
Основой работы Fine Reader, является так называемый пакет, содержащий всю информацию о распознаваемом документе. Пакет представляет собой набор страниц документа и может содержать около тысячи страниц. В один пакет для удобства работы рекомендуется объединять изображения, логически связанные между собой, например страницы одной книги. Пользователь импортирует в пакет изображение страниц со сканера или непосредственно из файлов графических форматов.
В окне Пакетвиден список страниц, входящих в открытый пакет. Для просмотра страницы нужно щелкнуть мышью по ее изображению или номеру, при этом откроются файлы, которыми данная страница представлена в пакете. Страницы в окне Пакет могут быть представлены пиктограммами или уменьшенным изображением страницы.
Импортированные изображения подвергаются графической обработке. Если исходное изображение представляет собой негатив, оно может быть инвертировано, далее производится очистка от лишних деталей — мелких дефектов изображения. Если не нужна цветность, то цветные изображения сводятся к черно-белым, что экономит место на диске и ускоряет процесс распознавания.
ABBYY FineReader как пользоваться
Следующий шаг — анализ макета страниц пакета, т. е. выделение областей, подлежащих распознаванию. На этом этапе Fine Reader анализирует ориентацию страницы и переворачивает изображение, если это необходимо, а также выделяет блоки — области, которые при дальнейшем анализе будут интерпретироваться как текст, таблицы или рисунки.
После анализа макета страниц, входящих в пакет, проводится собственно распознавание текста и таблиц. Именно технология распознавания является основой Fine Reader и обеспечивает ее Уникальность, однако этот процесс совершенно незаметен пользователю — он видит только бегущее по тексту выделение и типовую строку состояния, указывающую, сколько информации обработано, а сколько осталось.
Далее производится проверка правописания, после чего пользователь проверяет слова, которых нет в словаре системы, а также символы, в точности распознавания которых программа не уверена, при этом такие слова и буквы выделяются цветом.
Завершающий этап работы программы — сохранение и экспорт результатов распознавания. На самом деле, в сохранении результатов нет нужды, поскольку вся информация, включая распознанный текст и его форматирование, автоматически сохраняются в пакете вместе с исходным изображением и сведениями о макете страниц. Пользователь может просто закрыть Fine Reader , не опасаясь потери данных, однако отдельно сохраненный текст можно импортировать в различные форматы для дальнейшей работы с ним в других приложениях.
Каждый из описанных шагов — импорт изображений, анализ документа и распознавание, проверка орфографии и сохранение результатов представлены кнопками в панели инструментов программы, что значительно упрощает работу.
Главное окно программы Fine Reader. Программа относительно проста в использовании (особенно если учесть сложность выполняемой ею задачи). Отключаемые панели инструментов снабжены всплывающими подсказками, информативная строка состояния поясняет назначение всех элементов управления, имеется мощная справочная система.
РЕДАКТИРОВАНИЕ PDF ✏️ КАК РАСПОЗНАТЬ И ПЕРЕВЕСТИ ДОКУМЕНТ В WORD
После запуска программы Fine Reader (Пуск/Программы/АВВУУ Fine Reader) открывается Главное окно (рисунок 3.1) программы.

Рисунок 3.1 — Главное Окно Fine Reader
В верхней части Главного окна находится меню системы, под ним — панели инструментов. В программе их четыре: Стандартная, Форматирование, Изображение и ScanRead.в открывшемся меню выбрать пункт Мастер ScanRead
На первом этапе сканер играет роль «глаза» компьютера, при этом полученное изображение является ни чем иным, как набором черных, белых или цветных точек, картинкой, которую невозможно отредактировать ни в одном текстовом редакторе.
Fine Reader взаимодействует со сканером через стандартные драйверы, что обеспечивает ему совместимость практически со всеми современными сканерами.
Для сканирования изображения документ кладут на стекло сканера страницу с текстом или книгу и нажимают кнопку. Сканировать (Scan) или в меню Файл выбирают пункт Сканировать. В результате в Главном окне программы Fine Reader появится окно Изображение с «фотографией» вставленной в сканер страницы.
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании, что достигается установкой основных параметров сканирования — типа изображения, разрешения и яркости.
Сканирование в сером типе изображения (256 градаций) является оптимальным режимом для системы распознавания, и подбор яркости осуществляется автоматически. Черно-белый тип изображения обеспечивает более высокую скорость сканирования, но при этом теряется часть информации о буквах, что может привести к ухудшению качества распознавания на документах среднего и низкого качества печати.
Если необходимо, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используется серый тип изображения.
