
В SPSS можно выполнять анализ данных раздельно по группам. Группой в этом контексте называется определенное количество наблюдений с одинаковыми значениями признаков. Чтобы можно было производить обработку по группам, файл должен быть отсортирован по группирующим переменным. Такой переменной может быть, например, переменная sex.
В этом случае все переменные со значением признака 1 (женский) образуют одну группу, а все переменные со значением признака 2 (мужской) – другую группу. С каждой группой можно проводить определенные операции, например, выполнять частотный анализ. При этом частотный анализ проводится раздельно для признаков мужской и женский. В SPSS такое разделение на группы можно выполнять автоматически. Рассмотрим следующий пример, основанный на опросе студентов об их психическом состоянии и социальном положении:
Проведем частотный анализ переменной psyche (психическое состояние) раздельно для всех изучаемых специальностей. В соответствии со значениями переменной fach (специальность) у нас образуются 9 групп (1 = Юриспруденция, 2 = Экономика, 3 = Гуманитарные науки, 4 = Психология и т.д.). В этом случае файл данных studium.sav должен быть сначала отсортирован по переменной fach. Поступите следующим образом:
Grouping Data in SPSS
- Загрузите файл studium.sav в редактор данных.
- Выберите в меню команды Data › Split File… (Данные › Разделить файл) Откроется диалоговое окно Split File.
Рис. 7.7. Диалоговое окно Split File
По умолчанию разделение на группы не предполагается. Если выбрать пункт Organize output by groups (Разделить вывод на группы), мы получим вывод результатов по каждой группе отдельно. Эти группы должны быть определены в поле Groups based on (Группы, созданные на основе) на базе соответствующих переменных.
Еще одну возможность предоставляет опция Compare Groups (Сравнить группы). Она организует вывод таким образом, что можно визуально сравнить разные группы друг с другом. Но сначала мы рассмотрим раздельный вывод.
- Выберите опцию Organize output by groups. Для раздельного выполнения операций по группам необходимо, чтобы файл данных был предварительно отсортирован по этим группирующим переменным. По этой причине опция Sort the file by grouping variables (Сортировать файл по группирующим переменным) выбрана по умолчанию.
- Перенесите переменную fach в поле Groups based on. Если выбирается несколько группирующих переменных, то последовательность, в которой они стоят в списке, определяет порядок или приоритет сортировки.
- Щелкните на кнопке ОК. Файл studium.sav будет отсортирован по переменной fach, то есть разбит на группы в соответствии с ее значениями. Сообщение File split on (Разделение файла включено) в строке состояния внизу окна SPSS информирует об активации режиме разделения.
- Выполните частотный анализ переменной psyche.
Вы получите следующий результат (ниже для экономии места показаны частотные таблицы только для специальностей Юриспруденция и Естественные науки).
Ввод данных в SPSS ч 1
Источник: samoychiteli.ru
1.2. Сортировка и разделение на группы
Сортировка наблюдений. Данные в SPSS можно сортировать в соответствии со значениями одной или нескольких переменных. Для этого используется команда меню Data (Данные) Sort Cases. (Сортировать наблюдения), которая открывает диалоговое окно Sort Cases (Рис. 2.5). В список Sort by (Сортировать по) диалогового окна нужно перенести переменные, по которым будет осуществляться сортировка.
Для каждой переменной отдельно установить направление сортировки: Ascending (По возрастанию) или Descending — в порядке убывания.
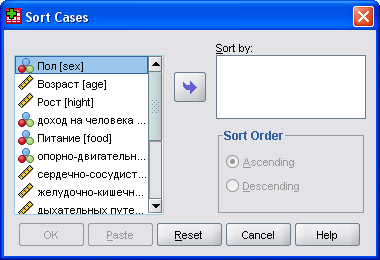
Упражнение 2.Упорядочить данные рабочего файла по возрасту. Для этого нужно открыть диалоговое окно Sort Cases и в список Sort by перенести переменнуюage. Настройку по умолчанию Ascending (По возрастанию) сохранить. Подтвердить настройки кнопкой ОК. В редакторе данные будет отсортирован по возрастанию значений переменной age.
Разделение наблюдений на группы. В SPSS можно выполнять анализ данных раздельно по группам. Группой в этом контексте называется определенное количество наблюдений с одинаковыми значениями признаков. Чтобы можно было производить обработку по группам, файл должен быть отсортирован по группирующим переменным. Такой переменной может быть, например, переменная sex.
В этом случае все переменные со значением признака 1 (женский) образуют одну группу, а все переменные со значением признака 2 (мужской) — другую группу. С каждой группой можно проводить определенные операции, например, выполнять частотный анализ. При этом частотный анализ проводится раздельно для признаков мужской и женский. В SPSS такое разделение на группы можно выполнять автоматически. Рассмотрим следующий пример, основанный на опросе студентов об их психическом состоянии и социальном положении:
Выберите в меню команды Data (Данные) Split File. (Разделить файл) Откроется диалоговое окно Split File.
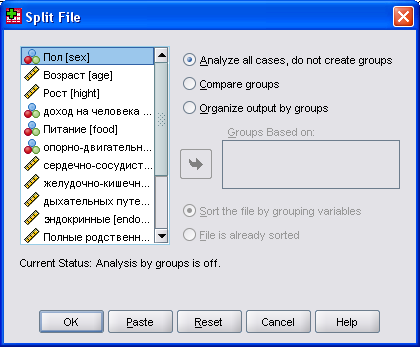
Рис. 7.7: Диалоговое окно Split File
По умолчанию разделение на группы не предполагается. Если выбрать пункт Organize output by groups (Разделить вывод на группы), мы получим вывод результатов по каждой группе отдельно. Эти группы должны быть определены в поле Groups based on (Группы, созданные на основе) на базе соответствующих переменных.
Еще одну возможность предоставляет опция Compare Groups (Сравнить группы). Она организует вывод таким образом, что можно визуально сравнить разные группы друг с другом. Но сначала мы рассмотрим раздельный вывод.
Выберите опцию Organize output by groups. Для раздельного выполнения операций по группам необходимо, чтобы файл данных был предварительно отсортирован по этим группирующим переменным. По этой причине опция Sort the file by grouping variables (Сортировать файл по группирующим переменным) выбрана по умолчанию.
Перенесите переменную sexв поле Groups based on. Если выбирается несколько группирующих переменных, то последовательность, в которой они стоят в списке, определяет порядок или приоритет сортировки.
Щелкните на кнопке ОК. Файл будет отсортирован по переменной fach, то есть разбит на группы в соответствии с ее значениями. Сообщение File split on (Разделение файла включено) в строке состояния внизу окна SPSS информирует об активации режиме разделения.
Источник: studfile.net
Пакет данных SPSS
Группировка данных: в зависимости от цели анализа числовые данные группируются равноудаленно или неэквидистантно. Этот процесс также называется дискретизацией данных. Обычно он используется для просмотра распределения, включая распределение потребления, распределение доходов, возрастное распределение и т. Д.
В SPSS визуальная группировка в основном используется для группировки данных. Сначала откройте данные и щелкните визуальную группировку под строкой меню преобразования:

В основном мы группируем возрасты, перемещаем переменную «возраст» в «переменные, которые нужно объединить» и нажимаем, чтобы продолжить:

Вы можете назвать группирующую переменную: возраст (групповая переменная). Из гистограммы мы видим, что данные в основном сосредоточены в 20 и 35. Мы можем использовать возраст как ширину группы, от 20 до 35 Его можно разделить на 3 группы, и все те, кто меньше 20, разделены на одну группу, а все те, кто больше 35, разделены на другую группу, щелкните, чтобы создать точки разделения:

Соответствующее значение создается в сетке под визуальной ячейкой, щелкните созданную метку:

Конечно, эту операцию можно назвать эквидистантной группировкой или неэквидистантной группировкой, то есть вручную вводить значения, которые должны быть разделены в сетке.
Также существует способ работы для неэквидистантных групп, а именно перекодирование:
Нажмите Перекодировать в другие переменные под строкой меню преобразования:

Поместите возраст в числовую переменную -> выходная переменная, имя выходной переменной — age_non-equidistant, а затем щелкните переменную, выберите старое значение и новое значение:

Старое значение слева можно выбрать в соответствии с диапазоном. Введите новое значение, соответствующее старому диапазону значений, в поле нового значения справа, а затем нажмите «Добавить» под полем нового значения:

Нажмите «Продолжить» для подтверждения.
Вы можете настроить отображение вывода результатов:
Источник: russianblogs.com