
Разберём основы логирования в Docker и Kubernetes, а затем рассмотрим два инструмента, которые можно смело использовать на продакшене: Grafana Loki и стек EFK: Elasticsearch + Fluent Bit + Kibana.
Логирование в Docker
На уровне Kubernetes приложения запущены в Pod’ах, но на уровне ниже они всё-таки работают обычно в Docker. Поэтому нужно настроить логирование таким образом, чтобы собирать логи с контейнеров. Контейнеры запускает Docker, значит надо разобраться, как логирование устроено на уровне Docker.
Надеюсь, каждый читатель знает: логи приложения надо писать в stdout/stderr, а не внутрь контейнера. Логи агрегирует Docker Daemon, и он работает именно с теми логами, которые отправляются на stdout/stderr. К тому же запись логов внутрь контейнера чревата проблемами: контейнер пухнет от растущего лога (так как никакого Logrotate в контейнере скорее всего нет), а Docker Daemon и не в курсе про этот лог.
У Docker есть несколько лог-драйверов или плагинов для сбора логов контейнеров. В бесплатной версии Docker Community Edition (CE) лог-драйверов меньше, чем в коммерческой Docker Enterprise Edition (EE).
Где хранить логи в документе или регистре сведений?

Docker EE я ни разу не использовал на практике: в Southbridge мы стараемся придерживаться Open Source решений, да и клиентам большая часть дополнительных возможностей Docker EE не нужна.
Лог-драйверы в Docker CE:
local — запись логов во внутренние файлы Docker Daemon;
json-file — создание json-log в папке каждого контейнера;
journald — отправка логов в journald.

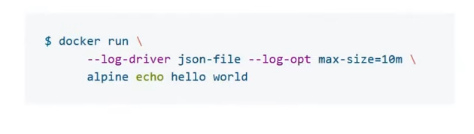
Настройки логирования в Docker находятся в файле daemon.json.
В поле “log-driver” указывают плагин, а в поле “log-opts” — его настройки. В примере выше указан плагин “json-file”, ограничение по размеру лога — “max-size”: “10m”; ограничение по количеству файлов (настройки ротации) — “max-file”: “3”; а также значения, которые будут прикручены к логам.
Некоторые настройки лог-драйвера можно задать через командную утилиту; это удобно, если отдельный контейнер нужно запустить с другим лог-драйвером.
Вот как выглядит схема логирования в Docker:
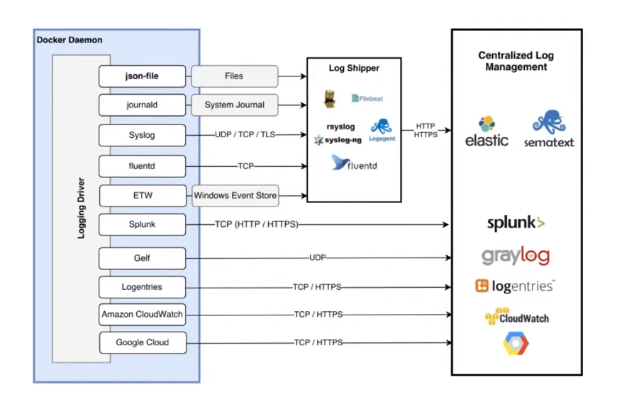
Как схема работает: лог-драйвер, например json-file, создаёт файлы. Сборщики логов (Rsyslog, Fluentd, Logagent и другие) эти файлы собирают и передают на хранение в Elastic, Sematext или другие хранилища.
Особенности логирования в Kubernetes
Упрощённо схема логирования в Kubernetes выглядит так: есть pod, в нём запущен контейнер, контейнер отправляет логи в stdout/stderr. Затем Docker создаёт файл и записывает логи, которые затем может ротировать.
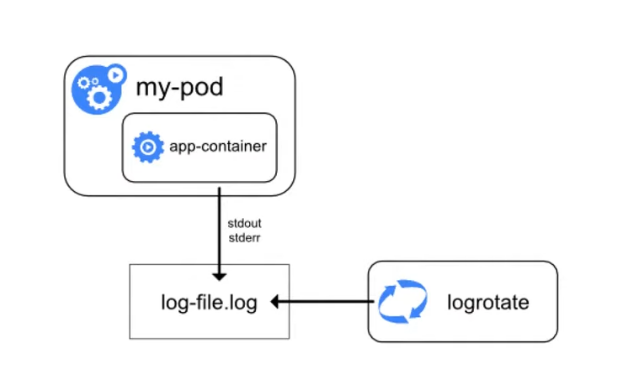
Рассмотрим особенности логирования в Kubernetes.
