
Разработать программу для тестирования знаний в разных областях. Пользователь должен ответить на несколько вопросов, которые случайным образом выбираются из общей базы вопросов. После того как пользователь ответил на все вопросы, программа должна высчитать и выдать результат прохождения теста — процент правильных ответов. Также необходимо дать возможность пользователю подключать внешние файлы, содержащие вопросы и варианты ответов к ним. Для того чтобы пользователь не смог прочитать правильные ответы, следует зашифровать файл с вопросами и ответами.
Структура базы вопросов и ответов
Перед тем как разработать сам тест, разберем содержимое файла, в котором будут храниться вопросы и варианты ответов к ним. Это будет ini-файл следующей структуры:
num=количество вопросов в базе
0=Первый вопрос
1=Второй вопрос
0=0твет к первому вопросу
1=0твет ко второму вопросу
0=Неправильный вариант к первому вопросу
1= Неправильный вариант ко второму вопросу
0=Неправильный вариант к первому вопросу
1= Неправильный вариант ко второму вопросу
0=Неправильный вариант к первому вопросу
1=Неправильный вариант ко второму вопросу
В этом ini-файле шесть разделов: num, Q, A, W1, W2 и W3. Как вы понимаете, если кто-то заглянет в этот файл, то уже через несколько минут он будет знать правильные ответы на все вопросы. А если он этот файл подкорректирует, то и вовсе будет получать только правильные варианты ответов. Для того чтобы этого не случилось, мы будем шифровать нашу базу вопросов.
Валерий Викторович Пякин. Вопрос-Ответ от 3 июля 2023 г.
Это можно сделать с помощью программы Блокнот-шифровальщик, рассмотренной в главе 7. Для шифрования выберем небольшое смещение, например, 101. После того как вы создали все вопросы и варианты ответов к ним, не забудьте указать количество вопросов в разделе num. После этого зашифруйте базу, используя смещение 101.
⊚ Пример зашифрованной базы вопросов/ответов можно найти на прилагаемом к книге компакт-диске в файле Chapter_13comp.ini.
Разработка формы
Создайте новый проект Delphi. Присвойте свойству Caption формы значение Tester, а свойству BorderStyle — bsNone. У верхнего края формы разместите компонент Label категории Standard, присвоив его свойству Caption значение Первый вопрос:.
Ниже разместите компонент Memo категории Standard, с помощью которого мы будем отображать текущий вопрос. Присвойте свойству Memo1.Readonly значение True, чтобы пользователь не мог изменить текст вопроса.
Под вопросом будут расположены варианты ответов. Разместите под компонентом Memo1 компонент RadioGroup (группа переключателей) категории Standard и присвойте его свойству Caption значение Варианты ответов:. Разместите на компоненте RadioGroup1 четыре компонента RadioButton (переключатели) категории Standard. Очистите для каждого из них свойство Caption, а свойству Name присвойте значения an1, an2, an3 и an4 соответственно.
ЗА ВСЁ ОТВЕЧУ! (Анимация Ответы на вопросы)
В любом месте формы разместите компонент Label, который изначально будет невидимым. Он будет служить для отображения результатов и в последствии будет растянут на всю форму. Установите для него свойства согласно табл. 13.1.
Таблица 13.1. Свойства компонента Label, отображающего результат теста
| Alignment | taCenter | Выравнивание текста — по центру |
| Color | clBlack | Цвет фона — черный |
| Font.Color | clRed | Цвет текста — красный |
| Font.Name | Arial | Название шрифта |
| Font.Size | 26 | Размер шрифта |
| Font.Style | [fsBold] | Начертание шрифта — полужирное |
| Visible | False | При запуске программы метка невидима |
Осуществлять переход к следующему вопросу мы будем с помощью панелей. Разместите под вариантами ответов пять компонентов Panel категории Standard. Для каждой из них присвойте свойству Caption значение Следующий вопрос>>>>>, свойству Color — значение clMaroon, а свойству Font.Color — значение clWhite. Присвойте им имена (свойство Name) p1, р2, p3, р4 и р5.
