
Интерпретаторы и компиляторы. Для того чтобы процессор мог выполнить программу, эта программа и данные, с которыми она работает, должны быть загружены в оперативную память.
Итак, мы создали программу на языке программирования (некоторый текст) и загрузили ее в оперативную память. Теперь мы хотим, чтобы процессор ее выполнил, однако процессор «понимает» команды только на машинном языке, а наша программа написана на языке программирования. Как быть?
Необходимо, чтобы в оперативной памяти находилась программа-переводчик (транслятор), автоматически переводящая программу с языка программирования на машинный язык. Компьютер может выполнять программы, написанные только на том языке программирования, транслятор которого размещен в оперативной памяти компьютера.
Трансляторы языков программирования бывают двух типов: интерпретаторы и компиляторы. Интерпретатор — это программа, которая обеспечивает последовательный перевод инструкций программы на машинный язык и их выполнение. Поэтому при каждом запуске программы на выполнение эта процедура повторяется. Достоинством интерпретаторов является удобство отладки программы (поиска в ней ошибок), так как возможно пошаговое ее выполнение, а недостатком — сравнительно малая скорость выполнения.
Лекция 6: Выполнение программы на компьютере
Компилятор действует иначе, он переводит весь текст программы на машинный язык и сохраняет его в исполнимом файле (обычно с расширением ехе). Затем этот уже готовый к выполнению файл, записанный на машинном языке, можно запускать на исполнение многократно. Достоинством компиляторов является большая скорость выполнения программы, а недостатком — трудоемкость отладки, так как невозможно пошаговое выполнение программы.
Современные системы программирования, и в том числе Visual Basic, позволяют работать в режиме как интерпретатора, так и компилятора. На этапе разработки и отладки программы используется режим интерпретатора, а для получения готовой исполняемой программы — режим компилятора.
Процесс выполнения программы. Рассмотрим процесс выполнения программы на примере рассмотренной выше программы (проект «Переменные»), написанной на языке программирования Visual Basic.
Ввод текста программы в оперативную память. Текст программы вводится в оперативную память с помощью клавиатуры или считывается из внешней памяти. Текст программы займет в памяти определенное количество ячеек (например, с ячейки номер I по ячейку I+K).
Перевод программы на машинный язык. Наша программа будет записана в памяти во внутреннем представлении языка программирования Visual Basic, который процессор «не понимает». Для перевода программы на машинный язык, понятный процессору, в памяти должна находиться программа-транслятор языка Visual Basic. Программа-транс — лятор после считывания в оперативную память из внешней памяти будет занимать в памяти определенное количество ячеек (например, с ячейки номер N по ячейку N+M).
Выполнение программы. После запуска программы на выполнение процессор последовательно будет считывать из памяти операторы и их выполнять.
Как с помощью клавиш запустить любую программу на Windows?
В процессе выполнения оператора объявления переменных Dim в оперативной памяти для их хранения отводится необходимое количество ячееек: для целочисленных переменных intA, intB — по две ячейки, для неотрицательной целочисленной переменной bytC — одна ячейка, для переменной одинарной точности sngD — четыре ячейки, для переменной двойной точности dblE — восемь ячеек, для строковых переменных strA и strB количество ячеек, равное количеству символов, составляющих их значения, для логических переменных ЫпА, ЫпВ, ЫпС — по две ячейки. Таким образом, в памяти для хранения данных (значений переменных) будет отведено определенное количество ячеек, например ячейки с 1-й по 39-ю (рис. 4.17).
Далее, в процессе выполнения операторов присваивания в отведенные переменным области оперативной памяти записываются их значения. Если в правой части оператора присваивания находятся арифметические выражения, то предварительно вычисляются их значения.
