную работу нескольких пользователей на одной базе данных под собственными учётными записями. Пользователи в этом случае могут иметь отличающиеся права доступа к данным и функциям программного обеспечения.
Наличие API Часто при использовании современного делового программного обеспечения возникает потребность автоматической передачи данных из одного ПО в другое. Например, может быть полезно автоматически передавать данные из Системы управления взаимоотношениями с клиентами (CRM) в Систему бухгалтерского учёта (БУ).
Для обеспечения такого и подобных сопряжений программные системы оснащаются специальными Прикладными программными интерфейсами (англ. API, Application Programming Interface). С помощью таких API любые компетентные программисты смогут связать два программных продукта между собой для автоматического обмена информацией. Отчётность и аналитика Наличие у продукта функций подготовки отчётности и/или аналитики позволяют получать систематизированные и визуализированные данные из системы для последующего анализа и принятия решений на основе данных.
Лучшие программы для распознавания текста. Рейтинг OCR.
Источник: soware.ru
Обзор программ для распознавания текста
У пользователей, которым приходится работать с документами, иногда возникает необходимость перевести текст с бумаги в цифровой документ, чтобы с ним можно было впоследствии работать в текстовом редакторе. Набирать текст с листка вручную – занятие довольно трудоемкое и неблагодарное, особенно если этого текста не один листик, а страниц 20-30, или даже больше. В таком случае может сильно пригодиться специальный инструмент для распознавания текста, называемый OCR (Optical Character Recognition). Программа оптического распознавания текста поможет выиграть время, которое вы могли бы потратить на перепечатку текста, а также даст возможность сохранить иллюстрации, что порой тоже очень важно. В данной статье мы проведем небольшой обзор наиболее популярных и востребованных OCR-инструментов
ABBYY Fine Reader
Программа ABBYY Fine Reader является одним из лучших инструментов для распознавания отсканированных документов. Также данная программа может распознавать PDF и DjVu-файлы.
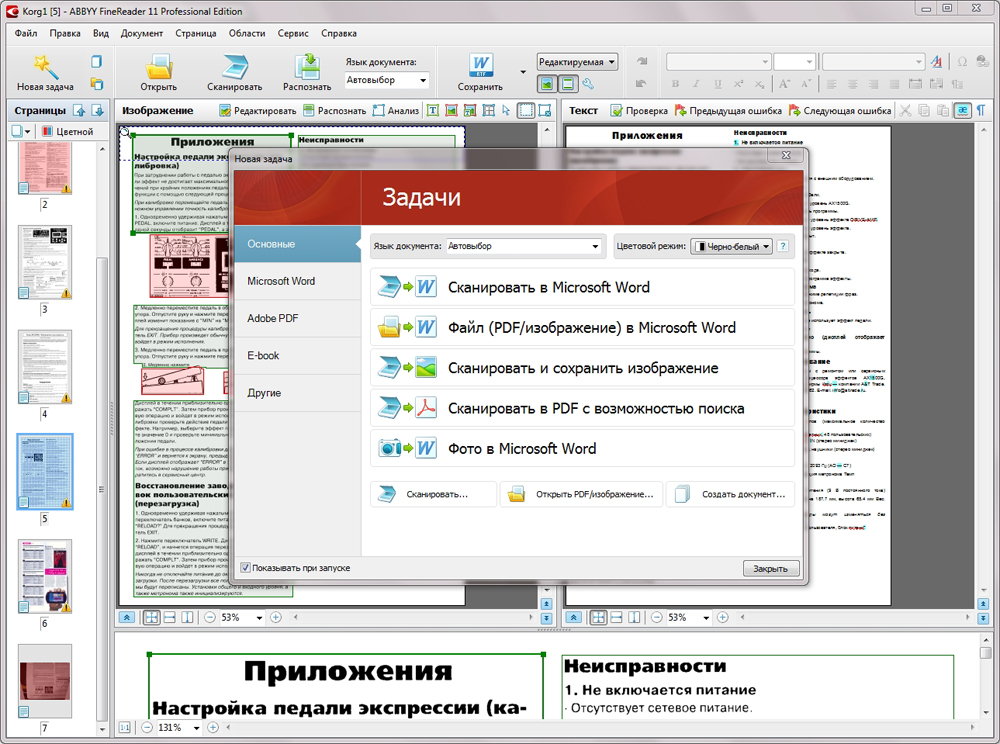
Fine Reader имеет встроенный текстовый редактор с проверкой орфографии, может проводить распознавание текста с изображений почти всех форматов, поддерживает более 180-ти языков. Программа позволяет проводить довольно качественное извлечение текста даже из тех изображений, которые были сделаны при помощи цифровой камеры и имеют неравномерное освещение и недостаточную резкость.
