
Не так давно мне предложили вести курс основ теории алгоритмов в одном московском лицее. Я, конечно, с удовольствием согласился. В понедельник была первая лекция на которой я постарался объяснить ребятам методы оценки сложности алгоритмов. Я думаю, что некоторым читателям Хабра эта информация тоже может оказаться полезной, или по крайней мере интересной.
Существует несколько способов измерения сложности алгоритма. Программисты обычно сосредотачивают внимание на скорости алгоритма, но не менее важны и другие показатели – требования к объёму памяти, свободному месте на диске. Использование быстрого алгоритма не приведёт к ожидаемым результатам, если для его работы понадобится больше памяти, чем есть у компьютера.
Память или время
Многие алгоритмы предлагают выбор между объёмом памяти и скоростью. Задачу можно решить быстро, использую большой объём памяти, или медленнее, занимая меньший объём.
Типичным примером в данном случае служит алгоритм поиска кратчайшего пути. Представив карту города в виде сети, можно написать алгоритм для определения кратчайшего расстояния между двумя любыми точками этой сети. Чтобы не вычислять эти расстояния всякий раз, когда они нам нужны, мы можем вывести кратчайшие расстояния между всеми точками и сохранить результаты в таблице. Когда нам понадобится узнать кратчайшее расстояние между двумя заданными точками, мы можем просто взять готовое расстояние из таблицы.
Блок-схема программы для вычисления факториала
Результат будет получен мгновенно, но это потребует огромного объёма памяти. Карта большого города может содержать десятки тысяч точек. Тогда, описанная выше таблица, должна содержать более 10 млрд. ячеек. Т.е. для того, чтобы повысить быстродействие алгоритма, необходимо использовать дополнительные 10 Гб памяти.
Из этой зависимости проистекает идея объёмно-временной сложности. При таком подходе алгоритм оценивается, как с точки зрении скорости выполнения, так и с точки зрения потреблённой памяти.
Мы будем уделять основное внимание временной сложности, но, тем не менее, обязательно будем оговаривать и объём потребляемой памяти.
Оценка порядка
При сравнении различных алгоритмов важно знать, как их сложность зависит от объёма входных данных. Допустим, при сортировке одним методом обработка тысячи чисел занимает 1 с., а обработка миллиона чисел – 10 с., при использовании другого алгоритма может потребоваться 2 с. и 5 с. соответственно. В таких условиях нельзя однозначно сказать, какой алгоритм лучше.
В общем случае сложность алгоритма можно оценить по порядку величины. Алгоритм имеет сложность O(f(n)), если при увеличении размерности входных данных N, время выполнения алгоритма возрастает с той же скоростью, что и функция f(N). Рассмотрим код, который для матрицы A[NxN] находит максимальный элемент в каждой строке.
for i:=1 to N do
begin
max:=A[i,1];
for j:=1 to N do
begin
if A[i,j]>max then
max:=A[i,j]
end;
Вычислительная сложность алгоритма
writeln(max);
end;
В этом алгоритме переменная i меняется от 1 до N. При каждом изменении i, переменная j тоже меняется от 1 до N. Во время каждой из N итераций внешнего цикла, внутренний цикл тоже выполняется N раз. Общее количество итераций внутреннего цикла равно N*N. Это определяет сложность алгоритма O(N^2).
Оценивая порядок сложности алгоритма, необходимо использовать только ту часть, которая возрастает быстрее всего. Предположим, что рабочий цикл описывается выражением N^3+N. В таком случае его сложность будет равна O(N^3). Рассмотрение быстро растущей части функции позволяет оценить поведение алгоритма при увеличении N. Например, при N=100, то разница между N^3+N=1000100 и N=1000000 равна всего лишь 100, что составляет 0,01%.
При вычислении O можно не учитывать постоянные множители в выражениях. Алгоритм с рабочим шагом 3N^3 рассматривается, как O(N^3). Это делает зависимость отношения O(N) от изменения размера задачи более очевидной.
Определение сложности
Наиболее сложными частями программы обычно является выполнение циклов и вызов процедур. В предыдущем примере весь алгоритм выполнен с помощью двух циклов.
Если одна процедура вызывает другую, то необходимо более тщательно оценить сложность последней. Если в ней выполняется определённое число инструкций (например, вывод на печать), то на оценку сложности это практически не влияет. Если же в вызываемой процедуре выполняется O(N) шагов, то функция может значительно усложнить алгоритм. Если же процедура вызывается внутри цикла, то влияние может быть намного больше.
В качестве примера рассмотрим две процедуры: Slow со сложностью O(N^3) и Fast со сложностью O(N^2).
procedure Slow;
var
i,j,k: integer;
begin
for i:=1 to N do
for j:=1 to N do
for k:=1 to N do
end;
procedure Fast;
var
i,j: integer;
begin
for i:=1 to N do
for j:=1 to N do
Slow;
end;
procedure Both;
begin
Fast;
end;
Если во внутренних циклах процедуры Fast происходит вызов процедуры Slow, то сложности процедур перемножаются. В данном случае сложность алгоритма составляет O(N^2 )*O(N^3 )=O(N^5).
Если же основная программа вызывает процедуры по очереди, то их сложности складываются: O(N^2 )+O(N^3 )=O(N^3). Следующий фрагмент имеет именно такую сложность:
procedure Slow;
var
i,j,k: integer;
begin
for i:=1 to N do
for j:=1 to N do
for k:=1 to N do
end;
procedure Fast;
var
i,j: integer;
begin
for i:=1 to N do
for j:=1 to N do
end;
procedure Both;
begin
Fast;
Slow;
end;
Сложность рекурсивных алгоритмов
Простая рекурсия
Напомним, что рекурсивными процедурами называются процедуры, которые вызывают сами себя. Их сложность определить довольно тяжело. Сложность этих алгоритмов зависит не только от сложности внутренних циклов, но и от количества итераций рекурсии. Рекурсивная процедура может выглядеть достаточно простой, но она может серьёзно усложнить программу, многократно вызывая себя.
Рассмотрим рекурсивную реализацию вычисления факториала:
function Factorial(n: Word): integer;
begin
if n > 1 then
Factorial:=n*Factorial(n-1)
else
Factorial:=1;
end;
Эта процедура выполняется N раз, таким образом, вычислительная сложность этого алгоритма равна O(N).
Многократная рекурсия
Рекурсивный алгоритм, который вызывает себя несколько раз, называется многократной рекурсией. Такие процедуры гораздо сложнее анализировать, кроме того, они могут сделать алгоритм гораздо сложнее.
Рассмотрим такую процедуру:
procedure DoubleRecursive(N: integer);
begin
if N>0 then
begin
DoubleRecursive(N-1);
DoubleRecursive(N-1);
end;
end;
Поскольку процедура вызывается дважды, можно было бы предположить, что её рабочий цикл будет равен O(2N)=O(N). Но на самом деле ситуация гораздо сложнее. Если внимательно исследовать этот алгоритм, то станет очевидно, что его сложность равна O(2^(N+1)-1)=O(2^N). Всегда надо помнить, что анализ сложности рекурсивных алгоритмов весьма нетривиальная задача.
Объёмная сложность рекурсивных алгоритмов
Для всех рекурсивных алгоритмов очень важно понятие объёмной сложности. При каждом вызове процедура запрашивает небольшой объём памяти, но этот объём может значительно увеличиваться в процессе рекурсивных вызовов. По этой причине всегда необходимо проводить хотя бы поверхностный анализ объёмной сложности рекурсивных процедур.
Средний и наихудший случай
Оценка сложности алгоритма до порядка является верхней границей сложности алгоритмов. Если программа имеет большой порядок сложности, это вовсе не означает, что алгоритм будет выполняться действительно долго. На некоторых наборах данных выполнение алгоритма занимает намного меньше времени, чем можно предположить на основе их сложности. Например, рассмотрим код, который ищет заданный элемент в векторе A.
function Locate(data: integer): integer;
var
i: integer;
fl: boolean;
begin
fl:=false; i:=1;
while (not fl) and (i <=N) do
begin
if A[i]=data then
fl:=true
else
i:=i+1;
end;
if not fl then
i:=0;
Locate:=I;
end;
Если искомый элемент находится в конце списка, то программе придётся выполнить N шагов. В таком случае сложность алгоритма составит O(N). В этом наихудшем случае время работы алгоритма будем максимальным.
С другой стороны, искомый элемент может находится в списке на первой позиции. Алгоритму придётся сделать всего один шаг. Такой случай называется наилучшим и его сложность можно оценить, как O(1).
Оба эти случая маловероятны. Нас больше всего интересует ожидаемый вариант. Если элемента списка изначально беспорядочно смешаны, то искомый элемент может оказаться в любом месте списка. В среднем потребуется сделать N/2 сравнений, чтобы найти требуемый элемент. Значит сложность этого алгоритма в среднем составляет O(N/2)=O(N).
В данном случае средняя и ожидаемая сложность совпадают, но для многих алгоритмов наихудший случай сильно отличается от ожидаемого. Например, алгоритм быстрой сортировки в наихудшем случае имеет сложность порядка O(N^2), в то время как ожидаемое поведение описывается оценкой O(N*log(N)), что много быстрее.
