
Вы сталкивались с языком, который не можете определить? Даже если ты этого не сделаешь Вы говорите на нескольких языках , может быть полезно узнать, что такое язык, просто взглянув на него.
Если вы когда-нибудь встретите слова или предложения, написанные на «неизвестном» языке, вот несколько инструментов, которые помогут вам определить их названия. иностранный язык быстро.

1. Переводчик Google
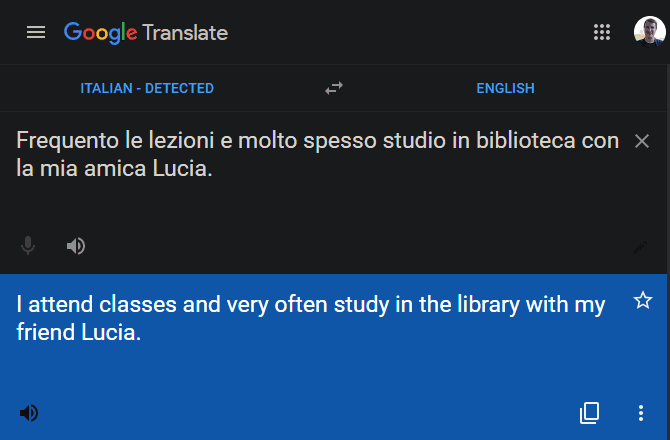
возможно, использовал Google Переводчик Из прошлого. Но знаете ли вы, что у нее есть выбор?Автоматическое распознавание языка«Что позволяет легко определять неизвестные языки?
Как узнать какой язык программирования тебе подходит?
Чтобы использовать его, скопируйте текст на неизвестном языке и перейдите в Google Translate. Вставьте текст в поле слева. Над этим полем вы должны увидеть опцию Автоматическое распознавание языка. Если вы его не видите, щелкните стрелку раскрывающегося списка, чтобы отобразить все поддерживаемые языки, и выберите Автоматическое распознавание языка.
Через мгновение текст определения языка должен измениться на [Название языка] — Обнаружено. Это позволяет вам легко выбрать язык и посмотреть, что говорится в тексте, для загрузки.
تقدم Google Переводчик Множество замечательных функций на Свои собственные телефонные приложения тоже. Там вы можете перевести почерк Или даже используйте камеру, чтобы перевести текст, который вы видите перед собой.
2. Какой это язык?
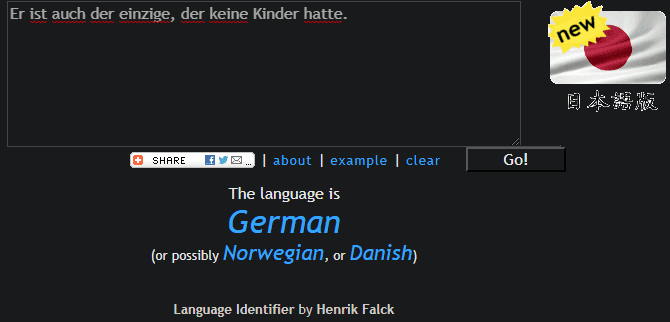
Выбрать Этот инструмент Удачно назвал любой язык при вставке текста или наборе слов. Не переводите текст, но это не то, что испортит впечатление, если вы просто хотите знать язык, на котором написан текст.
После ввода текста подождите секунду, и вы увидите используемый язык. В случаях, когда несколько языков похожи, инструмент предлагает другие возможные языки. В этом случае вам следует попробовать вставить другой образец из источника, чтобы вы могли подтвердить язык.
