
Довольно часто попадаются хорошие подкасты или аудиотрансляции с семинаров и конференций, однако интересная тема и интригующая манера подачи материала сводятся на нет невысоким качеством самой записи. Это может быть, как низкий уровень звука, так и сильные перепады громкости на разных отрывках. Они сильно портят впечатление и заставляют слушателя интенсивно мучать кнопки «громче-тише».
Отдельную проблему представляет фоновый шум, а также резкие вопли-кашли-чихания. Впрочем, все эти и многие другие недостатки можно устранить с помощью бесплатной программы Audacity. В данной статье я расскажу об обязательной минимальной обработке записи голоса или собственного подкаста, позволяющей сделать прослушивание комфортным.
Звуковой редактор Audacity бесплатен и имеет русский язык, он скачивается с официального сайта. Инсталляция не вызывает никаких проблем – опции при установке менять не требуется. Однако после инсталляции необходимо доустановить пару модулей, чтобы программа понимала различные аудиоформаты, а также самостоятельно могла экспортировать звук в mp3. Дело в том, что автор не стал связываться с юридической стороной вопроса легальности использования закрытых форматов и переложил эти проблемы на пользователя.
Как сделать качественный и приятный звук в audacity?

Настройка библиотек в Audacity. Сначала скачиваем, потом распаковываем, далее указываем.
Заходим в Правка-Параметры-Библиотеки. Здесь требуется установить библиотеки LAME и FFmpeg. Нажимаем на кнопку Скачать и в браузере откроется ссылка на нужную библиотеку – соответственно «LAME download page» и «Go to the external download page». После скачивания распаковываем содержимое архивов в папку с программой и указываем файл кнопкой Указать.
Теперь редактор полностью готов к работе. Открываем нужную аудиозапись.
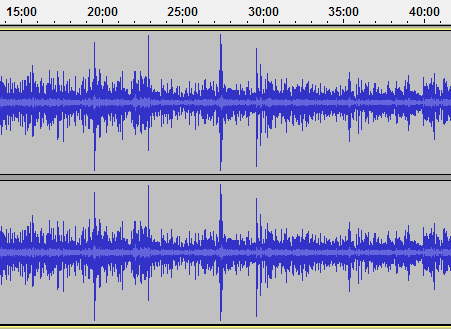
Необработанная аудиозапись в Audacity видна невооруженным глазом. Сильно выделяются пики, а общий уровень сигнала низкий.
В качественной записи общий уровень звука должен быть примерно одинаков, без резких скачков и всплесков. Зашкаливающие пики, мало того, что неприятно отдают в наушниках и колонках, так еще и будут мешать программе Audacity определить максимальный уровень сигнала. Удаляем всплески первым делом.
Удаление скачков и пиков
Заходим в Эффекты-Limiter (или Hard Limiter в зависимости от версии Audacity и плагина). На изображении показаны рекомендуемые параметры. Единственное, с чем стоить поиграться – Limit to (dB) – собственно он и указывает выше какого уровня пик будет срезаться. Конкретное значение дать затруднительно, многое зависит от характера звука, но я рекомендую от -2 до -6 dB.
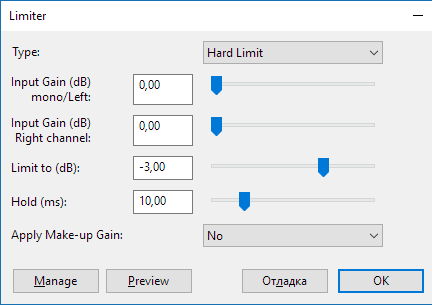
Как обработать голос в Audacity
Настройка плагина Limiter (Hard Limiter) в Audacity.
Главный параметр — Limit to (Db)
Сделайте несколько попыток. Контролируйте визуально, чтобы после применения фильтра срезались только скачки. Если упал уровень основной части, значит вы перестарались со значением Limit to (dB). В настройках есть кнопка Preview, позволяющая сразу прослушать обработанный фрагмент.

После обработки фильтром Hard Limiter в Audacity. Все пики срезаны, их остатки не превышают средний уровень.
Нормализация
Заходим в Эффекты-Нормировка сигнала (Normalize). Данный плагин поднимает (или снижает) общий уровень всей записи сразу. Тихий сигнал станет громче, а громкий еще громче.

Настройка нормализации в Audacity. Минус один Децибел обычно дает хороший результат.
Если вы видите, что голос получился тихим по всей длине, то ему явно требуется нормализация. Параметр Normalize maximum amplitude to указывает уровень под который будет выполняться подгонка. Рекомендую -1 dB.
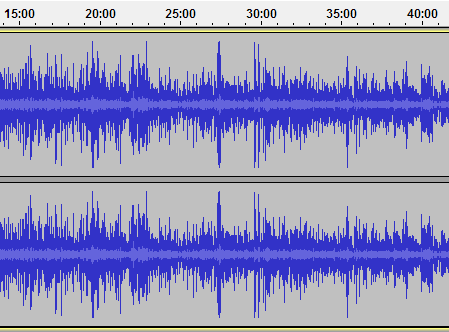
После применения нормализации. Обратите внимание, как вырос уровень, хотя характер сигнала почти не изменился.
Компрессор
Следующий плагин – Компрессор, – он один из самых важных. При этом виде обработки слабые и тихие звуки делаются громче, а слишком громкие – тише. То есть после проведения компрессии шепот и громкий вопль будут почти одинаковы по уровню, не придется крутить слайдер громкости. После окончания работы плагина вы визуально должны увидеть выравнивание сигнала.
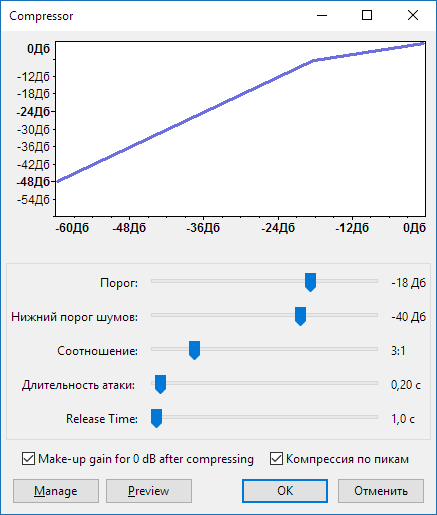
Настройка фильтра Компрессор в Audacity
Результат действия компрессора может сильно отличаться в каждом конкретном случае. Он может снизить или поднять общую громкость или же привести к появлению пиков (если не установлена галочка Компрессия по пикам в настройках плагина). Поэтому, если требуется, можно повторно применить Limiter или Нормализатор.

