
Программисты делятся на две категории: те, которые используют отладчик при разработке, и те, которые обходятся без него. В этом посте я попытался обобщить, какие типы сущностей можно выявить в исходном коде JS-программы, и как эти типы выглядят под отладчиком. JS-программисты из первой категории могут дополнить, если я упустил какой-либо тип сущностей, а JS-программисты из второй категории могут посмотреть на то, чего, возможно, никогда не видели.
Типы сущностей в исходном коде
Сам я сталкивался со следующими типами:
- примитивы: строка, число, логическое значение, null, undefined, символ;
- области видимости (scopes)
- (update) замыкания
- объекты
- массивы
- функции
- классы
- модули
- пакеты
Примитивы
С примитивами ничего интересного, на то они и примитивы. (BigInt) Вот код:
const aBool = true; const aNull = null; const aNum = 128; const aStr = ‘128’; const aSymLocal = Symbol(‘local symbol’); const aSymGlobal = Symbol.for(‘global symbol’); let aUndef;
А вот так примитивы выглядят под отладчиком (слева — в браузере Chrome, справа — в IDE PhpStorm):
Исходный код: что это такое и зачем это нужно | SEMANTICA
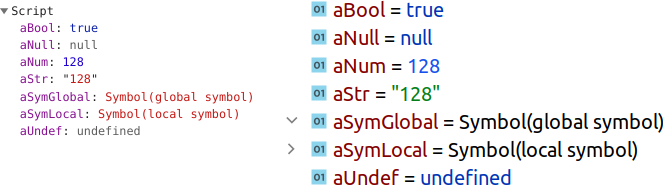
Ну разве что обращает на себя внимание стрелка рядом с символом в IDEA (PhpStorm), как будто aSymGlobal и aSymLocal являются составными компонентами, а не примитивными элементами. Стрелку на aSymGlobal я развернул — нет там ничего.
UPDATE: К примитивам можно отнести BigInt, т.к. у него свой собственный тип:
typeof BigInt(‘1’) === ‘bigint’ // true
Области видимости
Проще всего организовать различные области видимости переменных при помощи блоков:
При остановке в отладчике во внутреннем блоке видны переменные из всех трёх областей:

Также и в браузере, и в nodejs доступна глобальная область видимости (Global), а в nodejs ещё доступна область видимости исполняемого фрагмента кода (скрипта) — Local.
Объекты
В JavaScript’е всё, что не примитив, то объект (включая функции и массивы). В данном разделе я рассматриваю именно объекты (которые не функции и не массивы):
const code = Symbol(); const name = Symbol(); const obj = < [id]: 1, [code]: ‘ant’, [name]: ‘cat’, aStr: ‘string’, aNum: 64, anObj: < [code]: ‘dog’ >>
Символы рекомендуется использовать в качестве идентификаторов свойств объекта и из кода понятно, что ‘ant’ — это код для объекта obj , а ‘cat’ — это имя. Для объекта obj.anObj ‘dog’ — это код.
В отладчике не всё так однозначно:

Если у символа отсутствует описание, то непонятно, какое свойство является именем, а какое — кодом.
Прототип объекта
В свойстве obj.__proto__ находится ссылка на прототип, по которому создавался данный объект. Объекты создаются при помощи конструктора (функция Object.constructor() ), который в качестве прототипа для новых объектов использует свойство Object.constructor.prototype :
Основы программирования: Исходный код
const obj = <>;
Таким образом obj.__proto__ === obj.__proto__.constructor.prototype :

prototype в свою очередь содержит ту же функцию constructor , которая содержит тот же prototype , и т.д. — циклическая зависимость, по которой можно спускаться вглубь, пока хватит ресурсов компьютера.
В отладчике также видно, что, например, функция assign является методом конструктора f Object() (методом класса Object ), а не методом свежесозданного объекта obj .
Таким образом отладчик может быть своего рода кратким справочником по методам соответствующих базовых классов:
obj.__proto__.constructor.assign // Object.assign
Массивы
Массивы — это такие специфические объекты, которые и в коде, и под отладчиком выглядят слегка иначе, чем обычные объекты. Вместо фигурных скобок <> применяются квадратные [] :
let undef; const arr = [1, ‘str’, null, undef, , [‘internal’, ‘array’]];
Массив очень похож на объект, только вместо имён ключей (свойств) применяются числовые индексы:
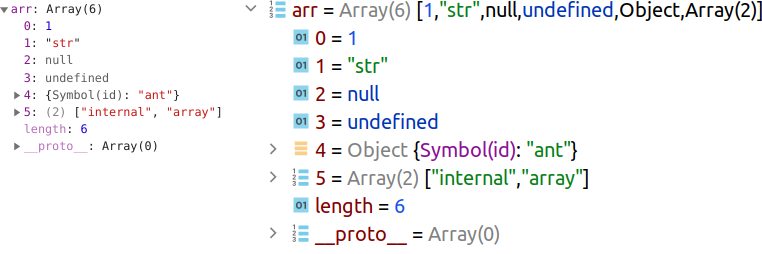
Прототип массива
Под отладчиком видно, что в основе у массивов находится Array:
arr.__proto__ => Array arr.__proto__.constructor.isArray // Array.isArray
у которого в основе находится Object:
arr.__proto__.__proto__ => Object
Функции
Стрелочные vs. Обычные
Стрелочные функции исполняются в области видимости родителя, обычные — создают собственную область видимости.
