
ABBYY FineReader Cистема оптического распознавания текста. С помщью этой программы можно быстро и точно переводить бумажные документы, PDF-файлы и цифровые фотографии документов в редактируемый формат.
Лицензия: Платно
Горыныч Программа для распознавания устной речи и набора текста методом диктовки. С его помощью вы сможете набрать текст просто прочитав его в микрофон.
Spell Checker Программа для проверки орфографии, которая работает с любым другим ПО и легко натсраивается под нужды конкретного пользователя.
Tesseract Программа для распознавания текстов. В настоящий момент программа умеет работать с UTF-8, а поддержка различных языков осуществляется с помощью дополнительных модулей.
Tesseract It! Утилита для распознавания текста в отсканированных документах. Очень проста в использовании и не требует дополнительных настроек.
EZSignIt Digital Code Signer EZSignIt Digital Code Signer — эта программа предназначена для подписи одного или нескольких файлов цифровыми сертификатами.
Как распознать текст с картинки, как из картинки получить форматируемый текст
Распознавание, статьи
Как активировать Office 365: все способы активации
27 Февраль 2019
Как открыть файл
Файл формата DOCX: чем открыть, описание, особенности
05 Февраль 2019
Пять альтернатив Microsoft Office
18 Февраль 2019
Как открыть файл
Файл формата pptx: чем открыть, описание, особенности
14 Февраль 2019
Post Graph Editor Программа для полуавтоматической оцифровки любых отсканированных графиков. В качестве исходного материала программа использу…
DataMatrix Recognizer Программа DataMatrix Recognizer предназначена для распознавания, декодирования и кодирования кодов DataMatrix. Осуществлена поддержка графических форматов JPEG, GIF, BMP.
SSuite Office — Spell Checker Самостоятельное приложение для проверки орфографии. В состав входит множество словарей, поддерживаются разные языки.
Extract Words From Text and HTML Files Extract Words From Text and HTML Files — это программа, которая позволяет извлекать текст из HTML файлов или текстовых файлов.
KyrSpell Орфографический модуль проверки орфографии киргизского языка, тезаурус (словарь синонимов) и расстановки переноса в приложениях Microsoft Office и других приложениях.
Canon MF Toolbox С помощью этой программы вы сможете сделать процесс сканирования ещё удобнее, а также получите возможность быстро приступить к работе с полученными сканами.
STP Программа для сканирования в формат PDF. Сканирует сразу в jpeg файл, а так же конвертирует несколько jpeg файлов в один pdf документ.
Scanitto Pro Программа для сканирования и распознавания текстов. Она может работать практически с любым сканером.
Лицензия: Платно
OCR CuneiForm Мощная система оптического распознавания текста. Эта программа поможет превратить скан документа или книги в редактируемый документ.
QR Code Reader QR Code Reader для Windows – настольный считыватель и генератор куар кода. Приложение сканирует шифр с экрана ПК, из папок, файлов или через веб-камеру, сохраняет информацию.
Распознавание текста с картинки. Python Tesseract ORC + OpenCV
- Программы для распознования на Windows — установка безопасна для ваших компьютеров. Более 40 антивирусных систем следят за чистотой программного обеспечения.
- FreeSoft обеспечивает быстрое и удобное скачивание лицензионных программ, официально переведенных на русский язык. Мы не распространяем взломанные или пиратские дистрибутивы.
- Тип лицензий указан в описаниях: большинство — бесплатны.
- Если нашли ошибки в коллекции или описаниях, пожалуйста, напишите нам по адресу [email protected]. В теме укажите слово «ошибка».
Источник: freesoft.ru
7 бесплатных программ и веб-сервисов для распознавания текста


С помощью этих инструментов вы сможете извлечь текстовое содержимое изображений и бумаг, чтобы работать с ним с максимальным комфортом.
1. Office Lens
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в мощный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы можно редактировать в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens.
Price: Free
Price: Free
Developer: Microsoft Corporation
Price: Free
2. Adobe Scan
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Результаты удобно экспортировать в кросс-платформенный сервис Adobe Acrobat, который позволяет редактировать PDF-файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
Price: Free +
Price: Free
3. Free OCR to Word
- Распознаёт: JPG, TIF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и другие форматы.
- Сохраняет: DOC, DOCX, TXT.