Для обычных текстов (с размером шрифта 10 и более пунктов) устанавливают разрешение не менее 300 точек на дюйм, а текстов с мелким шрифтом (9 и менее пунктов) — 400. 600 точек на дюйм. В большинстве случаев при сканировании подходит среднее значение яркости — 50 %, и только на некоторых документах при сканировании в черно-белом режиме может понадобиться дополнительная настройка яркости.
Для удобства сканирования большого числа страниц в программе предусмотрен специальный режим Сканировать несколько страниц. Он позволяет отсканировать несколько страниц в цикле, затем их распознать в один прием и сохранить в выбранном формате.
Распознаваемое изображение может содержать много лишних точек, возникших в результате сканирования документа среднего или плохого качества. Чтобы уменьшить количество лишних точек, можно воспользоваться опцией Очистить от мусора в меню Изображение.
Ряд настроек можно сделать еще перед началом сканирования в настройках можно указать программе инвертирование изображения, очистку его от «мусора», автоматическое определение ориентации текста на изображении, для чего в меню Сервис/Опции закладке Сканирование/Открытие следует отметить соответствующие позиции.
При распознавании изображение должно иметь стандартную ориентацию, т. е. текст должен читаться сверху вниз и строки должны быть горизонтальными. По умолчанию программа при распознавании определяет и корректирует ориентацию изображения автоматически, но имеется возможность повернуть изображение вручную.
После завершения сканирования изображение окажется включенным в конец пакета, если не активна опция Запрашивать номер страницы перед добавлением в пакет, а его пиктограмма отобразится на панели пакета (вертикальная панель слева на экране). Если щелкнуть мышью по этой пиктограмме, можно увидеть все окна Fine Reader , при этом основное место на экране будет занимать окно изображения и текста, в левой части которого расположено изображение страницы, а в правой будет находиться распознанный текст. Каждая из этих двух частей главного окна программы снабжена стандартными инструментами управления масштабом, а слева от окна изображения имеется еще и небольшая панель инструментов работы с изображением.
На изображении страницы можно увидеть небольшую пунктирную рамку с лупой. Та часть изображения, которая попадет в эту рамку, отображается в окне крупного плана. Щелчок мыши по определенной части изображения переместит центр увеличиваемой области в указанное место.
Анализ макета страниц.Передраспознаванием текста, необходимо указать, какие именно области подлежат распознаванию, как расположены строки.
Определение ориентации текста при установке соответствующей опции производится автоматически, хотя можно сделать это и вручную путем поворота исходного изображения. Выделение областей распознавания текста решает еще две задачи: во-первых, отдельными блоками выделяются таблицы и рисунки, которые не подлежат распознаванию; во-вторых, четкое выделение блоков позволяет максимально корректно сохранить макет исходной страницы при передаче распознанного документа во внешние приложения (МS Word и Adobe Acrobat).
Далее нажать кнопку Распознать, при этом различные части изображения, содержащие текст, таблицы или рисунки, окажутся обведенными рамками разных цветов и обозначены цифрами в углу каждой рамки. Цвет служит для обозначения типа блока — в стандартных настройках зеленый цвет для текста, красный для рисунков и синий для таблиц. Цветовое кодирование можно при желании изменить (рисунок 3.4).
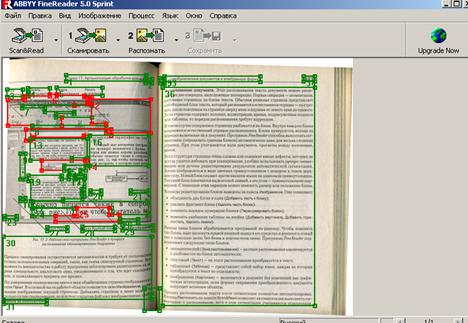
Рисунок 3.4 — Окно анализа макета страниц
Блоки — это заключенные в рамки участки изображения. Блоки выделяют для того, чтобы указать программе, какие участки отсканированной страницы надо распознавать и в каком порядке. Также по ним воспроизводится исходное оформление страницы.
При обработке изображений выделяются блоки следующих типов: зона распознавания, текст, таблица, картинка и штрих-код (только в версии Office).
Изменять размеры или форму существующих блоков можно, потянув мышью за их границы. Изменить тип блока позволяет «всплывающее» меню, появляющееся после щелчка мышью по пиктограмме в углу блока, обозначающего его тип.
Для более сложного редактирования макета используются панели инструментов, расположенные слева от окна изображения. Они позволяют нарисовать новые блоки заданного типа, добавить или удалить часть блока, хотя удалить блок можно также с клавиатуры нажатием на клавишу [Dе1] после его выделения.
