
Любая IT-инфраструктура нуждается в надежной защите. Информационная безопасность — это тема, которую не охватить за пару уроков. Однако существует некоторый минимум, который поможет защититься от атак непрофессиональных хакеров и ботов. В этой статье рассмотрим, как защитить сервер , используя 6 несложных методов.
Инструменты и методы защиты
Обеспечение защиты сервера от взлома всегда включает комплекс различных мер. Условно методы можно разделить на следующие направления:
- Защита каналов связи, через которые осуществляется администрирование и использование системы.
- Организация нескольких уровней безопасности системы.
- Разграничение доступа к ресурсам инфраструктуры.
- Мониторинг и аудит систем.
- Резервное копирование.
- Своевременные обновления (или откаты) ПО.
- Антивирусная защита серверов .
Далее рассмотрим 6 практических методов, позволяющих получить уровень защиты, который не по зубам непрофессиональным взломщикам и ботам.
Если требуют разблокировать iPhone
В официальном канале Timeweb Cloud собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Разграничение привилегий
При организации доступа к ресурсам следуйте универсальному правилу — процессы и пользователи должны иметь доступ только к тем ресурсам, которые минимально необходимы для работы. Особенно это касается баз данных и операционных систем. Принцип наименьших привилегий поможет наладить защиту сервера от несанкционированного доступа извне, минимизировав ущерб, а также от внутренних угроз.
Для каждого администратора лучше всего создать отдельную учетную запись, а операции, не требующих повышенных прав, нужно выполнять с непривилегированных аккаунтов. При использовании среды Microsoft Active Directory периодически проводите проверки и конфигурирование групповых политик, так как такой механизм в руках злонамеренного администратора или хакера может привести к серьезным нарушениям безопасности.
При работе с *nix системами не следует постоянно работать под учетной записью root . Лучше всего ее отключить и использовать программу sudo . Настройки sudo можно изменить в файле /etc/sudoers или командой visudo . Приведем две полезные директивы defaults , которые помогут следить за тем, кто что делает через sudo .
По умолчанию лог пишется в syslog . Следующая настройка (файл /etc/sudoers ) аккумулирует записи в отдельный файл для удобства:
Defaults log_host, log_year, logfile=»/var/log/sudo.log»
Этот параметр заставляет sudo записывать текст сеанса работы (лог команд, сообщения stdin , stderr , stdout и лог с tty/pty ) в директорию /var/log/sudo-io :
Defaults log_host, log_year, logfile=»/var/log/sudo.log»
Подробнее о работе с файлом sudoers мы писали в отдельной статье.
Мандатное управление доступом
Следующий совет касается Linux-систем и связан с предыдущим. Многие linux-админы довольствуются дискреционными механизмами разграничения доступа, которые являются основными и всегда активны. Между тем во многих дистрибутивах (AppArmor в Ubuntu, SELinux в RHEL-based системах) имеются механизмы мандатного управления. Они требуют более сложной настройки ОС и сервисов, зато позволяют детально разграничить доступ к объектам файловой системы, обеспечивая более надежную программную защиту сервера .
Как создать СВОЙ АНТИВИРУС на КОМПЬЮТЕР?
Удаленное администрирование ОС
При удаленном администрировании операционной системы используйте безопасные протоколы. Для Windows таким считается RDP, в Linux — SSH. Хоть эти протоколы и являются надежными, можно дополнительно усилить защиту.
Для RDP желательно заблокировать подключения учетных записей с пустым паролем. Сделать это можно через «Локальные политики безопасности» и параметр «Учетные записи: Разрешить использование пустых паролей только при консольном входе». Если не используется VPN, RDP-сессии можно защитить безопасным транспортным протоколом TLS, речь о котором пойдет чуть позже.
По умолчанию, проверка личности пользователя в SSH происходит по паролю. Установив аутентификацию по SSH-ключам, вы повысите защиту сервера, так как длинный ключ значительно сложнее подобрать, к тому же не придется вводить пароль (ключ хранится на сервере). Настройка ключей требует всего несколько простых шагов:
Генерация пары ключей на локальной машине:
ssh-keygen -t rsa
Размещение ключей на удаленной станции:
Если не хотите использовать ключи, присмотритесь к программе Fail2ban, которая ограничивает число попыток ввода пароля и блокирует IP-адреса. Также же не лишним будет поменять порты по умолчанию: 22/tcp для SSH, 3389/tcp для RDP.