Сохранять логи между деплоями. Это обязательное условие для корректной настройки логирования. Если не сохранять логи между деплоями, то при выходе новой версии приложения логи предыдущей будут затираться, перезагрузка контейнера также будет чревата потерей логов. У Kubernetes есть ключик —previous, он позволяет посмотреть логи приложения до последнего рестарта Pod’а, но не глубже.
Агрегировать логи со всех инстансов. Если микросервисы хостятся в облаках, то за контроль системы отвечает облачный провайдер. Если микросервисы на своём железе, то помимо логов с контейнеров нужно собирать и логи системы.
Раньше не было удобных инструментов для сбора логов и с системы, и с микросервисов. Обычно один инструмент собирал системные логи (например, Rsyslog), второй — логи с Docker (например, journal-bit с настройкой лог-драйвера Docker на journald). Пробовали использовать journal-bit — собирать логи и с контейнеров (в лог-драйвере Docker указывать, что нужно писать логи в journald), и с системы (в CentOS 7 уже есть systemd и journald). Решение рабочее, но не идеальное. Если логов много, journal-bit начинает лагать, сообщения теряются.
Эксперименты продолжались, и нашёлся другой способ. В CentOS 7 основные системные логи (messages, audit, secure) дублируются в var-лог в виде файлов. В Docker тоже можно настроить сохранение логов в файлы json. Соответственно, эти файлы из CentOS 7 и Docker можно собирать вместе.
Со временем стало популярно решение ELK Stack. Это комбинация нескольких инструментов: Elasticsearch, Logstash и Kibana.
Elasticsearch хранит логи с контейнеров, Logstash собирает логи с инстансов, Kibana позволяет обрабатывать полученные логи, строить по ним графики. Некоторое время ELK Stack активно использовали, но, на мой взгляд, его время проходит. Позже расскажу, почему.
Добавлять метаданные. Pod’ы, приложения, контейнеры могут быть запущены где угодно. Более того, у одного приложения может быть несколько инстансов. Логи записаны в одном формате, а нам надо понять, какая именно это реплика, какой Pod это пишет, в каком namespace он находится. Именно поэтому логам нужно добавлять метаданные.
Парсить логи. Забавно, но расходы на поддержку системы логирования и мониторинга могут превысить затраты на основное приложение. Когда у вас летят десятки и сотни тысяч логов в секунду, это кажется закономерным, но всё же надо знать грань. Один из способов эту грань найти — парсинг логов.
Как правило, не нужно собирать и хранить все логи, надо отправлять на хранение только часть — например, логи со статусом «warning» или «error». Если речь про логи nginx или ingress-контроллеров, то отправлять на хранение можно только те, статус которых отличен от 200. Но это не универсальный совет: если вы строите каким-то образом аналитику по логам Nginx, то их очевидно стоит собирать.
Бездумно фильтровать логи не рекомендуют, потому что отфильтрованных данных может не хватить для нормальной аналитики. С другой стороны, возможно аналитику стоит проводить не на уровне логирования, а на уровне сбора метрик. Тогда не придётся хранить сотни тысяч строк с кодом 200. Один из подходов — получать информацию о трафике и ошибках из метрик ingress-контроллеров.
В общем, здесь надо хорошо подумать: что вы хотите хранить и как долго, потому что иначе возникнет ситуация, когда система логирования будет отнимать ресурсов больше, чем основной проект.
Пока нет стандартного решения для логирования. В отличие от мониторинга, где есть одно, наиболее распространенное решение Prometheus, в логировании стандарта нет. В рамках этой лекции мы рассмотрим два инструмента: один популярный, а второй — набирающий популярность. Помимо них есть и другие, но в этой статье мы их не коснёмся.