Затем с помощью метода Print производится вывод значений переменных на форму, реализующую графический интерфейс программы. В этом процессе значения переменных считываются из памяти и высвечиваются на экране монитора.
| Имена переменных | Оперативная память | |
| ячейки | значение | |
| mtA | 1-2 | |
| intB | 3-4 | |
| bytC | ||
| sngD | 6-9 | 0,6666667 |
| dblE | 10-17 | 0,666666686534882 |
| strA | 18-22 | форма |
| strB | 23-33 | информатика |
| blnA | 34-35 | True |
| blnB | 36-37 | False |
| blnC | 38-39 | False |
| 1 | программный код | |
| l + K | ||
| N | транслятор языка программирования | |
| N + M |
| Рис. 4.17. Программа и данные в оперативной памяти |
Вопросы для размышления
1. Какую функцию выполняют трансляторы языков программирования?
2. В чем состоит различие между интерпретаторами и компиляторами?
я
4.15. Какое количество ячеек памяти было бы занято переменными в проекте «Переменные», если бы переменные не были объяв-
Источник: cyberpedia.su
Выполнение программы
Компьютерная программа — это последовательность инструкций, которые компьютер (вычислительная машина) будет исполнять. Иногда под программой понимают исходный код этой программы. Когда пользователь компьютера «запускает программу», он создаёт т.н. процесс, который соответствует этой программе. Процесс — выполнение инструкций программы.
Кроме того, каждый процесс может иметь один или несколько потоков выполнения (англ. thread). Этот курс не подразумевает использования нескольких потоков, поэтому понятие процесс и поток будут взаимозаменяемыми.
Логично, что процесс должен начинать выполнение с какой-либо команды. Место программы, откуда начинается выполнение программы, называется точкой входа в программу. В C++ точка входа в программу может быть только одна и записывается в следующем виде:
int main() < return 0; >;
Фигурные скобки, <>, в С++ используются для группировки. В данном случае они указывают на начало и конец функции main, которая обязательно должна присутствовать
в программе, и с которой начинается работа программы. Точка с запятой (;) ставится после каждого оператора языка, например, после оператора «return», возвращающего значение 0 и, таким образом, завершающий программу. Целое значение, с которым завершается программа, называется кодом ошибки. Если код ошибки — 0, то такая программа завершилась успешно.
Разберём следующий код:
int main() < int addOne = 6; int addTwo = 8; return 0; int sum = addOne + addTwo; >;
Внутри блока объявляются 3 переменные: addOne, addTwo и sum. Так как объявление переменной sum стоит после оператора return, то программа завершится ещё до того, как сможет узнать про существование переменной sum. Таким образом, sum не будет ни создана, ни инициализирована.
Операторы ветвления (выбора)
Часто необходимо выполнить (или не выполнить) последовательность команд в зависимости от осуществления какого-либо условия. К примеру, модуль любого числа равен самому числу, если оно не меньше 0, и самому числу, взятому с обратным знаком, в противном случае:
Перепишем это условие на языке C++
int main() < int value = 6;// Исходное значение X int result;// Сюда сохраним результат if (value >= 0) < // Если X ≥ 0, result = value; // тогда сохраняем само число >else < // Иначе result = -value; // его же, взятым с обратным знаком >; return 0; >;
Ветвь else является необязательной. В этом случае оператор if ограничивает блок кода, который может быть выполнен только при наступлении определённого условия. Операторы if могут быть вложенными. Это позволяет использовать 2 и более ограничений. Листинг 4 реализует вычисление результата для следующей функции:
int main() < int value = 6; int result = 0; if (value >= 1) < result = value — 1; >else if (value < -1) < result = -value — 1; >else < result = 0; >; return 0; >;
В этом примере во внешнем блоке if (value >= 1) в части else располагается внутренний блок if (value . Внешний блок выбирает все значения не меньшие 1, тогда как внутренний делит оставшееся множество (т.е. все значения меньшие 1) на два: на множество значений, меньшие –1 и множество не меньшее –1 и меньшее 1.
На заметку
В языке программирования Python комбинация else if была заменена на сокращённый вариант elif. Также в Python отказались от оператора выбора switch, т.к. с помощью оператора if-elif-else легко реализуется его функциональность.
