Data Scientist работает с огромным объемом данных, который необходимо проанализировать и обработать. Одним из подходов к анализу данных является их визуализация с использованием графического представления.
7196 просмотров
Сегодня существует множество библиотек для визуализации данных в Python. Одной из самых популярных является Matplotlib, однако этот инструмент создавался задолго до бурного развития Data Science, и в большей мере ориентирован на отображение массивов NumPy и параметрических функций SciPy. В то же время в Data Science распространен обобщенный тип объектов – датасеты, крупные таблицы с разнородными данными. Для визуализации подобных данных разрабатываются новые библиотеки визуализации, например, Plotly.
Далее предложим вашему вниманию сравнительный анализ библиотек Matplotlib и Plotly.
Сравнение проведем на данных, полученных при решении задачи оптимизации электронно-лучевого процесса. Подробней задача описана в отчете о научно-исследовательской работе «математическое и алгоритмическое обеспечение процесса электронно-лучевой сварки тонкостенных конструкций аэрокосмического назначения». Результаты работы модели сильно зависят от начальных параметров, которые варьируются в широком диапазоне, поэтому для экспресс-анализа полученных данных целесообразно использовать графическое представление переменных и целевой функции.
Визуализация Данных на Python | Pandas и Matplotlib
Программная реализация описанной задачи разбита на два модуля:
- module_1 содержит функции T_1, T_2, ψ (описание функций приведено ниже);
- module_2 выполняет расчет распределения температур (T_1 + T_2) по заданным параметрам с последующим графическим выводом в отдельном окне с возможностью сохранения графика в файл.
Для визуализации математического моделирования тепловых процессов необходимо установить библиотеки Plotly и Matplotlib. Plotly не входит ни в Anaconda, ни в стандартный пакет, поэтому устанавливаем через командную строку:
pip install plotly
Устанавливаем Matplotlib в Jupyter notebook с помощью кода:
!pip install matplotlib
Также для работы понадобятся библиотеки NumPy, SciPy, Pandas, Math и Csv для работы с сырыми данными:
import plotly import plotly.graph_objs as go import plotly.express as px from plotly.subplots import make_subplots import numpy as np import pandas as pd import os,sys,inspect import random import math import scipy.integrate import matplotlib.pyplot as plt import math import scipy.integrate import csv import svs
Ниже представлена функция для импортирования настроек из конфигурационного csv файла, принимает 1 аргумент — число — номер модуля, сам csv файл размещен в репозитории.
def import_csv_cofigs(module_num): try: # Начальная температура изделия T_n = 0 # Время t_ = 0 # Мощность q_ = 0 # Теплоемкость материала cp_ = 0 # Коэффициент температуропроводности alpha_ = 0 # Скорость сварки v_ = 0 # Коэффициент теплопроводности lambda_ = 0 # Толщина delta_ = 0 mainDialect = csv.Dialect mainDialect.doublequote = True mainDialect.quoting = csv.QUOTE_ALL mainDialect.delimiter = ‘;’ mainDialect.lineterminator = ‘n’ mainDialect.quotechar = ‘»‘ module_dir = ‘/’.join(sys.path[0].split(‘\’)) with open(f’/module_/module__input.csv’, ‘r’, encoding=’utf8′) as fr: file_reader = csv.reader(fr, dialect=mainDialect) for cnf_row in file_reader: if cnf_row[0] == ‘1’: T_n = float(cnf_row[2]) if cnf_row[0] == ‘2’: t_ = float(cnf_row[2]) if cnf_row[0] == ‘3’: q_ = float(cnf_row[2]) if cnf_row[0] == ‘4’: cp_ = float(cnf_row[2]) if cnf_row[0] == ‘5’: alpha_ = float(cnf_row[2]) if cnf_row[0] == ‘6’: v_ = float(cnf_row[2]) if cnf_row[0] == ‘7’: lambda_ = float(cnf_row[2]) if cnf_row[0] == ‘8’: delta_ = float(cnf_row[2]) return (T_n, t_, q_, cp_, alpha_, v_, lambda_, delta_) except Exception as e: print(‘[ERROR] Config import error!: ‘, e)
Основы Matplotlib. Визуализация данных. Графики и диаграммы в Python
Ниже представлено описание и код этих двух модулей, начнем с module_1:
import sys # Формула для состояния температурного поля при воздействии быстро движущегося точечного источника def T_1(T_n, V_, t_, q_, cp_, a_, v_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки R_ — длина радиус-вектора «»» R_ = math.sqrt(V_.x_**2 + V_.y_**2 + V_.z_**2) # Функция — подинтегральное выражение def f_(t_1): tau_ = t_1 return math.exp((-v_**2 * tau_)/(4*a_) — (R_**2)/(4*a_*tau_))*(1/(tau_**(3/2))) i_ = scipy.integrate.quad(f_, 0, t_, limit=1) return T_n + ((2*q_)/(cp_*math.sqrt((4*math.pi*a_)**3))) * math.exp((-v_*V_.x_)/(2*a_)) * i_[0] # Формула для состояния температурного поля при воздействии быстро движущегося линейного источника def T_2(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки lambda_ — коэффициент теплопроводности delta_ — толщина «»» # Функция — подинтегральное выражение def f_(t_1): tau_ = t_1 return math.exp( (-v_**2 * tau_)/(4*a_) — (2*lambda_*tau_)/(cp_*delta_) — (V_.x_**2+V_.y_**2)/(4*a_*tau_) ) * (1/tau_) i_ = scipy.integrate.quad(f_, 0, t_, limit=1) return T_n + ((q_)/(4*math.pi*lambda_*delta_)) * math.exp((-v_*V_.x_)/(2*a_)) * i_[0] # Функция ψ(x, y, z, v, t, q) def PSI_xyzvtq(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки lambda_ — коэффициент теплопроводности delta_ — толщина T_t — температура в стадии теплонасыщения «»» T_1_result = T_1(T_n, V_, t_, q_, cp_, a_, v_) T_2_result = T_2(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_) T_t = (T_1_result + T_2_result) * 0.9 return (T_t — T_n)/(T_1_result+T_2_result-T_n)
Дальше рассмотрим module_2:
from module_1.module_1 import T_1, T_2, PSI_xyzvtq, V_xyz, import_csv_cofigs work_configs = import_csv_cofigs(2) # Начальная температура изделия T_n = work_configs[0] # Время t_ = work_configs[1] # Мощность q_ = work_configs[2] # Теплоемкость материала cp_ = work_configs[3] # Коэффициент температуропроводности alpha_ = work_configs[4] # Скорость сварки v_ = work_configs[5] # Коэффициент теплопроводности lambda_ = work_configs[6] # Толщина delta_ = work_configs[7] def main(): show_matrix = [[], [], []] for i in range(-50,100,5): for j in range(-50,100,5): V_ = V_xyz(i/100,j/100,0) tmp_ = T_2(T_n, V_, t_, q_, cp_, alpha_, v_, lambda_, delta_) + T_1(T_n, V_, t_, q_, cp_, alpha_, v_) show_matrix[0].append(V_.x_) show_matrix[1].append(V_.y_) show_matrix[2].append(tmp_) if __name__ == «__main__»: main()
Создание графика
Начнем с отображающего эти столбцы графика. Настроим Jupyter с помощью волшебной команды %matplotlib :
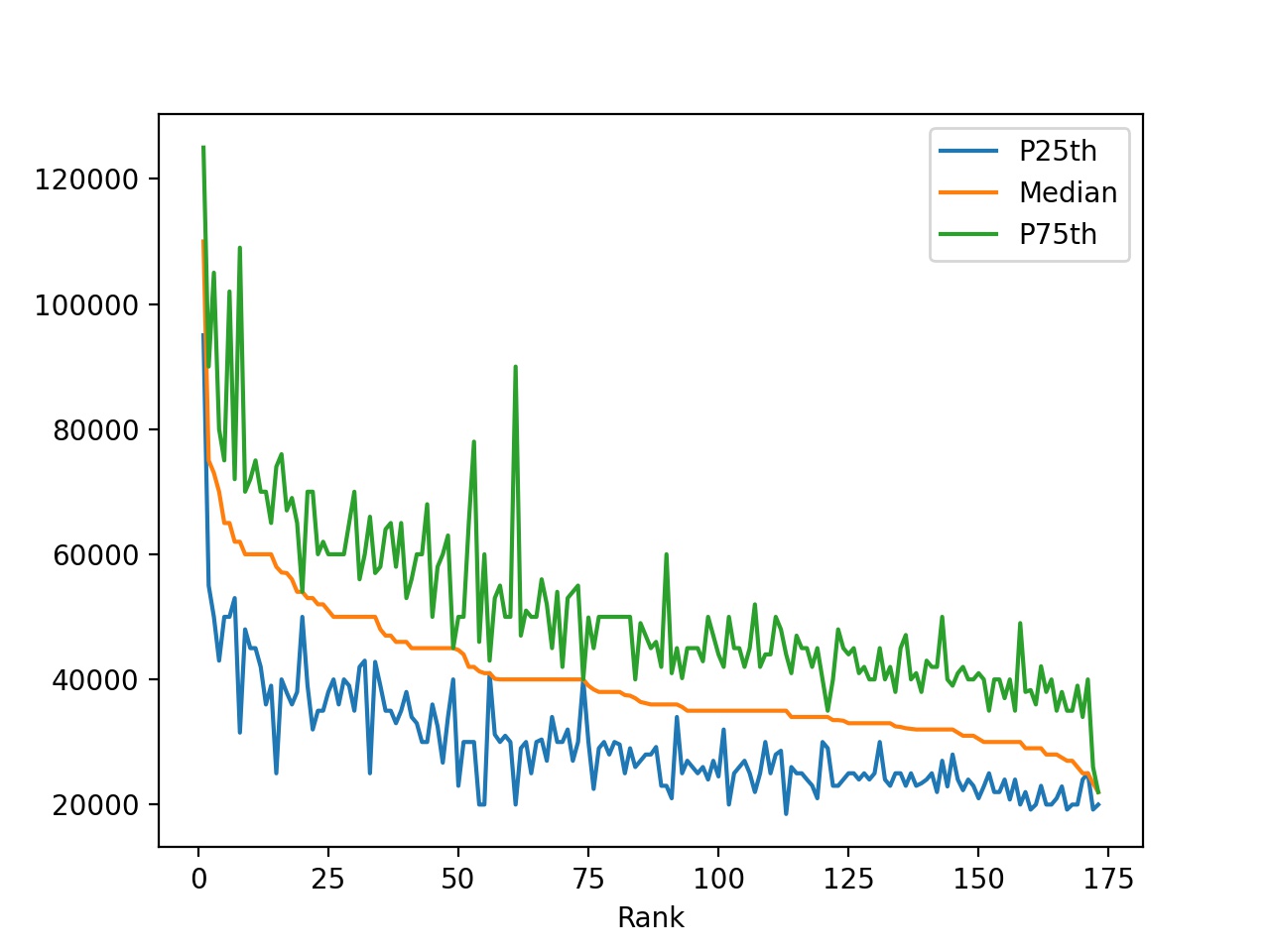
Глядя на график, можно сделать следующие наблюдения:
- Средний доход уменьшается с уменьшением рейтинга. Это ожидаемо, потому что он определяется медианным доходом.
