
Книга «A Practitioner’s Guide to Software Test Design» Lee Copeland была опубликована в 2003 году.
С тех пор она надежно закрепилась в списке книг, которые обязательно должен прочитать любой тестировщик. Её стоит прочитать в оригинале. Читается очень приятно: язык не сложный, стиль легкий. По ходу книги автор слегка иронизирует над собой, своими учениками, читателями и в целом над сферой нашей деятельности.
Далее приводится не перевод, а скорее подробный конспект раздела “Техники тестирования методом черного ящика”, в котором содержится описание применения техник тест-дизайна.
Ко мне в руки книга попала по совету бывшего коллеги, за что ему отдельное спасибо.
To be most effective and efficient test case must be designed, not just slapped together.
Equivalence Class Testing
Boundary Value Testing
Decision Table Testing
Pairwise Testing
State-Transition Testing
Use Case Testing
Классы эквивалентности (Equivalence Class Testing)
Техника
- Определить классы эквивалентности.
- Создать тест-кейсы для каждого класса эквивалентности.
Классом эквивалентности называется набор данных, который запускает одни и те же модули и должен приводить к одним и тем же результатам.
Тестировщик с нуля / Урок 6. Нефункциональное тестирование. Черный, белый и серый ящик
Любые данные в рамках класса эквивалентны, это означает что если один тест-кейс в кассе эквивалентности обнаружил/не обнаружил дефект, то все остальные тест-кейсы внутри этого класса эквивалентности обнаружат/не обнаружат тот же самый дефект.
Альтернативный подход — использование классов эквивалентности не для входов, а для выходов. Разделить варианты выходов на классы эквивалентности, определить какие входные значения могут инициировать такие выходы. Преимущество в том, что проверяется каждый возможный вариант выхода. Недостаток в том, что внутри класса эквивалентности по выходу, может прятаться несколько классов эквивалентности по входу.
При наличии нескольких переменных:
- валидные классы нескольких переменных объединяются в один тест-кейс;
- невалидные классы тестируются отдельно.
Let your designers and programmers know when they have helped you. They’ll appreciate the thought and may do in again.
Граничные значения (Boundary Value Testing)
Техника
- Определить классы эквивалентности
- Определить границы каждого класса эквивалентности
- Создать тест-кейсы для каждого граничного значения, выбирая по одной точке непосредственно на границе, выше и ниже границы.
Следует помнить, что точка выше или ниже границы может быть экземпляром другого класса эквивалентности, в этом случае дублировать тест не нужно.
Значения определяются типом. Если граница 5, то для поля, где вводятся целые числа тестируются точки 4 и 6, а для поля, где вводятся суммы в рублях и копейках тестируются точки 4,99 и 5,01.
Black-box vs White-box testing. Методологии тестирования | Курс тестирование ПО — Урок 8 | QA Labs
При наличии нескольких переменных:
- минимальные значения валидных границ объединяются в один тест-кейс;
- максимальные значения валидных границ объединяются в другой тест-кейс;
- невалидные границы тестируются отдельно, как и в случае с невалидными классами.
Boundary value testing focuses on the boundaries because that is where so many defects hide.
Таблица принятия решений (Decision Table Testing)
Техника
- Определить все условия
- Составить все возможные комбинации условий
- Убрать лишние комбинации. Удаляются те, в которых изменение значений никак не влияет на получаемый результат (Don’t care — DC)
- Определить действия
- Создать тест-кейсы для каждой комбинации
Таблица принятия решений — представляет связь составных условий и результирующих действий.
Если условие представляет из себя диапазон значений, то дополнительно создаются тесты для проверки значений выше и ниже граничного.
| 2 3 =8 комбинаций | Rule 1 | Rule 2 | Rule 3 | Rule 4 | Rule 5 | Rule 6 | Rule 7 | Rule 8 |
| Conditions | ||||||||
| Допустимый код акции | N | N | N | N | Y | Y | Y | Y |
| Допустимое количество | N | N | Y | Y | N | N | Y | Y |
| Достаточно средств | N | Y | N | Y | N | Y | N | Y |
| Actions | ||||||||
| Купить | N | N | N | N | N | N | N | Y |
Внимательно посмотрев на таблицу, можно заметить, что в правилах 1, 2, 3, 4, если код акции недопустимый, то проверка остальных условий не имеет смысла. Правила 5 и 6 могут быть объединены, т.к. условие проверки средств никак не влияет на результат. Условия, которые не оказывают влияние на результат помечаются как “DC”. Таблица преобразуется:
| 4 комбинации | Rule 1 | Rule 2 | Rule 3 | Rule 4 |
| Conditions | ||||
| Допустимый код акции | N | Y | Y | Y |
| Допустимое количество | DC | N | Y | Y |
| Достаточно средств | DC | DC | N | Y |
| Actions | ||||
| Купить | N | N | N | Y |
Т.к. всегда есть вероятность того, что таблица может быть преобразована неверно или код написан неправильно лучше, чтобы исходная таблица все равно была под рукой.