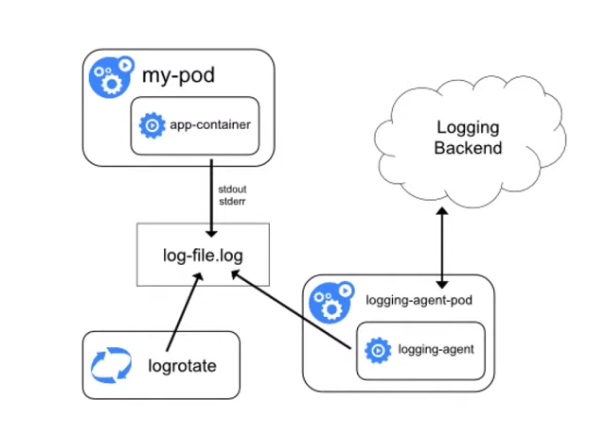
Учитывая все рассмотренные выше особенности, логирование в Kubernetes теперь можно представить на такой схеме:
Остаётся лог контейнера, ротирование, но появляется агент-сборщик, который подбирает логи и отправляет на хранение (на схеме — в Logging Backend). Агент работает на каждой ноде и, как правило, запущен в Kubernetes.
Теперь рассмотрим инструменты для логирования.
Grafana Loki
Grafana Loki появился недавно, но уже стал довольно известным. Его преимущества: лёгко устанавливается, потребляет мало ресурсов, не требует установки Elasticsearch, так как хранит данные в TSDB (time series database). В прошлой статье я писал, что в такой базе хранит данные Prometheus, и это одно из многочисленных сходств двух продуктов. Разработчики даже заявляют, что Loki — это «Prometheus для мира логирования».
Небольшое отступление про TSDB для тех, кто не читал предыдущую статью: TSDB отлично справляется с задачей хранения большого количества данных, временных рядов, но не предназначена для долгого хранения. Если по какой-то причине вам нужно хранить логи дольше двух недель, то лучше настроить их передачу в другую БД.
Ещё одно преимущество Loki — для визуализации данных используется Grafana. Очень удобно: в Grafana мы смотрим данные по мониторингу и там же, подключив Loki, смотрим логи. По логам можно строить графики.
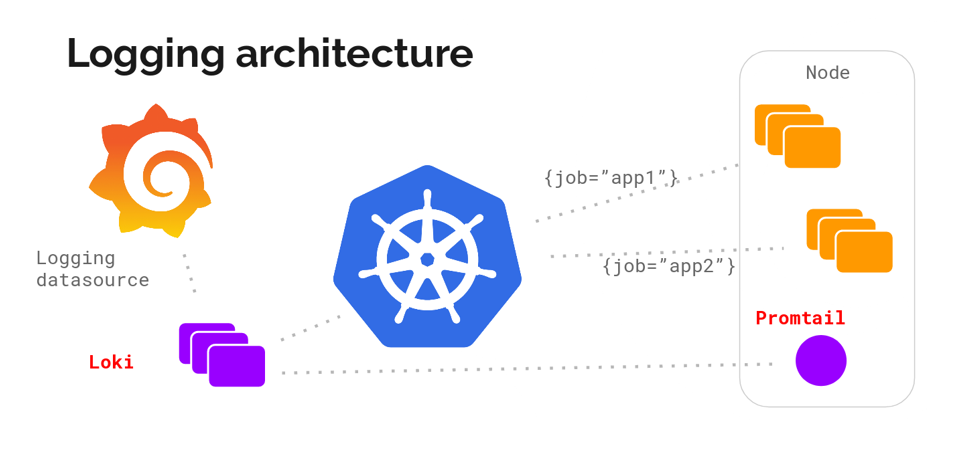
Архитектура Loki выглядит примерно так: ‘
С помощью DaemonSet на всех серверах кластера разворачивается агент — Promtail или Fluent Bit. Агент собирает логи. Loki их забирает и хранит у себя в TSDB. К логам сразу добавляются метаданные, что удобно: можно фильтровать по Pod’ам, namespaces, именам контейнеров и даже лейблам.
Loki работает в знакомом интерфейсе Grafana. У Loki даже есть собственный язык запросов, он называется LogQL — по названию и по синтаксису напоминает PromQL в Prometheus. В интерфейсе Loki есть подсказки с запросами, поэтому не обязательно их знать наизусть.