Посмотрите, как Компрессор изменил форму записи. Теперь и писк комара, и рев турбины имеют почти одинаковый уровень. Слушать такой аудиофайл комфортно.
Удаление шума
В этом разделе речь пойдет о негромком монотонном и непрерывном шуме, сопровождающем всю запись. Это может быть шелест вентилятора ноутбука или гул кондиционера, работающего неподалеку. Для чистки звука нам понадобится небольшой (3-10 сек) участок только с этим шумом (без голоса).

Удаление шума в Audacity
Программа проанализирует полученные характеристики, составит модель шумодава и попробует безболезненно изъять составляющие шума из общего спектра. Выделяем небольшой участок с шумом (и только с ним), далее запускаем плагин Эффекты-Подавление шума. Нажимаем Создать модель шума. Теперь можно применить фильтр на всей записи.
Снимаем выделение (или выделяем весь файл целиком) и повторно запускаем плагин, но на этот раз выполняем саму чистку, нажав ОК. Дать конкретные рекомендации сложно. Сделайте несколько попыток с разными параметрами.
Ползунок Подавление шума указывает насколько сильно снижать шум, а Sensivity указывает чувствительность – чем она выше, там сильнее может пострадать голос после чистки. Важно понимать, что предыдущий фильтр Компрессор поднимает слабые звуки, в том числе и шум. Поэтому запускать шумодав нужно перед компрессором.
Удаление вздохов, кашля и др
К сожалению фильтров, которые могли бы автоматически сделать удаление этих звуков нет (имеется в виду — без значительной потери качества основного сигнала), – это кропотливая ручная работа. Нужные участки выделяются курсором и либо заменяются тишиной (Создание–Создать тишину), либо вырезаются (кнопкой Del). В особых случаях, когда удаляемый участок звучит на фоне речи, его можно заглушить. Проблемные звуки все еще будут слышны, но они не будут привлекать внимание и портить речь.
Эквалайзер.
Даже если с уровнем сингала у вас все в порядке, голос говорящего может не понравится. Например, слишком басовитый или слишком писклявый. Иногда это результат применения некачественного или ненастроенного микрофона, и исправляется эквалайзером (Эффекты – Эквалайзер). Не буду особенно вдаваться в настройки – это потребует отдельной статьи, скажу лишь, что на диаграмме кривыми показаны занижаемые или поднимаемые частоты.
Для простоты можете пользоваться пресетами, многие из которых полезны – Bass boost (усиление басов), Bass cut (удаление басов), Treble boost (усление высоких), Treble cut (удаление высоких), 100Hz Rumble (удаление самых низких составляющих баса – особенно хорошо подходит для живых выступлений, где микрофон дает слишком много басов при выдохе). Крутизна кривой показывает насколько сильно будет подниматься/опускаться определенная частота. По аналогии с предыдущими плагинами можно сразу прослушать результат обработки и что-то подстроить.
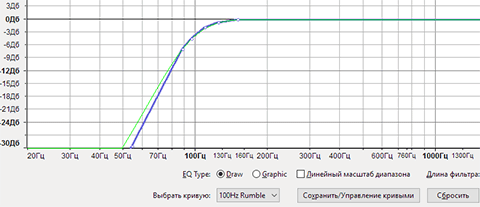
Эквалайзер в Audacity.
В данном примере срезаются частоты ниже 100 Гц
Сохранение полученного результата. Выполняется командой Экспорт аудио (пункт Экспорт выделенного аудио сохраняет только выделенный фрагмент). Далее выбираем формат – я использую MP3 и OGG. Последний хоть и имеет лучшее качество, но все же менее распространен, и может не воспроизводится старыми плеерами и бытовой техникой.
Для MP3 задается битрейт, чем он больше, тем лучше качество, но тем больше размер файла. Рекомендую использовать битрейт 192-320 kbps для стерео и в два раза меньший — для монофонической записи. Для OGG качество задается в условных единицах от 0 до 10.
В конце скажу, что статья дает лишь начальные знания по обработке звука, но даже проведя минимальную обработку и потратив всего лишь 20 минут, можно добиться существенного улучшения итогового качества звучания, приемлемого для прослушивания большой аудиторией. Через некоторое время, набрав опыта, вы будете без проблем выставлять нужные параметры плагинов на глаз.
Обычно при записи подкастов с участием одних и тех же голосов список фильтров почти не меняется. Можно воспользоваться встроенным руководством и детально изучить требуемые плагины, доведя обработку своего аудио до совершенства.
Источник: pc-hard.ru
Редактирование голоса. Тюнинг вокала. Автотюн. Elastic audio.

