
Разработчик jing chen указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Данные, используемые для отслеживания информации
- Идентификаторы
Не связанные с пользователем данные
Может вестись сбор следующих данных, которые не связаны с личностью пользователя:
- Идентификаторы
- Данные об использовании
- Диагностика
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Информация
Провайдер jing chen
Размер 16,8 МБ
Совместимость iPhone Требуется iOS 12.2 или новее. iPad Требуется iPadOS 12.2 или новее. iPod touch Требуется iOS 12.2 или новее. Mac Требуется macOS 11.0 или новее и компьютер Mac с чипом Apple M1 или новее.
русский, английский, голландский, греческий, датский, испанский, итальянский, корейский, немецкий, польский, португальский, традиционный китайский, турецкий, упрощенный китайский, финский, французский, шведский, японский
Распознавание текста с изображения на Python | EasyOCR vs Tesseract | Компьютерное зрение
Источник: apps.apple.com
Извлекаем текст из изображений в Windows 11 и Windows 10
Сталкивались ли вы с ситуацией, когда при просмотре презентации на YouTube вам необходим был текст из слайд-шоу призентации? Или, скажем, у вас есть отсканированный PDF-файл малоизвестной книги и вы хотели бы извлечь текст из определенной главы. Что ж, в такой ситуации вы скорее всего полагались на функции Google Lens или Live Text от Apple, однако инструмент PowerToys Text Extractor для Windows 10 и Windows 11 значительно упростит решение данной задачи.
С помощью комбинации клавиш вы сможете быстро извлекать текст из изображений. Снимок экрана, снимок фото или видео, PDF файл и вообще текст с любого изображения вы сможете легко извлечь. Итак, чтобы узнать, как легко извлечь текст из изображений в Windows 10 или Windows 11, следуйте нашему руководству, описанному ниже.
Захват текста из изображений в Windows 10/11
Функция Text Extractor была добавлена в PowerToys в сентябре, поэтому вам понадобится обновленная версия программы (v0.62.0 или более новая). Самое приятное в PowerToys Text Extractor заключается в том, что вам не нужно активное подключение к Интернету для извлечения текста. Функция выполняет обработку локально и при этом довольно быстро. С учетом сказанного давайте перейдем к инструкции и узнаем, как извлечь текст из изображений в Windows 10/11.
- Во-первых, вам необходимо установить бесплатную программу Microsoft PowerToys. Скачать программу можно из магазина Microsoft Store или с официального репозитория GitHub. Доступные источники для скачивания программы доступны на нашей странице Microsoft PowerToys.

Учим программу распознавать текст на картинках, видео, играх ▲ Python + OpenCV + Tesseract
- После установки программы откройте ее, запустив от имени Администратора, и перейдите в раздел «Text Extractor» в левой боковой панели. Убедитесь, что на правой панели включена опция «Включить Text Extractor». Как показано на снимке экрана, для извлечения текста из изображений вам нужно воспользоваться комбинацией клавиш Windows + Shift + T. Вы можете нажать на значок «ручка» рядом с «ярлыком активации», чтобы добавить свою комбинацию клавиш для активации функции извлечения текста.

- Теперь откройте изображение, из которого вы хотите извлечь текст. Воспользуйтесь комбинацией клавиш Win + Shift + T и выберите область изображения, из которой вы хотите извлечь текст.

- Инструмент извлечения текста автоматически захватит текст и скопирует его в буфер обмена. Далее откройте Блокнот или ваш любимый текстовый редактор и вставьте текст, нажав комбинацию клавш Ctrl + V . Текст из изображения будет скопирован в текстовый файл практически с идеальной точностью.

Сообщают, что неразборчивый текст из изображений старых книг также хорошо извлекается инструментом PowerToys Text Extractor.
- Если вы ищете альтернативу PowerToys Text Extractor, то вам стоит попробовать приложение Text Grab ( программа доступна бесплатно на GitHub, и стоит 9.99$ в магазине Microsoft Store), которая работает на Microsoft Windows.Media.Ocr API и обладает расширенными функциями.
Обработка OCR выполняется довольно быстро, и мы удивлены результатами. Даже без подключения к Интернету инструмент может локально захватывать текст из изображений с впечатляющей точностью.
