
Для работы с наборами данных Python предоставляет такие встроенные типы как списки, кортежи и словари.
Список (list) представляет тип данных, который хранит набор или последовательность элементов. Во многих языках программирования есть аналогичная структура данных, которая называется массив.
Создание списка
Для создания списка применяются квадратные скобки [] , внутри которых через запятую перечисляются элементы списка. Например, определим список чисел:
numbers = [1, 2, 3, 4, 5]
Подобным образом можно определять списки с данными других типов, например, определим список строк:
people = [«Tom», «Sam», «Bob»]
Также для создания списка можно использовать функцию-конструктор list() :
numbers1 = [] numbers2 = list()
Оба этих определения списка аналогичны — они создают пустой список.
Список необязательно должен содержать только однотипные объекты. Мы можем поместить в один и тот же список одновременно строки, числа, объекты других типов данных:
Программа подготовки к бегу на 1 км
objects = [1, 2.6, «Hello», True]
Для проверки элементов списка можно использовать стандартную функцию print, которая выводит содержимое списка в удобочитаемом виде:
numbers = [1, 2, 3, 4, 5] people = [«Tom», «Sam», «Bob»] print(numbers) # [1, 2, 3, 4, 5] print(people) # [«Tom», «Sam», «Bob»]
Конструктор list может принимать набор значений, на основе которых создается список:
numbers1 = [1, 2, 3, 4, 5] numbers2 = list(numbers1) print(numbers2) # [1, 2, 3, 4, 5] letters = list(«Hello») print(letters) # [‘H’, ‘e’, ‘l’, ‘l’, ‘o’]
Если необходимо создать список, в котором повторяется одно и то же значение несколько раз, то можно использовать символ звездочки *, то есть фактически применить операцию умножения к уже существующему списку:
numbers = [5] * 6 # 6 раз повторяем 5 print(numbers) # [5, 5, 5, 5, 5, 5] people = [«Tom»] * 3 # 3 раза повторяем «Tom» print(people) # [«Tom», «Tom», «Tom»] students = [«Bob», «Sam»] * 2 # 2 раза повторяем «Bob», «Sam» print(students) # [«Bob», «Sam», «Bob», «Sam»]
Обращение к элементам списка
Для обращения к элементам списка надо использовать индексы, которые представляют номер элемента в списка. Индексы начинаются с нуля.
То есть первый элемент будет иметь индекс 0, второй элемент — индекс 1 и так далее. Для обращения к элементам с конца можно использовать отрицательные индексы, начиная с -1. То есть у последнего элемента будет индекс -1, у предпоследнего — -2 и так далее.
people = [«Tom», «Sam», «Bob»] # получение элементов с начала списка print(people[0]) # Tom print(people[1]) # Sam print(people[2]) # Bob # получение элементов с конца списка print(people[-2]) # Sam print(people[-1]) # Bob print(people[-3]) # Tom
Для изменения элемента списка достаточно присвоить ему новое значение:
Первый раз в тренажерном зале, что нужно знать? Советы тренера!
people = [«Tom», «Sam», «Bob»] people[1] = «Mike» # изменение второго элемента print(people[1]) # Mike print(people) # [«Tom», «Mike», «Bob»]
Разложение списка
Python позволяет разложить список на отдельные элементы:
people = [«Tom», «Bob», «Sam»] tom, bob, sam = people print(tom) # Tom print(bob) # Bob print(sam) # Sam
В данном случае переменным tom, bob и sam последовательно присваиваются элементы из списка people. Однако следует учитывать, что количество переменных должно быть равно числу элементов присваиваемого списка.
Перебор элементов
Для перебора элементов можно использовать как цикл for, так и цикл while.
Перебор с помощью цикла for :
people = [«Tom», «Sam», «Bob»] for person in people: print(person)
Здесь будет производиться перебор списка people, и каждый его элемент будет помещаться в переменную person.
Перебор также можно сделать с помощью цикла while :
people = [«Tom», «Sam», «Bob»] i = 0 while i < len(people): print(people[i]) # применяем индекс для получения элемента i += 1
Для перебора с помощью функции len() получаем длину списка. С помощью счетчика i выводит по элементу, пока значение счетчика не станет равно длине списка.
Сравнение списков
Два списка считаются равными, если они содержат один и тот же набор элементов:
numbers1 = [1, 2, 3, 4, 5] numbers2 = list([1, 2, 3, 4, 5]) if numbers1 == numbers2: print(«numbers1 equal to numbers2») else: print(«numbers1 is not equal to numbers2»)
В данном случае оба списка будут равны.