Редактирование голоса, тюнинг интонирования — это то, что позволило в начале 2000х вылезти на сцену сотням не умеющих петь исполнителей. Цифровые технологии и Фурье-преобразования позволяют разложить одноголосную мелодию в набор нот. И конечно же, смотреть и изменять высоту этих нот. Причем, речь не только о вокале, но и о любом другом инструменте.
Лишь бы одновременно звучала только одна нота. Все духовые и струнные тоже отлично тюнятся! Сказочные возможности для любого музыканта, не правда ли?:)
Когда после перестройки нашу эстраду захлестнула волна фонограмм, у продюсеров еще все-таки оставалась головная боль — из артиста хотя бы один раз нужно было выжать хорошее исполнение, записать его в студии. А если артист мажет мимо нот или плохо соображает — одну песню можно записывать более двух дней! При этом и артист устает, психует, не понимает, что еще от него хотят. И звукорежиссер не рад такой работе. Получается достаточно дорогое производство фонограммы…
Но дальнейшее развитие компьютеров полностью решило часть проблемы. Теперь, если у артиста хорошая внешность иили приятный тембр голоса — уметь петь ему совсем не обязательно. Достаточно кое-как напеть, без совсем уж сильных въездов в ноты, и дальше звукорежиссер все вычистит-выправит. Попадать в ноты не обязательно.
Грубо говоря, запись будет звучать настолько хорошо, насколько хорошо от природы звучит тембр голоса певца. И выправка вокала в одной песне — максимум три часа работы.
Понятно, что платить за работу глупой симпатичной девочке, которая в ноты-то попасть не может, можно на порядок меньше, нежели певице с образованием, отучившейся 5-15 лет. А когда концерты можно проводить под фонограмму — вообще нет никакого смысла нанимать профессионалов. Это убыточно!
Радует, что последнее время интерес публики к живым выступлением повысился и все больше молодых отечественных артистов работает в живую. Впрочем, ладно. Это было небольшое лирическое отступление на тему сегодняшней статьи:) Сегодня я покажу, как редактировать голос, как вычистить из него все неправильные ноты.
Записываем голос под минусовку
В одном из прошлых уроков я показал, как создать проект в Samplitude и записать голос. Создаем новый проект. Петь будем под минусовку песни Лабиринт Григория Лепса (о которой я рассказывал в статьях по гармонии). Чтобы скачать минусовку, нажмите сюда правой кнопкой мыши и выберите «Сохранить как …».
Добавляем минусовку на «Дорожку 1»: File->Import->Load audio file, там выбираем скачанный файл. На «Дорожке 2» настраиваем запись с микрофона (как это сделать описано тут). Включаем запись и поем какой-нибудь фрагмент. Я спел припев. Вот что получилось:
Аудиозапись: Adobe Flash Player (версия 9 или выше) требуется для воспроизведения этой аудиозаписи. Скачать последнюю версию здесь. К тому же, в Вашем браузере должен быть включен JavaScript.
Готовим дорожку к тюнингу
Вокал звучит задавленно. Нужно его скомпрессировать. Я расскажу об этом подробнее в следующих статьях. Сейчас Вы можете ничего не делать (или сделайте дорожку с минусовкой потише). Я же повесил на дорожку с вокалом компрессор Waves RVox со значением Comp «-18db». Вот как изменилось звучание голоса:
Аудиозапись: Adobe Flash Player (версия 9 или выше) требуется для воспроизведения этой аудиозаписи. Скачать последнюю версию здесь. К тому же, в Вашем браузере должен быть включен JavaScript.