Источник: www.comss.ru
Распознавание текста в Linux (OCR)
Для Linux имеются разнообразные инструменты командной строки и с графическим интерфейсом для преобразования изображений в текст. В этой статье будут рассмотрены программы, с помощью которых вы можете после сканирования страниц книги или документов перевести их в текстовый формат.
OCR программы в Linux с графическим интерфейсом
OCRFeeder
OCRFeeder — это система анализа макета документов и оптического распознавания символов.
Откройте в этой программе изображения и она автоматически определит контуры областей, в которых находятся изображения и текст и выполнит OCR (распознавание текста) этого документа. Программа может сохранять полученные результаты в разные форматы, главным из них является ODT.
Программа имеет законченный GTK+ графический пользовательский интерфейс, который позволяет пользователям корректировать любые нераспознанные символы, определять или корректировать границы областей текста, устанавливать стили параграфов, очищать введённые изображения, импортировать PDF, сохранять и загружать проект, экспортировать всё в несколько форматов и так далее.
В общем, это программа по функциям схожая с Abbyy FineReader, в некотором смысле, можно сказать, что OCRFeeder это аналог Abbyy FineReader для Linux, по крайней мере, в его базовой функциональности.
В своей работе OCRFeeder использует сторонние движки оптического распознавания символов, например, по умолчанию она использует Tesseract. Для установки нужно установить и графический интерфейс OCRFeeder и Tesseract. В Debian и производных Tesseract устанавливается в качестве зависимости, поэтому необязательно указывать этот