
Многопоточность — это основная концепция программирования, которую поддерживают почти все языки программирования высокого уровня. В этом уроке по многопоточности в Python мы рассмотрим различные методы создания потоков и реализации синхронизации.
Давайте сначала узнаем, что такое поток и что означает многопоточность в компьютерных науках.
Что такое Thread в информатике?
В программировании поток — это наименьшая единица выполнения с независимым набором инструкций. Он является частью процесса и работает в таких же исполняемых ресурсах программы совместного использования контекста, как память. Поток имеет начальную точку, последовательность выполнения и результат. Он имеет указатель инструкций, который хранит текущее состояние потока и контролирует, что будет выполнено в следующем порядке.
Что такое Multithreading в информатике?
Способность процесса выполнять несколько потоков параллельно называется многопоточностью. В идеале многопоточность может значительно улучшить производительность любой программы. И механизм многопоточности Python довольно удобен для пользователя, который вы можете быстро освоить.
Потоки в Python за 5 минут
Плюсы многопоточности:
- Multithreading может значительно повысить скорость вычислений в многопроцессорных или многоядерных системах, поскольку каждый процессор или ядро обрабатывает отдельный поток одновременно.
- Multithreading позволяет программе оставаться отзывчивой, пока один поток ожидает ввода, а другой одновременно запускает графический интерфейс. Это утверждение справедливо как для многопроцессорных, так и для однопроцессорных систем.
- Все потоки процесса имеют доступ к его глобальным переменным. Если глобальная переменная изменяется в одном потоке, она видна и другим потокам. Поток также может иметь свои собственные локальные переменные.
Минусы многопоточности:
- В однопроцессорной системе многопоточность не влияет на скорость вычислений. Фактически производительность системы может снизиться из-за накладных расходов на управление потоками.
- Синхронизация необходима, чтобы избежать взаимного исключения при доступе к общим ресурсам процесса. Это напрямую ведет к увеличению использования памяти и процессора.
- Многопоточность увеличивает сложность программы, что также затрудняет отладку.
Это повышает вероятность потенциальных ошибок. - Это может вызвать голод, когда поток не получает регулярный доступ к общим ресурсам. Тогда он не сможет возобновить свою работу.
Python модули
Python предлагает два модуля для реализации потоков в программах.
Для вашей информации, модуль thread устарел в Python 3 и переименован в модуль _thread для обратной совместимости. Но мы объясним оба метода, потому что многие пользователи все еще используют устаревшие версии Python.
Основное различие между этими двумя модулями состоит в том, что модуль реализует поток как функцию. С другой стороны, модуль предлагает объектно-ориентированный подход, позволяющий создавать потоки.
Как запустить 2 цикла одновременно или же Многопоточность в Python | #Python #Программирование #Гайд
Как использовать модуль Thread для создания потоков?
Если вы решили применить модуль thread в своей программе, используйте следующий метод для создания потоков.
thread.start_new_thread ( function, args[, kwargs] )
Этот метод является довольно простым и эффективным способом создания потоков. Вы можете использовать его для запуска программ в Linux и Windows.
Этот метод запускает новый поток и возвращает его идентификатор. Он вызовет функцию, указанную в качестве параметра «function» с переданным списком аргументов. Когда возвращается функция, поток молча завершает работу.
Здесь args — это кортеж аргументов; используйте пустой кортеж для вызова без каких-либо аргументов. Необязательный аргумент указывает словарь аргументов с ключевыми словами.
Если функция завершается с необработанным исключением, выводится трассировка стека, а затем поток выходит (это не влияет на другие потоки, они продолжают работать). Используйте приведенный ниже код, чтобы узнать больше о многопоточности.