- Некоторые специальности имеют большие промежутки между 25-м и 75-м процентилями. Люди с такими степенями могут зарабатывать значительно меньше или значительно больше, чем средний доход.
- Другие специальности имеют очень небольшие промежутки между 25-м и 75-м процентилями. Люди с такими степенями получают зарплату, очень близкую к среднему доходу.
Некоторые специальности имеют широкий диапазон заработка, а другие – довольно узкий. Чтобы обнаружить и визуализировать эти различия, будем использовать другие типы графиков.
.plot() имеет несколько необязательных параметров, определяющих, какой тип графика создается:
- «area» – графики области;
- «bar» – вертикальные графики;
- «barh» – горизонтальные графики;
- «box» – квадратный график;
- «hexbin» – hexbin участки;
- «hist» – гистограммы;
- «kde» – оценка плотности ядра;
- «density» – псевдоним для «kde»;
- «line» – линейные графики;
- «pie» – круговые диаграммы;
- «scatter» – точечные диаграммы.
Значение по умолчанию – «line». Линейные графики обеспечивают хороший обзор ваших данных. Если не задать параметр для функции .plot(), она создаст линейный график с индексом по оси X и всеми числовыми столбцами по оси Y. Хотя это полезное значение по умолчанию для наборов данных с несколькими столбцами, для нашего датасета и его нескольких числовых столбцов оно выглядит небрежно.
В качестве альтернативы передаче строк параметру kind функции .plot(), объекты DataFrame имеют несколько методов, которые можно использовать для создания различных типов графиков:
По возможности попробуйте эти методы в действии.
Теперь, когда мы создали график, рассмотрим подробнее работу функции .plot().
Что под капотом: Matplotlib
Когда вы вызываете функцию .plot() для объекта DataFrame, Matplotlib создает график.
Чтобы убедиться в этом, воспользуемся двумя фрагментами кода. Создайте график с помощью Matplotlib, используя два столбца DataFrame:
Вы можете создать такой же график, используя метод DataFrame:
Вы можете использовать как pyplot.plot(), так и df.plot() для создания одного и того же графика. Однако если у вас уже есть экземпляр DataFrame, то df.plot() предлагает более чистый синтаксис.
Теперь приступим к изучению различных типов графиков и способов их создания.
Изучение данных
Следующие графики дадут общий обзор конкретного столбца набора данных. Вы рассмотрите распределение свойств на гистограмме и познакомитесь с инструментами для изучения исключений.
Распределения и гистограммы
DataFrame – не единственный класс в pandas с методом .plot(). Объект Series предоставляет аналогичную функциональность. Вы можете получить каждый столбец DataFrame как объект Series. Вот пример использования столбца «Median»:
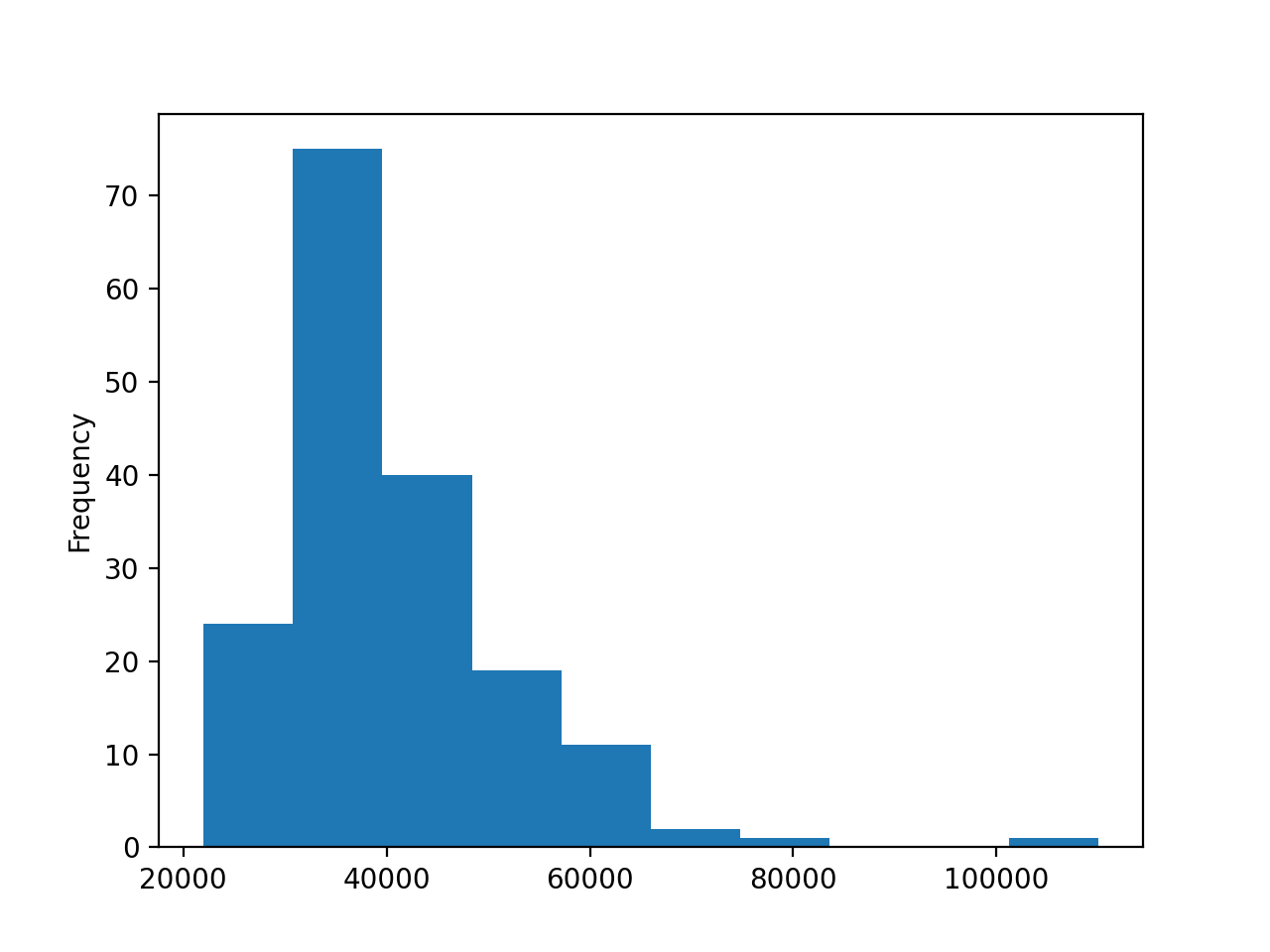
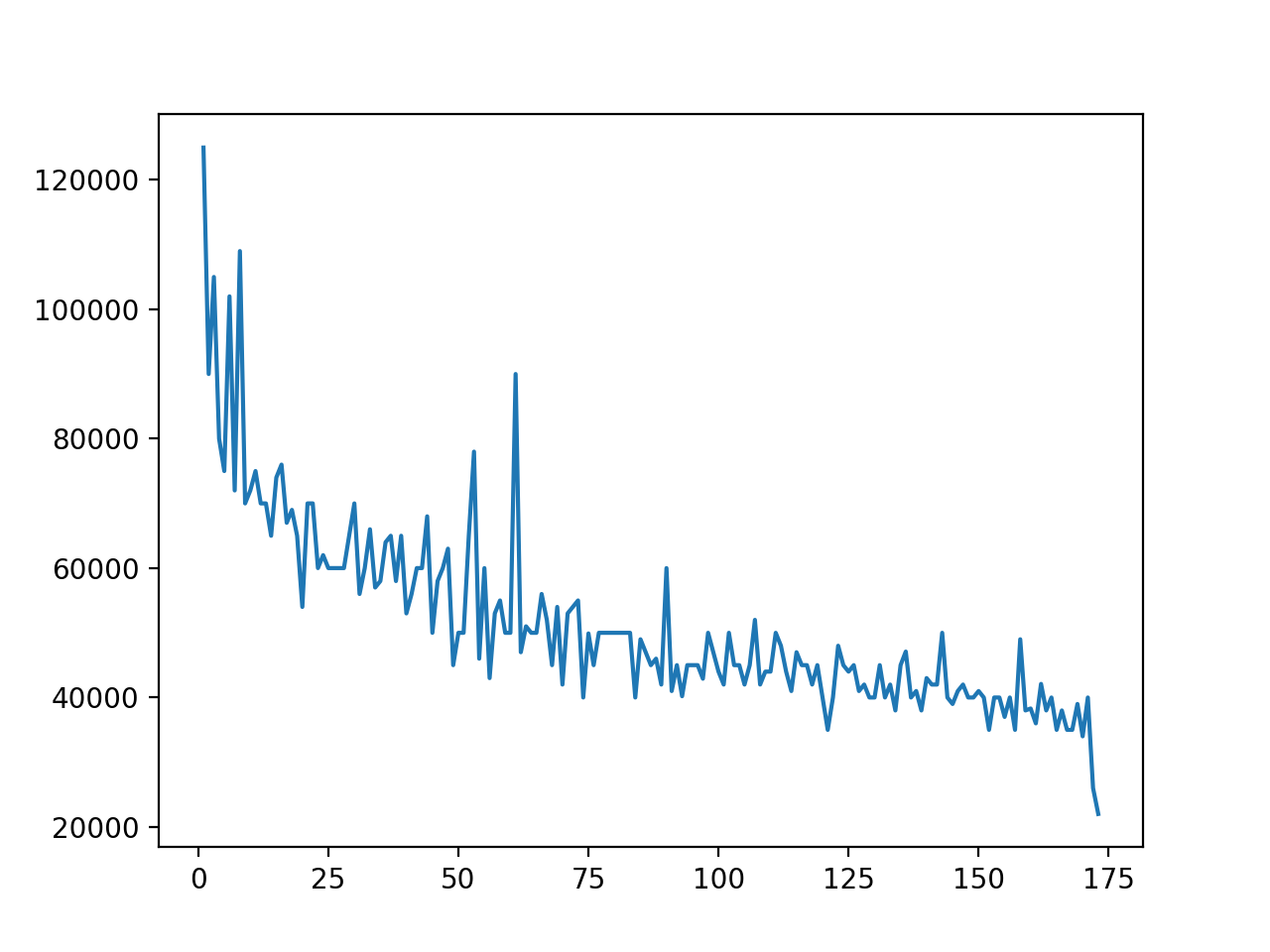
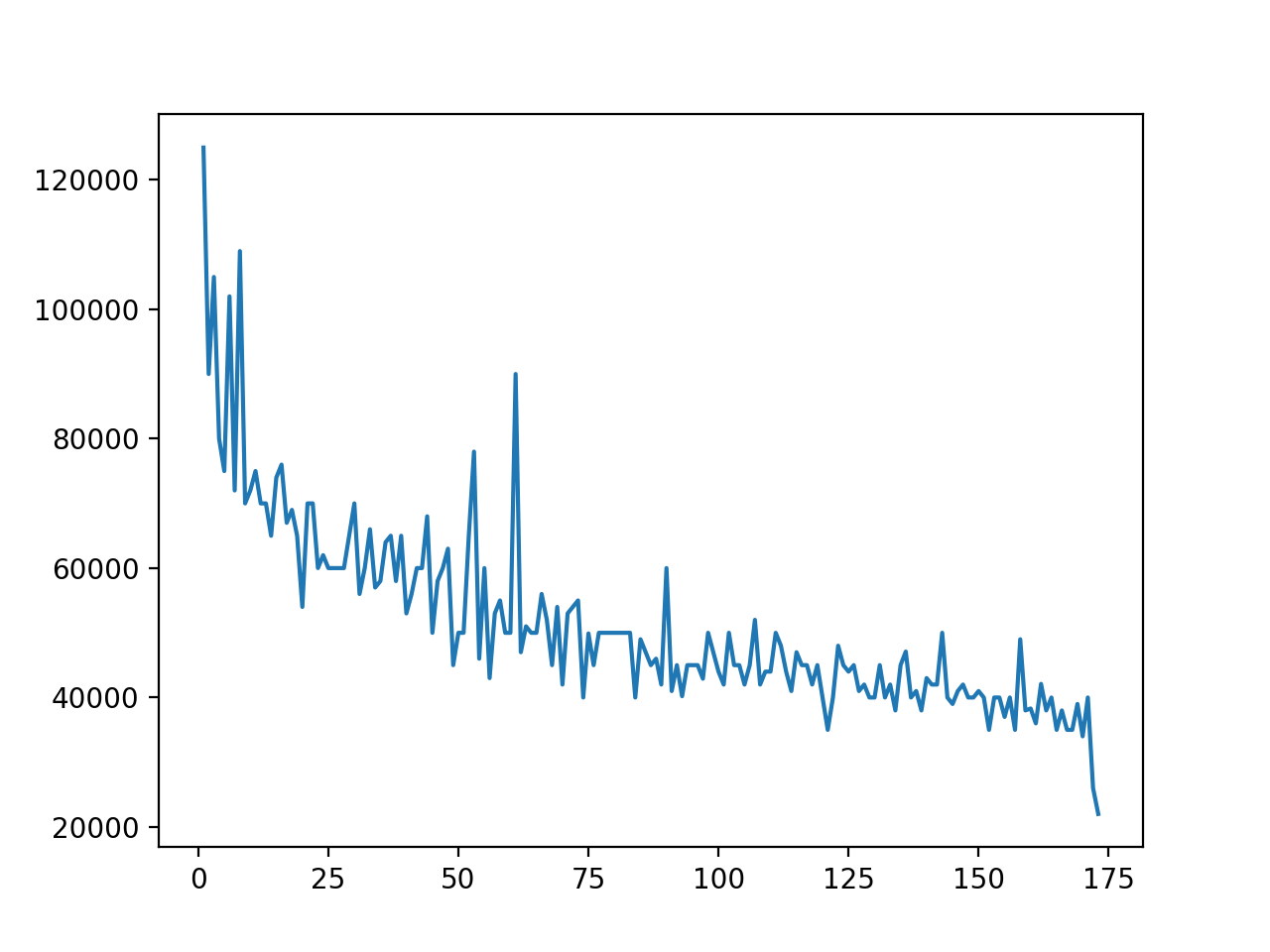
Гистограмма показывает данные, сгруппированные в десять ячеек в диапазоне от $20 000 до $120 000 с шагом в $10 000.
Исключения
В правой части графика виднеется маленькая ячейка – специалисты в этой области получают большую зарплату по сравнению со всеми категориями. Хотя это не основная цель, гистограмма может помочь обнаружить такие исключения. Исследуем эту штуку подробнее:
- какие специальности представляет это исключение?
- где его граница?
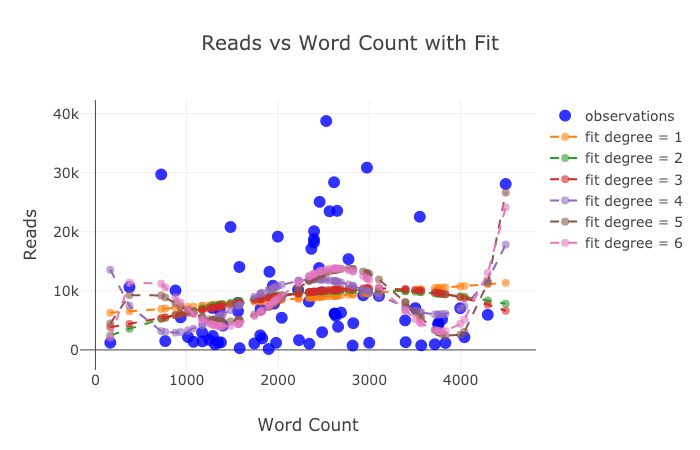
В отличие от первого графика, мы хотим сравнить несколько точек данных и увидеть более подробную информацию о них. Для этого вертикальный график является отличным инструментом. Выберем пять специальностей с самым высоким средним доходом. Необходимо выполнить два шага:
- Для сортировки по столбцу «Median» используйте функцию .sort_values() и укажите имя столбца, а также направление ascending=False.
- Чтобы получить первые пять пунктов списка, используйте функцию .head().
Создадим новый DataFrame top_5:
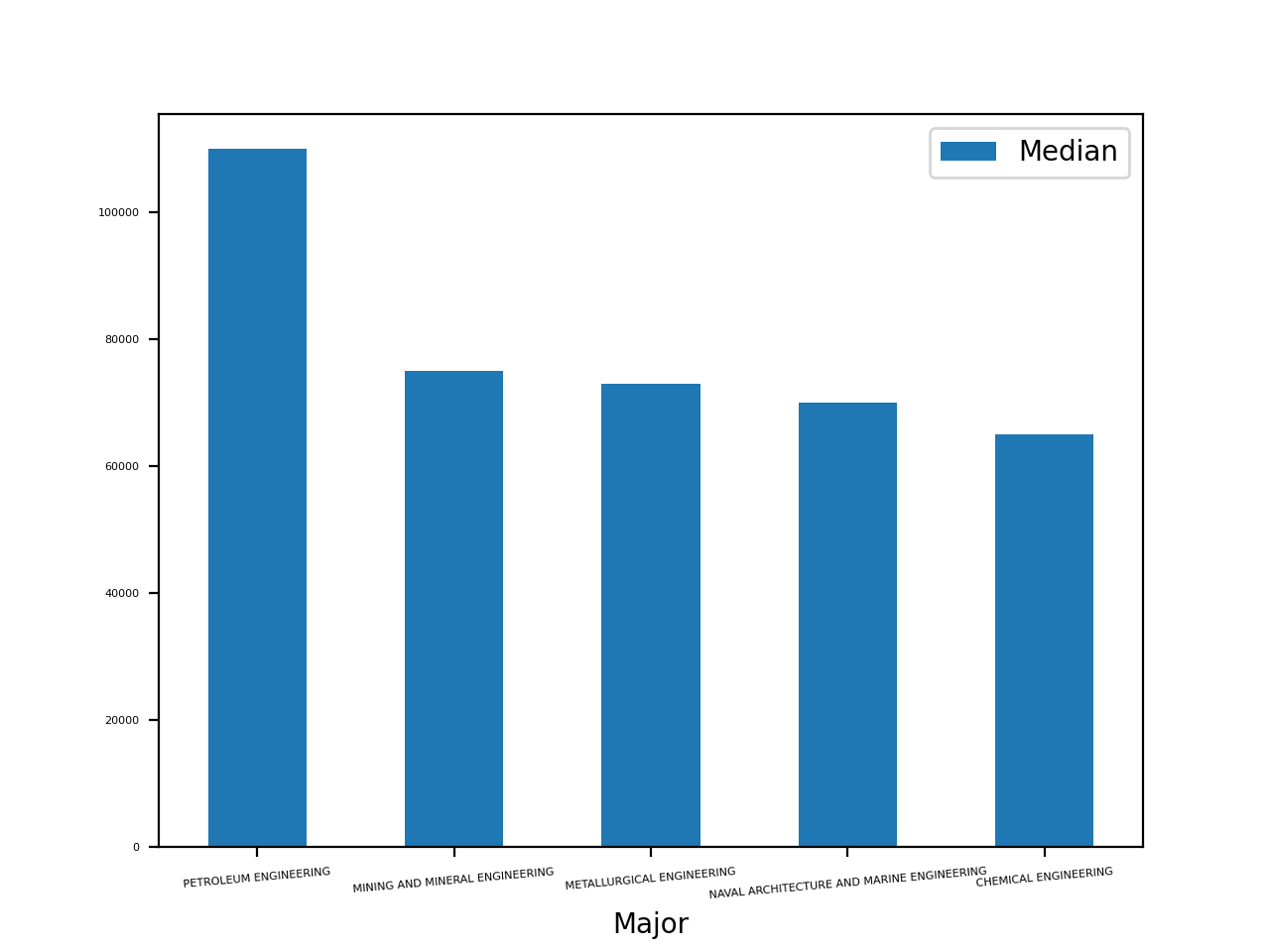
Этот график показывает, что средняя зарплата специалистов нефтегазового направления более чем на $20 000 выше остальных. Заработки занявших 2-4 места специальностей относительно близки друг к другу.
