
Есть много способов удалить дубликаты из списка Python:
- использование временного списка и цикла;
- использование встроенного метода set();
- использование ключей словаря;
- функция List count();
- понимание списка.
Список в Python может содержать повторяющиеся элементы. Давайте рассмотрим примеры удаления повторяющихся элементов разными способами.
1. Использование временного списка
Это метод для удаления повторяющихся элементов из списка. Мы создадим временный список и добавим в него элементы только в том случае, если его нет.
ints_list = [1, 2, 3, 4, 3, 2] temp = [] for x in ints_list: if x not in temp: temp.append(x) ints_list = temp print(f’Updated List after removing duplicates = ‘)
Результат: обновленный список после удаления дубликатов = [1, 2, 3, 4].
2. Функция set()
В наборе Python нет повторяющихся элементов. Мы можем использовать встроенную функцию set() для преобразования списка в набор, а затем использовать функцию list(), чтобы преобразовать его обратно в список.
Как удалить дубликаты файлов на компьютере Windows 11/10/8/7?✅
ints_list = [1, 2, 3, 4, 3, 2] ints_list1 = list(set(ints_list)) print(ints_list1) # [1, 2, 3, 4]
3. Перечисление элементов как ключей словаря
Как удалить дубли
После длительного использования компьютера на нем может накопиться большое количество одинаковых файлов, которые могут занимать много места на жестком диске и при этом быть совершенно ненужными. Диск можно и даже нужно время от времени очищать от подобного «мусора».

Статьи по теме:
- Как удалить дубли
- Как удалить повторяющиеся значения в экселе
- Как найти дубликаты
Инструкция
С помощью стандартных средств Windows поиск всех дублей на жестком диске займет очень много времени и сил, поэтому этот вариант вряд ли кого-то заинтересует. А вот воспользоваться специально разработанными для этой цели программами будет самым правильным решением.
Большинство программ, предназначенных для поиска и удаления дубликатов файлов, платные. Однако если вы не видите смысла в оплате процедуры очистки своего компьютера от повторяющихся файлов, можете воспользоваться и бесплатным софтом, ничем не уступающим своим платным конкурентам. Попробуйте программу DupKiller, которую можно скачать на сайте www.dupkiller.net.
Запустите программу после того, как она будет загружена и установлена на ваш компьютер. В Windows 7 может появиться предупреждение о том, что приложение могло быть установлено с ошибками. Не обращайте на это внимание и нажимайте кнопку «Эта программа установлена правильно».
Перед тем, как вы попадете в главное меню программы, вам будет предложено ознакомиться с советами по использованию этого приложения. Можете их почитать, а при отсутствии такого желания, проигнорировать это предложение, нажав кнопку «Закрыть».
Повторяющиеся значения в Excel: найти, выделить и удалить дубликаты
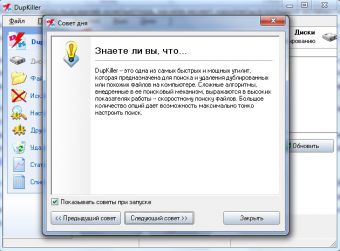
В главном меню программы вам следует установить флажки для разделов жесткого диска, на которых вы хотели бы выполнить поиск. По умолчанию поиск будет произведен по всему жесткому диску, и если вам это и нужно, сразу нажимайте кнопку «Сканировать».
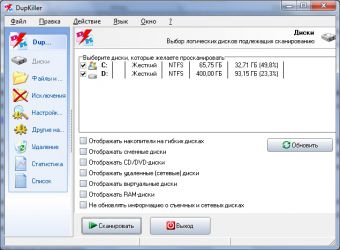
Через некоторое время, которое будет зависеть от размеров вашего жесткого диска, все дубликаты файлов будут найдены и представлены в виде списка. Установите флажки для файлов, которые следует удалить, и нажмите кнопку «Удалить выделенные файлы». Программа произведет физическое удаление выбранных файлов с жесткого диска.
Источник: www.kakprosto.ru
Как быстро найти и удалить все дубли страниц на сайте: 8 способов + лайфхак