Документация к языку LogQL
Loki в интерфейсе Grafana
Используя фильтры, в Loki можно найти коды (“400”, “404” и любой другой); посмотреть логи со всей ноды; отфильтровать все логи, где есть слово “error”. Если нажать на лог, раскроется карточка со всей информацией по событию.
В Loki достаточно инструментов, которые позволяют вытаскивать нужные логи, (хотя честно говоря, технически их могло быть и больше). Сейчас Loki активно развивается и набирает популярность.
Elastic + Fluent Bit + Kibana (EFK Stack)
Стек EFK — это более классический, и при этом не менее популярный инструмент логирования.
В начале статьи упоминался ELK (Elasticsearch + Logstash + Kibana), но этот стек устарел из-за не очень производительного и при этом ресурсоёмкого Logstash. Вместо него стали использовать более легковесный и производительный Fluentd, а спустя некоторое время ему в помощь пришёл Fluent Bit — ещё более легковесный, и ещё более производительный агент-сборщик.
Если верить разработчикам, то Fluent Bit более, чем в 100 раз лучше по производительности, чем Fluentd: «там, где Fluentd потребляет 20 Мб ОЗУ, Fluent Bit будет потреблять 150 Кб» — прямая цитата из документации. Глядя на это, Fluent Bit стали использовать чаще.
У Fluent Bit меньше возможностей, чем у Fluentd, но основные потребности он закрывает, поэтому мы в основном пользуемся Fluent Bit.
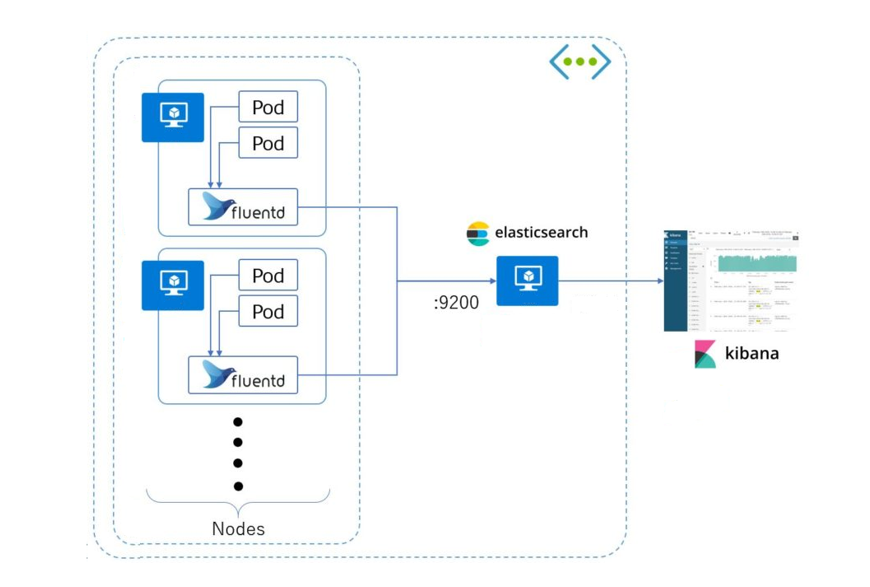
Схема работы стека EFK: агент собирает логи со всех Pod’ов (как правило, это DaemonSet, запущенный на всех серверах кластера) и отправляет в хранилище (Elasticsearch, PostgreSQL или Kafka). Kibana подключается к хранилищу и достаёт оттуда всю необходимую информацию.
Kibana представляет информацию в удобном веб-интерфейсе. Есть графики, фильтры и многое другое.
По логам можно создавать целые дашборды.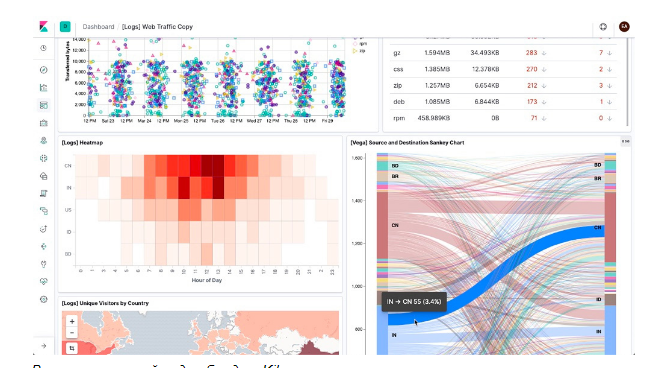
Вариант настройки дашборда в Kibana
Возможности Fluent Bit
Так как о Fluent Bit, как правило, слышали меньше, чем о Logstash, рассмотрим его чуть подробнее. Fluent Bit логически можно поделить на 6 модулей, на часть модулей можно навесить плагины, которые расширяют возможности Fluent Bit.