Если у вас есть точки данных с гораздо более высокими/низкими значениями, чем остальные, необходимо этот момент исследовать: можно просмотреть столбцы, содержащие связанные данные.
Рассмотрим все специальности, средняя зарплата которых превышает $60 000. Отфильтруем их по маске df [ df [«Median»] > 60000] и создадим график с тремя столбцами:
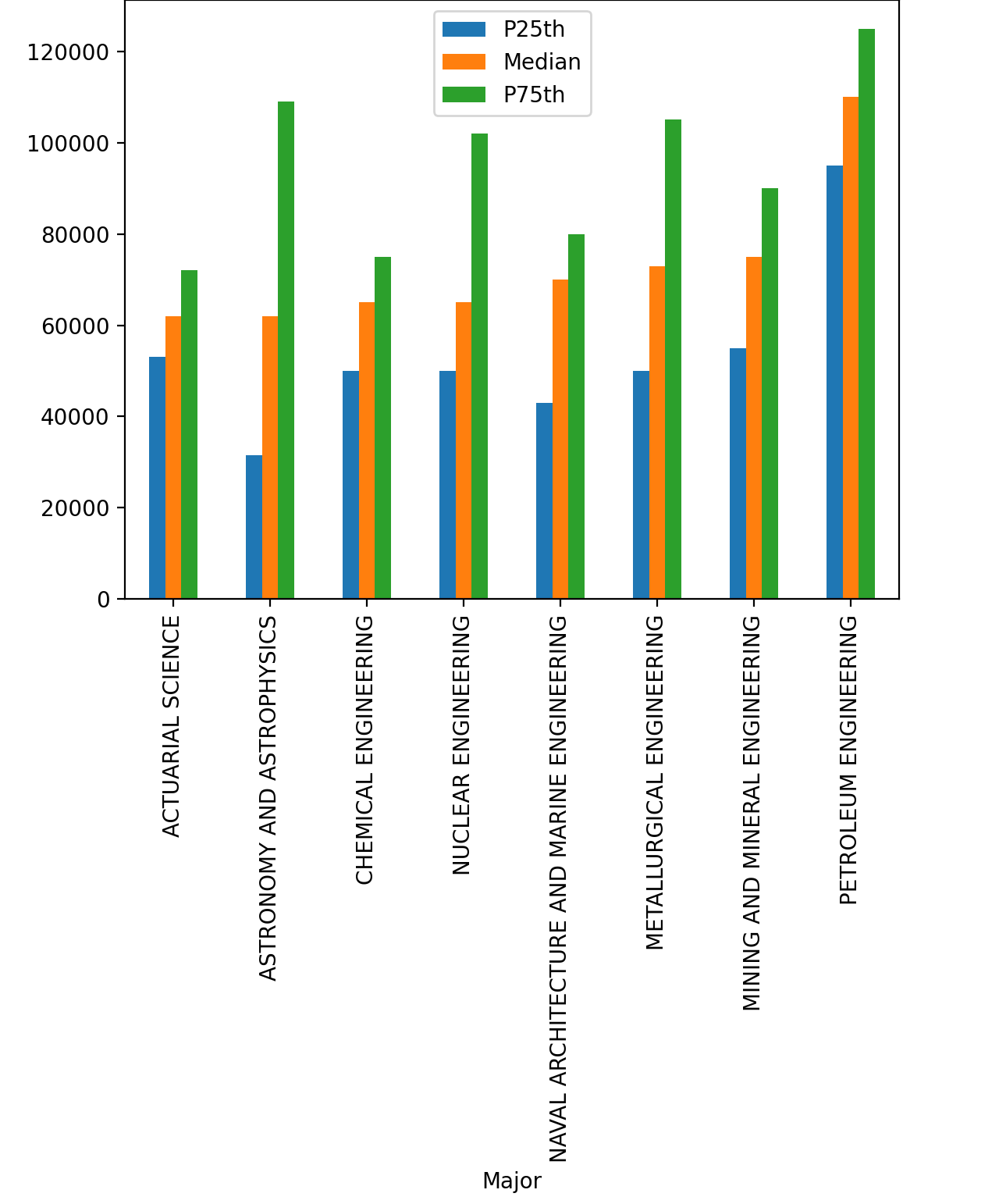
25-й и 75-й процентили подтверждают, что нефтяники самые высокооплачиваемые работники.
Почему исключения так важны? Если вы студент – все очевидно, но исключения интересны с точки зрения анализа. Неверные данные могут быть вызваны ошибками или погрешностями.
Корреляция
Часто требуется проверить, связаны ли столбцы набора данных. Например, связан ли высокий оклад с вероятностью не получить работу. В качестве первого шага создайте точечную диаграмму с этими столбцами:
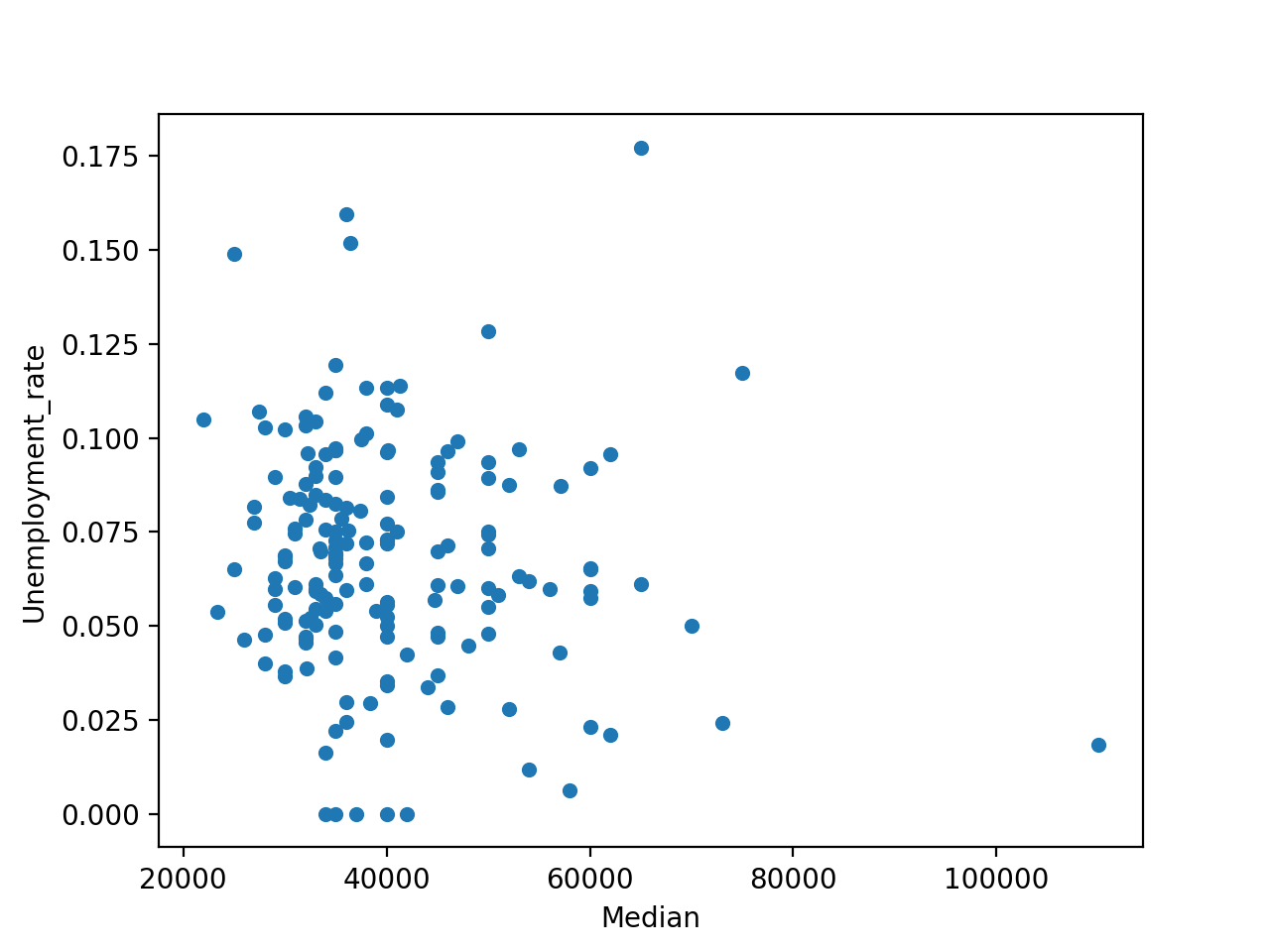
Можно заметить, что существенной корреляции между доходами и уровнем безработицы нет.