Да… До звания ‘певец’ мне очень далеко:) Не очень благозвучно, грязненько, а в одном месте спета вообще не та нота! Но ничего страшного, сейчас все исправим и зазвучит чище;)
Для начала, разрежем вокал по фразам. Так будет в дальнейшем проще монтировать — заменять или двигать фрагменты. При нарезке уже затюненных фрагментов иногда возникают глюки программы.
- Выберите нужный объект (щелкаем левой кнопкой мыши).
- Переместите указатель воспроизведения (вертикальная линия на весь экран) на место разреза (щелкните левой кнопкой мыши на горизонтальной метрической шкале над рабочей областью; см. цифру 48 на моей картинке — это и есть метрическая шкала).
- Нажмите на клавиатуре клавишу «T» (или в меню Edit->Split->Split objects).
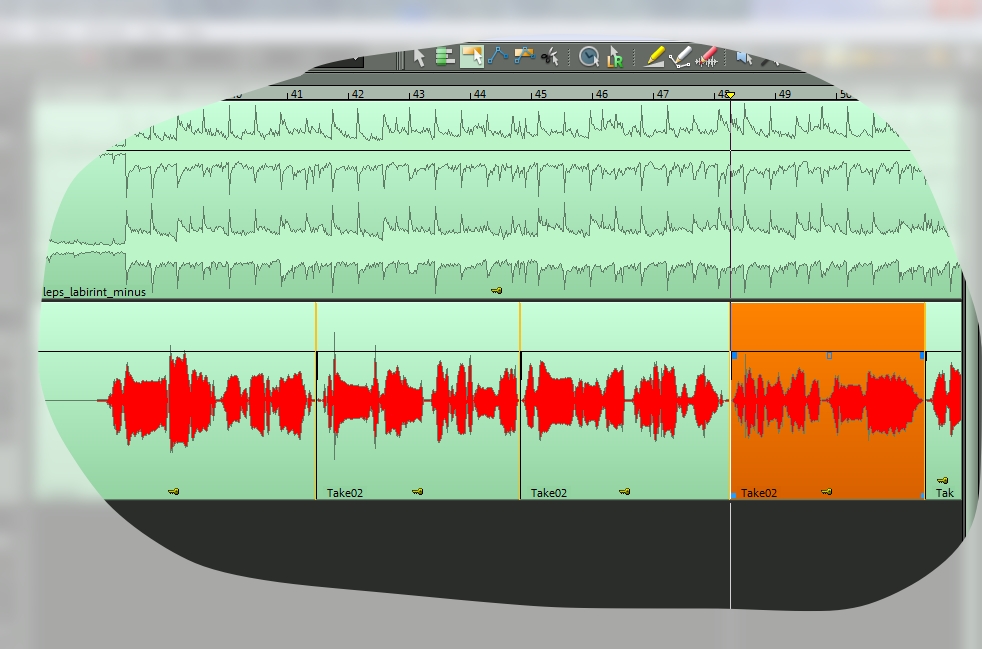
Если у Вас слишком мелкий масштаб рабочей области, скорректируйте ее с помощью кнопок ‘+’ и ‘-‘ справа внизу.
Я начну исправлять с самой грубой ошибки — в пятом фрагменте я спел вообще не ту ноту. Нажимаем правой кнопкой на пятый фрагмент, в появившемся меню выбираем «Object editor». В нем — слева «Time Pitch«, а там нажимаем кнопку «Elastic Audio».
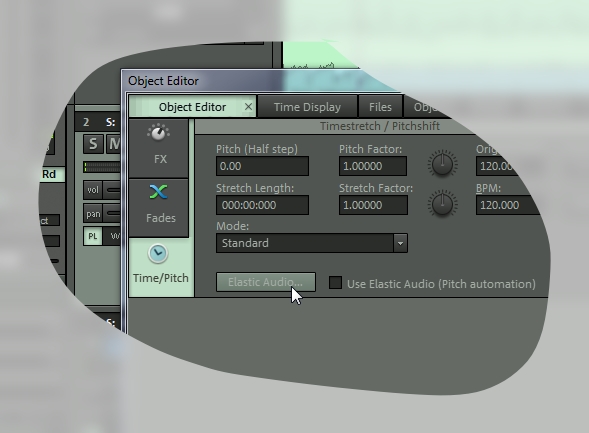
Elastic audio. Как пользоваться тюном?
Итак, мы зашли в модуль для тюнинга звука Samplitude. У него есть два режима работы — Relative и Direct. Первый позволяет без анализа содержимого звуковой дорожки влиять на высоту звука — поднять или опустить относительно первоначального состояния. В этом режиме удобно работать, если нужна грубая корректировка «на слух», либо если второй режим плохо распознает ноту.
Нам интересен второй режим — Direct. Он позволяет проанализировать звуковой фрагмент, отображает график изменения нот во времени. Когда мы заходим сюда впервые — анализ еще не проведен и звуковой фрагмент выглядит монолитно.
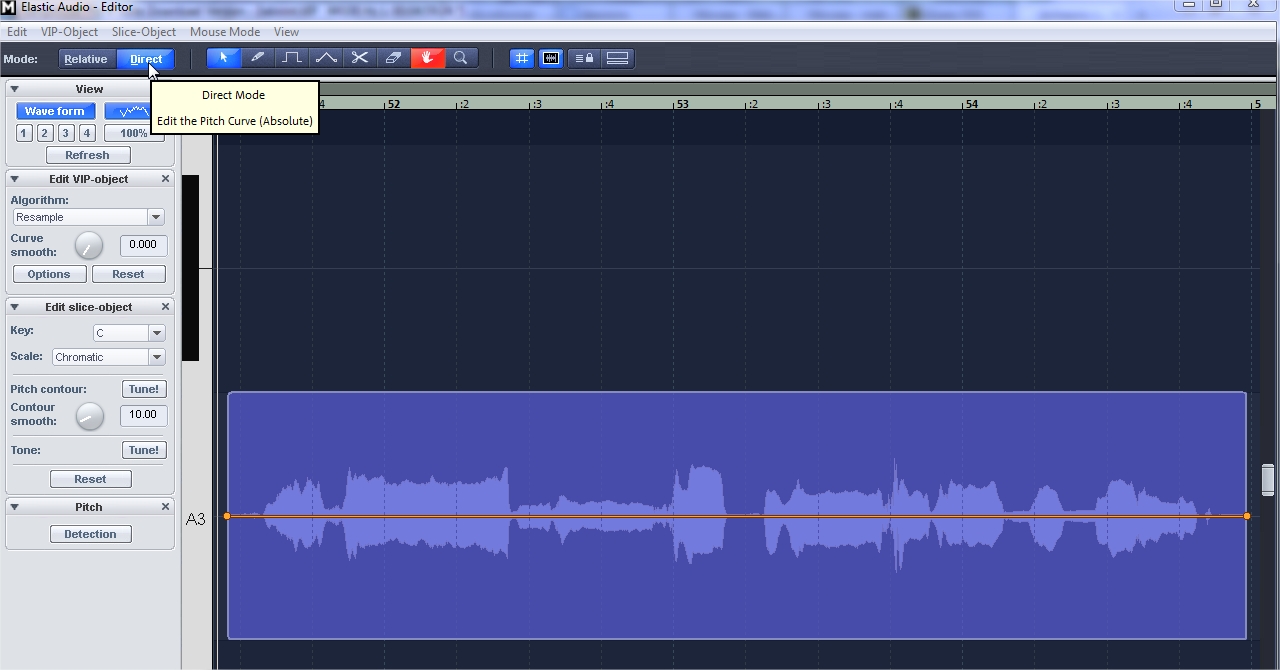
На панели слева внизу нажимаем кнопку Detection. Elastic Audio проанализирует фрагмент и картинка изменится.
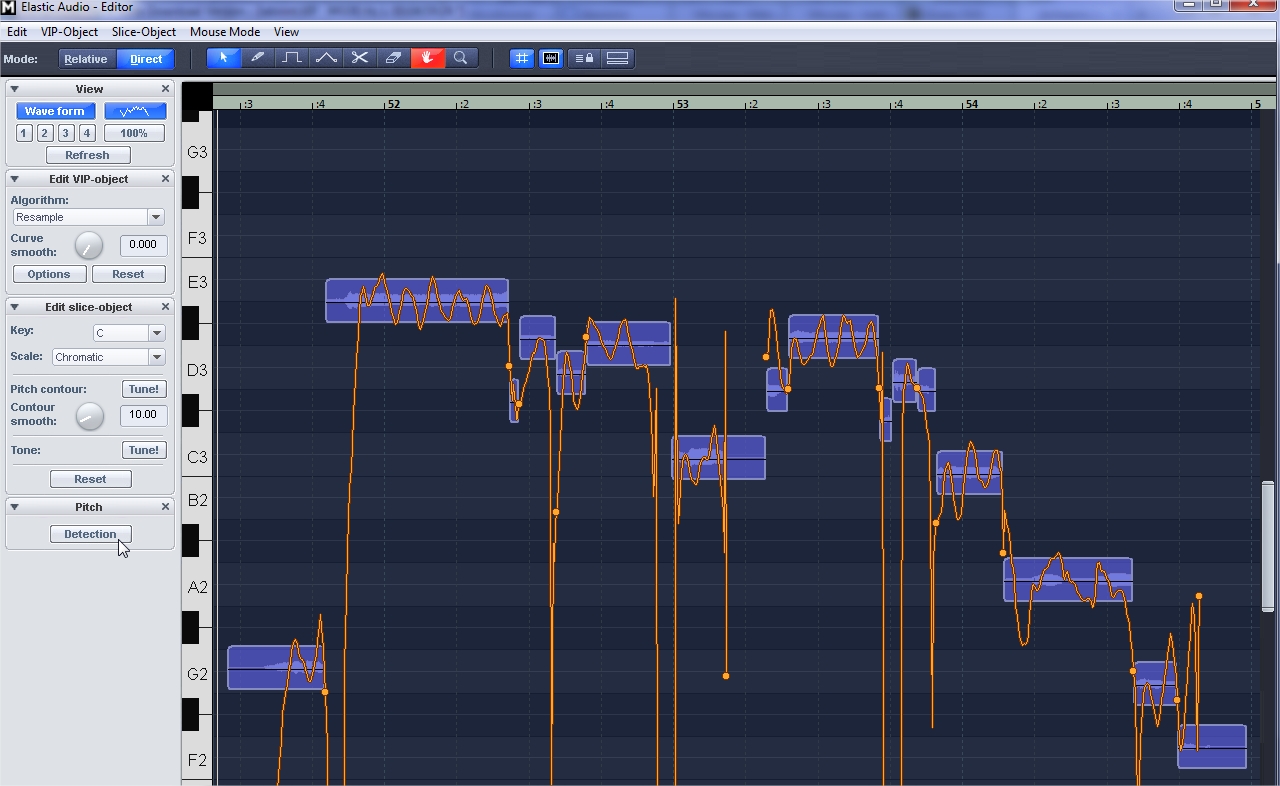
Обратите внимание на ноту в начале 52 такта. Что-то среднее между ми-бемоль и ми. Но в песне на этом месте нота фа. Перетащим эту ноту мышкой повыше.
Прослушаем фрагмент (мышкой нажимаем на метрическую панель сверху в нужном месте, затем нажимаем ‘Пробел’ для воспроизведения). То-то, теперь звучит хорошо! Будто так и спел:)
Ну, если придираться, то немного слышно ненатуральность голоса по сравнению с соседними нотами. Когда изменяешь высоту ноты более, чем на пол тона — это ощутимо. А если более чем на полтора тона — может зазвучать криминально. Но в данном случае будет незаметно. Особенно, если наложить реверберацию.
Настройка тюнера Algorithm
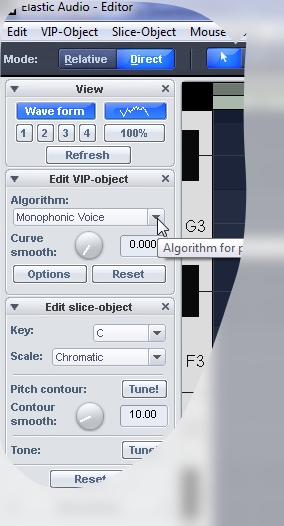
Важной настройкой для каждого аудио фрагмента является Algorithm. До манипуляций это поле содержит Standart. После манипуляций автоматически включается Resample. Есть и другие значения, например — Monophonic voice и Smooth. Чем они отличаются?
Математическим алгоритмом — за счет чего будет меняться высота звука. В случае Resample будет изменяться скорость. Самый натурально-звучащий режим. Если мы понизили ноту — она будет звучать дольше. Повысили — короче.
Как на пленочном магнитофоне — в ускоренном режиме голоса звучат выше. Это единственный режим, когда звуковой сигнал не достраивается компьютером. Обратите внимание, что если сильно изменить первую ноту в длинном фрагменте — все остальные ноты уедут по времени вперед или назад! Отчасти из-за этого нужно нарезать звуковую дорожку до Elastic Audio.
