
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Switch branches/tags
Branches Tags
Could not load branches
Nothing to show
Could not load tags
Nothing to show
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
- Local
- Codespaces
HTTPS GitHub CLI
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more about the CLI.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Урок 12 — Сжатие данных, программы-архиваторы и архивы с паролями | Компьютерные курсы 2020 (Win 10)
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
Latest commit message
Commit time
readme.md
В данном задании вам предстоит реализовать архиватор на основе алгоритма Хаффмана.
Программа-архиватор должна иметь следующий интерфейс командной строки:
- archiver -c archive_name file1 [file2 . ] — заархивировать файлы file1, file2, . и сохранить результат в файл archive_name .
- archiver -d archive_name — разархивировать файлы из архива archive_name и положить в текущую директорию.
- archiver -h — вывести справку по использованию программы.
Имена файлов (только имена файлов с расширениями, без дополнительного пути) должны сохраняться при архивации и разархивации.
Алгоритм сжатия устроен следующим образом:
- Подсчитывается частотность 8-битных символов в файле. Кроме содержимого файла надо учесть частоты символов в имени файла, а также добавить три служебных символа FILENAME_END=256 , ONE_MORE_FILE=257 , ARCHIVE_END=258 с частотами 1. Назначение этих символов будет описано позже. Таким образом, для кодирования расширенного алфавита необходимо 9 бит.
- Строится бинарный бор кодирования следующей процедурой:
- Для каждого символа алфавита добавляется соответствующая вершина в очередь с приоритетом. Упорядочение вершин в очереди осуществляется по неубыванию частот символов в файле (в «начале» очереди всегда вершина с символом с наименьшей встречаемостью в файле), а при равенстве частот — по возрастанию символов (для вершин, не являющихся листьями, в качестве сивола для сравнения используется наименьший из символов их потомков).
- Пока в очереди больше одного элемента, из нее последовательно извлекаются две вершины A и B с минимальными приоритетами. Создается новая вершина С, детьми которой являются вершины A и B. Вершина C помещается в очередь с приоритетом, равным сумме приоритетов вершин A и B.
- По окончанию процедуры в очереди остается ровно одна вершина, которая является корнем построенного бора. Листовые вершины являются терминальными. В каждой терминальной вершине записан символ из исходного файла. Каждая нетерминальная вершина дерева содержит два ребра: левое и правое, которые помечаются битами 0 и 1 соответственно. Каждой терминальной вершине соответствует битовая последовательность, получающаяся спуском из корня бора к терминальной вершине и выписыванием битов всех пройденных ребер. Для наглядности можно воспользоваться следующими иллюстрациями:
- gif demo
- gif demo
- graphic demo.
Алгоритм декодирования в целом обратен алгоритму кодирования и устроен следующим образом:
WinRar — как пользоваться архиватором?
- Из файла восстанавливается таблица кодирования (соответствие между сиволами и их кодами).
- По таблице кодирования строится бинарный бор.
- По бинарным последовательностям, прочитанным из входного файла, производится трассировка по бору от корня к листовым вершинам. При достижении очередной листовой вершины бора определяется соответсвующий ей символ, который записывается в выходной файл.
Для обеспечения кросс-платформенной совместимости нужно зафиксировать отображение последовательность бит (значений) в последовательности байтов: каждое значение читаем и записываем начиная со старшего бита до младшего.
Пример: дана последовательность unsigned char . Требуется прочитать из неё два 9-битных значения a и b . Представление на битовом уровне:
10000000 11000000 11100000 aaaaaaaa abbbbbbb bb
Следовательно, a = 257 , b = 259 .
Файл с архивом должен иметь следующий формат:
- 9 бит — количество символов в алфавите SYMBOLS_COUNT
- Блок данных для восстановления канонического кода
- SYMBOLS_COUNT значений по 9 бит — символы алфавита в порядке следования канонических кодов
- Список из MAX_SYMBOL_CODE_SIZE значений по 9 бит, i-й (при нумерации с 0) элемент которого — это количество символов с длиной кода i+1 . MAX_SYMBOL_CODE_SIZE — максимальная длина кода в текущем кодировании. Канонические коды соответствуют по порядку символам из предыдущего пункта. MAX_SYMBOL_CODE_SIZE не записывается явным образом в файл, т.к. его можно восстановить по имеющимся данным.
