

Все началось с того, что мне стало трудно находить нужную информацию, файлы. Чем больше файлов и папок у меня образовывалось, тем больше времени уходило на поиски нужного. Я понял, что каждый раз искать в бесконечных списках файлов и папок, особенно с условием вложенности это не вариант для больших объемов данных.
Что касается поиска по названию файла, то количество символов, указанных в названии ограниченно и слова при поиске должны быть в строго определенной последовательности. Тем более, если система индексирует другие, не нужные для поиска файла (системные файлы, файлы проектов), то поиск выдает много «мусора».
Более того по содержанию можно искать только текстовые файлы.
Структура содержания информации
Структура папок представляется собой в виде дерева. Мне это не нравится, потому что каждая папка может содержать только определенные файлы, если не учитывать копирование и ссылки.
Так же это можно представить с примером из реальной жизни, для того, чтобы найти зелёное свежее яблоко сорт «Девственный». Необходимо найти отдел с фруктами, затем отдел с яблоками, затем ищем зеленные, затем сорт, ну там ещё их на свежие, не свежие фасуют в этом воображаемом примере и наконец найти нужное apple.
Усложняется ещё все и тем, что я не помню есть ли там вообще яблоки, и если есть, то хранятся ли они в отделе фрукты.
А почему бы об этом просто не попросить прихвостня(они уже у всех есть, правда?) — «Принеси мне зелёное свежее яблоко».
Как сразу становится удобно!
В общем, всем этим я хочу сказать, что поиск нужной информации в папках хорош, если папок немного и если помнить какие папки существуют, а не перебирать все подряд.
А вот если мы не знаем существуют ли яблоки вообще, то спрашиваем прихвостня:
— Есть, господин! Сотни, игрушечные, красные, гнилые.
— Мне нужно свежее яблоко.
— Понял! Есть красное свежее яблоко «Сирота», красное свежее яблоко «Курага».
— А что насчёт зелёного свежего яблока.
— Есть! Зелёное свежее яблоко «Пух-тибидух» и Зелёное свежее яблоко «Девственный».
— В таком случае, принеси мне, пожалуй, Зелёное свежее яблоко «Девственный».
Вот последняя фраза как раз таки и стала названием приложения. Как ответ на команду пользователя — «Yes Sir».
Возвращаясь к яблокам. Заметили, что в первом случае нужно искать яблоки не пойми где, а во втором мы задаём уточняющие условия к запросу?

Приведу пример более реалистичный. Есть папка с музыкой и подпапки для разделения на жанры. Но что если в какой-то момент мне захочется послушать французскую музыку не зависимо от жанра. Вот тут то и вся проблемность древовидной структуры папок вылазит. Можно конечно, как советовали на форумах, создавать отдельные папки под язык произведения и кидать ссылки, но опять папки.
Как написать программу поиска телефонных номеров на Python? 1 часть.
А вот, что произойдет, если каждому файлу установить теги с жанром, языком, ну и конечно что это музыка, песня.
В этом случае возможно группировать, сортировать музыку гораздо гибче. Например, скомбинировав 3 тега: французская, русская, рок можно получить то, чего стандартными средствами Windows не возможно, ну или я чего-то не знаю.
Попытки найти готовое решение
Первой идеей было воспользоваться «тегированием» файлов, папок. Таким образом можно искать информацию комбинируя теги, не зависимо от порядка слов. И лучшими приложениями для этого, могу выделить XYplorer и Tagging for windows. Первая из себя представляет отдельный файловый менеджер с опцией тегирования. Второе приложение — дополнение к стандартному файловому менеджеру.
Однако они позволяют искать файлы только на ПК и конечно нельзя написать как в Гугл поисковике запрос близкий к пользователю, а алгоритм уже бы сам выбрал из запроса теги и отсортировал информацию по приоритету. В последствии удалил обе, они подвисали и крашились частенько (возможно дело в моих надстройках Windows, не хочу делать анти пиар этих отличных программ).
Визуальный поиск
В попытках найти оптимальный способ поиска доходило до странного. Я больше визуал и поэтому загружал изображения более менее подходящее по теме информации в социальную сеть ВКонтакте, а саму информацию сохранял в комментариях под изображениями. Это дало некоторый прирост в скорости поиска и пользоваться можно с любого устройства.
Но как вы, наверное, понимаете долго это продолжаться не могло. В конечном итоге я стал задумываться а к какой информации относится это изображение, на котором рельсы — означает адреса знакомых или желаемые места для путешествия. Ну а уж то, что под одним изображением образуется портянка из информации без возможности вложенности — это фиаско, бро.
Желаемый функционал
Я подумал, что было бы отлично разработать приложение, которое бы подходило по таким критериям:
- Можно использовать с любого устройства без возможности подключения к интернету.