Базовый пример Multithreading Python
# Пример многопоточности Python. # 1. Рассчитать факториал с помощью рекурсии. # 2. Вызовите факториальную функцию, используя поток. from thread import start_new_thread threadId = 1 def factorial(n): global threadId if n < 1: print «%s: %d» % («Thread», threadId ) threadId += 1 return 1 else: returnNumber = n * factorial( n — 1 ) # рекусрсивынй вызов print(str(n) + ‘! = ‘ + str(returnNumber)) return returnNumber start_new_thread(factorial,(5, )) start_new_thread(factorial,(4, )) c = raw_input(«Waiting for threads to return. n»)
Вы можете запустить приведенный выше код в своем локальном терминале или использовать любой онлайн-терминал. Как только вы запустите эту программу, она выдаст следующее.
Waiting for threads to return. Thread: 1 1! = 1 2! = 2 3! = 6 4! = 24 Thread: 2 1! = 1 2! = 2 3! = 6 4! = 24 5! = 120
Как использовать модуль Threading для создания потоков?
Последний модуль threading предоставляет богатые возможности и большую поддержку потоков, чем устаревший модуль thread, описанный в предыдущем разделе. Модуль threading является отличным примером многопоточности Python.
Модуль объединяет все методы модуля thread и предоставляет несколько дополнительных методов.
- threading.activeCount(): находит общее число активных объектов потока.
- threading.currentThread(): его можно использовать для определения количества объектов потока в элементе управления потоком вызывающей стороны.
- threading.enumerate(): он предоставит вам полный список объектов потока, которые в данный момент активны.
Помимо описанных выше методов, модуль также представляет класс Thread, который вы можете попробовать реализовать в потоках. Это объектно-ориентированный вариант многопоточности Python.
Класс имеет следующие методы.
| Методы класса | Описание метода |
| run(): | Это функция точки входа для любого потока. |
| start(): | запускает поток при вызове метода run. |
| join([time]): | позволяет программе ожидать завершения потоков. |
| isAlive(): | проверяет активный поток. |
| getName(): | извлекает имя потока. |
| setName(): | обновляет имя потока. |
При желании вы можете обратиться к родной документации Python, чтобы глубже изучить функциональность модуля threading.
Шаги для реализации потоков с помощью модуля Threading
Вы можете выполнить следующие шаги для создания нового потока с помощью модуля .
- Создайте класс наследовав его от Thread.
- Переопределите метод __ init __ (self [, args]) для предоставления аргументов в соответствии с требованиями.
- Затем переопределите метод run(self [, args]), чтобы создать бизнес-логику потока.
Как только вы определили новый подкласс Thread, вы должны создать его экземпляр, чтобы начать новый поток. Затем вызовите метод для его запуска. В конечном итоге он вызовет метод для выполнения бизнес-логики.
Пример — создание класса потока для печати даты
# Пример многопоточности Python для печати текущей даты. # 1. Определите подкласс, используя класс Thread. # 2. Создайте подкласс и запустите поток. import threading import datetime class myThread (threading.Thread): def __init__(self, name, counter): threading.Thread.__init__(self) self.threadID = counter self.name = name self.counter = counter def run(self): print(«Starting » + self.name) print_date(self.name, self.counter) print(«Exiting » + self.name) def print_date(threadName, counter): datefields = [] today = datetime.date.today() datefields.append(today) print( «%s[%d]: %s» % ( threadName, counter, datefields[0] ) ) # Создать треды thread1 = myThread(«Thread», 1) thread2 = myThread(«Thread», 2) # Запустить треды thread1.start() thread2.start() thread1.join() thread2.join() print(«Exiting the Program. «)
Python Multithreading — синхронизация потоков
Модуль имеет встроенную функциональность для реализации блокировки, которая позволяет синхронизировать потоки. Блокировка необходима для контроля доступа к общим ресурсам для предотвращения повреждения или пропущенных данных.
Вы можете вызвать метод Lock(), чтобы применить блокировки, он возвращает новый объект блокировки. Затем вы можете вызвать метод захвата (блокировки) объекта блокировки, чтобы заставить потоки работать синхронно.
