
Часто у вебмастера, маркетолога или SEO-специалиста возникает необходимость извлечь данные со страниц сайтов и отобразить их в удобном виде для дальнейшей обработки. Это может быть парсинг цен в интернет-магазине, получение числа лайков или извлечение содержимого отзывов с интересующих ресурсов.
38 239 просмотров
По умолчанию большинство программ технического аудита сайтов собирают только содержимое заголовков H1 и H2, однако, если например, вы хотите собрать заголовки H5, то их уже нужно будет извлекать отдельно. И чтобы избежать рутинной ручной работы по парсингу и извлечению данных из HTML-кода страниц – обычно используют веб-скраперы.
Веб-скрейпинг – это автоматизированный процесс извлечения данных с интересующих страниц сайта по определенным правилам.
Возможные сферы применения веб-скрейпинга:
- Отслеживание цен на товары в интернет-магазинах.
- Извлечение описаний товаров и услуг, получение числа товаров и картинок в листинге.
- Извлечение контактной информации (адреса электронной почты, телефоны и т.д.).
- Сбор данных для маркетинговых исследований (лайки, шеры, оценки в рейтингах).
- Извлечение специфичных данных из кода HTML-страниц (поиск систем аналитики, проверка наличия микроразметки).
- Мониторинг объявлений.
Основными способами веб-скрейпинга являются методы разбора данных используя XPath, CSS-селекторы, XQuery, RegExp и HTML templates.
ПОДГОТОВЬ СЕБЯ! 4 Эффективных Способа Сохранить Деньги в России в 2023 году / Дмитрий Черемушкин
- XPath представляет собой специальный язык запросов к элементам документа формата XML / XHTML. Для доступа к элементам XPath использует навигацию по DOM путем описания пути до нужного элемента на странице. С его помощью можно получить значение элемента по его порядковому номеру в документе, извлечь его текстовое содержимое или внутренний код, проверить наличие определенного элемента на странице. Описание XPath >>
- CSS-селекторы используются для поиска элемента его части (атрибут). CSS синтаксически похож на XPath, при этом в некоторых случаях CSS-локаторы работают быстрее и описываются более наглядно и кратко. Минусом CSS является то, что он работает лишь в одном направлении – вглубь документа. XPath же работает в обе стороны (например, можно искать родительский элемент по дочернему). Таблица сравнения CSS и XPath >>
- XQuery имеет в качестве основы язык XPath. XQuery имитирует XML, что позволяет создавать вложенные выражения в таким способом, который невозможен в XSLT. Описание XQuery >>
- RegExp – формальный язык поиска для извлечения значений из множества текстовых строк, соответствующих требуемым условиям (регулярному выражению). Описание RegExp >>
- HTML templates – язык извлечения данных из HTML документов, который представляет собой комбинацию HTML-разметки для описания шаблона поиска нужного фрагмента плюс функции и операции для извлечения и преобразования данных. Описание HTML templates >>
Обычно при помощи парсинга решаются задачи, с которыми сложно справиться вручную. Это может быть веб скрейпинг описаний товаров при создании нового интернет-магазина, скрейпинг в маркетинговых исследованиях для мониторинга цен, либо для мониторинга объявлений (например, по продаже квартир). Для задач SEO-оптимизации обычно используются узко специализированные инструменты, в которых уже встроены парсеры со всеми необходимыми настройками извлечения основных SEO параметров.
Как скачать видео с GetCourse (Геткурс) — сохраняем уроки из вебинарной комнаты на свой компьютер
BatchURLScraper
Существует множество инструментов, позволяющих осуществлять скрейпинг (извлекать данные из веб-сайтов), однако большинство из них платные и громоздкие, что несколько ограничивает их доступность для массового использования.
Поэтому нами был создан простой и бесплатный инструмент – BatchURLScraper, предназначенный для сбора данных из списка URL с возможностью экспорта полученных результатов в Excel.
Интерфейс программы достаточно прост и состоит всего из 3-х вкладок:
- Вкладка «Список URL» предназначена для добавления страниц парсинга и отображения результатов извлечения данных с возможностью их последующего экспорта.
- На вкладке «Правила» производится настройка правил скрейпинга при помощи XPath, CSS-локаторов, XQuery, RegExp или HTML templates.