Настройка фаервола
Правильная система безопасности состоит из уровней. Не стоит надеяться только на механизмы разграничения доступа. Логичней контролировать сетевые соединения до того, как они доберутся до сервисов. Для этого существуют файрволы.
Межсетевой экран (брандмауэр или файрвол) обеспечивает контроль доступа на уровне сети к участкам инфраструктуры. Руководствуясь определенным набором разрешающих правил, файрвол определяет, какой трафик пропускать через периметр. Все, что под правила не попадает, блокируется. Следует заметить, что в Linux, брандмауэр является частью ядра (netfilter), поэтому для работы в пользовательском пространстве необходимо установить фронтенд: nftables, iptables, ufw или firewalld.
Первое, что нужно сделать при настройке фаервола — закрыть неиспользуемые порты и оставить только те, к которым предполагается доступ извне. Например, для веб-сервера это порт 80 (http) и 443 (https). Ничего кардинально опасного в открытом порту нет (угроза может быть в программе, стоящем за портом), но все же лучше убрать лишнее.
Помимо обеспечения внешнего периметра безопасности, межсетевые экраны помогают разделить инфраструктуру на сегменты и контролировать трафик между ними. Если у вас имеются общедоступные сервисы, подумайте, можно ли их изолировать от внутренних ресурсов (DMZ). Также советуем присмотреться к системам обнаружения и предотвращения вторжений (IDS/IPS). Этот вид решений работает по обратному принципу — заблокировать проблему безопасности, все остальное пропустить.
Виртуальные частные сети
До этого мы рассматривали, как защитить сервер от взлома . Теперь рассмотрим защиту нескольких серверов. Сейчас виртуальные частные сети (VPN) чаще всего применяют в качестве анонимайзера и инструмента доступа к недоступным ресурсам. Однако основное их назначение – безопасное объединение сетей филиалов организаций. В своей сути VPN представляет собой логическую сеть поверх другой сети (например, Интернет). Безопасность обеспечивается средствами криптографии, поэтому защищенность соединений не зависит от безопасности базовой сети.
Существует множество VPN-протоколов. Выбор зависит от размеров организации, сети и требуемого уровня безопасности. Для маленькой фирмы и домашней локальной сети подойдет классический PPTP: почти на любом роутере или телефоне есть возможность настроить pptp. Из недостатков можно отметить устаревшие методы шифрования. Для высокого уровня защищенности и соединений типа сеть-сеть подходящим будут протоколы IPsec, для соединений сеть-узел — OpenVPN и WireGuard Однако они требуют более тонкой настройки, в отличие от PPTP.
TLS и инфраструктура открытых ключей
Многие протоколы прикладного уровня разрабатывались во времена, когда сети не выходили за пределы институтов и военных учреждений, а web еще не изобрели. HTTP, FTP, SMTP и другие популярные протоколы передают данные в виде обычного текста. Если хотите обеспечить защиту сайта, веб-панели управления внутренним сервисом или почты, используйте TLS.
TLS — это протокол защиты транспортного уровня, предназначенный для безопасной передачи данных в небезопасной сети. Хоть вместе с TLS часто встречается название SSL (SSL-сертификат, пакет OpenSSL), учитывайте, что современной версией протокола является TLS 1.2/1.3. Ранние версии TLS и протокол-предшественник SSL считаются устаревшими.
TLS позволяет обеспечить приватность, целостность данных и аутентификацию ресурса. Последнее достигается с помощью цифровой подписи и инфраструктуры открытых ключей (PKI). PKI работает следующим образом: подлинность сервера определяется SSL-сертификатом, который подписывается удостоверяющим центром (CA). Сертификат центра в свою очередь подписывается вышестоящим CA и так далее по цепочке. Сертификаты корневого центра являются самоподписанными, то есть доверие к ним подразумевается по умолчанию.
TLS также можно использовать вместе с VPN, например настроить авторизацию клиентов по SSL-сертификатам или TLS handshake. В таком случае необходимо внутри локальной сети самостоятельно организовать инфраструктуру открытых ключей (сервер CA, ключи и сертификаты узлов).
Чем опасны взломщики?