Получение части списка
Если необходимо получить какую-то определенную часть списка, то мы можем применять специальный синтаксис, который может принимать следующие формы:
- list[:end] : через параметр end передается индекс элемента, до которого нужно копировать список
- list[start:end] : параметр start указывает на индекс элемента, начиная с которого надо скопировать элементы
- list[start:end:step] : параметр step указывает на шаг, через который будут копироваться элементы из списка. По умолчанию этот параметр равен 1.
people = [«Tom», «Bob», «Alice», «Sam», «Tim», «Bill»] slice_people1 = people[:3] # с 0 по 3 print(slice_people1) # [«Tom», «Bob», «Alice»] slice_people2 = people[1:3] # с 1 по 3 print(slice_people2) # [«Bob», «Alice»] slice_people3 = people[1:6:2] # с 1 по 6 с шагом 2 print(slice_people3) # [«Bob», «Sam», «Bill»]
Можно использовать отрицательные индексы, тогда отсчет будет идти с конца, например, -1 — предпоследний, -2 — третий сконца и так далее.
people = [«Tom», «Bob», «Alice», «Sam», «Tim», «Bill»] slice_people1 = people[:-1] # с предпоследнего по нулевой print(slice_people1) # [«Tom», «Bob», «Alice», «Sam», «Tim», «Bill»] slice_people2 = people[-3:-1] # с третьего с конца по предпоследний print(slice_people2) # [ «Sam», «Tim»]
Методы и функции по работе со списками
Для управления элементами списки имеют целый ряд методов. Некоторые из них:
- append(item) : добавляет элемент item в конец списка
- insert(index, item) : добавляет элемент item в список по индексу index
- extend(items) : добавляет набор элементов items в конец списка
- remove(item) : удаляет элемент item. Удаляется только первое вхождение элемента. Если элемент не найден, генерирует исключение ValueError
- clear() : удаление всех элементов из списка
- index(item) : возвращает индекс элемента item. Если элемент не найден, генерирует исключение ValueError
- pop([index]) : удаляет и возвращает элемент по индексу index. Если индекс не передан, то просто удаляет последний элемент.
- count(item) : возвращает количество вхождений элемента item в список
- sort([key]) : сортирует элементы. По умолчанию сортирует по возрастанию. Но с помощью параметра key мы можем передать функцию сортировки.
- reverse() : расставляет все элементы в списке в обратном порядке
- copy() : копирует список
Кроме того, Python предоставляет ряд встроенных функций для работы со списками:
- len(list) : возвращает длину списка
- sorted(list, [key]) : возвращает отсортированный список
- min(list) : возвращает наименьший элемент списка
- max(list) : возвращает наибольший элемент списка
Добавление и удаление элементов
Для добавления элемента применяются методы append() , extend и insert , а для удаления — методы remove() , pop() и clear() .
people = [«Tom», «Bob»] # добавляем в конец списка people.append(«Alice») # [«Tom», «Bob», «Alice»] # добавляем на вторую позицию people.insert(1, «Bill») # [«Tom», «Bill», «Bob», «Alice»] # добавляем набор элементов [«Mike», «Sam»] people.extend([«Mike», «Sam»]) # [«Tom», «Bill», «Bob», «Alice», «Mike», «Sam»] # получаем индекс элемента index_of_tom = people.index(«Tom») # удаляем по этому индексу removed_item = people.pop(index_of_tom) # [«Bill», «Bob», «Alice», «Mike», «Sam»] # удаляем последний элемент last_item = people.pop() # [«Bill», «Bob», «Alice», «Mike»] # удаляем элемент «Alice» people.remove(«Alice») # [«Bill», «Bob», «Mike»] print(people) # [«Bill», «Bob», «Mike»] # удаляем все элементы people.clear() print(people) # []
Проверка наличия элемента
Если определенный элемент не найден, то методы remove и index генерируют исключение. Чтобы избежать подобной ситуации, перед операцией с элементом можно проверять его наличие с помощью ключевого слова in :
people = [«Tom», «Bob», «Alice», «Sam»] if «Alice» in people: people.remove(«Alice») print(people) # [«Tom», «Bob», «Sam»]
Выражение if «Alice» in people возвращает True, если элемент «Alice» имеется в списке people. Поэтому конструкция if «Alice» in people может выполнить последующий блок инструкций в зависимости от наличия элемента в списке.
Удаление с помощью del
Python также поддерживает еще один способ удаления элементов списка — с помощью оператора del . В качестве параметра этому оператору передается удаляемый элемент или набор элементов:
people = [«Tom», «Bob», «Alice», «Sam», «Bill», «Kate», «Mike»] del people[1] # удаляем второй элемент print(people) # [«Tom», «Alice», «Sam», «Bill», «Kate», «Mike»] del people[:3] # удаляем по четвертый элемент не включая print(people) # [«Bill», «Kate», «Mike»] del people[1:] # удаляем со второго элемента print(people) # [«Bill»]
Подсчет вхождений
Если необходимо узнать, сколько раз в списке присутствует тот или иной элемент, то можно применить метод count() :
people = [«Tom», «Bob», «Alice», «Tom», «Bill», «Tom»] people_count = people.count(«Tom») print(people_count) # 3
Сортировка
Для сортировки по возрастанию применяется метод sort() :
people = [«Tom», «Bob», «Alice», «Sam», «Bill»] people.sort() print(people) # [«Alice», «Bill», «Bob», «Sam», «Tom»]
Если необходимо отсортировать данные в обратном порядке, то мы можем после сортировки применить метод reverse() :
people = [«Tom», «Bob», «Alice», «Sam», «Bill»] people.sort() people.reverse() print(people) # [«Tom», «Sam», «Bob», «Bill», «Alice»]
При сортировке фактически сравниваются два объекта, и который из них «меньше», ставится перед тем, который «больше». Понятия «больше» и «меньше» довольно условны. И если для чисел все просто — числа расставляются в порядке возрастания, то для строк и других объектов ситуация сложнее.