Программа ABBYY Fine Reader выпускается в трех версиях: Home Edition, Professional Edition и Corporate Edition. Первая версия предназначена для домашнего использования и имеет слегка упрощенный интерфейс, вторая больше подходит для профессиональной работы с текстом, так как ее функциональность несколько шире, а версия Corporate Edition ориентирована на совместное использование в различных организациях.
ABBYY Fine Reader является платной программой, пробную демо-версию продукта можно бесплатно скачать на официальном сайте разработчика, который находится по адресу Abbyy.ru
OmniPage
OmniPage – это еще один качественный профессиональный инструмент для распознавания текста с графических и PDF-файлов. Программа обеспечивает качественное и быстрое распознавание документа с полным сохранением его структуры, что особенно важно при распознавании документов, которые содержат таблицы.
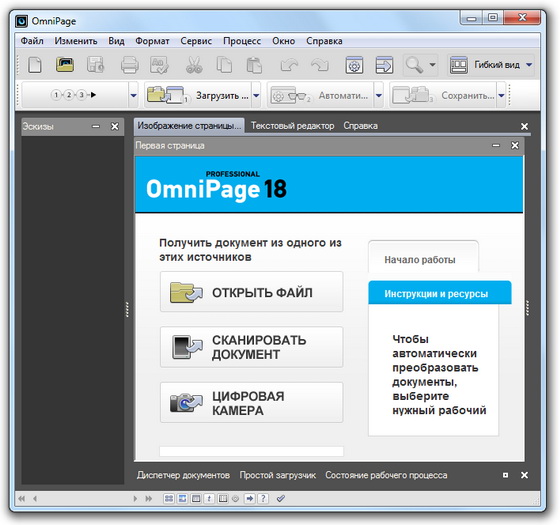
OmniPage имеет поддержку более чем 120 языков, также в программу встроены распознавательные словари для юридических, финансовых и медицинских терминов. Помимо распознавания текста, программа также имеет такие функции, как конвертация документов в PDF, конвертация электронных документов в аудиофайл и распознавание текста с изображения напрямую в аудиофайл.
Программа OmniPage также платная, приобрести ее можно на официальном сайте разработчика – Nuance.com .
OCR CuneiFrom
Программа OCR CuneiFrom после разработки позиционировалась как платный продукт, однако со временем компания-разработчик стала распространять ее бесплатно и даже открыла исходные коды программы, предложив всем желающим принять участие в улучшении работы программы. OCR CuneiFrom имеет простой, но приятный интерфейс, и может распознавать текст на более чем 20-ти языках. При распознавании программа сохраняет форматирование текста и расположение таблиц, а встроенные алгоритмы оптического распознавания позволяют выполнять извлечение текста даже из нечетких ксерокопий и факсов.