Общие функции оценки сложности

Сейчас мы перечислим некоторые функции, которые чаще всего используются для вычисления сложности. Функции перечислены в порядке возрастания сложности. Чем выше в этом списке находится функция, тем быстрее будет выполняться алгоритм с такой оценкой.
1. C – константа
2. log(log(N))
3. log(N)
4. N^C, 0 5. N
6. N*log(N)
7. N^C, C>1
8. C^N, C>1
9. N!
Если мы хотим оценить сложность алгоритма, уравнение сложности которого содержит несколько этих функций, то уравнение можно сократить до функции, расположенной ниже в таблице. Например, O(log(N)+N!)=O(N!).
Если алгоритм вызывается редко и для небольших объёмов данных, то приемлемой можно считать сложность O(N^2), если же алгоритм работает в реальном времени, то не всегда достаточно производительности O(N).
Обычно алгоритмы со сложностью N*log(N) работают с хорошей скоростью. Алгоритмы со сложностью N^C можно использовать только при небольших значениях C. Вычислительная сложность алгоритмов, порядок которых определяется функциями C^N и N! очень велика, поэтому такие алгоритмы могут использоваться только для обработки небольшого объёма данных.
В заключение приведём таблицу, которая показывает, как долго компьютер, осуществляющий миллион операций в секунду, будет выполнять некоторые медленные алгоритмы.
Источник: habr.com
Глубока ли кроличья нора, Часть 2: оценка сложности алгоритмов

В прошлой статье мы разбирались,что такое бенчмаркинг кода и как с его помощью оценивать производительность кода. В этой же поговорим про оценку сложности алгоритмов. А чтобы всё было наглядно, вместе попробуем оценить алгоритмы, которые используются для решения задачки на собеседовании в Google. Задач такого плана полным-полно на платформах типа LeetCode, CodeWars и других. И их ценность не в том, чтоб заучить различные алгоритмы сортировок, которые вы никогда не будете на практике писать самостоятельно, а в том, чтоб увидеть типичные проблемы, с которыми вы можете столкнуться в практических задачах при разработке.
Оценка сложности алгоритмов
- без этих знаний вы не сможете отличить суб-оптимальный код от оптимального и оптимизировать его;
- каждый средний или большой проект рано или поздно будет оперировать большим объёмом данных. Важно, чтоб ваши алгоритмы это предусматривали и не стали бомбой замедленного действия;
- если вы не понимаете концепции оценки сложности алгоритмов, вы, скорее всего, будете писать низкопроизводительный код по умолчанию.
Способы же оценки сложности существуют следующие:
O большое (O(n)) — позволяет оценить верхнюю границу сложности алгоритмов. Это отношение количества входных данных для алгоритма ко времени, за которое алгоритм сможет их обработать. Простыми словами, это максимальное время работы алгоритма при работе с большими объёмами данных.
o малое (o(n)) — позволяет оценить верхнюю границу, исключая точную оценку.
Омега (Ω(n)) — позволяет оценить нижнюю границу сложности.
Тета (Θ ()) — позволяет получить точную оценку сложности.
В большинстве IT-компаний для оценки сложности используют только большое O (BigO notation), поскольку чаще всего достаточно представлять, как быстро будет расти количество операций при увеличении входных данных в худшем случае. Остальные типы оценок используются редко.
Если представить график распространённых сложностей алгоритмов, они будут выглядеть вот так:
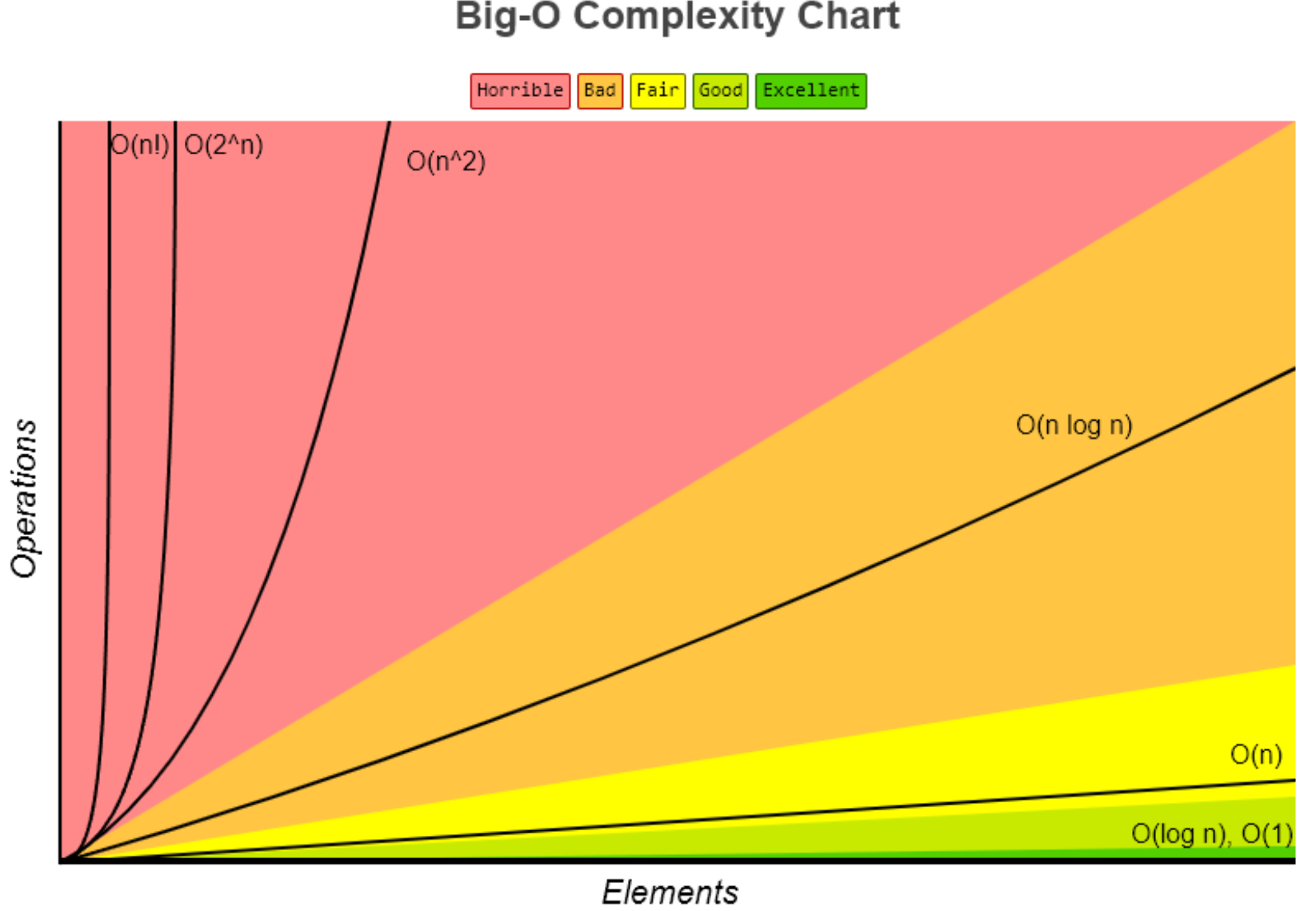
Если условно разделить сложности на зоны, то сложности вида O(log n), O(1) или O(C) можно будет отнести к зоне Excellent. Такие алгоритмы вне зависимости от объёмов данных будут выполняться очень быстро — практически мгновенно.
Алгоритмы сложности O(n) можно отнести к зоне Fair — к алгоритмам, сложность которых растёт предсказуемо и линейно. Например, если 100 элементов ваш алгоритм обрабатывает за 10 секунд, то 1000 он обработает примерно за 100 секунд. Не лучший результат, но предсказуемый.
Алгоритмы из красной зоны Horrible со сложностями O(N^2) и выше трудно отнести к высокопроизводительным. НО! Тут всё сильно зависит от объёмов входных данных. Если вы уверены, что у вас всегда будет небольшой объём данных (например, 100 элементов), и обрабатываться он будет в приемлемое для вас время, то всё в порядке, такие алгоритмы тоже можно использовать. Но если же вы не уверены в постоянности объёмов данных (может прийти и 10 000 элементов вместо 100) — лучше всё-таки задуматься над оптимизацией алгоритмов.
Оценка сложности по времени и по памяти
Оценку сложности алгоритмов следует проводить не только по времени выполнения, но и по потребляемой памяти. Например, для ускорения вычислений можно создать какую-нибудь промежуточную структуру данных типа массива или стека для ускорения алгоритма и кеширования результатов. Это приведёт к дополнительным затратам памяти, но при этом может существенно ускорить вычисления.
Однако если ваш алгоритм для выполнения будет требовать больше памяти, чем может предоставить ваш ПК, вы не получите ожидаемой производительности. А возможно код и вовсе будет выполнен некорректно.
Немного практики:правила расчета сложности
Пример 1:
Возьмём для начала простой алгоритм присвоения переменной:
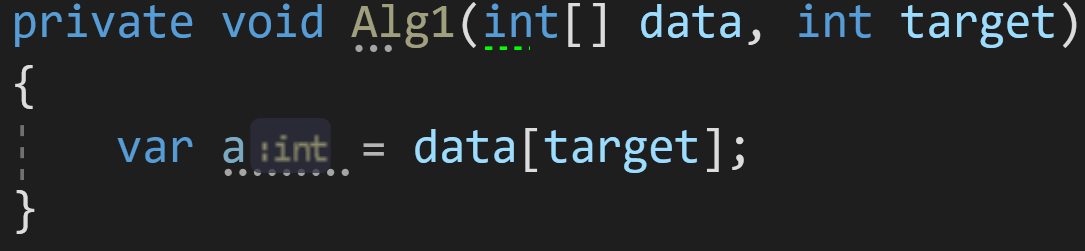
Какова его сложность по времени и по памяти?