В частности, строки оцениваются по первым символам. Если первые символы равны, оцениваются вторые символы и так далее. При чем цифровой символ считается «меньше», чем алфавитный заглавный символ, а заглавный символ считается меньше, чем строчный.
Таким образом, если в списке сочетаются строки с верхним и нижним регистром, то мы можем получить не совсем корректные результаты, так как для нас строка «bob» должна стоять до строки «Tom». И чтобы изменить стандартное поведение сортировки, мы можем передать в метод sort() в качестве параметра функцию:
people = [«Tom», «bob», «alice», «Sam», «Bill»] people.sort() # стандартная сортировка print(people) # [«Bill», «Sam», «Tom», «alice», «bob»] people.sort(key=str.lower) # сортировка без учета регистра print(people) # [«alice», «Bill», «bob», «Sam», «Tom»]
Кроме метода sort мы можем использовать встроенную функцию sorted , которая имеет две формы:
- sorted(list) : сортирует список list
- sorted(list, key) : сортирует список list, применяя к элементам функцию key
people = [«Tom», «bob», «alice», «Sam», «Bill»] sorted_people = sorted(people, key=str.lower) print(sorted_people) # [«alice», «Bill», «bob», «Sam», «Tom»]
При использовании этой функции следует учитывать, что эта функция не изменяет сортируемый список, а все отсортированные элементы она помещает в новый список, который возвращается в качестве результата.
Минимальное и максимальное значения
Встроенный функции Python min() и max() позволяют найти минимальное и максимальное значения соответственно:
numbers = [9, 21, 12, 1, 3, 15, 18] print(min(numbers)) # 1 print(max(numbers)) # 21
Копирование списков
При копировании списков следует учитывать, что списки представляют изменяемый (mutable) тип, поэтому если обе переменных будут указывать на один и тот же список, то изменение одной переменной, затронет и другую переменную:
people1 = [«Tom», «Bob», «Alice»] people2 = people1 people2.append(«Sam») # добавляем элемент во второй список # people1 и people2 указывают на один и тот же список print(people1) # [«Tom», «Bob», «Alice», «Sam»] print(people2) # [«Tom», «Bob», «Alice», «Sam»]
Это так называемое «поверхностное копирование» (shallow copy). И, как правило, такое поведение нежелательное. И чтобы происходило копирование элементов, но при этом переменные указывали на разные списки, необходимо выполнить глубокое копирование (deep copy). Для этого можно использовать метод copy() :
people1 = [«Tom», «Bob», «Alice»] people2 = people1.copy() # копируем элементы из people1 в people2 people2.append(«Sam») # добавляем элемент ТОЛЬКО во второй список # people1 и people2 указывают на разные списки print(people1) # [«Tom», «Bob», «Alice»] print(people2) # [«Tom», «Bob», «Alice», «Sam»]
Соединение списков
Для объединения списков применяется операция сложения (+):
people1 = [«Tom», «Bob», «Alice»] people2 = [«Tom», «Sam», «Tim», «Bill»] people3 = people1 + people2 print(people3) # [«Tom», «Bob», «Alice», «Tom», «Sam», «Tim», «Bill»]
Списки списков
Списки кроме стандартных данных типа строк, чисел, также могут содержать другие списки. Подобные списки можно ассоциировать с таблицами, где вложенные списки выполняют роль строк. Например:
people = [ [«Tom», 29], [«Alice», 33], [«Bob», 27] ] print(people[0]) # [«Tom», 29] print(people[0][0]) # Tom print(people[0][1]) # 29
Чтобы обратиться к элементу вложенного списка, необходимо использовать пару индексов: people[0][1] — обращение ко второму элементу первого вложенного списка.
Добавление, удаление и изменение общего списка, а также вложенных списков аналогично тому, как это делается с обычными (одномерными) списками:
people = [ [«Tom», 29], [«Alice», 33], [«Bob», 27] ] # создание вложенного списка person = list() person.append(«Bill») person.append(41) # добавление вложенного списка people.append(person) print(people[-1]) # [«Bill», 41] # добавление во вложенный список people[-1].append(«+79876543210») print(people[-1]) # [«Bill», 41, «+79876543210»] # удаление последнего элемента из вложенного списка people[-1].pop() print(people[-1]) # [«Bill», 41] # удаление всего последнего вложенного списка people.pop(-1) # изменение первого элемента people[0] = [«Sam», 18] print(people) # [ [«Sam», 18], [«Alice», 33], [«Bob», 27]]
Перебор вложенных списков:
people = [ [«Tom», 29], [«Alice», 33], [«Bob», 27] ] for person in people: for item in person: print(item, end=» | «)
Tom | 29 | Alice | 33 | Bob | 27 |
Источник: metanit.com
Списки в Python: что это такое и как с ними работать
Рассказали всё самое важное о списках для тех, кто только становится «змееустом».