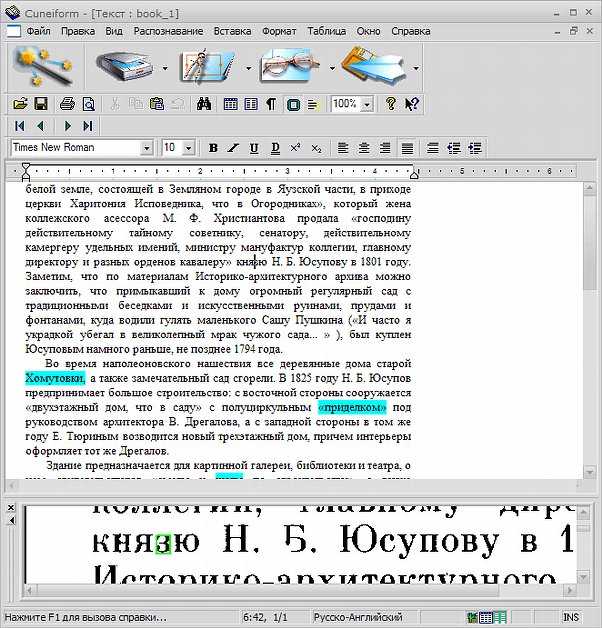
Программа OCR CuneiFrom является, пожалуй, лучшим бесплатным инструментом для распознавания документов. Скачать бесплатно данную утилиту можно на официальном сайте разработчика по адресу Cognitiveforms.ru .
Помимо программ для распознавания текста, вы можете воспользоваться еще и специальными сервисами, с помощью которых можно выполнять распознавание документов в режиме онлайн. Разумеется, их возможности несколько ограничены по-сравнению с возможностями специализированных программ, однако для небольших объемов такие сайты вполне сгодятся.
FineReader Onine
Сервис FineReader Online от компании ABBYY представляет собой «облегченную» версию программы FineReader. Так же, как и программа, онлайн-сервис отличается отличным качеством распознавания и поддержкой практически всех графических форматов. Распознанный текст можно загрузить на локальный диск компьютера или же экспортировать напрямую в облачные сервисы Google, Dropbox или Evernote.
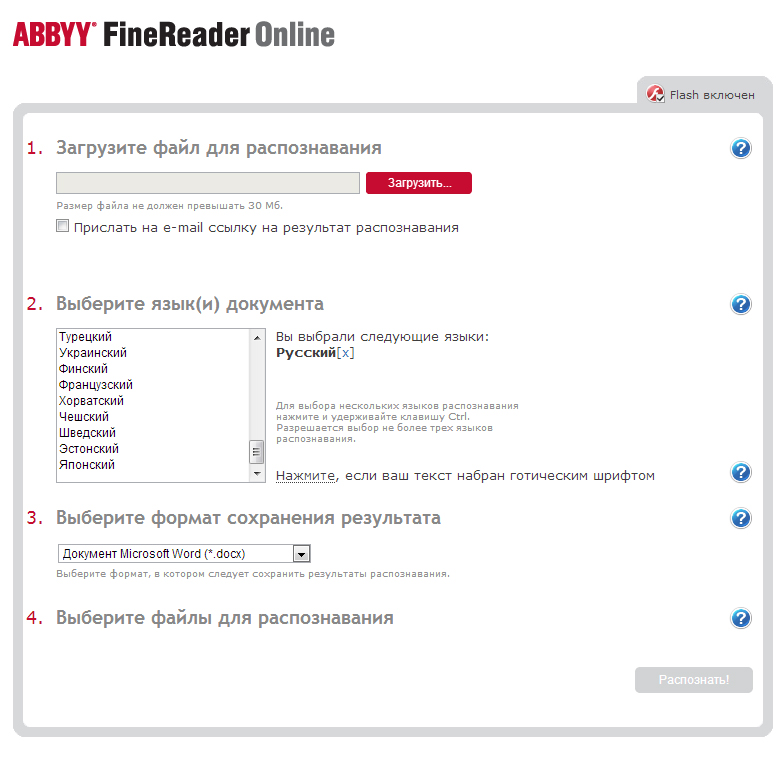
К сожалению, так же, как и «настольная» версия, онлайновый FineReader является платным – оплата проводится за каждую распознанную страницу текста.
Online OCR
При хорошем качестве сканированного изображения сервис Online OCR показывает весьма хорошие результаты – распознавание текста проводится почти без ошибок, с сохранением структуры. А вот с нечеткими сканами Online OCR справляется из рук вон плохо – иногда проще напечатать самому, чем исправлять то множество ошибок, которое получается при распознавании плохого исходника.