Используйте Resample, если нужно исправить всего одну ноту, а ее длительность не критична. Предварительно вырежьте эту ноту (до Elastic Audio), чтобы другие не съехали по времени.
Остальные алгоритмы оставляют длительность звука неизменной. Если Вы подняли ноту, то чтобы не произошло укорачивания звука, программа достроит недостающую длину на основе оригинального фрагмента. Другими словами, синтезирует ее. Аналогично и с опусканием ноты — тогда на основе оригинального удлинненого сигнала будет рассчитан усредненный с длительностью, как у оригинала.
Я обычно использую Monophonic Voice. При некоторых правках возникают щелчки — тогда я пробую другие алгоритмы. Или более мелко нарезаю сигнал перед Elastic Audio. Сейчас выберем именно Monophonic Voice.
Справа снизу нажимаем OK и закрываем Object Editor. Так мы исправили одну ноту. Конечно, в целом запись не стала звучать чище — остальные ноты-то такие же лажовые, как и были. Поэтому аналогичным образом просматриваем все фрагменты и вносим исправления.
Нюансы тюнинга вокала
Автоматическая подстройка ноты
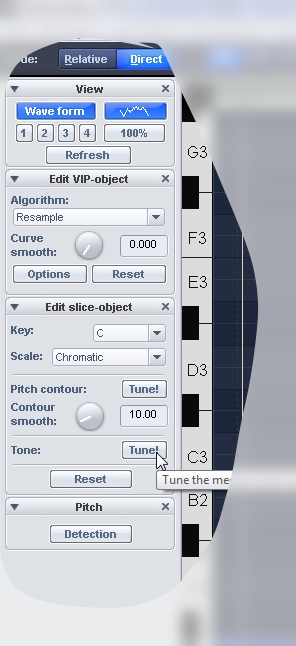
В Elastic Audio выделите нужные фрагменты и нажмите кнопку Tone: Tune слева-снизу. Программа автоматически подвинет ноту по высоте к ближайшему полутону. Когда нота исполнена с какой-либо вибрацией, на глаз определить высоту звука сложно (из-за неравномерной амплитуды). Есть два пути — либо руководствоваться слухом, двигать и переслушивать; либо использовать автоматическую подстройку.
Обратите внимание, что автоматическая подстройка срабатывает, видимо, по среднему значению. То есть если фрагмент не порезан на ноты, но реально представляет из себя два разных по высоте звука, результат подстройки может оказаться неправильным. Ровно как и со въездами/съездами — они могут помешать правильной работе автоподстройки.
Автоматическая перерисовка ноты
Я не пользуюсь этим режимом и не буду про него рассказывать. Поэкспериментируйте сами — за него отвечает вторая кнопка Tune, расположенная чуть выше чем та, о которой шла речь выше.
Некорректное распознавание нот — въезды и согласные
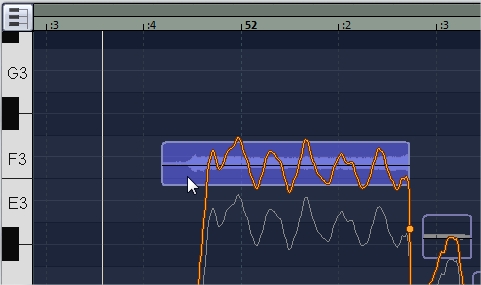
Некоторые ноты могут не распознаваться, либо распознаваться неверно. Причиной может быть хитрое или неправильное звукоизвлечение, плохая дикция. Например, въезд в начале ноты или съезд в конце. На картинке снизу (изображено самое начало припева) присутствует сразу несколько таких ошибок.
Первый и третий синие прямоугольники — это неверное распознавание на въезде и согласном звуке. Видно, что в неправильном синем прямоугольнике почти нет полезного содержания — мало изображения звукового сигнала и много пустоты. Можно не обращать внимание на такие вещи. Чаще всего я не трогаю такие звуки, реже — исправляю вместе с соседним слогом (выделяю и двигаю сразу два).
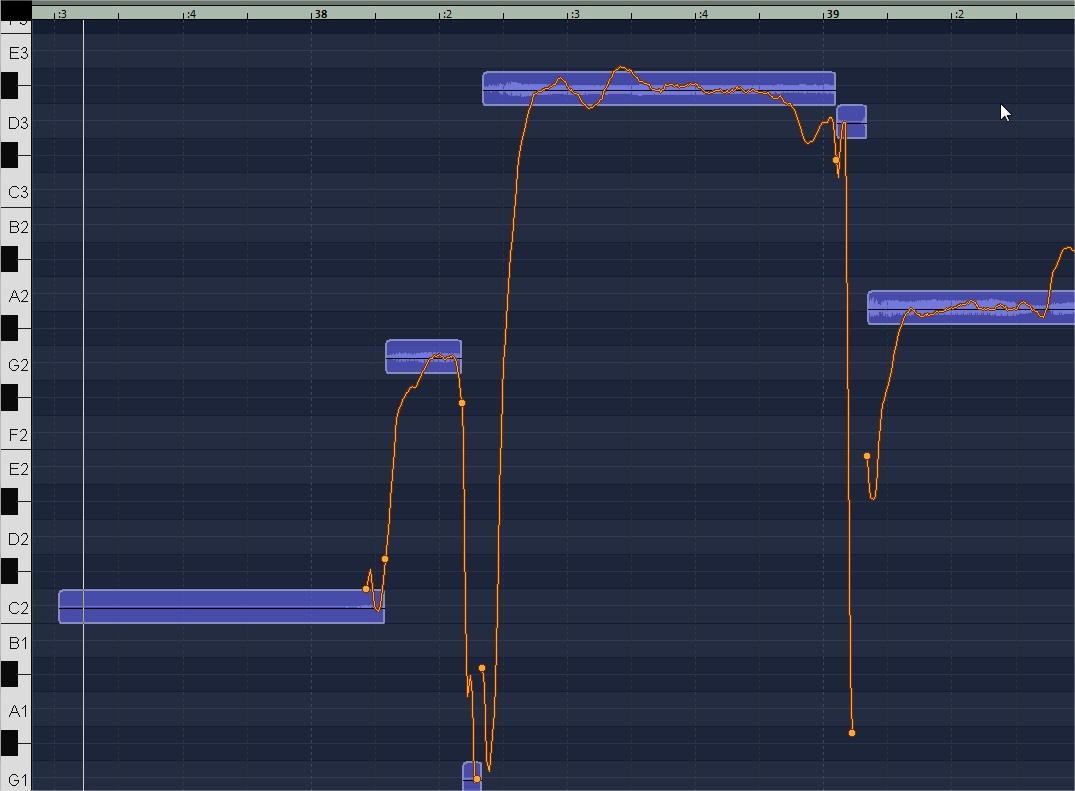
Некорректное распознавание нот — недоразделенные ноты
Иногда программа неправильно бьет ноты по длительностям. Рассмотрим 4 и 5 фрагменты с предыдущей картинки укрупненно.
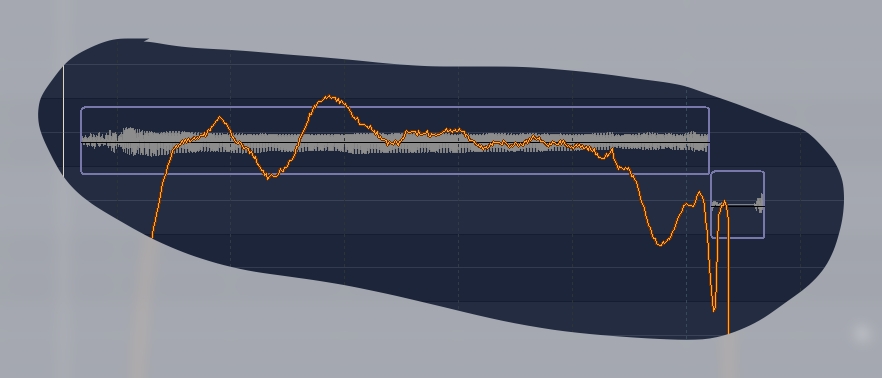
Здесь присутствуют два слога. Текст «вглу-ХУ-Ю». Но программа распознала только снятие слога «Ю» как отдельную ноту. Хотя на картинке видно, что слог изменился раньше (понижение графика в правой части). Чтобы исправить такие места, их можно разрезать.
Для этого на панели инструментов сверху есть кнопочка «Cut» с изображением ножниц. Выбираем ее.
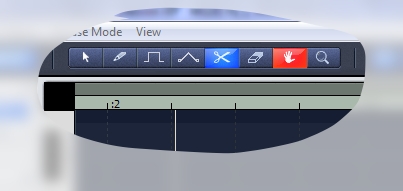
Теперь разрежем ноту.