Иллюстрация: Оля Ежак для Skillbox Media

Дмитрий Зверев
Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Сегодня мы подробно поговорим о, пожалуй, самых важных объектах в Python — списках. Разберём, зачем они нужны, как их использовать и какие удобные функции есть для работы с ними.
В статье есть всё, что начинающим разработчикам нужно знать о списках в Python:
- Что это такое
- Как создавать списки в Python
- Какие с ними можно выполнять операции
- Как работать совстроенными функциями
- Какие вPython есть методы управления элементами
Что такое списки
Список (list) — это упорядоченный набор элементов, каждый из которых имеет свой номер, или индекс, позволяющий быстро получить к нему доступ. Нумерация элементов в списке начинается с 0: почему-то так сложилось в C, а C — это база. Теорий на этот счёт много — на «Хабре» даже вышло большое расследование 🙂
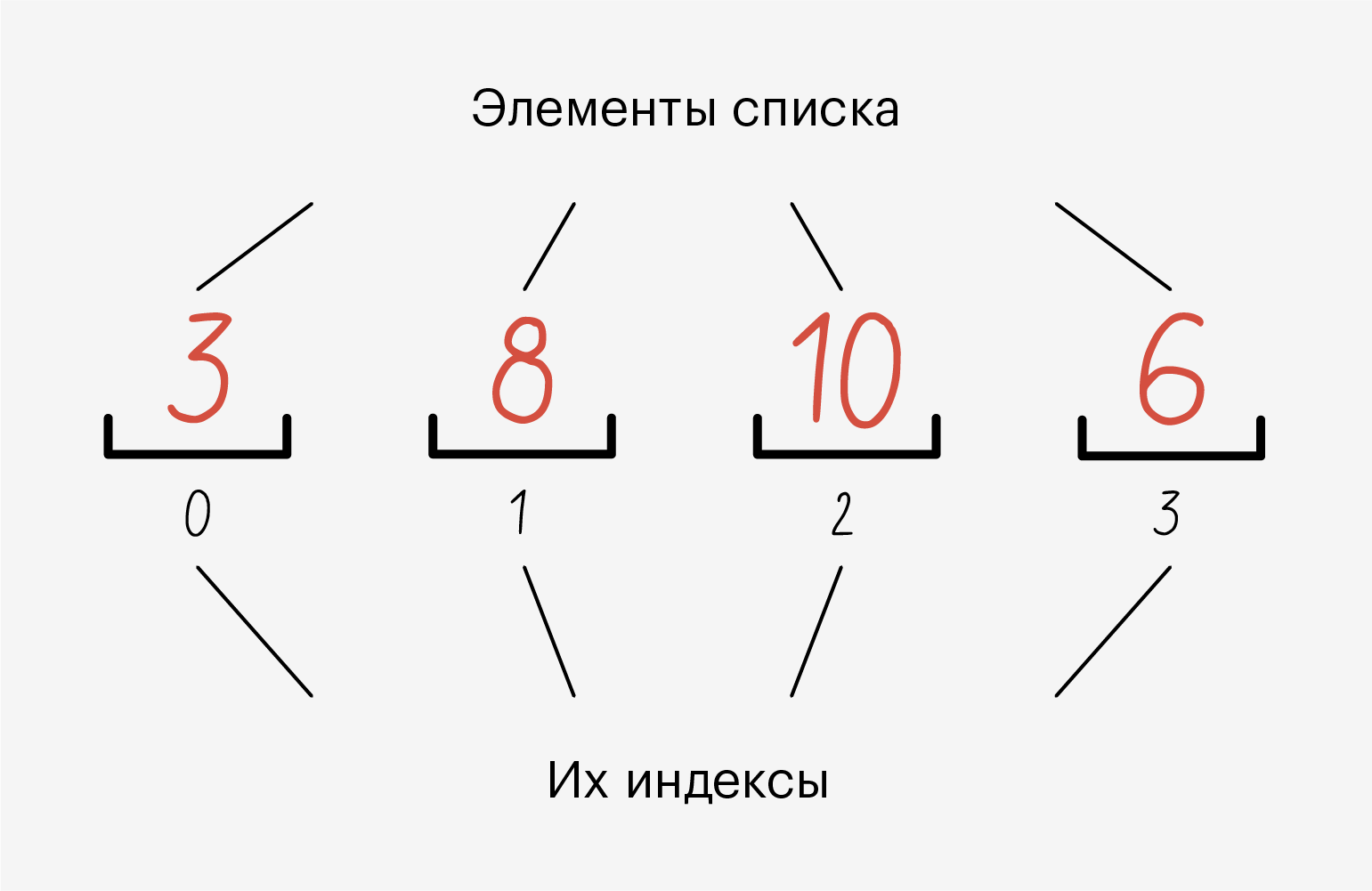
В одном списке одновременно могут лежать данные разных типов — например, и строки, и числа. А ещё в один список можно положить другой и ничего не сломается:
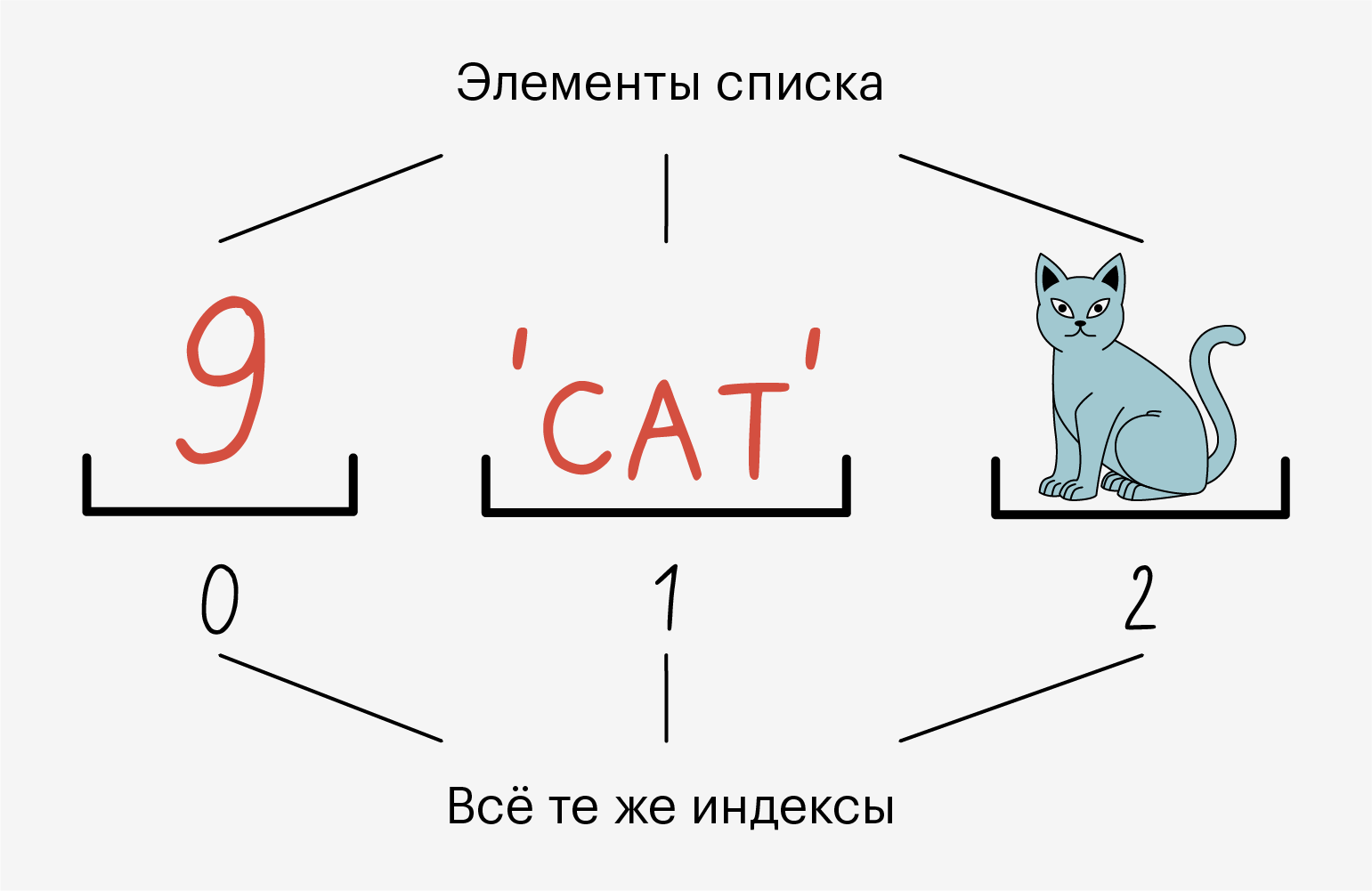
Все элементы в списке пронумерованы. Мы можем без проблем узнать индекс элемента и обратиться по нему.
Списки называют динамическими структурами данных, потому что их можно менять на ходу: удалить один или несколько элементов, заменить или добавить новые.