Для того чтобы убрать выпуклость и привести панель к виду стильной кнопки, изменим значение свойства BevelInner на bvRaised, а свойства BevelOuter — на bvLowered. Для всех панелей, кроме p1, присвойте свойству Visible значение False (изначально будет видна только первая панель).
Поскольку в программе будет предусмотрена возможность динамической загрузки базы вопросов/ответов, нам понадобится диалоговое окно открытия файла. Для этого разместим на форме компонент OpenDialog категории Dialogs и присвоим ему имя Open1 (свойство Name). Кроме того, определите в свойстве Filter следующий фильтр: ini-файлы|*.ini|Все файлы|*.*.
Теперь разработаем меню программы. Для этого разместите на форме компонент MainMenu категории Standard и создайте меню в соответствии с рис. 13.1.
⇖ Разработка меню рассматривается в главе 6, «Программа просмотра рисунков».
Рис. 13.1. Меню для программы-теста
Полученная форма должна примерно соответствовать рис. 13.2.
Рис. 13.2. Форма программы-теста
Разработка программного кода
Для начала, объявим все глобальные переменные:
Источник: www.uhlib.ru
Как сделать интеллектуальное приложение вопросов и ответов базы знаний с GPT-3 и Ruby

На основе содержимого сайта компании по продаже автозапчастей Sterling Parts создадим приложение вопросов и ответов, для интеллектуальности которых используем GPT-3, для кода — Ruby.
Вопросы ИИ задают пользователи, ответы берутся со страниц FAQ, About Us и Terms and Conditions.
Необходимые условия
- Средний уровень знаний Ruby.
- Понимание, как интегрировать Ruby с Openai.
Github
Код доступен на Github.
Описание процесса
Чтобы подготовить базу знаний для задаваемых по ней в GPT-3 вопросов, создадим два скрипта на Ruby. В отличие от ChatGPT, обучим модель ответам по конкретному содержимому сайта.
Для этого используем массивы, известные в машинном обучении как векторные вложения. Вложение — это процесс преобразования фрагмента текста в массив чисел.
Вот вектор — числовое представление значения, которое содержится в тексте:
С помощью этих векторов при проведении семантического поиска в базе знаний отыскивается наиболее релевантная информация, затем применяется GPT-3 и на вопрос пользователя дается содержательный ответ.
Слово «семантический» относится к смысловому значению языка. Если при поиске по ключевым словам в базе данных выявляются точные или частичные совпадения, то при семантическом поиске — совпадения по смысловому значению или сути вопроса.
Вопрос: «Как резать яблоки?»
Статья базы знаний 1: «Чтобы очистить апельсин, сначала нужно взять машинку для очистки апельсинов».
Статья базы знаний 2: «Чтобы нарезать яблоко, сначала нужно взять острый нож».
При семантическом поиске как наиболее релевантная вернется статья базы знаний 2. Такой поиск достаточно интеллектуален, чтобы «понимать», что «резать» и «нарезать» семантически близки. В основе этого понимания — довольно сложная математика.
Чтобы реализовать семантический поиск в приложении, нужно преобразовать текст в векторные вложения.
В GPT-3 имеется конечная точка вложения, ею текст преобразуется в вектор из 1500 значений, каждое из которых — какой-то признак текста.
Вот признаки, которые могут быть в векторном вложении:
- Семантическое значение.
- Части речи.
- Частота использования.
- Ассоциации с другими словами.
- Грамматическая структура.
- Тональность.
- Длина текста.
В GPT-3 имеются ограничения по токенам, поэтому базу знаний разбиваем на фрагменты всего не более 3000 токенов или 2000 слов. Каждый фрагмент преобразуется в вектор и сохраняется в БД доступным для поиска.
Задаваемый пользователем вопрос тоже преобразуется в вектор, который в ходе определенного математического процесса задействуется для поиска в БД фрагмента базы знаний с наиболее релевантным значением.
Этот фрагмент и вопрос отправляются в GPT-3, откуда выдается содержательный ответ.
Описание процесса
В базе знаний вопросов и ответов будет два скрипта на Ruby: embeddings.rb для подготовки векторных вложений и скрипт ИИ questions.rb .
Вот этапы создания ИИ вопросов и ответов:
- Разбиваем данные базы знаний на фрагменты по 2000 слов каждом и сохраняем в текстовом файле.