Необязательный параметр блокировки указывает, ожидает ли поток получения блокировки.
- В случае, если блокировка установлена на ноль, поток немедленно возвращается с нулевым значением, если блокировка не может быть получена, и 1, если блокировка получена.
- В случае, если для блокировки задано значение 1, поток блокируется и ожидает снятия блокировки.
Метод release() объекта блокировки используется для снятия блокировки, когда она больше не требуется.
Просто для вашей информации, встроенные в Python структуры данных, такие как списки, словари, являются поточно-ориентированными, что является побочным эффектом наличия атомарных байт-кодов для управления ими. Другие структуры данных, реализованные в Python или базовые типы, такие как целые числа и числа с плавающей запятой, не имеют такой защиты. Для защиты от одновременного доступа к объекту мы используем объект Lock.
Пример блокировки в многопоточности
Пример многопоточности Python для демонстрации блокировки. # 1. Определите подкласс, используя класс Thread. # 2. Создайте подкласс и запустите поток. # 3. Реализуйте блокировки в методе выполнения потока. import threading import datetimeexit Flag = 0 class myThread (threading.Thread): def __init__(self, name, counter): threading.Thread.__init__(self) self.threadID = counter self.name = name self.counter = counter def run(self): print(«Starting » + self.name) # Получить блокировку для синхронизации потока threadLock.acquire() print_date(self.name, self.counter) # Снять блокировку для следующего потока threadLock.release() print(«Exiting » + self.name) def print_date(threadName, counter): datefields = [] today = datetime.date.today() datefields.append(today) print( «%s[%d]: %s» % ( threadName, counter, datefields[0] ) ) threadLock = threading.Lock() threads = [] # создать треды thread1 = myThread(«Thread», 1) thread2 = myThread(«Thread», 2) # Запустить треды thread1.start() thread2.start() # Добавить треды в список threads.append(thread1) threads.append(thread2) # Дождитесь завершения всех потоков for t in threads: t.join() print «Exiting the Program. »
Подведем итоги — многопоточность Python для начинающих
Потоковые и многопроцессорные модули на Python

Главная идея потоков заключается в выполнении последовательности таких инструкций внутри программы, которые могут выполняться независимо от другого кода.
Так в чём же разница между потоковой и многопроцессорной обработкой данных? При одновременном выполнении нескольких задач обычно используется потоковая обработка, а при процессно-ориентированном параллелизме задействуется многопроцессорная обработка.
Задачи с ограничением скорости вычислений и ввода-вывода
Время выполнения задач, ограниченных скоростью вычислений, полностью зависит от производительности процессора, тогда как в задачах I/O Bound скорость выполнения процесса ограничена скоростью системы ввода-вывода.
В задачах с ограничением скорости вычислений программа расходует большую часть времени на использование центрального процессора, то есть на выполнение вычислений. К таким задачам можно отнести программы, занимающиеся исключительно перемалыванием чисел и проведением расчётов.
В задачах, ограниченных скоростью ввода-вывода, программы обрабатывают большие объёмы данных с диска в сравнении с необходимым объёмом вычислений. К таким задачам можно отнести, например, подсчёт количества строк в файле.
Проблема GIL на Python
Обычно на Python используется только один поток для выполнения нескольких записанных инструкций, то есть одновременно выполняется только один поток. Производительность однопоточного и многопоточного процессов здесь одинакова, и происходит это из-за GIL (Global Interpreter Lock — глобальной блокировки интерпретатора). Эта глобальная блокировка интерпретатора сама действует как поток и ограничивает другие потоки, делая невозможной многопоточность на Python.
Процессы ускоряют операции на Python, которые создают интенсивную вычислительную нагрузку на центральный процессор, используя сразу несколько ядер и избегая GIL, в то время как потоки лучше подходят для задач ввода-вывода или задач, связанных со внешними системами, потому что потоки могут более эффективно работать вместе. Для объединения процессов им нужно сериализовывать свои результаты, на что требуется время.