3. Идентификатор языка переведенной лаборатории
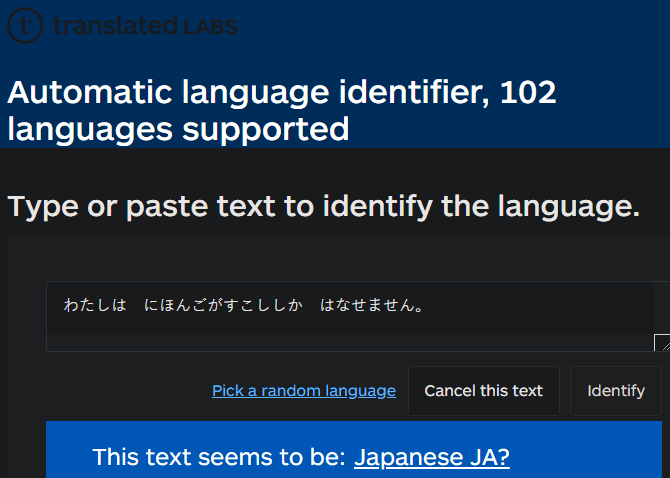
Тебе простой инструмент Другие, чтобы помочь вам выучить неизвестные языки. Просто введите текст, и вы сразу увидите, как лучше всего угадывать язык. Сервис поддерживает 102 языка, поэтому вполне вероятно, что все, что вы ищете, прямо здесь.
Какой язык программирования УЧИТЬ ПЕРВЫМ? | Для новичков
Здесь нет никаких излишеств, за исключением кнопки случайного выбора языка, если вы хотите испытать себя и выбрать язык самостоятельно.
4. Яндекс Переводчик
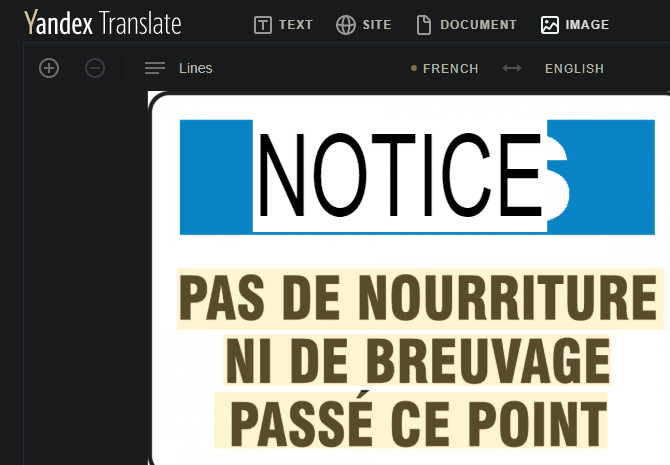
Вы с нетерпением ждете открытия язык с картинки? Сделать инструмент для перевода фотографий в Яндекс переводчик Это просто. Просто загрузите изображение со своего компьютера или перетащите его на страницу, и вы откроете для себя эту услугу. Язык, на котором это было написано на картинке.
Как и в Google Translate, опция автоматического распознавания языка должна быть включена по умолчанию. Если нет, щелкните название языка вверху справа и выберите Автоматическое распознавание языка. После этого текст изменится, чтобы отобразить язык изображения.
При желании выберите слева язык, на который хотите перевести. Затем вы можете щелкнуть текст на изображении, чтобы просмотреть его на своем языке.
5. Игры на определение языка
Вы найдете множество инструментов, которые помогут вам Знание языка который почти идентичен приведенному выше. Для чего-то немного другого, почему бы не попробовать веб-сайт, на котором вам предлагается выбрать разные языки? Это не только весело, но и проведенное некоторое время с этими языками поможет вам легче идентифицировать их в будущем.
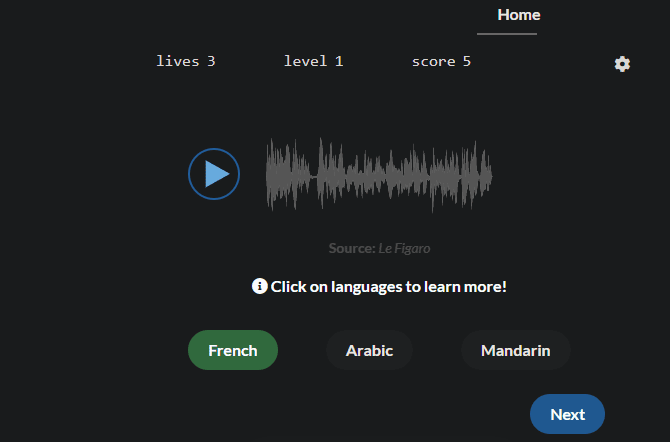
LingYourLanguage Это отличный сайт для этого. Он позволяет вам играть в одиночку или в многопользовательском режиме на четырех уровнях сложности: легкий, нормальный, сложный и энциклопедический.
