
Так как это нейросеть, то что бы добиться приемлемого качества голоса, необходимо долго «учить» её, на основе разных голосовых записей человека
это занимает сотни часов и десятки гигабайт файлов.
Но в этой статье мы разберём 2 возможных пути этой реализации:
1) Установка утилиты непосредственно на наш ПК и проведение всех манипуляций практически с нуля(заранее скачав «натренированные» данные)
2) Онлайн решение на Колаборатории гугла (быстро,есть русский язык)
Сразу скажу, что онлайн решение будет более быстрым и менее геморным, но а если вы хотите тренировать свою нейросеть, то тут никак не обойтись без установки всего этого на ПК.
Итак, рассмотрим сначала первый вариант.
Устанавливаем Multi-Tacotron-Voice-Cloning на ваш ПК
1)Переходим по ссылке на github проект клонирования голоса: https://github.com/vlomme/Multi-Tacotron-Voice-Cloning
и сразу скачаем проект на пк
2)Скачиваем заранее натренированные модели:
Нейросети копируют голоса людей за 5 секунд
3) Если ваш ПК и интернет это позволяет, рекомендуется также скачать
готовый сет для клонирования голоса:
Дальше разберемся что куда кидать.
4)Если вы устанавливали Avatarify(подмена лица), то у вас должен быть установленная Anaconda prompt.
Если у вас её нет, то скачиваем по ссылке:
Нужно выбрать Python 3.7 версию
5) Нужно также скачать и установить тулкит CUDA 10.0, если конечно до этого не устанавливали.
6)После всего этого, запускаем Anaconda prompt(miniconda3) и прописываем следующие команды:
conda create -n clone python=3.6
Источник: dzen.ru
Голосовой DeepFake: технология клонирования голоса

Как научить искусственный интеллект читать текст любым голосом? Рассказываем, что известно о технологии клонирования голоса, на примере открытого репозитория Real-Time Voice Cloning.
Проблема синтеза речи из текста (Text-to-Speech, TTS) представляет собой одну из классических задач для искусственного интеллекта. Цель ИИ – автоматизировать процесс чтения текста, основываясь на наборах данных, содержащих пары «текст – аудиофайл».
Одной из важных проблем синтеза речи является задача создания образа голоса со всеми его характерными особенностями. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Решение указанной проблемы имеет множество практических приложений:
- адаптация голосов актёров при локализации фильмов
- озвучивание персонажей игр
- голосовые поздравления
- начитка аудиокниг, в том числе клонирование голосов родителей для сказок, прочитанных профессиональными дикторами
- создание аудио- и видеокурсов
- рекламные видеоролики и аудиореклама
- голоса ботов и умных устройств, персонализированных голосовых помощников
- синтез устной речи естественного звучания для немых людей, в том числе для людей, утративших возможность говорить из примеров их собственной речи
- адаптация устной речи под модель местного акцента
Очевидно, что подобные технологии могут применяться с преступными целями: мошенничество, телефонное хулиганство, компрометирование в результате совмещения с технологией DeepFake. Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Нейросети теперь ещё и изменяют голос! Обзор Voice.ai
Для обучения системы необходимо иметь большое количество сопоставленных аудиозаписей и текстов. В случае голосов знаменитостей можно прибегать к помощи записей публичных выступлений, интервью, результатам творческой деятельности и т. п. В качестве текстовых пар могут применяться стенограммы или тексты, полученные в результате коррекции автоматически распознанной речи.
Отличительной особенностью последних разработок является то, что для создания правдоподобного образа «голосовой мишени» достаточно всё меньших интервалов звучащей устной речи.
Современное состояние
В сфере создания инструментов для клонирования голоса работают множество команд, стремящихся к коммерциализации программных продуктов. По приведённым ниже ссылкам вы можете оценить текущее состояние технологии:

- Resemble.AI (предоставляется демоверсия программы).
- iSpeech (есть демо для 27 языков, включая русский).
- Lyrebird AI (можно загрузить демоверсию на 3 часа речи).
- Vera Voice, созданный компанией Screenlife Technologies Тимура Бекмамбетова и командой проекта «Робот Вера». Недавно команда показала пример адаптации голосов русских знаменитостей:
Процесс обучения
Вместо предобученных моделей можно также задействовать модели, обученные на других примерах. Процесс обучения происходит посредством последовательного запуска скриптов той же библиотеки. Для того, чтобы узнать дополнительную информацию о каждом из скриптов, при используйте запуске из командной строки добавляйте аргумент -h .
Начинаем с подготовки данных для обучения кодера:
python3 encoder_preprocess.py
Для обучения кодер использует окружение visdom . Инструменты окружения выглядят следующим образом:
При необходимости вы можете отключить окружение с помощью аргумента —no_visdom .
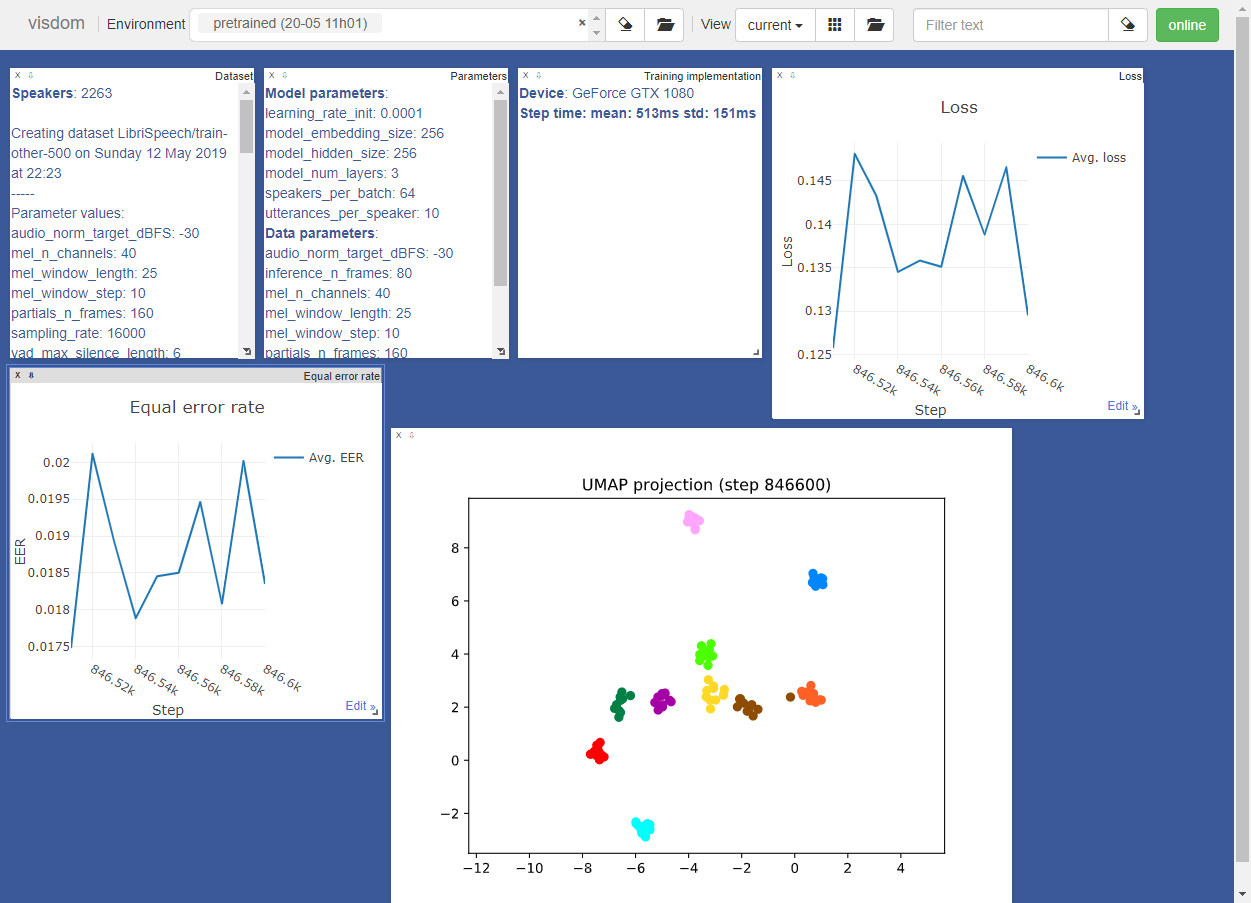
Обучаем кодер:
python3 encoder_train.py my_run
Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
python3 synthesizer_preprocess_audio.py
python3 synthesizer_preprocess_embeds.py /synthesizer
Теперь вы можете обучить синтезатор:
python3 synthesizer_train.py my_run /synthesizer
Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
python3 vocoder_preprocess.py
Наконец, обучаем вокодер:
python3 vocoder_train.py
Вокодер выводит сгенерированные аудиофайлы в директорию модели.
По материалам vc.ru. Автор matyushkin
Share on Facebook
![]()
Follow us
Posted in Голос, Обзор Tagged Deepfake, DeepFakeChallenge
Источник: deepfakechallenge.com
Клонирование голоса при помощи нейросети