Степень опасности угрозы зависит от ее вида. Атаки условно делятся на несколько видов.
Первый вид связан с проникновением за периметр безопасности. В этом случае злоумышленник получает доступ к учетной записи авторизованного пользователя сервиса или системы, например базы-данных. Угрозу представляют взломы привилегированных аккаунтов, так как в руки хакера попадают средства просмотра секретной информации и изменения параметров системы. Критически опасная разновидность «проникновения» — несанкционированный доступ к учетной записи суперпользователя операционной системы. В подобной ситуации под удар попадает большая часть инфраструктуры.
Другой вид атак нацелен на вывод системы из строя. Подобные угрозы не подразумевают утечек данных, но это не делает их менее опасными. Самая показательная атака такого рода — DoS и DDoS. Их суть заключается в том, что злоумышленники нагружают сервер лавиной обращений. Рабочий сервер не справляется с нагрузкой и перестает отвечать на запросы пользователей.
Иногда DoS бывает подспорьем для осуществления других атак.
Результатами атак часто становится утечки данных, финансовый и репутационный ущерб, поэтому при налаживании IT-инфраструктуры важно продумать хотя бы минимальный уровень безопасности.
Источник: timeweb.cloud
Как самостоятельно создать систему защиты персональных данных

Организации, которые обрабатывают персональные данные в бухгалтерских и кадровых программах, часто сталкиваются с вопросом, достаточно ли защищено программное обеспечение. Рассмотрим, как соблюдать требования Федерального закона от 27.07.2006 № 152-ФЗ (далее — 152-ФЗ) при работе в сервисах.
Как организации привести в порядок процессы обработки и защиты персональных данных
Напомним, что приведение процессов обработки и защиты персональных данных (далее — ПДн) в соответствие с действующими требованиями законодательства РФ в общем случае выглядит следующим образом:
- Обследование организации на предмет соответствия процессов обработки и защиты ПДн требованиям 152-ФЗ.
- Разработка комплекта внутренней организационно-распорядительной документации, которая регламентирует процессы обработки и защиты ПДн.
- Определение угроз безопасности и потенциальных нарушителей безопасности ПДн, обрабатываемых в информационной системе ПДн.
- Определение требуемого уровня защищенности ПДн, обрабатываемых в информационной системе ПДн.
- Разработка технического задания на создание системы защиты ПДн.
- Приобретение средств защиты информации.
- Внедрение системы защиты ПДн.
- Организация и проведение аттестации соответствия системы защиты ПДн требованиям безопасности информации.
Аттестация не является обязательной, однако получение аттестата соответствия даст уверенность в том, что меры, реализованные в рамках системы защиты ПДн, достаточно эффективны и удовлетворяют всем требованиям безопасности информации.
Сертифицированное бухгалтерское или кадровое ПО в данном контексте может рассматриваться лишь как средство защиты информации.
Пример
Информационная система отдела кадров небольшой организации регулярно работает с ПДн сотрудников. Их она ведет в специальных учетных программах. Еще, чтобы работать с ПДн, компания разработала организационно-распорядительные документы, ознакомила работников с требованиями 152-ФЗ, ограничила доступ в помещения обработки ПДн, внедрила охранную сигнализацию, но не внедрила технические средства защиты информации.
В этом случае оператор ПДн должен составить модель угроз и определить требуемый уровень защищенности ПДн, чтобы в дальнейшем разработать систему защиты ПДн.
Построение системы защиты персональных данных
Предположим, что компании требуется 4-й уровень защищенности ПДн при их обработке в информационной системе.