New OCR
И последний «герой» нашего обзора – абсолютно бесплатный онлайн-сервис New OCR . Сайт поддерживает распознавание на более, чем 50-ти языках и позволяет выполнять извлечение текста из всех популярных графических файлов, также для обрабатываемых сканов доступны такие функции, как увеличение контрастности, поворот изображений и выбор области распознавания.
Распознанный текст можно загрузить на компьютер (сервис поддерживает все распространенные форматы документов, в том числе формат .odt) или же отправить в хранилище «Документы Google».
Единственный недостаток сервиса New OCR – англоязычный интерфейс, однако он довольно прост, так что даже при самых начальных знаниях английского распознать текст не составит для вас труда.
Источник: www.bezpk.ru
Оптическое распознавание символов (optical character recognition, OCR). Программы для оптического распознавания символов: ABBYY FineReader, CuneiForm

Технология OCR (Optical Character Recognition) может быть использована для преобразования печатной копии документа в электронную версию. Например, если сканируется многостраничный экземпляр в файл TIFF, то его загружают в OCR-программу, которая распознает текст, и далее переводят в редактируемый файл. Некоторые приложения позволяют сканировать страницы и преобразовывать содержимое в документ за один шаг.
Хотя технология изначально была разработана для оптического распознавания печатных символов, она также может использоваться для рукописных. Например, почтовые службы, такие как USPS, используют программное обеспечение OCR для автоматической обработки писем и посылок, считывая адрес.
Области применения OCR

OCR расшифровывается, как Оптическое Распознание Символов. Это широко распространенная технология распознавания текста внутри изображений в виде отсканированных документов и фотографий. Технология используется для преобразования практически любого типа изображений, содержащих письменный, рукописный или напечатанный текст в машиночитаемые текстовые данные.
OCR стала популярной в начале 1990-х годов при попытке оцифровки исторических материалов. С тех пор метод претерпел значительные улучшения, и в настоящее время обеспечивает практически идеальную точность оптического распознавания символов. Расширенные методики, такие как Zonal OCR, используются для автоматизации сложных рабочих процессов на основе преобразования машинописных текстов в цифровые документы. После того как отсканированный материал прошел обработку, текст можно редактировать с помощью программ, таких как Microsoft Word или Google Docs, которые являются текстовыми редакторами.
До того как появилась эта технология, единственным вариантом оцифровки печатных документов был ручной набор текста. Это не только занимало много времени, но и приводило к неточностям и ошибкам при воспроизведении копии. OCR часто используется в качестве «скрытой» технологии во многих известных системах и службах, включающих автоматизацию ввода данных и индексацию для поисковых систем, автоматическое оптическое распознавание символов номерных знаков, а также помощь слепым и слабовидящим людям.
Процесс определения точности текста

Каждый шаг процесса OCR важен для определения точности окончательного текста. Он начинается с преобразования печатного документа. Если на нем есть следы, пятна и плохая контрастность, программное обеспечение при распознавании будет делать ошибки, а результат получится некорректным. Чтобы избежать этих проблем, можно сделать улучшенную ксерокопию печати.
Первый шаг работы — сканирование распечатанного текста. Программное обеспечение OCR работает с файлами изображений. Сканер или хорошая цифровая камера создают четкие фотокопии документов. Лучше преобразовать отсканированные файлы в черно-белом формате. Процесс является двоичным.
С помощью черного цвета на картинке происходит распознавание текста OCR, а белый, в свою очередь, выступает фоном.
Вторым этапом является определение символов. Скорость этого процесса зависит от используемой программы OCR. Большинство из них анализируют каждый элемент один за другим. Целью приложения является определение знаков, но хорошие программы распознают не только текст, но и таблицы, и другие элементы макета.
Процесс не идеален, так как есть много факторов, которые влияют на точность. Какие программы предназначены для оптического распознавания символов, рассмотрим ниже. А пользователю самостоятельно выбирать, что лучше. OCR имеют встроенные средства проверки правописания и выделяют слова с ошибками. Некоторые из них настолько сложны, что отмечают несоответствие слов и грамматические ошибки, пользователю остается лишь выполнить необходимую корректировку.