Хотя точечная диаграмма является отличным инструментом для получения первого впечатления о возможной корреляции, она не является окончательным доказательством связи – для этого подойдет функция .corr() .
Однако имейте в виду, что даже если существует корреляция между двумя значениями, не факт, что изменение одного приведет к изменению другого.
Анализ категориальных данных
Чтобы обрабатывать большие куски информации, удобно сортировать ее по категориям. Здесь мы познакомимся с инструментами для оценки категорий и проверки ее валидности.
Многие наборы данных уже содержат явную или неявную категоризацию – в нашем примере 173 специальности разделены на 16 категорий.
Группировка
Основное использование категорий – группирование и агрегирование. Можно использовать функцию .groupby() для определения популярности каждой из категорий в основном датасете:
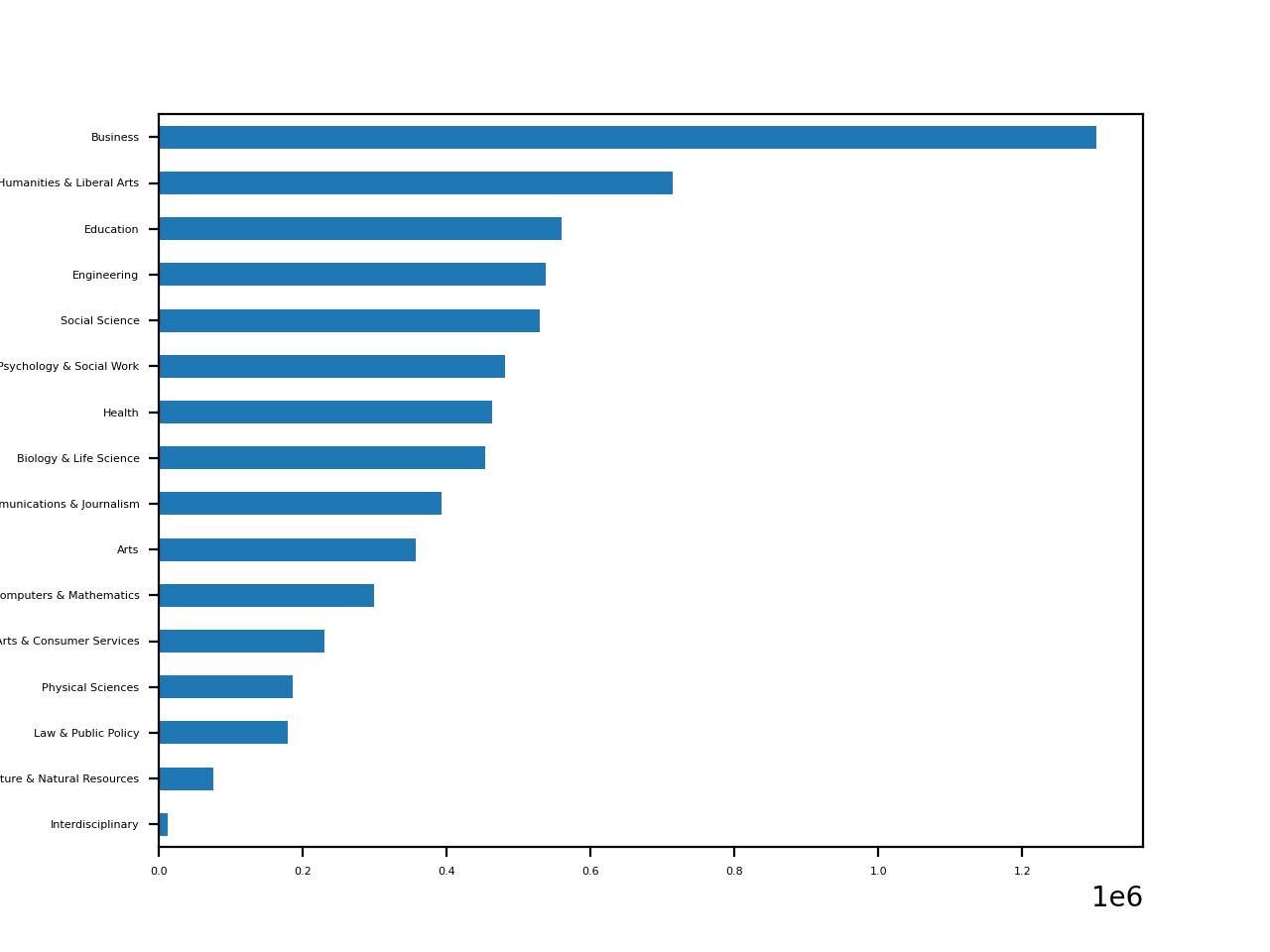
Определение коэффициентов
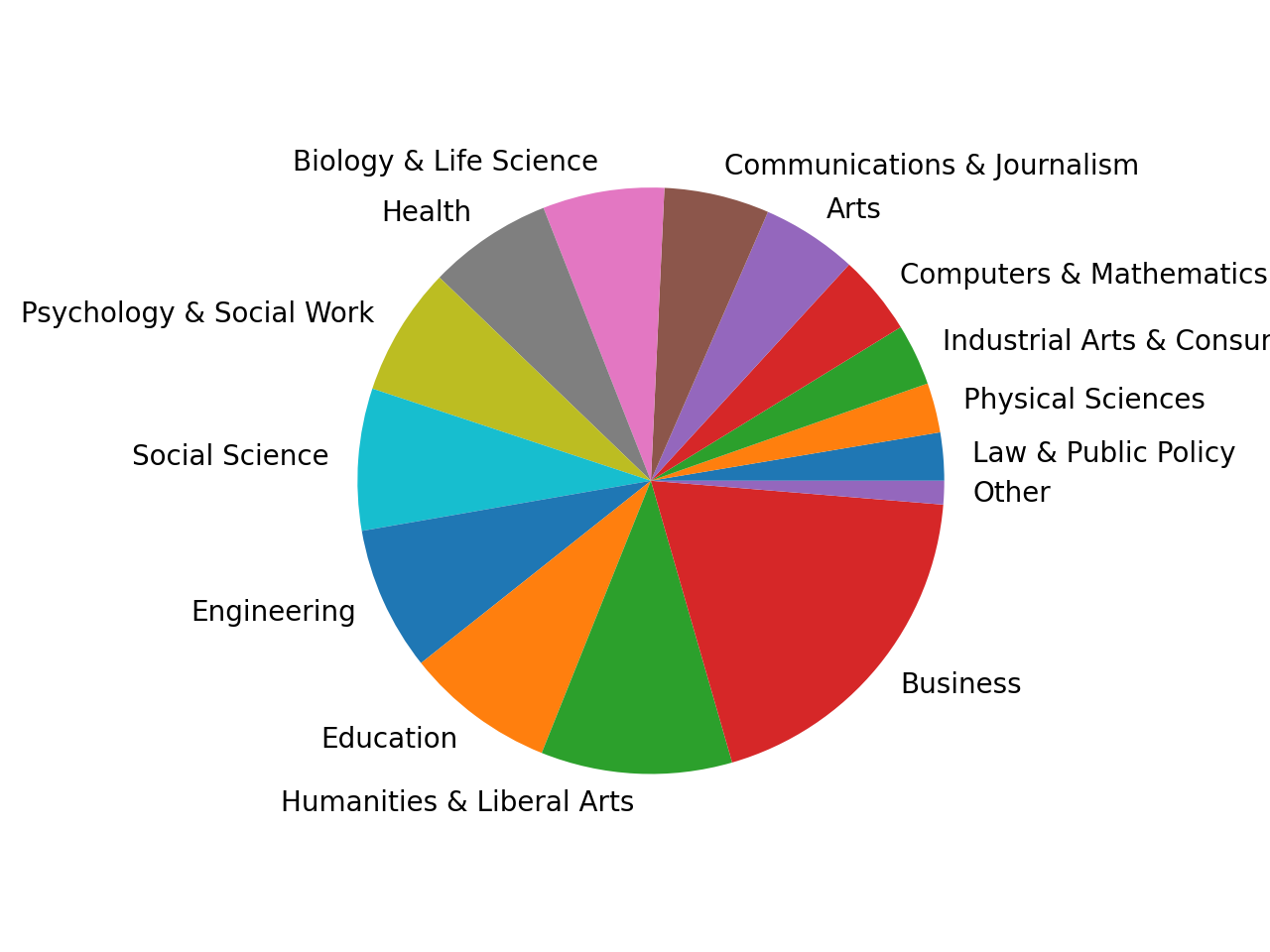
Если необходимо визуализировать соотношения, пригодятся круговые графики. Поскольку cat_totals содержит несколько маленьких категорий, создание кругового графика с помощью cat_totals.plot(kind=»pie») приведет к появлению крошечных фрагментов с перекрывающимися метками.
Чтобы решить проблему, следует объединить более мелкие категории в одну группу. Например, категории с общим числом менее 100 000 в категорию «Другое». Теперь создадим круговую диаграмму:
Заключение
Этот материал направлен на изучение процесса визуализации набора данных с помощью Python и библиотеки P andas.
Из него вы узнали, как сделать множество вещей:
- получить распределение вашего набора данных с помощью гистограммы;
- произвести корреляцию с точечной диаграммой;
- анализировать категории с гистограммами и их соотношениями с круговыми диаграммами;
- определить, какой график больше подходит для текущей задачи;
- используя функцию .plot() и небольшой DataFrame, эффективно управлять визуализацией ваших данных.
Используя эти знания, вы можете открывать для себя еще более интересные визуализации. Удачи!
На Python создают прикладные приложения, пишут тесты и бэкенд веб-приложений, автоматизируют задачи в системном администрировании, его используют в нейронных сетях и анализе больших данных. Язык можно изучить самостоятельно, но на это придется потратить немало времени.