Кроме оператора if существует оператор выбора switch:
int main() < char op = ‘-’; float result = 0.0; float a = 4.0, b = 3.0; switch (op) < case ‘+’: result = a + b; break; case ‘-’: result = a — b; case ‘*’: result = a * b; break; case ‘/’: result = a / b; break; default: /* Вывести ошибку */; >; return 0; >;
В круглых скобках после switch записывается любая переменная целого типа (или типа, который может быть представлен, как целочисленный).
В фигурных скобках перечисляются значения, с которыми будет происходит сравнение переменной. Выполнение начнётся с той ветви, в которой произошло совпадение (в примере это ‘–’). Оператор break устанавливается для того, чтобы поток программы закончил выполнение ветвей и продолжил работу за закрывающейся фигурной скобкой. Поэтому в приведённом примере забытый оператор break приведёт к ошибке, т.к. после того, как будет вычислена разность поток программы перейдёт на следующую ветвь и выполнит умножение.
Необязательная ветвь default выполнится в том случае, если значение переменной не совпала не с одним из перечисленных в case-ветвях.
На заметку
Часто программисты используют перечисления для использования с оператором switch. Это достаточно правильное и умное использование оператора switch. Более того, достаточно умные компиляторы способны во время компиляции проверить, все ли значения перечисления были учтены, и сообщить об этом программисту.
Циклы
Циклы позволяют выполнять один и тот же блок кода, пока выполняется определённое условие. В языке C++ существует 3 цикла: while, for и do-while. Первые два являются циклами с предусловием, последний — с постусловием. Когда некоторое логическое условие цикла истинно, то начинает выполняться тело цикла. Программисту необходимо следить, чтобы цикл мог когда-нибудь закончиться, т.е. рано или поздно
логическое условие должно стать ложным, иначе программа «зациклится».
Цикл while трактуется так: «пока логическое условие верно, выполнять блок кода». В коде синтаксически записывается следующим образом:
int main() < string text = “So beautiful text!”; int pos = 0; while (text[pos] != ‘t’) < pos++; >; return 0; >;
Если символ справа логического неравенства есть в искомой строке найден, то выполнение цикла прекратиться и переменная pos будет иметь значение позиции, в которой находится этот символ. Если же такого символа не будет вовсе, тогда программа завершится с ошибкой.
Синтаксис оператора цикла for следующий:
int main() < int arr1[] = ; int arr2[3]; for (int i = 0; i < 3; i++) < arr2[i] = arr1[i]; >; return 0; >;
Оператор цикла for в данном случае имеет следующее значение: «присвоить переменной i значение 0; пока i меньше 3-х копировать i-й элемент массива и увеличить i на 1». Все три части оператора (присвоение переменной значения, проверка логического условия и изменение переменной) могут быть опущены по желанию программиста, т.е. заменены на пустой оператор.
Запись for (int i = 0; i и
int i = 0; while (i < 3) < i++; >;
Условие цикла do-while проверяется после того, как блок кода будет выполнен, другими словами, определённый кусок кода будет выполнен хотя бы один раз, тогда как в циклах с предусловием он может не выполниться вовсе. Синтаксически цикл записывается так:
do < // выполнить хотя бы один раз >while (true);
Отметим, что при приведённой записи код будет выполняться бесконечно, так как логическое условие состоит только из значения true. Чтобы выйти из цикла можно внутри блока воспользоваться уже знакомым оператором break, позволяющий прервать выполнение цикла с любого места. Кроме оператора break существует оператор continue, который завершает текущую итерацию и переходит к выполнению следующей итерации
цикла.
Область видимости переменной
Объявление переменной вводит имя в область видимости (scope); это значит, что имя можно использовать лишь в ограниченной части программы. Для имени, объявленного в конкретном блоке кода (его называют локальным), область видимости простирается от точки объявления до конца содержащего это объявление блока.