Последний этап — сохранение готового документа в нужном формате. Если приложение не выдает необходимый, то можно воспользоваться многочисленными бесплатными конвекторами онлайн.
Оптическая технология для Брайля

Технология Optical Character Recognition (OCR) предоставляет слепым или слабовидящим людям возможность определить текст и произносить его вслух. При этом используется речевой вывод, а также отображается информация на дисплее Брайля.
Существует три основных элемента систем оптического распознавания символов: получение изображения, распознавание и чтение текста. Сначала распечатанный документ захватывается камерой, затем программное обеспечение OCR преобразует его в распознанные символы и слова, а после этого синтезатор в системе произносит определенный материал вслух или отображает на дисплее Брайля. Информация может быть сохранена в электронном формате на устройстве, на котором запущено ПО OCR, или в памяти автономного устройства.
Процесс учитывает логическую структуру языка. Система сделает вывод, что, например, союз «этом» в начале предложения является ошибкой и должен читаться, как «это». Она использует лексикон и применяет методы проверки правописания, аналогичные тем, которые используются во многих текстовых редакторах.
Все системы OCR создают временные файлы, содержащие символы и макет страницы. В некоторых системах они могут быть преобразованы в форматы, которые можно найти с помощью широко используемых компьютерных приложений, таких как текстовый редактор, электронная таблица и базы данных.
Выбор программ для распознавания текста

Рекомендуется осознано подойти к выбору программного обеспечения для распознавания текста. Лучше провести собственное тестирование или учесть мнение продвинутых пользователей.
Тестирование проводят с учетом следующих факторов:
- Точность — это то, что отличает хорошую OCR от плохой. Тем не менее нереально ожидать 100 % точности от приложения для распознавания рукописного текста. Такие факторы, как качество оригинальных документов и разрешение картинки существенно влияют на конечный результат. Хорошие OCR достигают 98 % при использовании современного сканера и исходников в удовлетворительном состоянии.
- Многоязычность — сегодня этим свойством обладают большинство программ. OCR сканирует отдельный символ, чтобы определить его. Если она рассчитана для распознавания только английских букв, то не сможет точно интерпретировать специальные знаки, например, такие, как буквы с акцентом на «е». Такое ПО будет представлять эти символы с ближайшим эквивалентом на английском языке. При применении приложения, которое поддерживает многоязычность, указывают язык документа, чтобы обеспечить точность распознавания.
- Поддержка рукописного ввода. Текст, созданный с помощью клавиатуры, легко распознается любой программой. Однако рукописный — это совсем другой метод сканирования. У людей очень разные почерки. Некоторые пишут аккуратно, в то время как большинство почерков недостаточно разборчивы. Качественные OCR могут распознавать любой почерк. Поэтому для архивации рукописного материала, потребуются программы для рукописного текста.
- Уровень автоматизации. OCR может запускаться автоматически или в интерактивном режиме. Если нужно будет сканировать много страниц одновременно, лучше рассмотреть автоматические программы. С помощью такой функции можно в несколько кликов осуществлять сканирование документов, одновременно выполняя другие задачи, и легко найти полученный файл PDF, txt или doc. Большинство бесплатных программ для распознавания текста имеют ограниченную автоматизацию.
- Сохранение макета. Основная цель этих программ — перевод текста в электронный вид. Некоторые не сохраняют макет оригинального документа. Поэтому приходится долго редактировать окончательный вариант. Хорошая программа должна сохранять исходный макет, тогда в окончательной копии потребуется незначительное редактирование. Такие приложения сохраняют столбцы, таблицы и графические изображения, как в исходном варианте.
Популярное ПО для мобильных устройств
OCR отлично подходит для переноса текста из физических источников непосредственно в цифровой документ. Существуют различные типы программ и приложений для настольных и мобильных устройств. Они различны по цене и имеют свои ключевые отличительные функции.
Наиболее популярные «Андроид»-сканеры:
- Office Lens — обеспечивает сканирование страниц и OCR для Android-пользователей бесплатно. Для конвертации необходимо подключение к интернету.