Дубли — это страницы с одинаковым контентом. Они могут появиться при автогенерации, некорректных настройках, вследствие изменения структуры сайта или при неправильной кластеризации. Дубликаты негативно влияют на SEO-продвижение, так как поисковые системы хуже ранжируют страницы с похожим контентом. Кроме того, большое количество слабых, несодержательных или пустых страниц понижают оценку всего сайта. Поэтому важно своевременно отслеживать и устранять подобные проблемы.
В данной статье подробно рассмотрим, как найти и удалить дубли, а также предотвратить их появление.
- 1 Виды дублей
- 1.1 Полные
- 1.2 Частичные
- 1.2.1 Характеристики в карточке товара
- 1.2.2 Пагинация
- 1.2.3 Подстановка контента
- 1.2.4 Версия для печати
- 2.1 Физическое удаление
- 2.2 Настройка 301 редиректа
- 2.3 Создание канонической страницы
- 2.4 Запрет индексации файла Robots.txt
- 5.1 Яндекс.Вебмастер
- 5.2 Netpeak Spider
- 5.3 Xenu
- 5.4 Screaming Frog Seo Spider
- 5.5 Сервис-лайфхак
Виды дублей
Дубликаты бывают 3-х видов:
- Полные — с полностью одинаковым контентом;
- Частичные — с частично повторяющимся контентом;
- Смысловые, когда несколько страниц несут один смысл, но разными словами.
Зачастую при анализе обращают внимание лишь на полные совпадения, но не стоит забывать про частичные и смысловые, так как к ним поисковики тоже относятся критично.
Полные
Полные дубли ухудшают хостовые факторы всего сайта и осложняют его продвижение в ТОП, поэтому от них нужно избавиться сразу после обнаружения.
К ним относятся:
- Версия с/без www. Возникает, если пользователь не указал зеркало в панели Яндекса и Google.
- Различные варианты главной страницы:
- site.net;
- site.net/index;
- site.net/index/;
- site.net/index.html;
- Страницы, появившиеся вследствие неправильной иерархии разделов:
- site.net/products/gift/
- site.net/products/category/gift/
- site.net/category/gift/
- UTM-метки. Метки используются, чтобы передавать данные для анализа рекламы и источника переходов. Обычно они не индексируются поисковиками, но бывают исключения.
- GET-параметры в URL. Иногда при передаче данных GET-параметры попадают в адрес страницы:
- site.net/products/gift/page.php?color=red
- Страницы, сгенерированные реферальной ссылкой. Обычно они содержат специальный параметр, который добавляется к URL. С такой ссылки должен стоять редирект на обычный URL, однако часто этим пренебрегают.
- Неправильно настроенная страница с ошибкой 404, которая провоцирует бесконечные дубли. Любой случайный набор символов в адресе сайта станет ссылкой и без редиректа отобразится как страница 404.
Избавиться от полных дубликатов можно, поставив редирект, убрав ошибку программно или закрыв документы от индексации.
Частичные
Частичные дубликаты оказывают не такое сильное влияние на сайт, как полные. Однако если их много — это ухудшает ранжирование веб-ресурса. Кроме того, они могут мешать продвижению и по конкретным ключевым запросам. Разберем в каких случаях они возникают.
Характеристики в карточке товара
Нередко, переключаясь на вкладку в товарной карточке, например, на отзывы, можно увидеть, как это меняет URL-адрес. При этом большая часть контента страницы остаётся прежней, что создает дубль.
Пагинация
Если CMS неправильно настроена, переход на следующую страницу в категории меняет URL, но не изменяет Title и Description. В итоге получается несколько разных ссылок с одинаковыми мета-тегами:
- site.net/category/notebooks/
- site.net/category/notebooks/?page=2
Такие URL-адреса поисковики индексируют как отдельные документы. Чтобы избежать дублирования, проверьте техническую реализацию вывода товаров и автогенерации.