На каждом этапе вы услышите аудиоклип на определенном языке, и вам нужно будет выбрать правильный ответ из нескольких вариантов. После ответа нажмите на язык, чтобы узнать о нем больше, если хотите. У вас есть ограниченное количество жизней, так что посмотрите, как далеко вы сможете продвинуться с системой оценок!
В игре более 2000 образцов на 80 языках, так что есть что открыть.
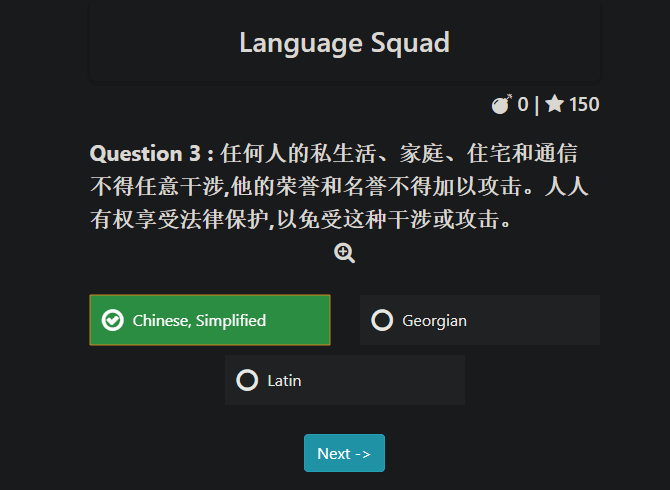
Еще одна забавная игра вроде этой Языковая команда. Он предлагает проблемы со звуком и алфавитом. Звуковая задача очень похожа на то, что предлагается в LingYourLanguage, представлены четыре уровня сложности, которые постепенно включают больше языков, чтобы повысить уровень сложности.
Alphabet Challenge, как и следовало ожидать, представляет вам образец текста на языке и просит вас выбрать его из нескольких вариантов. Выберите простой или сложный режим в зависимости от того, сколько языков вы хотите отображать.
Если вас интересует общее распознавание языка, эта задача поможет вам легче идентифицировать определенные буквы и фразы.
Изучите основы языка, чтобы лучше определять его
Просто и качественно определяем язык сообщений

У нас в компании YouScan в день обрабатывается около 100 млн. сообщений, на которых применяется много правил и разных смарт-функций. Для корректной их работы нужно правильно определить язык, потому что не все функции можно сделать агностическими относительно языка. В данной статье мы коротко расскажем про наше исследование данной задачи и покажем оценку качества на датасете из соц. сетей.
План статьи
- Проблемы определения языка
- Доступные публичные решения
- Compact Language Detector 2
- FastText
- Оценка качества
- Выводы
1. Проблемы определения языка
Определение языка достаточно старая проблема и многие ее пытаются решать в рамках мультиязычности своих продуктов. Более старые подходы используют решения основанные на н-граммах, когда считается к-во вхождений определенной н-граммы и на основе этого рассчитывается «скор» для каждого языка, после чего выбирается наиболее вероятный язык по нашей модели.
Главный недостаток данных моделей в том, что абсолютно не учитывается контекст, поэтому определение языка для схожих языковых групп затрудняется. Но из-за простоты моделей мы получаем в итоге высокую скорость определения, что позволяет экономить ресурсы для высоконагруженных систем. Другой вариант, более современный, – решение на рекуррентных нейронных сетях. Данное решение уже строится не только на н-граммах, а и учитывает контекст, что должно дать прирост в качестве работы.
Сложность создания своего решения упирается в сбор данных для обучения и самом процессе обучения. Самый очевидный выход – обучить модель на статьях википедии, потому что мы точно знаем язык и там очень качественные проверенные тексты, которые относительно легко собрать. А для обучения своей модели нужно потратить достаточно много времени, чтобы собрать датасет, его обработать и потом выбрать лучшую архитектуру. Скорее всего кто-то уже сделал это раньше нас. В следующем блоке мы рассмотрим существующие решения.