пакет явно. Но при этом помните, что вместе с Tesseract устанавливается по умолчанию только распознавание английского языка, для дополнительной поддержки русского, нужно явно указать этот пакет. Про распознавание других языков, а также про работу с Tesseract будет рассказано в этой же статье далее.
Установка OCRFeeder в Ubuntu, Linux Mint, Debian, Kali Linux и их производные:
sudo apt install ocrfeeder tesseract-ocr-rus
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
sudo pacman -S ocrfeeder tesseract-data-eng tesseract-data-rus
Как пользоваться OCRFeeder
Для запуска программы найдите её в меню (скорее всего, в разделе Офис):

Или в командной строке выполните команду:
ocrfeeder
Внешний вид программы:

Для анализа у меня есть тестовое изображение:

Загрузим его в программу (для этого нажмите знак плюс +). Вам необязательно добавлять изображения по одному — можно добавлять целыми папками или импортировать PDF документ.
Для распознавания в меню Документ выберем «Распознать документ» (будут распознаны все страницы, которые загружены в программу), либо «Распознать страницу» (будет распознана страница, которая выделена в данный момент).
В правом нижнем углу появляются результаты распознавания текста:
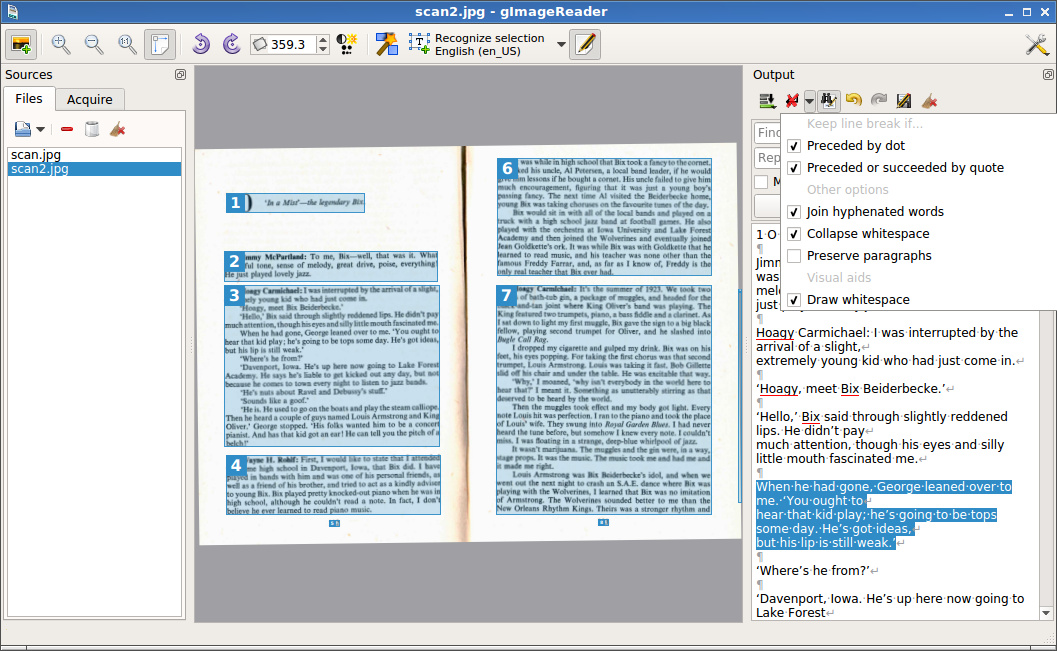
С моим тестовым файлом, результаты неудовлетворительные, поскольку программа неудачно выбрала области для распознавания. Это исправить легко, просто выбираем новую область и выбираем «Распознать выделенную область»:
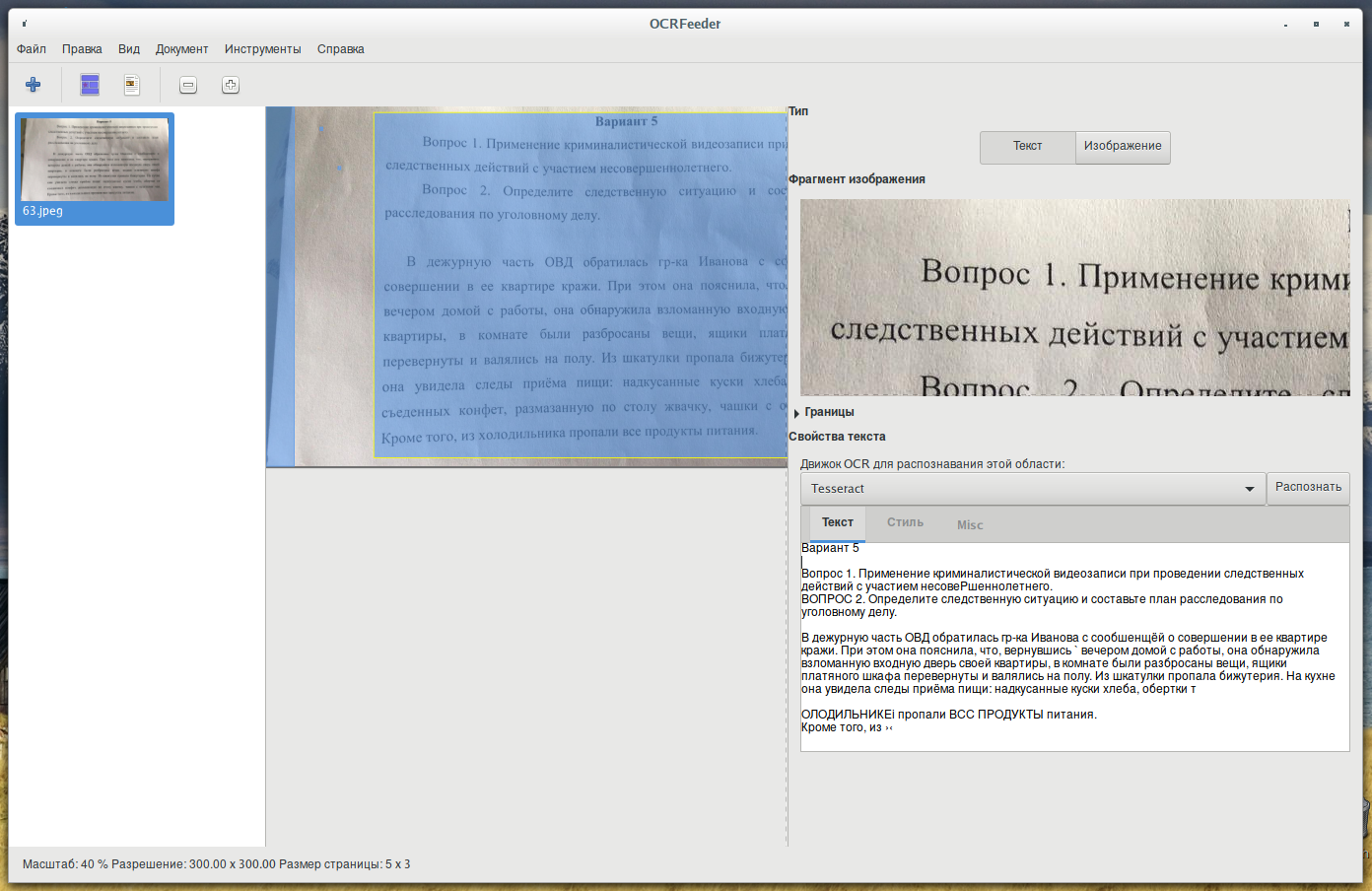
Как видим, результаты не идеальные, но вполне удовлетворительные — после небольшой ручной корректировки, этот текст пригоден для использования.