- Вкладка «Настройки» содержит общие настройки программы (число потоков, User-Agent и т.п.).
Источник: vc.ru
Как сохранить программу с сайта
Как-то на одном из web-ресурсов одному товарищу попалась коллекция редких видеороликов, которые, как показало исследование страницы сайта, были загружены в конкретную директорию на том самом сайте и имели однотипные названия файлов. И этот товарищ захотел скачать эти видеоролики на свой компьютер, чтобы ознакомиться с их содержимым в более спокойной обстановке и без интернета (в самолете во время длительного перелета).

Таким образом сформировалась задача — скачать эти видеоролики, причем, желательно автоматизированно, так как их количество было более 400 шт!
Вариантов скачать данные файлы было несколько:
1. С помощью одного их плагинов для браузера, позволяющих сохранять видео с web-страницы. Данный вариант не подходил, так как абсолютно не имел автоматизации, и каждый видео-файл нужно было бы запускать и скачивать отдельно. НЕ ПОДХОДИТ!
2. Открывать каждый файл по прямой ссылке (типа такой: http: // site.ru/some-folder/video154.mp4) и с помощью нажатия клавиш CTRL + S сохранять файл в нужную папку на компьютере. Этот способ сохранения также без автоматизации. НЕ ПОДХОДИТ!
3. Использовать программу Offline Explorer Enterprise или ее аналог. Подобные программы могут скачивать сайты почти со всем их содержимым, можно настроить скачивание только конкретных типов файлов, запустить процесс и ждать окончания, занимаясь другими делами.
Но данные программы практически все платные, их нужно найти, скачать, купить(?!), установить, настроить и только после этого запустить процесс и наслаждаться результатом. НЕ ОЧЕНЬ ПОДХОДИТ!
4. Использовать простую программу WGET и БАТник (BAT-файл). Программа WGET бесплатная, БАТник написать — 5 минут, и готово! Запустить БАТник и ждать окончания скачивания всех файлов. ПОДХОДИТ!
Содержимое BAT-файла:
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video1.mp4» — P D : 2
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video2.mp4» — P D : 2
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video3.mp4» — P D : 2
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video4.mp4» — P D : 2
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video5.mp4» — P D : 2
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video6.mp4» — P D : 2
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video7.mp4» — P D : 2
.
.
wget . exe — c —no-check- certificate «http: // site.ru/some-folder/video450.mp4» — P D : 2
Синтаксис команды очень простой:
wget.exe — использовать программу WGET;
-c — ключ для возобновления закачки с места остановки, если загрузка файла случайно прервется;
—no-check-certificate — игнорировать сертификаты сайтов (для HTTPS). Если не добавить этот ключ, а на сайте стоит жесткая переадресация всех HTTP-запросов на HTTPS (например, 301-ый редирект), то можно получить ошибку:
ERROR: cannot verify site.ru’s certificate, issued by `/C=US/O=Let’s Encrypt/CN=Let’s Encrypt Authority X3′:
Unable to locally verify the issuer’s authority.To connect to vs1.coursehunters.net insecurely, use `—no-check-certificate’.
Unable to establish SSL connection.
И скачать файлы не получится. Потому что, ХЗ какой сертификат используется :)))
После добавления ключа будет отображаться предупреждение, просто игнорируем его:
WARNING: cannot verify vs1.coursehunters.net’s certificate, issued by `/C=US/O=Let’s Encrypt/CN=Let’s Encrypt Authority X3′:
Unable to locally verify the issuer’s authority.
«http: // site.ru/some-folder/video1.mp4» — адрес конкретного файла, который нужно скачать. Внимание: пробелы перед // и после не нужны!
-P D:2 — путь для сохранения скачиваемых файлов (если не хотим, чтобы файлы сохранялись в папку с программой WGET и БАТником).
Соответственно, прописать в BAT-файле столько строк, сколько файлов нужно скачать. Сгенерировать нужное количество однотипных строк можно с помощью регулярных выражений или программы MS Excel (как вариант).