Переменная называется глобальной, если она объявлена вне функции main и других блоков кода. Чтобы отличить глобальную переменную от локальной можно использовать два двоеточия перед её именем. Лучше вовсе избегать использования глобальных переменных во избежания перекрытия имён и случайного изменения в коде значения глобальной переменной, вместо локальной.
Следующий код полностью поясняет все возможные ситуации:
int global = 5; // создание глобальной переменной int main() < int global = 4; // создание локальной переменной global; // =4, вызов локальной переменной ::global; // =5, вызов глобальной переменной int outer = 0; // создание локальной переменной < // начало внутреннего блока outer; // =0, вызов лок. переменной внешнего блока float outer = 3.0; // перекрытие имени внеш. перемен. outer; // =3.0 вызов лок. переменной типа float int inner = 2; // создание лок. внутр. переменной inner; // =2, вызов лок. переменной >// inner; // ошибка! Такой переменной в этом блоке нет. // float outer; // ошибка! Такая переменная уже существует return 0; >;
Источник: markoutte.me
3.3. Этапы выполнения программы
Выполнение программы состоит из следующих этапов работы ПК:
— чтение процессором из ОЗУ очередной команды,
— последующее чтение процессором из ОЗУ операнда и, при необходимости,- второго,
— исполнение в процессоре закодированной в команде операции,
— запись результата операции, при необходимости, в ОЗУ или в порт,
- формирование адреса следующей команды и обращение за ней в ОЗУ.
3.4. Структурная организация процессора.
. Основные типы логических схем аппаратуры ЭВМ Преобразование информации в ЭВМ выполняется при помощи электронных схем, имеющих различную сложность. По функциональной сложности принято делить электронные схемы ВТ на элементы, узлы (блоки) и устройства. 3.4.1. Логические элементы.Элемент- это простейшая схема, выполняющая операции над значениями двоичных разрядов (битами). Основные элементы делятся на логические и элементы памяти. Логические элементы выполняют двоичные (бинарные) операции, на основе которых осуществляются практически все преобразования информации. В качестве логических элементов используются элементы И, ИЛИ, НЕ и другие, производные от них — И-НЕ, ИЛИ-НЕ, И-ИЛИ-НЕ и т.д. Элементы памяти чаще всего представляют собой триггеры различных типов, но любой триггер хранит только один двоичный разряд.. Кроме логических элементов используются и вспомогательные элементы, усиливающие или формирующие сигналы стандартной формы, но, как правило, не выполняющие никаких логических функций. Элементы и триггеры обозначаются так, как показано на рис.3.6 а): элемент изображается прямоугольником, входы — линиями слева, выходы – справа. 3.4.2.УзлыУзлы (функциональные блоки, далее — простоблоки) состоят из элементов и выполняют операции преобразования информации над байтами или структурами, состоящими из нескольких байтов, называемых словами. В зависимости от состава узлы могут быть 2-х типов: комбинационного (комбинационные схемы — КС) или накапливающего (автоматы , схемы с памятью, последовательные схемы). 1) Узлы комбинационного типа состоят из логических элементов. Их главная особенность заключается в том, что выходной сигнал (Y)в момент времениt зависит только от комбинации входных сигналов (X) в тот же момент времени, при этом каждой комбинации сигналов на входе соответствует определенный выходной сигнал. Выходной сигнал может измениться только при получении другого входного сигнала. При неоднократном повторении одного и того же входного сигнала значение выходного также повторяется, поэтому комбинационная схема фактически осуществляет перекодировку входных сигналов в выходные. Несмотря на кажущуюся примитивность логики работы комбинационных схем, все основные преобразования информации в ЭВМ выполняются с их помощью. Это объясняется тем, что в основе преобразования данных в ВТ заложено выполнение логических или арифметических операций. К