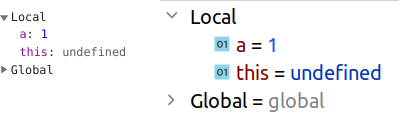
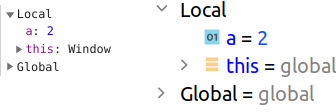
// arrow function ((a) => < debugger; return a + 2; >)(1); // regular function (function (a) < debugger; return a + 2; >)(2);
Если запустить данный код в браузере/nodejs, то переменная this в локальной области видимости будет неопределена для стрелочных функций:
и будет соответствовать глобальному объекту (Window или global) для обычных:
Именованные vs. Анонимные
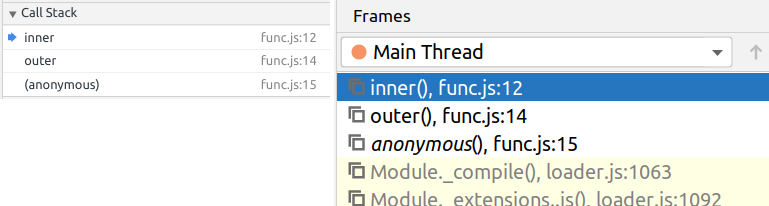
Различия между именованными и анонимными функциями видны в стеке вызовов.
// anonymous functions (function (a) < return 2 + (function (b) < debugger; return b + 4; >)(a); >)(1); // named functions (function outer(a) < return 2 + (function inner(b) < debugger; return b + 4; >)(a); >)(1);
Для анонимных функций в стеке указывается только файл и строка кода:

Для именованных — ещё и имя функции, что удобно:
Прототип функции
Прототипом функции является объект Function, для которого прототипом является Object:
func.__proto__ => Function func.__proto__.constructor.caller // Function.caller func.__proto__.__proto__ => Object
Классы
Именованные vs. Анонимные
< const AnonClass = class < name = ‘Anonymous’ >; class NamedClass < name = ‘Named’ >function makeAnonClass() < return class < name = ‘Dynamic Anon’ >; > function makeNamedClass() < return class DynamicNamed < name = ‘Dynamic Named’ >; > const DynamicAnonClass = makeAnonClass(); const DynamicNamedClass = makeNamedClass(); const anon = new AnonClass(); const named = new NamedClass(); const dynAnon = new DynamicAnonClass(); const dynNamed = new DynamicNamedClass(); const justObj = new (class < name = ‘Just Object’ >)(); debugger; >
Объекты, созданные при помощи анонимного класса, приравненного к какой-либо переменной, в отладчике видны под именем этой переменной ( anon ).
Объекты, созданные при помощи именованных классов, в отладчике видны под именами этих классов ( dynNamed и named ).
Имя класса, к которому принадлежит объект, находится в obj.__proto__.constructor.name .
Объекты, созданные при помощи динамически созданного анонимного класса, видны в отладчике IDEA под именем базового класса Object, а в отладчике Хрома — без названия, как и простой объект ( dynAnon ). Т.е., у них obj.__proto__.constructor.name отсутствует.
Объект justObj проще было бы создать при помощи обычных фигурных скобок , чем при помощи одноразовой конструкции new (class )() .
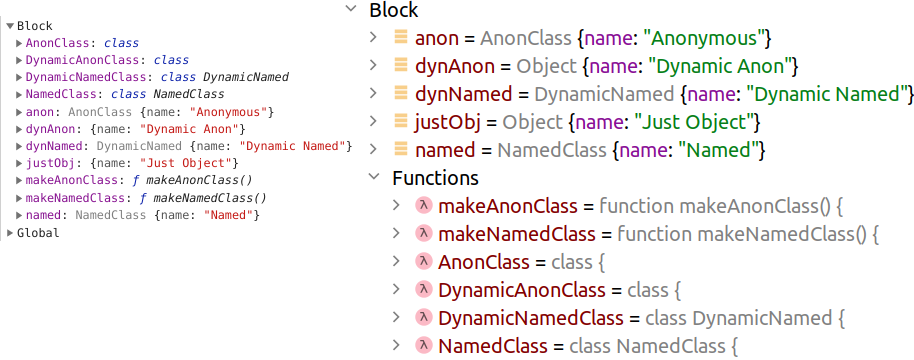
В общем, объекты, созданные при помощи именованных классов, в отладчике маркируются именем соответствующего класса (именем конструктора), что очень сильно облегчает жизнь разработчику.
Отладчик Хрома выводит и классы, и объекты-переменные в едином списке, IDEA выделяет функции и классы в отдельный список Functions внутри соответствующей области видимости.
Класс — это функция
class Demo <>
В отладчике видно, что класс Demo является функцией ( Demo.__proto__ => Function ). IDEA выносит классы в секцию Functions внутри блока:
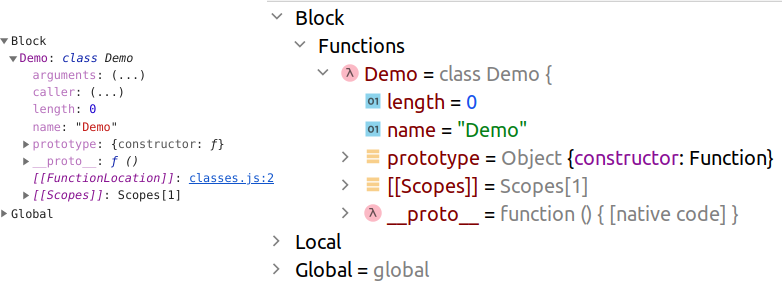
У класса есть свойство prototype которое он использует в качестве свойства __proto__ для новых объектов, создаваемых при помощи оператора new :
const demo = new Demo(); demo.__proto__ === Demo.prototype // true
Экземпляры класса
Экземпляры, создаваемые при помощи оператора new , являются объектами (не функциями, как сам класс):
< class Demo < propA methodA() <>> const demo = new Demo(); debugger; >
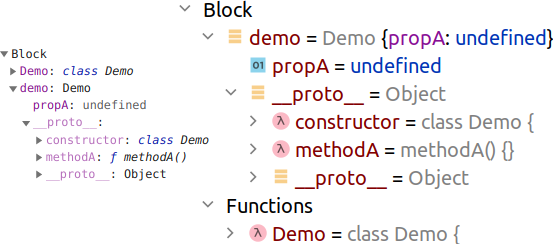
Под отладчиком видно, что методы нового объекта находятся в его прототипе ( demo.__proto__.methodA ), а свойства — в самом объекте ( demo.propA ).