Ну вот. Ее можно двигать отдельно.
Ошибки интонирования, которые нельзя исправить подвинув ноту целиком
Присмотритесь к предыдущему изображению и прислушайтесь к записи. Слог «вглу-ХУ» дергается, дрожит в начале. Звучит неприятно. Используем инструмент «Pen» (карандаш), чтобы перерисовать ноту.

Вместо дерготни проведем более-менее гладкую линию (стремиться рисовать прямые не надо, это будет звучать неестественно).
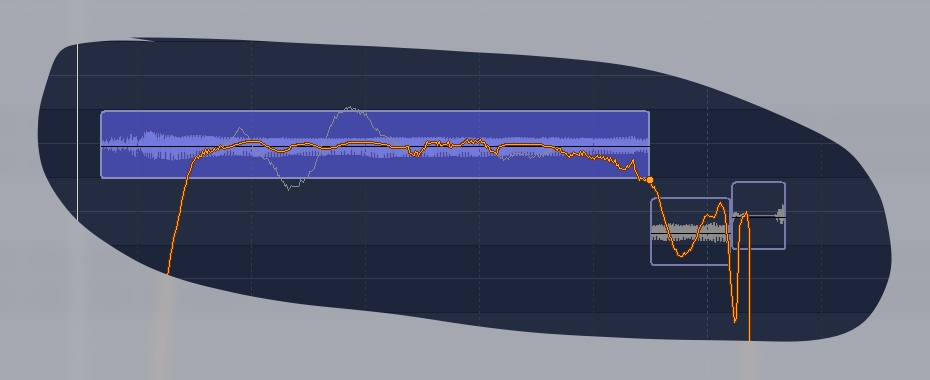
Ноты можно тянуть за один конец, а другой будет оставаться на оригинальном месте
Такой метод хорош, когда исполнитель взял ноту точно, но под конец сполз. Или наоборот. В общем, если ноту перекосило. В комбинации с другими способами правки — очень эффективно.