Итак, нужно сделать следующее:
- Создать БАТник;
- Скачать программу WGET с этого сайта либо с иного web-ресурса;
- Поместить программу WGET в одну папку с БАТником;
- Запустить БАТник и ждать окончания процесса скачивания файлов;

- Если скачивание в какой-то момент остановится, закрыть консоль и запустить заново, предварительно удалив строки, в которых прописаны уже скачанные файлы. Строку с последним недокаченным файлом не удалять!
Как сохранить страницу сайта на компьютере?
Чтобы иметь доступ к содержимому какого-то веб-портала даже без подключения к сети, надо сделать локальную копию страницы (скрин, текстовый или HTML-файл), которая будет храниться на диске. Так вы в любой момент сможете изучить находящуюся там информацию. Конечно, если компьютер с необходимыми данными окажется рядом. Можно перенести не только текстовый контент, но и картинки, элементы форматирования, структуру. Узнайте, как сделать скриншот страницы ресурса глобальной сети, скопировать её сразу со всем графическим и мультимедийным контентом или сохранить её содержимое в виде файла.

Скопировать из браузера
Можно перенести данные из обозревателя в любой текстовый редактор. Для этого лучше всего подойдёт Microsoft Word. В нём корректно отображаются изображения и форматирование. Хотя из-за специфики документа может не очень эстетично выглядеть реклама, меню и некоторые фреймы.
- Откройте нужный URL.
- Нажмите Ctrl+A. Или кликните правой кнопкой мыши по любой свободной от картинок и flash-анимации области и в контекстном меню выберите «Выделить». Это надо сделать для охвата всей информации, а не какого-то произвольного куска статьи.
- Ctrl+C. Или в том же контекстном меню найдите опцию «Копировать».
- Откройте Word.
- Поставьте курсор в документ и нажмите клавиши Ctrl+V.
- После этого надо сохранить файл.
Иногда получается так, что переносится только текст. Если вам нужен остальной контент, можно взять и его. Вот как скопировать страницу веб-ресурса полностью — со всеми гиперссылками, рисунками:
- Проделайте предыдущие шаги до пункта 4.
- Кликните в документе правой кнопкой мыши.
- В разделе «Параметры вставки» отыщите кнопку «Сохранить исходное форматирование». Наведите на неё — во всплывающей подсказке появится название. Если у вас компьютер с Office 2007, возможность выбрать этот параметр появляется только после вставки — рядом с добавленным фрагментом отобразится соответствующая пиктограмма.
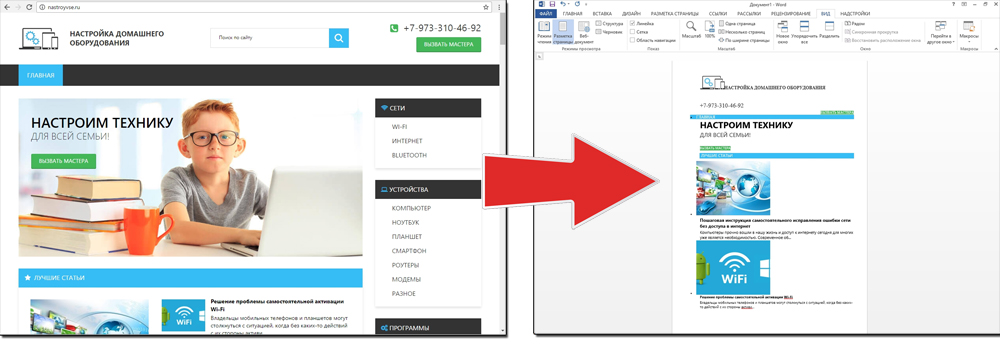
Способ №1: копипаст
В некоторых случаях нельзя скопировать графику и форматирование. Только текст. Даже без разделения на абзацы. Но можно сделать скриншот или использовать специальное программное обеспечение для переноса содержимого страницы на компьютер.
Сайты с защитой от копирования
Иногда на ресурсе стоит так называемая «Защита от копирования». Она заключается в том, что текст на них нельзя выделить или перенести в другое место. Но это ограничение можно обойти. Вот как это сделать:
- Щёлкните правой кнопкой мыши в любом свободном месте страницы.
- Выберите «Исходный код» или «Просмотр кода».
- Откроется окно, в котором вся информация находится в html-тегах.