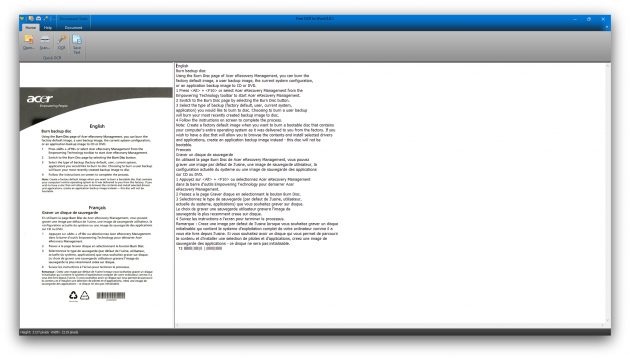
Настольная программа Free OCR to Word распознаёт выбранные пользователем изображения, извлекая из них чистый текст без форматирования. Его можно копировать в буфер обмена, сохранять в формате TXT или экспортировать в Word.
4. FineReader Online
- Распознаёт: JPG, TIF, BMP, PNG, PCX, DCX, PDF (не защищённые паролем).
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A.
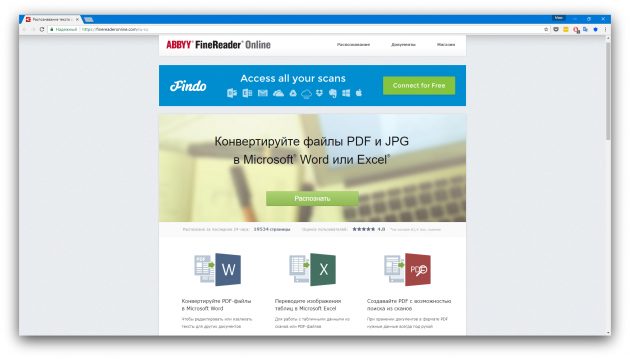
Онлайновый сервис, который конвертирует не только тексты, но и таблицы. Увы, бесплатные возможности FineReader Online ограничены. После регистрации вам позволят распознать без оплаты всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Поэтому сервис больше подойдёт тем, кто не нуждается в услугах распознавания слишком часто.
5. Online OCR
- Распознаёт: JPG, BMP, TIFF, GIF, PDF.
- Сохраняет: DOCX, XLSX, TXT.
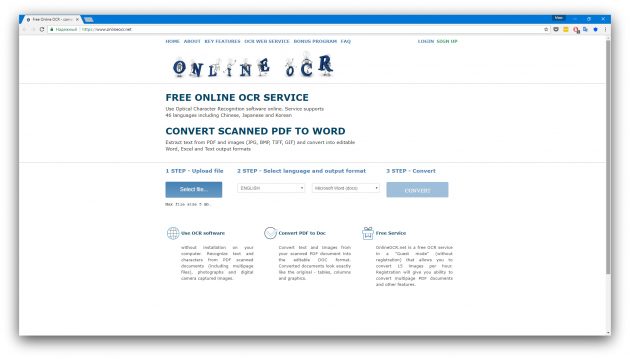
Ещё один сайт, с помощью которого можно распознать тексты и таблицы. В отличие от FineReader, в Online OCR вполне можно обойтись без регистрации. Хотя она может понадобиться, если вы планируете загружать несколько файлов для распознавания за один раз. В то же время FineReader поддерживает больше форматов.
6. Free OCR
- Распознаёт: JPG, GIF, TIFF BMP, PNG, PDF.
- Сохраняет: TXT.
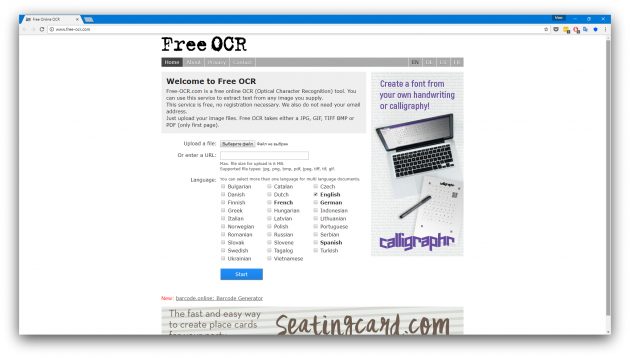
Free OCR — простейший онлайн-сервис, извлекающий текст из PDF-файлов и изображений. Результат распознавания — чистый текст без форматирования. Кроме того, сервис может уступать по точности вышеперечисленным аналогам. Зато Free OCR не требует регистрации и справляется с мультиязычными документами.
7. Microsoft OneNote
- Распознаёт: популярные форматы изображений.
- Сохраняет: файлы OneNote.