Famous Software Tester Mick Jagger gives excellent advice regarding this “You can’t always get what you want, but if you try sometimes, you just might find, you get what you need.”
Попарное тестирование
Техника
- Определить параметры (variables)
- Определить количество значений для каждого параметра (choices for variable)
- Построить массив, содержащий колонки для каждого параметра и значения в колонках, которые содержать все сочетания значений этих параметров друг с другом.
- Сопоставить полученный ортогональный массив с целью тестирования.
- Построить тест-кейсы.
Опытным путем было определено, что большинство дефектов это или одиночные дефекты (single-mode defects), или парные дефекты (double-mode defects), т.е. проявляющиеся при сочетании одного параметра всего лишь с одним другим параметром, при том что значение остальных параметров не имеет значения.
Если количество комбинаций значений переменных велико, не стоит пытаться протестировать все возможные комбинации, лучше сосредоточиться на тестировании всех пар значений переменных.
Два подхода попарного тестирования (pairwise testing): метод ортогонального массива (orthogonal arrays) и метод всех пар (allpair algorithm).
Ортогональный массив — это двумерный массив, обладающий особым свойством: если выбрать две любые колонки в массиве, то в них будут присутствовать все возможные сочетания значений параметров, тем же самым свойством обладают все пары колонок.
Все пары — для создания массива используется алгоритм, генерирующий пары напрямую, без использования дополнительной балансировки. Если имеется большое количество параметров, принимающих маленькое количество значений, то для составления пар лучше использовать этот метод.
Не обязательно составлять попарные комбинации вручную, для этого существует масса инструментов.
Нужно учитывать, что могут возникнуть ограничения связанные с тем, что некоторые сочетания параметров никогда не будут иметь места.
There is no underlying “software defect physics” that guarantees pairwise testing will be of benefit. There is only one way to know — try it.
Диаграмма переходов состояний
Техника
Состояние (State) — Условие в котором система ожидает одно или несколько событий.Состояние помнит что было получено на вход и определяет ответную реакцию, которая должна произойти. Это событие может быть приводить в новое состояние и/или инициировать новое действие. Состояние обычно отражает значение некоторой переменной в системе. Изображается в форме круга.
Переход (Transition) — Представляет переход из текущего состояния в новое, в результате выполнения какого-то действия. Изображается в виде стрелки.
Событие (Event) — Событие, ставшее причиной изменения состояния. Обычно событие поступает в систему из внешнего мира посредством некоторого интерфейса. Иногда это событие инициируется внутри самой системы например такие как срабатывание таймера, снижение ниже какого-то уровня. Считается, что событие происходит моментально.
Событие может быть как независимым, так и связанным. Когда событие случается, система может изменить состояние или остаться в прежнем состоянии и/или инициировать действие. События могут иметь, связанные с ними параметры (номер карты, сумма на счете). Изображается как подпись к стрелке перехода.
Действие (Action) — Операция, инициированная в результате смены состояния. Зачастую это некоторый ответ системы. Помните, что действие происходит при переходе между состояниями. Состояния сами по себе статичны. Указывается через слеш в подписи к стрелке перехода после события.
Диаграмма перехода состояний представляет собой одну специфическую сущность (например, процесс резервирования). Частая ошибка — попытка смешивать разные сущности в одной диаграмме (например Резервирование и Пассажира с событиями и действиями, связанными с каждым из них).
Может использоваться, когда системе нужно знать предысторию или правильный порядок выполнения операций.
На основании Диаграммы перехода состояний составляется Таблица перехода состояний. Таблица содержит 4 колонки: текущее состояние, событие, действие, следующее состояние.
Преимущество Таблицы перехода состояний в том, что это перечень всех возможных комбинаций переходов из состояния в состояние, в том числе и невалидных. При анализе такой таблицы могут быть замечены пробелы в требованиях. Использование таблицы перехода состояний может помочь отследить недопустимые переходы между состояниями.