Старайтесь делать все компоненты программы по возможности более универсальными и не привязанными к специфике конкретной задачи. Например, алгоритмы кодирования и декодирования должны работать с потоками ввода-вывода, а не файлами.
Программа должна корректно обрабатывать очень большие (во много раз превосходящие по объему оперативную память) файлы. Это означает, что при работе программы данные не должны накапливаться в памяти.
Файлы с форматом, не соответствующим спецификации, не должны приводить к «падению» программы. Все исключительные ситуации должны корректно обрабатываться с выводом понятного пользователю сообщения об ошибке. При любых ошибках программа должна возвращать код 111 , при успешном завершении — код 0 .
Скорее всего, вам понадобятся следующие компоненты:
- Обертки над потоками ввода-вывода, позволяющие читать и писать значения по 1 и 9 бит.
- Бор с интерфейсом, позволяющим удобно его обходить.
- Очередь с приоритетами.
Подробный дизайн программы рекомендуется обсудить с преподавателем на семинарах.
Проект проверяется преподавателями. Все сдачи будут проходить код ревью. Автомерж роботом для проекта не применяется.
Код проекта должен лежать в папке src. Для сдачи проекта используйте ветку submits/archiver
Минимальная реализация проекта должна быть полностью функциональной (т.е. корректно архивировать и разархивировать файлы) — она оценивается в 6 баллов.
Решения, не удовлетворяющие требованиям к минимальной реализации, оцениваются в 0 баллов.
Дополнительные баллы (максимум 1 балл за каждый пункт) можно получить:
- Обобщенную (не завязанную на специфику конкретной задачи) реализацию очереди с приоритетами без использования стандартных очередей, алгоритмов и коллекций, обеспечивающих сортированность. Реализация должна быть алгоритмически эффективной, т.е. иметь сложность вставки и извлечения не более O(logN), где N — число элементов в очереди.
- Обобщенную реализацию класса для работы с аргументами командной строки (без использования готовых аналогов)
- Обобщенную реализацию потоков побитового ввода и вывода
- Покрытие юнит тестами всех критичных компонентов. Ваш семинарист поможет с определением достаточности покрытия.
Баллы могут быть сняты за серьезные недочеты, например:
- Отсутствие или неверную декомпозицию на файлы, классы, методы и функции
- Утечки памяти
- Неконтролируемое падение программы
- Нечитаемый код
- Нарушение стиля кодирования
- UB на каком-либо входе или наборе аргументов функции
- Выбор неэффективных структур данных или их неэффективное использование
- Неоправданные копирования объектов
- Неверные сигнатуры функций и методов
Для проекта установлен жесткий дедлайн 23:59 23.10.2022 — это означает, что решения, отправленные после этого времени, не будут оцениваться.
Дополнительных штрафов за время сдачи нет.
Источник: github.com
Создаем свой архиватор в 200 строчек кода

2013-02-27 в 18:57, admin , рубрики: c++, архивация, Песочница, файлы, метки: c++, архивация, файлы
Архивы в современное время играют немаловажную роль в хранении данных. Они позволяют хранить внутри себя набор разнообразных файлов. Это достаточно удобно, например, для передачи данных по сети — легче передавать один файл, чем несколько. Также архивы позволяют хранить информацию в удобной структурированной форме. Вы это, несомненно, осознавали и до этого.
В данной статье мы попробуем разработать собственный кроссплатформенный консольный архиватор с поддержкой как архивации, так и распаковки ранее запакованых файлов. Требуется уложиться в 200 строчек кода. Писать будем на C++, используя при этом лишь его стандартные библиотеки. Поэтому привязанности к определенной платформе нет — работать это будет и в Windows, и в Linux.
Почему C++, а не привычный C? Не то, что бы я имею что-то против СИ, просто в нем достаточно проблематично работать со строками и, к тому же, отсутствует ООП. Следовательно, если бы мы использовали C, то в 200 строк, думаю, вряд ли бы уложились. Ну, да ладно, приступим же!
Intro
Для начала немного теории. Думаю, все, кто читает эту статью, прекрасно знают, что любой файл — это обыкновенная последовательность байт, которой оперирует процесс, открывший файл( ресурс ). Файлы — это последовательность байт, которая приобретает различные формы в пределах файловой системы. Формы — это типы файлов, их назначения. Для операционной системы файлы — это байты, о назначении которых ей ничего не известно.