С одной стороны, нас может ввести в заблуждение массив данных data неизвестной размерности. Но брать его в расчёт при оценке сложности внутреннего алгоритма будет некорректно.
Правило 1: внешние данные не учитываются в сложности алгоритма.
Получается, наш алгоритм состоит только из одной строчки: var a = data[target];
Доступ к элементу массива по индексу — известная операция со сложностью O(1) или O(C). Соответственно, и весь алгоритм по времени у нас займет O(1).
Дополнительная же память выделяется только под одну переменную. А значит, объём данных, которые мы будем передавать (хоть 1 000, хоть 10 000), не скажется на финальном результате. Соответственно, сложность по памяти у нас так же — O(1) или O(C).
Для упрощения записи дальше я везде буду писать O(C) вместо O(1), C в этом случае — это константа. Она может равняться 1, 2 или даже 100 — для современных компьютеров это число не принципиально, поскольку и 1, и 100 операций выполняются практически за одно и то же время.
Пример 2:
Рассмотрим второй алгоритм, очень похожий на первый:
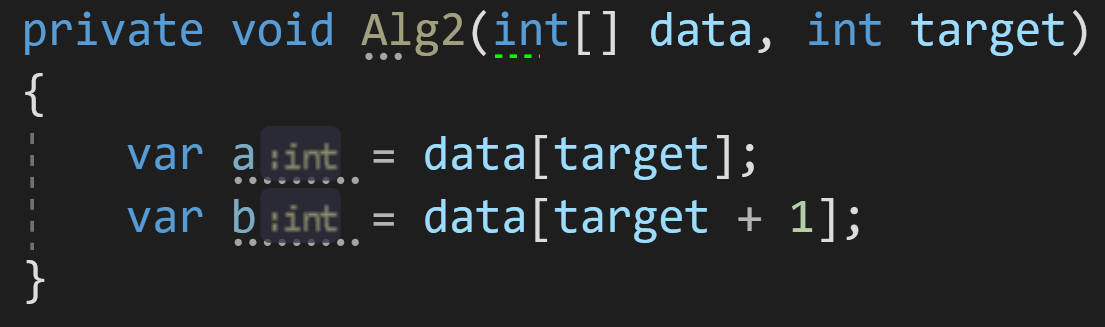
Влияет ли размерность входного массива data на количество операций в нём? Нет.
А на выделенную память? Тоже нет.
Сложность этого алгоритма по времени выполнения можно было бы оценить как O(2*C) — поскольку у нас выполняется в два раза больше операций, чем в предыдущем примере, 2 присваивания вместо 1. Но у нас и на этот счёт есть правило:
Правило 2: опускать константные множители, если они не влияют на результат кардинальным образом.
Если принять это правило в расчёт, сложность этого алгоритма будет такой же, как и в первом примере — O(C) по времени и O(C) по памяти.
Пример 3:
В третьем примере добавим в наш алгоритм цикл для обработки данных:
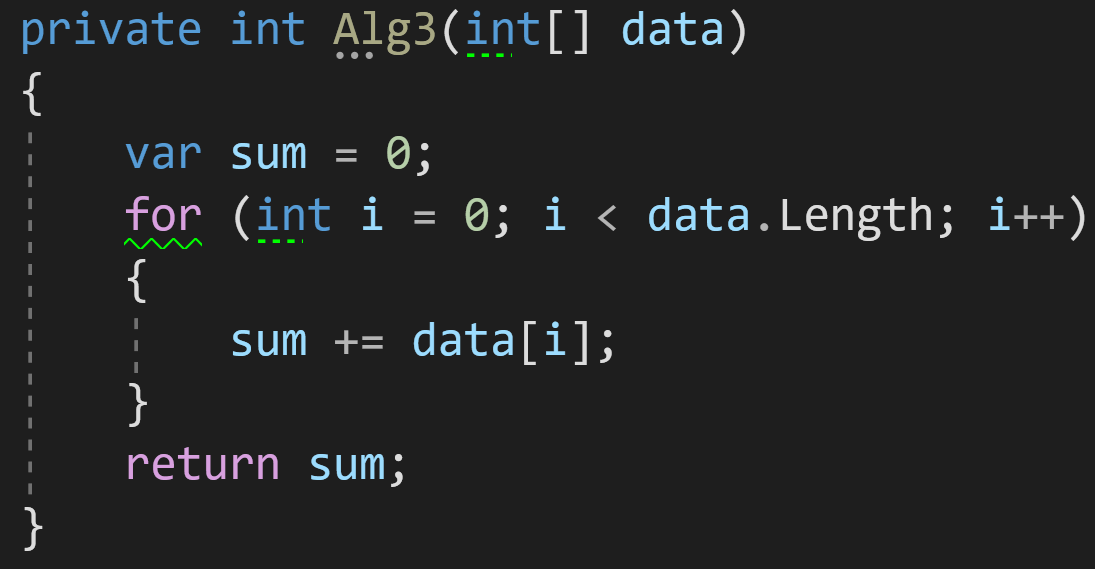
Как мы видим, количество операций, которые будет выполнять цикл, напрямую зависит от количества входных данных: больше элементов в data — больше циклов обработки потребуется для получения финального результата.
Казалось бы, если взять в учёт каждую строчку кода нашего алгоритма, то получилось бы что-то такое:
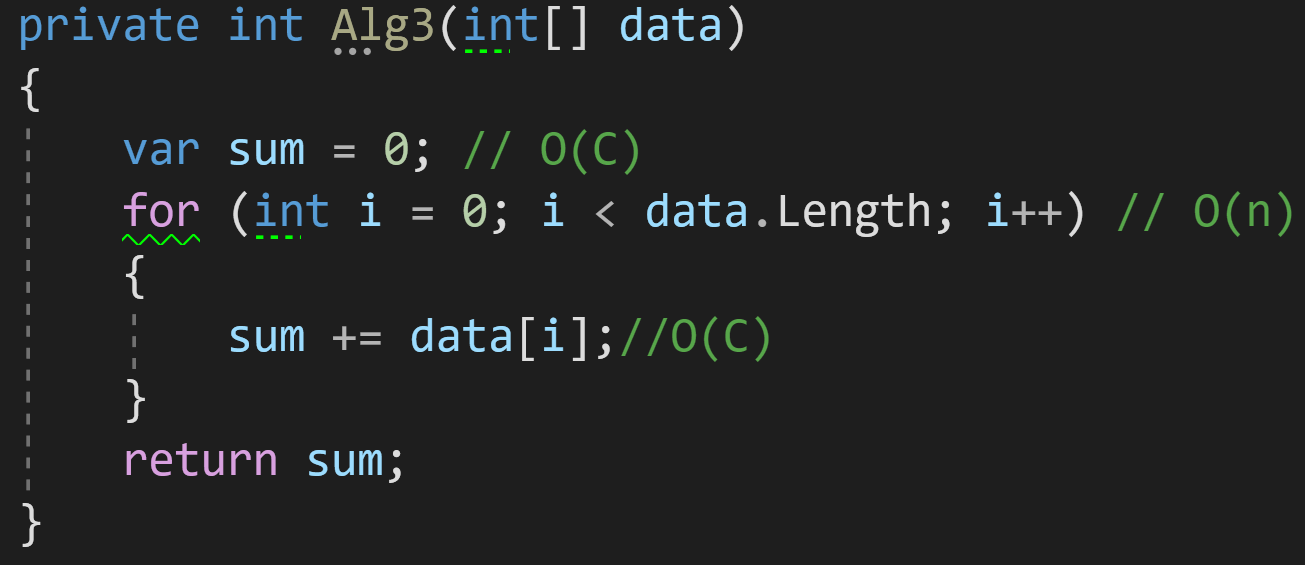
И тогда финальная сложность алгоритма получится O(C)+O(n). Но тут опять вмешивается новое правило:
Правило 3: опускать элементы оценки, которые меньше максимальной сложности алгоритма.
Поясню: если у вас O(C)+O(n), результирующая сложность будет O(n), поскольку O(n) будет расти всегда быстрее, чем O(C).
Еще один пример — O(n)+O(n^2). При такой сложности у нас N^2 всегда растёт быстрее, чем N, а значит O(n) мы отбрасываем и остаётся только O(n^2).
Итак, сложность нашего третьего примера — O(n).
Пример 4:
В четвёртом примере добавим на вход уже двумерный массив.