Как обычно с системами OCR — чем лучше качество исходного текста (имеют значение ровность, размер, контрастность и другое), тем лучше получается результат (хотя в любом случае требуется вычитка и корректировка полученного при распознавании текста):
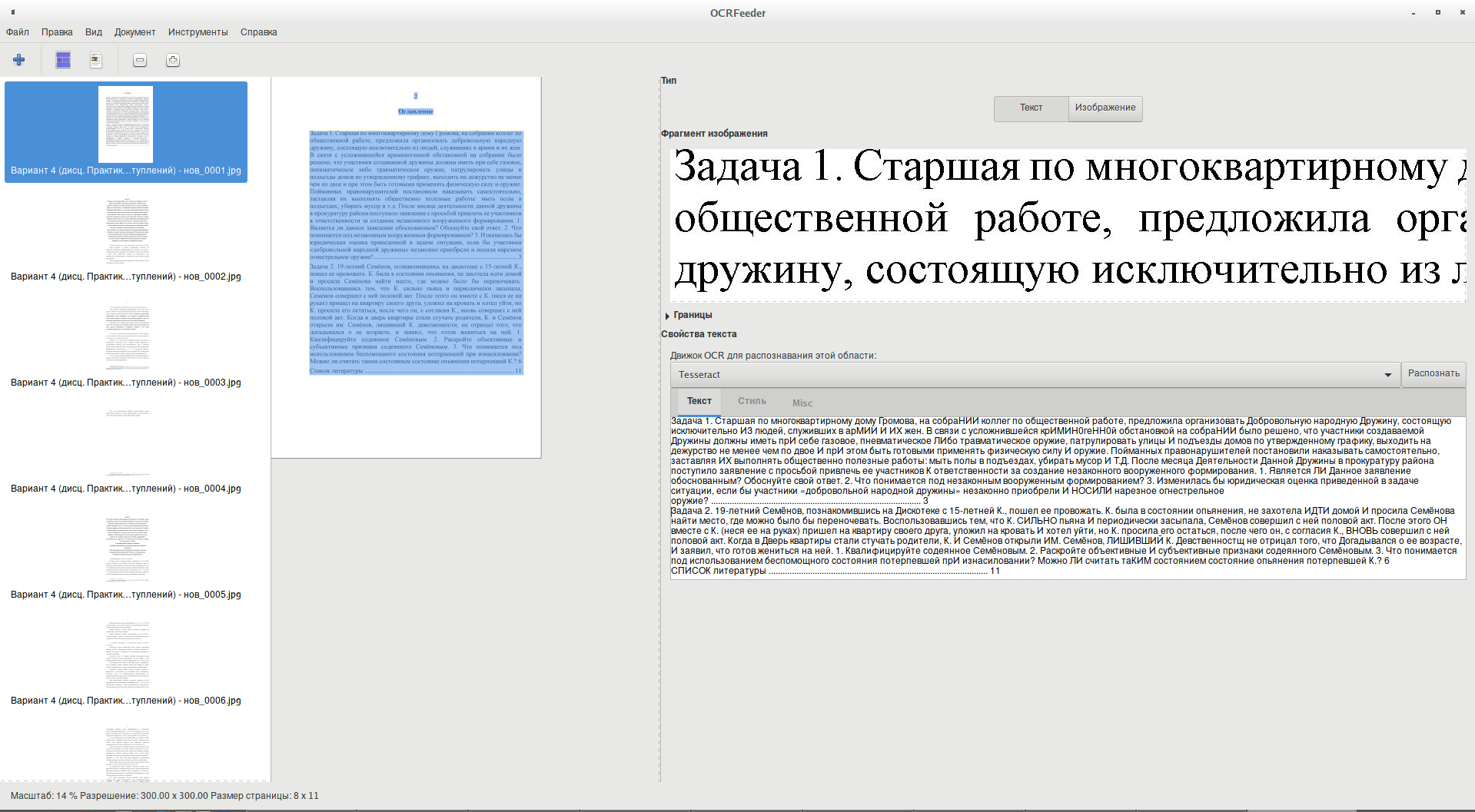
По умолчанию языком для распознавания установлен тот же язык, что имеет ваша система, то есть, скорее всего, русский язык. Вы можете изменить язык в Меню → Настройки → Распознавание → Default language. Если вы выбрали неверный язык, то движок оптического распознавания символов вернёт плохие результаты. Если вы выбрали язык, который не поддерживается движком, то он может вернуть пустую страницу.