- Поиск личной информации настолько быстро, насколько это возможно.
- Поиск должен быть простым как Google Search.
- Возможность сохранить всю текстовую информацию в текстовый файл.
Выбор технологий
1. По первому пункту из желаний было решено разработать веб приложение, так как с любого устройства, на котором есть браузер, можно получить к нему доступ. Данные хранятся в localstorage браузера, но при открытии сайта сразу выгружаются в переменную для обеспечения лучшей скорости.
Для синхронизации данных с другим устройством, браузером я взял базу данных mysql от 000webhost бесплатно, но потом перестал использовать из-за ограничений на объем. Сейчас единственный способ для обновления пользовательских данных — импорт и экспорт файла. Однако я делаю это очень редко, т.к. в основном пользуюсь только со смартфона. Что касается офлайн режима — я использовал serviceworking. Необходимо только один раз зайти на сайт, чтобы все ресурсы сайта загрузились и дальше использовать полностью офлайн из браузера.
2. Быстрый поиск.
Раз поиск должен осуществляться подобно Гугл поисковику, то нужно чтобы каждое слово из запроса проверять на существующий из уже созданного блока информации. Таким блоком у меня выступает объект с ключами: уникальное название блока, действие(показать информацию, открыть ссылку. ), содержимое, теги.
Итак, по ключу «теги» у нас будет храниться массив из символов(слов) для конкретного блока информации.
Сразу возьмём пример блока.
Название: как создать сайт.
Действие: показать информацию.
Содержимое: берём html, добавляем js и украшаем css.
Теги: создание сайта, веб программирование, верстка.
Массив из тегов формируется из текстов полученных с полей ввода для тегов и названия. Каждое слово это тег, разделять можно запятой и пробелом. Была идея конечно сделать как на Ютубе, теги как словосочетания, но я решил остановиться на более широкой выдаче по ключевым словам. Из примера блока выше массив тегов будет таким: [«как», «создать», «сайт», «создание», «сайта», «веб», «программирование», «верстка»].
Теперь самое важное — определиться как будет происходить поиск. Первое, что пришло в голову это брать каждое слово из поискового запроса и сравнивать с каждым словом из тега каждого блока. В голову как пришло, так и ушло, это отвратительная идея. Следующей идеей было создание объекта, в котором каждый тег это отдельный ключ, а значение это массив из индексов блоков.
3. Итак, при вводе запроса проверяется есть ли слово в хранилище тегов, если да, то блок добавляется в массив на отображение.Теперь нужно отсортировать по приоритету. Чем выше результат в выдаче, тем более он подходит запросу. Это я реализовал с помощью количества ключевых слов в запросе, чем больше слов из запроса содержится в массиве тегов блока, тем более блок приоритетнее.
4. И насчёт сохранение в файл совсем кратко. Можно сохранять и импортировать файл в виде json.Так же мой опыт с использованием ВКонтакте как поисковик по изображениям дал мне идею для возможности добавлять изображение к каждому блоку при желании.
Итоги
В результате я сделал то, чем пользуюсь уже больше года. Как веб, так и ПК версия оказались очень полезными. Использую для работы и личной жизни. Скорость поиска, которую я в итоге получил меня многократно выручала, когда нужно было найти что-то очень быстро.
Ответвление в другие проекты
Веб приложение мне настолько понравилось, что я захотел написать программу для исполнения программ по команде от запроса пользователя на ПК. Вдохновлённый голосовыми помощниками, я создал программу, которая ищет и исполняет файлы. А поиск соответственно так же подобен веб поисковику. Особенность в том, что можно перетащить файл/файлы напрямую в программу и алгоритм автоматически установит теги исходя из названия файла и папок, в которых он содержится. Но это тема другого поста, если этот окажется интересным.
Послесловие
Буду рад любым комментариям. Узнать ваше мнение по поводу идеи. Полная ли это ерунда. Или, в чем я почти не сомневаюсь, есть уже приложения с подобной реализацией.
Источник: habr.com
Как я написал свою поисковую систему для быстрого поиска личной информации
Все началось с того, что мне стало трудно находить нужную информацию, файлы. Чем больше файлов и папок у меня образовывалось, тем больше времени уходило на поиски нужного. Я понял, что каждый раз искать в бесконечных списках файлов и папок, особенно с условием вложенности это не вариант для больших объемов данных.
Что касается поиска по названию файла, то количество символов, указанных в названии ограниченно и слова при поиске должны быть в строго определенной последовательности. Тем более, если система индексирует другие, не нужные для поиска файла (системные файлы, файлы проектов), то поиск выдает много «мусора».