- Чтобы найти нужный кусок текста, нажмите Ctrl+F и в появившемся поле введите часть слова или предложения. Будет показан искомый отрывок, который можно выделять и копировать.
Если вы хотите сохранить на компьютер какой-то сайт целиком, не надо полностью удалять теги, чтобы осталась только полезная информация. Можете воспользоваться любым html-редактором. Подойдёт, например, FrontPage. Разбираться в веб-дизайне не требуется.
- Выделите весь html-код.
- Откройте редактор веб-страниц.
- Скопируйте туда этот код.
- Перейдите в режим просмотра, чтобы увидеть, как будет выглядеть копия.
- Перейдите в Файл — Сохранить как. Выберите тип файла (лучше оставить по умолчанию HTML), укажите путь к папке, где он будет находиться, и подтвердите действие. Он сохранится на электронную вычислительную машину.
Защита от копирования может быть привязана к какому-то js-скрипту. Чтобы отключить её, надо в браузере запретить выполнение JavaScript. Это можно сделать в настройках веб-обозревателя. Но из-за этого иногда сбиваются параметры всей страницы. Она будет отображаться неправильно или выдавать ошибку.
Ведь там работает много различных скриптов, а не один, блокирующий выделение.
Если на сервисе есть подобная защита, лучше разобраться, как скопировать страницу ресурса глобальной сети другим способом. Например, можно создать скриншот.
Скриншот
Снимок экрана — это самый простой способ добавить какую-то информацию на компьютер. Она сохраняется в виде графического файла. Его можно открыть и просмотреть в любое время. Вот как сделать скрин:
- Зайдите на нужный портал.
- Нажмите на клавиатуре кнопку PrintScreen (иногда она называется «PrntScr» или «PrtSc»). Снимок экрана будет добавлен в буфер обмена — временное хранилище, используемое при операциях «Копировать-Вставить».
- Откройте любой графический редактор. В операционной системе Windows есть свой — называется «Paint». Можете воспользоваться им. В нём можно обрезать и немного подкорректировать скриншот. Для более серьёзного редактирования графики надо устанавливать на компьютер профессиональные программы (Adobe Photoshop, к примеру). Но чтобы просто сделать копию страницы, хватит и собственных средств Windows.
- Вставьте скрин в редактор. Для этого нажмите Ctrl+V.
- Можно добавить его и в текстовый процессор (тот же Word), который поддерживает работу с графикой.
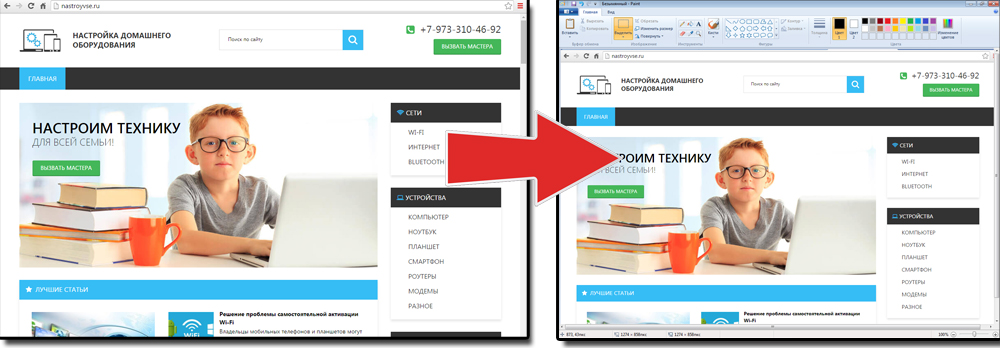
Получить снимок страницы можно с помощью графических редакторов. Например, Paint.
Информация будет представлена в виде сплошной картинки, а не набора символов. Если понадобится скопировать какую-то часть материала, придётся перепечатывать его вручную. Ведь скриншот — не статья. Чтобы облегчить задачу, воспользуйтесь утилитами для распознавания текста с рисунков.
Так удобно копировать небольшие куски. Но вот с объёмным контентом сложнее. Придётся делать много снимков, прокручивать, часто открывать редактор. Но можно разобраться, как сделать скрин всей страницы портала, а не её части. Используйте специализированные программы.