2. Доступные публичные решения
Compact Language Detector 2
CLD2 – это вероятностная модель на основе машинного обучения (Наивный Баессовский классификатор), которая может определять 83 различных языка для текста в формате UTF-8 или html/xml. Для смешанных языков модель возвращает топ-3 языка, где вероятность расчитывается как приблизительный процент текста от общего числа байт. Если модель не уверена в своем ответе, то возвращает тег «unc».
Точность и полнота данной модели на достаточно хорошем уровне, но главное преимущество – это скорость. Создатели заявляют про 30кб в 1ms, на наших тестах питоновской обертки мы получили от 21 до 26кб в 1ms (70000-85000 сообщений в секунду, средний размер которых 0.8кб, а медиана – 0.3кб).
Данное решение очень простое в использовании. Для начала нужно установить его питоновскую обертку или воспользоваться нашим докером.
Чтобы сделать прогноз, достаточно просто импортировать библиотеку pycld2 и написать одну дополнительную строчку кода:
Определение языка с помощью cld2
import pycld2 as cld2 cld2.detect(«Bonjour, Habr!») # (True, # 14, # ((‘FRENCH’, ‘fr’, 92, 1102.0), # (‘Unknown’, ‘un’, 0, 0.0), # (‘Unknown’, ‘un’, 0, 0.0)))
Ответ детектора – это tuple из трех элементов:
- определился язык или нет;
- к-во символов;
- tuple из трех наиболее вероятных языков, где на первом месте идет полное название,
на втором – сокращение по стандарту ISO 3166 Codes, на третьем – процент символов пренадлежащих данному языку, на четвертом – к-во байт.
FastText
FastText – это библиотека написанная фейсбуком для эффективного обучения и классификации текстов. В рамках данного проекта фейсбук ресерч представил эмбеддинги для 157 языков, которые показывают state-of-the-art результаты на разных задачах, а также модель для определения языка и другие супервайзд задачи.
Для модели определения языка они использовали данные Wikipedia, Tatoeba and SETimes, а в качестве классификатора – свое решение на фасттексте.
Разработчики фейсбук ресерч предоставляют две модели:
- lid.176.bin, которая немного быстрее и точнее второй модели, но весит 128Мб;
- lid.176.ftz – сжатая версия оригинальной модели.
Для использования этих моделей в питоне, сначала нужно установить питоновскую обертку для фасттекста. Могут возникнуть сложности по ее установке, поэтому нужно внимательно придерживаться инструкции на гитхабе или воспользоваться нашим докером. А также необходимо скачать модель по вышеприведенной ссылке. Мы будем использовать оригинальную версию в данной статье.
Классифицировать язык с помощью модели от фейсбука немного сложнее, для этого нам понадобится уже три строки кода:
Определение языка с помощью модели FastText
from pyfasttext import FastText model = FastText(‘../model/lid.176.bin’) model.predict_proba([«Bonjour, Habr!»], 3) #[[(‘fr’, 0.7602248429835308), # (‘en’, 0.05550386696556002), # (‘ca’, 0.04721488914800802)]]
Модель FastText’a позволяет предсказывать вероятность для n-языков, где по дефолту n=1, но в этом примере мы вывели результат для топ-3 языков. Для этой модели это уже общая вероятность предсказания языка для текста, а не к-во символов, которые пренадлежат определенному языку, как было в модели cld2. Скорость работы тоже достаточно высокая – больше 60000 сообщений в секунду.
3. Оценка качества
Оценивать качество работы алгоритмов будем на данных из соц.сетей за случайное время, взятых из системы YouScan (приблизительно 500 тысяч упоминаний), поэтому в выборке будет больше русского и английского языков, 43% и 32% соответственно, украинского, испанского и португальского – около 2% каждого, из остальных языков меньше 1%. За правильный таргет мы будем брать разметку через google translate, так как на данный момент гугл очень хорошо справляется не только с переводом, а и с определением языка текстов. Конечно, его разметка неидеальна, но в большинстве случаев ей можно доверять.