Статические свойства и методы
< class Demo < static propStat static methodStat() < return this.propStat; >> const demo = new Demo(); Demo.methodStat(); debugger; >
Статические члены «вешаются» на саму класс-функцию, а не на объекты, создаваемые при помощи оператора new :
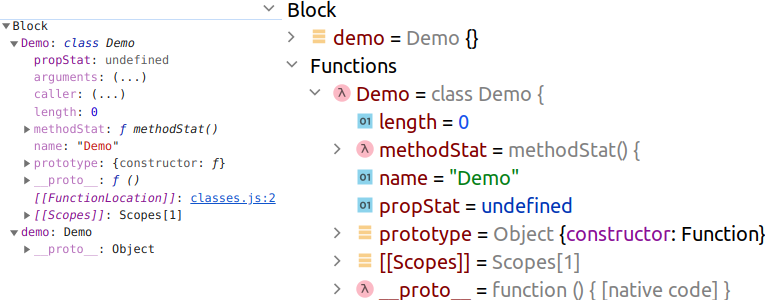
Видно, что у объекта demo нет никаких свойств и методов, зато у класс-функции Demo есть свойство propStat и метод methodStat .
Приватные свойства и методы
< class Demo < #propPriv = ‘private’ #methodPriv() < return this.#propPriv; >> const demo = new Demo(); debugger; >
Приватные свойства и методы видны в Хроме, а в IDEA прячутся в деталях объекта, но видны в его аннотации:

Акцессоры (get виртуальное» свойство, позволяя контролировать присвоение данных этому свойству и получение данных от свойства:
< class Demo < #prop get prop() < return this.#prop; >set prop(data) < this.#prop = data; >> const demo = new Demo(); demo.prop = ‘access’; debugger; >
И в Хроме, и в IDEA данное «виртуальное» свойство при отладке сразу не отображается (стоит троеточие вместо значения), а для получения данных нужно в явном виде вызвать getter (двойной щелчок мыши по свойству):
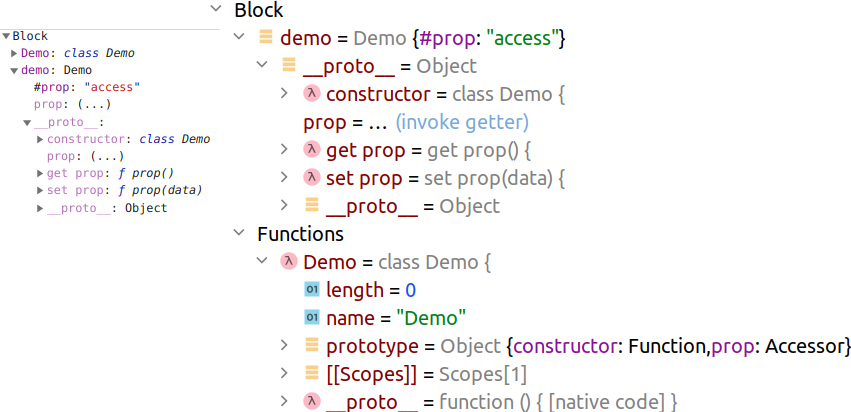
В IDEA в аннотации прототипа класс-функции ( Demo.prototype ) видно, что prop: Accessor . Также стоит отметить, что «виртуальное» свойство (являясь парой функций) относится скорее к прототипу объекта, чем к самому объекту: если Хром отображает prop в свойствах объекта и в свойствах его прототипа, то IDEA — только в свойствах прототипа.
Наследование
< class Parent < name = ‘parent’ parentAge = 64 action() <>actionParent() <> > class Child extends Parent < name = ‘child’ childAge = 32 action() <>actionChild() <> > const child = new Child(); debugger; >
При наследовании прототипы выстраиваются в цепочку, а при добавлении свойств в новый объект конструктор наследника перекрывает значения таких же свойств родителя ( name в итоге равен «child»):

Также видно, что перекрытые методы родителя доступны через прототипы:
child.__proto__.__proto__.action();
Из необычного, и Хром, и Idea аннотируют прототип child.__proto__ как Parent , хотя прототип по факту содержит методы из класса Child .
Модули
Модуль в JS — это отдельный файл, подключаемый через import . Пусть содержимое модуля находится в файле ./sub.mjs (расширение «*.mjs» означает, что в файл содержит ES6-модуль):
function modFunc() <> class ModClass <> const MOD_CONST=’CONSTANT’; export ;
а вызывающий скрипт выглядит так:
import * as sub from ‘./sub.mjs’; debugger;
Под отладчиком в вызывающем скрипте виден элемент sub , который не является обычным JS-объектом (у него нет прототипа):
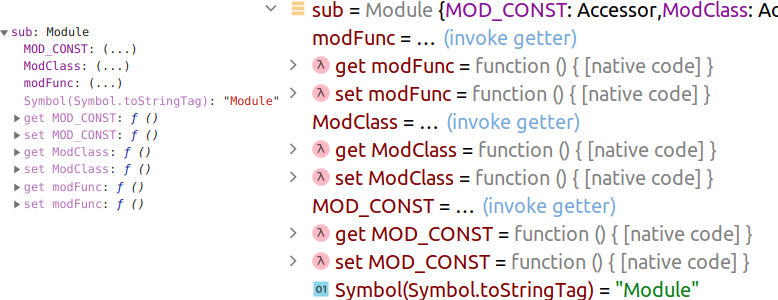
Также видно, что экспортируемые объекты модуля являются «виртуальными» свойствами (доступны через акцессоры).