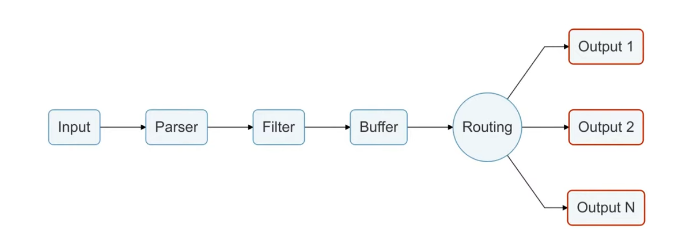
Модуль Input собирает логи из файлов, служб systemd и даже из tcp-socket (надо только указать endpoint, и Fluent Bit начнёт туда ходить). Этих возможностей достаточно, чтобы собирать логи и с системы, и с контейнеров.
В продакшене мы чаще всего используем плагины tail (его можно натравить на папку с логами) и systemd (ему можно сказать, из каких служб собирать логи).
Модуль Parser приводит логи к общему виду. По умолчанию логи Nginx представляют собой строку. С помощью плагина эту строку можно преобразовать в JSON: задать поля и их значения. С JSON намного проще работать, чем со строковым логом, потому что есть более гибкие возможности сортировки.
Модуль Filter. На этом уровне отсеиваются ненужные логи. Например, на хранение отправляются логи только со значением “warning” или с определёнными лейблами. Отобранные логи попадают в буфер.
Модуль Buffer. У Fluent Bit есть два вида буфера: буфер памяти и буфер на диске. Буфер — это временное хранилище логов, нужное на случай ошибок или сбоев. Всем хочется сэкономить на ОЗУ, поэтому обычно выбирают дисковый буфер, но нужно учитывать, что перед уходом на диск логи всё равно выгружаются в память.
Модуль Routing/Output содержит правила и адреса отправки логов. Как уже было сказано, логи можно отправлять в Elasticsearch, PostgreSQL или, например, Kafka.
Интересно, что из Fluent Bit логи можно отправлять во Fluentd. Так как первый более легковесный и менее функциональный, через него можно собирать логи и отправлять во Fluentd, и уже там, с помощью дополнительных плагинов, их дообрабатывать и отправлять в хранилища.
Если планируете использовать Elasticsearch
- Настройте оповещения с помощью ElastAlert. Эта программа вычленяет из общего потока логов важные сообщения и делает по ним алёрты в почту или другой канал. Правда, не так давно вышла грустная новость о том, что проект может скоро прекратить существование.
- Ротируйте логи с помощью приложения Curator или обращения к API Elasticsearch. Сам Elastic, в принципе, сейчас делает существенные шаги по управлению жизнью индексов без применения сторонних инструментов. В целом нет никакого смысла хранить логи долго: вряд ли какой-то лог понадобится спустя две недели — если он действительно критичный, за две недели он точно будет отработан. На крайний случай старые логи можно архивировать и отправлять куда-нибудь на долгосрочное хранение. Я слышал про особенные логи, которые положено по закону хранить до 5 лет. Лично с таким не сталкивался, но я бы подобную информацию не приравнивал к обычным логам, и возможно даже хранил их отдельно.
Может быть интересно:
- Интенсив по Python для инженеров и разработчиков
- Курс по GoLang для инженеров
Источник: slurm.io
C#. Установка и настройка NLog
Многие начинающие разработчики рано или поздно сталкиваются с необходимостью ведения журналов работы приложения, или попросту лог-файлов. Самостоятельно разрабатывать функции ведения журналов не самая хорошая идея, тем более, что существует огромное множество готовых пакетов логгирования. Не будем перечислять их все и рассматривать достоинства и недостатки различных решений. Цель данной статьи показать, как использовать один из популярных пакетов по ведению разного рода журналов NLog в своем приложении.