Утилиты для создания скриншотов
Существуют программы для работы со снимками экрана. С их помощью можно охватить контент полностью, а не скринить по кускам.
- Популярное приложение с разнообразным функционалом.
- Расширение для веб-браузера. Можно сделать картинку всей страницы, просто нажав кнопку на панели инструментов.
- Снимает всё, что можно снять: произвольные области, окна, большие веб-ресурсы. Есть инструментарий для редактирования получившихся изображений и библиотека эффектов.
- Автоматически прокручивает, делает серию кадров и самостоятельно объединяет их в один скриншот.
Есть также онлайн-сервисы, которые могут сформировать снимок. Они работают по одному принципу: вставить адрес сайта — получить картинку. Вот некоторые из них.
- Capture Full Page
- Web Screenshots
- Thumbalizr
- Snapito
Сохранить как HTML-файл
Вот как сохранить страницу ресурса глобальной сети на компьютер в формате html. Впоследствии его можно будет конвертировать в другой тип. При таком копировании картинки с веб-портала помещаются в отдельную папку, которая будет иметь то же название, что html-файл, и находится в том же месте, что и он.
- Откройте сайт.
- Кликните правой кнопкой мышки в любом месте, свободном от рисунков, фонов, видео и анимации.
- Выберите «Сохранить как». В Mozilla Firefox аналогичную кнопку можно найти в меню. Для этого нужно нажать на значок с тремя горизонтальными чёрточками. В Opera эти настройки вызываются кликом на логотип.
- Задайте имя. Укажите путь.
- Подтвердите действие.
Сохранить как PDF
В Google Chrome можно создать из страницы PDF-файл. Данная функция предназначена для распечатки на принтере. Но доступно копирование и на компьютер.
- Кликните на пиктограмму в виде трёх линий (они справа вверху).
- Нажмите «Печать» или воспользуйтесь сочетанием клавиш Ctrl+P.
- Кликните «Изменить».
- Пункт «Сохранить как PDF».
- На левой панели повторно нажмите кнопку с таким же названием.
- Дайте файлу имя и укажите путь.
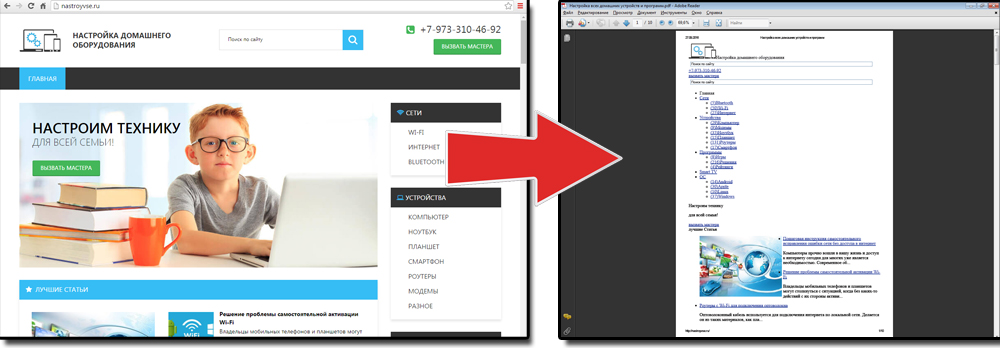
Еще один способ — сохранить как PDF-страницу с помощью штатных средств Chrome.
Эта функция доступна исключительно в Chrome. Для других веб-обозревателей нужны плагины. Printpdf для Firefox и Web2PDFConvert для Opera.
Утилиты для сохранения сайтов целиком
Есть программы для копирования ресурсов глобальной сети целиком. То есть со всем контентом, переходами, меню, ссылками. По такой странице можно будет «гулять», как по настоящей. Для этого подойдут следующие утилиты:
- HTTrack Website Copier.
- Local Website Archive.
- Teleport Pro.
- WebCopier Pro.
Есть много способов перенести страницу сайта на ПК. Какой выбрать — зависит от ваших нужд. Если хотите сохранить информацию, чтобы потом её изучить, достаточно обычного снимка экрана. Но когда надо работать с этими данными, редактировать их, добавлять в документы, лучше скопировать их или создать html-файл.
Источник: nastroyvse.ru