Если вы хотите быстро понять основы программирования на Python, обратите внимание на онлайн-курс «Библиотеки программиста». За 30 уроков (15 теоретических и 15 практических занятий) под руководством практикующих экспертов вы не только изучите основы синтаксиса, но и освоите две интегрированные среды разработки (PyCharm и Jupyter Notebook), работу со словарями, парсинг веб-страниц, создание ботов для Telegram и Instagram, тестирование кода и даже анализ данных. Чтобы процесс обучения стал более интересным и комфортным, студенты получат от нас обратную связь. Кураторы и преподаватели курса ответят на все вопросы по теме лекций и практических занятий.
Источники
Источник: proglib.io
Качественно новый уровень визуализации данных в Python
Нам сложно отказываться от дел, на которые мы уже потратили много времени. Поэтому мы остаёмся на нелюбимой работе, вкладываемся в проекты, которые точно не «взлетят». А ещё продолжаем пользоваться утомительной библиотекой matplotlib для построения графиков, когда есть более эффективные и привлекательные альтернативы.
За последние несколько месяцев я осознал, что единственная причина, по которой я пользуюсь matplotlib, заключается в том, что я потратил сотни часов на изучение её запутанного синтаксиса. Из-за неё я жил на StackOverflow, пытаясь найти ответ на тот или иной вопрос. К счастью, для создания графиков на Python настали светлые времена, и после изучения доступных вариантов я выбрал явного победителя (с точки зрения простоты использования, документации и функциональности) в лице библиотеки plotly. В этой статье мы с ней познакомимся и научимся делать более качественные графики за меньшее время — зачастую с помощью одной строки кода.
Весь код для этой статьи доступен на GitHub. Все графики интерактивны, а посмотреть их можно на NBViewer.
Пример графиков plotly (источник)
Обзор plotly
Пакет plotly для Python — это open-source библиотека, основанная на plotly.js, которая, в свою очередь, основана на d3.js. Мы будем использовать обёртку для plotly под названием cufflinks, написанную для работы с DataFrame’ами Pandas.
Data Engineer АО «Гринатом» , Москва , По итогам собеседования
Вообще, Plotly — это графическая компания с несколькими продуктами и open-source инструментами. Библиотека на Python бесплатна для использования, и мы можем создавать графики без ограничений в офлайн-режиме плюс до 25 графиков в онлайн-режиме.
Весь код из этой статьи был написан в Jupyter Notebook с plotly + cufflinks, запущенными в офлайн-режиме. После установки plotly и cufflinks с помощью pip install cufflinks plotly добавьте следующие импорты в блокнот Jupyter:
# Стандартные импорты plotly import plotly.plotly as py import plotly.graph_obs as go from plotly.offline import iplot import cufflinks cufflinks.go_offline() # Устанавливаем глобальную тему cf.set_config_file(world_readable=True, theme=’pearl’, offline=True)
Гистограммы и бочки с усами
Графики по одной переменной — стандартный способ начать анализ, а гистограмма — надёжный выбор (хоть и не без изъянов) для отображения распределения. Давайте нарисуем интерактивную гистограмму количества лайков, используя статистику моих постов на Medium ( df это обычный DataFrame):
df[‘claps’].iplot(kind=’hist’, xTitle=’claps’, yTitle=’count’, title=’Claps Distribution’)
Интерактивная гистограмма, созданная с помощью plotly + cufflinks
Если вы работали с matplotlib, то вы заметили, что нам пришлось добавить всего одну букву ( iplot() вместо plot() ), чтобы получить гораздо более красивый и интерактивный график! Можно кликнуть на данные для получения подробностей, приблизить части графика и, как мы потом увидим, выбирать отдельные категории для просмотра.
А вот так можно построить наложенные друг на друга гистограммы:
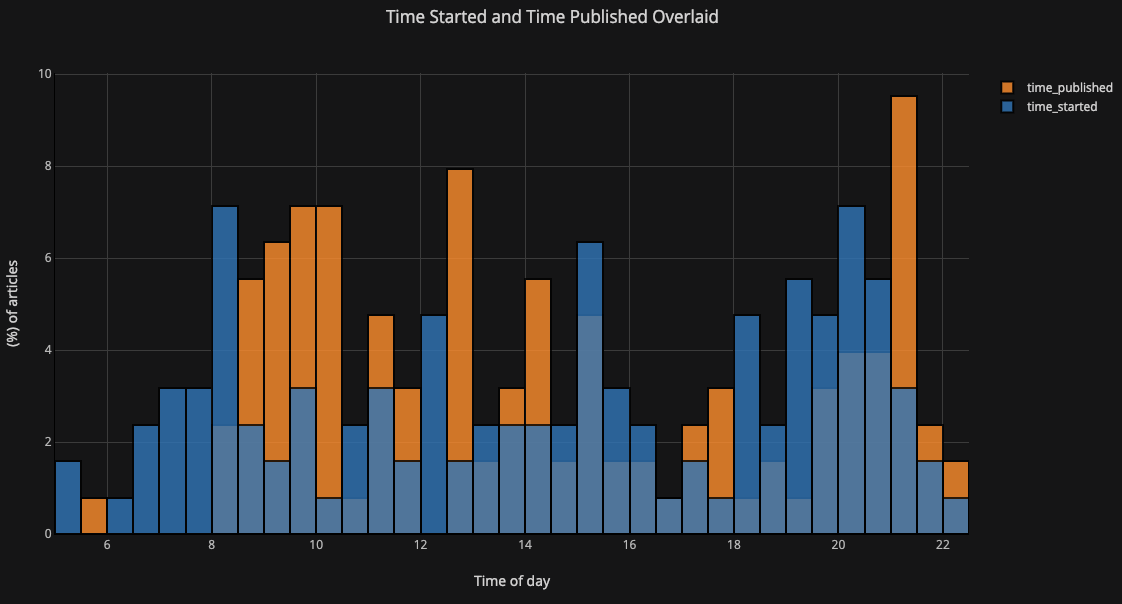
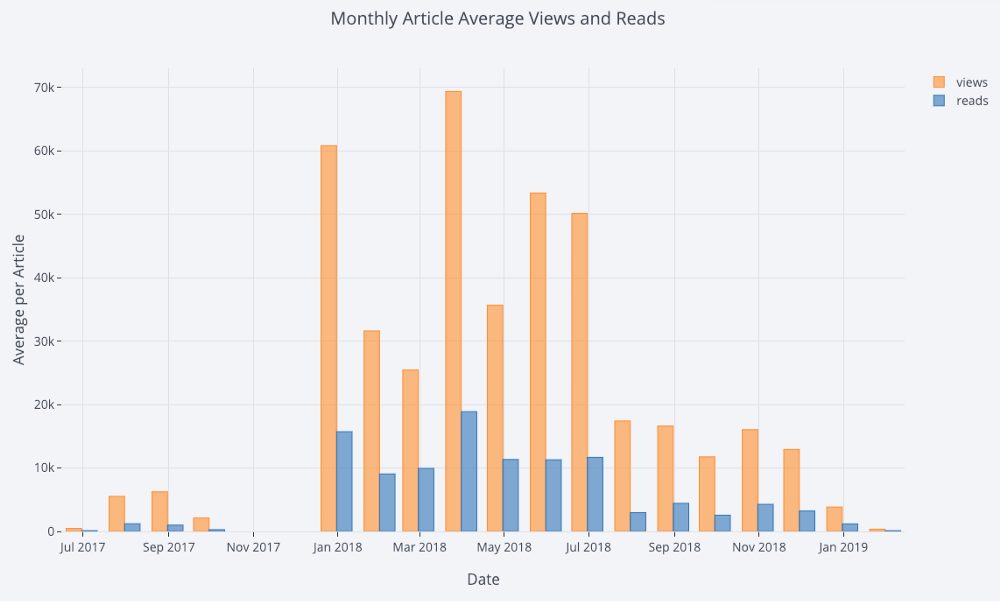
Немного поколдовав с pandas, получим столбчатую диаграмму:
# Создаём DataFrame с месячной частотой и строим график df2 = df[[‘view’,’reads’,’published_date’]]. set_index(‘published_date’). resample(‘M’).mean() df2.iplot(kind=’bar’, xTitle=’Date’, yTitle=’Average’, title=’Monthly Average Views and Reads’)
Как видите, мы можем совмещать возможности pandas и plotly + cufflinks. Для графика «ящик с усами», который показывает количество лайкнувших каждый пост, мы сначала используем pivot() , а затем строим график:
df.pivot(columns=’publication’, values=’fans’).iplot( kind=’box’, yTitle=’fans’, title=’Fans Distribution by Publication’)
Преимущества интерактивности заключаются в том, что мы можем исследовать данные и делать их выборки любым образом. Ящик с усами содержит много информации, большая часть которой пройдёт мимо нас, если мы не сможем видеть числа!
Диаграмма рассеяния
Это, наверное, наиболее часто используемая диаграмма при анализе данных. Она позволяет увидеть изменение переменной с течением времени или отношение между двумя (или более) переменными.
Временные ряды
В значительной части данных содержится информация о времени. К счастью, plotly + cufflinks были разработаны с расчётом на визуализацию временных рядов. Создадим DataFrame с моими статьями и посмотрим, как менялись тренды.
# Создаём DataFrame со статьями Towards Data Science tds = df[df[‘publication’] == ‘Towards Data Science’]. set_index(‘published_date’) # Строим продолжительность чтения как временной ряд tds[[‘claps’, ‘fans’, ‘title’]].iplot( y=’claps’, mode=’lines+markers’, secondary_y = ‘fans’, secondary_y_title=’Fans’, xTitle=’Date’, yTitle=’Claps’, text=’title’, title=’Fans and Claps over Time’)
Здесь мы в одну строку делаем сразу несколько разных вещей:
- Автоматически получаем красиво отформатированную ось X;
- Добавляем дополнительную ось Y, так как у переменных разные диапазоны;
- Добавляем заголовки статей, которые высвечиваются при наведении курсора.