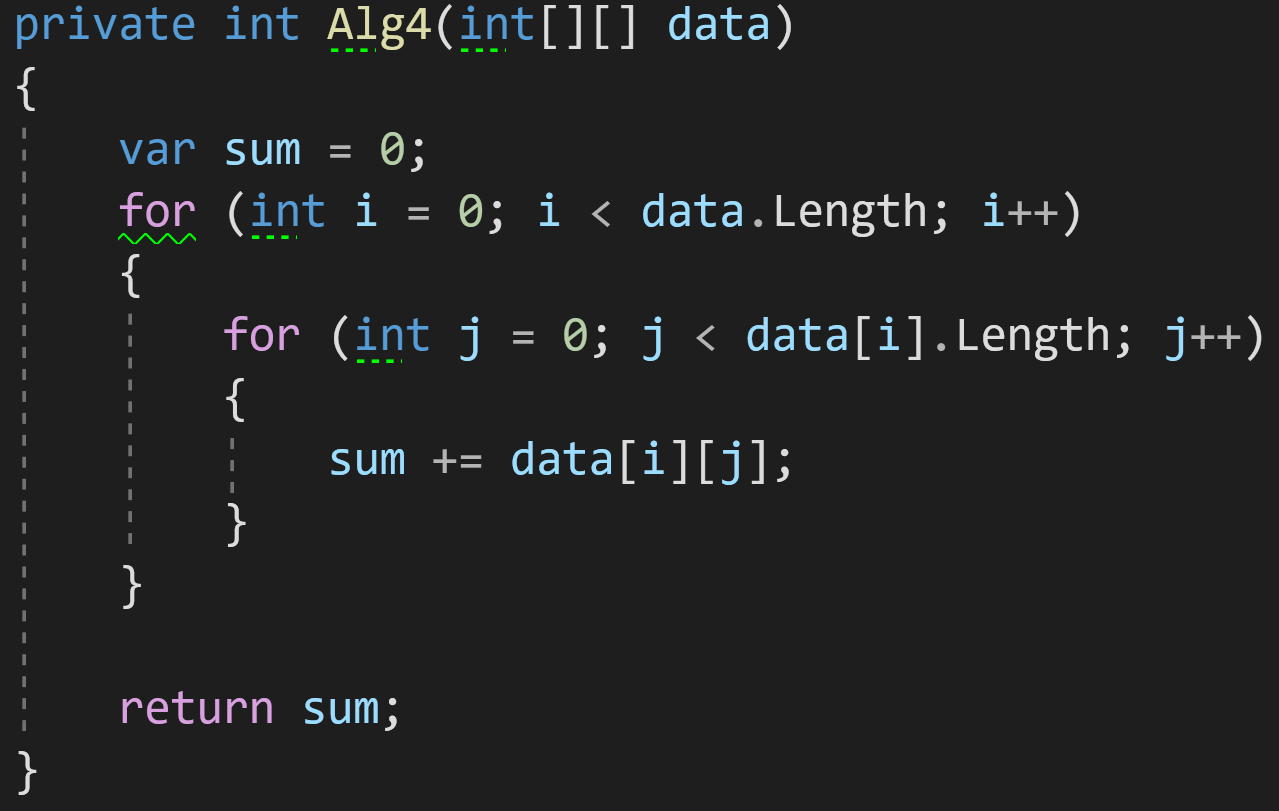
И для его обработки нам теперь нужно два цикла. Оба этих цикла будут зависеть от размерности входных данных data.
Правило 4: вложенные сложности перемножаются.
Сложность внешнего цикла в нашем примере — O(N), сложность внутреннего цикла — O(N) (или O(M), если массив не квадратный). Согласно правилу, две эти сложности должны быть умножены. В результате максимальная сложность всего алгоритма будет равна O(N^2).
Пример 5:
А что мы видим тут? Цикл — уже известная нам сложность O(n), но внутри вызывается функция Alg4() из предыдущего примера:
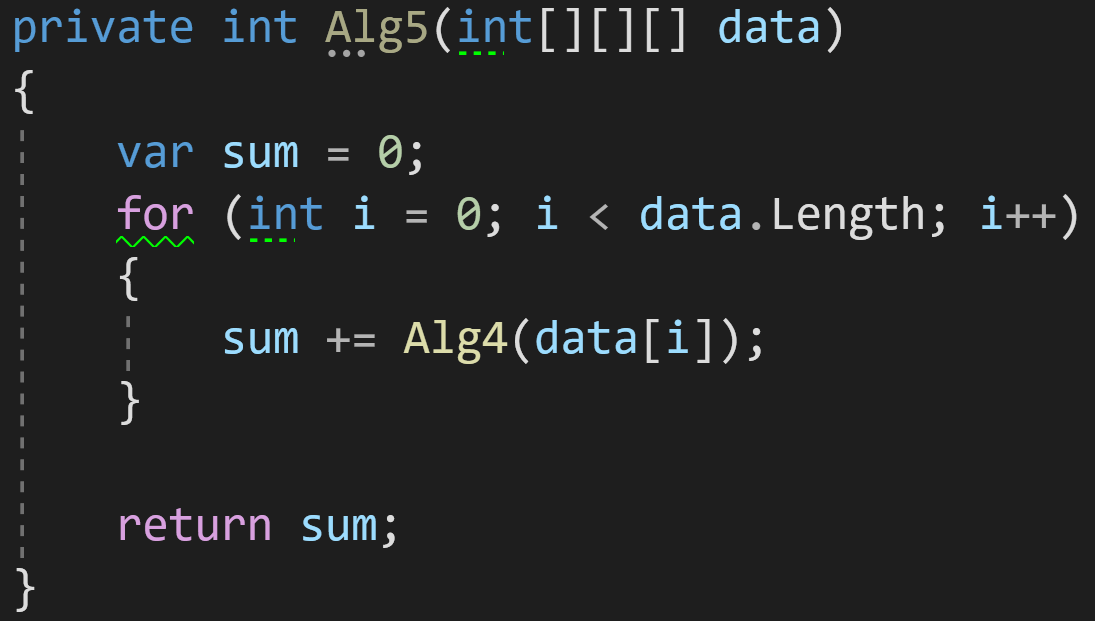
Если мы вспомним её сложность O(n^2), а также правило 4, то получим, что сложность этого алгоритма — O(n^3) при всей его визуальной минималистичности.
Правило 5: включайте в оценку общей сложности алгоритма оценки всех вложенных вызовов функций.
Именно поэтому важно понимать сложность методов синтаксического сахара вроде LINQ — чтоб была возможность оценить, как метод будет вести себя при увеличении объёмов данных. При использовании их в коде без понимания внутреннего устройства вы рискуете получить очень высокую сложность алгоритма, который будет захлебываться при увеличении входящих данных.
Приведу пример минималистичного алгоритма, который выглядит хорошо и компактно (ни в коем случае не претендует на эталонный код), но станет бомбой замедленного действия при работе с большими объёмами данных:
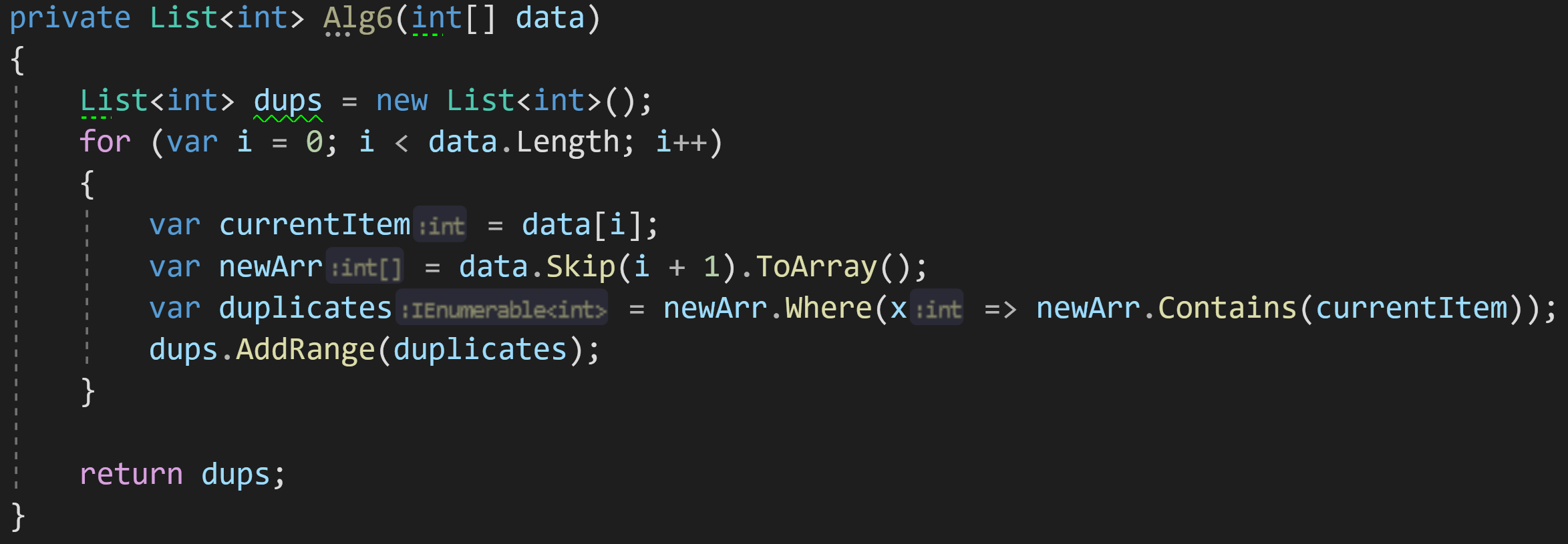
Что мы тут видим? Цикл = O(n), Where = от O(1) до O(n), в зависимости от типа хранящихся внутри данных, Contains = O(n).