Так как это нейросеть, то что бы добиться приемлемого качества голоса, необходимо долго «учить» её, на основе разных голосовых записей человека
это занимает сотни часов и десятки гигабайт файлов.
Но в этой статье мы разберём 2 возможных пути этой реализации:
1) Установка утилиты непосредственно на наш ПК и проведение всех манипуляций практически с нуля(заранее скачав «натренированные» данные)
2) Онлайн решение на Колаборатории гугла (быстро,есть русский язык)
Сразу скажу, что онлайн решение будет более быстрым и менее геморным, но а если вы хотите тренировать свою нейросеть, то тут никак не обойтись без установки всего этого на ПК.
Итак, рассмотрим сначала первый вариант.
Устанавливаем Multi-Tacotron-Voice-Cloning на ваш ПК
1)Переходим по ссылке на github проект клонирования голоса: https://github.com/vlomme/Multi-Tacotron-Voice-Cloning
и сразу скачаем проект на пк

2)Скачиваем заранее натренированные модели:
3) Если ваш ПК и интернет это позволяет, рекомендуется также скачать
готовый сет для клонирования голоса:
Дальше разберемся что куда кидать.
4)Если вы устанавливали Avatarify(подмена лица), то у вас должен быть установленная Anaconda prompt.
Если у вас её нет, то скачиваем по ссылке:
Нужно выбрать Python 3.7 версию
5) Нужно также скачать и установить тулкит CUDA 10.0, если конечно до этого не устанавливали.
6)После всего этого, запускаем Anaconda prompt(miniconda3) и прописываем следующие команды:
conda create -n clone python=3.6

Далее нас попросят нажать y и продолжить(enter):

Готово,теперь нам нужно активировать виртуальную среду, которую мы только что сделали
Для этого прописываем там же:
conda activate clone
После этого, нужно устанавливать необходимые пакеты
прописываем в консоле Anaconda:
conda install pytorch

Теперь распаковываем архив с github, и копируем его путь.Далее в консоли анаконды прописываем:
cd (ВАШ ПУТЬ К ФАЙЛАМ С АРХИВА)
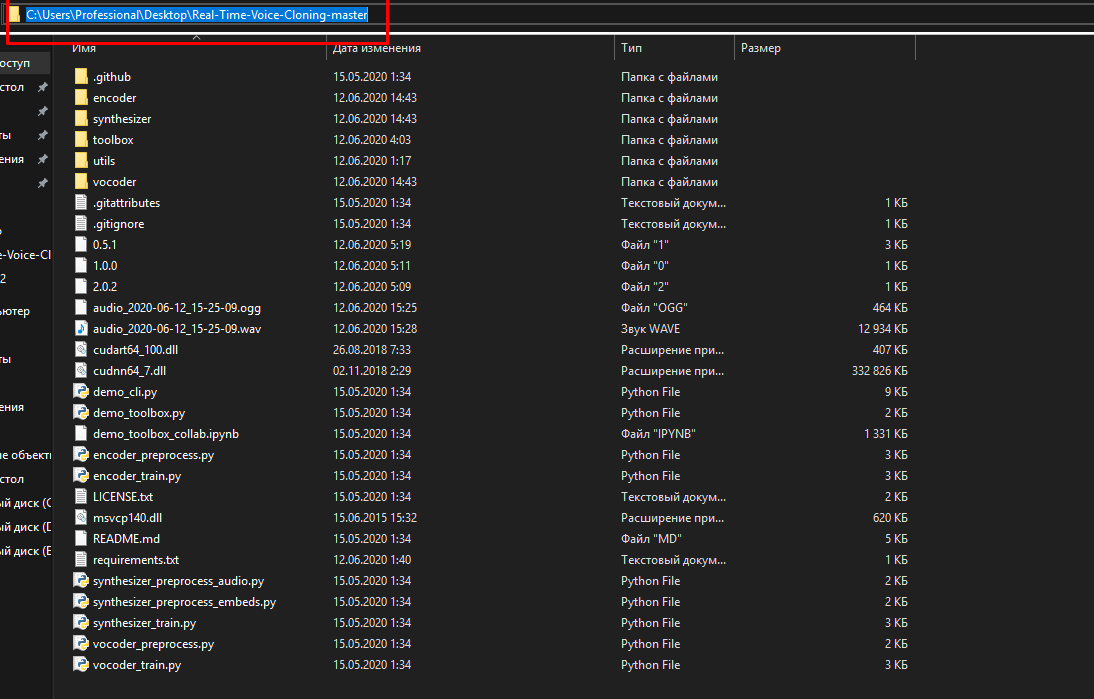