Может быть выбран один из 4 вариантов создания тест-кейсов:
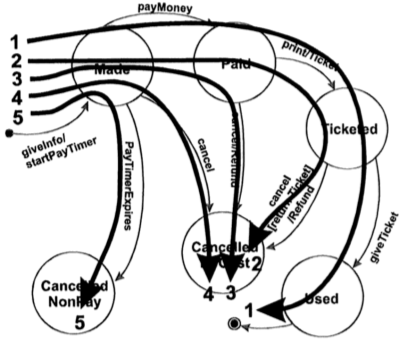
- Создать наборы тест-кейсов так, чтобы все состояния были пройдены хотя бы по одному разу. В одном тест-кейсе может быть описан переход через несколько состояний. Это довольно слабый уровень тестового покрытия.
- Создать наборы тест-кейсов так, чтобы все события были инициированы хотя бы по одному разу. Тест-кейсы, которые покрывают все события в то же время покрывают и все состояния. Снова слабый уровень тестового покрытия.
- Создать наборы тест-кейсов так, чтобы все пути были пройдены хотя бы по одному разу. Такой способ хорош с точки зрения тестового покрытия, однако практически не осуществим. Если диаграмма имеет циклы, то количество возможных путей может оказаться бесконечным.
- Создать наборы тест-кейсов так, чтобы все переходы были выполнены хотя бы по одному разу. Этот способ обеспечивает хороший уровень тестового покрытия, поэтому рекомендуется использовать именно его.
Рекомендуемая стратегия создания тест-кейсов состоит в том, чтобы хотя бы по разу протестировать все переходы между состояниями. В высокорисковых системах, где требуется более надежное тестовое покрытие, возможно создавать тест-кейсы на каждый путь (цепочку переходов) между состояниями.
And now for something completely different. Monty Python
Варианты использования (Use Case Testing)
Техника
Use case — это сценарии, описывающие то как actor (обычно человек, но может быть и другая система) пользуется системой для достижения определенной цели. Варианты использования описываются с точки зрения пользователя, а не системы. Внутренние работы по поддержанию работоспособности системы не являются частью варианта использования.
Хотя бы один тест-кейс должен проверять основной сценарий и хотя бы по одному кейсу должно приходится на альтернативные сценарии.
Рекомендации по созданию тест-кейсов на основе вариантов использования
- Начать с валидных данных и наиболее частых сценариев.
- Проверить граничные значения и невалидные значения (с использованием ранее рассмотренных техник).
- Редко используемые сценарии, крайне важные для системы (так называемая “Остановка ядерного реактора” Shut Down The Nuclear Reactor)
- Тесты на каждое ветку-альтернативу (Extension) каждого шага
- Попробовать выполнить операцию в непривычном порядке
- Извратить предусловие, если это действительно может произойти
- Если транзакция имеет циклы, запустите ее в цикле, и не один-два раза — будьте жестче
- Найти очень долгий и извилистый путь и пройдите по нему
- Если ожидается, что транзакция будет выполняться в логичном порядке, попробовать выполнить ее в обратном порядке (например заполнить поля не сверху вниз, а снизу вверх)
- Создать тесты на защиту от дурака
Шаблон описания вариантов использования
| Use Case Component | Description |
| Use Case Number or Identifier (Номер или идентификатор) |
Уникальный идентификатор |
| Use Case Name (Наименование) |
В форме предложения, содержащего глагол в активной форме (что сделать?). Например, Авторизоваться, Создать заказ |
| Goal in Context (Цель и контекст) |
Более детальное описание цели, если это необходимо. Например, Создать заказ от имени организации. |
| Scope (Границы) | Корпорация (общий)|Система|Подсистема |
| Level (Уровень) | Общая|Частная|Подфункция |
| Primary Actor (Основной исполнитель | Роль или описание основного пользователя |
| Preconditions (Предусловия) | Состояние, в котором система должна находится до начала варианта использования |
| Success End Conditions (В случае успеха) | Состояние, в которое должна перейти система в случае удачного завершения варианта использования |
| Failed End Conditions (В случае провала) | Состояние, в которое должна перейти система в случае НЕудачного завершения варианта использования |
| Trigger (Условие срабатывания) | Действие, инициирующее запуск этого варианта использования |
| Main Success Scenario (Основной сценарий) |
Шаги и действия |
| Extensions (Дополнительные условия) |
Источник: temofeev.ru
Тестирование методом черного ящика
Тестирование методом черного ящика базируется на том, что все тесты основываются на спецификации системы или ее компонентов. Система представляется как «черный ящик», поведение которого можно определить только посредством изучения ее входных и соответствующих выходных данных. Другое название этого метода – функциональное тестирование – связано с тем, что испытатель проверяет не реализацию ПО, а только его выполняемые функции [2,3].