Рассмотрим техническую реализацию отдельно выбранных мер по обеспечению безопасности ПДн:
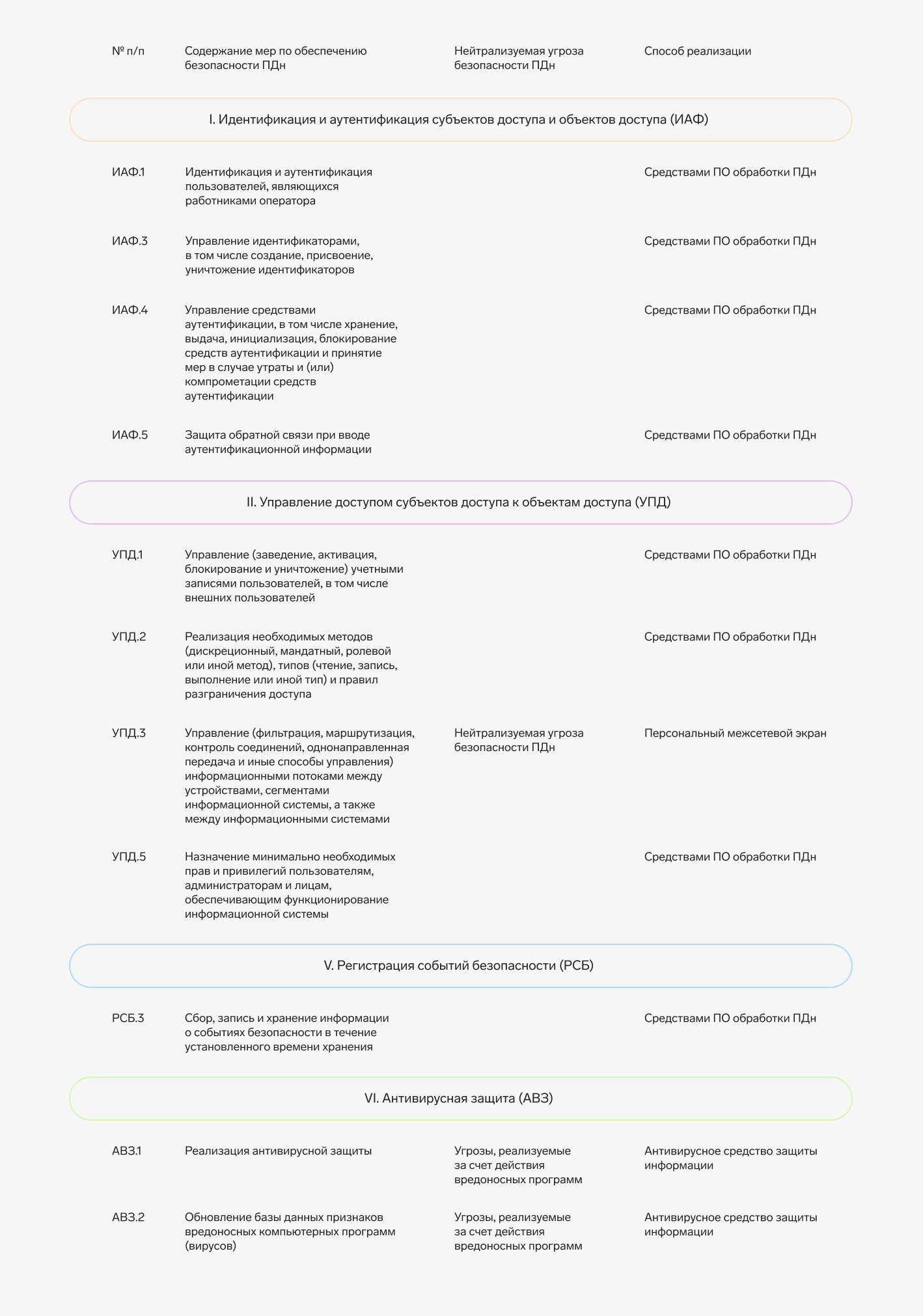
Как видно из таблицы выше, для нейтрализации актуальных угроз безопасности ПДн используются межсетевой экран и антивирусные средства защиты информации. Кроме того, согласно Приказу ФСТЭК РФ от 18.02.2013 № 21, для обеспечения 4-го уровня защищенности ПДн межсетевой экран и антивирусное средство должны иметь сертификаты соответствия не ниже 5-го класса по требованиям безопасности информации средств защиты информации.
ПО обработки ПДн также используется в качестве способа реализации требований Приказа ФСТЭК РФ от 18.02.2013 № 21, однако оно не используется для нейтрализации актуальных угроз безопасности ПДн, а следовательно, процедура оценки соответствия такого ПО не требуется.