- Преобразуем каждый текстовый файл в векторное вложение с помощью конечной точки вложений OpenAI. [embeddings.rb]
- Сохраняем в БД для последующих запросов вложения и исходный текст базы знаний. Базой данных будет CSV-файл. [embeddings.rb]
- Получаем пользовательский вопрос и преобразуем в его векторное вложение. [questions.rb]
- Сравниваем вектор вопроса по базе данных и находим текст базы знаний с ближайшим к вопросу семантическим значением. [questions.rb]
- Специальной подсказкой передаем пользовательский вопрос и текст базы знаний в конечную точку GPT-3 completions . [questions.rb]
- Получаем от GPT-3 ответ и показываем его пользователю. [questions.rb]
Этап 1. Подготовка данных
В GPT-3 подсказка и ответ вместе ограничены 4096 токенами, поэтому важно преобразовать данные базы знаний на фрагменты по 2000 слов. Нужно достаточно места для токенов вопроса и ответа.
По возможности создаем фрагменты с близким значением. На страницах FAQ, About Us и Terms and Conditions сайта Sterling Parts менее 1000-2000 слов, поэтому семантически имеет смысл поместить каждую из них в отдельный текстовый файл.
В приложении на Ruby создаем папку training-data , в ней будет текст базы знаний для приложения:
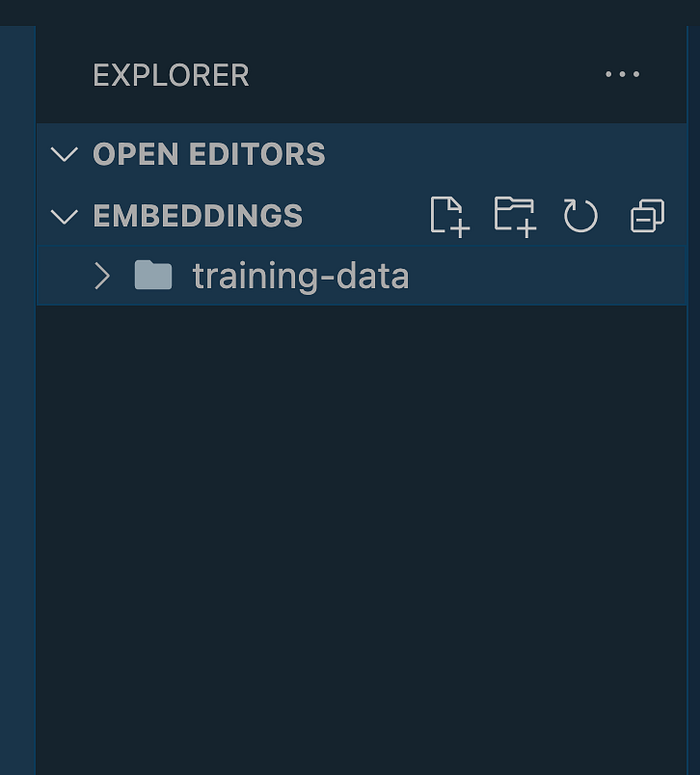
Эти страницы сайта Sterling Parts сохранятся в стандартных файлах .txt :
- https://www.sterlingparts.com.au/faqs;
- https://www.sterlingparts.com.au/about-us;
- https://www.sterlingparts.com.au/Terms-and-Conditions.
