
Презентация на тему: » Системы распознавания текста Технология обработки текстовой информации.» — Транскрипт:
1 Системы распознавания текста Технология обработки текстовой информации
2 Необходимость в системах распознавания символов С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Однако работать с таким текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой графический файл — обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать элементы графического изображения в последовательности текстовых символов.
3 Программы распознавания текста Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR). Наиболее распространенные системы оптического распознавания символов: ABBYY FineReader CuneiForm от Cognitive
4 Получение электронного документа 1.Отсканировать изображение (с помощью ПО сканера); 2.Распознать структуру размещения текста на странице: выделить колонки, таблицы, изображения и т.д. 3.Выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать в текст; 4.Проверка орфографии (если необходимо); 5.Сохранение в файл или передача текста в другое приложение, например в Word.
5 Методы распознавания символов Если исходный документ имеет типографское качество то задача распознавания решается методом сравнения с растровым шаблоном. При распознавании документов с низким качеством печати используется метод распознавания символов по наличию в них определенных структурных элементов (отрезков, колец, дуг и др.).
6 ABBYY FineReader FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати. FineReader имеет массы дополнительных функций и удобный интерфес.
7 Оптимальное разрешение при сканировании Оптимальным разрешением для обычных текстов является dpi и dpi для текстов, набранных мелким шрифтом (9 и менее пунктов). Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.
8 Вопросы: Зачем нужны программы распознавания текста? Как происходит распознавание текста? Какие программы распознания текста вы знаете? Какими пользовались? Какое разрешение является оптимальным для сканирования текста, изображений?
Источник: www.myshared.ru
Презентация на тему Системы распознавания текста
Необходимость в системах распознавания символов С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Однако работать с таким текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой графический файл — обычную картинку. Текст можно будет читать
- Главная
- Информатика
- Системы распознавания текста








Слайды и текст этой презентации
Слайд 1 Системы распознавания текста
Технология обработки текстовой информации
Слайд 2 Необходимость в системах распознавания символов
С помощью сканера достаточно
просто получить изображение страницы текста в графическом файле. Однако
работать с таким текстом невозможно: как любое сканированное изображение, страница
с текстом представляет собой графический файл — обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать элементы графического изображения в последовательности текстовых символов.
Слайд 3 Программы распознавания текста
Преобразованием графического изображения в текст занимаются
специальные программы распознавания текста (Optical Character Recognition — OCR).
Наиболее
распространенные системы оптического распознавания символов:
BBYY FineReader
CuneiForm от Cognitive
Слайд 4 Получение электронного документа
Отсканировать изображение (с помощью ПО сканера);
Распознать
структуру размещения текста на странице: выделить колонки, таблицы, изображения
и т.д.
Выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать
в текст;
Проверка орфографии (если необходимо);
Сохранение в файл или передача текста в другое приложение, например в Word.
Слайд 5 Методы распознавания символов
Если исходный документ имеет типографское качество
то задача распознавания решается методом сравнения с растровым шаблоном.
При распознавании документов с низким качеством печати используется метод распознавания
символов по наличию в них определенных структурных элементов (отрезков, колец, дуг и др.).
Слайд 6 ABBYY FineReader
FineReader — омнифонтовая система оптического распознавания текстов.
Это означает, что она позволяет распознавать тексты, набранные практически
любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая
точность распознавания и малая чувствительность к дефектам печати.
FineReader имеет массы дополнительных функций и удобный интерфес.
Слайд 7 Оптимальное разрешение при сканировании
Оптимальным разрешением для обычных текстов
является — 300 dpi и 400-600 dpi для текстов,
набранных мелким шрифтом (9 и менее пунктов).
Сканирование в сером является
оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.
Источник: mypreza.com
Программы распознавания текста

Распознавание текста на отсканированных или сфотографированных документах довольно актуальная задача: в офисах нередко требуется оцифровать входящую корреспонденцию, то или иное постановление и т. д., а студентам при подготовке рефератов и курсовых работ приходится вставлять выдержки из бумажных либо электронных книг в формате DJVU. Да и просто взять текст с сайта, на котором копирование не работает, тоже проще всего через распознавание текста на скриншоте.