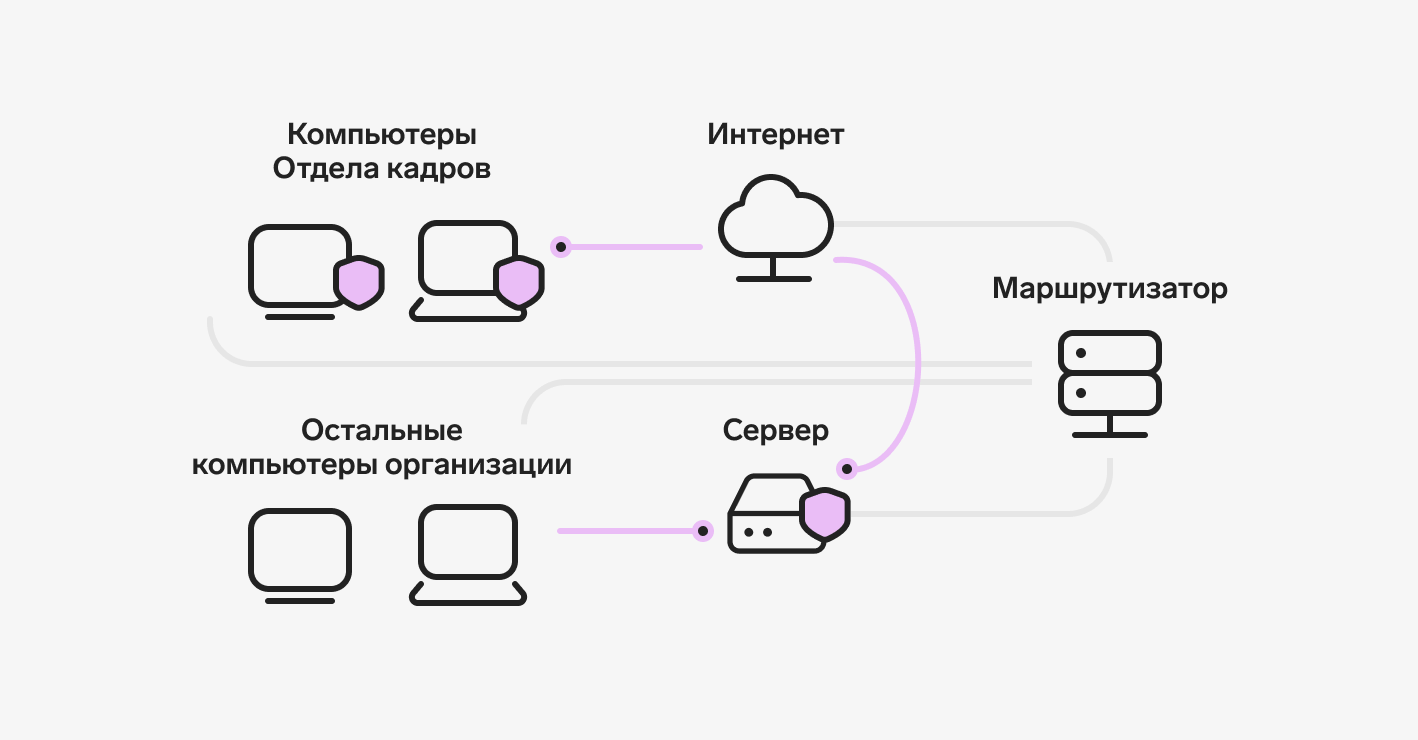
Текущая система защиты ПДн позволит разграничить доступ к серверу обработки ПДн и защитит рабочие станции от актуальных угроз безопасности.
Выводы
Наличие у программы сертификата соответствия ФСТЭК не решает проблемы защиты ПДн. Существует множество средств защиты информации и сценариев их использования. Для построения эффективной и адекватной системы защиты ПДн важно понимать принципы и порядок реализации мер, направленных на обеспечение безопасности ПДн.
Защита персональных данных — это комплекс мероприятий, направленных на обеспечение безопасности персональных данных, и внедрение системы защиты является лишь одним из этапов обеспечения безопасности.
Рекомендации по защите персональных данных
Не стоит забывать о поддержании созданной системы защиты ПДн в актуальном состоянии. Периодически необходимо проверять актуальность организационно-распорядительной документации, обновлять модель угроз и контролировать обеспечение установленного уровня защищенности ПДн.
Безопасность
Комплекс услуг по обеспечению информационной безопасности предприятия. Подключение к ГИС: АИСТ ГБД, ЕГИСМ и др.
Безопасность
Комплекс услуг по обеспечению информационной безопасности предприятия. Подключение к ГИС: АИСТ ГБД, ЕГИСМ и др.