Курс «Java для Android-разработчиков»
Более того, по содержанию можно искать только текстовые файлы.
Ссылка на проект — тут.
Структура содержания информации
Структура папок представляется собой в виде дерева. Мне это не нравится, потому что каждая папка может содержать только определенные файлы, если не учитывать копирование и ссылки.
Так же это можно представить с примером из реальной жизни, для того, чтобы найти зелёное свежее яблоко сорт «Девственный». Необходимо найти отдел с фруктами, затем отдел с яблоками, затем ищем зеленные, затем сорт, ну там ещё их на свежие, не свежие фасуют в этом воображаемом примере и наконец найти нужное apple.
Усложняется ещё все и тем, что я не помню есть ли там вообще яблоки, и если есть, то хранятся ли они в отделе фрукты.
А почему бы об этом просто не попросить прихвостня (они уже у всех есть, правда?): «Принеси мне зелёное свежее яблоко».
Как сразу становится удобно!
В общем, всем этим я хочу сказать, что поиск нужной информации в папках хорош, если папок немного и если помнить какие папки существуют, а не перебирать все подряд.
А вот если мы не знаем существуют ли яблоки вообще, то спрашиваем прихвостня:
— Есть, господин! Сотни, игрушечные, красные, гнилые….
— Мне нужно свежее яблоко.
— Понял! Есть красное свежее яблоко «Сирота», красное свежее яблоко «Курага», …
— А что насчёт зелёного свежего яблока.
— Есть! Зелёное свежее яблоко «Пух-тибидух» и Зелёное свежее яблоко «Девственный».
— В таком случае, принеси мне, пожалуй, Зелёное свежее яблоко «Девственный».
Вот последняя фраза как раз таки и стала названием приложения. Как ответ на команду пользователя — «Yes Sir».
Возвращаясь к яблокам. Заметили, что в первом случае нужно искать яблоки не пойми где, а во втором мы задаём уточняющие условия к запросу?
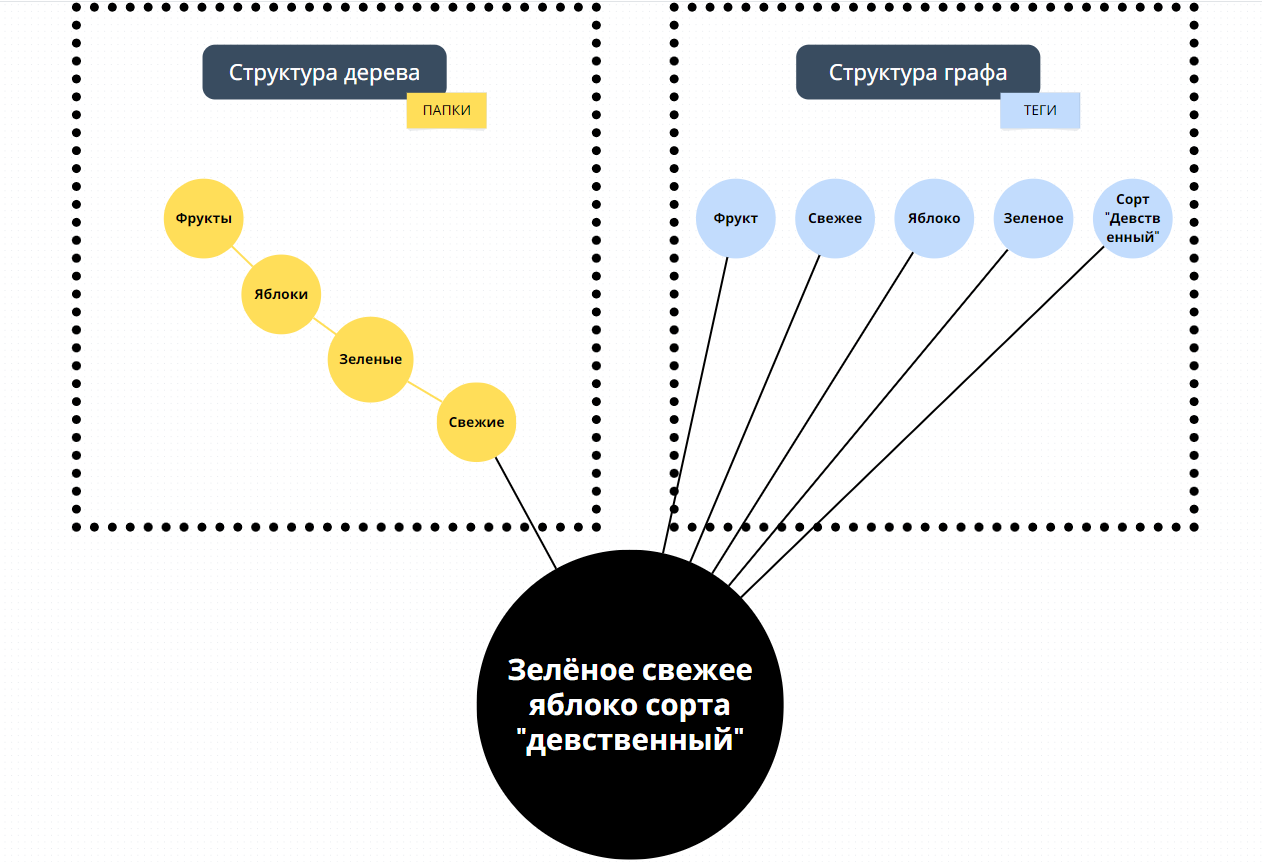
Для нахождения нужного результата, используя древовидную структуру (папки), приходится обходить все узлы. А в случае графа (теги) можно получить результат, в лучшем случае, за проход по единственному узлу.
