
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup, lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении. Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Обучение парсингу на Python, парсинг любых сайтов, в том числе SPA
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.
import requests user_id = 12345 url = ‘http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list’ % (user_id) # url для второй страницы r = requests.get(url) with open(‘test.html’, ‘w’) as output_file: output_file.write(r.text.encode(‘cp1251’))

Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.
Импорт (парсинг) нетабличных данных с сайтов в Excel с помощью Power Query
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью «Сеть» в «Инструментах разработчика» в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.
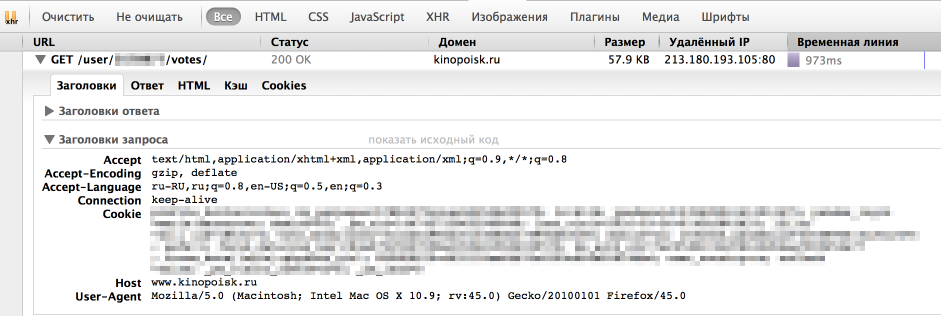
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
headers = < ‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0’ >r = requests.get(url, headers = headers)
На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Теперь мы умеем сохранять одну страницу с оценками. Но обычно у пользователя достаточно много оценок и нужно проитерироваться по всем страницам. Интересующий нас номер страницы легко передать непосредственно в url. Остается только вопрос: «Как понять сколько всего страниц с оценками?» Я решила эту проблему следующим образом: если указать слишком большой номер страницы, то нам вернется вот такая страница без таблицы с фильмами. Таким образом мы можем итерироваться по страницам до тех, пор пока находится блок с оценками фильмов ( ).

Полный код для загрузки данных
import requests # establishing session s = requests.Session() s.headers.update(< ‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0’ >) def load_user_data(user_id, page, session): url = ‘http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/%d/#list’ % (user_id, page) request = session.get(url) return request.text def contain_movies_data(text): soup = BeautifulSoup(text) film_list = soup.find(‘div’, ) return film_list is not None # loading files page = 1 while True: data = load_user_data(user_id, page, s) if contain_movies_data(data): with open(‘./page_%d.html’ % (page), ‘w’) as output_file: output_file.write(data.encode(‘cp1251’)) page += 1 else: break
Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию «Инспектировать элемент» в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге . Выделим эту ноду:
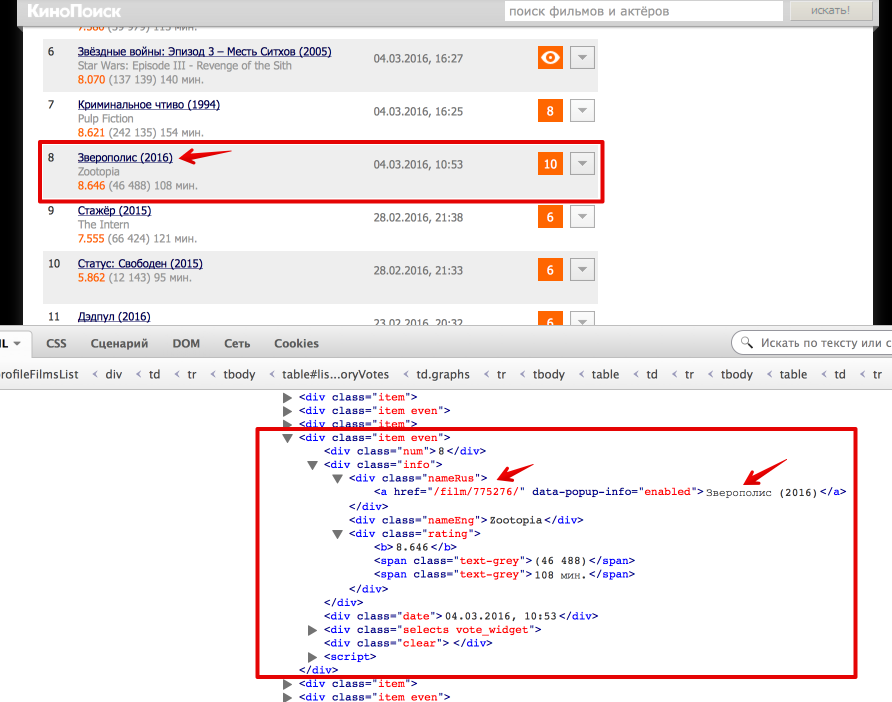
Каждый фильм представлен как или . Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
Еще небольшой хинт для debug’a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
# BeatifulSoup print item #lxml from lxml import etree print etree.tostring(item_lxml)
Полный код для парсинга html-файлов под катом
Резюме