Пакеты
Пакет — это способ организации кода в nodejs, в браузере пакеты отсутствуют. Если JS-модуль представляет из себя файл, то пакет — это группа файлов, главным из которых является package.json , в котором задаётся точка входа в пакет (по-умолчанию — index.js ). В точке входа описывается экспорт пакета, аналогично тому, как описывается экспорт в модуле. Поэтому импорт пакета аналогичен импорту модуля, за исключением того, что при импорте указывается не путь к модулю (filepath или URL), а имя пакета:
// import * as sub from ‘./sub.mjs’; import * as express from ‘express’;
Под отладчиком сущности, импортируемые из пакета, аналогичны импортируемым из модуля:

Резюме
Не знаю, увидели ли вы что-либо новое для себя в этой статье (если нет, то надеюсь, вы хотя бы не читали её внимательно, надеясь найти что-то новое), зато я обнаружил для себя много чего незнакомого, пока её писал. Что уже хорошо, пусть и не в масштабах Вселенной.
Всем спасибо за внимание. Хэппи, как говорится, кодинга. Ну и дебаггинга.
Источник: habr.com
Как выглядит программный код
Исхо́дный код (также исхо́дный текст) — текст компьютерной программы на каком-либо языке программирования или языке разметки, который может быть прочтён человеком. В обобщённом смысле — любые входные данные для транслятора. Исходный код транслируется в исполняемый код целиком до запуска программы при помощи компилятора или может исполняться сразу при помощи интерпретатора.
Назначение [ править | править код ]
Исходный код либо используется для получения объектного кода, либо выполняется интерпретатором. Изменения выполняются только над исходным, с последующим повторным преобразованием в объектный.
Другое важное назначение исходного кода — в качестве описания программы. По тексту программы можно восстановить логику её поведения. Для облегчения понимания исходного кода используются комментарии. Существуют также инструментальные средства, позволяющие автоматически получать документацию по исходному коду — т. н. генераторы документации.
Кроме того, исходный код имеет много других применений. Он может использоваться как инструмент обучения; начинающим программистам бывает полезно исследовать существующий исходный код для изучения техники и методологии программирования. Он также используется как инструмент общения между опытными программистами благодаря своей лаконичной и недвусмысленной природе. Совместное использование кода разработчиками часто упоминается как фактор, способствующий улучшению опыта программистов.
Программисты часто переносят исходный код (в виде модулей, в имеющемся виде или с адаптацией) из одного проекта в другой, что носит название повторного использования кода.
Исходный код — важнейший компонент для процесса портирования программного обеспечения на другие платформы. Без исходного кода какой-либо части ПО портирование либо слишком сложно, либо вообще невозможно.
Организация [ править | править код ]
Исходный код некоторой части ПО (модуля, компонента) может состоять из одного или нескольких файлов. Код программы не обязательно пишется только на одном языке программирования. Например, часто программы, написанные на языке Си, из соображений оптимизации содержат вставки кода на языке ассемблера. Также возможны ситуации, когда некоторые компоненты или части программы пишутся на различных языках, с последующей сборкой в единый исполняемый модуль при помощи технологии, известной как компоновка библиотек (library linking).
Сложное программное обеспечение при сборке требует использования десятков или даже сотен файлов с исходным кодом. В таких случаях для упрощения сборки обычно используются файлы проектов, содержащие описание зависимостей между файлами с исходным кодом и описывающие процесс сборки. Эти файлы также могут содержать параметры для компилятора и среды проектирования.
Для разных сред проектирования могут применяться разные файлы проекта, причём в некоторых средах эти файлы могут быть в текстовом формате, пригодном для непосредственного редактирования программистом с помощью универсальных текстовых редакторов, в других средах поддерживаются специальные форматы, а создание и изменения файлов производится с помощью специальных инструментальных программ. Файлы проектов обычно включают в понятие «исходный код». Часто под исходным кодом подразумевают и файлы ресурсов, содержащие различные данные, например графические изображения, нужные для сборки программы.
Для облегчения работы с исходным кодом и для совместной работы над кодом командой программистов используются системы управления версиями.
Качество [ править | править код ]
В отличие от человека, для компьютера нет «хорошо написанного» или «плохо написанного» кода. Но то, как написан код, может сильно влиять на процесс сопровождения ПО. О качестве исходного кода можно судить по следующим параметрам:
- читаемость кода (в том числе наличие комментариев к коду);
- лёгкость в поддержке, тестировании, отладке и устранении ошибок, модификации и портировании;
- экономное использование ресурсов: памяти, процессора, дискового пространства;
- отсутствие замечаний, выводимых компилятором;
- отсутствие «мусора» — неиспользуемых переменных, недостижимых блоков кода, ненужных устаревших комментариев и т. д.;
- адекватная обработка ошибок;
- возможность интернационализации интерфейса.
Неисполняемый исходный код [ править | править код ]
Копилефтные лицензии для свободного ПО требуют распространения исходного кода. Эти лицензии часто используются также для работ, не являющихся программами — например, документации, изображений, файлов данных для компьютерных игр.