Приведу пример более реалистичный. Есть папка с музыкой и подпапки для разделения на жанры. Но что если в какой-то момент мне захочется послушать французскую музыку не зависимо от жанра. Вот тут то и вся проблемность древовидной структуры папок вылазит. Можно конечно, как советовали на форумах, создавать отдельные папки под язык произведения и кидать ссылки, но опять папки…
А вот, что произойдет, если каждому файлу установить теги с жанром, языком, ну и конечно что это музыка, песня.
В этом случае возможно группировать, сортировать музыку гораздо гибче. Например, скомбинировав 3 тега: французская, русская, рок можно получить то, чего стандартными средствами Windows не возможно, ну или я чего-то не знаю.
Попытки найти готовое решение
Первой идеей было воспользоваться «тегированием» файлов, папок. Таким образом можно искать информацию комбинируя теги, не зависимо от порядка слов. И лучшими приложениями для этого, могу выделить XYplorer и Tagging for windows. Первая из себя представляет отдельный файловый менеджер с опцией тегирования. Второе приложение — дополнение к стандартному файловому менеджеру.
Однако они позволяют искать файлы только на ПК и конечно нельзя написать как в Гугл поисковике запрос близкий к пользователю, а алгоритм уже бы сам выбрал из запроса теги и отсортировал информацию по приоритету. В последствии удалил обе, они подвисали и крашились частенько (возможно дело в моих надстройках Windows, не хочу делать анти пиар этих отличных программ).
Визуальный поиск
В попытках найти оптимальный способ поиска доходило до странного. Я больше визуал и поэтому загружал изображения более менее подходящее по теме информации в социальную сеть ВКонтакте, а саму информацию сохранял в комментариях под изображениями. Это дало некоторый прирост в скорости поиска и пользоваться можно с любого устройства. Но как вы, наверное, понимаете долго это продолжаться не могло. В конечном итоге я стал задумываться а к какой информации относится это изображение, на котором рельсы — означает адреса знакомых или желаемые места для путешествия… Ну а уж то, что под одним изображением образуется портянка из информации без возможности вложенности — это фиаско, бро.
Желаемый функционал
Я подумал, что было бы отлично разработать приложение, которое бы подходило по таким критериям:
- Можно использовать с любого устройства без возможности подключения к интернету.
- Поиск личной информации настолько быстро, насколько это возможно.
- Поиск должен быть простым как Google Search.
- Возможность сохранить всю текстовую информацию в текстовый файл.
Выбор технологий
1. По первому пункту из желаний было решено разработать веб приложение, так как с любого устройства, на котором есть браузер, можно получить к нему доступ. Данные хранятся в localstorage браузера, но при открытии сайта сразу выгружаются в переменную для обеспечения лучшей скорости.
Для синхронизации данных с другим устройством, браузером я взял базу данных mysql от 000webhost бесплатно, но потом перестал использовать из-за ограничений на объем. Сейчас единственный способ для обновления пользовательских данных — импорт и экспорт файла. Однако я делаю это очень редко, т.к. в основном пользуюсь только со смартфона. Что касается офлайн режима — я использовал serviceworking. Необходимо только один раз зайти на сайт, чтобы все ресурсы сайта загрузились и дальше использовать полностью офлайн из браузера.
2. Быстрый поиск.
Раз поиск должен осуществляться подобно Гугл поисковику, то нужно чтобы каждое слово из запроса проверять на существующий из уже созданного блока информации. Таким блоком у меня выступает объект с ключами: уникальное название блока, действие(показать информацию, открыть ссылку…), содержимое, теги.
Итак, по ключу «теги» у нас будет храниться массив из символов(слов) для конкретного блока информации.
Сразу возьмём пример блока.