На рисунке 3 показана модель системы, тестируемая методом черного ящика. Этот метод также применим к системам, организованным в виде набора функций или объектов. Испытатель подставляет в компонент или систему входные данные и исследует соответствующие выходные данные. Если выходные данные не совпадают с предсказанными, значит, во время тестирования ПО успешно обнаружена ошибка (дефект).
Основная задача испытателя – подобрать такие входные данные, чтобы среди них с высокой вероятностью присутствовали элементы множества 1е. Во многих случаях выбор тестовых данных основывается на предварительном опыте испытателя. Однако дополнительно к этим эвристическим знаниям можно также использовать систематический метод выбора входных данных, обсуждаемый в следующем разделе [2,3].
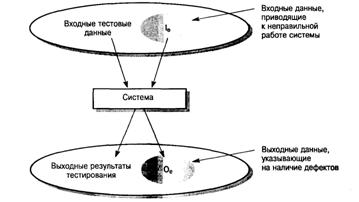
Рисунок 3 – Тестирование методом черного ящика
1.3 Структурное тестирование
Метод структурного тестирования (рисунок 4) предполагает создание тестов на основе структуры системы и ее реализации. Такой подход иногда называют тестированием методом «белого ящика», «стеклянного ящика» или «прозрачного ящика», чтобы отличать его от тестирования методом черного ящика [3].
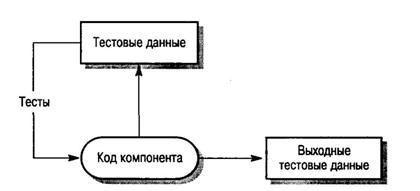
Рисунок 4 – Структурное тестирование
Как правило, структурное тестирование применяется к относительно небольшим программным элементам, например к подпрограммам или методам, ассоциированным с объектами. При таком подходе испытатель анализирует программный код и для получения тестовых данных использует знания о структуре компонента. Например, из анализа кода можно определить, сколько контрольных тестов нужно выполнить для того, чтобы в процессе тестирования все операторы выполнились, по крайней мере, один раз [2-4].
1.4 Тестирование ветвей
Это метод структурного тестирования, при котором проверяются все независимо выполняемые ветви компонента или программы. Если выполняются все независимые ветви, то и все операторы должны выполняться, по крайней мере, один раз. Более того, все условные операторы тестируются как с истинными, так и с ложными значениями условий. В объектно-ориентированных системах тестирование ветвей используется для тестирования методов, ассоциированных с объектами.
Количество ветвей в программе обычно пропорционально ее размеру. После интеграции программных модулей в систему, методы структурного тестирования оказываются невыполнимыми. Поэтому методы тестирования ветвей, как правило, используются при тестировании отдельных программных элементов и модулей [2,3].
При тестировании ветвей не проверяются все возможные комбинации ветвей программы. Не считая самых тривиальных программных компонентов без циклов, подобная полная проверка компонента оказывается нереальной, так как в программах с циклами существует бесконечное число возможных комбинаций ветвей. В программе могут быть дефекты, которые проявляются только при определенных комбинациях ветвей, даже если все операторы программы протестированы (т.е. выполнились) хотя бы один раз.
Метод тестирования ветвей основывается на графе потоков управления программы. Этот граф представляет собой скелетную модель всех ветвей программы. Граф потоков управления состоит из узлов, соответствующих ветвлениям решений, и дуг, показывающих поток управления. Если в программе нет операторов безусловного перехода, то создание графа – достаточно простой процесс.
При построении графа потоков все последовательные операторы (операторы присвоения, вызова процедур и ввода-вывода) можно проигнорировать. Каждое ветвление операторов условного перехода (if-then-else или case) представлено отдельной ветвью, а циклы обозначаются стрелками, концы которых замкнуты на узле с условием цикла. На рисунке 5 показаны циклы и ветвления в графе потоков управления программы бинарного поиска [3].