Вы можете экспортировать для распознавания PDF документы. А полученные результаты сохранять в различных форматах:
Также вы можете сохранить весь проект целиком в собственном формате программы.
Если вы запускаете OCRFeeder из командной строки, то вы можете использовать несколько опций для ускорения процесса добавления изображений.
ocrfeeder [опции]
—version показать версию программы и выйти -h, —help показать справку и выйти -i ИЗОБРАЖЕНИЕ1 [ИЗОБРАЖЕНИЕ2, . ], —images=ИЗОБРАЖЕНИЕ1 [ИЗОБРАЖЕНИЕ2, . ] изображения, которые будут автоматически добавлены при запуске программы. Используйте эту опцию перед каждым изображением для добавления. -d ДИРЕКТОРИЯ, —dir=ДИРЕКТОРИЯ директория с изображениями, которая будет добавлена автоматически при запуске программы.
gImageReader
gImageReader — это графический GTK+ интерфейс для tesseract-ocr.
Tesseract — пожалуй, самое точное программное обеспечение с открытым исходным кодом для оптического распознавания символов (OCR) и может распознавать текст на более чем 60 языках.
gImageReader поддерживает автоматическое определение макета страницы, но пользователь также может вручную задать и отредактировать области распознавания. Есть возможность импортировать изображения с диска, устройств сканирования, буфера обмена и скриншотов. gImageReader также поддерживает многостраничные документы PDF. Распознанный текст отображается непосредственно рядом с изображением и базовое редактирование текста включает поиск/замену и удаление сломанных строк если это возможно. Также поддерживается проверка орфографии для выводимого текста если установлены соответствующие словари.
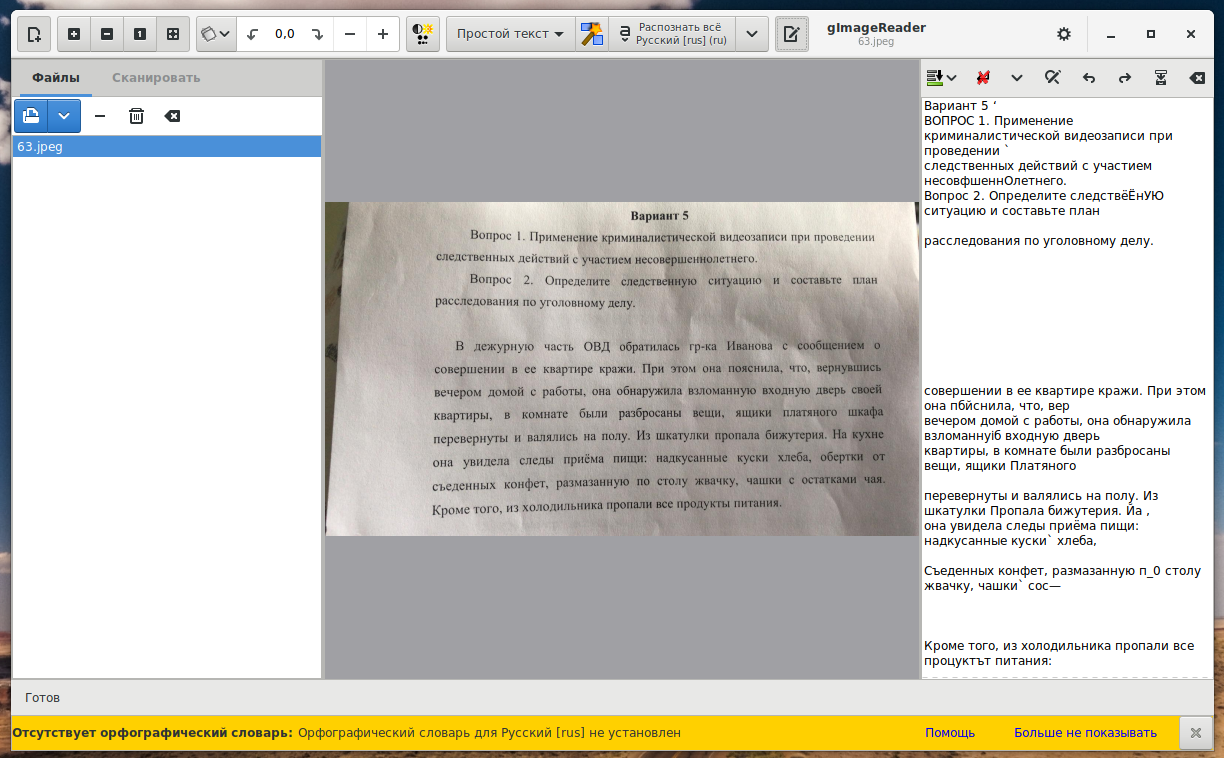
- Импорт PDF документов и изображений с диска, сканирующих устройств, буфера обмена и скриншотов
- Обработка нескольких изображений и документов за один проход
- Ручное или автоматическое определение области распознавания
- Распознавание в простой текст или в документ hOCR
- Распознанный текст отображается рядом с исходным изображением
- Последующая обработка текста, включая проверку орфографии
- Геренирование PDF документов из hOCR документов
Установка OCRFeeder в Ubuntu, Linux Mint, Debian, Kali Linux и их производные:
sudo apt install gimagereader
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