В таких случаях исходным кодом считается форма данной работы, предпочтительная для её редактирования. В лицензиях, предназначенных не только для ПО, она также может называться версией в «прозрачном формате». Это может быть, например:
- для файла, сжатого с потерей данных — версия без потерь;
- для рендеравекторного изображения или трёхмерной модели — соответственно, векторная версия и модель;
- для изображения текста — такой же текст в текстовом формате;
- для музыки — файл во внутреннем формате музыкального редактора;
- и наконец, сам файл, если он удовлетворяет указанным условиям, либо если более удобной версии просто не существовало.
Любая программа или онлайн-сервисы, например, Word, Microsoft Windows, WhatsApp или же браузер, которые ежедневно запускают сотни миллионов человек, так или иначе, состоят из особых инструкций. Или специального программного кода, который понятен машине, говорит, что ей делать или, наоборот, не делать. Или как правильно реагировать на действия пользователя. Что такое программный код, будет разобрано в этой статье.
Описание
Программный код программы — это текст, выполненный на особом языке, понятном машине. Он может выполняться непосредственно по тексту с помощью интерпретатора или транслироваться в особый вид с помощью компилятора.

Исходный код программы может состоять из нескольких файлов. При этом все они должны быть одинакового формата. Текст программы, содержащейся в них, должен быть написан на одном и том же языке. Правда, могут встречаться и исключения. Например, в веб-разработке в файле страницы могут содержаться несколько различных языков программирования и стандартов.
В зависимости от сложности проекта, могут присутствовать такие языки и технологии, как PHP, HTML, JavaScript, Java и другие.
Сложные программные комплексы при сборке могут потребовать большого количества файлов, которое может исчисляться целыми сотнями. Для совместной работы над такими большими проектами программисты очень часто используют системы контроля версий. Они позволяют одновременно работать с несколькими экземплярами исходного кода, который на определённом этапе разработки можно соединить в один общий.

Качество кода
Компьютер не способен понять, как написан код для него, плохо или хорошо. Если он будет работоспособен и не содержит ошибок, то машина запустит его в любом случае. Плохой код может усложнить задачи сопровождения программного обеспечения. Особенно актуально это для больших проектов. Обычно качественный код характеризуется несколькими параметрами:
- Читаемость кода. Одного взгляда на него должно хватать, чтобы обобщенно понять, что реализуется участком кода.
- Присутствие понятных и ёмких комментариев. Данный параметр очень сильно влияет на читаемость, легкость в отладке, тестирование поддержки и устранение ошибок программного кода.
- Низкая сложность.
- Оптимизация кода. Организовать его стоит таким образом, чтобы программа использовала как можно меньше системных ресурсов, таких как память, время процессора и пространство жёсткого диска.
- Отсутствие мусора. То есть не используемых переменных или блоков кода, в которой никогда не заходит управление программой.
Вредоносный программный код
Помимо полезных программ, существуют такие, которые могут нанести вред системе или даже оборудованию. Как правило, пишется такой код людьми, которые заинтересованы в какой-либо выгоде от происходящего процесса. Например, программы, которые могут похищать личные данные с компьютеров пользователей. Ими могут быть номера платёжных карт, паспортные данные, или какая-либо другая конфиденциальная информация. Другие могут просто оказывать влияние на работу системы, тем самым вызывая сбои и мешая полноценной функциональности.
Рекомендации по написанию хорошего кода
Джефф Вогел — программист с большим опытом — поделился несколькими советами для того, чтобы научить начинающих разработчиков правилам хорошего кода.
В частности, он предлагает всегда комментировать свой программный код. Что такое комментарий? Это понятное и краткое описание того, что происходит в данной строке кода или функции. Дело в том, что разработка определённой программы может затянуться на месяц или вообще приостановиться на некоторое время.
Вернувшись к работе над проектом через пару месяцев, даже опытному программисту будет сложно разобраться в своей же программе. Но подробные комментарии смогут восстановить цепочку событий и поведение кода.
Далее он рекомендует использовать в программе глобальные переменные как можно чаще. Это объясняется тем, что при изменении программного кода, придётся корректировать значение переменной всего лишь в одном месте. При этом все использующие значение функции или процедуры сразу об этом узнают и будут производить операции уже с новыми данными.
Имена переменных и выявление ошибок
Правильное название переменных также поможет значительно сократить время на изучение исходного кода программы, даже если код написан собственными руками. То есть хорошим кодом считается такой текст, где переменные и функции имеют имена, по которым можно понять, что именно они делают или хранят. При этом нужно стараться не использовать длинных имён переменных.

Очень важно уделять большое внимание своевременному устранению ошибок. Что такое программный код, который исполняется идеально? Это код, в котором нет ошибок. То есть любое ветвление цикла или изменение переменной, или вовсе какие-либо непредвиденные действия пользователя, всегда приведут к ожидаемому результату. Это достигается за счёт тестирования готового программного продукта по несколько раз.
Выявление ошибок программного кода, а точнее, их предугадывание возможно на этапе проектирования программы. Присутствие в коде различных проверок условий и возможных исключений, поможет вести управление программой по определённому курсу.
Оптимизация имеет колоссальное значение для написания работоспособной программы, которая будет экономно использовать ресурсы компьютера и при этом не допускать ошибок выполнения программного кода. Что такое оптимизированная программа? Это продукт, который способен выполнять весь заявленный функционал, ведя себя при этом «тихо» и экономно.
Практически всегда оптимизации для стабильной работы программы можно добиться только в результате проведения нескольких тестов на разных платформах и в различных условиях. Если программа начинает вести себя непредсказуемо, нужно определить, что стало причиной и по возможности устранить или перехватить процесс.