Итого сложность такого алгоритма будет от O(n^2) до O(n^3) по времени выполнения.
ToArray() будет выделять на каждой итерации дополнительную память под копию массива, а значит сложность по памяти составит O(n^2).
Задачка от Google
Возьмём для нашего финального оценивания задачку, которую дают на собеседовании в Google.
Подробный разбор задачи и алгоритмы решения можно посмотреть вот в этом видео от Саши Лукина. Рекомендую посмотреть его перед тем, как продолжить читать эту статью.
Вкратце, цель алгоритма — найти в массиве два любых числа, которые в сумме дали бы нам искомое число target.
Решение 1: полный проход по массиву
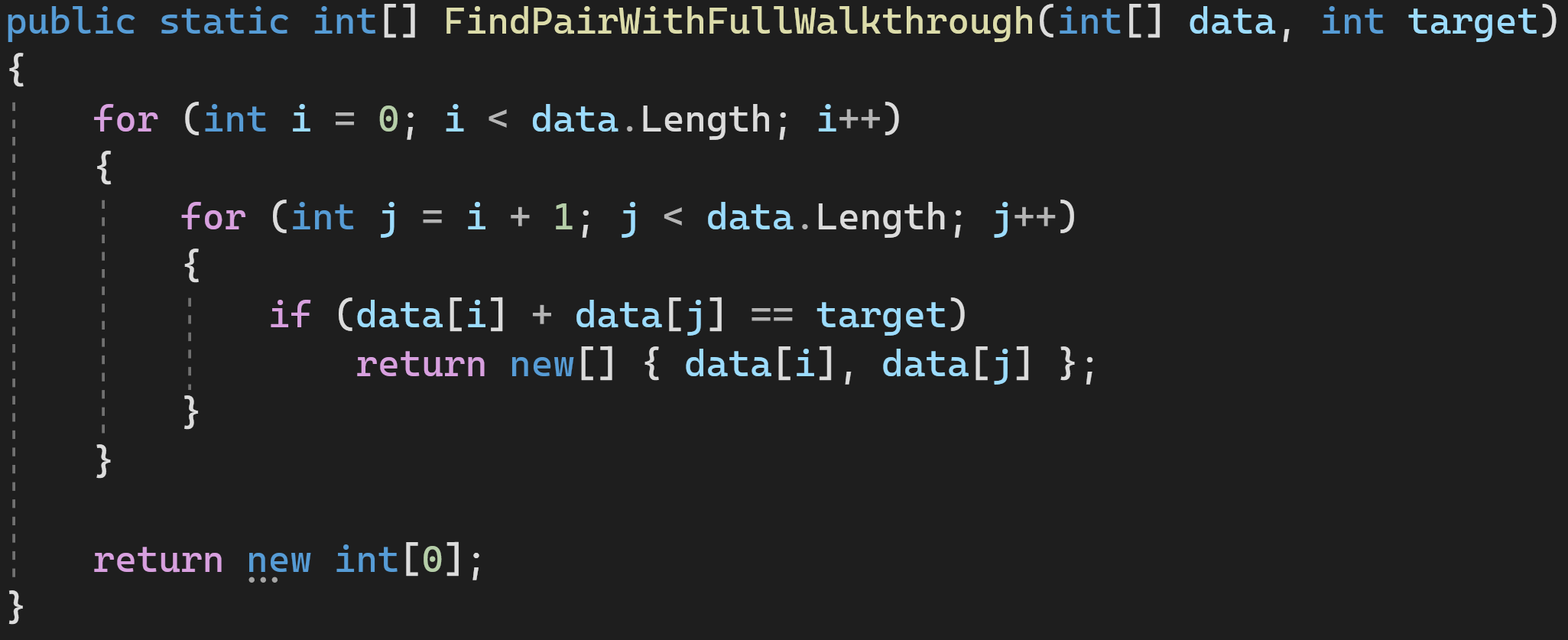
Сложность по времени: O(n^2)
Сложность по памяти: O(С)
Это решение в лоб. Не самое оптимальное, поскольку время быстро растёт при увеличении количества элементов, но зато дополнительную память мы особо не потребляем.
Решение 2: используем HashSet
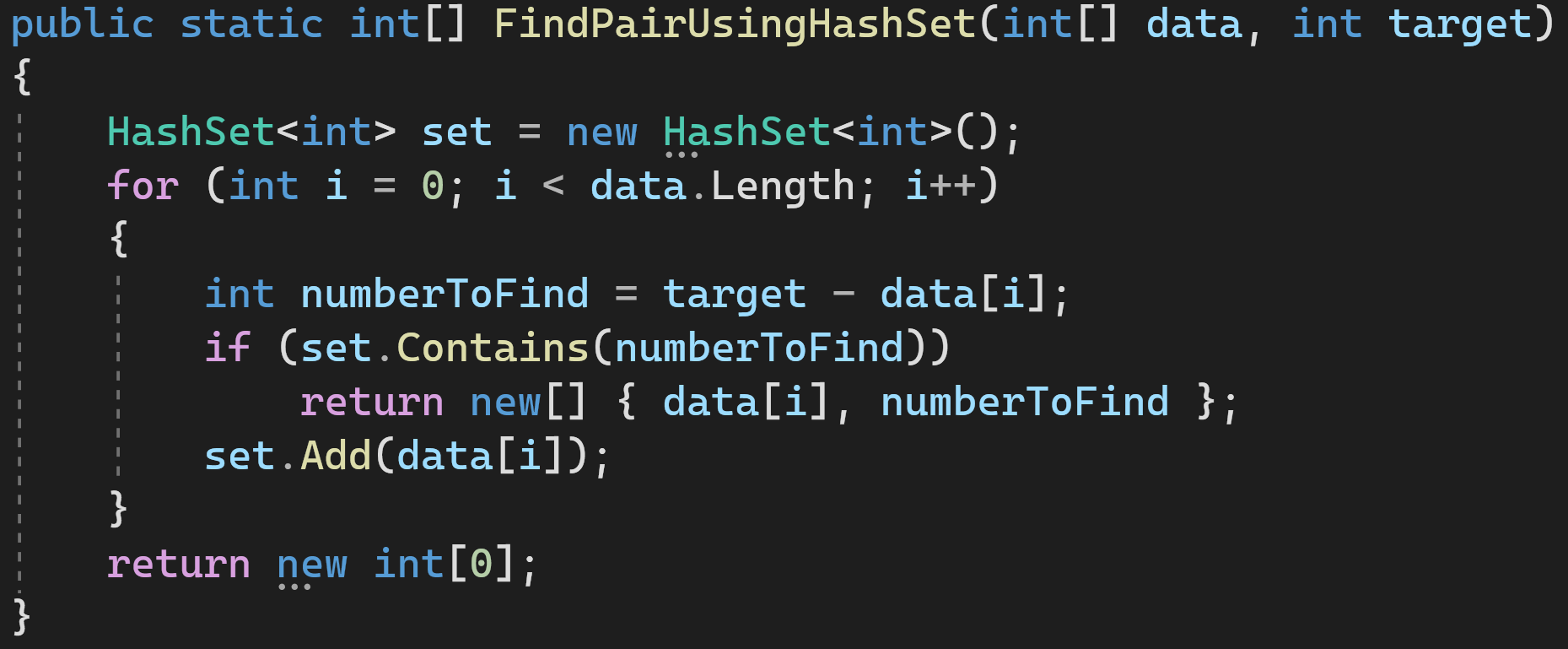
Проходимся по массиву и добавляем элементы, которые мы уже проверили, в HashSet. Если HashSet содержит недостающий для суммы элемент, значит всё хорошо, мы закончили и можем возвращать результат.
Сложность по времени: O(n)
Сложность по памяти: O(n)
Это как раз пример того, как можно выиграть в производительности, выделив дополнительную память для промежуточных структур.