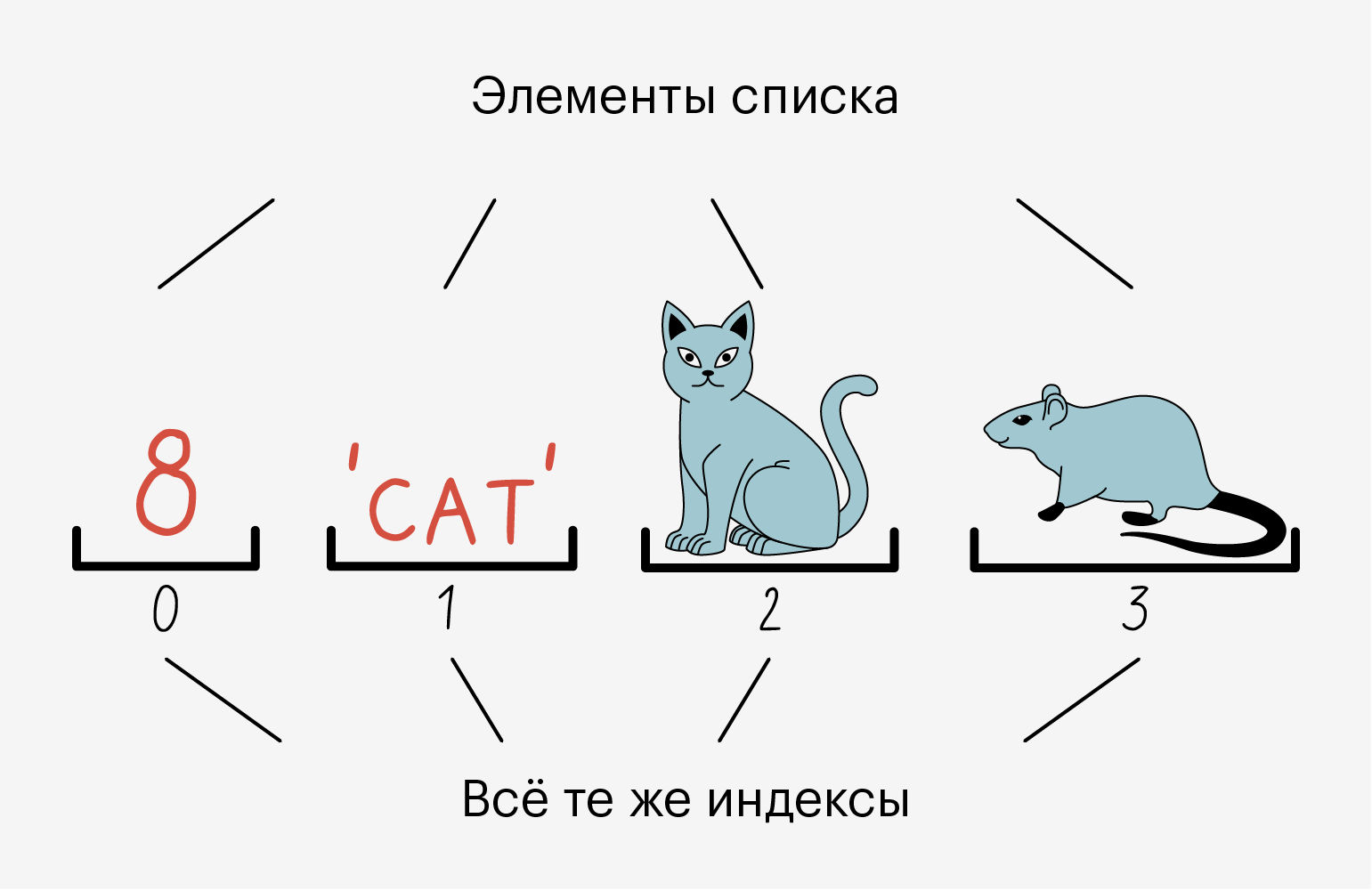
Когда мы создаём объект list, в памяти компьютера под него резервируется место. Нам не нужно переживать о том, сколько выделяется места и когда оно освобождается, — Python всё сделает сам. Например, когда мы добавляем новые элементы, он выделяет память, а когда удаляем старые — освобождает.
Под капотом списков в Python лежит структура данных под названием «массив». У массива есть два важных свойства: под каждый элемент он резервирует одинаковое количество памяти, а все элементы следуют друг за другом, без «пробелов».
Однако в списках Python можно хранить объекты разного размера и типа. Более того, размер массива ограничен, а размер списка в Python — нет. Но всё равно мы знаем, сколько у нас элементов, а значит, можем обратиться к любому из них с помощью индексов.
И тут есть небольшой трюк: списки в Python представляют собой массив ссылок. Да-да, решение очень элегантное — каждый элемент такого массива хранит не сами данные, а ссылку на их расположение в памяти компьютера!
Как создать список в Python
Чтобы создать объект list, в Python используют квадратные скобки — []. Внутри них перечисляют элементы через запятую:

Операции со списками
Если просто хранить данные в списках, то от них будет мало толку. Поэтому давайте рассмотрим, какие операции они позволяют выполнить.