Заключение
Что такое программный код? Говоря простым языком, это набор инструкций и понятий для компьютера. Он содержит текст, который компилятор или интерпретатор могут превратить в понятный машине язык. То есть, по сути, программный код — это посредник между человеком и компьютером, который упрощает их взаимоотношения.
Исходный код — это текст компьютерной программы на языке программирования или языке разметки, который состоит из цифр и букв английского языка для понимания человеком. Исходный код компьютерной программы транслируется в исполняемы код, понятный для компьютера, и запускает работу программы с помощью компилятора или выполняет код через интерпретатор. С исходным кодом работают программисты, прописывая всю логику работы программы, добавляя комментарии в наиболее сложные участки кода для понимания их работы другими программистами, генерируя автоматическими инструментами документацию исходного кода.
Комментарии и документация, да и сам по себе исходный код программы, предназначен не только для понимания принципов и логики работы программы и отдельных ее частей, но и для обучения начинающих программистов, изучения применяемых техни и методологии разработанной программы. Совместное использование программного кода позволяет улучшать общий опыт работы программистов.
Так как очень часто одни и те же участки программного кода используются в нескольких местах программы, либо задействованы в нескольких других программах, такие участки кода принято выделять в модули и компоненты, которые можно в любой момент быстро подключить и использовать в нужной программе. Такое действие назвается — повторным использованием программного кода. Это очень облегчает разработку программ и делает ее заметно быстрей, без необходимости повторно писать одни и те же участки программного кода.
В случае применения таких модулей и компонентов, да и вообще, исходного кода самого по себе, важным моментом является переносимость на другие программные платформы, их правильная работа на этих платформах.
Переносимые модули и компоненты с исходным кодом могут состоять из одного и более файлов (десятки, тысячи файлов с кодом), а также написаны на разных языках программирования. Например, часть программы на языке программирования Си, может содержать части кода на языке ассемблера.
Для удобства и облегчения работы с исходным кодом существует множество инструментов, позволяющий автоматизировать написание кода, обеспечивать командную работу над кодом, создавать и контролировать различные версии программ.
Для компьютера, нет разницы и понимания «хорошего кода» или «плохого кода». Программисту же, для понимания что происходит в программе, написанной другим программистом, поддержки и написания новых частей программы, качество исходного кода является очень важной вещью. Ведь если код будет труден для понимания, его невозможно прочитать, а если возможно, но на это уходит много времени, то разработка и поддержка программы существенно усложнит жизнь программиста. Поэтому качество кода должно соответствовать следующим требованиям:
- читаемость кода — простой и локаничный код, с понятными комментариями там, где это действительно требуется
- легкость в пониманиии, тестировании и отладке для написания новых частей программы и устранения ошибок
- экономичное использование ресурсов — памяти, процессов, пространства на диске
- отсутствие неиспользуемых переменных, неиспользуемых участков кода, устаревших комментариев
- переносимость программы на другие платформы
Источник: hololenses.ru
2. Представление программ. Исходный код. Откомпилированный код
Исхо́дный код — текст компьютерной программы на каком-либо языке программирования или языке разметки, который может быть прочтён человеком. Исходный код либо используется для получения объектного кода, либо выполняется интерпретатором. Изменения никогда не выполняются над объектным кодом, только над исходным, с последующим повторным преобразованием в объектный.
Исходный код — код на языке программирования понятном человеку (программисту). Объектный (исполняемый) код — код в машинных кодах (командах) «понятных» процессору. Он их и только их и исполняет.
3. Компиляция программного кода
Компиляция — трансляция программы, составленной на исходном языке высокого уровня, в эквивалентную программу на низкоуровневом языке, близком машинному коду(абсолютный код, объектный модуль, иногда на язык ассемблера). Входной информацией для компилятора (исходный код) является описание алгоритма или программа напроблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).
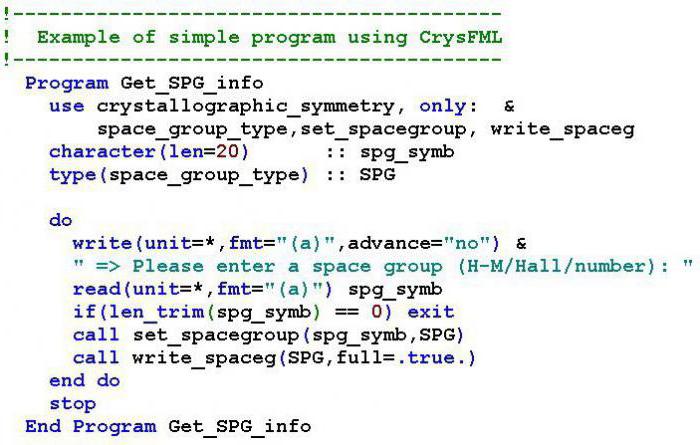
4. Создание проекта Visual C
Создавать проекты Visual C++ можно несколькими способами:
- Использовать шаблоны проектов, такие как Шаблон консольного приложения CLR (C++), помогающие быстро создавать простые проекты.
- Можно также использовать мастера приложений, помогающие в создании решений. Решение может содержать множество проектов и может быть написано на любом языке, входящем в состав Visual Studio. Среда разработки Visual Studio может обрабатывать зависимости между проектами, конфигурации отдельных проектов, развертывание проектов, и управление исходным кодом. Этот метод хорошо работает для крупномасштабных приложений.
- Можно создать простой текстовый файл и сохранить его с расширением CPP. Используя мастер приложений Win32, создайте пустой проект. Добавьте вновь созданный CPP-файл в среду разработки Visual Studio. Этот метод хорошо работает в случае очень простого консольного приложения.