Тем, у кого потребность в распознавании текста возникает не чаще раза в месяц, можно посоветовать любой профильный онлайн-сервис или же всем известные бесплатные OneNote и «Google Документы». Можно воспользоваться и пакетом Adobe Acrobat. Однако для работы с большим количеством документов все перечисленные программы неудобны. В связи с этим рассмотрим несколько специализированных решений, созданных для распознавания текста и подходящих для постоянной работы с отсканированными документами.
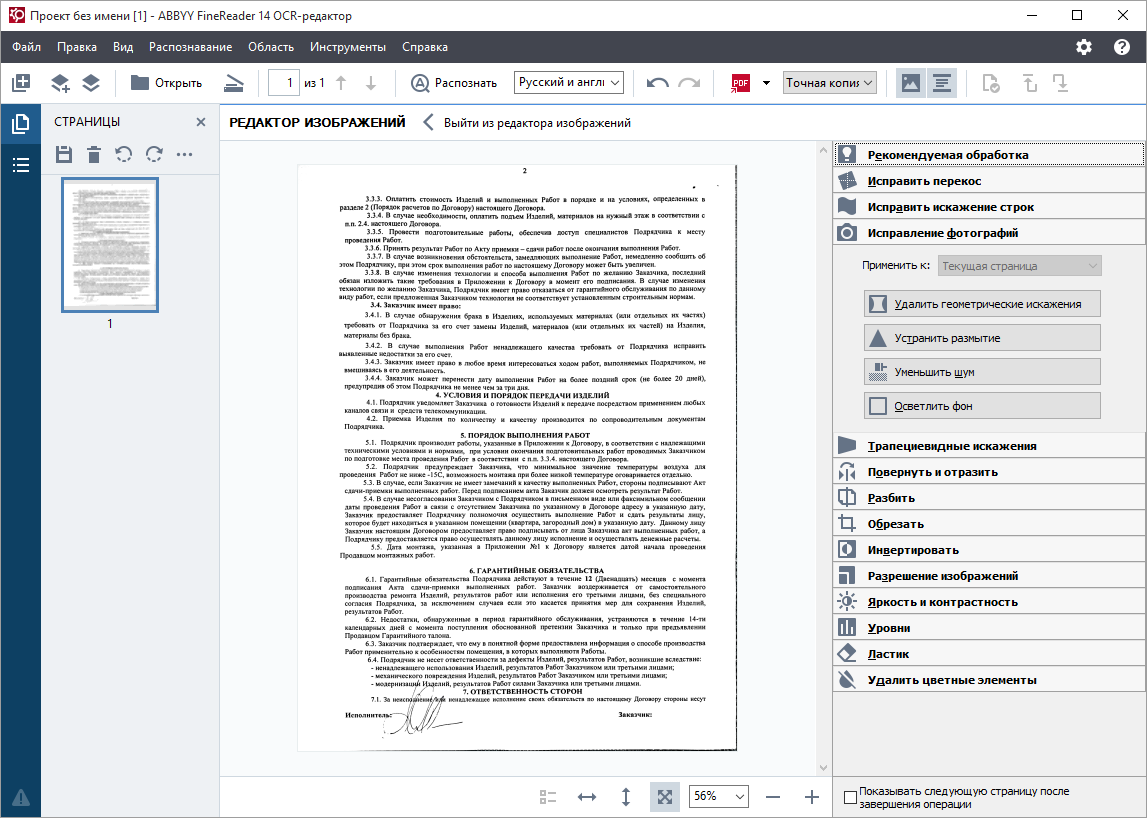
Вам будет интересно: Как оснастить конференц-комнату
Эта программа, пожалуй, не менее популярна в своем сегменте, чем Adobe Photoshop среди графических редакторов. И причина, конечно же, не только в продуманной маркетинговой политике, но прежде всего в высокой точности распознавания текста на многих языках и множестве дополнительных возможностей. Последняя версия продукта – 14-я.