git clone https://aur.archlinux.org/gtkspellmm.git cd gtkspellmm makepkg -si cd .. git clone https://aur.archlinux.org/gimagereader.git cd gimagereader makepkg -si
ocrgui
ocrgui — это графический интерфейс для OCR программ (Tesseract, GOCR). Программа давно не обновлялась и может отсутствовать в стандартных репозиториях.
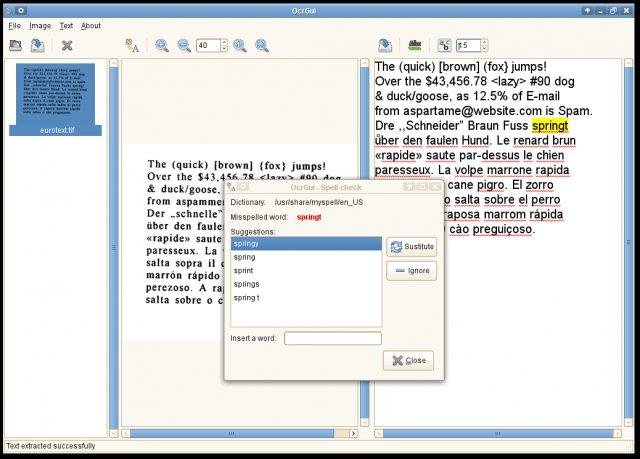
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
git clone https://aur.archlinux.org/ocrgui.git cd ocrgui makepkg -si
screentranslator
Это экранный переводчик, программа захватывает область экрана, распознаёт текст и выполняет его перевод. Если вам не нужен перевод, то его можно отключить.
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
git clone https://aur.archlinux.org/screentranslator.git cd screentranslator makepkg -si
В настройках укажите путь к tesseract: /usr/bin/tesseract
Утилиты командной строки для OCR
Далее будут рассмотрены движки оптического распознавания символов, которые имеют интерфейс командной строки. Эта информация может пригодиться продвинутым пользователям, привыкшим иметь дело с консолью, а также пользователям OCRFeeder, поскольку эта программа умеет работать с каждым из рассмотренных ниже OCR инструментов, и знание их особенностей и различий помогут вам правильно выбрать используемый движок OCR:

Tesseract
Tesseract — это движок оптического распознавания символов (OCR) с открытым исходным кодом. Его можно использовать напрямую, с помощью API для извлечения печатного текста из изображений, а также программы с графическим интерфейсом, такие как OCRFeeder, могут использовать Tesseract. Этот движок поддерживает большое количество языков. Пакет включает в себя утилиту командной строки.
tesseract —help | —help-psm | —help-oem | —version tesseract —list-langs [—tessdata-dir ПУТЬ] tesseract —print-parameters [опции. ] [конфигурационный файл. ] tesseract имя_изображения|stdin вывод|stdout [опции. ] [конфигурационный файл. ]
—tessdata-dir ПУТЬ Указать путь расположения tessdata. —user-words ПУТЬ Указать расположение пользовательского файла со словами. —user-patterns ПУТЬ Указать расположение пользовательского файла с образцами. -l ЯЗЫК[+ЯЗЫК] Указать язык(и), используемые для OCR. -c ПЕРЕМЕННАЯ=ЗНАЧЕНИЕ Установить значения конфигурационных переменных.