Решение 3: используем бинарный поиск
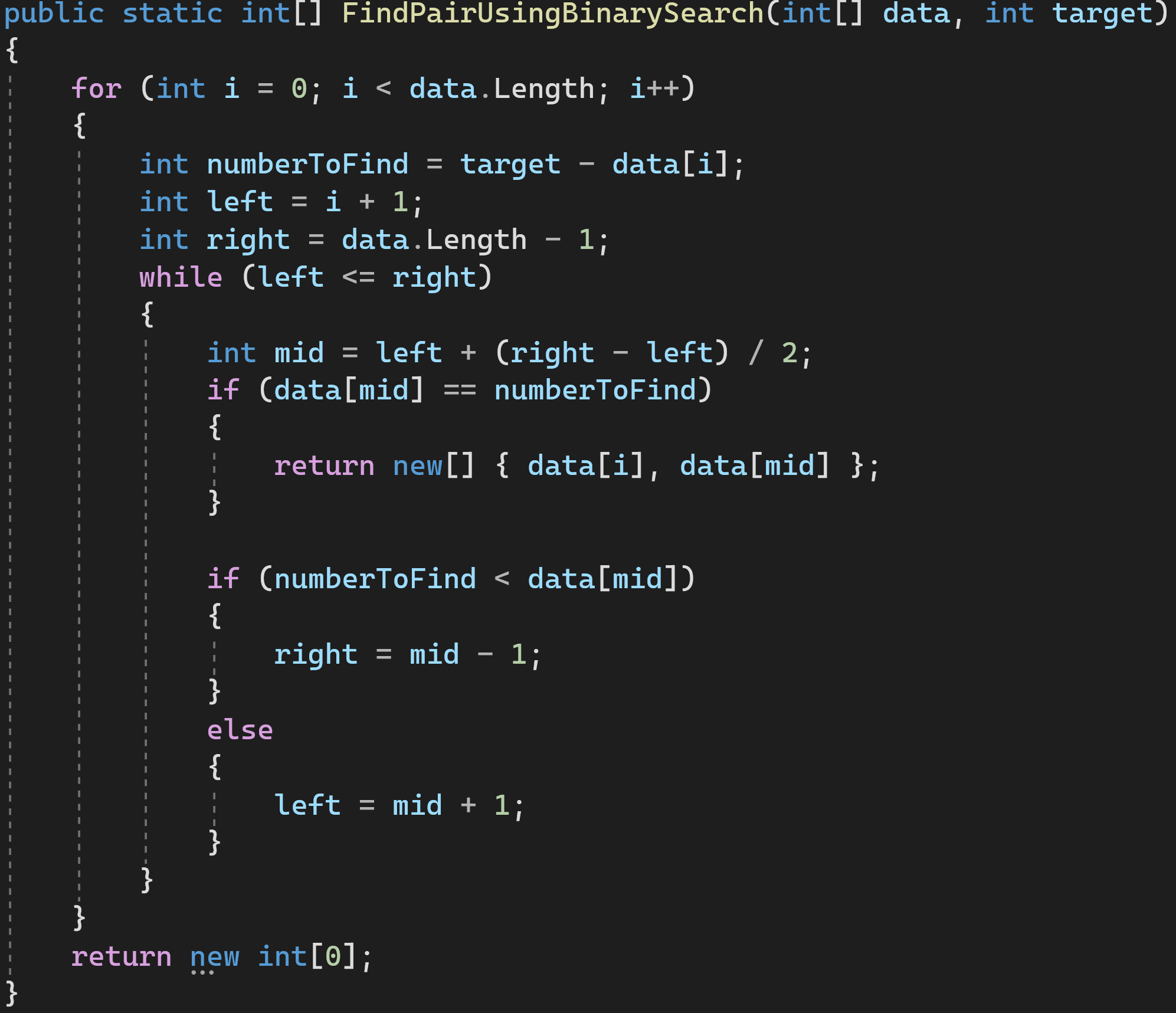
Алгоритм бинарного поиска имеет известную сложность — O(log(n)). O(n) нам добавилась от внешнего цикла for, а всё, что внутри цикла while — это и есть алгоритм бинарного поиска. Согласно Правилу 4 сложности перемножаются.
Сложность по времени: O(n*log(n))
Сложность по памяти: O(С)
Решение 4: используем метод двух указателей
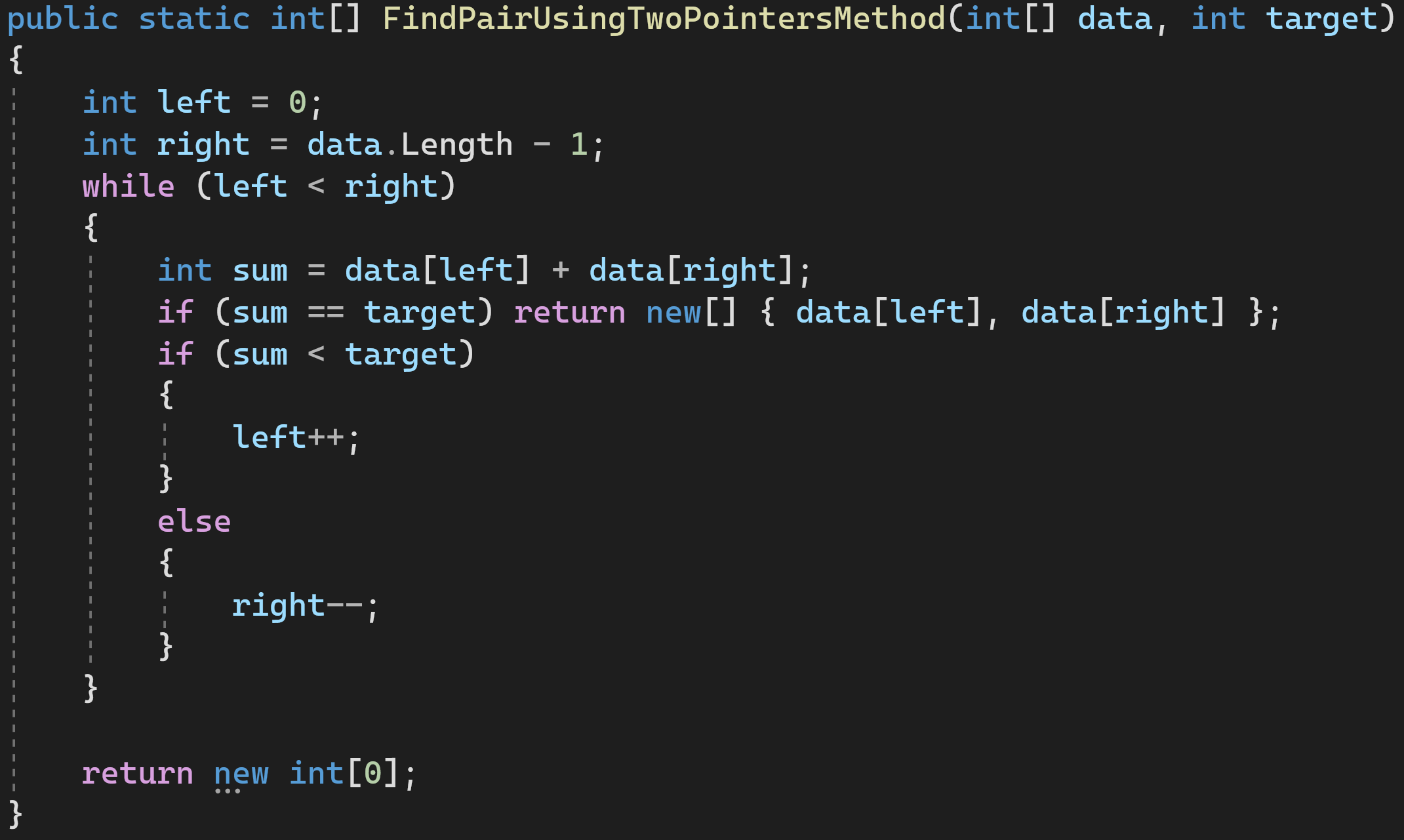
Двигаем левый и правый указатели к центру, пока они не сойдутся или не найдется пара подходящих нам значений.
Сложность по времени: O(n)
Сложность по памяти: O(С)
И это — самый оптимальный из всех вариантов решения, не использующий дополнительной памяти и совершающий наименьшее количество операций.
Бенчмаркинг решений
Теперь, зная сложности всех четырёх вариантов решения, попробуем провести бенчмаркинг этого кода и посмотреть, как алгоритмы будут вести себя на различных наборах данных.
Результаты будут следующими:

Что же мы тут видим?
За baseline решения мы берём прямой проход массиву FindPairWithFullWalkthrough. На 10 объектах он отрабатывает в среднем за 20 наносекунд и занимает второе место по производительности.
Быстрее на малом объёме данных выполняется только наш самый оптимальный вариант решения — FindPairUsingTwoPointersMethod.
Вариант же с HashSet занял в 8 раз больше времени для работы с малым объёмом данных и потребовал выделения дополнительной памяти, которую потом нужно будет собрать Garbage Collector-у.
На 1 000 же элементов вариант с полным проходом по циклу (FindPairWithFullWalkthrough) начал заметно отставать от остальных алгоритмов. Причиной этому — его сложность O(n^2), которая растёт заметно быстрее всех остальных сложностей.
На 10 000 элементах алгоритму с полным проходом потребовалось и вовсе 9,7 секунды для завершения расчетов, в то время как остальные справлялись за 0.1 секунды и меньше. А самый оптимальный вариант решения и вовсе нашёл решение за 3 миллисекунды.
Заключение
Сложность алгоритмов

Привет! Сегодняшняя лекция будет немного отличаться от остальных. Отличаться она будет тем, что имеет лишь косвенное отношение к Java.  Тем не менее, эта тема очень важна для каждого программиста. Мы поговорим об алгоритмах . Что такое алгоритм? Говоря простым языком, это некоторая последовательность действий, которые необходимо совершить для достижения нужного результата . Мы часто используем алгоритмы в повседневной жизни. Например, каждое утро перед тобой стоит задача: прийти на учебу или работу, и быть при этом:
Тем не менее, эта тема очень важна для каждого программиста. Мы поговорим об алгоритмах . Что такое алгоритм? Говоря простым языком, это некоторая последовательность действий, которые необходимо совершить для достижения нужного результата . Мы часто используем алгоритмы в повседневной жизни. Например, каждое утро перед тобой стоит задача: прийти на учебу или работу, и быть при этом:
- Одетым
- Чистым
- Сытым
Какой алгоритм позволит тебе добиться этого результата?
- Проснуться по будильнику.
- Принять душ, умыться.
- Приготовить завтрак, сварить кофе/заварить чай.
- Поесть.