- Сканеры PDF (например, ABBYY TextGrabber, CamScanner, MDScan, OCR Instantly) — выполняют сканирование с последующим OCR. В ПО нет ограничений на количество отсканированных страниц и отсутствуют водяные знаки.
- Онлайн OCR. Его можно найти в Интернете, сервис очень прост и удобен в использовании. Отличительной чертой является то, что он поддерживает 46 языков, выходной документ весит не более 5 МБ, его легко преобразовать в Microsoft Word, Excel или обычный текстовый формат. После регистрации можно конвертировать многостраничные PDF, RTF, Excel и файлы размером до 100 МБ. Для больших объемов распознавания есть платная версия.
Документы Google

Для тех, кто уже знаком с документами Google, можно использовать OCR, встроенный в Google Drive. Для достижения наилучших результатов шрифт должен быть установлен на Arial или Times New Roman. Можно улучшить результат, убедившись, что сканированное изображение имеет равномерное освещение и четкую контрастность. Фотоматериалы могут обрабатываться индивидуально в файлах: jpg, png, gif или в многостраничных документах PDF. Расширение поддерживает большинство языков.
У Google есть много обучающих программ и возможностей облачной обработки. Многие пользователи считают, что у сервиса нет достаточно продвинутых функций и опций. Тем не менее, если используется приложение Google Drive для Android, можно сканировать страницы прямо из приложения, используя камеру на смартфоне.
В противном случае загружают документы с помощью сканера, подключенного к компьютеру, или любым другим способом, чтобы начать обработку распознавания в Google Диске. Для физических лиц на Google Диске предлагается бесплатный уровень хранения около 19 ГБ с возможностью расширения до 100 ГБ через Google One за 1,99 долл. США.
Оптическое распознавание Abbyy

Abbyy FineReader работает с документами уже давно. Это комплексное решение, как для бизнеса, так и для обычных пользователей. В нем можно получить все необходимые функции для извлечения содержания текстов из сканера с полной читаемостью, аккуратно организованные оцифрованные материалы. Помимо распознавания текстов и преобразования в PDF, Microsoft Office или другие форматы, программа также может сравнивать их, добавлять аннотации и комментарии.
Abbyy FineReader может конвертировать материал в пакетном режиме и обрабатывать множество выходных форматов на 192-х различных языках. Есть сопутствующие мобильные приложения, когда нужно выполнить быстрое сканирование с телефона.
Программное обеспечение не самое современное, но оно простое, функциональное и отлично справляется со своей работой. Утилита имеет прочную репутацию одного из лучших вариантов в области оптического распознавания символов. Можно воспользоваться бесплатной пробной версией. ПО стоит от 199,99 долл. США за стандартную разовую бессрочную лицензию.
Если кому-то покажется это дорогим вариантом, можно воспользоваться хорошей альтернативой ABBYY FineReader — онлайн версией. Она ограничена тем, что позволяет сканировать только 10 страниц в месяц. Но поставляется со всеми другими функциями премиум-версии. Потребуется регистрация, чтобы получить доступ. Она поддерживает очень много форматов входных файлов, и можно выбрать выходные, такие как PDF, Word, Excel, PowerPoint и e-Pub.
Облачный сервис Adobe Acrobat

Adobe Acrobat отвечает всем требованиям и предлагает впечатляющий список возможностей и опций, хотя цена немного круче, чем у конкурентов. Для всех функций оптического распознавания текста выбирают Pro версию Adobe Acrobat. DC означает «Облако документов», и довольно четко интегрируется с облачным решением Adobe, если нужно получить доступ к своим файлам с любого компьютера. Также есть простая и бесшовная интеграция со всем остальными сервисами Adobe, например, таким как Photoshop.
Если пользователь решит оплатить Pro версию Adobe Acrobat DC, он получит все инструменты распознавания текста, возможность добавлять комментарии и отзывы к содержанию, специализированный сервис для сканирования таблиц, возможность быстрого сравнения двух документов вместе. Материалы можно редактировать прямо на экране через несколько секунд после их сканирования.
Знак Adobe гарантирует определенный уровень качества, и пользователи впечатлены интуитивностью и возможностями Adobe Acrobat DC. Подписка на сервис начинается с 12,99 долл. США.