Источник: kontur.ru
Виртуалка своими руками. Как обфусцировать код при помощи виртуализации и что делать с такой защитой

Есть множество решений для защиты программ, которые определяют работу внутри изолированных сред, работают с антиотладочными приемами, контролируют целостность своего кода и динамически шифруют свои данные в памяти, защищаясь от дампа. Еще одна мощная техника защиты — это виртуализация кода. В этой статье я покажу, как она работает.
![]()
INFO
Читай другие статьи автора по теме дебага и защиты от него.
- Тайный WinAPI. Как обфусцировать вызовы WinAPI в своем приложении
- Детект песочницы. Учимся определять, работает ли приложение в sandbox-изоляции
- Антиотладка. Теория и практика защиты приложений от дебага
- Набор программ для взлома программ. Выбираем инструменты для реверса
Здесь я имею в виду не виртуальные машины вроде VirtualBox или VMware, а те, при помощи которых запутывают исполняемый код, чтобы затруднить анализ программной логики. В этой статье мы коснемся принципов работы виртуальных машин, компиляторов, трансляции кода, а также напишем свою виртуальную машину, которая будет понимать наш собственный язык программирования.
Итак, виртуальные машины, предназначенные для запутывания кода, основаны на идее замены «обычного» байт-кода, который, например, используется в архитектуре x86-64, на тот байт-код, который мы изобретем сами. Чтобы реконструировать поток управления в программе, подвергшейся виртуализации, необходимо проанализировать каждый опкод и разобраться, что он делает. Чтобы понимать, что происходит, нужно немного коснуться работы процессора — ведь, по сути, перед нами стоит задача «написать процессор».
Нам предстоит написать некое подобие транслятора-интерпретатора кода — чтобы исходный код, который мы будем писать, начал обрабатываться внутри нашей виртуальной машины. Можно провести аналогию с процессорами: современные процессоры представляют собой сложные устройства, которые управляются микрокодом. Многие наборы инструкций, особенно современные, типа Advanced Vector Extensions (AVX), — это, по сути, подпрограммы на микрокоде процессора, который, в свою очередь, напрямую взаимодействует с железом процессора.
Получается, что современные процессоры похожи больше на софт, а не на железо: сложные инструкции типа VBROADCASTSS , VINSERTF128 , VMASKMOVPS реализованы исключительно «софтверно» при помощи программ, состоящих из микрокодов. А таких наборов инструкций, как ты, возможно, знаешь, много — достаточно открыть техническое описание какого-нибудь Skylake и посмотреть на поддерживаемые наборы инструкций.
![]()
INFO
Микропрограммы процессора состоят из микроинструкций, а они, в свою очередь, реализуют элементарные операции процессора — операции, которые уже нельзя разделить на более мелкие, например работа с арифметико-логическим устройством (АЛУ) процессора: подсоединение регистров к входам АЛУ, обновление кодов состояния АЛУ, настройка АЛУ на выполнение математических операций.
Стековая виртуальная машина
Нам необходимо будет эмулировать, помимо работы процессора, работу памяти (RAM). Для этого мы воспользуемся реализацией собственного стека, который будет работать по принципу LIFO.
![]()
INFO
LIFO (last in, first out) — способ организации хранения данных, который похож на стопку журналов на столе: если нужный журнал лежит в середине стопки, нельзя его просто вытащить, можно только поочередно убирать журналы сверху и так до него добраться. Получается, мы всегда работаем только с верхушкой этой стопки.
В этом нет ничего сложного — по сути, это просто массив данных с указателем на них. Для наглядности код:
// Размер памяти VM const int MAXMEM = 5; // Массив памяти, который состоит из элементов типа int int stack[MAXMEM]; // Указатель на положение данных в стеке, сейчас стек не инициализирован int sp = -1;
Этот стек станет оперативной памятью нашей виртуальной машины. Чтобы путешествовать по нему, достаточно обычных операций с массивами:
stack[++sp] = data1; // Положим данные int data2 = stack[—sp]; // Возьмем данные
Далее, чтобы наша память не «сломалась», нам необходимо позаботиться о проверках, чтобы не срабатывали попытки взять данные, когда память пуста, либо положить больше данных, чем она может вместить.