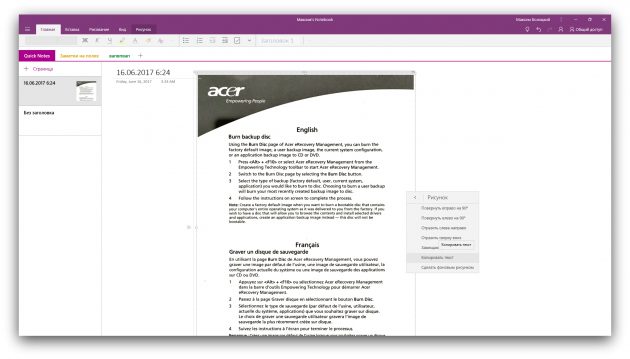
В настольной версии популярного заметочника OneNote тоже есть функция распознавания текста, которая работает с загруженными в сервис изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Рисунок» ? «Текст», то всё текстовое содержимое будет скопировано в буфер обмена.
Источник: comdas.ru
Какие из этих программ являются платными бесплатными для распознавания текста

- Услуги сканирования
- Распознавание текста документов
- Распознавание и оцифровка книг
- Обработка анкет
- Ввод данных и информации
- Создание электронного архива документов
- Создание электронных библиотек
- Создание электронного каталога
- Преобразование информации
- Создание электронных книг
- Аутсорсинг бизнес процессов
- Аутстаффинг
- Хранение и уничтожение документов
- Архивная обработка документов
Популярное
- Сканирование документов от 1,5 руб./страница
- Сканирование книг от 4 руб./страница
- Сканирование фотографий от 10 руб./фото
- Распознавание текста от 2 руб./стр
- Сканирование чертежей формата А1 от 60 руб./стр
- Обработка анкет от 2 руб./анкета

3 руб. за одну страницу исходного документа.
Стоимость распознавания с ручной настройкой, проверкой и форматированием в среднем составляет
от 16 руб. до 39 руб. за одну страницу исходного документа.
Она зависит от времени потраченного оператором на обработку одной страницы, которое в свою очередь зависит от состояния исходного изображения (сильный фон, копия, недостаточная контрастность) и сложности структуры самого документа (наличие таблиц, рисунков, сносок, многоязычность и т.п.)
В таблице представлены примеры изображений и стоимости их распознавания:
Исходная страница
Характеристика
Стоимость

16 руб. за страницу

23 руб. за страницу

Сложная страница 1 степени
39 руб. за страницу
Сроки
В среднем на распознавание одного документа в 200-300 страниц, или книги такого же объёма уходит от 2 до 5 рабочих дней.
На крупных проектах большой штат позволяет нам обрабатывать до нескольких тысяч страниц в день.
Почему мы?
Наша компания профессионально предоставляет услуги распознавания текста документов, начиная с 2006 года. За это время мы распознали сотни тысяч страниц документов.
Наши клиенты, как правило, обращаются к нам снова и снова и вот почему:
- Большой опыт (наши операторы имеют стаж работы от 2-х до 10 лет)
- Высокое качество
- Разумные цены
- Постоплата (вы получаете результат и только после этого оплачиваете)
- Бережное обращение с документами
Этапы распознавания текста
Распознавание текста документов проводится в несколько этапов:
- Сканирование оригинала. Обычно этот процесс осуществляется в черно-белом режиме, однако при необходимости мы выполняем его в цвете или градациях серого.
- Распознавание структуры страниц. Для этого наши специалисты используют специальное программное обеспечение — Abbyy Finereader. На данный момент эта система считается лучшей, и ее алгоритм непрерывно совершенствуется, что позволяет обрабатывать документы любой сложности и практически в любом состоянии.
- Распознавание текста. На этом этапе особенно важно правильно установить параметры программы Abbyy Finereader, чтобы минимизировать ошибки распознавания. Их количество зависит от таких факторов, как полиграфическое качество исходника, размер и контрастность текста, сложность взаимного размещения элементов на странице.
- Проверка правильности распознавания. Выполняется визуально с целью выявления неправильно распознанных символов.
- Проверка орфографических ошибок. На четвертом этапе, как правило, не удается избавиться от всех ошибок, поэтому дополнительно мы проверяем орфографию, например, в текстовом редакторе Microsoft Word.
- Форматирование и оформление электронного документа. В текстовом редакторе Microsoft Word устанавливается единый формат и стиль документа, размер и тип шрифта, производится размещение и структурирование таблиц. При необходимости вручную вводится текст, формулы, таблицы, которые не удалось распознать автоматически. Мы не выполняем полностью автоматическое распознавание документа, а работаем в полуавтоматическом режиме с обязательным проведением корректировки после каждого этапа обработки. В результате в электронной версии не полностью сохраняется форматирование оригинала, но на выходе получается качественный, легко читаемый документ.