Лучшее бесплатное программное обеспечение
Free OCR to Word — это лучшее бесплатное программное обеспечение для оптического распознавания символов, использующее новейшие механизмы. Tesseract — самый мощный инструмент для данного типа ПО и считается одним из самых точных методов. Программа поддерживает несколько форматов изображений и TIFF нескольких страниц. Этот сервис может быть использован совершенно бесплатно для извлечения текста из предоставленного фотоматериала.
Двигатель Tesseract был первоначально разработан Hewlett Packard Labs в 1985-1994 годах. Некоторые изменения были внесены в него в 1996 году. В 1995 году он был включен в тройку лучших механизмов распознавания. Он работает с Windows, Linux и Mac OS X. FreeOCR может обрабатывать изображения, имеющие многоколонный и многоязычный текст. Он обрабатывает форматы PDF и поддерживает устройства TWAIN такие, как сканеры, имеет широко распространенный интерфейс с двойным окном, настройки которого легко понять.
Free OCR to Word может сэкономить много времени без необходимости повторного ввода уже написанного произведения. Программа берет документ, отсканированный объект или изображение и преобразует его в читаемый, редактируемый и точный материал. ПО можно бесплатно загрузить в Word. OCR to Word оптимизирован для работы со всеми типами сканеров и имеет рейтинг точности 98 %, современный интерфейс, который позволяет легко получить доступ ко всем задачам, имеются функции поворота на случай, если фото не помещается на экране правильно. ПО извлекает текст из захваченных снимков с помощью смартфонов или цифровых камер с высокой точностью и качеством.
Распознавание символов в Linux
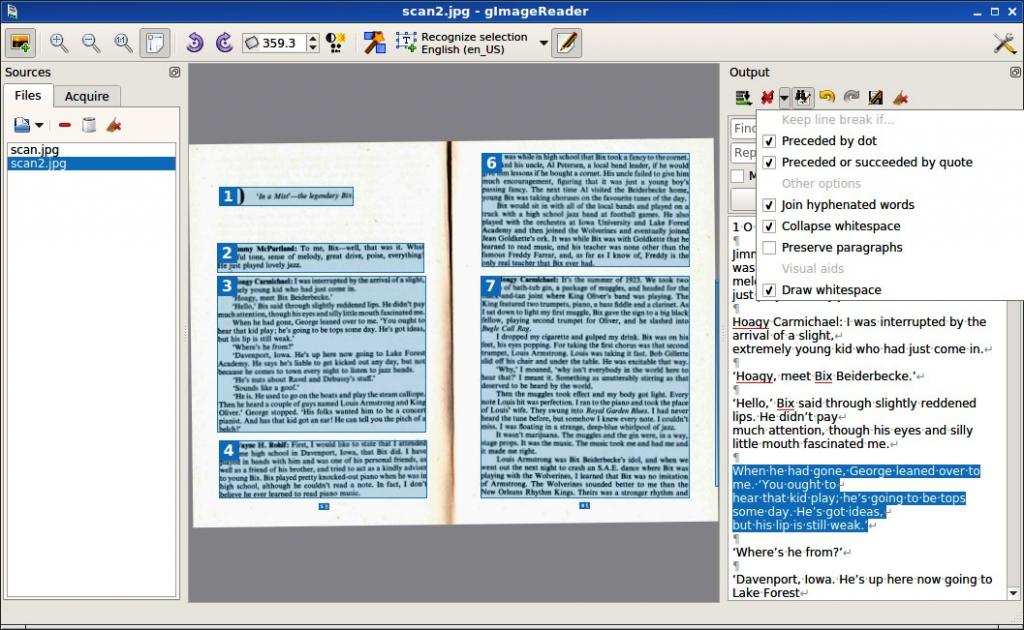
Набор OCRFeeder предоставляет удобный графический интерфейс Linux, который в основном является внешним интерфейсом для некоторых изображений, OCR и текстовых инструментов таких, как распечатка или проверка орфографии. Он не считывает символы сам по себе, но вместо этого использует другие приложения OCR через так называемые настройки «механизмов распознавания». Он имеет предопределенные параметры для Tesseract, CuneiForm, GOCR и Ocrad.