Название: как создать сайт.
Действие: показать информацию.
Содержимое: берём html, добавляем js и украшаем css.
Теги: создание сайта, веб программирование, верстка.
Массив из тегов формируется из текстов полученных с полей ввода для тегов и названия. Каждое слово это тег, разделять можно запятой и пробелом. Была идея конечно сделать как на Ютубе, теги как словосочетания, но я решил остановиться на более широкой выдаче по ключевым словам. Из примера блока выше массив тегов будет таким: [«как», «создать», «сайт», «создание», «сайта», «веб», «программирование», «верстка»].
Теперь самое важное — определиться как будет происходить поиск. Первое, что пришло в голову это брать каждое слово из поискового запроса и сравнивать с каждым словом из тега каждого блока. В голову как пришло, так и ушло, это отвратительная идея. Следующей идеей было создание объекта, в котором каждый тег это отдельный ключ, а значение это массив из индексов блоков.
3. Итак, при вводе запроса проверяется есть ли слово в хранилище тегов, если да, то блок добавляется в массив на отображение.Теперь нужно отсортировать по приоритету. Чем выше результат в выдаче, тем более он подходит запросу. Это я реализовал с помощью количества ключевых слов в запросе, чем больше слов из запроса содержится в массиве тегов блока, тем более блок приоритетнее.
4. И насчёт сохранение в файл совсем кратко. Можно сохранять и импортировать файл в виде json.Так же мой опыт с использованием ВКонтакте как поисковик по изображениям дал мне идею для возможности добавлять изображение к каждому блоку при желании.
Итоги
В результате я сделал то, чем пользуюсь уже больше года. Как веб, так и ПК версия оказались очень полезными. Использую для работы и личной жизни. Скорость поиска, которую я в итоге получил меня многократно выручала, когда нужно было найти что-то очень быстро.
Ответвление в другие проекты
Веб приложение мне настолько понравилось, что я захотел написать программу для исполнения программ по команде от запроса пользователя на ПК. Вдохновлённый голосовыми помощниками, я создал программу, которая ищет и исполняет файлы. А поиск соответственно так же подобен веб поисковику. Особенность в том, что можно перетащить файл/файлы напрямую в программу и алгоритм автоматически установит теги исходя из названия файла и папок, в которых он содержится. Но это тема другого поста, если этот окажется интересным.
Послесловие
Буду рад любым комментариям. Узнать ваше мнение по поводу идеи. Полная ли это ерунда. Или, в чем я почти не сомневаюсь, есть уже приложения с подобной реализацией. Спасибо!
Источник: tproger.ru
Как создать собственную поисковую систему

Custom Search Engine (CSE) — мощный инструмент профессионального сорсера. С его помощью можно создать поисковый движок, который будет находить нужных вам кандидатов именно в тех источниках, которые вы укажете.
Основатель кадрового агентства Tech-recruiter и Академии IT-рекрутинга Язиля Насибуллина объяснила, как создать и настроить CSE. А для тех, кто не хочет возиться с настройками, Язиля рассказала про готовые движки для поиска на GitHub, LinkedIn, Behance, Хабр Карьере и в других источниках.
О чем вы узнаете

Язиля Насибуллина, основатель агентства Tech-recruiter, автор канала IT-рекрутинг
Зачем сорсеру CSE
CSE — это инструмент от компании Гугл, который позволяет настроить поиск под свои задачи:
- выбрать ресурсы или даже разделы сайтов, которые нужно сканировать;
- искать в определенных регионах;
- задать синонимы, которые будут автоматически подставляться в запрос;
- нацелить поиск на конкретные типы файлов;
- и многое другое, о чем я еще расскажу.
Владельцы сайтов пользуются CSE, чтобы организовать внутренний поиск по своим ресурсам. А сорсеры применяют этот инструмент, чтобы экономить время и получать максимально качественные выдачи.
Когда полезен Custom Search Engine:
- Не хватает возможностей X-ray и внутреннего поиска по сайту. Например, можно создать поисковый движок для GitHub и LinkedIn, используя операторы, которые работают только внутри CSE. Кроме того, поисковый запрос в Гугле ограничен 32 словами — Custom Search Engine позволяет обойти этот лимит.
- Нужно ограничить поиск на определенных сайтах, добавить или исключить конкретные регионы. В стандартном поиске Гугла это сделать сложнее — часто в выдачу попадают нерелевантные результаты, несмотря на оператор «-».
- Надо настроить поиск для начинающих ресечеров и рекрутеров. Например, опытный сорсер создает набор движков, которыми будут пользоваться его коллеги — просто вбивать название должности и получать резюме. Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
- Необходимо найти редкого эксперта с уникальным стеком — можно создать под него отдельный движок. И наоборот: чем стандартнее запрос и больше кандидатов на рынке, тем меньше нужны все эти «сорсинговые штучки».