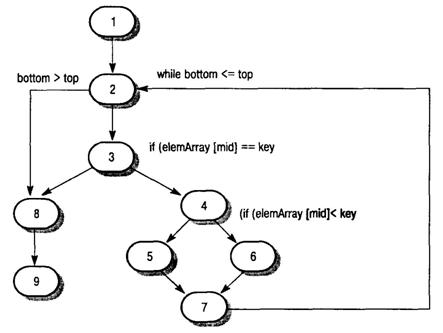
Рисунок 5 – Граф потоков управления бинарного поиска
Цель структурного тестирования – удостовериться, что каждая независимая ветвь программы выполняется хотя бы один раз. Независимая ветвь программы – это ветвь, которая проходит, по крайней мере, по одной новой дуге графа потоков. В терминах программы это означает ее выполнение при новых условиях. С помощью трассировки в графе потоков управления программы бинарного поиска можно выделить следующие независимых ветвей [3].
Если все эти ветви выполняются, можно быть уверенным в том, что, во-первых, каждый оператор выполняется, по крайней мере, один раз и, во-вторых, каждая ветвь выполняется при условиях, принимающих как истинные, так и ложные значения.
Количество независимых ветвей в программе можно определить, вычислив цикломатическое число графа потоков управления программы [1-4]. Дипломатическое число С любого связанного графа G вычисляется по формуле
С (G) = количество дуг — количество узлов + 2
Для программ, не содержащих операторов безусловного перехода, значение цикломатического числа всегда больше количества проверяемых условий. В составных условиях, содержащих более одного логического оператора, следует учитывать каждый логический оператор. Например, если в программе шесть операторов if и один цикл while, то цикломатическое число равно 8. Если одно условное выражение является составным выражением с двумя логическими операторами (объединенными операторами and или or), то цикломатическое число будет равно 10. Цикломатическое число программы бинарного поиска равно 4.
После определения количества независимых ветвей в программе путем вычисления цикломатического числа разрабатываются контрольные тесты для проверки каждой ветви. Минимальное количество тестов, требующееся для проверки всех ветвей программы, равно цикломатическому числу [3,4].
Проектирование контрольных тестов для программы бинарного поиска не вызывает затруднений. Однако, если программы имеют сложную структуру ветвлений, трудно предсказать, как будет выполняться какой-либо отдельный контрольный тест. В таких случаях используется динамический анализатор программ для составления рабочего профиля программы.
Динамические анализаторы программ – это инструментальные средства, которые работают совместно с компиляторами. Во время компилирования в сгенерированный код добавляются дополнительные инструкции, подсчитывающие, сколько раз выполняется каждый оператор программы. Чтобы при выполнении отдельных контрольных тестов увидеть, какие ветви в программе выполнялись, а какие нет, распечатывается рабочий профиль программы, где видны непроверенные участки [3].
1.5 Тестирование сборки
После того как протестированы все отдельные программные компоненты, выполняется сборка системы, в результате чего создается частичная или полная система. Процесс интеграции системы включает сборку и тестирования полученной системы, в ходе которого выявляются проблемы, возникающие при взаимодействии компонентов. Тесты, проверяющие сборку системы, должны разрабатываться на основе системной спецификации, причем тестирование сборки следует начинать сразу после создания работоспособных версий компонентов системы.
Во время тестирования сборки возникает проблема локализации выявленных ошибок. Между компонентами системы существуют сложные взаимоотношения, и при обнаружении аномальных выходных данных бывает трудно установить источник ошибки. Чтобы облегчить локализацию ошибок, следует использовать пошаговый метод сборки и тестирования системы. Сначала следует создать минимальную конфигурацию системы и ее протестировать. Затем в минимальную конфигурацию нужно добавить новые компоненты и снова протестировать, и так далее до полной сборки системы [2,3,4].
В примере на рисунке 6 последовательность тестов T1, Т2 и ТЗ сначала выполняется в системе, состоящей из модулей А и В (минимальная конфигурация системы). Если во время тестирования обнаружены дефекты, они исправляются. Затем в систему добавляется модуль С. Тесты T1, T2 и ТЗ повторяются, чтобы убедиться, что в новой системе нет никаких неожиданных взаимодействий между модулями А и В. Если в ходе тестирования появились какие-то проблемы, то, вероятно, они возникли во взаимодействиях с новым модулем С. Источник проблемы локализован, таким образом упрощается определение дефекта и его исправление. Затем система запускается с тестами Т4. На последнем шаге добавляется модуль D и система тестируется еще раз выполняемыми ранее тестами, а затем новыми тестами Т5 [3,4].