// Проверка стека на пустоту // Функция вернет TRUE (1), если стек пуст, // и FALSE (0), если данные есть int empty_sp() < return sp == -1 ? 1 : 0; >// Проверка стека на заполненность // Функция вернет TRUE (1), если стек полон, // и FALSE (0), если место еще есть int full_sp()
Как видишь, никакой магии нет! Мы успешно запрограммировали память для нашей будущей VM. Далее переходим к командам. Создадим перечисление под названием mnemonics и заполним его инструкциями для нашей VM (читай комментарии):
// Поддерживаемые мнемоники VM typedef enum < // Положить значение на стек. Этот параметр имеет один аргумент PUSH = 0x00d00201, // Получить значение со стека. Берется верхушка стека POP = 0x00d00205, // Сложить два верхних значения стека ADD = 0x00d00202, // Вычесть два верхних значения стека SUB = 0x00d00206, // Поделить два значения DIV = 0x00d00203, // Перемножить два значения.
Во всех четырех операциях результат кладется на стек MUL = 0x00d00204, // Ввести данные ENTER = 0x00d00211, // Сверка данных с шаблоном TEST = 0x00d00209, // Вывести верхушку стека PRINT = 0x00d00210, // Вывести все данные, которые находятся в нашей памяти RAM = 0x00d00208, // Завершить работу виртуальной машины EXIT = 0x00d00207 >mnemonics;
У каждой мнемоники есть значение в шестнадцатеричном формате, которое мы присвоили самостоятельно. Если бы мы не сделали этого, в перечислении все элементы были бы пронумерованы начиная с нуля с шагом в единицу. Зачем мы так поступили, я объясню позже, а мы теперь готовы написать программу, которая состоит из наших инструкций, я также ее прокомментирую.
// Исполняемый код const int code[] = < PUSH, 22, // Кладем на стек 22 PUSH, 45, // Кладем на стек 45 RAM, // Выводим содержимое памяти SUB, // Вычитание POP, // Вытащить результат из стека PUSH, 23, // Кладем на стек 23 PUSH, 9, // Кладем на стек 9 PUSH, 5, // Проверка на ошибку RAM, // Выводим содержимое памяти PRINT, // Выводим верхушку стека ADD, // Сложение POP, // Вытащить результат PUSH, 7, // Кладем на стек 7 PUSH, 7, // Кладем на стек 7 RAM, // Выводим содержимое памяти ADD, // Сложение POP, // Вытащить результат POP, // Проверка на ошибку ENTER, // Ввод данных PRINT, // Выводим верхушку стека TEST, // Проверяем данные EXIT // Остановка VM >;
Как видишь, это такой же простой массив. Единственное, что может немного смутить, — манера записи, но это лишь для наглядности.
Кроме того, нам понадобится еще одна переменная, чтобы перемещаться по коду в случае необходимости.
int ip = 0; // Указатель на инструкцию (мнемонику)
Теперь мы подошли к самому интересному — основному циклу виртуальной машины. Именно этот цикл оживит наши инструкции и придаст им смысл. Я приведу полный листинг с комментариями.