При автоматическом анализе макета страниц оригинальные изображения достаточно корректно разбиваются на блоки. Неточности, которые программа все-таки допускает, можно легко отредактировать с помощью панели инструментов.
Распознавание текста.После создания макета и его редактирования можно приступить к распознаванию. Задача распознавания состоит в том, чтобы преобразовать отсканированное изображение в текст, сохранив при этом оформление страницы. Fine Reader поддерживает более сотни языков. Язык, на котором будет проводиться распознавание, выбирается на основной панели инструментов.
Если исходный текст документа многоязычный, то можно указать несколько языков одновременно, однако следует принять во внимание, что увеличение числа включенных языков замедляет процесс распознавания. Помимо языка оригинала, модуль распознавания учитывает и тип печати, который по умолчанию определяется автоматически, но при необходимости может быть установлен и вручную.
При распознавании текстов, напечатанных на матричном принтере в черновом режиме или на пишущей машинке, можно добиться более высокого качества распознавания, установив правильный тип печати. Выделяются два специфических типа печати: Матричный принтер и пишущая машинка (Сервис/Опции/Тип печати).
Проверка правописания и сохранение результатов работы.Модуль распознавания анализирует не только отдельные символы, но и целые слова, используя при этом встроенный словарь. Кроме того, этот модуль особым образом помечает «неуверенно распознанные» символы.
Работа со словами, неизвестными системе, и с неуверенно распознанными символами осуществляется в модуле проверки правописания. Он вызывается кнопкой Проверить правописание. На рисунок 3.5 изображен спеллер Fine Reader, который предлагает варианты слов, один из которых надо выбрать и нажать кнопку Заменить. Можно поправить ошибку прямо в окне спеллера, а можно оставить слово, как оно есть, если это правильное, но не известное спеллеру слово, тогда используется кнопка Пропустить.
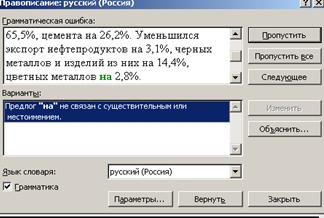
Рисунок 3.5 — Диалоговое окно проверки правописания
Весь распознанный текст виден в окне текста главного окна программы. Оно представляет собой несложный текстовый редактор, позволяющий свободно изменять и гарнитуру шрифта, и его начертание. К тому же в этом окне цветом будут отмечены неуверенно распознанные символы.
После окончания проверки правописания следует определить, в каком формате сохранять полученные результаты (кнопка Сохранить), например RTF, DОС, PDF, НТМL, DBF, ХLS.
Как видно из приведенного списка, Fine Reader позволяет передавать результаты распознавания практически во все широко используемые приложения, такие как MS Word, Мs Ехсе1, а также использовать автоматический ввод для публикации в Wеb и для заполнения баз данных.
3.2 Системы машинного перевода
Дата добавления: 2018-04-15 ; просмотров: 377 ; Мы поможем в написании вашей работы!
Источник: studopedia.net
Как выполняется настройка операций выполняемых программой fine reader
Внимание Скидка 50% на курсы! Спешите подать
заявку
Профессиональной переподготовки 30 курсов от 6900 руб.
Курсы для всех от 3000 руб. от 1500 руб.
Повышение квалификации 36 курсов от 1500 руб.
Лицензия №037267 от 17.03.2016 г.
выдана департаментом образования г. Москвы

Конспект урока информатики на тему «Возможности систем распознавания текстов»
Тема: Возможности систем распознавания текстов.
Цель. Изучить возможности и порядок работы с программой распознавания текста Fine Reader .
Оборудование: ЛВС, персональный компьютер, среда MS Word, программа FineReader.
FineReader — это система оптического распознавания текстов (OCR), которая преобразует полученное с помощью сканера графическое изображение (картинку) в текст (т. е. в коды букв, «понятные» системе).
Процесс ввода текстов в компьютер осуществляется в несколько этапов: сканирование; выделение блоков на изображении; распознавание; проверка ошибок; сохранение результата распознавания (передача его в другое приложение, в буфер и т. п.).
Программа Fine Reader выпускается отечественной компанией ABBYY Software ( www . bitsoft . ru ). Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках, а также для распознавания смешанных двуязычных текстов.
Программа имеет ряд удобных возможностей. Она позволяет объединять сканирование и распознавание в одну операцию, рабо тать с пакетами документов (или с многостраничными докумен тами) и с бланками. Программу можно обучать для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов. Она позволяет редактировать распознанный текст и проверять его орфографию.
Fine Reader работает с разными моделями сканеров. В частности, П рограмма поддерживает стандарт TWAIN .
Порядок выполнения работы
- Выполните сканирование предложенного Вам документа и сохраните его в папке «…. Группа» на Рабочем столе центрального компьютера.
- Скопируйте папку «…. Группа» в Общую папку на центральном компьютере.
- По локальной сети откройте эту папку на вашем компьютере. Скопируйте свой документ в свою папку.
- Запустите программу FineReade r ( Пуск – Программы )
- В окне FineReader выполните команду Файл – Открыть изображение, найдите свой документ и откройте его в окне программы FineReader .
- Выберите язык для распознавания документа.
- Выполните распознавание графического файла, сегментируйте текстовые блоки, таблицы и рисунки.
- Выполните проверку отсканированного документа. Ошибки исправляйте в окне Текст или в диалоговом окне Проверка .
- Сохраните отсканированный документ в формате Word .
- Задайте параметры страниц документа ( вкладка Разметка страницы – группа Параметры страницы ): ориентация альбомная, левое поле 1,5 см, правое 1,5 см, верхнее 3см, нижнее 2 см., расстановка переносов Автоматическая . Параметры абзацев: выравнивание по ширине, отступ первой строки 1,5см, интервал перед абзацем 6пт, интервал между строчками 1,15. Для картинки используйте команду Обтекание текстом – по контуру .
- В верхний колонтитул запишите дату и номер работы. В нижний колонтитул запишите виши фамилию, имя и группу. В готовый документ запишите тему и цель работы.
- Выведите готовый документ на печать.
- Перечислите основные элементы окна программы Fine Reader.
- Дайте понятие сегментации изображения.
- Как выполняется настройка операций, выполняемых программой Fine Reader ?
Источник: doc4web.ru
Конспект урока «Возможности систем распознавания текстов» по информатике
FineReader — это система оптического распознавания текстов (OCR), которая преобразует полученное с помощью сканера графическое изображение (картинку) в текст (т. е. в коды букв, «понятные» системе).
Процесс ввода текстов в компьютер осуществляется в несколько этапов: сканирование; выделение блоков на изображении; распознавание; проверка ошибок; сохранение результата распознавания (передача его в другое приложение, в буфер и т. п.).
Программа Fine Reader выпускается отечественной компанией ABBYY Software ( www . bitsoft . ru ). Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках, а также для распознавания смешанных двуязычных текстов.
Программа имеет ряд удобных возможностей. Она позволяет объединять сканирование и распознавание в одну операцию, рабо тать с пакетами документов (или с многостраничными докумен тами) и с бланками. Программу можно обучать для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов. Она позволяет редактировать распознанный текст и проверять его орфографию.
Fine Reader работает с разными моделями сканеров. В частности, П рограмма поддерживает стандарт TWAIN .
Порядок выполнения работы
- Выполните сканирование предложенного Вам документа и сохраните его в папке «…. Группа»на Рабочем столе центрального компьютера.
- Скопируйте папку «…. Группа»в Общую папку на центральном компьютере.
- По локальной сети откройте эту папку на вашем компьютере. Скопируйте свой документ в свою папку.
- Запустите программу FineReade r ( Пуск – Программы )
- В окне FineReader выполните команду Файл – Открыть изображение, найдите свой документ и откройте его в окне программы FineReader.
- Выберите язык для распознавания документа.
- Выполните распознавание графического файла, сегментируйте текстовые блоки, таблицы и рисунки.
- Выполните проверку отсканированного документа. Ошибки исправляйте в окне Текст или в диалоговом окне Проверка.
- Сохраните отсканированный документ в формате Word .
- Задайте параметры страниц документа (вкладка Разметка страницы – группа Параметры страницы): ориентация альбомная, левое поле 1,5 см, правое 1,5 см, верхнее 3см, нижнее 2 см., расстановка переносов Автоматическая. Параметры абзацев: выравнивание по ширине, отступ первой строки 1,5см, интервал перед абзацем 6пт, интервал между строчками 1,15. Для картинки используйте команду Обтекание текстом – по контуру.
- В верхний колонтитул запишите дату и номер работы. В нижний колонтитул запишите виши фамилию, имя и группу. В готовый документ запишите тему и цель работы.
- Выведите готовый документ на печать.
Контрольные вопросы
- Перечислите основные элементы окна программы Fine Reader.
- Дайте понятие сегментации изображения.
- Как выполняется настройка операций, выполняемых программой FineReader?