типовым узлам ВТ комбинационного типа, сумматоры, дешифраторы, компараторы, мультиплексоры и др. 2) Узлы с памятью (автоматы) состоят из логических элементов и элементов памяти. Информация, записанная в памяти автомата, называется состоянием автомата (Q). Выходной сигнал автомата в общем случае зависит от сигнала на входе и состояния автомата, поэтому при одном и том же входном сигнале, но в разные моменты времени автомат может выдавать различные выходные сигналы. При работе автомата в его памяти накапливается обобщенная информация обо всех входных сигналах, поступивших к данному моменту времени, поэтому состояние автомата и выходной сигнал зависят от всей предыстории входных сигналов. Наличие памяти позволяет автомату выполнять не только отдельные операции, но и последовательности взаимосвязанных операций, т.е. заданные алгоритмы обработки данных. К типовым узлам ВТ с памятью относятся регистры и счетчики. Обозначения узлов в схемах ЭВМ аналогично обозначениям элементов. Например, обозначение суммирующего n-разрядного счетчика с прямыми и инверсными выходами – на рис. 3.6. б. На вход, обозначенный как +1, поступают суммируемые логические сигналы (единицы), с выхода счетчика Q, состоящего из n выходных линий, снимается состояние счетчика в виде n – разрядного двоичного кода. Несколько узлов могут объединяться в функциональные блоки (например, блок сумматора может включать в себя собственно сумматор и регистр сумматора).  n Q n а) б) Рис.3.6.а) и б) 3.4.3..Устройства ЭВМ. Строятся из элементов и узлов и выполняют определенный набор однотипных операций. К устройствам, например, компьютера относятся запоминающие устройства, арифметико-логическое устройство, центральное устройство управления, устройства ввода и вывода. Устройства ВТ конструктивно выполняют отдельно или несколько устройств объединяют в один конструктивный блок (например, процессор ЭВМ). Для понимания организации средств ВТ и процессов преобразования информации в них необходимо изучить логику работы его составных частей, прежде всего состав и работу элементов и типовых узлов. Процессор является основным «мозговым» устройством ЭВМ, в задачу которого входит исполнение находящегося в памяти программного (исполняемого) кода, который получается в результате трансляции текста программы на каком-либо языке программирования. В настоящее время под словом процессор обычно подразумевают МП – микросхему, которая, помимо соответственно процессора, может содержать и другие узлы. Процессор ЭВМ объединяет -устройство управления (УУ); — арифметико-логическое устройство (АЛУ); — блоки регистров. 3.4.4. Типовые узлы и устройства аппаратуры ЭВМ 3.4.4.1. Регистры предназначены для приема, временного хранения и выдачи данных. Регистр – основная схема хранения информации в процессоре, контроллере, адаптере и порту ЭВМ всех классов и типов. Кроме хранения данных регистры могут выполнять сдвиг данных, по этой причине различают регистры параллельные и сдвигающие. На основе регистра строят схемы счета единиц (нулей). Основу регистра составляют триггеры, число которых равно разрядности хранимых в регистре данных, т.е. n-разрядный двоичный код хранится в n- разрядном регистре. Параллельным называют . n-разрядный регистр с одновременной (т.е. параллельной записью.) записью в него всех n разрядов двоичного кода. Параллельный регистр имеет наиболее простую схему. Обычно именно его называют просто регистром. Обычно регистр имеет один общий вход сброса (установки в 0) и n входов записываемого в него двоичного кода 3.4.4.2. Счетчиком называется регистр, который «считает» входные сигналы, т.е. под действием каждого входного сигнала хранимый двоичный код изменяется на «1». . Счетчики могут считать с различными коэффициентами пересчета. Счетчики, считающие с коэффициентом пересчета 2 n , где n –число триггеров, называются двоичными . В зависимости от направления счета счетчики могут быть суммирующими, вычитающими и реверсивными. Суммирующие счетчики при поступлении каждого входного импульса увеличивают показания (состояния каждого триггера, т.