Как создать поисковый движок
Зайдите в сервис «Программируемая поисковая система» и выберите, в каком интерфейсе будете работать — в стандартном или новом.
Создание движка в стандартном интерфейсе
Здесь нужно указать:
- сайты для поиска;
- язык;
- название системы — желательно осмысленное, чтобы быстро находить нужный вариант, когда у вас будет набор движков на все случаи жизни.
Например, создаю систему для поиска по профилям пользователей на LinkedIn:

Здесь я указываю адрес linkedin.com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
Как только докажу, что я не робот, и нажму на кнопку «Создать», меня перебросит на следующую страницу со ссылкой на поисковую систему — движок уже будет работать.
Создание движка в новом интерфейсе
Сначала нужно выбрать название системы и указать сайты, по которым надо искать. Потом этот список сайтов можно будет изменить в настройках. Например, создам движок для Хабр Карьеры:
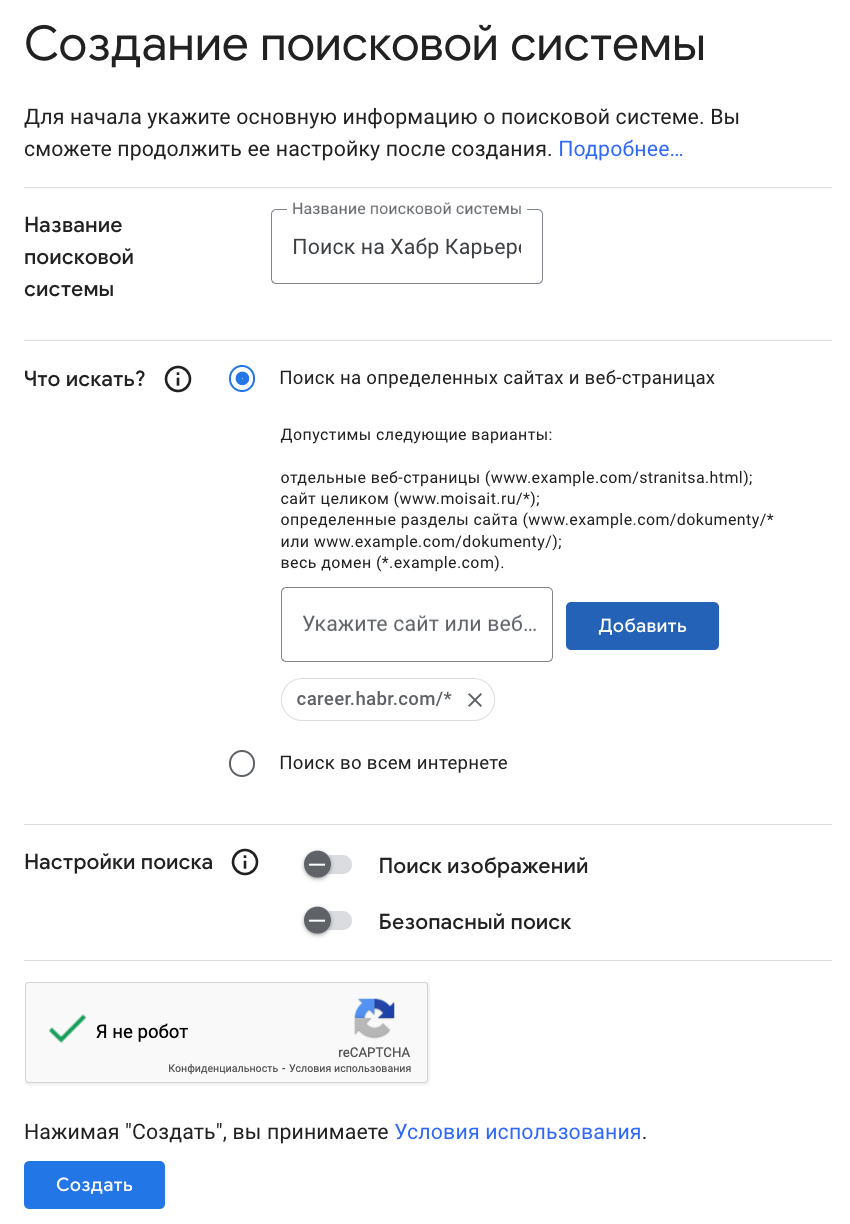
Кстати, можно не ограничиваться конкретными сайтами, а задать целые доменные зоны, например так: *.ru или *.com. Когда я нажму кнопку «Создать», мне предложат настроить систему:
- Выбрать регион поиска — разрешается указать только один. По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
- Добавить в поиск новые сайты.