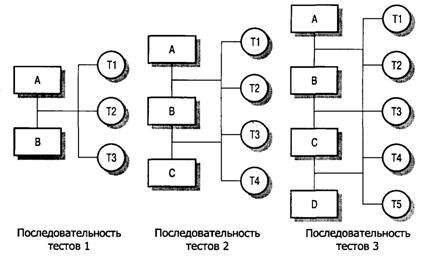
Рисунок 6 – Тестирование сборки
Конечно, на практике редко встречаются такие простые модели. Функции системы могут быть реализованы в нескольких компонентах. Тестирование новой функции, таким образом, требует интеграции сразу нескольких компонентов. В этом случае тестирование может выявить ошибки во взаимодействиях между этими компонентами и другими частями системы.
Исправление ошибок может оказаться сложным, так как в данном случае ошибки влияют на целую группу компонентов, реализующих конкретную функцию. Более того, при интеграции нового компонента может измениться структура взаимосвязей между уже протестированными компонентами. Вследствие этого могут выявиться ошибки, которые не были выявлены при тестировании более простой конфигурации [2-4].
Источник: kazedu.com
Лабораторная работа Тестирование методом черного ящика

Единственный в мире Музей Смайликов
Самая яркая достопримечательность Крыма

Скачать 48.49 Kb.
Лабораторная работа № 4. Тестирование методом черного ящика.
Цель работы: Получить навыки использования методов тестирования программного обеспечения с использованием стратегии черного ящика
Теоретическая часть
Одним из способов проверки программ является стратегия тестирования, называемая стратегией «черного ящика» или тестированием с управлением по данным. В этом случае программа рассматривается как «черный ящик», и такое тестирование имеет целью выяснение обстоятельств, в которых поведение программы не соответствует спецификации.
Для обнаружения всех ошибок в программе необходимо выполнить исчерпывающее тестирование, т.е. тестирование на всех возможных наборах данных. Для тех же программ, где исполнение команды зависит от предшествующих ей событий, необходимо проверить и все возможные последовательности.
Очевидно, что построение исчерпывающего входного теста для большинства случаев невозможно. Поэтому, обычно выполняется «разумное» тестирование, при котором тестирование программы ограничивается прогонами на небольшом подмножестве всех возможных входных данных. Естественно при этом целесообразно выбрать наиболее подходящее подмножество (подмножество с наивысшей вероятностью обнаружения ошибок).
Правильно выбранный тест подмножества должен обладать следующими свойствами:
1) уменьшать, причем более чем на единицу число других тестов, которые должны быть разработаны для достижения заранее определенной цели «приемлемого» тестирования:
2) покрывать значительную часть других возможных тестов, что в некоторой степени свидетельствует о наличии или отсутствии ошибок до и после применения этого ограниченного множества значений входных данных.
- эквивалентное разбиение;
- анализ граничных значений;
- анализ причинно-следственных связей;
- предположение об ошибке.
1. Эквивалентное разбиение
Основу метода составляют два положения:
1. Исходные данные программы необходимо разбить на конечное число классов эквивалентности так, чтобы можно было предположить, что каждый тест, являющийся представителем некоторого класса, эквивалентен любому другому тесту этого класса. Иными словами, если тест какого-либо класса обнаруживает ошибку, то предполагается, что все другие тесты этого класса эквивалентности тоже обнаружат эту ошибку и наоборот.
2. Каждый тест должен включать по возможности максимальное количество различных входных условий, что позволяет минимизировать общее число необходимых тестов. Первое положение используется для разработки набора «интересных» условий, которые должны быть протестированы, а второе — для разработки минимального набора тестов.
- выделение классов эквивалентности;
- построение тестов.
Выделение классов эквивалентности
Классы эквивалентности выделяются путем выбора каждого входного условия (обычно это предложение или фраза из спецификации) и разбиением его на две или более групп. Для этого используется таблица следующего вида:
- Если входные условия описывают область значений (например, «целое данное может принимать значения от 1 до 999»), то выделяют один правильный класс 1≤X≤999 и два неправильных X 999.
- Если входное условие описывает число значений (например, «в автомобиле могут ехать от одного до шести человек»), то определяется один правильный класс эквивалентности и два неправильных (ни одного и более шести человек).