Для большей наглядности можно легко добавить текстовые аннотации:
tds_monthly_totals.iplot( mode=’lines+markers+text’, text=text, y=’word_count’, opacity=0.8, xTitle=’Date’, yTitle=’Word Count’, title=’Total Word Count by Month’)
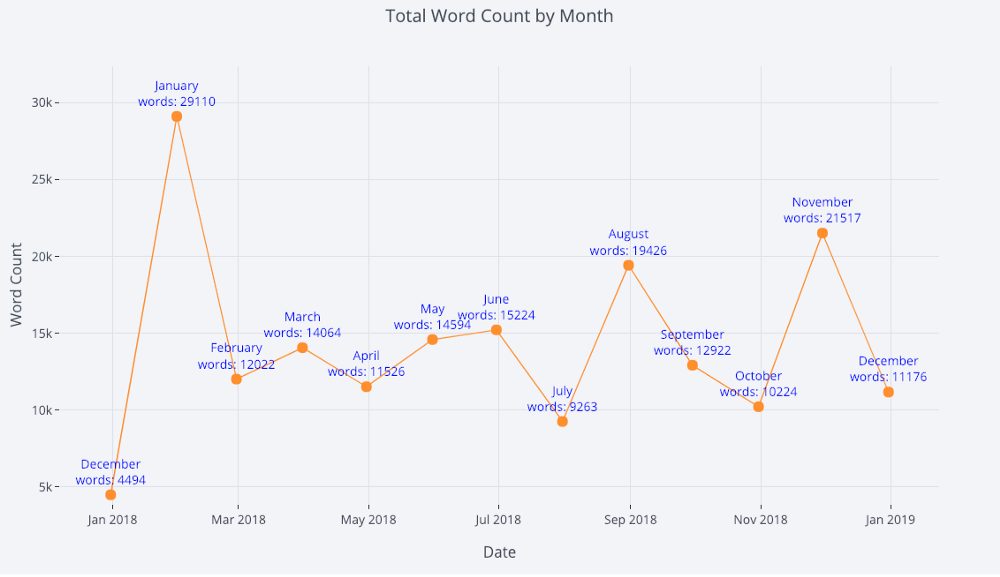
Диаграмма рассеяния с аннотациями
А вот так можно создать точечную диаграмму с двумя переменными, окрашенными согласно третьей категориальной переменной:
df.iplot( x=’read_time’, y=’read_ratio’, # Указываем категорию categories=’publication’, xTitle=’Read Time’, yTitle=’Reading Percent’, title=’Reading Percent vs Read Ratio by Publication’)
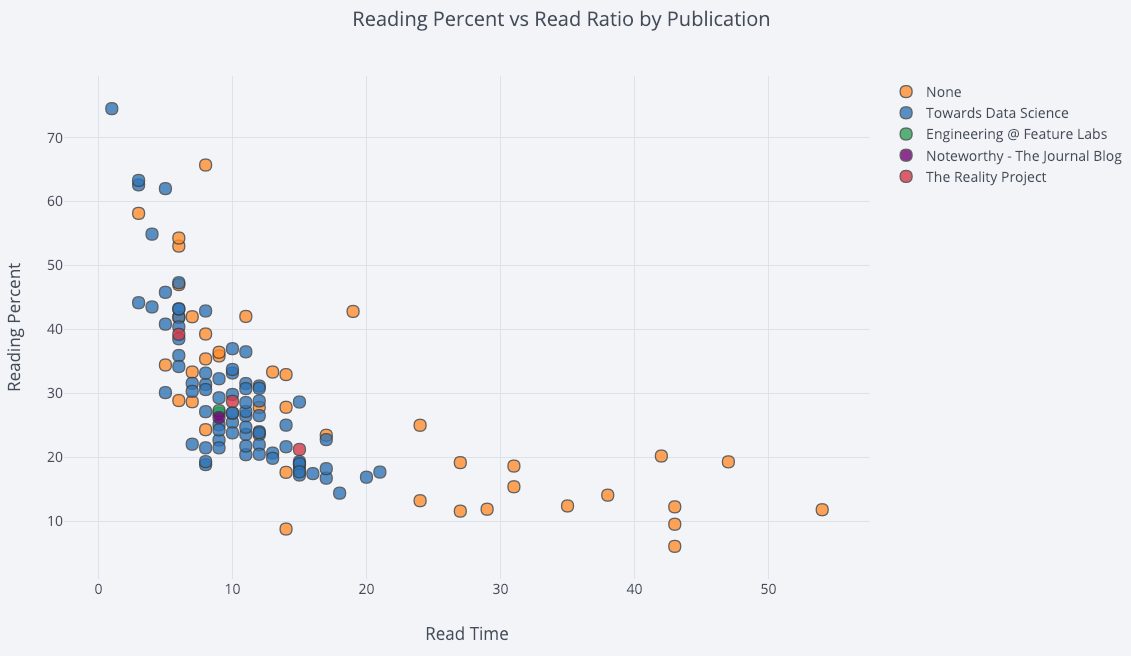
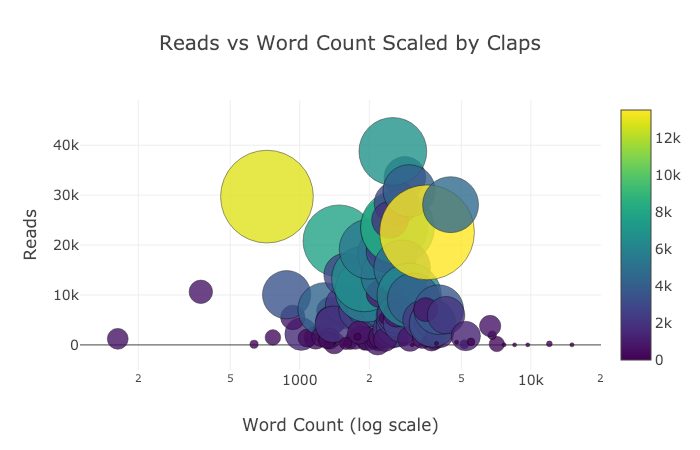
Сделаем график немного более сложным, используя логарифмическую ось (настраивается через аргумент layout , подробнее в документации) и установив размер пузырьков в соответствии с числовой переменной:
tds.iplot( x=’word_count’, y=’reads’, size=’read_ratio’, text=text, mode=’markers’, # Log xaxis layout=dict( xaxis=dict(type=’log’, title=’Word Count’), yaxis=dict(title=’Reads’), title=’Reads vs Log Word Count Sized by Read Ratio’))
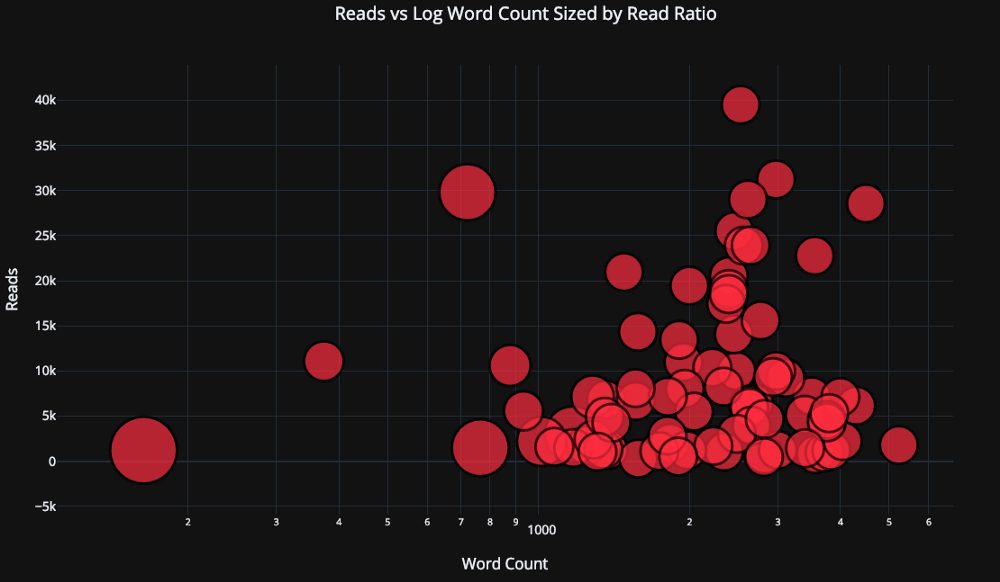
Если захотеть (подробности в блокноте), то можно уместить даже 4 переменные (не советую) на одном графике!

Как и раньше, мы совмещаем возможности pandas и plotly + cufflinks для получения полезных графиков:
df.pivot_table( values=’views’, index=’published_date’, columns=’publication’).cumsum().iplot( mode=’markers+lines’, size=8, symbol=[1, 2, 3, 4, 5], layout=dict( xaxis=dict(title=’Date’), yaxis=dict(type=’log’, title=’Total Views’), title=’Total Views over Time by Publication’))
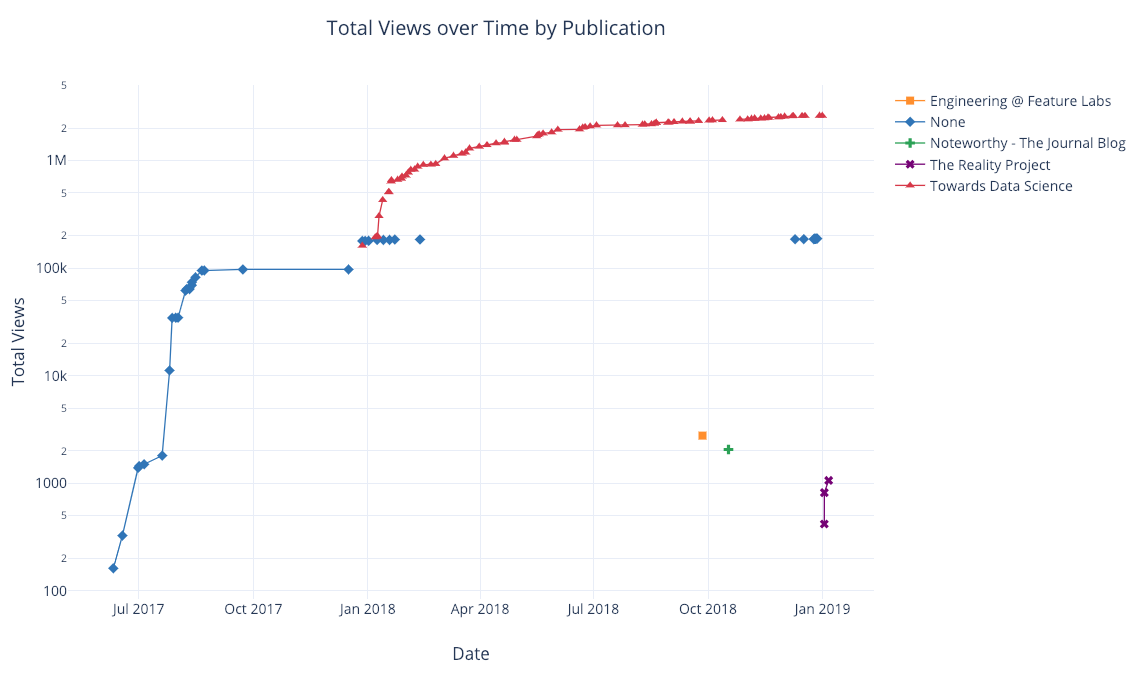
Загляните в блокнот или документацию, чтобы увидеть больше примеров добавленной функциональности. Мы можем добавить текстовые аннотации, контрольные линии и линии тренда с помощью всего лишь одной строки кода и при этом сохраним всю интерактивность.