Конкретными параметрами созданного проекта можно управлять при помощи мастеров кода и страниц свойств. Перед началом программирования необходимо задать проект. Проект содержит все исходные материалы для приложения, такие как файлы исходного кода, файлы ресурсов, такие как значки, ссылки на внешние файлы, на которые опирается программа, и данные конфигурации, такие как параметры компилятора. При построении проекта Visual C# вызывает компилятор C# и другие внутренние средства для создания исполняемой сборки из файлов проекта. Для создания нового проекта в меню Файл следует указать Создать и щелкнуть Проект. После выбора проекта и нажатия на кнопку ОК, Visual Studio создает проект и можно начинать написание кода. Файлы проекта, ссылки, параметры и ресурсы отображаются в Обозревателе решений справа. Проект может включать любое число дополнительных файлов с расширением CS, которые могут быть связаны с определенной формой Windows. В предыдущем примере Обозревателя решений в файле program.cs находится точка входа для приложения. Отдельный файл CS может содержать любое число определений классов и структур. Чтобы добавить в проект новые или существующие файлы или классы, в меню Проект выберите команду Добавить новый элемент или Добавить существующий элемент. 5.Подключение библиотек. Заголовочный файл. Прототипы функций. Подключение библиотек.Библиотеки предоставляют возможность использовать при разработке программы готовые фрагменты кода .В библиотеки могут быть включены подпрограммы, структуры данных, классы, макросы. Для языка C++ разработано много библиотек различного назначения. Некоторые библиотеки используются по умолчанию, их подключение к проекту осуществляется автоматически .Другие библиотеки можно использовать по требованию , для этого следует подключить директивой #include их заголовки и/или сделать соответствующие настройки проекта. Файлы, содержащие библиотеки, имеют расширение *.lib (статическая) и *.dll (динамическая). Существуют два вида использования библиотек в исполняемом файле: статическое и динамическое. При статическом подключении фрагменты библиотек встраиваются в программу, что увеличивает ее код, но делает программу автономной, так как для выполнения готовой программы не требуется наличие библиотеки на компьютере. При динамическом подключении программа обращается к библиотеке в процессе своей работы. Динамическое подключение библиотеки экономит код, но для работы программы необходимо наличие библиотеки в определенном месте на диске. Компоненты библиотеки подключаются с помощью заголовочных файлов: – одномерный массив элементов; – двусвязный список элементов; – очередь элементов; – стек элементов; – дата и время; – основные алгоритмы; – функции обработки данных (поиск, сортировка, обработка строк в стиле C, генератор случайных чисел); – строка; – стандартные потоки ввода/вывода; – комплексные числа; – общие математические функции; – работа с динамической памятью. < conio.h >консольный ввод-вывод стандартный заголовочный файл ввода/вывода набор классов, методов и функций, которые предоставляют интерфейс для чтения/записи данных из/в файл. Для манипуляции с данными файлов используются объекты, называемые потоками («stream»). Заголовочный файл или подключаемый файл — в языках программирования файл, механически «вставляемый» компилятором в исходный текст в том месте, где располагается некоторая директива #include в Си. В языках программирования Си и C++, заголовочные файлы — основной способ подключить к программе типы данных, структуры, прототипы функций, перечислимые типы, и макросы, используемые в другом модуле. Имеет по умолчанию расширение .h; иногда для заголовочных файлов языка C++ используют расширение .hpp. Заголовочный файл в общем случае может содержать любые конструкции языка программирования, но на практике исполняемый код в заголовочные файлы не помещают. Например, идентификаторы, которые должны быть объявлены более чем в одном файле, удобно описать в заголовочном файле, а затем его подключать по мере надобности. Подобным же образом работает модульность и в большинстве ассемблеров. Прототип функции В современных, правильно написанных программах на языке С каждую функцию перед использованием необходимо объявлять. Обычно это делается с помощью прототипа функции. Прототипы дают компилятору возможность тщательнее выполнять проверку типов.. Если используются прототипы, то компилятор может обнаружить любые сомнительные преобразования типов аргументов, необходимые при вызове функции, если тип ее параметров отличается от типов аргументов. При этом будут выданы предупреждения обо всех таких сомнительных преобразованиях. Компилятор также обнаружит различия в количестве аргументов, использованных при вызове функции, и в количестве параметров функции. В общем виде прототип функции должен выглядеть таким образом: тип имя_функции(тип имя_парам1, тип имя_парам2, . имя_парамN); Использование имен параметров не обязательно. Однако они дают возможность компилятору при наличии ошибки указать имена, для которых обнаружено несоответствие типов, так что не поленитесь указать этих имен — это позволит сэкономить время впоследствии. 6. 1) *h, *hpp-Заголовочные файлы библиотеки механически «вставляемый» компилятором в исходный текст *c, *cpp исходный файл 7. Структура программы на С 1. заголовок 2. включение необходимых внешних файлов 3. ваши определения для удобства работы 4. объявление глобальных переменных Перед использованием переменной в Си её необходимо объявить! Т.е. указать компилятору какой тип данных она может хранить и как она называется. Глобальные переменные объявляются, вне какой либо функции. Т.е. не после фигурной скобки <. Они доступны в любом месте программы, значит можно читать их значения и присваивать им значения там, где требуется. 5. описание функций — обработчиков прерываний 6. описание других функций используемых в программе 7. функция main — это единственный обязательный пункт ! 8. Стандартные числовые типы данных. Размер, диапазон, операции.