Также на каждой странице пагинации необходимо указать каноническую страницу, которая будет считаться главной. Как указать этот атрибут, будет рассмотрено ниже.
Подстановка контента
Часто для повышения видимости по запросам с указанием города в шапку сайта добавляют выбор региона. При нажатии которого на странице меняется номер телефона. Бывают случаи, когда в адрес добавляется аргумент, например «wt_city_by_default=..». В результате, у каждой страницы появляется несколько одинаковых версий с разными ссылками. Не допускайте подобной генерации или используйте 301 редирект.
Версия для печати
Версии для печати полностью копируют контент и нужны для преобразования формата содержимого. Пример:
- site.net/blog/content
- site.net/blog/content/print – версия для печати;
Поэтому необходимо закрывать их от индексации в robots.txt.
Смысловые
Смысловые дубли — это статьи, написанные под запросы из одного кластера. Чтобы их обнаружить, нужно воспользоваться результатом парсинга сайта, выполненного, например, программой Screaming Frog. Затем скопировать заголовки всех статей и добавить их в любой Hard-кластеризатор с порогом группировки 3,4. Если несколько статей попали в один кластер – оставьте наиболее качественную, а с остальных поставьте 301 редирект.
Варианты устранения дубликатов
При дублировании важно не только избавиться от копий, но и предотвратить появление новых.
Физическое удаление
Самым простым способом было бы удалить повторяющиеся страницы вручную. Однако перед удалением нужно учитывать несколько важных моментов:
- Источник возникновения. Зачастую физическое удаление не решает проблему, поэтому ищите причину;
- Страницы можно удалять, только если вы уверены, что на них не ссылаются другие ресурсы. Проверить это можно с помощью условно-бесплатного инструмента.
Настройка 301 редиректа
Если дублей не много или на них есть ссылки, настройте редирект на главную или продвигаемую страницу. Настройка осуществляется через редактирование файла . htaccess либо с помощью плагинов. Старый документ со временем выпадет из индекса, а весь ссылочный вес перейдет новой странице.
Создание канонической страницы
Указав каноническую страницу, вы показываете поисковым системам, какой документ считать основным. Этот способ используется для того, чтобы показать, какую страницу нужно индексировать при пагинации, сортировке, попадании в URL GET-параметров и UTM-меток. Для этого на всех дублях в теге прописывается следующая строчка со ссылкой на оригинальную страницу:
Например, на странице пагинации главной должна считаться только одна страница: первая или «Показать все». На остальных необходимо прописать атрибут rel=»canonical», также можно использовать теги rel=prev/next.
Для 1-ой страницы:
Для второй и последующей:
Для решения этой задачи на сайтах WordPress используйте плагины Yoast SEO или All in One SEO Pack. Чтобы все заработало просто зайдите в настройки плагина и отметьте пункт «Канонические URL».