Стандартные потоки вывода также манипулируют последовательностью байт, попутно модифицируя их( это зависит от класса потока, некоторые потоки являются «сырыми», т.е работают, непосредственно, с байтами ).
Так что же требуется знать, чтобы написать архиватор? Думаю, кроме наличия некоторых знаний уровня «выше базового», касающихся C++, лишь то, что файл — это байты. И ничего более.
Codding
Пусть наш консольный архиватор будет называться Zipper`ом. Мне кажется, вполне подходящее название 🙂
Для работы потребуется несколько стандартных библиотек C++:
#include #include #include #include
Да, мы будем также использовать STL. Это удобно, «модно» и лаконично. STL позволит нам в разы сократить код.
Также мы будем использовать стандартное пространство имен:
using namespace std;
Теперь разберемся с тем, как вообще будет функционировать наш архиватор. Итак, Zipper будет принимать из консоли некоторые параметры:
-pack — архивация(упаковка) файлов
-unpack — разархивация(распаковка) данных из файла-архива
-files — набор файлов для архивации( при наличии -pack ) или один файл для разархивации( при наличии -unpack )
-path — путь для сохранения разархивированных данных( при наличии -unpack ) или путь для сохранения архива ( при наличии -pack )
Распаковка данных из архива тесно связана с тем, что происходит при архивации. Архивация же будет происходить в два этапа:
1) Получение информации об архивируемых файлах
2) Создание единого файла архива, содержащего блок информации о всех файлах внутри себя и все файлы в бинарном представлении.
При архивации сначала будет происходить получении информации о всех файлах и сохраняться в промежуточный текстовый файл в таком виде:
Затем текстовый файл побайтно будет переписан в начало файла-архива и удален. Пояснения к параметрам формата информации:
size_of_string — пять байт, содержащие числа, составляющие единое число в 10-ичной системе счисления, которое указывает общий размер(в байтах) последующего блока информации( до )
filesize — размер определенного файла в байтах
filename — имя этого файла.
Ну а после блока с информацией мы просто переписываем все архивируемые файлы побайтно в наш архив.
Вот, собственно, и весь процесс архивации. Теперь вернемся к коду.
Для наибольшего удобства мы создадим один класс «Zipper», который будет отвечать за все, что происходит внутри архиватора. Итак, архитектура класса » Zipper «:
class Zipper < private: vectorfiles; // набор файлов (-files) string path; // путь (-path) string real_bin_file; // имя выходного файла-архива( используется при архивации ) public: Zipper(vector if(vec.size()>0) files.assign(vec.begin(),vec.end()); path = p+»»; real_bin_file=path+»binary.zipper»; > > void getInfo(); // Метод для получения информации о файлах на этапе архивации void InCompress(); // Архивация данных void OutCompress(string binary); // Распаковка данных ( binary — путь до архива ) // Статический метод для выделения имени файла из полного пути. // Используется для внутренних нужд. static string get_file_name(string fn) >;
Нам также потребуется кое-какой простой «метод-отшельник» для подсчета количества разрядов в числе. Это потребуется, например, для записи числа в архив, как динамического буфера символов. Метод:
int digs(double w) < int yield = 0; while(w>10) return yield+1; >
Итак, мы уже имеем более-менее качественный интерфейс. Но пока все то, что было задумано, лишь в сознании.