е. состояние счетчика) на единицу, вычитающие – уменьшают. Принято обозначать вход суммирующего счетчика «+1», а вычитающего — «-1» . Реверсивные счетчики могут работать как в режиме – суммирования, так и в режиме вычитания. 3.4.3. Арифметико-логическое устройство (АЛУ) предназначено для выполнения арифметических и логических операций над данными разного формата. В зависимости от характера выполняемой операций и формата данных различают следующие типы операций в АЛУ:
n Q n а) б) Рис.3.6.а) и б) 3.4.3..Устройства ЭВМ. Строятся из элементов и узлов и выполняют определенный набор однотипных операций. К устройствам, например, компьютера относятся запоминающие устройства, арифметико-логическое устройство, центральное устройство управления, устройства ввода и вывода. Устройства ВТ конструктивно выполняют отдельно или несколько устройств объединяют в один конструктивный блок (например, процессор ЭВМ). Для понимания организации средств ВТ и процессов преобразования информации в них необходимо изучить логику работы его составных частей, прежде всего состав и работу элементов и типовых узлов. Процессор является основным «мозговым» устройством ЭВМ, в задачу которого входит исполнение находящегося в памяти программного (исполняемого) кода, который получается в результате трансляции текста программы на каком-либо языке программирования. В настоящее время под словом процессор обычно подразумевают МП – микросхему, которая, помимо соответственно процессора, может содержать и другие узлы. Процессор ЭВМ объединяет -устройство управления (УУ); — арифметико-логическое устройство (АЛУ); — блоки регистров. 3.4.4. Типовые узлы и устройства аппаратуры ЭВМ 3.4.4.1. Регистры предназначены для приема, временного хранения и выдачи данных. Регистр – основная схема хранения информации в процессоре, контроллере, адаптере и порту ЭВМ всех классов и типов. Кроме хранения данных регистры могут выполнять сдвиг данных, по этой причине различают регистры параллельные и сдвигающие. На основе регистра строят схемы счета единиц (нулей). Основу регистра составляют триггеры, число которых равно разрядности хранимых в регистре данных, т.е. n-разрядный двоичный код хранится в n- разрядном регистре. Параллельным называют . n-разрядный регистр с одновременной (т.е. параллельной записью.) записью в него всех n разрядов двоичного кода. Параллельный регистр имеет наиболее простую схему. Обычно именно его называют просто регистром. Обычно регистр имеет один общий вход сброса (установки в 0) и n входов записываемого в него двоичного кода 3.4.4.2. Счетчиком называется регистр, который «считает» входные сигналы, т.е. под действием каждого входного сигнала хранимый двоичный код изменяется на «1». . Счетчики могут считать с различными коэффициентами пересчета. Счетчики, считающие с коэффициентом пересчета 2 n , где n –число триггеров, называются двоичными . В зависимости от направления счета счетчики могут быть суммирующими, вычитающими и реверсивными. Суммирующие счетчики при поступлении каждого входного импульса увеличивают показания (состояния каждого триггера, т.е. состояние счетчика) на единицу, вычитающие – уменьшают. Принято обозначать вход суммирующего счетчика «+1», а вычитающего — «-1» . Реверсивные счетчики могут работать как в режиме – суммирования, так и в режиме вычитания. 3.4.3. Арифметико-логическое устройство (АЛУ) предназначено для выполнения арифметических и логических операций над данными разного формата. В зависимости от характера выполняемой операций и формата данных различают следующие типы операций в АЛУ:
- арифметические операции над целыми числами с ФТ (операции целочисленной арифметики);
- арифметические операции над числами с ПТ;
- арифметические операции над двоично-десятичными числами (операции десятичной арифметики);
- логические операции.