Индексация
Доступ к элементам списка получают по индексам, через квадратные скобки []:
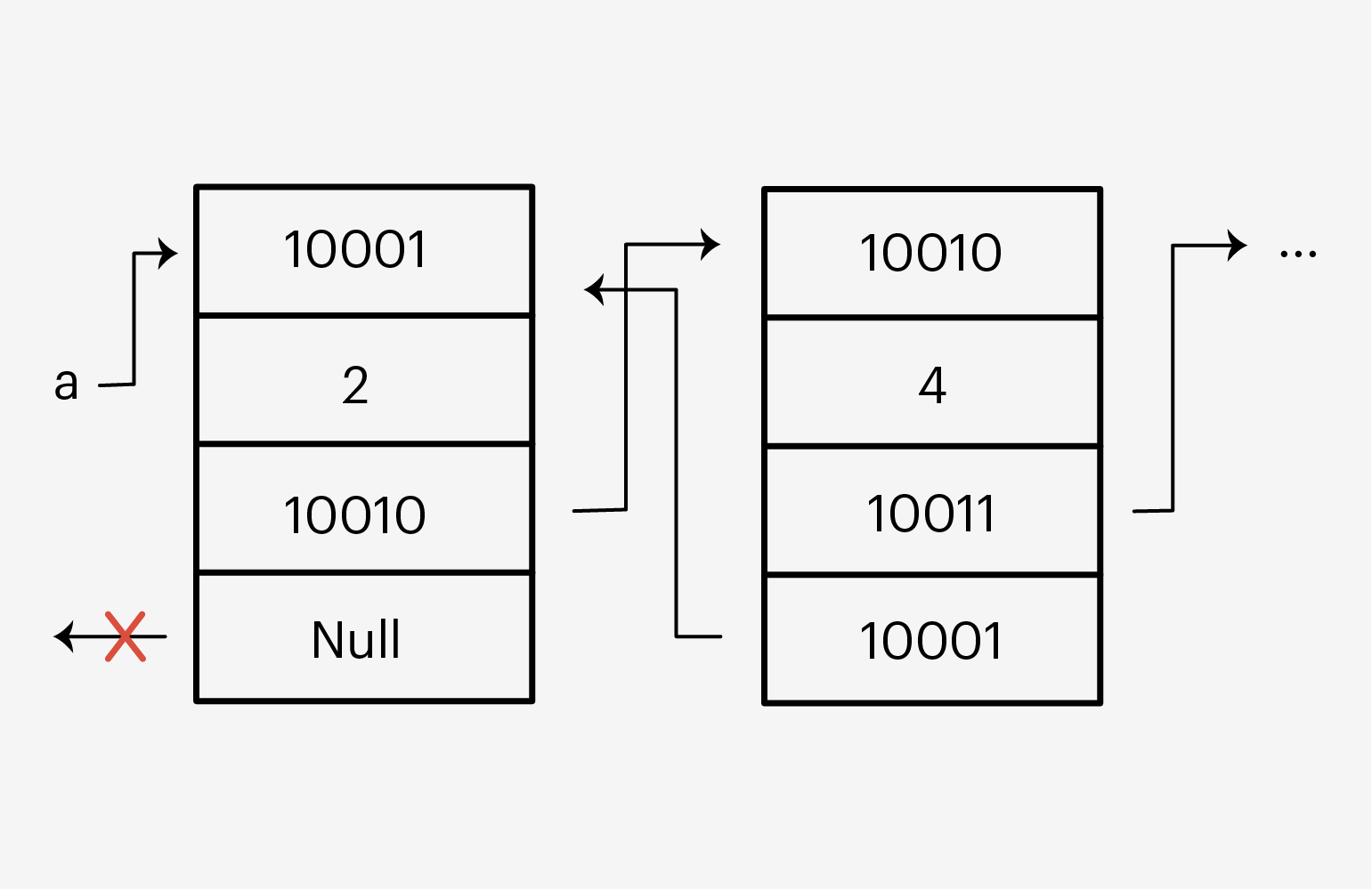
Каждый элемент списка имеет четыре секции: свой адрес, данные, адрес следующего элемента и адрес предыдущего. Если мы получили доступ к какому-то элементу, мы без проблем можем двигаться вперёд-назад по этому списку и менять его данные.
Поэтому, когда мы присвоили списку b список a, то на самом деле присвоили ему ссылку на первый элемент — по сути, сделав их одним списком.
Объединение списков
Иногда полезно объединить два списка. Чтобы это сделать, используют оператор +:

insert()
Добавляет новый элемент по индексу:

clear()
Удаляет все элементы из списка и делает его пустым:
a = [1, 2, 3] a.clear() print(a) >>> []
index()
Возвращает индекс элемента списка в Python:
a = [1, 2, 3] print(a.index(2)) >>> 1
Если элемента нет в списке, выведется ошибка:
a = [1, 2, 3] print(a.index(4)) Traceback (most recent call last): File «», line 1, in ValueError: 4 is not in list
pop()
Удаляет элемент по индексу и возвращает его как результат:
a = [1, 2, 3] print(a.pop()) print(a) >>> 3 >>> [1, 2]
[ Сборник задач ]
Тема 4. Работа со списками
Несколько слов о том, что из себя представляют списки в Python, и какие операции можно с ними выполнять.
Вопросы и ответы
5 вопросов по теме «Списки» + ответы
Условия задач
6 задач по теме двух уровней сложности: Базовый и *Продвинутый
Решения задач
Приводим код решений указанных выше задач

Список – последовательность элементов, объединенных в один контейнер. Главная особенность – они изменяемы.