Разрешено использовать аргумент -c несколько раз. —psm ЧИСЛО Указать режим сегментации страницы. —oem ЧИСЛО Указать режим движка OCR. ПРИМЕЧАНИЕ: Эти опции должны идти перед любым конфигурационным файлом. Режимы сегментации страницы: 0 Только ориентация и обнаружение скриптом (OSD). 1 Автоматическая сегментация страницы с OSD. 2 Автоматическая сегментация страницы но без OSD или OCR.
3 Полностью автоматическая сегментация страницы, но без OSD. (По умолчанию) 4 Предполагается единичная колонка текста переменной длины. 5 Предполагается единый унифицированный блок вертикально выравненного текста. 6 Предполагается единый унифицированный блок текста. 7 Обрабатывать изображение как единичную текстовую строку. 8 Обрабатывать изображение как единичное слово.
9 Обрабатывать изображение как единичное слово в круге. 10 Обрабатывать изображение как единичный символ. 11 Разреженный текст. Найти столько текста, сколько возможно без особого порядка. 12 Разреженный текст с OSD. 13 Сырая строка. Обрабатывать изображение как единичную текстовую строку, обход специфичных для Tesseract хаков. Режимы движка OCR: 0 Только оригинальный Tesseract.
1 Только Cube. 2 Tesseract + cube. 3 По умолчанию, основан на том, что доступно. Единичные опции: -h, —help Показать справку. —help-psm Показать режимы сегментации страницы. —help-oem Показать режимы движка OCR. -v, —version Показать информацию о версии. —list-langs Вывести список доступных языков для движка tesseract. —print-parameters Напечатать параметры tesseract в stdout (стандартный вывод).
Обратите внимание на опцию -l, после которой нужно указать используемый язык. Если он не указан, то подразумевается английский. Можно указать несколько языков, разделённых знаком плюс. Tesseract использует 3-символьные коды языков ISO 639-2.
Доступны следующие языки:
Ocrad
GNU Ocrad это OCR (Optical Character Recognition — оптическое распознавание символов) программа, основывающаяся на методе извлечения признаков. Она считывает битовую карту изображения в формате pgm/pbm и выдаёт текств в байтовом (8-бит) или UTF-8 форматах.
Ocrad включает анализатор разметки, способный разделять столбцы или блоки текста, какие обычно бывают на печатных страницах.
Для лучшего результата символы должны быть по крайней мере 20 пикселей в высоту. Если они меньше, попробуйте опцию —scale. Сканированные изображения на 300 dpi обычно дают размер символов достаточно хорошего размера для ocrad.
Слитые, очень смелые или очень светлые (сломанные) символы обычно не распознаются правильно. Старайтесь избегать их.
ocrad [опции] [файлы]
-h, —help показать справку и выйти -V, —version вывести информацию о версии и выйти -a, —append добавить текст к файлу вывода -c, —charset= попробуйте ‘—charset=help’ для получения списка имён -e, —filter= попробуйте ‘—filter=help’ для получения списка имён -E, —user-filter= определённый пользователем фильтр, смотрите мануал для получения форматов -f, —force принудительно переписать файл вывода -F, —format= формат вывода (byte, utf8) -i, —invert инвертировать уравни изображения (белый на чёрном) -l, —layout выполнить анализ макета -o, —output= поместить вывод в -q, —quiet подавить все сообщения -s, —scale=[-] масштабировать входное изображение на [1/] -t, —transform= попробуйте ‘—transform=help’ для получения списка имён -T, —threshold= порог для бинаризации (0-100%) -u, —cut= обрезать входное изображение по заданному прямоугольнику -v, —verbose быть вербальной -x, —export= экспортировать результаты в формат ORF в
Если файлы не указаны, то ocrad считывает изображения из стандартного ввода. Если опция -o не указана, ocrad отправляет текст в стандартный вывод.