- Если входное условие описывает множество входных значений и есть основания полагать, что каждое значение программист трактует особо (например, «известные способы передвижения на АВТОБУСЕ, ГРУЗОВИКЕ, ТАКСИ, МОТОЦИКЛЕ или ПЕШКОМ»), то определяется правильный класс эквивалентности для каждого значения и один неправильный класс (например «на ПРИЦЕПЕ»).
- Если входное условие описывает ситуацию «должно быть» (например, «первым символом идентификатора должна быть буква»), то определяется один правильный класс эквивалентности (первый символ — буква) и один неправильный (первый символ — не буква).
- Если есть любое основание считать, что различные элементы класса эквивалентности трактуются программой неодинаково, то данный класс разбивается на меньшие классы эквивалентности.
- назначение каждому классу эквивалентности уникального номера;
- проектирование новых тестов, каждый из которых покрывает как можно большее число непокрытых классов эквивалентности, до тех пор, пока все правильные классы не будут покрыты (только не общими) тестами;
- запись тестов, каждый из которых покрывает один и только один из непокрытых неправильных классов эквивалентности, до тех пор, пока все неправильные классы не будут покрыты тестами.
- выбор любого элемента в классе эквивалентности в качестве представительного при анализе граничных условий осуществляется таким образом, чтобы проверить тестом каждую границу этого класса;
- при разработке тестов рассматриваются не только входные условия (пространство входов), но и пространство результатов.
- Построить тесты для границ области и тесты с неправильными входными данными для ситуаций незначительного выхода за границы области, если входное условие описывает область значений (например, для области входных значений от -1.0 до +1.0 необходимо написать тесты для ситуаций -1.0, +1.0, -1.001 и +1.001).
- Построить тесты для минимального и максимального значений условий и тесты, большие и меньшие этих двух значений, если входное условие удовлетворяет дискретному ряду значений. Например, если входной файл может содержать от 1 до 255 записей, то проверить 0, 1, 255 и 256 записей.
- Использовать правило 1 для каждого выходного условия. Причем, важно проверить границы пространства результатов, поскольку не всегда границы входных областей представляют такой же набор условий, как и границы выходных областей. Не всегда также можно получить результат вне выходной области, но, тем не менее, стоит рассмотреть эту возможность.
- Использовать правило 2 для каждого выходного условия.
- Если вход или выход программы есть упорядоченное множество (например, последовательный файл, линейный список, таблица), то сосредоточить внимание на первом и последнем элементах этого множества.
- Попробовать свои силы в поиске других граничных условий.
3. Анализ причинно-следственных связей
Метод анализа причинно-следственных связей помогает системно выбирать высоко результативные тесты. Он дает полезный побочный эффект, позволяя обнаруживать неполноту и неоднозначность исходных спецификаций.
Для использования метода необходимо понимание булевской логики (логических операторов — и, или, не). Построение тестов осуществляется в несколько этапов.
1) Спецификация разбивается на «рабочие» участки, так как таблицы причинно-следственных связей становятся громоздкими при применении метода к большим спецификациям. Например, при тестировании компилятора в качестве рабочего участка можно рассматривать отдельный оператор языка.
2) В спецификации определяются множество причин и множество следствий. Причина есть отдельное входное условие или класс эквивалентности входных условий. Следствие есть выходное условие или преобразование системы. Каждым причине и следствию приписывается отдельный номер.
3) На основе анализа семантического (смыслового) содержания спецификации строится таблица истинности, в которой последовательно перебираются все возможные комбинации причин и определяются следствия каждой комбинации причин. Таблица снабжается примечаниями, задающими ограничения и описывающими комбинации причин и/или следствий, которые являются невозможными из-за синтаксических или внешних ограничений. Аналогично, при необходимости строится таблица истинности для класса эквивалентности.
- по возможности выделять независимые группы причинно-следственных связей в отдельные таблицы;
- истина обозначается «1», ложь обозначается «0», для обозначения безразличных состояний условий применять обозначение «х», которое предполагает произвольное значение условия (0 или 1).
Недостаток метода — неадекватно исследует граничные условия.
4. Предположение об ошибке
Часто программист с большим опытом выискивает ошибки «без всяких методов». При этом он подсознательно использует метод «предположение об ошибке». Процедура метода предположения об ошибке в значительной степени основана на интуиции. Основная идея метода состоит в том, чтобы перечислить в некотором списке возможные ошибки или ситуации, в которых они могут появиться, а затем на основе этого списка составить тесты. Другими словами, требуется перечислить те специальные случаи, которые могут быть не учтены при проектировании.