Метриками для оценки качества определения языка будут точность, полнота и f1. Давайте их посчитаем и выведем в таблице:
Сравнение качества двух алгоритмов
with open(«../data/lang_data.txt», «r») as f: text_l, cld2_l, ft_l, g_l = [], [], [], [] s = » for i in f: s += i if ‘ |endn’ in s: text, cld2, ft, g = s.strip().rsplit(» ||| «, 3) text_l.append(text) cld2_l.append(cld2) ft_l.append(ft) g_l.append(g.replace(» |end», «»)) s=» data = pd.DataFrame() def lang_summary(lang, col): prec = (data.loc[data[col] == lang, «google»] == data.loc[data[col] == lang, col]).mean() rec = (data.loc[data[«google»] == lang, «google»] == data.loc[data[«google»] == lang, col]).mean() return round(prec, 3), round(rec, 3), round(2*prec*rec / (prec + rec),3) results = <> for approach in [«cld2», «ft»]: results[approach] = <> for l in data[«google»].value_counts().index[:20]: results[approach][l] = lang_summary(l, approach) res = pd.DataFrame.from_dict(results) res[«cld2_prec»], res[«cld2_rec»], res[«cld2_f1»] = res[«cld2»].apply(lambda x: [x[0], x[1], x[2]]).str res[«ft_prec»], res[«ft_rec»], res[«ft_f1»] = res[«ft»].apply(lambda x: [x[0], x[1], x[2]]).str res.drop(columns=[«cld2», «ft»], inplace=True) arrays = [[‘cld2’, ‘cld2’, ‘cld2’, ‘ft’, ‘ft’, ‘ft’], [‘precision’, ‘recall’, ‘f1_score’, ‘precision’, ‘recall’, ‘f1_score’]] tuples = list(zip(*arrays)) res.columns = pd.MultiIndex.from_tuples(tuples, names=[«approach», «metrics»])
| metrics | prec | rec | f1 | prec | rec | f1 | prec | rec | f1 |
| ar | 0.992 | 0.725 | 0.838 | 0.918 | 0.697 | 0.793 | 0.968 | 0.788 | 0.869 |
| az | 0.95 | 0.752 | 0.839 | 0.888 | 0.547 | 0.677 | 0.914 | 0.787 | 0.845 |
| bg | 0.529 | 0.136 | 0.217 | 0.286 | 0.178 | 0.219 | 0.408 | 0.214 | 0.281 |
| en | 0.949 | 0.844 | 0.894 | 0.885 | 0.869 | 0.877 | 0.912 | 0.925 | 0.918 |
| es | 0.987 | 0.653 | 0.786 | 0.709 | 0.814 | 0.758 | 0.828 | 0.834 | 0.831 |
| fr | 0.991 | 0.713 | 0.829 | 0.53 | 0.803 | 0.638 | 0.713 | 0.81 | 0.758 |
| id | 0.763 | 0.543 | 0.634 | 0.481 | 0.404 | 0.439 | 0.659 | 0.603 | 0.63 |
| it | 0.975 | 0.466 | 0.631 | 0.519 | 0.778 | 0.622 | 0.666 | 0.752 | 0.706 |
| ja | 0.994 | 0.899 | 0.944 | 0.602 | 0.842 | 0.702 | 0.847 | 0.905 | 0.875 |
| ka | 0.962 | 0.995 | 0.979 | 0.959 | 0.905 | 0.931 | 0.958 | 0.995 | 0.976 |
| kk | 0.908 | 0.653 | 0.759 | 0.804 | 0.584 | 0.677 | 0.831 | 0.713 | 0.767 |
| ko | 0.984 | 0.886 | 0.933 | 0.94 | 0.704 | 0.805 | 0.966 | 0.91 | 0.937 |
| ms | 0.801 | 0.578 | 0.672 | 0.369 | 0.101 | 0.159 | 0.73 | 0.586 | 0.65 |
| pt | 0.968 | 0.753 | 0.847 | 0.805 | 0.771 | 0.788 | 0.867 | 0.864 | 0.865 |
| ru | 0.987 | 0.809 | 0.889 | 0.936 | 0.933 | 0.935 | 0.953 | 0.948 | 0.95 |
| sr | 0.093 | 0.114 | 0.103 | 0.174 | 0.103 | 0.13 | 0.106 | 0.16 | 0.128 |
| th | 0.989 | 0.986 | 0.987 | 0.973 | 0.927 | 0.95 | 0.979 | 0.986 | 0.983 |
| tr | 0.961 | 0.639 | 0.768 | 0.607 | 0.73 | 0.663 | 0.769 | 0.764 | 0.767 |
| uk | 0.949 | 0.671 | 0.786 | 0.615 | 0.733 | 0.669 | 0.774 | 0.777 | 0.775 |