// Трансляция кода VM void decoder(int instr) < switch (instr) < case PUSH: < // Проверяем, есть ли место в памяти if (full_sp()) < printf(«Memory is fulln»); break; >// Перемещаемся в свободную ячейку памяти sp++; // В массиве кода берем следующее за мнемоникой PUSH значение // и кладем его в ячейку памяти stack[sp] = code[++ip]; break; > case POP: < // Проверка памяти на пустоту if (empty_sp()) < printf(«Memory is emptyn»); break; >// Берем значение с верхушки стека int pop_value = stack[sp—]; // и выводим его printf(«Result: %d n», pop_value); break; > case ADD: < // Берем два верхних значения стека int a = stack[sp—]; int b = stack[sp—]; sp++; // Складываем их и кладем результат на стек stack[sp] = b + a; // Выводим сообщение printf(«ADD->»); break; > case SUB: < // Берем два верхних значения стека int a = stack[sp—]; int b = stack[sp—]; sp++; // Вычитаем их и кладем результат на стек stack[sp] = a — b; // Выводим сообщение printf(«SUB->»); break; > case DIV: < // Берем два верхних значения стека int a = stack[sp—]; int b = stack[sp—]; sp++; // Делим их и кладем результат на стек stack[sp] = a / b; // Выводим сообщение printf(«DIV->»); break; > case MUL: < // Берем два верхних значения стека int a = stack[sp—]; int b = stack[sp—]; sp++; // Перемножаем их и кладем результат на стек stack[sp] = a * b; // Выводим сообщение printf(«DIV->»); break; > case RAM: < // Это простой цикл вывода всех значений массива int x = sp; for (; x >= 0; —x) < printf(«RAM[%u]: %un», x, stack[x]); >break; > case TEST: < // Сверка верхнего значения стека с числом 0x31337 // Если числа совпадают, выводится сообщение «Good Pass!», // иначе «Bad Pass!» stack[sp—] == 0x31337 ? printf(«Good Pass!n») : printf(«Bad Pass!n»); break; >case PRINT: < printf(«PRINT Stack[%u]: %un», sp, stack[sp]); break; >case ENTER: < printf(«ENTER Password: «); // Перемещаемся вверх по памяти // и при помощи scanf_s записываем данные в наш массив // Введенные данные окажутся на верхушке массива sp++; scanf_s(«%i», break; >case EXIT: < // Установка глобальной переменной в FALSE, // чтобы прервать работу VM VM = false; printf(«Exit VMn»); break; >> >
Разумеется, это не самый стабильный код в мире, и можно добавить еще разные проверки для повышения стабильности, но я попытался найти золотую середину между сложностью кода и легкостью его восприятия.
Итак, мы реализовали команды виртуальной машины. Давай теперь ее запустим!
int main() < while (VM) < // Переменная, которая контролирует работу VM decoder(code[ip]); ip++; >system(«pause»); >
Надо сказать, что я установил значение переменной MAXMEM равным единице, чтобы память VM вмещала только два значения. Нам все равно больше не нужно, но это полезно для демонстрации работы функций, которые контролируют переполнение или опустошение памяти. Вот скриншот работы виртуальной машины.


Другие статьи в выпуске:
Xakep #239. Вскрыть и изучить
- Содержание выпуска
- Подписка на «Хакер» -60%
Вроде бы все работает как надо. Теперь давай посмотрим, как распутывать код, который спрятан внутри подобной виртуалки.
На самом деле все очень просто: нужно загрузить этот файл в дизассемблер, найти наш цикл switch/case и посмотреть на места, где происходит сравнение с нашими константами-инструкциями. Заглянув в каждое ветвление после сравнения с константой, можно определить, за что отвечает эта константа-инструкция.
В итоге можно написать автоматический скрипт, прогон которого будет раскладывать весь наш байт-код и давать верные имена подпрограммам, которые представляют инструкции виртуальной машины. Получается, потратив некоторое время на анализ виртуальной машины, можно потом написать универсальный скрипт, который будет «снимать» эту VM с любой программы. Мы ведь будем знать все значения констант-инструкций! Но это не совсем так.
Помнишь перечисление mnemonics , в котором мы присваивали значения нашим командам? Я обещал еще вернуться к нему. Его можно записать немного по-другому:
static unsigned long time = (unsigned int)__TIMESTAMP__; #define time x typedef enum < // Положить значение на стек. Этот параметр имеет один аргумент PUSH = 0x00d00201 ^ x, // Получить значение со стека. Берется верхушка стека POP = 0x00d00205 ^ x, // Сложить два верхних значения стека ADD = 0x00d00202 ^ x, // Вычесть два верхних значения стека SUB = 0x00d00206 ^ x, // Поделить два значения DIV = 0x00d00203 ^ x, // Перемножить два значения.
Во всех четырех операциях результат кладется на стек MUL = 0x00d00204 ^ x, // Ввести данные ENTER = 0x00d00211 ^ x, // Сверка данных с шаблоном TEST = 0x00d00209 ^ x, // Вывести верхушку стека PRINT = 0x00d00210 ^ x, // Вывести все данные, которые находятся в нашей памяти RAM = 0x00d00208 ^ x, // Завершить работу виртуальной машины EXIT = 0x00d00207 ^ x, >mnemonics;
Ничего необычного, просто операция xor (побитовое исключающее ИЛИ) применяется к каждому значению кодов наших мнемоник. Но обрати внимание на то, как инициализируется эта переменная.
static unsigned long time = (unsigned int)__TIMESTAMP__;