Работая с системой распознавания Abbyy Finereader много лет, наши специалисты детально изучили ее функционал и выработали особые приемы и методы обработки исходников, позволяющие проводить распознавание документов различных типов и в любом состоянии.
Благодаря современному оборудованию, идеально настроенному программному обеспечению и четко отработанному технологическому процессу себестоимость работ значительно уменьшилась, поэтому мы имеем возможность предложить заказчикам весьма привлекательные цены.
Наши цены
| Автоматическое распознавание за страницу (без проверки и корректировки результатов) | 3р. |
| Распознавание. Простая страница* (за страницу) | 16р. |
| Распознавание. Стандартная страница* (за страницу) | 23р. |
| Распознавание. Сложная страница 1 степени* (за страницу) | 39р. |
| Распознавание. Сложная страница 2 степени* (за страницу) | 56р. |
| Распознавание. Сложная страница 3 степени* (за страницу) | 85р. |
| Распознавание. Сложная страница 4 степени* (за страницу) | 115р. |
| Сверхсложная страница* (за страницу) | 190р. |
Наценки
к базовой стоимости распознавания текста
| Наличие на странице текста на иностранном языке (коэффициент) | умнож. на 1,3 |
| Распознавание ксерокопии или наличие на странице засветов или шумов (коэффициент) | умнож. на 1,5 |
| Наличие 2-х колонок текста на странице (коэффициент) | умнож. на 1,3 |
| Наличие 3-х колонок текста на странице (коэффициент) | умнож. на 1,5 |
| Ввод формул в редакторе формул (за элемент) | 35р. |
* Порядок определения сложности страницы при распознавании текста
Тип сложности страницы определяется в зависимости от количества баллов рассчитанных для страницы
| Кол-во баллов | Тип страницы | |
| от | до | |
| Простая страница | ||
| 1 | 3 | Стандартная страница |
| 4 | 6 | Сложная страница 1 |
| 7 | 10 | Сложная страница 2 |
| 11 | 16 | Сложная страница 3 |
| 17 | 25 | Сложная страница 4 |
| 26 | Сверхсложная страница | |
Количество баллов сложности для страницы вычисляется суммированием значений расчетных баллов для каждого элемента страницы
| Элемент страницы | Кол-во расчетных баллов | Комментарий |
| Простой рисунок | 1 | |
| Простая таблица | 2 | Небольшая таблица без объединения ячеек |
| Сложная таблица | 6 | Таблица на всю страницу, или таблица с объединением ячеек |
| Наличие сносок | 4 | |
| Верхний или нижний регистр | 0,5 | |
| Мелкий текст | 6 |
Типы исходных материалов для определения стоимости оцифровки
Простой текст — единый текстовый фрагмент с простым стилем оформления.
Простая таблица — структура данных из 1-12 строк, с однотипным форматированием ячеек и текстом в них.
Сложная таблица — структура данных, занимающая всю страницу, не разбитая на ячейки либо с неоднородными (объединенными) ячейками и текстом.
Рисунок — графический элемент, как правило, с подписью.
Формула — комбинация сложных символов и элементов, отображение которой возможно только с помощью специального редактора формул.
Закажите эту услугу со скидкой!
Для детального обсуждения условий сотрудничества, получения консультации и оформления заказа на любую из наших услуг:
- Оставаясь на рабочем месте
- В удобное время
- За считанные минуты
Делать самому или доверить профессионалам?
Ответ на этот вопрос зависит от того насколько вы цените своё время.
Пример
Для работы с фрагментами текста из книг и других документов вам необходимо преобразовать в электронную форму 50 печатных страниц. Предположим, что оборудование для сканирования и программное обеспечение для распознавания текста есть в наличии. Если вы не занимаетесь этим регулярно, то на выполнение работы вам потребуется не менее 9 часов.
Однако вы можете предоставить исходные материалы нашим специалистам и:
- получить качественный результат на следующий день в удобной вам форме.
- подождать около 20 минут (время сканирования) и забрать оригиналы, а готовый электронный документ получить на указанный адрес электронной почты или скачать с нашего FTP-сервера.
Стоимость наших услуг составит приблизительно 800р. — 1500р. для 50 страниц в зависимости качества исходников.
Таким образом, при самостоятельном выполнении этой работы вы сэкономите 90-170 рублей за один час своей работы.
Решайте сами, стоит ли эта сумма потраченного времени.
Страница сгенерирована за 0.04 секунд !
Источник: redocs.ru