Для начала, создадим консольное приложение demoNlog

В проекте следует перейти в установщик пакетов NuGet

Далее, необходимо найти и установить два пакета NLog и NLog.Config

Важный момент, конфигурационный файл NLog.Config должен находиться в директории программы, поэтому необходимо выставить свойство файла «Копировать в выходной каталог» в статус «Всегда копировать». Это позволит упростить и автоматизировать применение изменений конфигурации логгирования.

Теперь можно приступить к настройке логгирования.
Определим, для примера, следующую задачу логгирования: Каждый день в отдельный файл, пишем все события начиная с уровня Debug и выше, логи пишутся в папку «logs».
Для начала необходимо в секцию прописать параметры целевого вывода:
/logs/$.log» layout=»$ $> $» />

Таким образом, мы создаем целевой вывод с именем filedata, типом вывода File, и целевой файл logsYYYY-MM-DD.log будет создаваться новый каждый день с именем даты.
Формат вывода будет следующего вида:
2018-04-20 12:27:05.9121 DEBUG debug message
После этого, в секции необходимо добавить следующие параметры:

Таким образом в лог будет попадать информация с минимальным уровнем Debug и попадать в целевой лог filedata.
Теперь пропишем в нашей программе следующий код
using NLog; namespace demoNlog < internal class Program < private static Logger logger = LogManager.GetCurrentClassLogger(); private static void Main(string[] args) < logger.Trace(«trace message»); logger.Debug(«debug message»); logger.Info(«info message»); logger.Warn(«warn message»); logger.Error(«error message»); logger.Fatal(«fatal message»); >> >
После работы программы в папке logs будет создан лог-файл, в котором будет отражен журнал работы программы:
2018-04-23 13:20:34.9792 DEBUG debug message 2018-04-23 13:20:35.0552 INFO info message 2018-04-23 13:20:35.0552 WARN warn message 2018-04-23 13:20:35.0552 ERROR error message 2018-04-23 13:20:35.0552 FATAL fatal message
Пример описан в видео на нашем канале:
ссылки к статье:
Текст примера: [wpdm_package 24 594 times, 1 visits today)
Источник: subreal-team.com
10 сборщиков логов с открытым исходным кодом для централизованного ведения журнала
Обзоры
Автор cryptoparty На чтение 8 мин Опубликовано 15.01.2019
Точно так же как безопасность, регистрация системных сообщений – другой ключевой компонент веб-приложений (или приложений в целом), который отодвигается на второй план из-за старых привычек и неспособности видеть впереди.
То, что многие считают бесполезными набросками цифровой ленты, – это мощные инструменты, позволяющие заглянуть в ваши приложения, исправить ошибки, улучшить слабые места и порадовать клиентов.
Прежде чем мы перейдем к централизованному ведению журналов, давайте сначала рассмотрим, почему ведение журналов ( логирование ) так важно.
Два типа (уровня) регистрации сообщений журналов
Компьютеры являются детерминированными системами, кроме случаев, когда это не так.
Как безопасник, я сталкивался со многими случаями, когда наблюдаемое поведение приложения ставило всех в тупик целыми днями, но ключ к разгадке всегда был в журналах.
Каждое программное обеспечение, которое мы запускаем, производит (или, по крайней мере, должно генерировать) журналы, которые сообщают нам, через что они проходили, когда возникала проблемная ситуация.
Теперь, как мне кажется, ведение журнала бывает двух типов: автоматически сгенерированные журналы и сгенерированные программистом журналы.
Обращаем ваше внимание, что этих различий и классификации нету в учебниках, и цитирование меня по этой терминологии доставит вам неприятности. ?
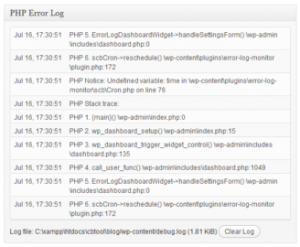
Изображение выше показывает то, что можно назвать автоматически сгенерированным журналом.
В данном конкретном случае это система WordPress, регистрирующая непредвиденное состояние (уведомление) при запуске некоторого кода PHP.
Журналы, подобные этим, создаются постоянно – с помощью инструментов баз данных, таких как MySQL, веб-серверов, таких как Apache, языков программирования и сред, мобильных устройств и даже операционных систем.