- Если не погладил одежду с вечера — погладить.
- Одеться.
- Выйти из дома.
Эта последовательность действий точно позволит тебе получить необходимый результат. В программировании вся суть нашей работы заключается в постоянном решении задач. Значительную часть этих задач можно выполнить, используя уже известные алгоритмы. К примеру, перед тобой стоит задача: отсортировать список из 100 имен в массиве . Задача это довольно проста, но решить ее можно разными способами. Вот один из вариантов решения: Алгоритм сортировки имен по алфавиту:
- Купить или скачать в Интернете “Словарь русских личных имен” 1966 года издания.
- Находить каждое имя из нашего списка в этом словаре.
- Записывать на бумажку, на какой странице словаря находится имя.
- Расставить имена по порядку, используя записи на бумажке.
Позволит ли такая последовательность действий решить нашу задачу? Да, вполне позволит. Будет ли это решение эффективным ? Вряд ли. Здесь мы подошли к еще одному очень важному свойству алгоритмов — их эффективности . Решить задачу можно разными способами. Но и в программировании, и в обычной жизни мы выбираем способ, который будет наиболее эффективным. Если твоя задача — сделать бутерброд со сливочным маслом, ты, конечно, можешь начать с того, что посеешь пшеницу и подоишь корову. Но это будет неэффективное решение — оно займет очень много времени и будет стоить много денег. Для решения твоей простой задачи хлеб и масло можно просто купить. А алгоритм с пшеницей и коровой хоть и позволяет решить задачу, слишком сложный, чтобы применять его на практике. Для оценки сложности алгоритмов в программировании создали специальное обозначение под названием Big-O (“большая О”) . Big-O позволяет оценить, насколько время выполнения алгоритма зависит от переданных в него данных . Давай рассмотрим самый простой пример — передачу данных. Представь, что тебе нужно передать некоторую информацию в виде файла на большое расстояние (например, 5000 километров). Какой алгоритм будет наиболее эффективным? Это зависит от тех данных, с которыми ему предстоит работать. К примеру, у нас есть аудиофайл размером 10 мегабайт.  В этом случае, самым эффективным алгоритмом будет передать файл через Интернет. Это займет максимум пару минут! Итак, давай еще раз озвучим наш алгоритм: “Если требуется передать информацию в виде файлов на расстояние 5000 километров, нужно использовать передачу данных через Интернет”. Отлично. Теперь давай проанализируем его. Решает ли он нашу задачу? В общем-то да, вполне решает. А вот что можно сказать насчет его сложности? Хм, а вот тут уже все интереснее. Дело в том, что наш алгоритм очень сильно зависит от входящих данных, а именно — от размера файлов. Сейчас у нас 10 мегабайт, и все в порядке. А что, если нам нужно будет передать 500 мегабайт? 20 гигабайт? 500 терабайт? 30 петабайт? Перестанет ли наш алгоритм работать? Нет, все эти объемы данных все равно можно передать. Станет ли он выполняться дольше? Да, станет! Теперь нам известна важная особенность нашего алгоритма: чем больше размер данных для передачи, тем дольше времени займет выполнение алгоритма . Но нам хотелось бы более точно понимать, как выглядит эта зависимость (между размером данных и временем на их передачу). В нашем случае сложность алгоритма будет линейной . “Линейная” означает, что при увеличении объема данных время на их передачу вырастет примерно пропорционально. Если данных станет в 2 раза больше, и времени на их передачу понадобится в 2 раза больше. Если данных станет больше в 10 раз, и время передачи увеличится в 10 раз. Используя обозначение Big-O, сложность нашего алгоритма определяется как O(N) . Это обозначение лучше всего запомнить на будущее — оно всегда используется для алгоритмов с линейной сложностью. Обрати внимание: мы вообще не говорим здесь о разных “переменных” вещах: скорости интернета, мощности нашего компьютера и так далее. При оценке сложности алгоритма в этом просто нет смысла — мы в любом случае не можем это контролировать. Big-O оценивает именно сам алгоритм, независимо от “окружающей среды” в которой ему придется работать. Продолжим работать с нашим примером. Допустим, в итоге выяснилось, что размер файлов для передачи составляет 800 терабайт. Если мы будем передавать их через Интернет, задача, конечно, будет решена. Есть только одна проблема: передача по стандартному современному каналу (со скоростью 100 мегабит в секунду), который используется дома у большинства из нас, займет примерно 708 дней. Почти 2 года! :O Так, наш алгоритм тут явно не подходит. Нужно какое-то другое решение! Неожиданно на помощь к нам приходит IT-гигант — компания Amazon! Ее сервис Amazon Snowmobile позволяет загрузить большой объем данных в передвижные хранилища и доставить по нужному адресу на грузовике!
В этом случае, самым эффективным алгоритмом будет передать файл через Интернет. Это займет максимум пару минут! Итак, давай еще раз озвучим наш алгоритм: “Если требуется передать информацию в виде файлов на расстояние 5000 километров, нужно использовать передачу данных через Интернет”. Отлично. Теперь давай проанализируем его. Решает ли он нашу задачу? В общем-то да, вполне решает. А вот что можно сказать насчет его сложности? Хм, а вот тут уже все интереснее. Дело в том, что наш алгоритм очень сильно зависит от входящих данных, а именно — от размера файлов. Сейчас у нас 10 мегабайт, и все в порядке. А что, если нам нужно будет передать 500 мегабайт? 20 гигабайт? 500 терабайт? 30 петабайт? Перестанет ли наш алгоритм работать? Нет, все эти объемы данных все равно можно передать. Станет ли он выполняться дольше? Да, станет! Теперь нам известна важная особенность нашего алгоритма: чем больше размер данных для передачи, тем дольше времени займет выполнение алгоритма . Но нам хотелось бы более точно понимать, как выглядит эта зависимость (между размером данных и временем на их передачу). В нашем случае сложность алгоритма будет линейной . “Линейная” означает, что при увеличении объема данных время на их передачу вырастет примерно пропорционально. Если данных станет в 2 раза больше, и времени на их передачу понадобится в 2 раза больше. Если данных станет больше в 10 раз, и время передачи увеличится в 10 раз. Используя обозначение Big-O, сложность нашего алгоритма определяется как O(N) . Это обозначение лучше всего запомнить на будущее — оно всегда используется для алгоритмов с линейной сложностью. Обрати внимание: мы вообще не говорим здесь о разных “переменных” вещах: скорости интернета, мощности нашего компьютера и так далее. При оценке сложности алгоритма в этом просто нет смысла — мы в любом случае не можем это контролировать. Big-O оценивает именно сам алгоритм, независимо от “окружающей среды” в которой ему придется работать. Продолжим работать с нашим примером. Допустим, в итоге выяснилось, что размер файлов для передачи составляет 800 терабайт. Если мы будем передавать их через Интернет, задача, конечно, будет решена. Есть только одна проблема: передача по стандартному современному каналу (со скоростью 100 мегабит в секунду), который используется дома у большинства из нас, займет примерно 708 дней. Почти 2 года! :O Так, наш алгоритм тут явно не подходит. Нужно какое-то другое решение! Неожиданно на помощь к нам приходит IT-гигант — компания Amazon! Ее сервис Amazon Snowmobile позволяет загрузить большой объем данных в передвижные хранилища и доставить по нужному адресу на грузовике!  Итак, у нас есть новый алгоритм! “Если требуется передать информацию в виде файлов на расстояние 5000 километров и этот процесс займет больше 14 дней при передаче через Интернет, нужно использовать перевозку данных на грузовике Amazon”. Цифра 14 дней здесь выбрана случайно: допустим, это максимальный срок, который мы можем себе позволить. Давай проанализируем наш алгоритм. Что насчет скорости? Даже если грузовик поедет со скоростью всего 50 км/ч, он преодолеет 5000 километров всего за 100 часов. Это чуть больше четырех дней! Это намного лучше, чем вариант с передачей по интернету. А что со сложностью этого алгоритма? Будет ли она тоже линейной, O(N)? Нет, не будет. Ведь грузовику без разницы, как сильно ты его нагрузишь — он все равно поедет примерно с одной и той же скоростью и приедет в срок. Будет ли у нас 800 терабайт, или в 10 раз больше данных, грузовик все равно доедет до места за 5 дней. Иными словами, у алгоритма доставки данных через грузовик постоянная сложность . “Постоянная” означает, что она не зависит от передаваемых в алгоритм данных. Положи в грузовик флешку на 1Гб — он доедет за 5 дней. Положи туда диски с 800 терабайтами данных — он доедет за 5 дней. При использовании Big-O постоянная сложность обозначается как O(1) . Раз уж мы познакомились с O(N) и O(1) , давай теперь рассмотрим более “программистские” примеры 🙂 Допустим, тебе дан массив из 100 чисел, и задача — вывести в консоль каждое из них. Ты пишешь обычный цикл for , который выполняет эту задачу
Итак, у нас есть новый алгоритм! “Если требуется передать информацию в виде файлов на расстояние 5000 километров и этот процесс займет больше 14 дней при передаче через Интернет, нужно использовать перевозку данных на грузовике Amazon”. Цифра 14 дней здесь выбрана случайно: допустим, это максимальный срок, который мы можем себе позволить. Давай проанализируем наш алгоритм. Что насчет скорости? Даже если грузовик поедет со скоростью всего 50 км/ч, он преодолеет 5000 километров всего за 100 часов. Это чуть больше четырех дней! Это намного лучше, чем вариант с передачей по интернету. А что со сложностью этого алгоритма? Будет ли она тоже линейной, O(N)? Нет, не будет. Ведь грузовику без разницы, как сильно ты его нагрузишь — он все равно поедет примерно с одной и той же скоростью и приедет в срок. Будет ли у нас 800 терабайт, или в 10 раз больше данных, грузовик все равно доедет до места за 5 дней. Иными словами, у алгоритма доставки данных через грузовик постоянная сложность . “Постоянная” означает, что она не зависит от передаваемых в алгоритм данных. Положи в грузовик флешку на 1Гб — он доедет за 5 дней. Положи туда диски с 800 терабайтами данных — он доедет за 5 дней. При использовании Big-O постоянная сложность обозначается как O(1) . Раз уж мы познакомились с O(N) и O(1) , давай теперь рассмотрим более “программистские” примеры 🙂 Допустим, тебе дан массив из 100 чисел, и задача — вывести в консоль каждое из них. Ты пишешь обычный цикл for , который выполняет эту задачу
int[] numbers = new int[100]; // ..заполняем массив числами for (int i: numbers)
Какая сложность у написанного алгоритма? Линейная, O(N). Число действий, которые должна совершить программа, зависит от того, сколько именно чисел в нее передали. Если в массиве будет 100 чисел, действий (выводов на экран) будет 100.