В зависимости от набора операций и особенностей реализации алгоритмов их выполнения организация АЛУ может быть различной. По характеру использования различают многофункциональные и блочные АЛУ. В многофункциональных АЛУ все операции выполняются с использованием в основном одних и тех же аппаратных средств, которые настраиваются на заданный тип операций с помощью для управляющих сигналов. Обратим внимание, что входы АЛУ для управляющих сигналов (а значит и сами сигналы) на схемах АЛУ в этой лекции не показаны. Блочные АЛУ включают в себя отдельные блоки для операций различного типа. Эти блоки могут работать параллельно, что повышает быстродействие АЛУ, однако требует больших затрат на оборудование. На входы АЛУ поступают операнды, а на его выходе формируется результат преобразования операндов (результат операции). В ходе выполнения операции АЛУ выдает признаки (условия), характеризующие результат. К таким признакам относятся, например, знак результата, равенство результата нулю, значение цифры множителя при умножении, знак остатка при делении и т.д. АЛУ состоит из комбинационных схем, поэтому в операциях над двумя операндами оба операнда должны устанавливаться на обоих входах АЛУ одновременно! Основу АЛУ составляет двоичный сумматор, т.к. сложение двоичных дополнительных или обратных кодов составляет основу 4-х арифметических операций: сложение, вычитание, умножение, деление. В зависимости от числа магистралей различают трех-, двух- и одномагистральные (3-,2-,1-шинные) АЛУ. а) Трехмагистральное АЛУ Структура трехмагистрального АЛУ (рис.3.7) позволяет выполнить за один такт чтение операндов из регистров, их суммирование в АЛУ и запись суммы в регистр. Однако три магистрали занимают значительную часть кристалла микросхемы. 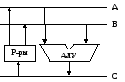 Рис.3.7. Трехмагистральное АЛУ: б)Двухмагистральное АЛУ Двухмагистральные АЛУ (рис.3.8.) содержит буферный (промежуточный) регистр (БР) и требует для сложения двух машинных тактов. В первом такте по магистрали В из Регистра в БР считывается операнд В. Во втором такте операнд А по той же освободившейся от операнда В магистрали В считывается из Регистра на вход АЛУ, операнды А и В суммируются и результат по магистрали А записывается в РОН.
Рис.3.7. Трехмагистральное АЛУ: б)Двухмагистральное АЛУ Двухмагистральные АЛУ (рис.3.8.) содержит буферный (промежуточный) регистр (БР) и требует для сложения двух машинных тактов. В первом такте по магистрали В из Регистра в БР считывается операнд В. Во втором такте операнд А по той же освободившейся от операнда В магистрали В считывается из Регистра на вход АЛУ, операнды А и В суммируются и результат по магистрали А записывается в РОН. 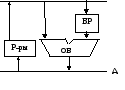 В Рис.3.8. Двухмагистральное АЛУ в) Одномагистральное АЛУ Одномагистральное АЛУ использует два буферных регистра (рис.3.9.). В таком АЛУ сложение выполняется за три такта. В первом такте осуществляется чтение операнда А из Р в БР1, во втором — операнда В из Р в БР2, а в третьем суммируются операнды; результат записывается в один из регистров блока Р.
В Рис.3.8. Двухмагистральное АЛУ в) Одномагистральное АЛУ Одномагистральное АЛУ использует два буферных регистра (рис.3.9.). В таком АЛУ сложение выполняется за три такта. В первом такте осуществляется чтение операнда А из Р в БР1, во втором — операнда В из Р в БР2, а в третьем суммируются операнды; результат записывается в один из регистров блока Р. 
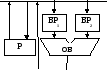 : Рис 3.9. Одномагистральное АЛУ Контрольные вопросы и задания: 1) Нарисуйте блочную схему алгоритма операции вычитания в одномагистральном АЛУ. 2) Составьте 5-8 простых и 5-8 сложных ( на Ваш взгляд ) вопросов и заданий по теме лекции. 7
: Рис 3.9. Одномагистральное АЛУ Контрольные вопросы и задания: 1) Нарисуйте блочную схему алгоритма операции вычитания в одномагистральном АЛУ. 2) Составьте 5-8 простых и 5-8 сложных ( на Ваш взгляд ) вопросов и заданий по теме лекции. 7
Источник: studfile.net