Они редко содержат большую ценность, и программисты даже не удосуживаются их изучить, кроме случаев, когда что-то идет не так.
В такие моменты они копаются глубоко в коде, пытаясь понять, что пошло не так.
Но автоматически сгенерированные журналы могут помочь только так сильно.
Если несколько человек имеют доступ администратора к сайту, например, и один из них удаляет важную часть информации, невозможно обнаружить виновника с помощью автоматически сгенерированных журналов.
С точки зрения систем, связанных как приложение, это был просто еще один день в работе – кто-то имел необходимые полномочия для выполнения задачи, и поэтому система выполнила ее.
Здесь нужен дополнительный уровень явной, обширной регистрации, которая создает следы для человеческой стороны вещей.
Это то, что я называю созданными программистом журналами, и они составляют основу чувствительных отраслей, таких как банковское дело.
Вот пример того, как может выглядеть такая схема регистрации:
Логгирование это сила
Итак, с учетом этих двух типов журналов в системе, вот как вы можете использовать их и усилить воздействие.
Боевой дух и продуктивность команды
Как я уже говорил, когда ошибки долго не отслеживаются, разработчики в вашей команде разочаровываются и теряют все больше и больше времени, закрывая свои хвосты.
И вот в чем дело с отладкой – она требует свежего, любопытного ума с самого начала.
И что затрудняет отладку?
По моему опыту, отсутствие ведения журнала или отсутствие знаний о ведении журнала.
Для начала вы можете не осознавать, что ваша любимая база данных – это просто еще одна часть программного обеспечения, которая генерирует журналы, или вы не будете интенсивно регистрировать события в своем приложении (см. Журналы, сгенерированные программистом выше).
Я особенно помню случай, когда приложение перестало отвечать на запросы, и никто не знал, почему.
Несколько дней спустя виновником стало ограничение дискового ввода-вывода из-за чрезмерного трафика.
Потому что никто не удосужился посмотреть журналы,и никто не мог понять, почему система упала.
Если вы регулярно посещаете журнал медленных запросов, вы узнаете, какие операции занимают больше всего времени, и, следовательно, обнаружите небольшие, но важные области, требующие работы.
Часто такие небольшие изменения работают лучше, чем удвоение емкости оборудования.
Невозможно сосчитать, сколько способов решения проблем подарит вам хорошая система журналов.
Возможно, лучшим аргументом является то, что это автоматическое действие, которое когда-то настроено, не нуждается в каком-либо мониторинге и однажды спасет вас от разорения.
В связи с этим давайте рассмотрим некоторые из удивительных сборщиков журналов с открытым исходным кодом (унифицированных инструментов ведения журналов).
1 Graylog
2 Logstash
Если вы являетесь поклонником или пользователем стека Elastic, стоит попробовать Logstash (стек ELK )
Как и другие инструменты ведения журнала в этом списке, у Logstash,полностью открытый исходный код, дает вам свободу развертывания и использования по своему усмотрению.
Но не вводите себя в заблуждение: Logstash – это иснтрумент, возможности которого намного превосходят любые скромные средства ведения журналов.
Он способен собирать огромные объемы данных с разных платформ, позволяет определять и выполнять собственные конвейеры данных, понимать неструктурированные дампы журналов и многое другое.
Конечно, единственным ограничением является то, что он работает только с набором продуктов Elastic, но если вы скоро начнете и хотите масштабироваться, Logstash – это то, что вам нужно!
3 Fluentd
Среди централизованных инструментов ведения журналов, которые выполняют роль промежуточного уровня для приема данных, Flutend является первым среди равных.
Обладая превосходной библиотекой плагинов, Fluentd может собирать данные практически из любой производственной системы, перемешивать их в нужной структуре, создавать собственный конвейер и передавать его на свою любимую аналитическую платформу, будь то MongoDB или Elasticsearch.
Fluentd построен на Ruby, является продуктом с полностью открытым исходным кодом и пользуется большой популярностью благодаря своей гибкости и модульности.
С такими крупными компаниями, как Microsoft, Atlassian и Twilio, использующим эту платформу, Fluentd нечего доказывать. ?
4 Flume
Если на самом деле вам нужны действительно большие наборы данных, и вы в конечном итоге захотите объединить все в нечто вроде Hadoop, Flume – один из лучших вариантов.