Комбинированные методы
Конечно, часто все не так просто исправляется и нужно применять комбинации всех вышеописанных методов. Резать цельную ноту на части, двигать концы одних частей, перерисовывать другие части, поднимать или опускать целиком третьи…
Заключение
После того, как я выправил свой записанный голос, получилось следующее:
Аудиозапись: Adobe Flash Player (версия 9 или выше) требуется для воспроизведения этой аудиозаписи. Скачать последнюю версию здесь. К тому же, в Вашем браузере должен быть включен JavaScript.
Согласитесь, звучит поприличнее?:) В будущем перепишем пару слов, подвигаем уже записанные и наложим реверберацию. Уведем поглубже в микс, подожмем — будет еще приличнее!;))))
Вот и все, что я использую, когда исправляю интонирование:) Есть различные плагины, выполняющие корректировку в автоматическом режиме. Солирующий инструмент или вокал — это не то, к чему допустимо применять автоматику. Нужно корректировать каждую нотку с любовью, чтобы все звучало естественно и чисто. Поэтому я не буду рассматривать такие плагины.
А в следующей статье скажу пару слов о монтаже — нарезке и склейке фрагментов. Надеюсь, кому-то была полезна эта статья! Если у Вас есть замечания по манере изложения, по сути или просто хотите что-то сказать — пишите в комментариях! Не надо писать мне в личку — ведь Ваши вопросы могут быть интересны и другим. Я обязательно отвечу. И не забывайте подписываться на обновления (теперь можно не только через соц. сети, но и по e-mail) — в правой колонке сайта:)
Источник: songwritter.ru
Как сделать звук студийного качества через нейросеть Enhance Speech от Adobe
Практически все нейросети, которые находятся на слуху, работают с графикой и носят скорее развлекательный характер. Но в начале января компания Adobe представила сервис Adobe Podcast с несколькими профессиональными инструментами для создания подкастов. Среди них особое место занимает Enhance Speech — нейросеть, улучшающая звук микрофона. Давайте разберемся, как она работает, действительно ли делает запись более чистой, и кому может пригодиться такой инструмент.