Статусы выхода: 0 для нормального выхода, 1 при проблемах в среде (файл не найден, неверные флаги, ошибки ввода/вывода и т.д.), 2 говорит о повреждённом или неверном файле ввода, 3 для ошибки внутренней консистенции (например, баг), которая вызвала панику в ocrad.
gocr
gocr — это мультиплатформенная программа распознавания текстов (OCR). Она принимает файлы изображений pnm, pbm, pgm, ppm, some pcx и tga. В настоящее время программа должна быть способна хорошо работать со сканами, в которых есть текст в один столбец и нет таблиц. Поддерживается размер шрифта от 20 до 60 пикселей.
gocr [options] pnm_file_name # use — for stdin
Опции (больше подробностей в мануале man gocr):
-h, —help -i имя — файл с изображением ввода (pnm,pgm,pbm,ppm,pcx. ) -o имя — файл вывода (перенаправление stdout) -e имя — файл журналирования (перенаправление stderr) -x имя — перенаправление прогресса в fifo (смотрите мануал) -p имя — путь базы данных включает конечный слэш (по умолчанию это ./db/) -f формат — формат вывода (ISO8859_1 TeX HTML XML UTF8 ASCII) -l число — пороговый уровень серого 0
Провести анализ разметки:
gocr -m 4 text1.pbm
Расширенная база данных:
gocr -m 130 -p ./database/ text1.pbm
Использовать файл jpeg переданный по трубе:
djpeg -pnm -gray text.jpg | gocr
Cuneiform
Cuneiform — это многоязычная система OCR (распознавания текста). В дополнении к распознаванию текста, она также анализирует разметку и распознаёт формат текста.
Поддерживаются следующие языки: болгарский, хорватский, чешский, датский, голландский, английский, эстонский, французский, немецкий, венгерский, итальянский, латышский, литовский, польский, португальский, румынский, русский, сербский, словенский, испанский, шведский, турецкий и украинский.
cuneiform [-l имя_языка -f формат —dotmatrix —fax —singlecolumn -o result_file] imagefile
—dotmatrix
Режим распознавания оптимизирован для текстов, напечатанных на принтерах с точечной матрицей
—fax
Использовать режим распознавания, оптимизированный для текстов, переданных по факсу.
—singlecolumn
Отключить анализ разметки страницы и исходить из того, что изображение состоит из одной колонки текста.
-f формат
Выбрать формат вывода. Доступны следующие форматы:
- html (HTML формат),
- hocr (hOCR HTML формат),
- native (родной формат Cuneiform 2000),
- rtf (RTF формат),
- smarttext (простой текст с TeX параграфами),
- text (простой текст).
По умолчанию это plain text.
-l язык
По умолчанию Cuneiform распознаёт английский текст. Для изменения языка используйте переключатель командной строки, после -l после которого следует код языка (обычно трёхбуквенный код ISO 639-2).
Поддерживаются следующие языки:
bul Болгарский cze Чешский dan Датский dut Голландский eng Английский est Эстонский fra Французский ger Немецкий hrv Хорватский hun Венгерский ita Итальянский lav латышский lit Литовский pol Польский por Португальский rum Румынский rus Русский ruseng смешанный Русский/Английский slv Словенский spa Испанский srp Сербский swe Шведский tur Турецкий ukr Украинский
-o вывод
Если вы не указали файл вывода с переключателем -o, то Cuneiform запишет результаты в файл ‘cuneiform-out.format’. Расширение файла зависит от вашего формата вывода.
Форматы ввода
Cuneiform может обрабатывать любые изображения с единичной страницой, которые GraphicsMagick знает как открывать. Посмотрите мануала gm(1) для полного списка поддерживаемых форматов изображений.
ocropy
ocropy — это написанный на Python OCR пакет, использующий рекуррентные нейронные сети (ранее назывался OCRopus).
ocropy — это коллекция программ для анализа документов, это не простая OCR система, которая распознаёт тексты в графическом интерфейсе или с запуском одной команды. Функции ocropy разбиты на отдельные модули и, например, для простого распознавания текста может потребоваться ввести несколько команд для подготовки документа.
В дополнении к самим скриптам распознавания, имеется ряд скриптов для базового редактирования и коррекции, измерению процента ошибок, определению матриц путаницы и т. п.
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
git clone https://aur.archlinux.org/ocropy.git cd ocropy makepkg -si
Источник: zalinux.ru