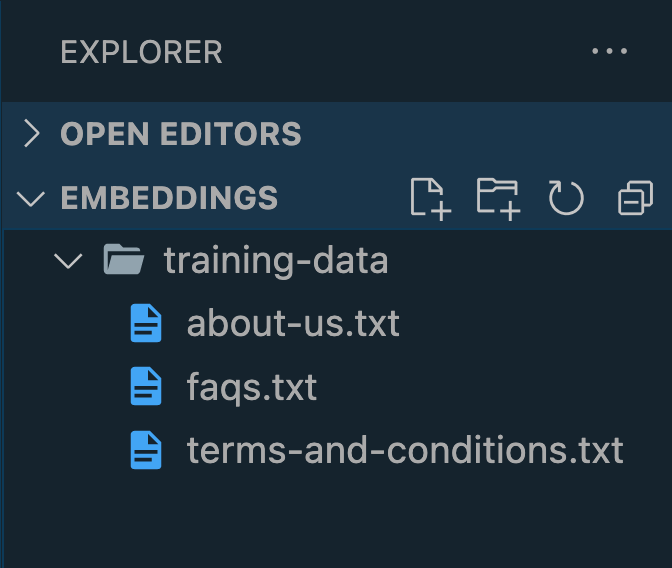
Страница Terms and Conditions — самая большая, 2008 слов. Скопируйте и вставьте свой контент в текстовые файлы папки training-data . Названия неважны, главное — чтобы файлы были .txt :
Этап 2. Преобразование данных в векторные вложения
Для работы с API OpenAI потребуется ruby-openai , устанавливаем нужные библиотеки:
gem install ruby-openai dotenv
Сохраняем API-ключ OpenAI в файле .env .
Импортируем библиотеку openai и API-ключом создаем новый экземпляр:
# embeddings.rb
require ‘dotenv’
require ‘ruby/openai’
Dotenv.load()
openai = OpenAI::Client.new(access_token: ENV[‘OPENAI_API_KEY’])
Далее — процесс извлечения всех данных из текстовых файлов. В Ruby проходится папка training-data , данные каждого текстового файла считываются и сохраняются в массиве:
# embeddings.rb
# Данные каждого файла сохраняются в массиве
text_array = []
# В папке /training-data перебираются все файлы .txt
Dir.glob(«training-data/*.txt») do |file|
# Данные каждого файла считываются и добавляются в массив
# В методе dump пробелы преобразуются в символы новой строки n
text = File.read(file).dump()
text_array end
Все данные для обучения сохранены в text_array , преобразуем каждое тело текста в векторное вложение конечной точкой OpenAI embeddings , которой принимается два параметра: model в виде text-embedding-ada-002 и input в виде текста каждого файла:
# embeddings.rb
# Вложения сохраняются в этом массиве
embedding_array = []
# Перебирается каждый элемент массива
text_array.each do |text|
# Текст передается в API вложений, откуда возвращается вектор и
# сохраняется в переменной response.
response = openai.embeddings(
parameters: model: «text-embedding-ada-002»,
input: text
>
)
# Из объекта response извлекается вложение
embedding = response[‘data’][0][’embedding’]
# Создается хеш Ruby, в котором содержатся вектор и исходный текст
embedding_hash =
# Хеш сохраняется в массиве.
embedding_array end
Выводим переменную embedding и видим вектор из 1500 значений. Это векторное вложение.
В embedding_array сохраняются значения векторных вложений и исходного текста, впоследствии сохраняемые в БД для целей семантического поиска.
Этап 3. Сохранение вложений в CSV, т. е. в БД
Для целей этой статьи база данных заменяется CSV-файлом. У специализированных векторных БД очень эффективные алгоритмы семантического поиска. Для Ruby оптимальный инструмент — Redis с его векторным поиском.
На этом этапе создается CSV-файл с двумя столбцами — embedding и text — для сохранения из каждого файла исходного текста с его векторным вложением.