Это «чистый» проект с открытым исходным кодом, в том смысле, что он поддерживается нашим любимым Apache Foundation, что означает отсутствие корпоративного плана.
Это может быть то, что вы точно ищете. ?
Написанный на Java (который продолжает удивлять меня, когда дело доходит до революционных технологий), исходный код Flume полностью открыт.
Flume лучше всего подойдет вам, если вы ищете распределенную отказоустойчивую платформу для загрузки данных для работы в тяжелых условиях.
5 Octopussy
Я даю ноль из десяти наименованию продукта, но Octopussy может быть хорошим выбором, если ваши потребности просты, и вы задаетесь вопросом о том, что же такое суета, связанная с конвейерами, приемом, агрегацией и т. д
По моему мнению, Octopussy покрывает потребности большинства продуктов (оценочная статистика бесполезна, но, если бы мне пришлось угадывать, я бы сказал, что в реальном мире она учитывает 80% случаев использования)
У Octopussy нет отличного пользовательского интерфейса:
но он компенсирует скорость и отсутствие раздувания.
Исходный код доступен на GitHub, как и ожидалось, и я думаю, что он заслуживает серьезного изучения.
6 LOGalyze
LOGalyze был коммерческим продуктом, который недавно стал инструментом с открытым исходным кодом.
Хотя я не смог реализовать проект на GitHub, они сделали установщик Windows и весь исходный код загружаемым.
Если вы намерены участвовать в сообществе, вы можете найти подробную информацию о списке рассылки здесь.
LOGalyze – это относительно гибкое и мощное предложение, которое отлично подойдет для развертываний в одной системе, которые стремятся объединить ведение журналов из известных источников, таких как Postfix, Apache и т. д. и выводить их в форматах CSV, PDF, HTML или аналогичных.
Да, он не делает все, но поскольку это был коммерческий продукт в свое время, он делает это довольно хорошо.
7 LogPacker
Когда дело доходит до выбора инструмента для работы, у меня есть два критерия: он должен быть целенаправленным и опираться на активную бизнес-модель.
Проблема программного обеспечения с открытым исходным кодом, как правило, заключается в том, что через несколько месяцев / лет вероятность застоя или выхода из строя высока.
Там нет подсчета того, сколько инструментов ведения журнала было запущено,а только можно найти количество на кладбище GitHub.
По этому критерию LogPacker – мой любимый.
8 Logwatch
Я уверен, что среди нас есть те, кто не хочет, чтобы вся церемония была связана с «единой», «централизованной» системой ведения журналов.
Их бизнес базируется на отдельных серверах, и они ищут что-то быстрое и эффективное для просмотра своих файлов журналов.
Ну тогда, скажи привет Logwatch.
После установки LogWatch может сканировать системные журналы и создавать отчеты нужного вам типа.
Это несколько устаревшее программное обеспечение (читай «надежное»), хотя оно было написано на Perl.
Итак, вам понадобится Perl 5.6+ на вашем сервере для его запуска.
У меня нет скриншотов, которыми можно поделиться, потому что это чисто командная строка, демонизированный процесс.
Если вы наркоман CLI и любите стиль старой школы, вам понравится Logwatch!
9 Syslog-ng
Инструмент Syslog-ng был разработан как способ обработки файлов системного журнала (установленный протокол клиент-сервер для регистрации в системе) в режиме реального времени.
Однако со временем он стал поддерживать другие форматы данных: неструктурированные, SQL и NoSQL.
Как работает протокол системного журнала, довольно четко подытожено на следующем рисунке.
syslog-ng – это надежный инструмент для сбора и классификации журналов промышленного уровня, написанный на языке Си и давно известный в отрасли.
Лучшая часть – это расширяемость, позволяющая вам писать плагины на C, Python, Java, Lua или Perl.
10 Inav
От глупой командной строки, не требующих настройки инструментов до полномасштабной обработки данных – все это здесь!
Я что-то пропустил? Конечно, я сделал это!
Пожалуйста, дайте мне знать в комментариях, и я буду рад добавить эту сюда
Пожалуйста, не спамьте и никого не оскорбляйте. Это поле для комментариев, а не спамбокс. Рекламные ссылки не индексируются!
Источник: itsecforu.ru