pip install -r requirements.txt

пошла установка необходимых модулей,нужно дождаться конца установки.
ещё пропишем одну команду:
conda install numba
Теперь нужно распаковать те доп. архивы,которые вы скачивали ранее
архив pretrained.zip распаковываем прямо в папку с программой Real-Time-Voice-Cloning-master, а второй архив если скачивали:
создаём в папке с программой подпапку LibriSpeech
в ней создаём папку train-clean-100 и туда скидываем данные с распакованного архива.
Так же,что бы не было ошибок, закидываем в папку утилиты dll файлы CUDA:
Их можно найти в папке: C:ProgramDataMiniconda3pkgspytorch-1.0.0-py3.7_cuda100_cudnn7_1Libsite-packagestorchlib
Если устанавливали avatarify, то тут: ProgramDataMiniconda3envsavatarifyLibsite-packagestorchlib
Теперь попробуем запустить:
Вводим в анаконде следующее:
Процесс много жрёт! на системе с 16 гб ОЗУ пришлось закрыть почти все программы, имейте ввиду.
У нас откроется главное окно:

Вверху по кнопке Browse мы загружаем нужный нам образец голоса в формате wav. Либо можно записать фрагмент своего голоса, нажав на кнопку record.
Вы должны понимать, что речь должна быть нормальной, состоящей из 9-10 слов, обладать чёткостью. Натренированные данные заточены под английский текст, так что с русским тут не выйдет(англ. более менее)

После того, как загрузили голос, пишем нужный текст на английском вверху справа, и нажимаем кнопку Synthesize and vocode. После чего, мы услышим полученный вариант голоса
Если несколько раз проводить эту процедуру, то качество голоса может самостоятельно улучшаться.
Вот пример голоса Игоря, до и через несколько проходов:
Если хотите сохранить результат:
Редактируем изначально файл demo_cli.py, прописываем нужный текст и имя исх.файла:

Сохраняем, и в анаконде вместо python demo_toolbox.py прописываем:
И всё, пойдёт процесс генерации. По завершению вы получите в той же папке готовый вариант.
Что же,вариант очень интересный, но занимает много времени,ресурсов и сил.
Да и тренировать свои данные надо,не вариант
переходим ко второму варианту.
Tacotrone на Colaboratory
1.Переходим по ссылке
2.Нажимаем Connect в правом углу

Теперь во вкладке runtime выбираем run all.


Теперь в конце отобразятся 2 аудиофайла: Оригинал и склонированный, с заданным текстом.
здесь уже подготовлено всё,даже пример голоса. Можете попробовать написать свой текст на русском в этом поле:

Теперь, если мы хотим загрузить чей-то голос, то для начала надо подготовить его в формате wav, затем открыть слева в меню Files:


Нажимаем кнопку Upload вверху, и выбираем наш подготовленный голос. достаточно даже 9-15 секунд речи.
после того, как файл прогрузился, сместим его ближе к ex.wav:

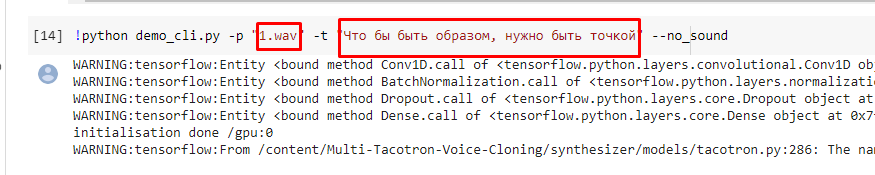
В этой строчке меняем сначала название файла на ваш загруженный, и также меняем текст на желаемый.
После этого нажимаем запуск кода:
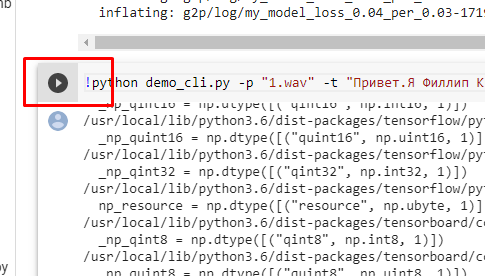
После завершения, прокручиваем вниз и запускаем следующий код:

Ниже отобразится клонированный файл,который вы можете прослушать либо скачать
Вот пример голоса Киркорова:
Стоит отметить, что не с каждым примером голоса всё работает корректно.Речи может совсем не быть, или очень не разборчивая
Так что нужно поэкспериментировать, ведь тут тоже данные тренировались на шаблонном примере, но может выйти очень неплохой результат и с этими данными.Экспериментируйте с разными вариантами текста, а так же голоса.
Стоит отметить, что при перезагрузке этого сайта вам придётся проводить все манипуляции заново, а так же не будут сохраняться ваши загруженные файлы.
Источник: telegra.ph