Пора бы воплотить идею 🙂 Реализуем метод архивации данных:
void Zipper::InCompress() < char byte[1]; // единичный буфер для считывания одного байта getInfo(); // получаем необходимую информацию о том, что архивируем FILE *f; FILE *main=fopen((this->real_bin_file).c_str(),»wb»); // файл — архив FILE *info = fopen((this->path+»info.txt»).c_str(),»rb»); // файл с информацией // переписываем информацию в архив while(!feof(info)) < if(fread(byte,1,1,info)==1) fwrite(byte,1,1,main); >fclose(info); remove((this->path+»info.txt»).c_str()); // прибираемся за собой // последовательная запись в архив архивируемых файлов побайтно : for(vector::iterator itr=this->files.begin();itr!=this->files.end();++itr) < f = fopen((*itr).c_str(),»rb»); if(!f)< coutwhile(!feof(f)) < if(fread(byte,1,1,f)==1) fwrite(byte,1,1,main); >coutreal_bin_file fclose(main); >
Осталось лишь реализовать наш заветный метод для получения информации. Метод » getInfo() «:
void Zipper::getInfo() < char byte[1]; // единичный буфер для считывания одного байта basic_strings_info = «»; remove((this->path+»info.txt»).c_str()); // на всякий случай FILE *info = fopen((this->path+»info.txt»).c_str(),»a+»); // сохраняем информацию в наш текстовый файл int bytes_size=0; // длина информационного блока в байтах for(vector::iterator itr=this->files.begin();itr!=this->files.end();++itr) < FILE *f = fopen((*itr).c_str(),»rb»); if(!f) break; // получаем размер архивируемого файла fseek(f,0,SEEK_END); int size = ftell(f); string name = Zipper::get_file_name(*itr); // получаем имя архивируемого файла char *m_size = new char[digs(size)]; itoa(size,m_size,10); fclose(f); bytes_size+=digs(size); bytes_size+=strlen(name.c_str()); // все, что «нарыли», сохраняем в промежуточный буфер : s_info.append(m_size); s_info.append(«||»); s_info.append(name); s_info.append(«||»); delete [] m_size; >bytes_size = s_info.size()+2; char *b_buff = new char[digs(bytes_size)]; itoa(bytes_size,b_buff,10); // форматируем до 5 байт if(digs(bytes_size)
На этом с архивацией данных все.
Осталось лишь добавить смысла в архивацию, а именно — распаковку того, что внутри архива. Для этого реализуем последний нереализованный метод класса Zipper — метод OutCompress(). Как говорилось в начале статьи, распаковка тесно связана с упаковкой.Эта привязанность связана с информационным блоком.
Если возникнет ошибка при архивации, а именно на этапе получения информации( например, где-то просчет на 1 байт ), то весь процесс распаковки с треском рухнет. Но, этого нам, конечно же, не нужно! Мы ведь пишем валидный код. Итак, процесс распаковки состоит всего из одного этапа, содержащего два подэтапа:
1) Разборка блока с информацией о том, что содержится в архиве
2) Чтение «мессива» байт всех файлов внутри архива по правилам, указанным в информационной секции.
Что ж, реализация метода распаковки:
void Zipper::OutCompress(string binary) < FILE *bin = fopen(binary.c_str(),»rb»); // открываем архив в режиме чтения char info_block_size[5]; // размер информационного блока fread(info_block_size,1,5,bin); // получаем размер int _sz = atoi(info_block_size); // преобразуем буфер в число char *info_block = new char[_sz]; // информационный блок fread(info_block,1,_sz,bin); // считываем его // Парсинг информационного блока : vectortokens; char *tok = strtok(info_block,»||»); int toks = 0; while(tok) < if(strlen(tok)==0) break; tokens.push_back(tok); tok=strtok(NULL,»||»); toks++; >if(toks%2==1) toks—; // удаляем мусор int files=toks/2; // количество обнаруженных файлов в архиве char byte[1]; // единичный буфер для считывания одного байта // Процесс распаковки всех файлов( по правилам полученным из блока с информацией ) : for(int i=0;ipath.c_str()); strcat(full_path,name); int _sz = atoi(size); coutpath fclose(curr); delete [] size; delete [] name; > fclose(bin); >
Вот, собственно, и все, что касается нашего архиватора/распаковщика. Но так как это приложение планируется использовать в консольном режиме, то нам придется подстроить наш Zipper для консоли. Нам необходимо реализовать поддержку 4 параметров, речь о которых шла в самом начале. Это делается довольно легко:
int main(int argv, char* argc[]) < /*/ Supported args: // // -pack, -unpack, -files, -path // /*/ setlocale(LC_ALL,»Russian»); cout1) < vectorfiles; // массив файлов, переданных через параметры из консоли string path = «»; // путь bool flag_fs = false, flag_path = false; // флаги режима чтения/записи char type[6]; // тип: упаковка или распаковка memset(type,0,6); for(int i=1;i if(strcmp(argc[i],»-unpack»)==0) < strcpy(type,»unpack»); flag_fs=flag_path=false;>if(strcmp(argc[i],»-path»)==0) if(strcmp(argc[i],»-files»)==0) if(flag_path) if(flag_fs) files.push_back(string(argc[i])); > Zipper *zip = new Zipper(files,path); if(strcmp(type,»pack»)==0) zip->InCompress(); if(strcmp(type,»unpack»)==0) zip->OutCompress(files[0]); > else cout
Вот, собственно, и все приложение.