Импортируем библиотеку csv :
# embeddings.rb
require ‘dotenv’
require ‘ruby/openai’
require ‘csv’
Вот окончательный код для скрипта embeddings.rb , в нем создается CSV-файл с заголовками embedding и text , перебирается embedding_array , а соответствующие векторные вложения и текст сохраняются в CSV:
embeddings.rb
CSV.open(«embeddings.csv», «w») do |csv|
# Так задаются заголовки
csv embedding_array.each do |obj|
# Чтобы избежать ошибок с разделением запятыми между значениями в CSV,
# вектор вложения сохраняется в виде строки
csv end
end
Дальше скрипт embeddings.rb запускается, CSV-файл заполняется данными:
ruby embeddings.rb
Вот файловая структура после запуска:
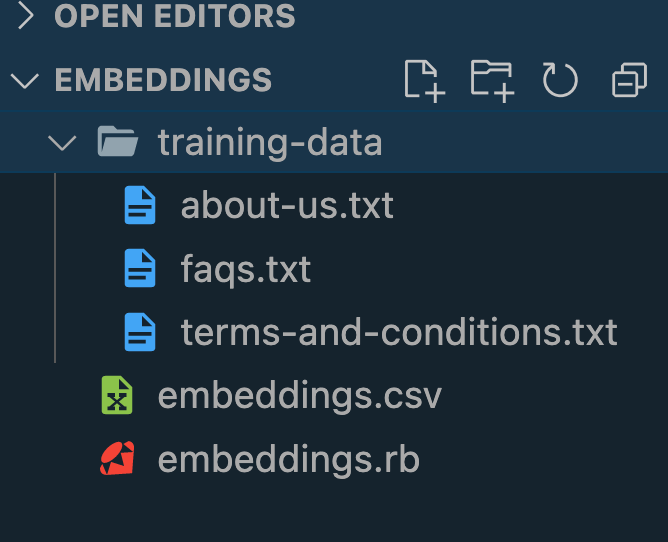
Этап 4. Получение вопроса пользователя
Переходим к Ruby-скрипту questions.rb . Это основной файл для запроса в CSV векторов вопроса пользователя. При выполнении возвращается исходный текст с наибольшим семантическим сходством и интеллектуальный ответ от GPT-3.
Он запускается в приложении Rails, и вопрос пользователя получается из текстового поля представления. Для простоты выполним все в CLI.
Создаем файл questions.rb и импортируем нужную библиотеку:
# questions.rb
require ‘dotenv’
require ‘ruby/openai’
require ‘csv’
Dotenv.load()
openai = OpenAI::Client.new(access_token: ENV[‘OPENAI_API_KEY’])
Вопрос пользователя будет в запросе к базе знаний, поэтому:
# questions.rb
puts «Welcome to the Sterling Parts AI Knowledge Base. How can I help you?»
question = gets
С помощью конечной точки OpenAI embeddings преобразуем вопрос пользователя в векторное вложение, чтобы потом математической формулой найти в файле embeddings.csv ближайший по сути и значению текст:
# questions.rb
# Вопрос преобразуется в векторное вложение
response = openai.embeddings(
parameters: model: «text-embedding-ada-002»,
input: question
>
)
# Значение вложения извлекается
question_embedding = response[‘data’][0][’embedding’]
Выводя вложение, увидим массив из 1500 значений. Это векторное вложение.
Этап 5. Поиск в CSV текста с ближайшим к вопросу семантическим значением
Здесь применяется косинусное сходство, им в машинном обучении определяется близость двух векторов. Это легко изобразить в двух измерениях на графике, поскольку у вектора два значения:
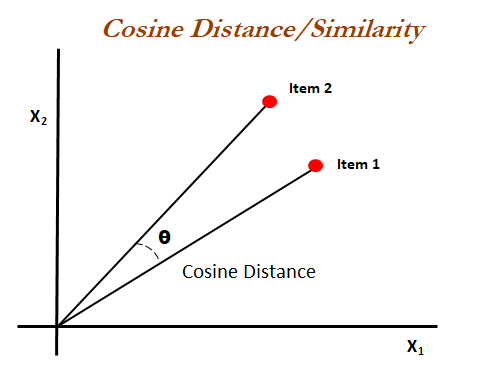
Косинусным сходством определяется отношение двух векторов. Его значение варьируется между 0 и 1, где 1 — идентичные векторы.
В векторных вложениях у векторов 1500 значений. Визуально представить это невозможно, тем не менее по косинусному сходству компьютером определяется, в каком текстовом файле содержатся ближайшие к вопросу пользователя смысловые значения.
С библиотекой Ruby cosine-similarity нет необходимости понимать внутренние механизмы выполняемых вычислений:
gem install cosine-similarity
Импортируем библиотеку вверху файла questions.rb :
# questions.rb
require ‘dotenv’
require ‘ruby/openai’
require ‘csv’
require ‘cosine-similarity’
Дальше перебираем все строки CSV-файла и сравниваем вектор вопроса с векторами исходного текста. В методе cosine_similarity вопрос сравнивается с каждым исходным текстом, возвращается число от 0 до 1.