В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.
Полный код проекта можно найти на github’e.
UPD
- Аутентификация: зачастую для того, чтобы получить данные с сайта нужно пройти аутентификацию, в простейшем случае это просто HTTP Basic Auth: логин и пароль. Тут нам снова поможет библиотека Requests. Кроме того, широко распространена oauth2: как использовать oauth2 в python можно почитать на stackoverflow. Также в комментариях есть пример от Terras того, как пройти аутентификацию в web-форме.
- Контролы: На сайте также могут быть дополнительные web-формы (выпадающие списки, check box’ы итд). Алгоритм работы с ними примерно тот же: смотрим, что посылает браузер и отправляем эти же параметры как data в POST-запрос (Requests, stackoverflow). Также могу порекомендовать посмотреть 2й урок курса «Data Wrangling» на Udacity, где подробно рассмотрен пример scrapping сайта US Department of Transportation и посылка данных web-форм.
Источник: habr.com
Как взять данные с сайта в программу

Комментарии
Популярные По порядку
Не удалось загрузить комментарии.
ЛУЧШИЕ СТАТЬИ ПО ТЕМЕ
ООП на Python: концепции, принципы и примеры реализации
Программирование на Python допускает различные методологии, но в его основе лежит объектный подход, поэтому работать в стиле ООП на Python очень просто.
3 самых важных сферы применения Python: возможности языка
Существует множество областей применения Python, но в некоторых он особенно хорош. Разбираемся, что же можно делать на этом ЯП.
Программирование на Python: от новичка до профессионала
Пошаговая инструкция для всех, кто хочет изучить программирование на Python (или программирование вообще), но не знает, куда сделать первый шаг.
Источник: proglib.io
Получение данных c веб-сайта без API в 3 строки кода на Python
Рассказываем о том, как можно сэкономить время и нервы при автоматизации процесса получения данных с веб-сайтов без соответствующего API-интерфейса.
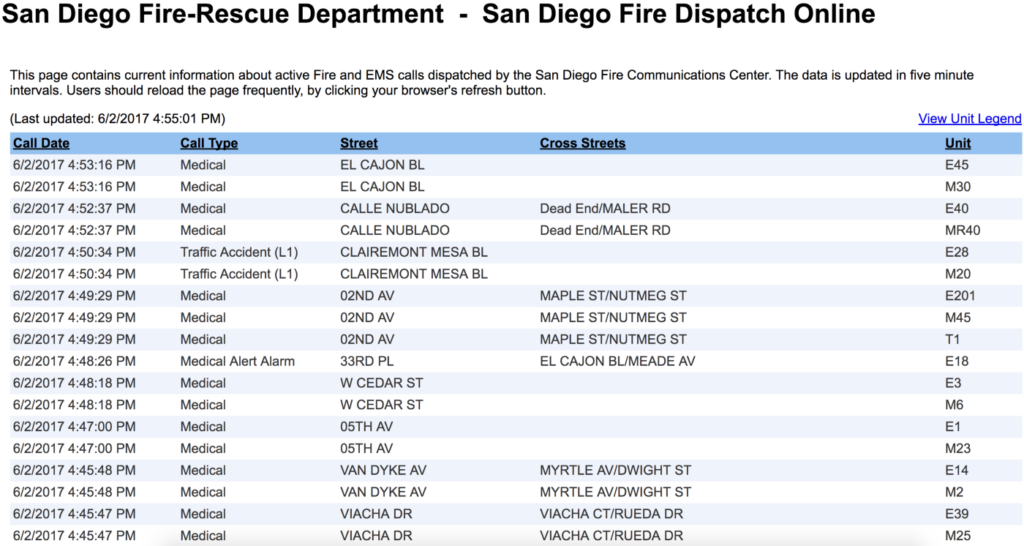
Предположим, что в поисках данных, необходимых для вашего проекта, вы натыкаетесь на такую веб-страницу:
Вот они — все необходимые данные для вашего проекта.
Но что же делать, если нужные вам данные находятся на сайте, который не предоставляет API для их получения? Конечно же, можно потратить несколько часов и написать обработчик, который получит эти данные и преобразует их в нужный для вашего приложения формат.
Но есть и более простое решение — это библиотека Pandas и ее встроенная функция read_html() , которая предназначена для получения данных с html-страниц.
import pandas as pd tables = pd.read_html(«http://apps.sandiego.gov/sdfiredispatch/») print(tables[0])
Прим. перев. В данной статье используется версия Pandas 0.20.3
Devops-инженер Ренессанс Банк , , можно удалённо , По итогам собеседования
Да, все настолько просто. Pandas находит html-таблицы на странице и возвращает их как новый объект DataFrame .
Теперь попробуем указать Pandas, что первая (а точнее нулевая) строка таблицы содержит заголовки столбцов, а также попросим ее сформировать datetime -объект из строки, находящейся в столбце с датой и временем.
import pandas as pd calls_df, = pd.read_html(«http://apps.sandiego.gov/sdfiredispatch/», header=0, parse_dates=[«Call Date»]) print(calls_df)
На выходе мы получим следующий результат:
Call Date Call Type Street Cross Streets Unit 0 2017-06-02 17:27:58 Medical HIGHLAND AV WIGHTMAN ST/UNIVERSITY AV E17 1 2017-06-02 17:27:58 Medical HIGHLAND AV WIGHTMAN ST/UNIVERSITY AV M34 2 2017-06-02 17:23:51 Medical EMERSON ST LOCUST ST/EVERGREEN ST E22 3 2017-06-02 17:23:51 Medical EMERSON ST LOCUST ST/EVERGREEN ST M47 4 2017-06-02 17:23:15 Medical MARAUDER WY BARON LN/FROBISHER ST E38 5 2017-06-02 17:23:15 Medical MARAUDER WY BARON LN/FROBISHER ST M41
Теперь все эти данные находятся в DataFrame -объекте. Если же нам нужны данные в формате json, добавим еще одну строчку кода:
import pandas as pd calls_df, = pd.read_html(«http://apps.sandiego.gov/sdfiredispatch/», header=0, parse_dates=[«Call Date»]) print(calls_df.to_json(orient=»records», date_format=»iso»))
В результате вы получите данные в формате json с правильным форматированием даты по стандарту ISO 8601:
[ < «Call Date»: «2017-06-02T17:34:00.000Z», «Call Type»: «Medical», «Street»: «ROSECRANS ST», «Cross Streets»: «HANCOCK ST/ALLEY», «Unit»: «M21» >, < «Call Date»: «2017-06-02T17:34:00.000Z», «Call Type»: «Medical», «Street»: «ROSECRANS ST», «Cross Streets»: «HANCOCK ST/ALLEY», «Unit»: «T20» >, < «Call Date»: «2017-06-02T17:30:34.000Z», «Call Type»: «Medical», «Street»: «SPORTS ARENA BL», «Cross Streets»: «CAM DEL RIO WEST/EAST DR», «Unit»: «E20» >// и т.д. ]
При желании данные можно сохранить в CSV или XLS:
import pandas as pd calls_df, = pd.read_html(«http://apps.sandiego.gov/sdfiredispatch/», header=0, parse_dates=[«Call Date»]) calls_df.to_csv(«calls.csv», index=False)
Выполните код и откройте файл calls.csv . Он откроется в приложении для работы с таблицами:

И, конечно же, Pandas упрощает анализ:
calls_df.describe()
Call Date Call Type Street Cross Streets Unit count 69 69 69 64 69 unique 29 2 29 27 60 top 2017-06-02 16:59:50 Medical CHANNEL WY LA SALLE ST/WESTERN ST E1 freq 5 66 5 5 2 first 2017-06-02 16:36:46 NaN NaN NaN NaN last 2017-06-02 17:41:30 NaN NaN NaN NaN
calls_df.groupby(«Call Type»).count()
Call Date Street Cross Streets Unit Call Type Medical 66 66 61 66 Traffic Accident (L1) 3 3 3 3
И обработку данных:
calls_df[«Unit»].unique()
Результат метода unique :
array([‘E46’, ‘MR33’, ‘T40’, ‘E201’, ‘M6’, ‘E34’, ‘M34’, ‘E29’, ‘M30’, ‘M43’, ‘M21’, ‘T20’, ‘E20’, ‘M20’, ‘E26’, ‘M32’, ‘SQ55’, ‘E1’, ‘M26’, ‘BLS4’, ‘E17’, ‘E22’, ‘M47’, ‘E38’, ‘M41’, ‘E5’, ‘M19’, ‘E28’, ‘M1’, ‘E42’, ‘M42’, ‘E23’, ‘MR9’, ‘PD’, ‘LCCNOT’, ‘M52’, ‘E45’, ‘M12’, ‘E40’, ‘MR40’, ‘M45’, ‘T1’, ‘M23’, ‘E14’, ‘M2’, ‘E39’, ‘M25’, ‘E8’, ‘M17’, ‘E4’, ‘M22’, ‘M37’, ‘E7’, ‘M31’, ‘E9’, ‘M39’, ‘SQ56’, ‘E10’, ‘M44’, ‘M11’], dtype=object)
Теперь вы знаете, как с помощью Python и Pandas можно быстро получить данные с практически любого сайта, не прилагая особых усилий. Освободившееся время предлагаем посвятить чтению других интересных материалов по Python на нашем сайте.
Источник: tproger.ru