Testing
Теперь займемся неотъемлемой частью разработки — тестированием. Для наибольшего удобства я все продемонстрирую в картинках.
1) В корне локального диска «C» я создам папку с именем «test», в которой будут находиться все файлы для архивации. В «C:test» создам еще одну папку для демонстрации разархивации — «unpack»:
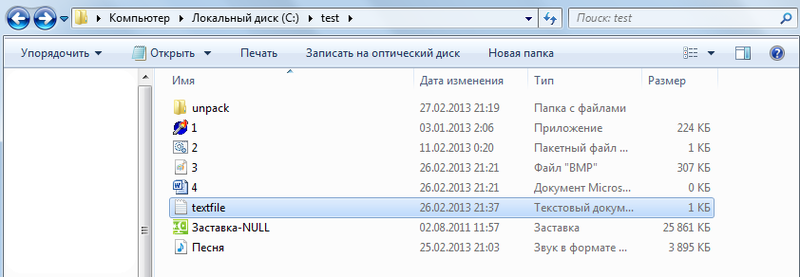
Далее открываем консоль и архивируем содержимое » C:test «:
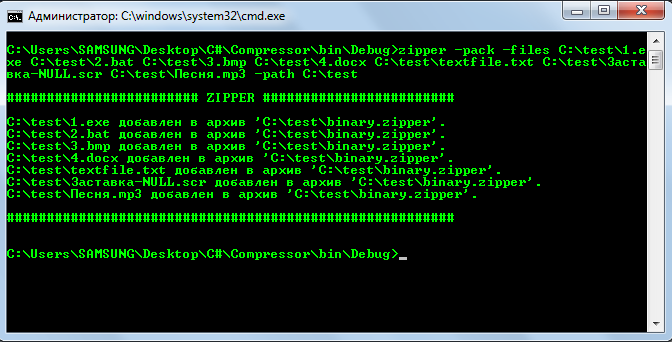
Смотрим, что новенького в » C:test «:
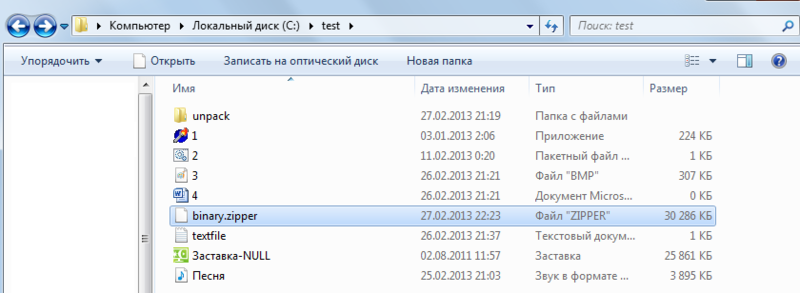
Видим там наш архив — «binary.zipper». Откроем его с помощью какого-нибудь текстового редактора для изучения содержимого. Я это сделаю с помощью NotePad++:

Пишем архиватор на C#
Недавно натолкнулся на один пост на Хабре, где шлось о написании собственного архиватора. В нём шла речь об dllке zlib.net.dll.
Попробовал поработать с ней — не получилось… Но на сайте автора этой библиотеки нашёл ещё одну — она называется «.NET Zip Component ZipForge.NET». Её можно скачать тут.
Она бесплатна лишь для некоммерческого использования.
Если вы хотите распространять свой продукт,
вам необходимо приобрести лицензию.
(а больше нам и не нужно)
Итак, приступим:
Сжатие
Распаковка архива
Заключение
Вот так просто мы можем создать свой архиватор. В следующем посте я расскажу как действительно
создать хороший архиватор на подобие 7zip, с помощью этой отличной библиотеки.
Также создадим самораскрывающийся архив, GUI для архиватора и конечно же сделаем возможность
просматривать .zip файлы с помощью нашего менеджера.
Источник: habr.com