- Исключить из поиска какие-то адреса. Можно убрать из области поиска не только сайт целиком, но и отдельные веб-страницы или разделы (www.example.com/jobs/*), а также весь домен (*.example.com).
Я настраиваю поиск кандидатов по Хабр Карьере, так что исключу разделы с вакансиями, курсами и информацией о компаниях:
Продвинутая настройка CSE
Предупрежу сразу: все настройки я буду проводить в стандартном интерфейсе — так привычнее. Кроме того, на момент выхода этой статьи новая версия панели управления считается предварительной — многое еще может поменяться. В целом, различия между версиями косметические. Если научиться работать в старом интерфейсе, то будет легко найти аналогичные разделы в новой панели.
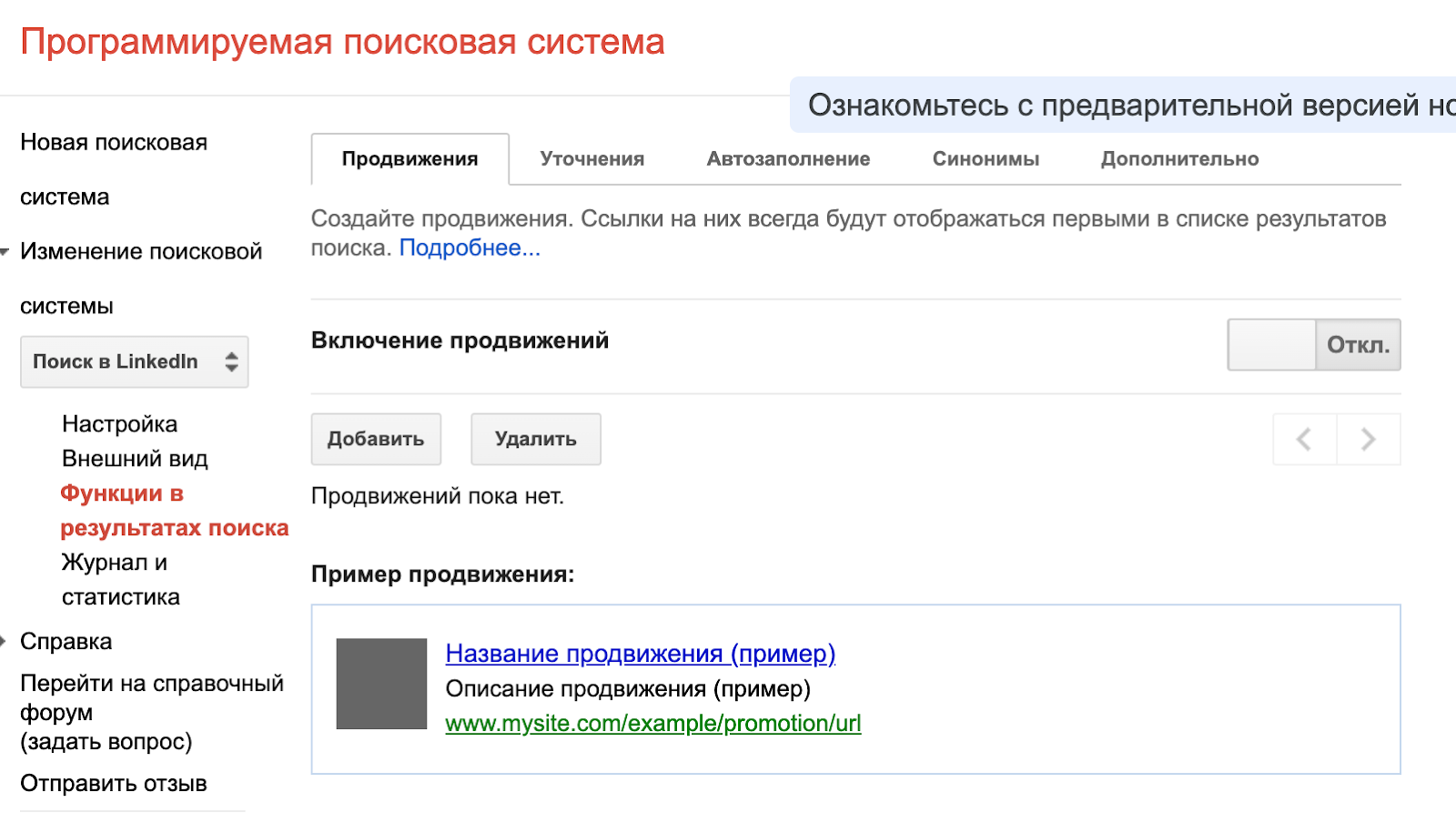
Самые полезные настройки находятся в подразделе «Функции в результатах поиска» раздела «Изменение поисковой системы»:
Добавление запроса
Можно прописать дополнительные запросы, которые будут включаться в поиск автоматически. Для этого:
- В разделе «Функции в результатах поиска» нужно перейти во вкладку «Дополнительно».