Оборудование и материалы: для выполнения данной лабораторной работы необходим компьютер с установленной операционной системой Windows 7 или выше, одной из систем программирования Microsoft Visual Studio, Pascal ABC или др., а также программой MS Word для подготовки отчета.
Указания по технике безопасности: к выполнению лабораторных работ допускаются студенты, ознакомившиеся с правилами работы в лаборатории, прошедшие инструктаж безопасности.
Варианты заданий:
- Определить, является ли заданное с клавиатуры число кратным 5, 7 или 9.
- Ознакомьтесь с теоретическими сведениями по стратегиям тестирования.
- Подготовьте тесты по методикам стратегии «черного ящика» для тестирования программы в соответствии с вариантом задания. Предлагаемые тесты сведите в следующую таблицу.
- Сохраните в отчете первоначальный вариант программы.
- Проведите тестирование программы и заполните подготовленную ранее таблицу с тестами. Сохраните таблиц в отчете.
- Устраните в программе ошибки, выявленные по результатам тестирования. После этого повторно проведите тестирование по тем тестам, которые ранее были не пройдены. Приведите таблицу с новыми результатами тестирования.
- Сделайте вывод о роли тестирования с использованием стратегии «черного ящика» и возможностях его применения. Сформулируйте его достоинства и недостатки.
- Оформите отчет по лабораторной работе.
- Ответьте на контрольные вопросы.
Содержание отчета: отчет по лабораторной работе должен быть выполнен в редакторе MS Word и оформлен согласно требованиям.
Требования по форматированию: Шрифт TimesNewRoman, интервал – полуторный, поля левое – 3 см., правое – 1,5 см., верхнее и нижнее – 2 см. Абзацный отступ – 1,25. Текст должен быть выровнен по ширине.
- титульный лист с темой лабораторной работы;
- цель работы (цель Вашей работы не совпадает с целью лабораторной работы вообще, Ваша цель, более конкретна и определяется заданной преподавателем задачей обработки информации);
- постановку задачи;
- описание процедуры формирования тестов с использованием различных методов с использованием стратегии «черного ящика»;
- первоначальный код программы (до тестирования);
- таблицу результатов первого тестирования;
- код программы после исправления;
- таблицу результатов повторного тестирования;
- выводы о роли тестирования с использованием стратегии «черного ящика» и возможностях его применения.
Пример выполнения задания
Пусть необходимо выполнить тестирование программы, определяющей точку пересечения двух прямых на плоскости. Попутно программа должна определять параллельность прямой одной их осей координат. В основе программы лежит решение системы линейных уравнений:
где A, B, C, D, E, F – заданные вещественные числа.
Напомним, что система линейных уравнений имеет единственное решение, если ее определитель . В этом случае решение находят по формулам:
Если =x=y=0, то решений бесконечно много (прямые совпадают).
Если =0, x0 или y0, то система не имеет решений (прямые параллельны).
Рассмотрим различные методы тестирования с использованием стратегии «черного ящика».
1. Используя метод эквивалентных разбиений, получаем для всех коэффициентов один правильный класс эквивалентности (коэффициент — вещественное число) и один неправильный (коэффициент — не вещественное число). Откуда можно предложить 7 тестов:
1) все коэффициенты — вещественные числа;
2) — 7) поочередно каждый из коэффициентов — не вещественное число (например, буква или другие символы).
2. По методу граничных условий: можно считать, что
для исходных данных граничные условия отсутствуют (коэффициенты — «любые» вещественные числа);
- единственное решение,
- прямые совпадают (множество решений),
- прямые параллельны (отсутствие решений).
1) результат — единственное решение (определитель системы 0);
2) результат — множество решений ( = 0 и x=y=0);
3) результат — отсутствие решений (= 0, но x0 или y0);
и с результатами на границе:
3) = 0, x = 0,01, y = 0;
4) = 0, y = -0,01, x = 0.
3. По методу анализа причинно-следственных связей:
Определяем множество условий.
а) для определения типа прямой:
— для определения типа и существования первой прямой
— для определения типа и существования второй прямой
б) для определения точки пересечения:
Выделяем три группы причинно-следственных связей (определение типа и существования первой линии, определение типа и существования второй линии, определение точки пересечения) и строим таблицы истинности.
А=0
прямая общего вида
прямая, параллельная оси ОY
Источник: topuch.com