Основные преимущества ABBYY Finereader:
Вам будет интересно: Как отключить обновления в Windows 10?
Из недостатков можно назвать один, но довольно существенный: бессрочная лицензия самой дешевой версии FineReader стоит 6990 рублей, а подписка на год – 3190 рублей. Но для тех, кто постоянно работает с документами, причем это является частью их бизнеса, данный недостаток вряд ли станет препятствием для приобретения продукта.
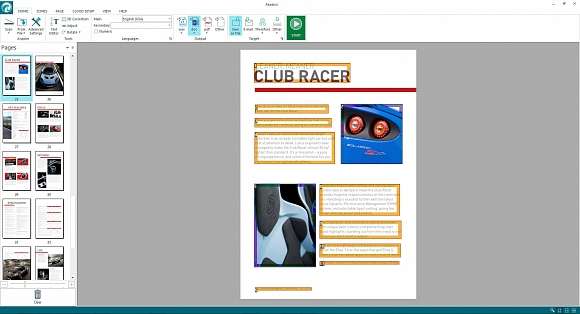
Довольно мощное решение для распознавания текста в отсканированных документах. Программа совсем немного уступает FineReader в основном назначении и даже имеет дополнительные инструменты, которые отсутствуют у лидера. В настоящий момент актуальна 17-я версия.
Пакет предлагается в двух версиях – Readiris Pro и Readiris Corporate (поддерживает еще пакетную обработку документов и создание PDF/A). Обе распространяются с постоянными лицензиями: первая стоит €99, вторая – €199. Как видим, самая дешевая сопоставима по цене с младшей версией FineReader. Так как различия по функциональности непринципиальны, то при выборе стоит ориентироваться на удобство для конкретного пользователя.
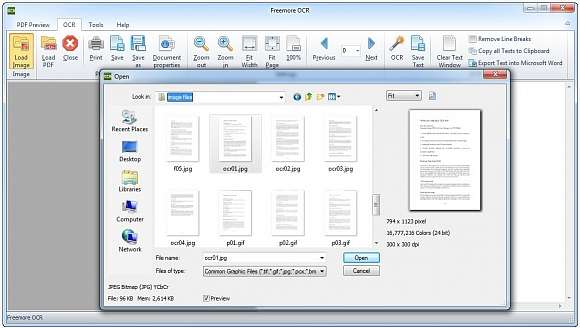
Абсолютно бесплатная программа, однако и по функциональности, и по удобству она уступает двум предыдущим. К тому же вместе с Freemore OCR пытается установиться различный рекламный мусор, чему активно сопротивляется антивирус.
Особенности Freemore OSR:
1. По умолчанию поддерживается распознавание только английского текста. Пакеты других языков нужно загружать дополнительно.
2. Наличие встроенного инструмента сканирования документов.
3. Поддержка распознавания текста с графических файлов JPG/JPEG, TIF, TIFF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и т. д.
5. Экспорт обработанного текста в Microsoft Office.
6. Форматирование исходного документа программа, к сожалению, не сохраняет.
Как видим, бесплатное решение явно на уровень ниже развитых платных аналогов. Но все же Freemore OCR распознает текст лучше, чем онлайн-сервисы или программы, в которых эта функция встроена в качестве дополнительной (например, тот же OneNote с ошибками распознает скриншот с самого себя). Да и удобнее при работе с большим количеством документов использовать именно специализированную программу. В общем, если финансовая ситуация сложная, Freemore OCR может стать выходом. Только стоить учесть, что и с установкой этого продукта придется помучиться.
Каких-то пять-десять лет назад конкуренция в сегменте программ распознавания текста была выше и количество таких продуктов было больше. Но теперь в явные лидеры выбились FineReader и Readiris Pro, оставив соперников далеко позади.
Что же касается бесплатных решений, то их предложение заметно сузилось. Помнится, CuneiForm распознавала текст почти как FineReader, да и по функциональности не слишком уступала, однако ее поддержка прекращена, как и ряда других аналогов. Похоже, эту нишу прочно заняли онлайн-сервисы и продолжать поддержку программ не имеет смысла.
Источник: 1ku.ru