Элементы списка индексируются, состоят в основном из однотипных данных, перебираются, сохраняют порядок.
Для решения заданий необходимо повторить свойства и методы списков.
Программирование на Python. Урок 2. Типы данных
Разбираем типы данных в Python: списки, кортежи, словари, множества и т. д. Рассматриваем часто используемые способы ввода-вывода данных. Решаем задачи.

Вопросы по теме «Работа со списками»
1. Перечислите характеристики типа данных «список», которые вы знаете.
Свойств много. Озвучим некоторые:
1. Списки изменяются динамически (вы можете создать пустой список, потом добавить в него ряд элементов, затем удалить часть из них – и все это будет осуществляться в одном контейнере, относиться к одной и той же переменной);
2. К элементам списка можно получить доступ по индексу (начиная с нулевого). Индексация бывает и обратной, отрицательной (индекс -1 обозначает последний элемент списка, -2 – предпоследний и т.д.);
3. В списках может содержаться ряд элементов любых типов (числа, строки, другие списки …);
4. У списков имеется большое разнообразие методов, позволяющих осуществлять операции с ними (расширять, удалять элементы, очищать, сортировать);
5. Списки можно «резать», т.е. формировать более мелкие последовательности на основании имеющейся;
6. Значения элементов могут повторяться.
2. Как проверить наличие элемента в списке?
Есть 2 очевидных способа:
1. При помощи конструкции in:
Пример – IDE
lst = [1, 2, 3, 14, 33, 1, 1]
if 1 in lst:
____print(‘Есть’)
Результат:
Есть
2. При помощи метода count:
Пример – IDE
lst = [1, 2, 3, 14, 33, 1, 1]
if lst.count(5):
____print(‘Есть’)
else:
____print(‘Нет’)
Результат:
Нет
3. Чем отличаются методы append() и extend()?
Метод append() добавляет в конец текущего списка новый элемент.
Метод extend() добавляет в конец текущего списка новые элементы в распакованном виде.
Посмотрим отличия на примере.
Пример – IDE
lst = [1, 2, 3, 14, 33, 1, 1]
lst.extend(‘Добавка’)
print(lst)
Результат:
[1, 2, 3, 14, 33, 1, 1, ‘Д’, ‘о’, ‘б’, ‘а’, ‘в’, ‘к’, ‘а’]
Пример – IDE
lst = [1, 2, 3, 14, 33, 1, 1]
lst.append(‘Добавка’)
print(lst)
Результат:
[1, 2, 3, 14, 33, 1, 1, ‘Добавка’]
4. Какие параметры можно передавать при срезах списков?
Для срезов можно пользоваться функцией slice() или специальным сокращением, куда входит 3 параметра: начало среза (по умолчанию – первый элемент), конец среза (конечный член списка, не включая его), шаг (по умолчанию – 1, т.е. выбираем все элементы без пропусков).
Пример – IDE
h = [1, 2, 3, 14, 33, 1, 9]
print(h[slice(2, 6, 2)])
Результат:
[3, 33]
Т.е. создаем новый список начиная с элемента с индексом 2 (в нашем случае это цифра 3) вплоть до 6 элемента (не включая его) с шагом 2 (пропускаем каждое второе значение).
Часть или все параметры можно опускать в специальных сокращениях.
Пример – IDE
h = [1, 2, 3, 14, 33, 1, 9]
print(h[2:6:2])
print(h[::2])
Результат:
[3, 33]
[1, 3, 33, 9]
5*. Что произойдет со списком lst1 в первом и втором случаях? Поясните результат.
Случай 1 – IDE
lst1 = [1, 2, 3, 14, 33, 1, 9]
lst2 = [1, 2, 3, 14, 33, 1, 9]
lst2.append(789)
Случай 2 – IDE
lst1 = [1, 2, 3, 14, 33, 1, 9]
lst2 = lst1
lst2.append(789)
В первом случае список lst1 не изменится, во втором – в нем появится новый элемент 789.
Первый пример показывает создание двух разных списков, хоть и являющихся равными. Тем не менее они занимают разные области в памяти. И изменение одного из списков не вызывает аналогичного поведения в другом.
Во втором примере обе переменные ссылаются на один список, поэтому модификация любой из них отразится на другой.
# Тест случая 1
lst1 = [1, 2, 3, 14, 33, 1, 9]
lst2 = [1, 2, 3, 14, 33, 1, 9]
lst2.append(789)
print(lst1, lst2, sep=’n’)
Результат:
[1, 2, 3, 14, 33, 1, 9]
[1, 2, 3, 14, 33, 1, 9, 789]
# Тест случая 2
lst1 = [1, 2, 3, 14, 33, 1, 9]
lst2 = lst1
lst1.append(789)
print(lst1, lst2, sep=’n’)
Результат:
[1, 2, 3, 14, 33, 1, 9, 789]
[1, 2, 3, 14, 33, 1, 9, 789]
Источник: smartiqa.ru