Если чисел в массиве будет 10000, нужно будет совершить 10000 действий. Можно ли улучшить наш алгоритм? Нет. Нам в любом случае придется совершить N проходов по массиву и выполнить N выводов в консоль. Рассмотрим другой пример.
public static void main(String[] args) < LinkedListnumbers = new LinkedList<>(); numbers.add(0, 20202); numbers.add(0, 123); numbers.add(0, 8283); >
У нас есть пустой LinkedList , в который мы вставляем несколько чисел. Нам нужно оценить сложность алгоритма вставки одного числа в LinkedList в нашем примере, и как она зависит от числа элементов, находящихся в списке. Ответом будет O(1) — постоянная сложность . Почему?
Обрати внимание: каждый раз мы вставляем число в начало списка. К тому же, как ты помнишь, при вставке числа в LinkedList элементы никуда не сдвигаются — происходит переопределение ссылок (если вдруг забыл, как работает LinkedList, загляни в одну из наших старых лекций). Если сейчас первое число в нашем списке — число х , а мы вставляем в начало списка число y, все, что для этого нужно:
x.previous = y; y.previous = null; y.next = x;

Для этого переопределения ссылок нам неважно, сколько чисел сейчас в LinkedList — хоть одно, хоть миллиард. Сложность алгоритма будет постоянной — O(1).
Логарифмическая сложность
Без паники! 🙂 Если при слове “логарифмический” тебе захотелось закрыть лекцию и не читать дальше — подожди пару минут. Никаких математических сложностей здесь не будет (таких объяснений полно и в других местах), а все примеры разберем “на пальцах”. Представь, что твоя задача — найти одно конкретное число в массиве из 100 чисел. Точнее, проверить, есть ли оно там вообще.
Как только нужное число найдено, поиск нужно прекратить, а в консоль вывести запись “Нужное число обнаружено! Его индекс в массиве = . ” Как бы ты решил такую задачу? Здесь решение очевидно: нужно перебрать элементы массива по очереди начиная с первого (или с последнего) и проверять, совпадает ли текущее число с искомым.
Соответственно, количество действий прямо зависит от числа элементов в массиве. Если у нас 100 чисел, значит, нам нужно 100 раз перейти к следующему элементу и 100 раз проверить число на совпадение. Если чисел будет 1000, значит и шагов-проверок будет 1000.
Это очевидно линейная сложность, O(N) . А теперь мы добавим в наш пример одно уточнение: массив, в котором тебе нужно найти число, отсортирован по возрастанию . Меняет ли это что-то для нашей задачи? Мы по-прежнему можем искать нужное число перебором.
Но вместо этого мы можем использовать известный алгоритм двоичного поиска .  В верхнем ряду на изображении мы видим отсортированный массив. В нем нам необходимо найти число 23. Вместо того, чтобы перебирать числа, мы просто делим массив на 2 части и проверяем среднее число в массиве.
В верхнем ряду на изображении мы видим отсортированный массив. В нем нам необходимо найти число 23. Вместо того, чтобы перебирать числа, мы просто делим массив на 2 части и проверяем среднее число в массиве.
Находим число, которое располагается в ячейке 4 и проверяем его (второй ряд на картинке). Это число равно 16, а мы ищем 23. Текущее число меньше. Что это означает? Что все предыдущие числа (которые расположены до числа 16) можно не проверять : они точно будут меньше того, которое мы ищем, ведь наш массив отсортирован!
Продолжим поиск среди оставшихся 5 элементов. Обрати внимание: мы сделали всего одну проверку, но уже отмели половину возможных вариантов. У нас осталось всего 5 элементов. Мы повторим наш шаг — снова разделим оставшийся массив на 2 и снова возьмем средний элемент (строка 3 на рисунке). Это число 56, и оно больше того, которое мы ищем. Что это означает?
Что мы отметаем еще 3 варианта — само число 56, и два числа после него (они точно больше 23, ведь массив отсортирован). У нас осталось всего 2 числа для проверки (последний ряд на рисунке) — числа с индексами массива 5 и 6. Проверяем первое из них, и это то что мы искали — число 23!
Его индекс = 5! Давай рассмотрим результаты работы нашего алгоритма, а потом разберемся с его сложностью. (Кстати, теперь ты понимаешь, почему его называют двоичным: его суть заключается в постоянном делении данных на 2). Результат впечатляет!
Если бы мы искали нужное число линейным поиском, нам понадобилось бы 10 проверок, а с двоичным поиском мы уложились в 3! В худшем случае их было бы 4, если бы на последнем шаге нужным нам числом оказалось второе, а не первое. А что с его сложностью?
Это очень интересный момент 🙂 Алгоритм двоичного поиска гораздо меньше зависит от числа элементов в массиве, чем алгоритм линейного поиска (то есть, простого перебора). При 10 элементах в массиве линейному поиску понадобится максимум 10 проверок, а двоичному — максимум 4 проверки. Разница в 2,5 раза.
Но для массива в 1000 элементов линейному поиску понадобится 1000 проверок, а двоичному — всего 10 ! Разница уже в 100 раз! Обрати внимание: число элементов в массиве увеличилось в 100 раз (с 10 до 1000), а количество необходимых проверок для двоичного поиска увеличилось всего в 2,5 раза — с 4 до 10.
Если мы дойдем до 10000 элементов , разница будет еще более впечатляющей: 10000 проверок для линейного поиска, и всего 14 проверок для двоичного. И снова: число элементов увеличилось в 1000 раз (с 10 до 10000), а число проверок увеличилось всего в 3,5 раза (с 4 до 14). Сложность алгоритма двоичного поиска логарифмическая , или,если использовать обозначения Big-O, — O(log n) . Почему она так называется?
Логарифм — это такая штуковина, обратная возведению в степень. Двоичный логарифм использует для подсчета степени числа 2. Вот, например, у нас есть 10000 элементов, которые нам надо перебрать двоичным поиском.
 Сейчас у тебя есть картинка перед глазами, и ты знаешь что для этого нужно максимум 14 проверок. Но что если картинки перед глазами не будет, а тебе нужно посчитать точное число необходимых проверок?
Сейчас у тебя есть картинка перед глазами, и ты знаешь что для этого нужно максимум 14 проверок. Но что если картинки перед глазами не будет, а тебе нужно посчитать точное число необходимых проверок?
Достаточно ответить на простой вопрос: в какую степень надо возвести число 2, чтобы полученный результат был >= числу проверяемых элементов? Для 10000 это будет 14 степень. 2 в 13 степени — это слишком мало (8192) А вот 2 в 14 степени = 16384 , это число удовлетворяет нашему условию (оно >= числу элементов в массиве). Мы нашли логарифм — 14.
Столько проверок нам и нужно! 🙂 Алгоритмы и их сложность — тема слишком обширная, чтобы вместить ее в одну лекцию. Но знать ее очень важно: на многих собеседованиях ты получишь алгоритмические задачи. Для теории я могу порекомендовать тебе несколько книг. Начать можно с “Грокаем алгоритмы”: хотя примеры в книге написаны на Python, язык книги и примеры очень просты.
Лучший вариант для новичка, к тому же она небольшая по объему. Из чтения посерьезней — книги Роберта Лафоре и Роберта Седжвика. Обе написаны на Java, что сделает изучение для тебя немного попроще. Ведь ты неплохо знаком с этим языком! 🙂 Для учеников с хорошей математической подготовкой лучшим вариантом будет книга Томаса Кормена.
Но одной теорией сыт не будешь! “Знать” != “уметь” Практиковать решения задач на алгоритмы можно на HackerRank и Leetcode. Задачки оттуда частенько используют даже на собеседованиях в Google и Facebook, так что скучно тебе точно не будет 🙂 Для закрепления материала лекции, советую посмотреть отличное видео про Big-O на YouTube. Увидимся на следующих лекциях! 🙂
Источник: javarush.com