| uz | 0.666 | 0.512 | 0.579 | 0.77 | 0.169 | 0.278 | 0.655 | 0.541 | 0.592 |
По результатам хорошо видно, что у подхода cld2 очень высокая точность определения языка, только для непопулярных языков она падает ниже 90%, и в 90% случаев результат лучше, чем у fasttext’a. При примерно одинаковой полноте для двух подходов, f1 скор больше у cld2.
Особенность cld2 модели в том, что она выдает прогноз только для тех сообщений, где она достаточно уверена, это объясняет высокую точность. Модель fasttext’a выдает ответ для большинства сообщений, поэтому точность существенно ниже, но странно, что полнота не существенно выше, а в половине случаев – ниже. Но если «подкрутить» порог для модели fasttext’a, то можно улучшить точность.
4. Выводы
В целом, обе модели дают хороший результат и могут быть использованы для решения задачи определения языка в разных доменах. Главное их преимущество – высокая скорость, которая дает возможность сделать так называемый «ансамбль» и добавить необходимый препроцессинг для повышения качества.
Весь код для воспроизведения экспериментов и тестирований вышеприведенных подходов вы можете найти в нашем репозитории.
Также можете посмотреть тестирование этих решений в другой статье, где сравнивается точность и скорость на 6 западноевропейских языках.
Источник: habr.com
LiveInternetLiveInternet
 Я — фотографПлагин для публикации фотографий в дневнике пользователя. Минимальные системные требования: Internet Explorer 6, Fire Fox 1.5, Opera 9.5, Safari 3.1.1 со включенным JavaScript. Возможно это будет рабо
Я — фотографПлагин для публикации фотографий в дневнике пользователя. Минимальные системные требования: Internet Explorer 6, Fire Fox 1.5, Opera 9.5, Safari 3.1.1 со включенным JavaScript. Возможно это будет рабо Всегда под рукойаналогов нет ^_^ Позволяет вставить в профиль панель с произвольным Html-кодом. Можно разместить там банеры, счетчики и прочее
Всегда под рукойаналогов нет ^_^ Позволяет вставить в профиль панель с произвольным Html-кодом. Можно разместить там банеры, счетчики и прочее Индикатор места в рейтинге Яндексвот:)
Индикатор места в рейтинге Яндексвот:) Календарь биоритмовЭтот бесплатный калькулятор биоритмов Вы можете разместить у себя в блоге или на своей домашней странице. Это позволит Вам или вашим друзьям не терять время в Сети в поисках программы биоритмов, а сра
Календарь биоритмовЭтот бесплатный калькулятор биоритмов Вы можете разместить у себя в блоге или на своей домашней странице. Это позволит Вам или вашим друзьям не терять время в Сети в поисках программы биоритмов, а сра Каталог блоговКаталог блогов позволяет упорядочить блоги людей и сообществ по категориям, позволяя быстрее находить нужные и интересные блоги среди огромного количества блогов на сайте li.ru
Каталог блоговКаталог блогов позволяет упорядочить блоги людей и сообществ по категориям, позволяя быстрее находить нужные и интересные блоги среди огромного количества блогов на сайте li.ru
Источник: www.liveinternet.ru