Потоки на Python не дают никаких преимуществ для задач, создающих интенсивную вычислительную нагрузку на процессор, именно из-за GIL.
Зачем нужен GIL?
Потоковый модуль использует потоки, многопроцессорный модуль использует процессы. Разница в том, что потоки выполняются в одном и том же пространстве памяти, а у процессов отдельная память. Это немного затрудняет совместное использование объектов процессами с многопроцессорной обработкой. В этом случае обычно выполняется сериализация объектов.
Но потоки используют одну память, поэтому нужно быть осторожным, иначе два потока будут записывать данные в одну и ту же память одновременно. Именно для этого и существует глобальная блокировка интерпретатора.
Если бы мы запустили на Python скрипт, выполняющий простую задачу — спать (ну очень времязатратную!), он выглядел бы так:
import time start = time.perf_counter() def please_sleep(n): print(«Sleeping for <> seconds».format(n)) time.sleep(n) print(«Done Sleeping») for i in range(1,5): please_sleep(i) finish = time.perf_counter() print(«Finished in <> seconds».format(finish-start))
Получаем результат, который и ожидали:
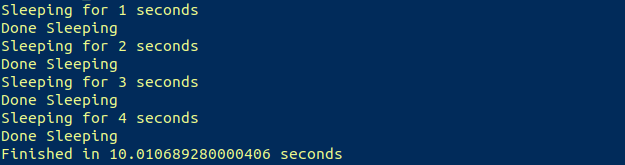
Рабочий процесс этого скрипта будет выглядеть примерно так:
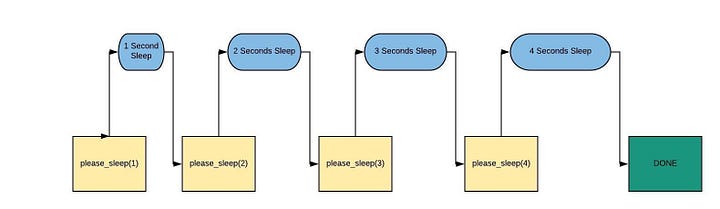
Начнём с потокового модуля
Потоковый модуль
Рабочий процесс потоковой обработки можно представить в таком виде:
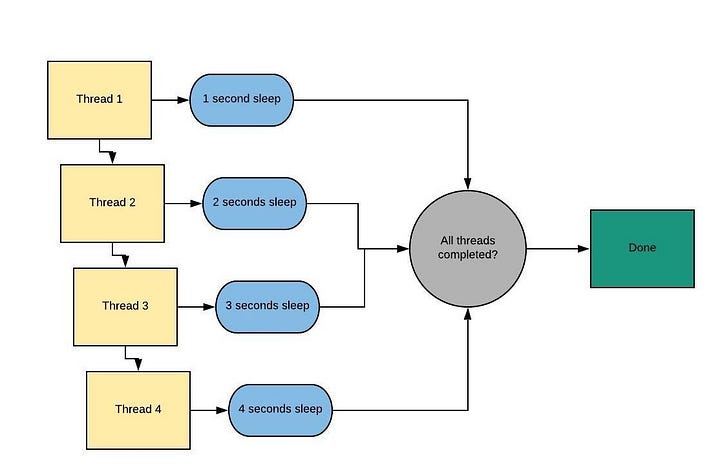
Сначала нужно импортировать потоковый модуль (это очевидно!).
Чтобы воспроизвести приведённый выше скрипт, используя потоки, потребуется создать несколько потоков. Это можно сделать многократным выполнением простого метода Thread (поток). Вот синтаксис этого метода:
thread1 = threading.Thread(target = method_name, args = [list of arguments])
После создания потоков нужно запустить их с помощью метода start:
thread1.start()
Давайте сначала возьмём простой пример, создав всего 2 потока, а затем попробуем повторить приведённый выше скрипт:
import time import threading start = time.perf_counter() def please_sleep(n): print(«Sleeping for <> seconds».format(n)) time.sleep(n) print(«Done Sleeping») t1 = threading.Thread(target = please_sleep, args = [1]) t2 = threading.Thread(target = please_sleep, args = [2]) t1.start() t2.start() finish = time.perf_counter() print(«Finished in <> seconds».format(finish-start))
Согласно рабочему процессу, этот фрагмент кода должен выполняться в течение примерно двух секунд. Теперь посмотрим, что он выведет на экран:

Результат не соответствует нашим ожиданиям. Такое поведение вызвано тем, что после запуска обоих потоков, в то время как потоки спали, наш скрипт работал в многопоточном режиме и продолжил выполнение с остальной частью скрипта. Это тут же привело к подсчёту времени до завершения.
Чтобы этого не допустить, надо задействовать метод join. При вызове метода join вызывающий поток (в нашем случае основной поток) блокируется до тех пор, пока не завершится объект потока (метод please_sleep), на котором он был вызван. Аналогично можно вызвать его в метод start:
thread1.join()
Повторим основной скрипт, используя всё то, что мы сейчас делали:
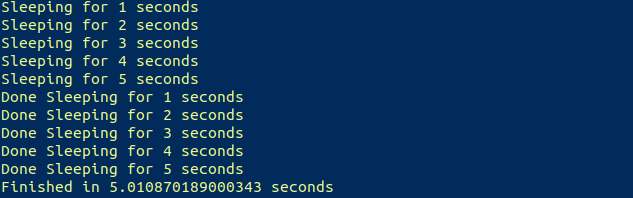
import time import threading start = time.perf_counter() def please_sleep(n): print(«Sleeping for <> seconds».format(n)) time.sleep(n) print(«Done Sleeping for <> seconds».format(n)) threads = [] for i in range(1,5): t = threading.Thread(target = please_sleep, args = [i]) t.start() threads.append(t) finish = time.perf_counter() print(«Finished in <> seconds».format(finish-start))
Теперь выводится ожидаемый результат:
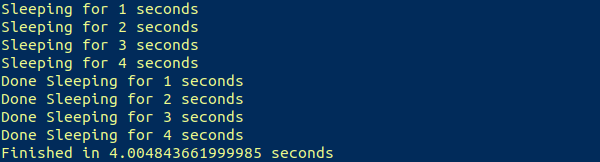
Примерно за четыре секунды успешно были выполнены четыре задачи, на которые первоначально уходило около десяти секунд.
Можно ли достигнуть тех же результатов с помощью модуля многопроцессорной обработки? Да, можно. Давайте в этом убедимся.
Модуль многопроцессорной обработки
Проиллюстрируем наши рассуждения примером с четырёхъядерным процессором. Вот рабочий процесс многопроцессорной обработки данных.
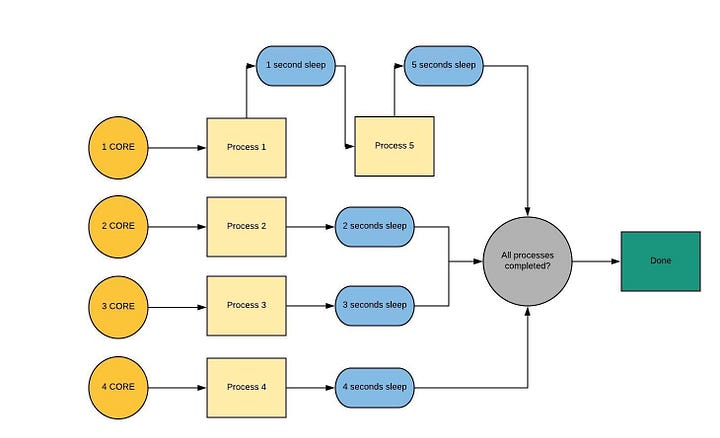
Процесс для запуска процесса ? происходит аналогично запуску потоков. Здесь мы первым делом импортируем многопроцессорный модуль, а затем вызываем метод Process, за которым следует метод start.
process1 = multiprocessing.Process(target = method_name, args = [list of arguments])
process1.start()
Потоки более легковесны и расходуют меньше вычислительных ресурсов по сравнению с процессами, а значит возникновение процессов происходит немного медленнее, чем порождение потоков. Вот пример:
import time import multiprocessing start = time.perf_counter() def please_sleep(n): print(«Sleeping for <> seconds».format(n)) time.sleep(n) print(«Done Sleeping for <> seconds».format(n)) p1 = multiprocessing.Process(target = please_sleep, args = [1]) p2 = multiprocessing.Process(target = please_sleep, args = [2]) p1.start() p2.start() finish = time.perf_counter() print(«Finished in <> seconds».format(finish-start))
Теперь вывод на экран показывает, что процессы были запущены после выполнения всего скрипта, подтверждая то, что было сказано ранее.

Метод join здесь тоже не даёт скрипту выполняться от момента вызова метода и до тех пор, пока процесс не будет завершен. Вызывается он так:
process1.join()
Давайте теперь создадим скрипт, который использует многопоточность для распараллеливания этого метода.
import time import multiprocessing start = time.perf_counter() def please_sleep(n): print(«Sleeping for <> seconds».format(n)) time.sleep(n) print(«Done Sleeping for <> seconds».format(n)) processes = [] for i in range(1,6): p = multiprocessing.Process(target = please_sleep, args = [i]) p.start() processes.append(p) for p in processes: p.join() finish = time.perf_counter() print(«Finished in <> seconds».format(finish-start))
Вывод теперь соответствует рабочему процессу:
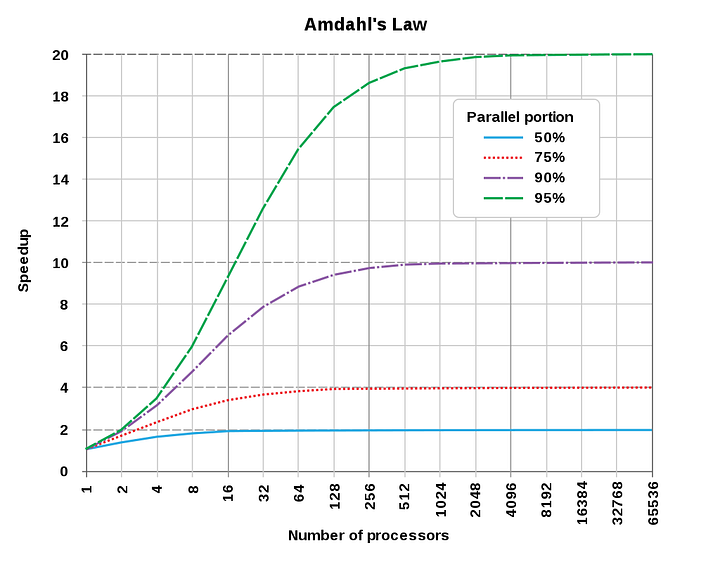
Использование параллелизма всегда приводит к потере эффективности, вынуждая расходовать больше ресурсов, поэтому общее время параллельных вычислений обычно оказывается больше, чем последовательных. Воспользовавшись законом Амдала, можно сказать, что параллельные вычисления с большим числом процессоров эффективны только для программ с высокой степенью распараллеливания.
Ценю ваше терпение и благодарю за то, что дочитали до конца.?
- Вы умеете говорить на Python?
- Расширение Python с помощью C
- Анализ аудиоданных с помощью глубокого обучения и Python (часть 1)
Источник: nuancesprog.ru
Одновременно запускать несколько скриптов python
Как я могу запускать несколько скриптов python? В настоящий момент я запускаю один так, как python script1.py .
Я пробовал python script1.py script2.py , и это не работает: запускается только первый script. Кроме того, я попытался использовать один файл следующим образом:
import script1 import script2 python script1.py python script2.py
Однако это тоже не работает.
ОТВЕТЫ
Ответ 1
python script1.py
Что все script. Он будет запускать два сценария Python в одно и то же время.
Python мог бы сделать то же самое, но потребовалось бы намного больше ввода текста и плохой выбор для этой проблемы.
Я думаю, что это возможно, хотя вы принимаете неправильный подход к решению своей проблемы, и я хотел бы услышать, что вы получаете.
Ответ 2
Простейшим решением одновременного запуска двух процессов Python является запуск из файла bash и указание каждому процессу перейти в фоновый режим с помощью оператора оболочки python script2.py b» + , а затем «c» +
Я смотрю это окно:
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 17:26:49) [MSC v.1900 32 bit (Intel)] on win32 Type «copyright», «credits» or «license()» for more information. >>> = RESTART: C:UsersMikeAppDataLocalProgramsPythonPython36-32progA.py = progA is running b b progA is running c c progA is running
Затем я возвращаюсь в Windows Start и снова открываю IDLE, на этот раз открывая файл progB.py. Я запускаю программу, и когда будет предложено ввести ввод, введите «x» + , а затем «y» +
Я смотрю это окно:
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 17:26:49) [MSC v.1900 32 bit (Intel)] on win32 Type «copyright», «credits» or «license()» for more information. >>> = RESTART: C:UsersMikeAppDataLocalProgramsPythonPython36-32progB.py = progB is running x x progB is running y y progB is running
Теперь две программы IDLE Python 3.6.3 Shell запускаются одновременно, одна оболочка запускает progA, а другая — progB.
Ответ 4
Вы можете использовать Gnu-Parallel для одновременного запуска команд, работает в Windows, Linux/Unix.
parallel . «python script1.py» «python script2.py»
Ответ 5
Я делаю это в node.js(в Windows 10), открывая 2 отдельных экземпляра cmd и запуская каждую программу в каждом экземпляре.
Это имеет то преимущество, что запись на консоль легко видна для каждого script.
Я вижу, что в python можно сделать то же самое: 2 оболочки.
Вы можете одновременно запускать несколько экземпляров оболочки IDLE/Python. Итак, откройте IDLE и запустите код сервера, а затем снова откройте IDLE, который запустит отдельный экземпляр, а затем запустит ваш код клиента.
Ответ 6
Если вы хотите запустить два скрипта Python параллельно, просто добавьте следующее в конец скрипта:
if __name__==»__main__»: Main()
Ответ 7
Попробуйте использовать докеры. Докеры — хороший выбор для разделения разных систем
Ответ 8
Я должен был сделать это и использовал подпроцесс.
import subprocess subprocess.run(«python3 script1.py , shell=True)
Ответ 9
Вы пробуете следующие способы запуска нескольких скриптов Python:
import os print «Starting script1» os.system(«python script1.py arg1 arg2 arg3») print «script1 ended» print «Starting script2» os.system(«python script2.py arg1 arg2 arg3») print «script2 ended»
Примечание. Выполнение нескольких сценариев зависит от чисто подчеркнутой операционной системы, и это не будет параллельным, я был новичком в Python, когда ответил на него.
Обновление: я нашел пакет: https://pypi.org/project/schedule/ Выше пакет может быть использован для запуска нескольких сценариев и функций, пожалуйста, проверьте это, и, возможно, на выходных также предоставит некоторый пример.
то есть: график импорта время импорта script1, script2
def job(): print(«I’m working. «) schedule.every(10).minutes.do(job) schedule.every().hour.do(job) schedule.every().day.at(«10:30»).do(job) schedule.every(5).to(10).days.do(job) schedule.every().monday.do(job) schedule.every().wednesday.at(«13:15»).do(job) while True: schedule.run_pending() time.sleep(1)
Источник: utyatnishna.ru