- Открыть там раздел «Настройки веб-поиска».
- В поле «Добавление запроса» вписать фразу, которая будет подставляться автоматически — писать ее при каждом запросе не придется.
Например, сделаю движок для поиска файлов в формате pdf и docx — предполагается, что это будут резюме. Использую оператор «filetype»:

Уточнения
Усовершенствую движок для LinkedIn — настрою поиск так, чтобы отдельно показывались профили кандидатов с контактными данными. Это можно сделать с помощью уточнений.
В разделе «Функции в результатах поиска» нужно перейти во вкладку «Уточнения», нажать на кнопку «Добавить» и создать дополнительные условия поиска. Результаты по каждому условию будут выводиться на отдельную вкладку.
Например, добавлю поиск по всем профилям, в которых есть почта на gmail.com и ссылка на телеграм:

Синонимы
Вручную прописывать десятки синонимов через OR при каждом запросе утомительно. В CSE для каждого ключевого слова можно задать набор синонимов, которые будут добавляться автоматически.
- Перейти в раздел «Функции в результатах поиска», а оттуда — во вкладку «Синонимы».
- Нажать на кнопку «Добавить».
- На верхней строчке написать ключевое слово, а на нижней — набор синонимов к нему.

Как искать с помощью CSE
Если перейдете по ссылке вашего поискового движка, то вы увидите обычную поисковую строку и больше ничего. Не нужно писать «site:» и название сайта для поиска — этот запрос скрыт «под капотом» системы, как и остальные настройки. А в остальном здесь работают все стандартные операторы, в том числе: OR, — , “ ”.
Например, так будет выглядеть запрос в движке для LinkedIn на поиск PHP-разработчиков из Москвы:

Сейчас движок сканирует всю страницу пользователя целиком. Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
- «more:p:person-jobtitle:» — поиск по позиции;
- «more:p:person-org:» — поиск по компании или учебному заведению;
- «more:p:person-role:» — поиск в заголовке страницы.
А у GitHub есть свой оператор, который обращается к строке «о себе» — «more:p:metatags-og_description:».
Готовые поисковые движки
Вам не обязательно создавать движок самостоятельно — можно воспользоваться готовыми вариантами, если они подходят под ваши задачи. Например, поисковики от Ирины Шамаевой и Балажа Парочай:
Мои поисковые системы:
- GitHub.
- Behance — поиск резюме. Настройки самые простые: в сайтах для поиска я указала «behance.net/*/resume» — раздел, где хранятся резюме пользователей.
- Хабр Карьера. Здесь к каждому допросу автоматически добавляется фраза «последний визит», чтобы искать только по личным страницам пользователей.
- Европейский LinkedIn. Я занимаюсь международным рекрутингом и ищу кандидатов по всей Европе. Для этого сделала движок поиска по доменным областям LinkedIn тех стран, которые мне интересны.
Еще про сорсинг в блоге Хантфлоу
- Рекрутинг в LinkedIn: часть 1 и часть 2
- Сорсинг на GitHub
- Как находить кандидатов на Stack Overflow
- Инструменты сорсинга: обзор для начинающих
- 25 ресурсов для обучения сорсингу
- 11 нестандартных источников для сорсинга
- Руководство по сорсингу от Нарека Асликяна
Главное про CSE
- Custom Search Engine — инструмент для создания собственных поисковых систем. С его помощью сорсер экономит время и получает более релевантные результаты.
- Принцип простой: вы один раз проводите настройку, убирая повторяющиеся части запросов и синонимы «под капот», а потом используете систему, чтобы находить подходящих кандидатов.
- Чтобы часть запроса подставлялась автоматически:
- перейдите во вкладку «Дополнительно» в разделе «Функции в результатах поиска»;
- откройте раздел «Настройки веб-поиска»;
- в поле «Добавление запроса» впишите нужную фразу.
- Можно добавлять или исключать из поиска целые доменные зоны, сайты целиком, отдельные страницы и разделы.
- Настройка «синонимы» позволяет задать набор синонимов, которые будут автоматически добавляться к запросу для каждого ключевого слова.
- С помощью уточнений вы можете создать вкладки с результатами ответов на дополнительные запросы. Например, это удобно, когда нужно посмотреть, у кого из найденных кандидатов есть контактные данные в профиле.

Главный редактор Хантфлоу
Источник: huntflow.ru