Эта нейросеть разорит арендаторов студий для записи подкастов
Что такое Adobe Podcast
Сервис Adobe Podcast ориентирован на публику, которая занимается созданием подкастов. Его технологической основой является аудиоредактор Project Shasta, запущенный еще в конце 2021 года. На первых порах онлайн-сервис предлагал пользователям удаленно записывать подкасты, преобразовывать речь в текст, а также настраивать микрофон, но позже появилась та самая нейросеть.

Помимо нейросети Enhance Speech сервис Adobe Podcast предлагает инструмент для калибровки микрофона
Аналогичный набор функций сейчас доступен и в Adobe Podcast. По сути, это ребрендинг Project Shasta и направлен на более широкую аудиторию. Хотя для доступа ко всем возможностям необходимо подать заявку через форму на сайте, нейросеть Enhance Speech, которая является одним из инструментов онлайн-сервиса, доступна любому желающему совершенно бесплатно.
⚡ Подпишись на Appleinsider в Пульс Mail.ru, чтобы получать новости из мира Apple первым
Как работает нейросеть Enhance Speech
Главная задача Adobe Enhance Speech — сделать речь, записанную в не самых подходящих условиях и не на самое качественное оборудование, более выразительной и чистой. Почти во всех случаях нейросеть достигает заявленных целей, действительно отсекая внешние шумы и создавая впечатление, будто голос был записан в профессиональной студии подкастов.
Но Enhance Speech свойственны те же недостатки, что и нейросетям, улучшающим качество фото. Если при работе с графикой искусственный интеллект делает картинку нарочито мультяшной, пытаясь сгладить все недостатки изображения, то ИИ Adobe слишком агрессивно отсекает внешние шумы, делая звук плоским. Для подкастов — это то, что нужно. Но, если прогнать через нейросеть Adobe аудиодорожку какого-нибудь старого телевизионного репортажа, звук получится неестественно рафинированным. Складывается впечатление, что ролик в прямом смысле слова переозвучили.

❗ Поделись своим мнением или задай вопрос в нашем телеграм-чате
Поэтому в сценариях, выходящих за пределы создания подкастов, помимо Enhance Speech от Adobe нужно использовать дополнительные инструменты. Один из умельцев загрузил на YouTube сцену из фильма «Гражданин Кейн» (1941), которую не только прогнал через нейросеть Adobe, но и наложил на получившуюся аудиодорожку эффект реверберации. Звук стал менее плоским, но итоговый результат все равно заставляет рассматривать Enhance Speech исключительно как инструмент для работы с подкастами.

Кроме того, в своем нынешнем виде нейросеть для улучшения звука микрофона имеет несколько ограничений: поддерживаются только форматы WAV и MP3, продолжительность записи не должна превышать 1 час, а размер файла — 1 гигабайт.
Загляни в телеграм-канал Сундук Али-Бабы, где мы собрали лучшие товары с Алиэкспресс
Как улучшить звук через нейросеть Adobe
Воспользоваться Enhance Speech можно на специальной странице сайта Adobe Podcast. Ее содержимое корректно отображается только в десктопной версии, поэтому при попытке прогнать звук через нейросеть со своего iPhone вы не увидите нужных кнопок для работы с нейросетью даже в режиме просмотра ПК-версии сайта.

Также на странице Enhance Speech есть пример обработанного нейросетью голоса
При первом посещении необходимо создать учетную запись. Для этого нажмите кнопку «Sign Up». Чтобы войти, можно воспользоваться аккаунтом Google или Apple ID. После успешной авторизации на экране появится кнопка «Upload», нажав которую вы сможете загрузить аудиофайл для его дальнейшей обработки.
Загрузить можно только MP3 или WAV
Нейросеть для улучшения звука не дает выставить никакие дополнительные параметры и сразу берется за дело. По окончании появляется возможность прослушать получившееся аудио, а также скачать его на свое устройство, нажав кнопку «Download».

Обработка аудио займет от 1 до 10 минут в зависимости от продолжительности записи
В качестве эксперимента я загрузил 24-секундную аудиодорожку легендарного ролика «Пацаны ваще ребята». Чтобы ее обработать, Enhance Speech потребовалось около минуты, а итоговый размер файла увеличился с 0,2 Мб до 4,5 Мб. Но результат меня более чем устроил. Именно так звучало бы это видео, если бы его записью занималась бригада провинциального телеканала.
⚡ Подпишись на Appleinsider в Дзене, где мы публикуем эксклюзивные материалы
Что еще умеют нейросети
Enhance Speech — одна из множества нейросетей, за развитием которых пристально следят коллеги с Hi-News.ru. Наша редакция тоже неоднократно показывала, что нейросети позволяют:
- меняться лицами со знаменитостями;
- улучшать качество фото;
- делать портреты из фото;
- брать интервью у Стива Джобса;
- рисовать обои для iPhone.
Остается только догадываться, что еще в скором времени научатся делать нейросети и смогут ли они, наконец, заменить человеческий труд. А пока напишите в комментариях, чего вы ждете от искусственного интеллекта в 2023 году.
Источник: appleinsider.ru