Запрет индексации файла Robots.txt
Файле robots.txt — это своеобразная инструкция по индексации для поисковиков. Она подойдёт, чтобы запретить индексацию служебных страниц и дублей.
Для этого нужно воспользоваться директивой Disallow, которая запрещает поисковому роботу индексацию.
Disallow: /dir/ – директория dir запрещена для индексации
Disallow: /dir – директория dir и все вложенные документы запрещены для индексации
Disallow: *XXX – все страницы, в URL которых встречается набор символов XXX, запрещены для индексации.
Внимательно следите за тем какие директивы вы прописываете в robots. П ри некорректном написании можно заблокировать не те разделы либо вовсе закрыть сайт от поисковых систем.
Запрет индексировать страницы действует для всех роботов. Но каждый из них реагирует на директиву Disallow по-разному: Яндекс со временем удалит из индекса запрещенные страницы, а Google может проигнорировать правило, если на данный документ ведут ссылки.
Причины возникновения
Обычно при взгляде на URL-адрес можно сразу определить причину возникновения дубля. Но иногда нужен более детальный анализ и знание особенностей CMS. Ниже приведены 6 основных причин, почему они могут появляться:
- ID-сессии, которые нужны, чтобы контролировать действия юзеров или анализировать данные о товарах в корзине.
- Особенности CMS. Joomla создаёт большое количество дублей, в отличие, например, от WordPress .
- Ссылки с GET-параметрами.
- Страницы комментариев.
- Документы для печати.
- Документы с www и без www.
Некоторые ошибки могут появиться и по другим причинам, например, если не указан редирект со старой страницы на новую или из-за особенностей конкретных скриптов и плагинов. С каждой такой проблемой нужно разбираться индивидуально.
Отдельным пунктом можно выделить страницы, дублирующиеся по смыслу. Такая ошибка часто встречается при неправильной разгруппировке. Подробнее о том как ее не сделать читайте по ссылке.
Как дубликаты влияют на позиции сайта
Дубли существенно затрудняют SEO- продвижение и могут стать препятствием для выхода запросов в ТОП поисковой выдачи.
Чем же они так опасны:
- Снижают релевантность страниц. Если поисковик замечает несколько url-ов с одинаковым контентом, их релевантность снижается и оба документа начинают ранжироваться хуже.
- Уменьшают процент уникальности текстов. Уникальность будет разделена между дублирующими документами, а значит копия будет неуникальной по отношению к основной странице. В итоге общая уникальность сайта понизится.
- Разделяют вес. Поисковик показывает по одному запросу только 1 станицу сайта (если он не витальный), поэтому наличие нескольких документов снижает вес каждого урла.
- Увеличивают время индексации. Поисковый робот дольше сканирует веб-ресурс из-за большого количества документов.
Инструменты для поиска
Как найти дублирующие ся документы? Это можно сделать с помощью программ и онлайн-сервисов. Часть из них платные, другие – бесплатные, некоторые – условно-бесплатные (с пробной версией или ограниченным функционалом).
Яндекс.Вебмастер
Чтобы посмотреть наличие дубликатов в панели Яндекса, необходимо:
- выбрать вкладку «Индексирование»;
- открыть раздел «Страницы в поиске»;
- посмотреть количество «Исключенных страниц».

Страницы исключаются из индекса по разным причинам, в том числе из-за повторяющегося контента. Обычно конкретная причина прописана под ссылкой.
Netpeak Spider
Netpeak Spider – платная программа с 14-дневной пробной версией. Если провести поиск по заданному сайту, программа покажет все найденные ошибки и дубликаты.

Xenu
Бесплатным аналогом этих программ является Xenu, где можно проанализировать даже не проиндексированный сайт.

При сканировании программа найдет повторяющиеся заголовки и мета-описания.
Screaming Frog Seo Spider
Screaming Frog Seo Spider является условно-бесплатной программой. До 500 ссылок можно проверить бесплатно, после чего понадобится платная версия. Наличие дублей программа определяет так же, как и Xenu, но быстрее и эффективнее. Если нет денег на покупку рабочий ключ можно найти в сети.

Сервис-лайфхак
Для тех кто не хочет осваивать программы, рекомендую воспользоваться техническим анализом от Wizard.Sape. Аудит делается в автоматическом режиме в среднем за 2-4 часа. Цена вопроса — 690 рублей. В течении 30 дней бесплатно можно провести повторную проверку.
Помимо дублированного контента и мета-тегов инструмент выдает много полезной информации:
- показывает все 301 редиректы;
- обрабатку заранее ошибочных адресов;
- страницы на которых нет контента;
- битые внешние и внутренние ссылки и картинки.

Вывод
Полные и частичные дубли значительно осложняют продвижение сайта. Поэтому обязательно проверяйте ресурс на дубликаты, как сгенерированные, так и смысловые и применяйте описанные в статье методы для их устранения.
Источник: altblog.ru