Здесь представлен конспект к уроку на тему «Возможности систем распознавания текстов», который Вы можете бесплатно скачать на нашем сайте. Предмет конспекта: Информатика Также здесь Вы можете найти дополнительные учебные материалы и презентации по данной теме, используя которые, Вы сможете еще больше заинтересовать аудиторию и преподнести еще больше полезной информации.
Список похожих конспектов
Возможности текстового редактора Word
ГБОУ СПО «Ардатовский аграрный техникум». План занятия. по дисциплине «Информатика и ИКТ». Тема: Возможности текстового редактора Word. . .
Возможности текстового редактора Word
Открытый урок по информатике. Возможности текстового редактора. Word. . Цели урока. : закрепить и систематизировать знания и умения учащихся по .
Возможности текстового редактора Word
Урок информатики в 8 классе по теме. . «Возможности текстового редактора Word. ». Цели урока. : закрепить и систематизировать знания и умения .
Возможности текстового процессора MS Word
Урок на тему: «Возможности текстового процессора. MS. . Word. .». Цели урока:. закрепить и систематизировать знания и умения учащихся по теме .
Системы оптического распознавания документов
Тема: Системы оптического распознавания документов. Цель:. формирование представления о программах для работы со сканером, знать системы распознавания .
Кодирование числовой информации. Представление информации с помощью систем счисления
6. . ПЛАН-КОНСПЕКТ УРОКА «Кодирование числовой информации. Представление информации с помощью систем счисления.». . ФИО. . Макшанцев .
Кодирование информации с помощью знаковых систем
ПЛАН-КОНСПЕКТ УРОКА Кодирование информации с помощью знаковых систем. . (Тема урока). . ФИО (полностью). . Семиякин Геннадий Николаевич. .
Киберугрозы современности: главные правила их распознавания и предотвращения
Тема урока: «Киберугрозы современности: главные правила их распознавания и предотвращения». Учитель: Полиенко Елена .
Информационные модели систем управления
КОНСПЕКТ УРОКА . ПО ИНФОРМАТИКЕ. Тема урока «. Информационные модели систем управления». Класс. 9. Тема урока. :. «. Информационные модели .
Возможности динамических (электронных) таблиц
УТВЕРЖДАЮ. зам. директора по УР. _____________. План урока. Дата. 12.02.2014. Группа. № ПК-13.
Дисциплина:. «Информатика и ИКТ». Тема .
Представление числовой информации с помощью систем счисления
Разработка уроков №3-4. «Представление числовой информации с помощью систем счисления». по теме: «Информация и информационные процессы». 10 класс. .
Представление текстов в памяти компьютера. Кодировочные таблицы
. Государственное бюджетное общеобразовательное учреждение средняя общеобразовательная школа № 247 Красносельского района Санкт-Петербурга. .
Графический интерфейс операционных систем и приложений
Тема урока “Графический интерфейс операционных систем и приложений”. 8 класс. 1 час учебного времени. Тип урока:. урок изучения и первичного .
Возможности Интернета. Поиск информации в сети Интернет
Урок №33. Тема: Возможности Интернета. Поиск информации в сети Интернет. Цель:. Актуализировать знания учащихся о глобальной сети Интернет. Дать .
Компьютерное моделирование биологических систем
ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ. СРЕДНЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ. «ТВЕРСКОЙ КОЛЛЕДЖ СЕРВИСА и ТУРИЗМА». .
Перевод чисел из 2,8,16 систем счисления в 10 систему счисления с помощью программы MS Office Excel
Технологическая карта урока. Информатика. 9 класс. ФГОС. Раздел программы:.
Тема урока:. Перевод чисел из 2,8,16 систем счисления в 10 систему счисления .
Графический интерфейс операционных систем и приложений
БЕГАЛИЕВ РУСТАМ НУРМАНБЕТОВИЧ. УЧИТЕЛЬ ИНФОРМАТИКИ. МКОУ ТАЕЖНИНСКАЯ СОШ №7. Конспект урока информатики в 8 классе. по теме «Графический .
Представление числовой информации с помощью систем счисления
Графический интерфейс операционных систем и приложений
ТЕХНОЛОГИЧЕСКАЯ КАРТА УРОКА. Урок по информатике на тему: «Графический интерфейс операционных систем и приложений». Педагогические задачи. .
Графический способ решения систем уравнений с 2-мя переменными средствами Microsoft Excel
Урок по теме:. «Графический способ решения систем уравнений с 2-мя переменными средствами. Microsoft. . Excel. ». Класс: 9. . . Кол-во часов: .
Источник: prezentacii.org