| ТИП ДАННЫХ | РАЗМЕР В БАЙТАХ | ТОЧНОСТЬ | ИНТЕРВАЛ ЗНАЧЕНИЙ |
| SINGLE | 4 | 7ЦИФР | ОТ 0.71Е-45 ДО 3.4Е+38 |
| REAL, float | 6 | 11 ЦИФР | ОТ 2.94Е-39 ДО 1.7Е+38 |
| DOUBLE | 8 | 15 ЦИФР | ОТ 4.94Е-324 ДО 1.79Е+308 |
| EXTENDED | 10 | 19 ЦИФР | ОТ 3.3Е-4932 ДО 1.18Е+4932 |
| COMP | 8 | ТОЛЬКО ЦЕЛЫЕ | — +9.2Е+18 |
Int 4 от -2 147 483 648 до +2 147 483 647 9. Консольный ввод-вывод Существует два вида консольного ввода и вывода :
- Printf- ввод ,scanf- вывод
- >-ввод
. conio.h — заголовочный файл для работы с консолью и он поддерживает функцию _getch(), которая извлекает символ из потока ввода. Определяет, было ли нажатие клавиш клавиатуры. Форматирование и вывод («печать») строки напрямую в и из консоль 10. Форматный ввод- вывод Форматный ввод/вывод Функции printf() и scanf() выполняют форматный ввод и вывод, то есть они могут читать и писать данные в разных форматах. Данные на консоль выводит printf(). А ее «дополнение», функция scanf(), наоборот — считывает данные с клавиатуры. Обе функции могут работать с любым встроенным типом данных, а также с символьными строками, которые завершаются символом конца строки (‘0’). #include // Подключаем заголовочный файл void main() < char* a; //Объявляем переменную а printf(«Vvedite text:n»); //Приглашение ввести текст scanf (a); //Вводим текст и присваиваем его на переменную puts(a); //Ввыводим текст с переменной а >11. Операции с числовыми данными. Приоритет операций  12. Вещественные типы данных. Представление в памяти Вещественные типы аппаратно могут иметь два представления: вещественные числа с фиксированной точкой и вещественные числа с плавающей точкой. Как правило, по умолчанию компиляторы преобразуют вещественные значения в экспоненциальный формат (формат с плавающей точкой), если синтаксис языка явно не указывает применение формата с фиксированной точкой. знаковый разряд обозначается буквой s, экспонента — e, а мантисса — m. 14. Алгоритмическая конструкция «выбор»
12. Вещественные типы данных. Представление в памяти Вещественные типы аппаратно могут иметь два представления: вещественные числа с фиксированной точкой и вещественные числа с плавающей точкой. Как правило, по умолчанию компиляторы преобразуют вещественные значения в экспоненциальный формат (формат с плавающей точкой), если синтаксис языка явно не указывает применение формата с фиксированной точкой. знаковый разряд обозначается буквой s, экспонента — e, а мантисса — m. 14. Алгоритмическая конструкция «выбор»
| Алгоритмический язык | Блок-схема |
| действие 1 действие 2 . действие n |  |
 15. Алгоритмическая конструкция «цикл»
15. Алгоритмическая конструкция «цикл»  18. Выделение динамической памяти .Операторы new , delete
18. Выделение динамической памяти .Операторы new , delete  Для этого вам необходимо знать всего два оператора:
Для этого вам необходимо знать всего два оператора:
- new — выделение памяти, если выделение памяти не произошло возвращается нулевой указатель;
- delete — освобождение памяти, не во всех компиляторах после освобождения памяти указателю присваивается 0.
#include using namespace std; int main() < // создание объекта типа int со значением 45 // и сохранение его адреса в указателе obj int* obj = new int(45); // освободили память на которую указывал obj cout19. Выделение динамической памяти. Подпрограммы malloc, calloc, free Динамическое распределение памяти — способ выделения оперативной памяти компьютера для объектов в программе, при котором выделение памяти под объект осуществляется во время выполнения программы. При динамическом распределении памяти объекты размещаются в т.н. «куче» при конструировании объекта указывается размер запрашиваемой под объект памяти, и, в случае успеха, выделенная область памяти, условно говоря, «изымается» из «кучи», становясь недоступной при последующих операциях выделения памяти. Противоположная по смыслу операция — освобождение занятой ранее под какой-либо объект памяти: освобождаемая память, также условно говоря, возвращается в «кучу» и становится доступной при дальнейших операциях выделения памяти. По мере создания в программе новых объектов, количество доступной памяти уменьшается. Отсюда вытекает необходимость постоянно освобождать ранее выделенную память. В идеальной ситуации программа должна полностью освободить всю память, которая потребовалась для работы. По аналогии с этим, каждая процедура (функция или подпрограмма) должна обеспечить освобождение всей памяти, выделенной в ходе выполнении процедуры. Некорректное распределение памяти приводит к т.н. «утечкам» памяти, когда выделенная память не освобождается. Многократные утечки памяти могут привести к исчерпанию всей оперативной памяти и нарушить работу операционной системы. Другая проблема — это проблема фрагментации памяти. Выделение памяти происходит блоками — непрерывными фрагментами оперативной памяти (таким образом, каждый блок — это несколько идущих подряд байтов). В какой-то момент, в куче попросту может не оказаться блока подходящего размера и, даже, если свободная память достаточна для размещения объекта, операция выделения памяти окончится неудачей. Для управления динамическим распределением памяти используется «сборщик мусора» — программный объект, который следит за выделением памяти и обеспечивает её своевременное освобождение. Сборщик мусора также следит за тем, чтобы свободные блоки имели максимальный размер, и, при необходимости, осуществляет дефрагментацию памяти.
Источник: studfile.net