Интересует сходство с наибольшим значением. Это текст, ближайший к вопросу по сути и значению:
# questions.rb
# По мере прохождения CSV в коде, показатели сходства сохраняются
similarity_array = []
# Проходится CSV, вычисляется косинусное сходство между
# вектором вопроса и вложением каждого текста
CSV.foreach(«embeddings.csv», headers: true) do |row|
# Вложение извлекается из столбца, выполняется его парсинг в массив
text_embedding = JSON.parse(row[’embedding’])
# В массив добавляется показатель сходства
similarity_array end
# Возвращается индекс наивысшего показателя сходства
index_of_max = similarity_array.index(similarity_array.max)
В переменной index_of_max теперь содержится индекс наивысшего показателя сходства. Им из CSV извлекается текст, который с вопросом пользователя отправляется в GPT-3:
# questions.rb
# Так сохраняется исходный текст
original_text = «»
# Проходится CSV, находится текст с наивысшим
# показателем сходства
CSV.foreach(«embeddings.csv», headers: true).with_index do |row, rowno|
if rowno == index_of_max
original_text = row[‘text’]
end
end
Этап 6. Передача пользовательского вопроса и текста базы знаний в конечную точку GPT-3 completions
Остаемся с файлом questions.rb . В скрипте теперь хранятся вопрос пользователя question и исходный текст original_text , ближайшие друг к другу по значению. Чтобы получить на вопрос пользователя интеллектуальный ответ, передадим эту информацию в конечную точку GPT-3 completions .
Специальной подсказкой GPT-3 подводится к тому, чтобы отвечать должным образом, соответственно вопросу пользователя и назначению базы знаний. Это делается в рамках структуры подсказки:
prompt =
«You are an AI assistant. You work for Sterling Parts which is a car parts
online store located in Australia. You will be asked questions from a
customer and will answer in a helpful and friendly manner.
You will be provided company information from Sterline Parts under the
[Article] section. The customer question will be provided unders the
[Question] section. You will answer the customers questions based on the
article.
If the users question is not answered by the article you will respond with
‘I’m sorry I don’t know.’
[Article]
#
[Question]
#»
В хорошей подсказке достаточно информации для формирования шаблона ответа. В первом абзаце GPT подводится к тому, как отвечать на вопрос пользователя, а во втором — дается контекст для определения информации, используемой GPT в ответе. В нижней части из предыдущих этапов вставляются original_text и question .
Если от GPT лучшего ответа не поступает, стоит поменять подсказку и поэкспериментировать с ней в интерактивной среде OpenAI.
Дальше, чтобы получить интеллектуальный ответ, подсказка передается в конечную точку GPT completions :
response = openai.completions(
parameters: model: «text-davinci-003»,
prompt: prompt,
temperature: 0.2,
max_tokens: 500,
>
)
Температура в коде низкая, а значит, от GPT вернется наиболее вероятный ответ. Хотите от GPT более творческого подхода к ответам? Увеличьте ее до 0,9.
Ответ в этой конечной точке сгенерируется за секунды — в зависимости от нагрузки сервера.
Этап 7. Получение ответа от GPT-3 и отображение его для пользователя
В конце выводим ответ GPT для пользователя:
puts «nAI response:n»
puts response[‘choices’][0][‘text’].lstrip
Отладка ответа
Почему от GPT возвращается неудовлетворительный ответ. Три фактора:
- Подготовка данных.
- Структура подсказки.
- Параметр температуры.
Подготовка данных
По возможности создавайте каждый файл содержащим близкое значение. Если файл обрывается в середине предложения и следующий возобновляется на полпути, это чревато проблемой поиска точного текста для передачи в GPT.
Чтобы доработать поиск сходства, разбейте их на мелкие, сгруппированные по значению тексты.
Структура подсказки
Здесь нужна практика, метод проб и ошибок вне конкуренции.
Чем яснее и однозначнее подсказка, тем адекватнее вашим задачам генерируемые в GPT результаты.
Параметр температуры
Если вкратце, температурой определяется случайность или «креативность» модели: при низкой температуре ответы ожидаемые, при высокой к ним более творческий подход. Чтобы получить результаты под свои задачи, поэкспериментируйте с этим параметром.
Доработка модели
В специфических ситуациях, чтобы получать адекватные базе знаний и пользователям ответы, требуется дообучение модели.
Имеется ряд подходов, которые сводятся к встроенной подводке и тонкой настройке.
Встроенная подводка заключается в приведении в подсказке примеров вопросов и ответов, например, для получения от GPT ответов в конкретном формате или определенным способом. Я часто применяю этот подход, когда нужен ответ в JSON.
Тонкая настройка — совершенно иной подход, применяемый для обучения собственной GPT-модели задачам, которым она ранее не обучалась. Например, задавать ей вопросы, нацеленные на извлечение конкретной информации.
- Как я создал расширение браузера и обучил ChatGPTобращатьсяк внешним сайтам за информацией о текущих событиях
- Как работает GPT3
- Раскройте потенциал VS Code для программирования на Ruby
Читайте нас в Telegram, VK и Дзен
Источник: nuancesprog.ru
Задать вопрос пользователю, ответ на вопрос


17 правил для составления оптимального ЗАПРОСа к данным базы 1С 50
Для формирования и выполнения запросов к таблицам базы данных в платформе 1С используется специальный объект языка программирования Запрос . Создается этот объект вызовом конструкции Новый Запрос . Запрос удобно использовать, когда требуется получ 1C и Google Maps 21
была поставлена задача отображения на географической карте медицинских учреждений. После обзора предлагаемых решений был выбран сервис google. Но так же подобного рода подход будет работать и с картами сервиса yandex. Во время решения задачи было реш 1C: Enterprise Development Tools 51
И вот случилось долгожданное: Вышел 1C: Enterprise Development Tools — это среда для разработки конфигурации в IDE Eclipse. С сайта 1С: « 1C:Enterprise Development Tools » – это инструмент нового поколения для разработчиков бизнес-приложений систем 1С Предприятие что это? 12
Что такое 1С? 1С — это фирма , у которой одно из направлений деятельности — разработка программного обеспечения для автоматизации бизнес-процессов предприятий. « 1С:Предприятие » — конкретный продукт, который выпускает компания 1С . Что такое COM-подключение к базе 7.7 из .NET, .NET Core 1
Инсталяция: dotnet add package sabatex.V1C77 или добавить через NUGET пакет sabatex.V1C77. Добавить пространство имен: using sabatex.V1C77; пример использованя: —C# static void Main(string args) < // создаем строку соединен Посмотреть все результаты поиска похожих
Еще в этой же категории
Полнотекстовый поиск в 1С (что это и пример использования) 27
Полнотекстовый поиск — позволит найти текстовую информацию, размещенную практически в любом месте используемой конфигурации. При этом искать нужные данные можно либо по всей конфигурации в целом, либо сузив область поиска до нескольких объектов Формат, функция форматирования значений 21
//Функция формирует удобное для чтения представление значений. // Примеры форматирования чисел ЗначФормат = Формат(123456.789, » ЧЦ=10; ЧДЦ=2″ ); // ЗначФормат = » 123 456,79″ ЗначФормат = Формат(123456.789, » ЧГ=0; ЧДЦ=2″ ); // Знач Обработчики событий при записи объектов. Зачем и что за чем? 18
Программисту, имеющего немного опыта на платформе 1С 8.2, бывает сложно разобраться: ПередЗаписью, ПриЗаписи, ПослеЗаписи, на сервере, на клиенте, в модуле формы, в модуле объекта, а-а-а-а-аааа. Именно такое сложное чувство непонимания УстановитьСсылкуНового 12
Установить ссылку нового это специальный механизм программиста, который позволяет присваивать новому объекту нужную ссылку. В основном это задача обмена, во многих типовых обменах используется синхронизация по UID объекта. Рассмотрим этот метод на к МоментВремени, получение остатков до и после проведения 11
» Момент времени» — виртуальное поле, не хранится в базе данных. Содержит объект МоментВремени (который включает в себя дату и ССЫЛКУ НА ДОКУМЕНТ) В 7.7 было понятие ПозицияДокумента, а в 8.x Момент времени Для получения Остатков, Движений: М Посмотреть все в категории Встроенные Функции
Источник: helpf.pro