Пользователю нужно только установить в Ubuntu выбранные им движки — один или несколько и затем обнаружить их в настройках Feeder. Можно добавить другие движки и изменить эти параметры вручную. В одном приложении может быть несколько разных движков. Главное окно Feeder позволяет на лету выбрать, какой их них использовать для конкретной области, также есть настройка для выбора одного по умолчанию. Для выбора языка прочитанного текста, в случае с Tesseract и CuneiForm, необходимо добавить переключатель «-l» с соответствующим кодом языка / скрипта, например, «-l pol» для польского или «-l dan-frak» для датского к настройкам данного движка
Технология оптического распознавания печатных символов «Тессеракт» в начале могла распознавать текст только на английском языке, версия 2.x сделала ее многоязычной. При необходимости можно установить более одного словаря. Новые версии оцифровывают текст на основе ISO 963-2.
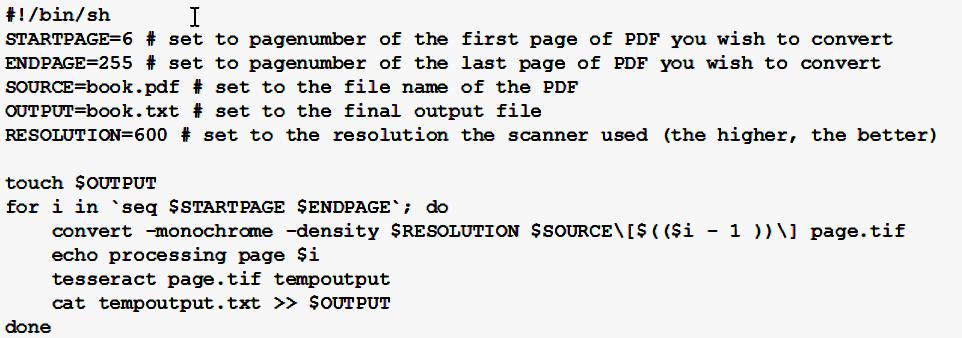
После успешной установки используют команду «tesseract>путь к изображению>базовое имя выходного файла». Tesseract автоматически придаст выходному документу расширение «.txt», можно указать опцию «-l», за которой следует код языка. Для версий Tesseract более ранних, чем третья, очень важно, чтобы изображение было в формате файла тегового значения и имело расширение «.tif», а не «.tiff». Командная строка должна выглядеть следующим образом:»$ tesseract ~ / input.tif output».
Где «input.tif» — это документ для преобразования, расположенный в домашней папке, а «output» — материал, который Tesseract создаст, как «output.txt». Часто отсканированные тексты хранятся в виде растрового рисунка в большом документе PDF. Используя ImageMagick, отдельные страницы могут быть извлечены в виде файлов TIFF для обработки с Tesseract. Следующий скрипт может помочь автоматизировать этот процесс.
Программа CuneiForm — это еще одна система оптического распознавания текста, которая была первоначально разработана и основана на открытых источниках Cognitive Technologies. Версия Windows, которая имеет собственный графический интерфейс, может быть запущена с некоторыми результатами в Wine. Его порт Linux разрабатывается на Launchpad и хотя в настоящее время у него нет собственного графического интерфейса, CuneiForm может быть успешно запущен из графического интерфейса OCRFeeder.
Ниже приведен пример, как успешно преобразовать некоторые скриншоты изображений .jpeg доски объявлений в Интернете в полезные текстовые файлы.

Технология OCR не стоит на месте, в перспективе признание интеллектуальной системы оптического распознавания символов — ICR. Этот стандарт является передовым. Большая часть ICR имеет самообучающуюся систему, называемую нейронной сетью, которая автоматически обновляет базу данных для новых образцов почерка. Она расширяет полезность сканирующих устройств для целей обработки документов от распознавания печатного текста (функция OCR) до рукописных материалов и могут достигать более 97 % степени точности при чтении рукописного материала в структурированных формах.
Источник: fb.ru