Продвинутые графики
Теперь познакомимся с несколькими графиками, которые используются не так часто, но могут выглядеть довольно впечатляюще. Мы воспользуемся plotly.figure_factory(), чтобы даже эти невероятные графики создавать в одну строку.
Матрица рассеяния
Матрица рассеяния — отличный выбор, если нам нужно изучить отношения между многими переменными:
import plotly.figure_factory as ff figure = ff.create_scatterplotmatrix( df[[‘claps’, ‘publication’, ‘views’, ‘read_ratio’,’word_count’]], diag=’histogram’, index=’publication’)
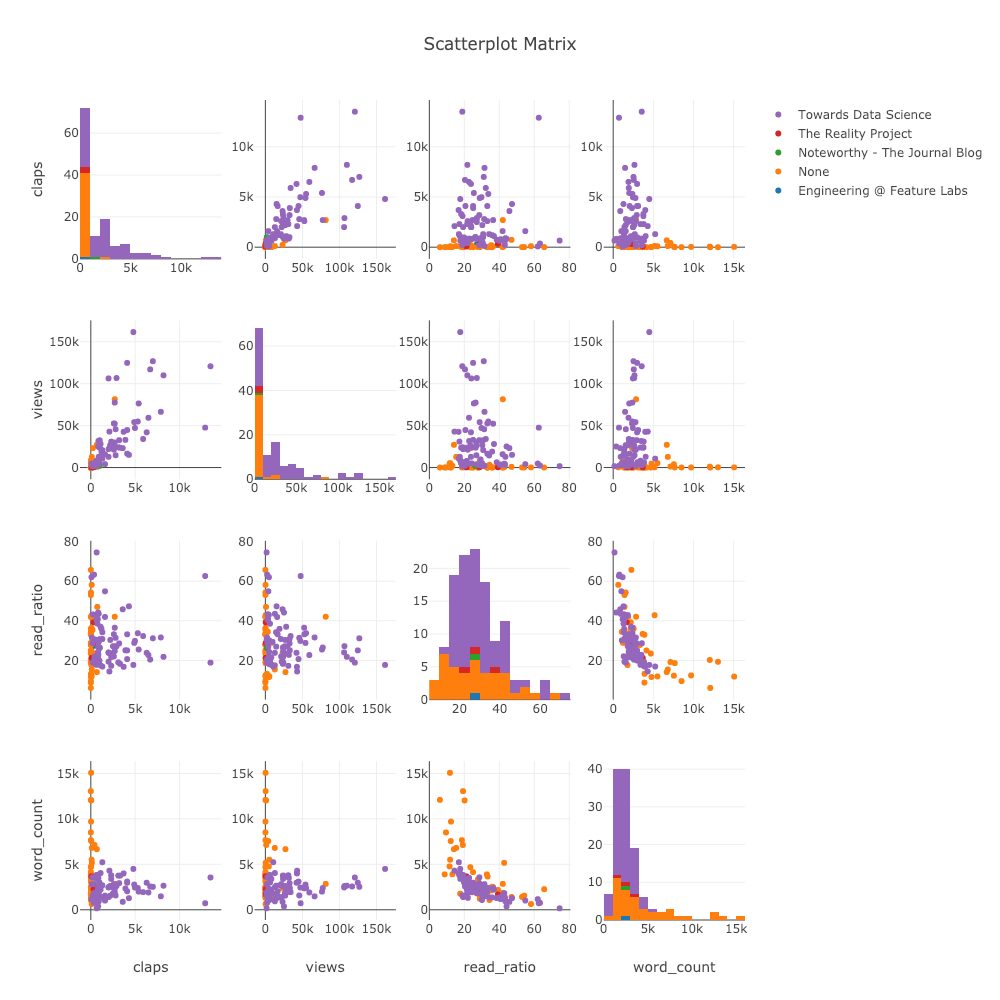
Даже этот график полностью интерактивен, что позволяет нам исследовать данные.
Корреляционная тепловая карта
Чтобы отобразить взаимосвязи между числовыми переменными, сначала посчитаем коэффициенты корреляции, а затем создадим аннотированную тепловую карту:
corrs = df.corr() figure = ff.create_annotated_heatmap( z=corrs.values, x=list(corrs.columns), y=list(corrs.index), annotation_text=corrs.round(2).values, showscale=True)
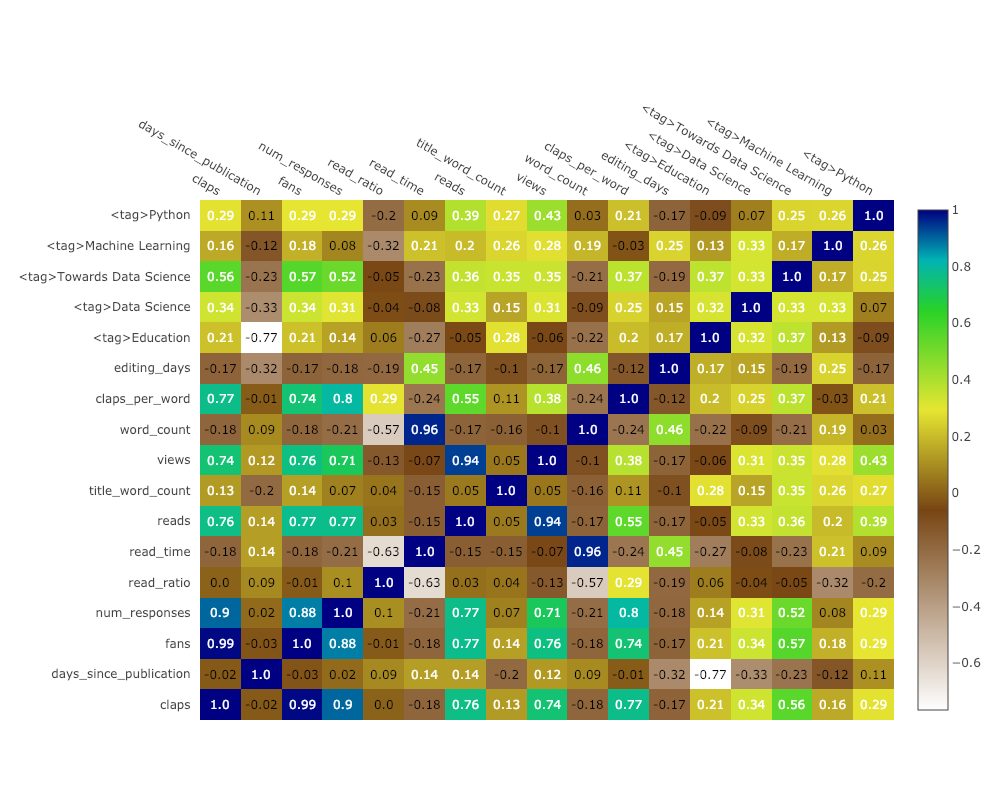
Cufflinks также предлагает несколько тем, которые можно использовать для получения совершенно другого стиля, не прилагая усилий. Например, ниже можно увидеть графики с темами «space» и «ggplot»
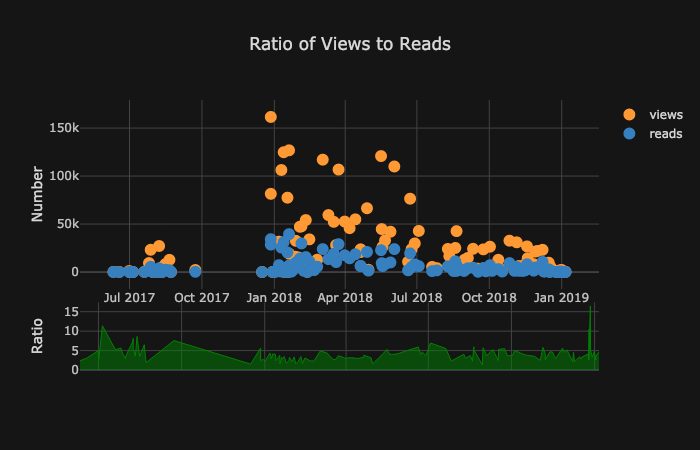
Ну и куда без круговой диаграммы?

Редактирование в Plotly Chart Studio
В процессе создания этих графиков в блокноте можно заметить маленькую ссылку в правом нижнем углу, которая гласит «Export to plot.ly». После перехода по ней вы попадёте в редактор графиков, где вы можете внести финальные штрихи в график перед презентацией графика. Вы можете добавить аннотации, выбрать цвета и в целом сделать из графика конфетку. Затем можно опубликовать график и поделиться ссылкой на него.
Ниже показаны два графика, которые я подправил в Chart Studio: